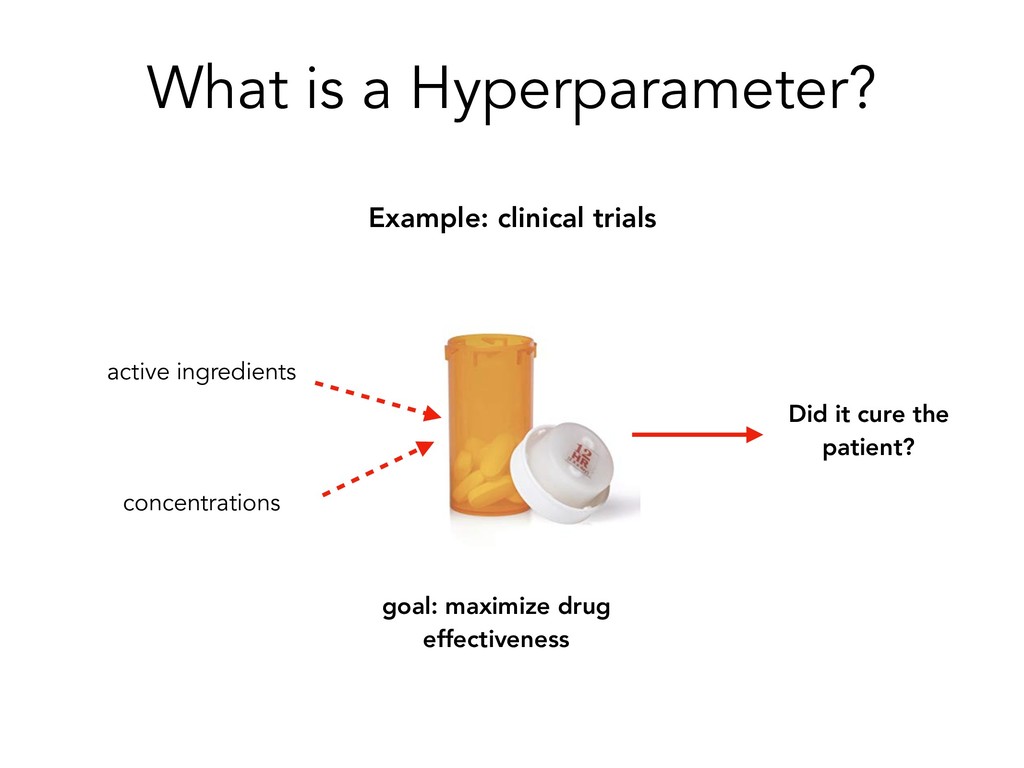
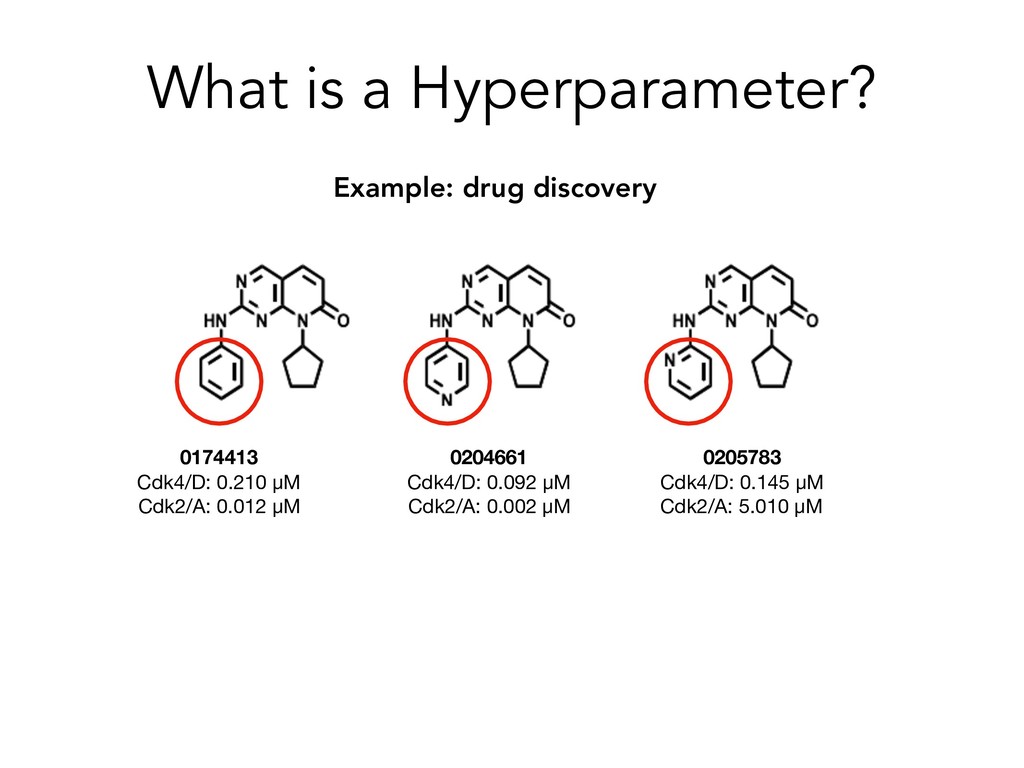
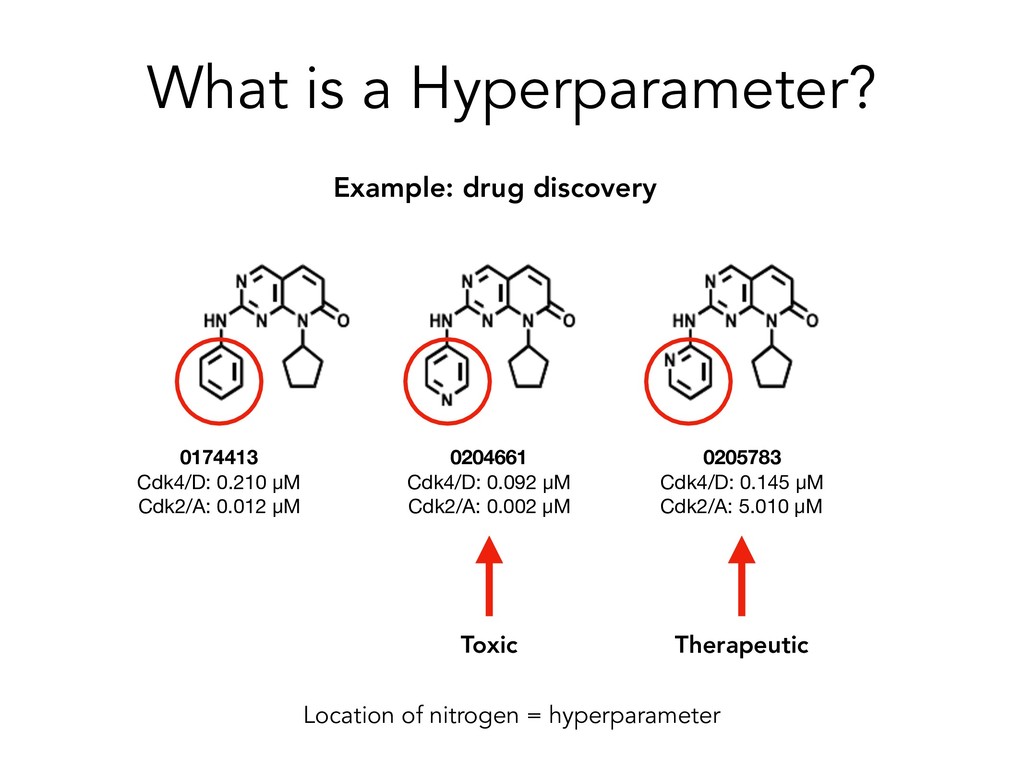
to transition time from data pre-processing and integration to model building and interrogation using familiar toolsets within Python. • Pre-processes diverse, raw medical data types (e.g. images, chemical structures, tabular data), and constructs workflows designed to reduce bias and maximize efficiency • Applications: early stage drug discovery, disease diagnostics, patient outcome prediction
