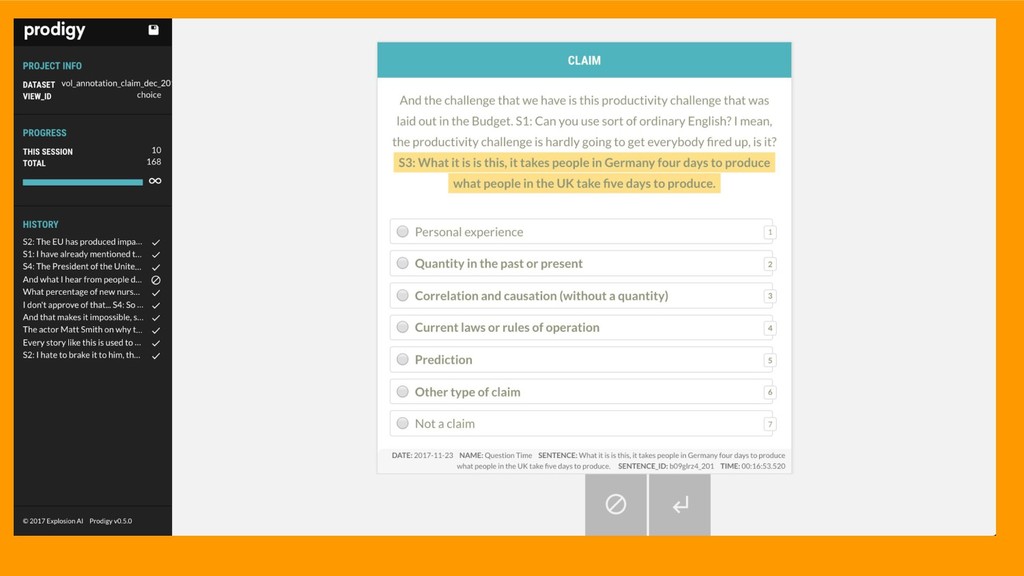
“The government has spent £3bn on reorganisation of the NHS” But excluding Personal Experience “I am a qualified social worker, qualified for over 20 years.” (abridged definition)
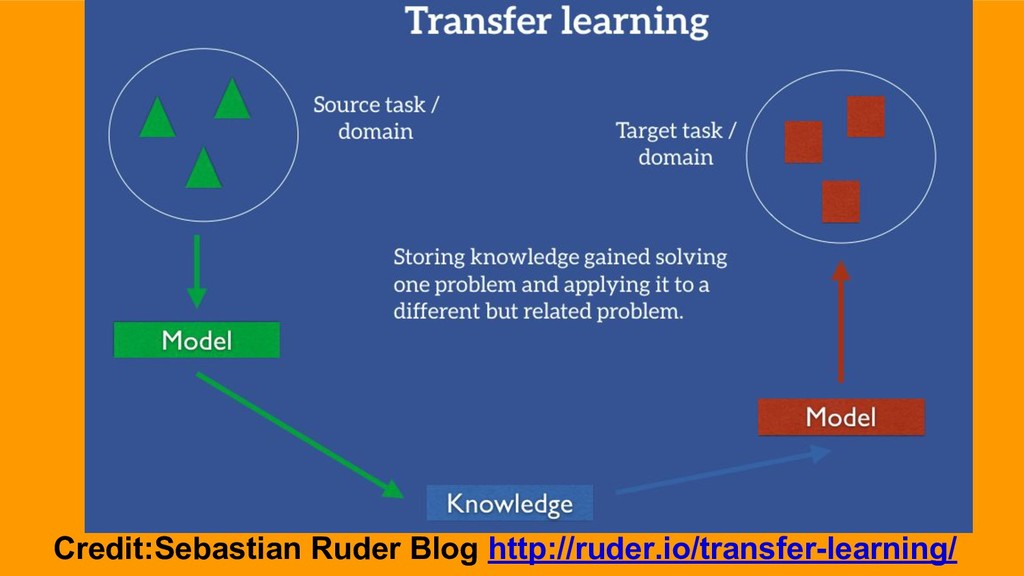
GloVe on Common Crawl 840B words (unsupervised) - Trained on a Natural Language Inference tasks 1M sentence pairs. (supervised) - InferSent + logistic evaluated on 10 transfer tasks. - Better than attention, CNN and other
“Two dogs are running through a field” - Definitely True: “There are animals outdoors” - Might be true: “Some puppies are running to catch a stick” - Definitely False: “The pets are sitting on a couch”
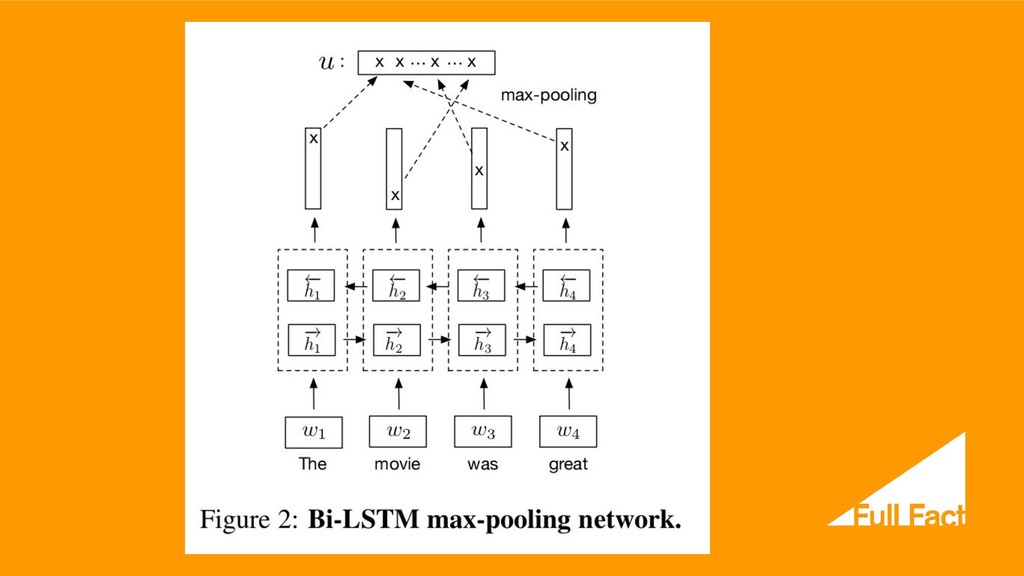
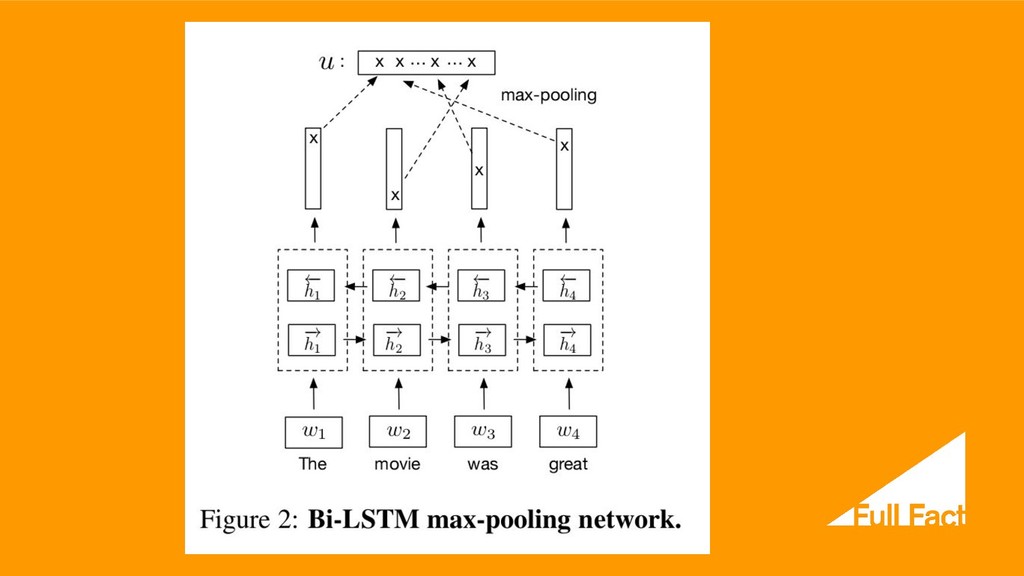
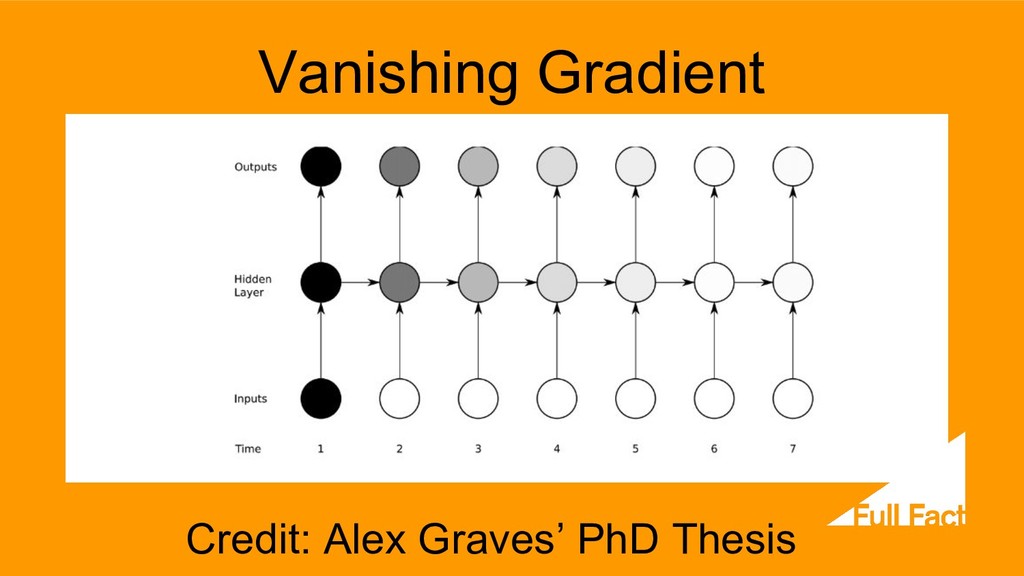
can we base our understanding of what we’ve heard on something that hasn’t been said yet? ...Sounds, words, and even whole sentences that at first mean nothing are found to make sense in the light of future context.” Alex Graves and Jurgen Schmidhuber, “Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures”, 2005
1) Precision mistake. Label something that is not a claim as a claim. WRONG: “Chocolate is great.” is a claim 2) Recall mistake. Label something that is a claim as not a claim. WRONG: “350 million a week for the EU” is not a claim
Benj Pettit, Data Scientist, Elsevier Michal Lopuszynski, Data Scientist, Warsaw University Oliver Price, Masters student, Warwick University Andreas Geroski, our best annotator Let’s talk if you are interested in volunteering
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}