Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
本当はこわいエンコーディングの話
Search
とみたまさひろ
January 13, 2013
Programming
10k
15
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
本当はこわいエンコーディングの話
東京Ruby会議10 で発表したスライド
とみたまさひろ
January 13, 2013
More Decks by とみたまさひろ
See All by とみたまさひろ
MySQLとPostgreSQLのコレーション / Collation of MySQL and PostgreSQL
tmtms
1
1.8k
文字列の並び順 / Unicode Collation
tmtms
4
1.1k
夢の印税生活 / Life on Royalties
tmtms
0
630
文字列の並び順 / String Collation
tmtms
1
230
日本MySQLユーザ会ができるまで / making MyNA
tmtms
1
1.1k
Ruby on Browser - RubyWorld Conference 2024
tmtms
1
1.6k
Ruby on Browser
tmtms
1
2.3k
私のRSpecの書き方 / How I write RSpec
tmtms
5
2.3k
ショートカットと端末 / shortcut & terminal
tmtms
2
1.1k
Other Decks in Programming
See All in Programming
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
310
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
110
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
170
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
180
1B+ /day規模のログを管理する技術
broadleaf
0
130
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
継続モナドとリアクティブプログラミング
yukikurage
3
490
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
510
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.3k
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.8k
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
3.4k
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
140
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Visualization
eitanlees
152
17k
Rails Girls Zürich Keynote
gr2m
96
14k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Everyday Curiosity
cassininazir
0
250
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
190
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Music & Morning Musume
bryan
47
7.3k
BBQ
matthewcrist
89
10k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
How to build a perfect <img>
jonoalderson
1
5.8k
Transcript
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 本当はこわい エンコーディングの話 とみたまさひろ 東京Ruby会議10 2013-01-13
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 自己紹介 とみた まさひろ http://tmtms.hatenablog.com https://twitter.com/tmtms
好きなもの/環境 Ruby, Rabbit, MySQL, Emacs, Git, Ubuntu, ThinkPad 所属など 長野県北部在住 / 某社プログラマー / 日本 MySQLユーザ会 / 長野ソフトウェア技術者 グループ(NSEG)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディング
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディングとは 文字符号化方式 文字をどのようなバイト列で表現するか UTF-8 とか
EUC-JP とか SHIFT_JIS と かそーゆー奴 「charset」とか呼ばれたりする 「文字コード」とか呼ばれたりする
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 同じバイト列でも別の文字 0xC2 0xA9 の2バイトは UTF-8
では「©」1文字 EUC-JP では「息」1文字 SHIFT_JIS では「ツゥ」2文字
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Ruby 1.8 "\xC2\xA9" という文字列は Ruby
