case universally acknowledged, that a single woman in defiance of a good sense, must be in use of a son. It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.
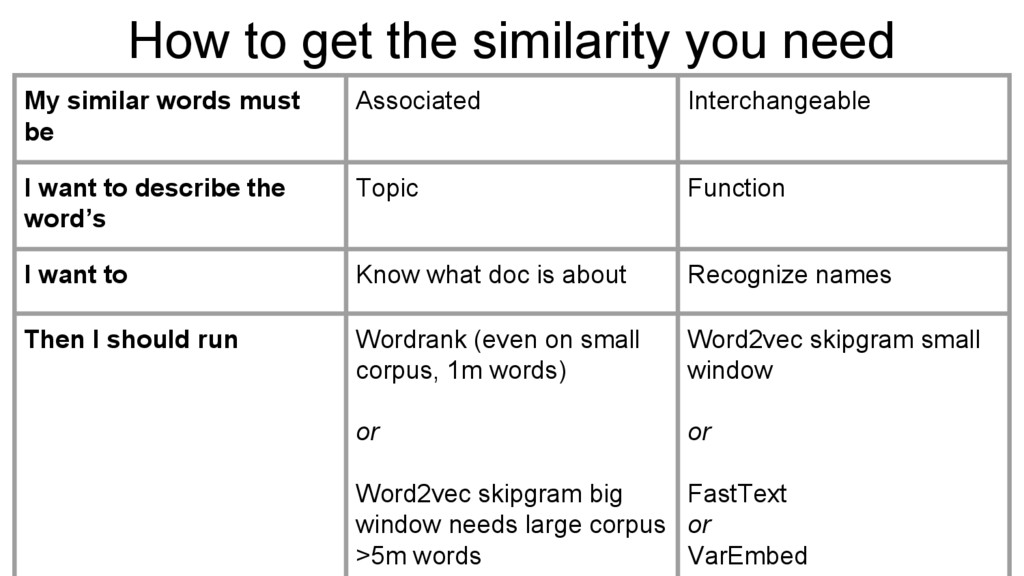
must be Associated Interchangeable I want to describe the word’s Topic Function I want to Know what doc is about Recognize names Then I should run Wordrank (even on small corpus, 1m words) or Word2vec skipgram big window needs large corpus >5m words Word2vec skipgram small window or FastText or VarEmbed
[GANs will get there in 3 years too :)] Google ran word2vec on 100billion of unlabelled words. Then shared their trained model. Thanks to Google for cutting our training time to zero!. :)
- Factorise the co-occurence matrix (SVD/LSA) - GLoVe - EigenWords - WordRank - VarEmbed - FastText Disclaimer Word2vec is not the only word embedding in the world
the company it keeps” -J. R. Firth 1957 Richard Socher’s NLP course http://cs224d.stanford.edu/lectures/CS224d-Lecture2.pdf How to come up with an embeddig?