notes: AWS Comprehend Medical • Diagnosing diabetic eye disease: Google AI • Assessing patient reported symptoms: Babylon Health • Developing targeted cancer treatments using precision medicine: Microsoft
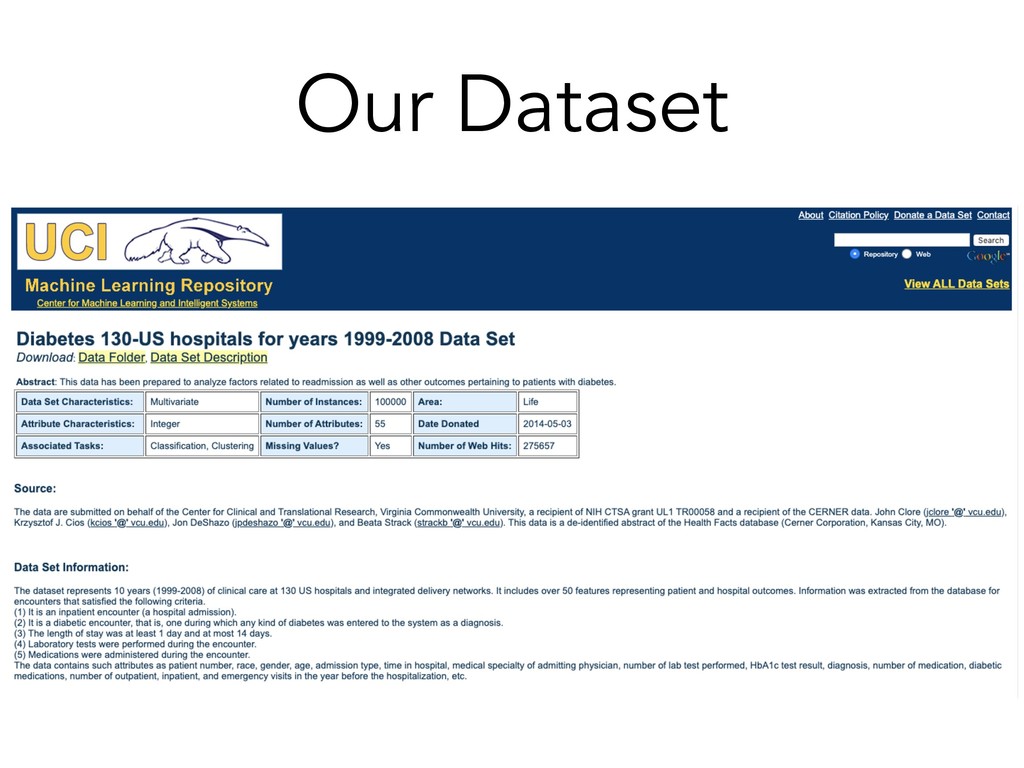
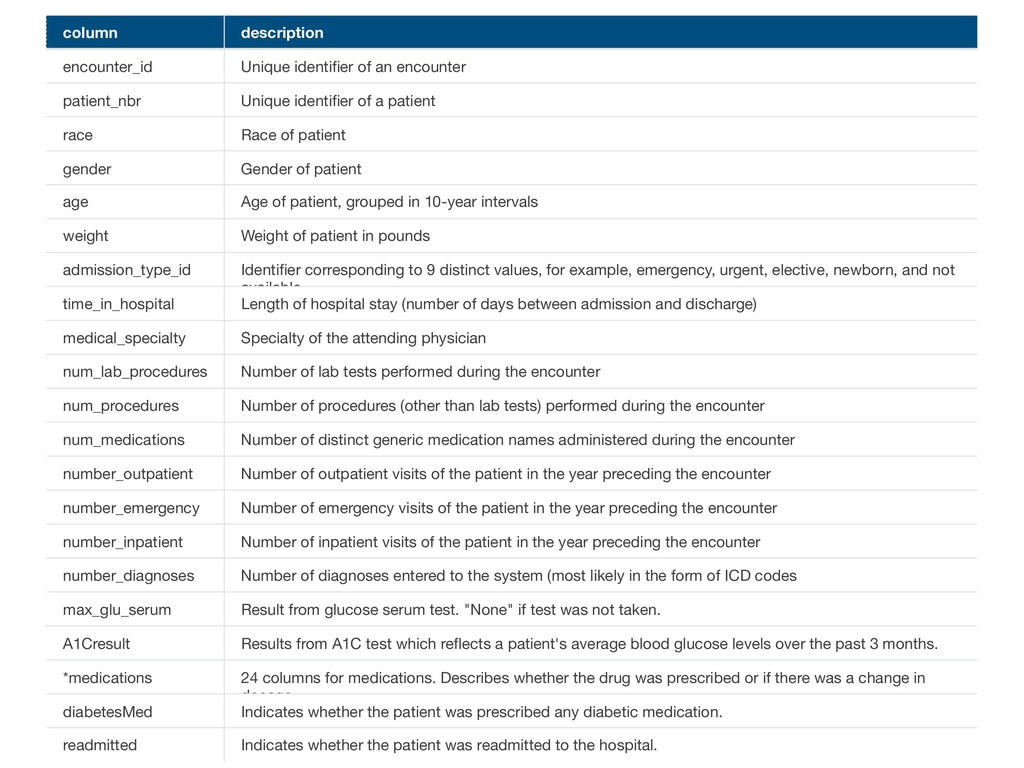
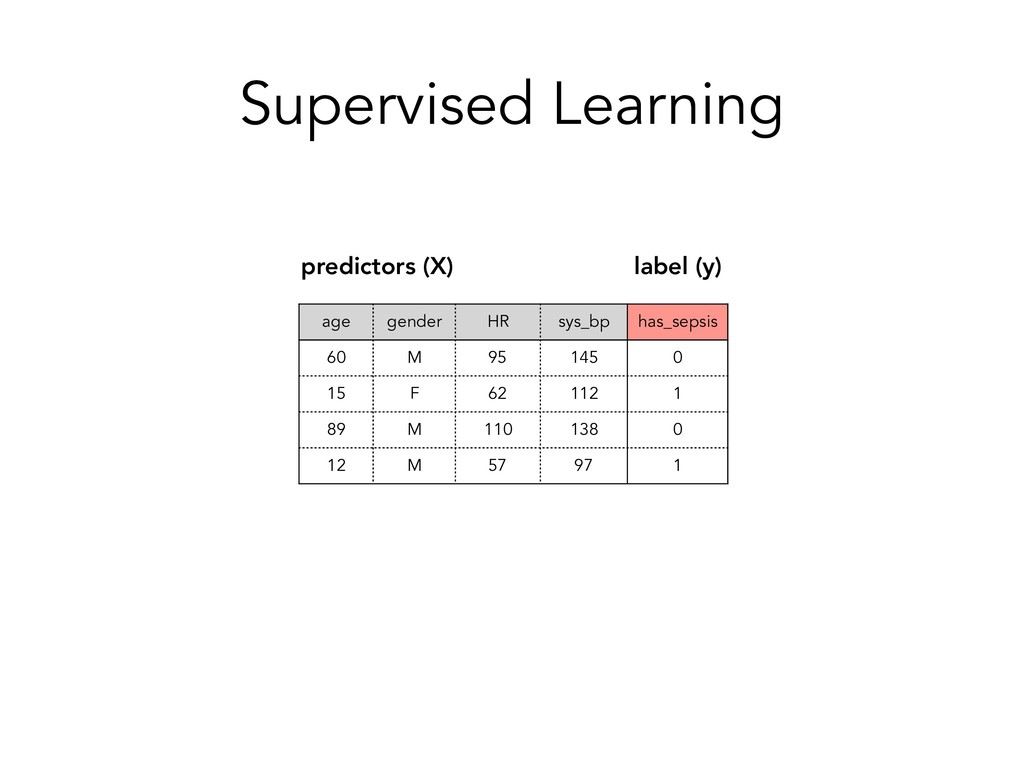
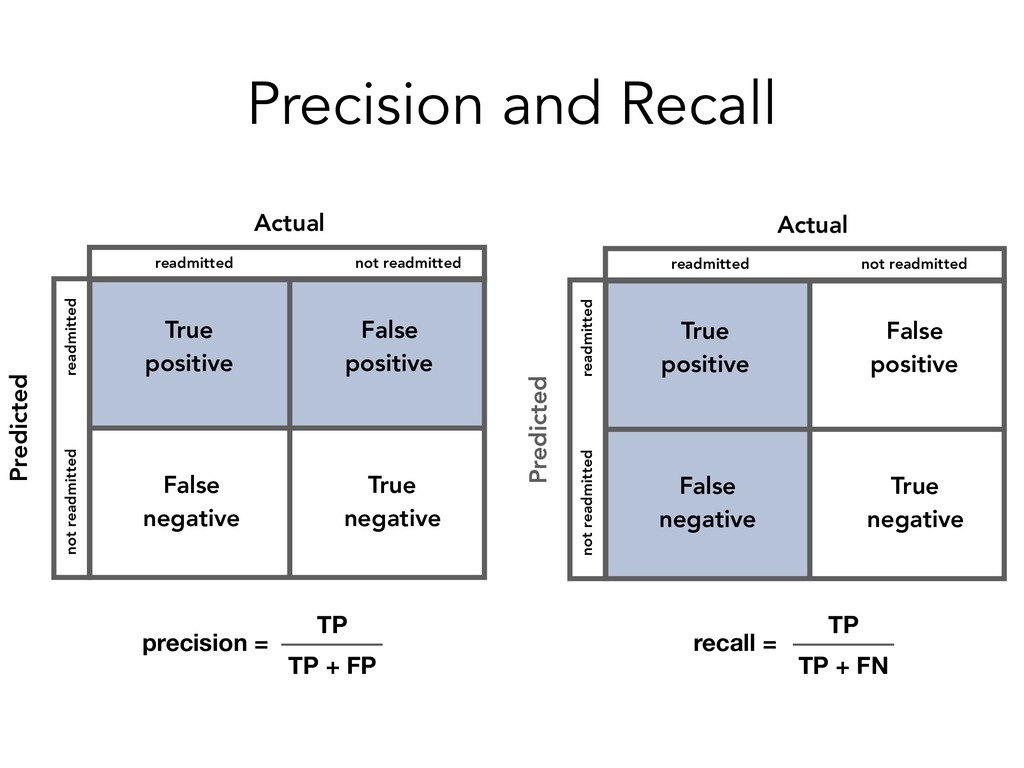
identifier of a patient race Race of patient gender Gender of patient age Age of patient, grouped in 10-year intervals weight Weight of patient in pounds admission_type_id Identifier corresponding