的に はただのバイト列 エンコーディング情報を持たない "©"(UTF-8) として扱うか "息"(EUC-JP) として扱うかはプログラム次第 正規表現にはエンコーディングあり /〜/n /〜/s /〜/u /〜/e
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Ruby 1.9 文字列のエンコーディングは文字列自身が 知っている "©"(UTF-8)
と "息"(EUC-JP) は同じバイ ト列だけど異なる文字列 "あ"(UTF-8) と "あ"(EUC-JP) は同じ文 字を表してるけど等しくない 同じプログラム中で複数のエンコーディ ングの文字列を同時に扱える(珍しいかも) 正規表現にもエンコーディングあり
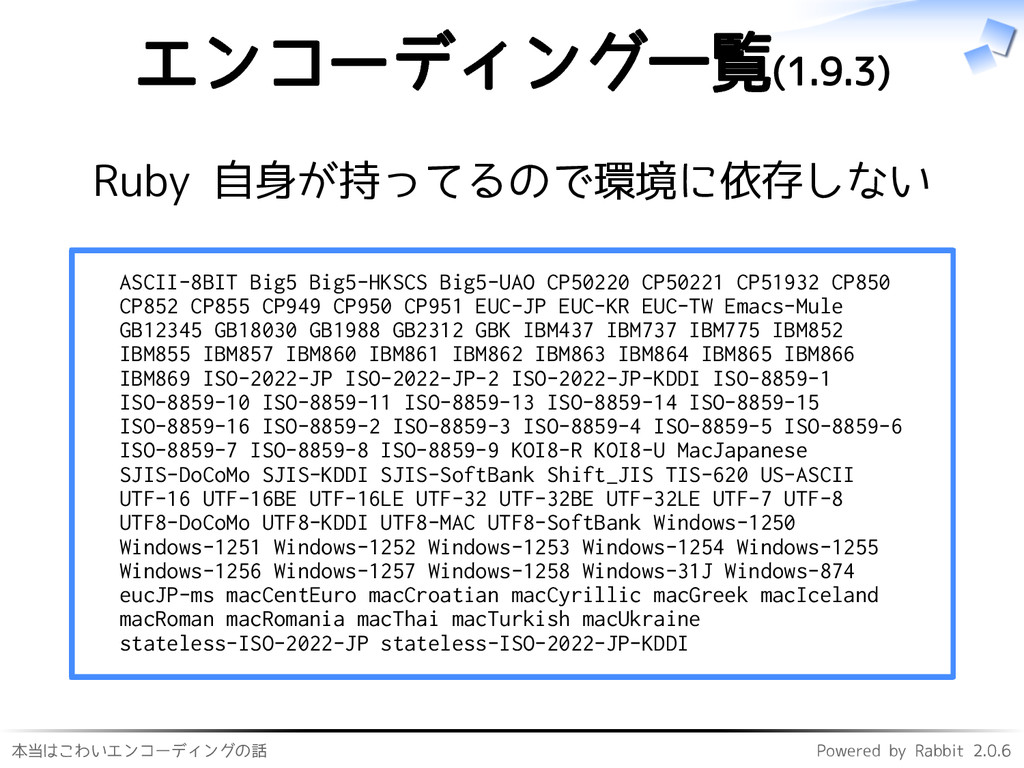
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディング一覧(1.9.3) Ruby 自身が持ってるので環境に依存しない ASCII-8BIT Big5
Big5-HKSCS Big5-UAO CP50220 CP50221 CP51932 CP850 CP852 CP855 CP949 CP950 CP951 EUC-JP EUC-KR EUC-TW Emacs-Mule GB12345 GB18030 GB1988 GB2312 GBK IBM437 IBM737 IBM775 IBM852 IBM855 IBM857 IBM860 IBM861 IBM862 IBM863 IBM864 IBM865 IBM866 IBM869 ISO-2022-JP ISO-2022-JP-2 ISO-2022-JP-KDDI ISO-8859-1 ISO-8859-10 ISO-8859-11 ISO-8859-13 ISO-8859-14 ISO-8859-15 ISO-8859-16 ISO-8859-2 ISO-8859-3 ISO-8859-4 ISO-8859-5 ISO-8859-6 ISO-8859-7 ISO-8859-8 ISO-8859-9 KOI8-R KOI8-U MacJapanese SJIS-DoCoMo SJIS-KDDI SJIS-SoftBank Shift_JIS TIS-620 US-ASCII UTF-16 UTF-16BE UTF-16LE UTF-32 UTF-32BE UTF-32LE UTF-7 UTF-8 UTF8-DoCoMo UTF8-KDDI UTF8-MAC UTF8-SoftBank Windows-1250 Windows-1251 Windows-1252 Windows-1253 Windows-1254 Windows-1255 Windows-1256 Windows-1257 Windows-1258 Windows-31J Windows-874 eucJP-ms macCentEuro macCroatian macCyrillic macGreek macIceland macRoman macRomania macThai macTurkish macUkraine stateless-ISO-2022-JP stateless-ISO-2022-JP-KDDI
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 うれしいこと
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 1.8ではバイト単位 "あいう".size #=> 9 "あいう".bytesize
#=> 9 "あいう".chars{|c| ... } #=> "\xE3","\x81","\x82", ... "あいう"[0] #=> 0xE3 "あいう".reverse #=> "\x86\x81\xE3\x84\x81\xE3\x82\x81\xE3"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 1.9では文字単位 "あいう".size #=> 3 "あいう".bytesize
#=> 9 "あいう".chars{|c| ... } #=> "あ", "い", "う" "あいう"[0] #=> "あ" "あいう".reverse #=> "ういあ"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディング変換 # -*- coding: utf-8
-*- s = "あいう" #=> "\xE3\x81\x82\xE3\x81\x84\xE3\x81\x86" s.encoding #=> #<Encoding:UTF-8> s2 = s.encode("CP932") #=> "\x82\xA0\x82\xA2\x82\xA4" s2.encoding #=> #<Encoding:Windows-31J>
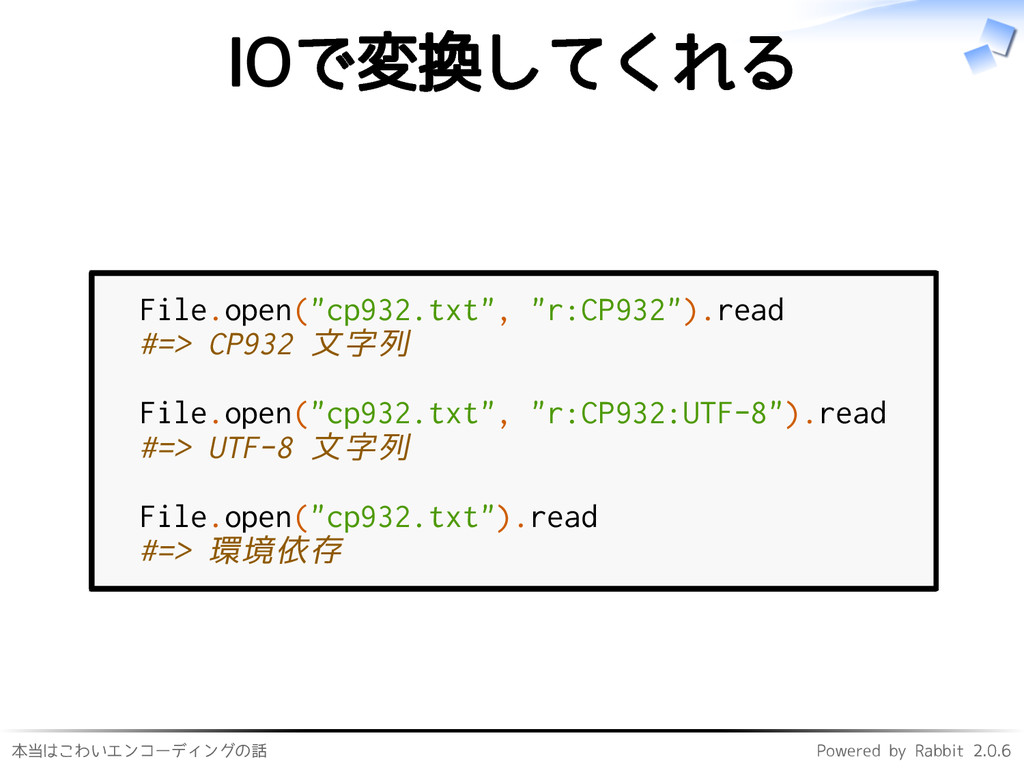
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 IOで変換してくれる File.open("cp932.txt", "r:CP932").read #=> CP932
文字列 File.open("cp932.txt", "r:CP932:UTF-8").read #=> UTF-8 文字列 File.open("cp932.txt").read #=> 環境依存
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 うれしいことばかりじゃない
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 変換先にない文字 # -*- coding: utf-8
-*- "あ♥".encode("CP932") #=> Encoding::UndefinedConversionError
