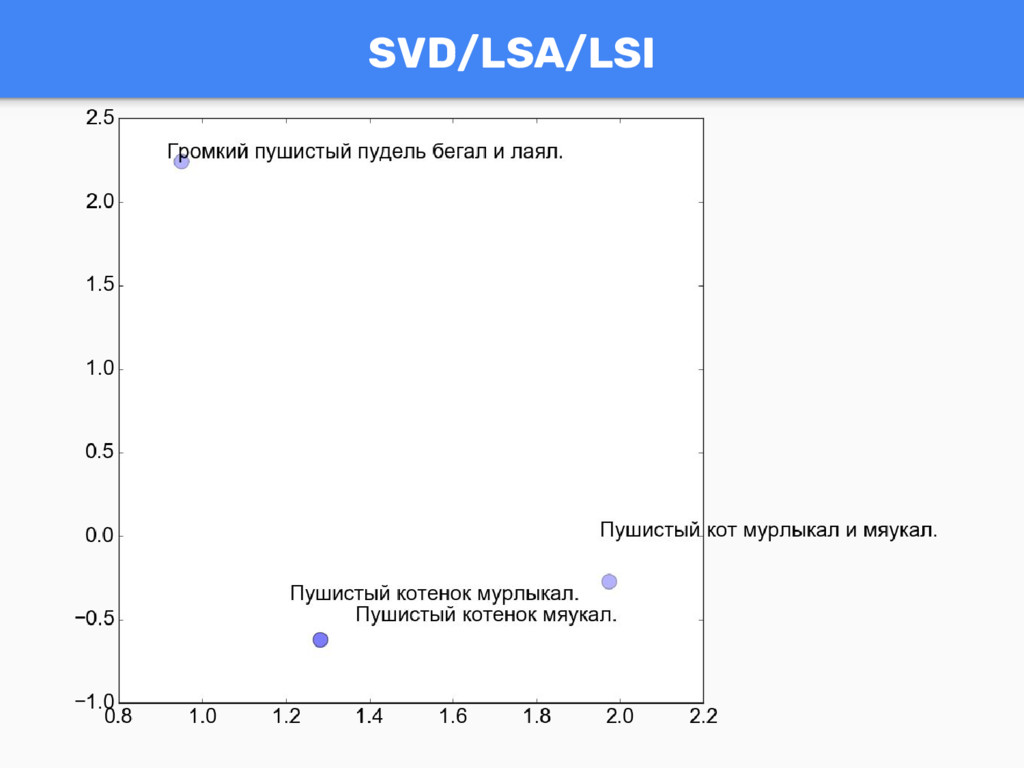
texts = [u"Пушистый котенок мурлыкал." , u"Пушистый кот мурлыкал и мяукал.", u"Пушистый котенок мяукал.", u"Громкий пушистый пудель бегал и лаял."] tokenized_texts = [list(tokenize(text.lower())) for text in texts] dictionary = Dictionary(tokenized_texts) corpus = [dictionary.doc2bow(text) for text in tokenized_texts] corpus(doc-term matrix): [[(0, 1), (1, 1), (2, 1)], [(1, 1), (2, 1), (3, 1), (4, 1), (5, 1)], [(0, 1), (1, 1), (5, 1)], [(1, 1), (4, 1), (6, 1), (7, 1), (8, 1), (9, 1)]]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CO-OCCURRENCE MATRIX FOR DOC2VEC котенок context words: [пушистый, мурлыкал, мяукал].](https://files.speakerdeck.com/presentations/fa6dadef64204871affa3f4e8280c354/slide_17.jpg){kind=link}