to 9 distinct values, for example, emergency, urgent, elective, newborn, and not available time_in_hospital Length of hospital stay (number of days between admission and discharge) medical_specialty Specialty of the attending physician num_lab_procedures Number of lab tests performed during the encounter num_procedures Number of procedures (other than lab tests) performed during the encounter num_medications Number of distinct generic medication names administered during the encounter number_outpatient Number of outpatient visits of the patient in the year preceding the encounter number_emergency Number of emergency visits of the patient in the year preceding the encounter number_inpatient Number of inpatient visits of the patient in the year preceding the encounter number_diagnoses Number of diagnoses entered to the system (most likely in the form of ICD codes max_glu_serum Result from glucose serum test. "None" if test was not taken. A1Cresult Results from A1C test which reflects a patient's average blood glucose levels over the past 3 months. *medications 24 columns for medications. Describes whether the drug was prescribed or if there was a change in dosage. diabetesMed Indicates whether the patient was prescribed any diabetic medication. readmitted Indicates whether the patient was readmitted to the hospital.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
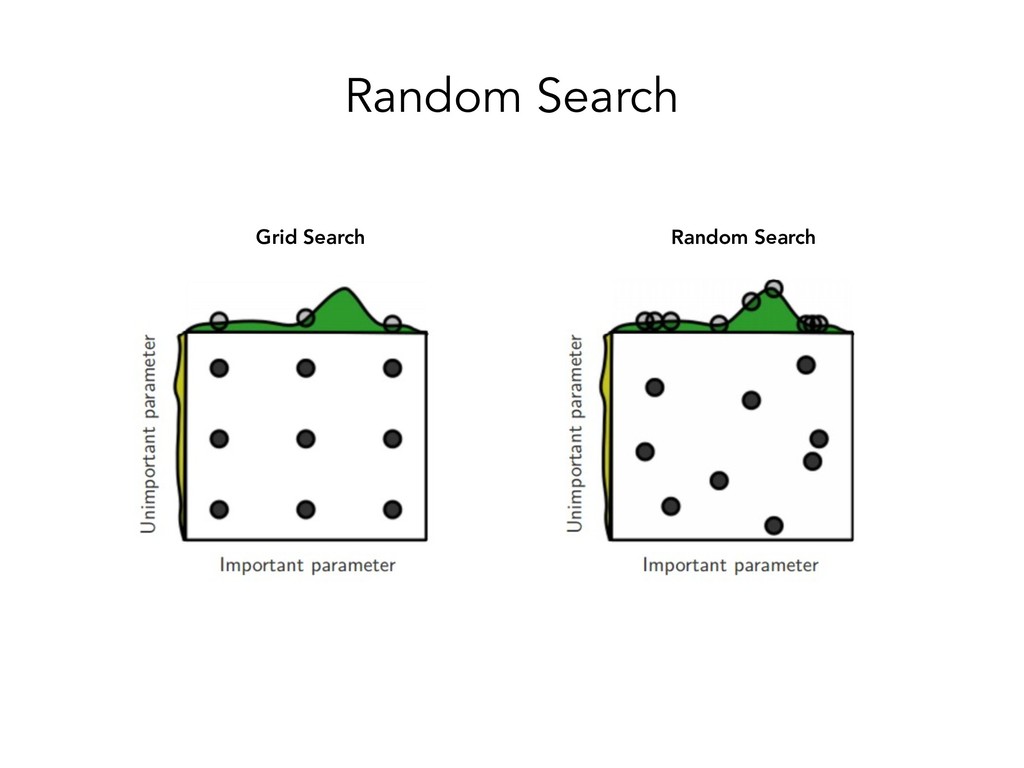
![Grid Search Search Space • n_estimators = [5,10,50] • max_depth](https://files.speakerdeck.com/presentations/be7ff561d2184a299da022bbc554830b/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}