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 変換元にない文字 # -*- coding: utf-8
-*- "あ\xFF".encode("CP932") #=> Encoding::InvalidByteSequenceError
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディングがあっても 変換できるとは限らない # -*- coding:
utf-8 -*- "あいう".encode("UTF-7") #=> Encoding::ConverterNotFoundError
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディングの不一致 utf8 = "あいう" cp932
= "あ".encode("CP932") utf8.start_with?(cp932) #=> Encoding::CompatibilityError
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 文字列と正規表現の エンコーディングの不一致 utf8 = "あいう"
re = /./s utf8 =~ re #=> Encoding::CompatibilityError
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディングが同じでも 不正な文字を含んでいる utf8 = "あ\xFF"
utf8 =~ /./ #=> invalid byte sequence in UTF-8 # (ArgumentError)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 IO
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 メソッドによって エンコーディングが異なる テキスト読み込み(エンコードあり) IO#gets IO#getc
IO#lines IO#read 等 バイナリ読み込み(ASCII-8BIT固定) IO#read(n) IO#sysread 等
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 IO#read IO#read(size) は ASCII-8BIT IO#read()
は外部エンコーディング依存 引数の有無によって結果のエンコーディ ングが異なる! なにそれこわい
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 外部エンコーディング ファイル自身は自分の内容のエンコーデ ィングを知らない ファイルから読み込んだ文字列の Ruby
内でのエンコーディングは何らかの方法 で指定する必要がある
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 引数で指定 File.open(filename, "r:UTF-8") File.read(filename, :encoding=>"UTF-8")
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 環境変数 引数で指定されてない場合は環境変数が参照 される LC_ALL LC_CTYPE
LANG
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 環境変数による違い % cat utf-8.txt あいうえお
% export LC_ALL=C % ruby -e 'p File.read("utf-8.txt").size' 16 % export LC_ALL=ja_JP.UTF-8 % ruby -e 'p File.read("utf-8.txt").size' 6 環境変数によって動きが変わっちゃう!こわい
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 入力時にはエラーにならない utf8 = File.read("utf8.txt", :encoding=>"UTF-8")
# 実は UTF-8 として不正な文字が含まれていて 〜〜〜〜〜〜 # ずっと後で別のメソッドでエラーになったり utf8 =~ /./ #=> invalid byte sequence in UTF-8 (ArgumentError)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 CGI require "cgi" cgi =
CGI.new 不正な文字のパラメータを渡すとエラー GET http://example.com/hoge.cgi?fuga=%FF #=> Accept-Charset encoding error (CGI::InvalidEncoding)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Rails 不正な文字のパラメータを渡すとエラー POST http://example.com/posts post[title]=%FF
#=> ArgumentError (invalid byte sequence in UTF-8)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エラーになりすぎこわい!
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 対処
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 変換先にない文字を置換 "あ♥".encode("CP932") #=> Encoding::UndefinedConversionError "あ♥".encode("CP932",