![котенок context words: [пушистый, мурлыкал, мяукал]. кот context words: [пушистый,](https://files.speakerdeck.com/presentations/fa6dadef64204871affa3f4e8280c354/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
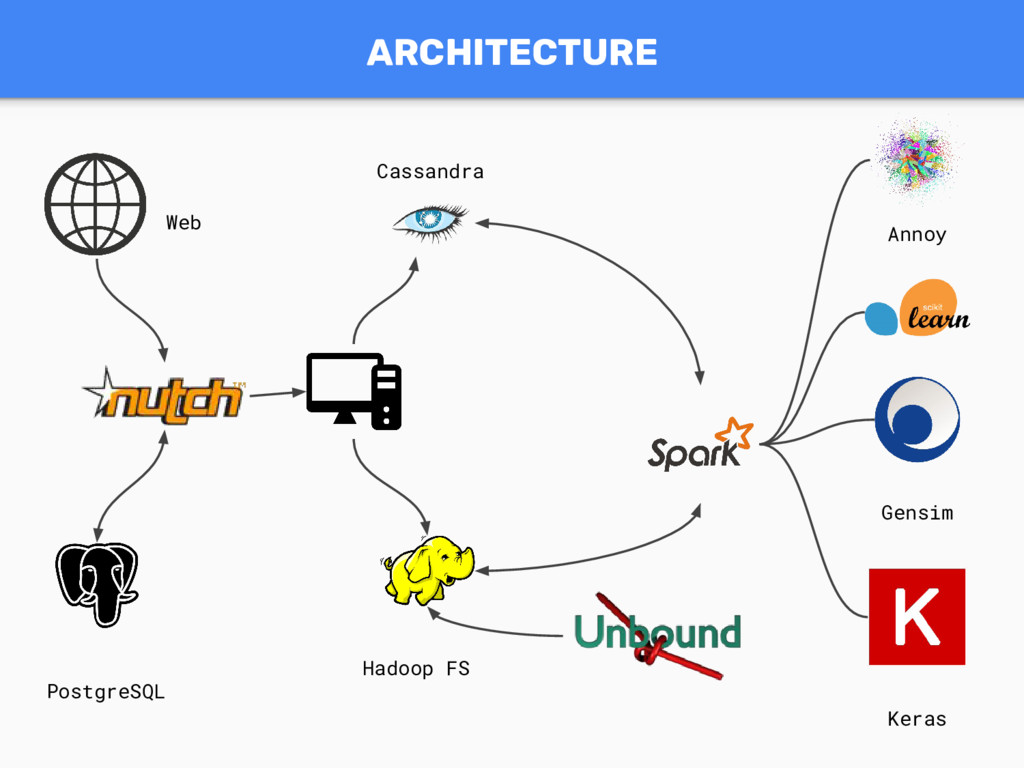{kind=link}
{kind=link}
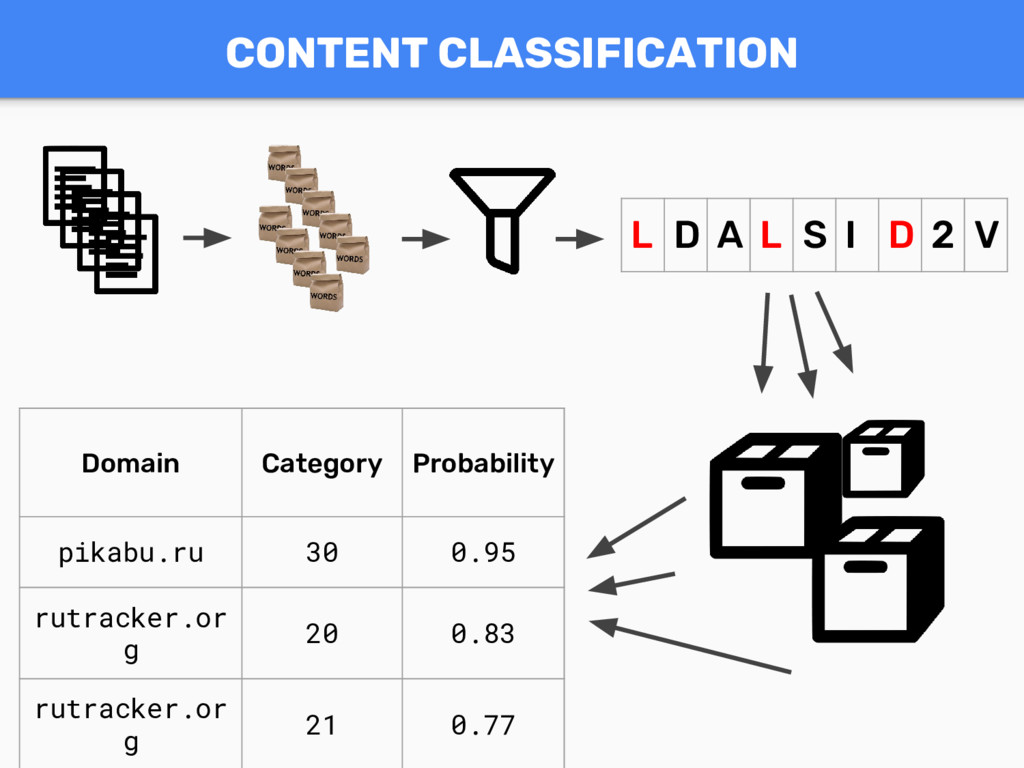{kind=link}
{kind=link}
{kind=link}
{kind=link}
![STUDENT INCUBATOR https://rare-technologies.com/incubator/ [email protected]](https://files.speakerdeck.com/presentations/fa6dadef64204871affa3f4e8280c354/slide_29.jpg){kind=link}
{kind=link}
![RaRe-Technologies/gensim gensim_py [email protected] [email protected] [email protected] THANK YOU FOR YOUR ATTENTION!](https://files.speakerdeck.com/presentations/fa6dadef64204871affa3f4e8280c354/slide_31.jpg){kind=link}