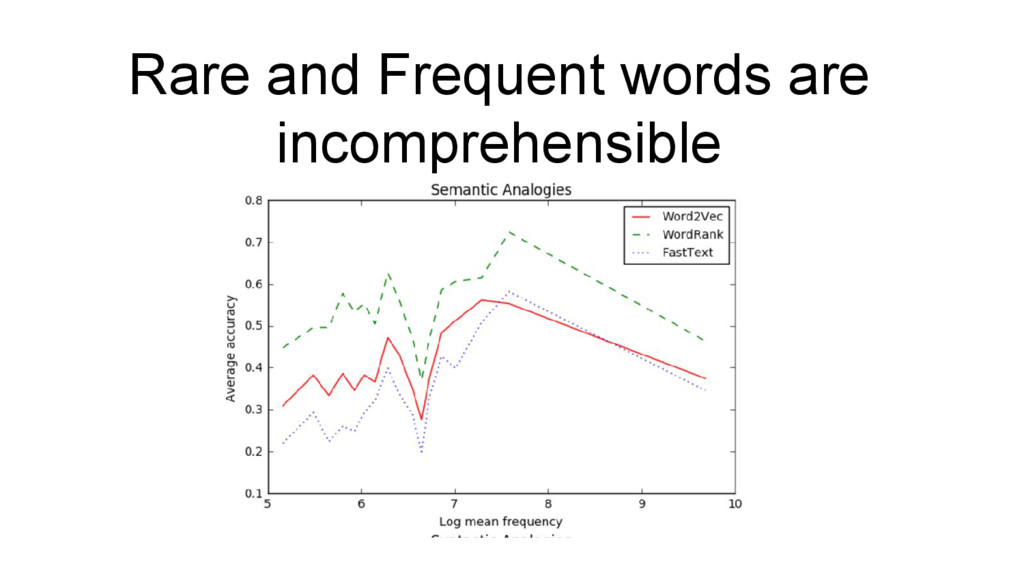
must be Associated Interchangeable I want to describes the word’s Topic Function I want to Know what doc is about Recognize names Then I should run Wordrank (even on small corpus, 1m words) or Word2vec skipgram big window needs large corpus >5m words Word2vec skipgram small window or FastText or VarEmbed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}