:undef=>:replace) #=> "あ?"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 変換元にない文字を置換 "あ\xFF".encode("CP932") #=> Encoding::InvalidByteSequenceError "あ\xFF".encode("CP932",
:invalid=>:replace) #=> "あ?"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 置換文字の指定 "あ♥".encode("CP932", :undef=>:replace, :replace=>"〓") #=>
CP932 で "あ〓"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 そもそも変換が必要になるような ことをしないのが吉
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 UTF-8に統一すれば たいていは問題ない
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 UTF-8に統一したつもりでも 他のエンコーディングが現れるこ とも File.open(filename, "r:UTF-8").read
#=> UTF-8 文字列 File.open(filename).read #=> 環境依存
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 いちいち引数で指定する?
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 デフォルト値を指定する プログラムで使用するファイルのエンコーディ ングがすべて同一であれば Encoding.default_external =
"UTF-8" File.read(filename) #=> UTF-8文字列
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 これで問題ない?
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 ASCII-8BIT
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 メソッドによっては ASCII-8BIT f = File.open(filename,
"r:UTF-8") f.gets #=> UTF-8 f.read(10) #=> ASCII-8BIT
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 ソケットは ASCII-8BIT require 'socket' Encoding.default_external
= "UTF-8" TCPSocket.new('127.0.0.1', 25).gets #=> ASCII-8BIT
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 気をつけるしかない
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 不正な文字
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 エンコーディングがUTF-8でも データがUTF-8とは限らない f = File.open("/dev/urandom",
"r:UTF-8") str = f.gets str.encoding #=> #<Encoding:UTF-8> str =~ /./ #=> invalid byte sequence in UTF-8 (ArgumentError)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 事前に判定 String#valid_encoding? f = File.open("/dev/urandom",
"r:UTF-8") str = f.gets str.valid_encoding? #=> false
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 不正な文字を置換したい 簡単な方法はない String#encode は変換元と変換先が同じ 場合は何もしない
# -*- coding: utf-8 -*- "あ\xFF".encode("CP932", :invalid=>:replace) #=> "あ?" "あ\xFF".encode("UTF-8", :invalid=>:replace) #=> "あ\xFF"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Iconv ではできたけど… require "iconv" src
= "あい\xFFうえ" dst = "" iconv = Iconv.new("utf-8", "utf-8") begin dst.concat iconv.iconv(src) rescue Iconv::IllegalSequence => e dst.concat e.success dst.concat "〓" src = e.failed[1..-1] retry end dst #=> "あい〓うえ" Iconv は 2.0 で廃止
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 同じ文字群を持つ 別のエンコーディングを経由 "あ\xFF". encode("UTF-16", :invalid=>:replace).
encode("UTF-8") #=> "あ�"
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 2.0.xだとできるようになる?