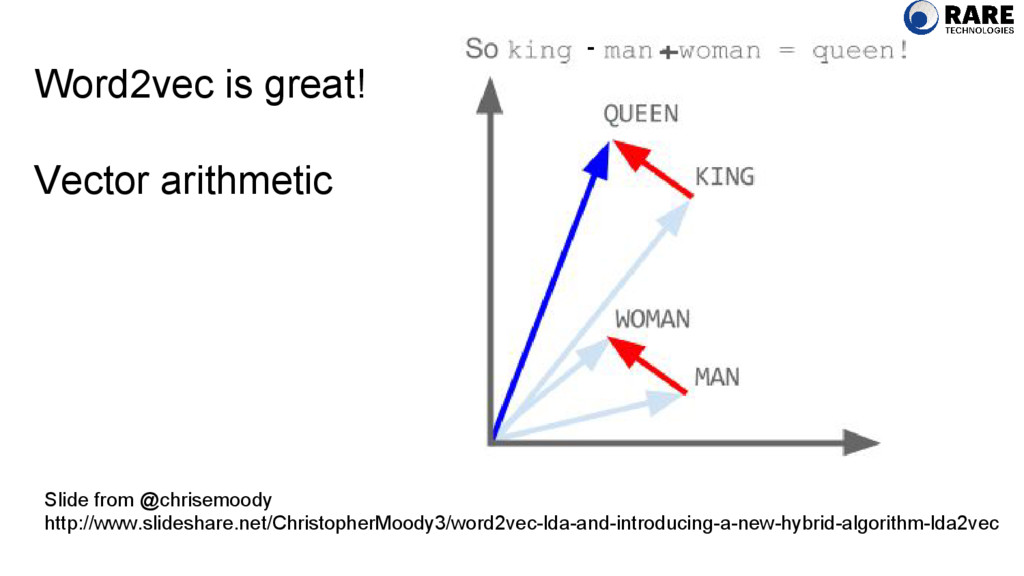
of seeing the context words given the word over. P(the|over) P(fox|over) P(jumped|over) P(the|over) P(lazy|over) P(dog|over) word2vec algorithm Used with permission from @chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec
from @chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec P(fox|over) P(v fox |v over )
from @chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT = P(v THE |v OVER )
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
@chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec Should depend on whether it’s the input or the output. P(v OUT |v IN ) “The fox jumped over the lazy dog” v IN v OUT
similarity. How similar are two vectors? Just dot product for unit length vectors v OUT * v IN Used with permission from @chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec
1] Normalization term over all out words Used with permission from @chrisemoody http://www.slideshare.net/ChristopherMoody3/word2vec-lda-and-introducing-a-new-hybrid-algorithm-lda2vec
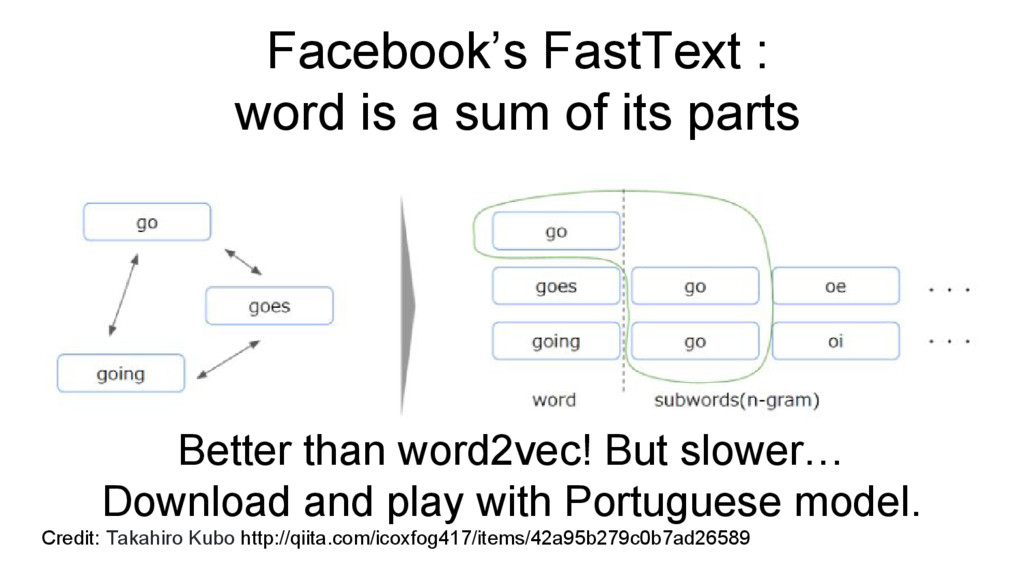
Credit: Takahiro Kubo http://qiita.com/icoxfog417/items/42a95b279c0b7ad26589 Better than word2vec! But slower… Download and play with Portuguese model.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Get a probability in [0,1] out of similarity in [-1,](https://files.speakerdeck.com/presentations/e38711838d3f4e8c8dd462a9c58d3610/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}