... ... the cute furry cat purred and miaowed ... ... that the cute kitten miaowed and she ... ... the loud furry dog ran and bit ... kitten context words: [cute, purred, miaowed]. cat context words: [cute, furry, miaowed]. dog context words: [loud, furry, ran, bit]. Credit: Ed Grefenstette https://github.com/oxford-cs-deepnlp-2017/
log n, in Glove log(X) cute furry bit … kitten 2 0 0 ... cat 1 1 0 ... dog 0 1 1 ... ... ... ... ... ... X = = U * V Dims: vocab x vocab = (vocab x small) * (small x vocab) First row of U is the word embedding of “kitten”
Word Kitten Classification problem WordRank Input: Context Cute Output: Ranking 1. Kitten 2. Cat 3. Dog Robust: Mistake at the top of the rank costs more than mistake at the bottom.
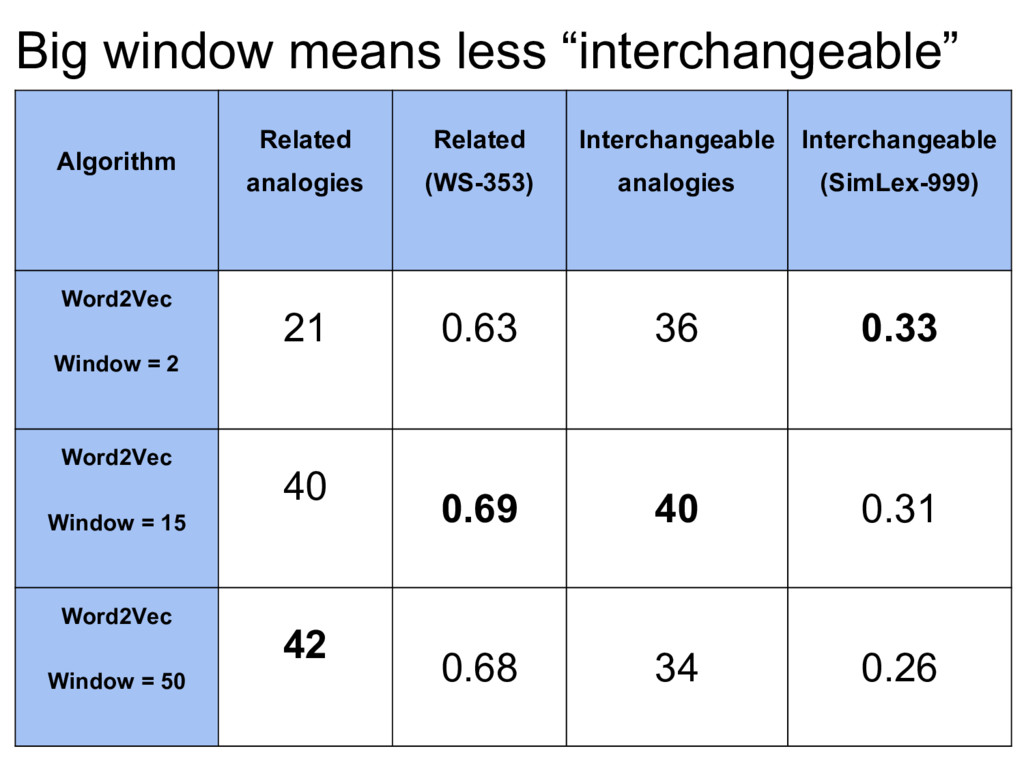
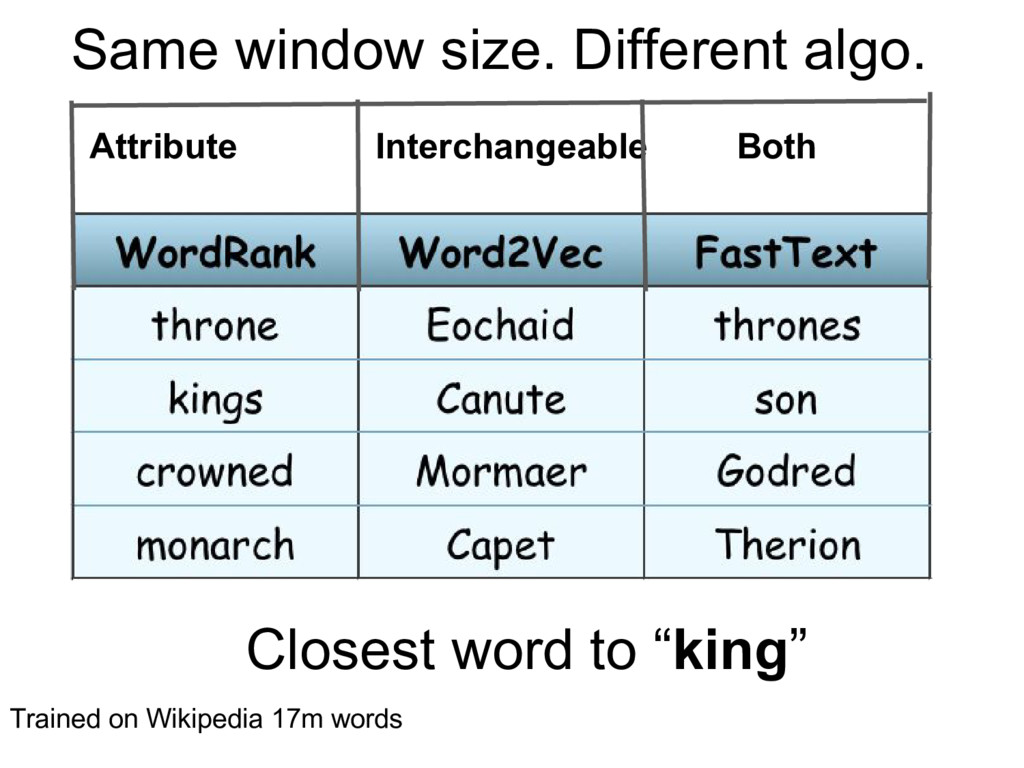
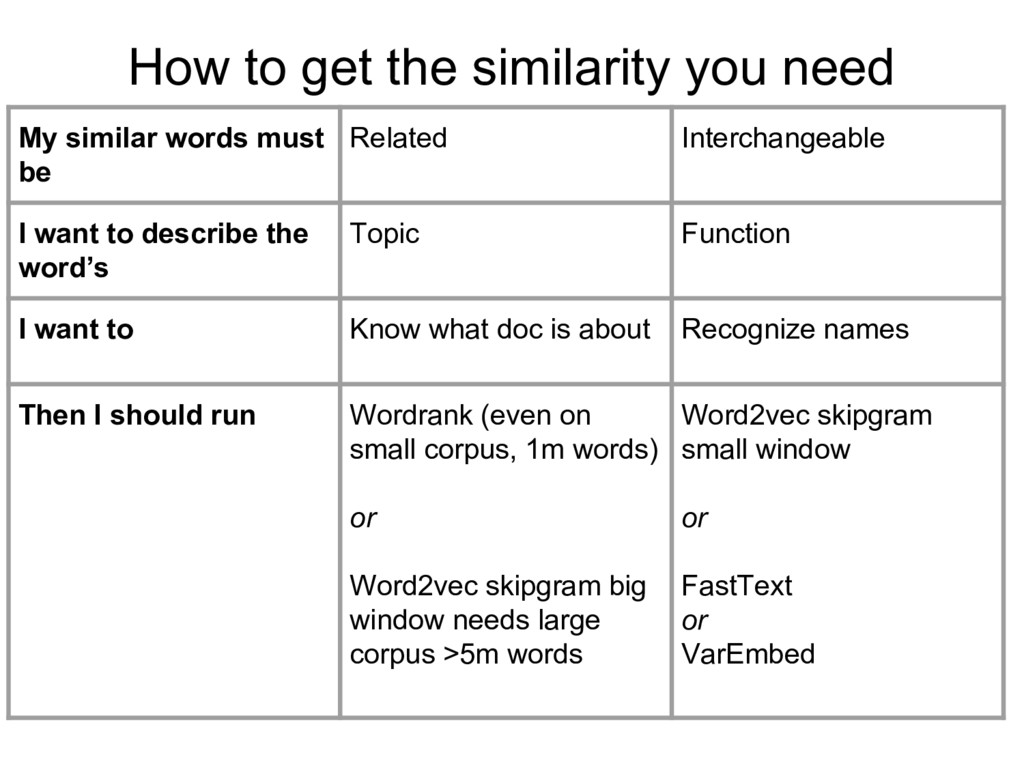
must be Related Interchangeable I want to describe the word’s Topic Function I want to Know what doc is about Recognize names Then I should run Wordrank (even on small corpus, 1m words) or Word2vec skipgram big window needs large corpus >5m words Word2vec skipgram small window or FastText or VarEmbed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Co-occurence matrix kitten context words: [cute, purred, miaowed]. cat context](https://files.speakerdeck.com/presentations/36e596fe10c9411693582a6f898560ab/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}