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 CGI や Rails
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 パラメータが不正な文字で エラー 放置でいいんじゃない? 外部からの不正なデータは最前線でエラー になってくれた方がありがたかったり
後の処理に渡されても扱いに困るだけ 実害はログが鬱陶しいくらい?
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 CGIで頑張るなら require 'cgi' # 一旦
ASCII-8BIT で受けて cgi = CGI.new :accept_charset=>"ASCII-8BIT" # パラメータ毎にどうにかする hoge = cgi['hoge'].encode("UTF-8", "UTF-8") unless hoge.valid_encoding? ...
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Railsは... よくわかりません (><)
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 おまけ
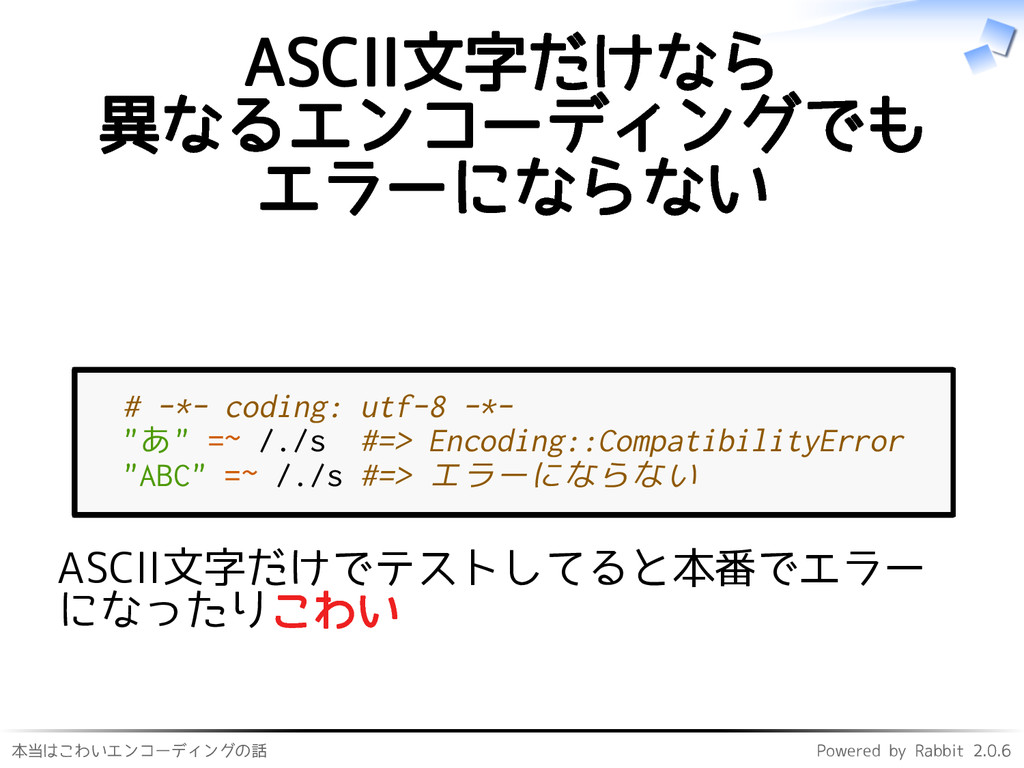
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 ASCII文字だけなら 異なるエンコーディングでも エラーにならない # -*-
coding: utf-8 -*- "あ" =~ /./s #=> Encoding::CompatibilityError "ABC" =~ /./s #=> エラーにならない ASCII文字だけでテストしてると本番でエラー になったりこわい
本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 まとめ 内部のエンコーディングは UTF-8 に統一 しよう
IO 読み込みで ASCII-8BIT になってるこ とがある 外部からのデータは不正な文字が入ってる ことがある ちゃんと気をつければそんなに こわくない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![本当はこわいエンコーディングの話 Powered by Rabbit 2.0.6 Rails 不正な文字のパラメータを渡すとエラー POST http://example.com/posts post[title]=%FF](https://files.speakerdeck.com/presentations/8f975be03f0401304c57123138154bc3/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}