or streaming processed Examples: Apache Spark, Flink, Beam What kind of data? At rest Lives in data warehouse or static iles (e.g., csv, tsv, excel, etc.) Exploratory data analysis
or streaming processed Examples: Apache Spark, Flink, Beam What kind of data? At rest Lives in data warehouse or static iles (e.g., csv, tsv, excel, etc.) Exploratory data analysis
! Rule of thumb: have 5 to 10 times as much RAM as the size of your dataset • Very strong community, works well with many other libraries (e.g., seaborn, matplotlib, scikit-learn) Pandas v1 Overview
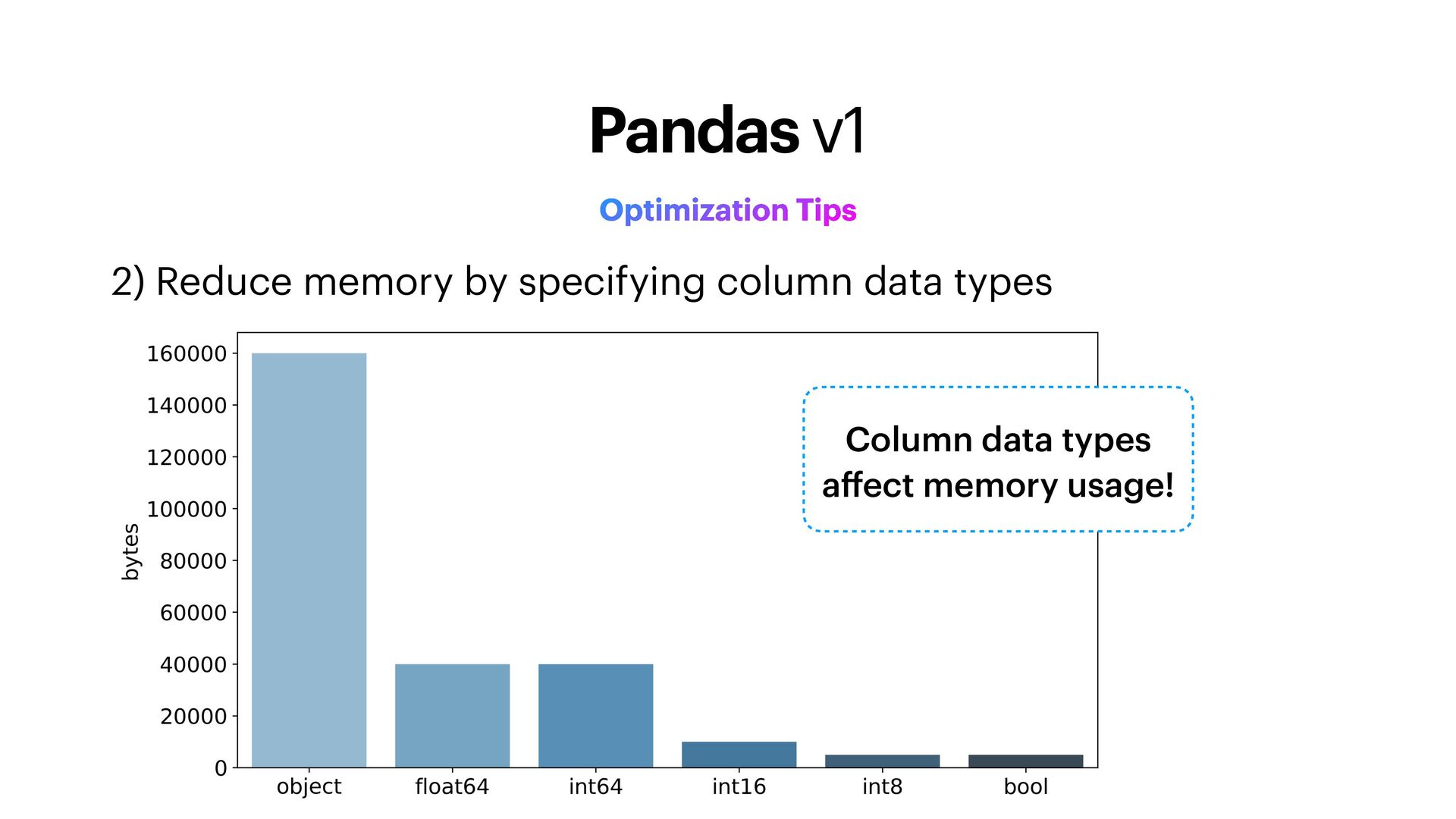
Specify column data types when loading data 3) Down-cast integers and loats 4) Filter irst before merging or aggregating 5) Avoid for loops at all costs 6) Serialize your data Optimization Tips Pandas v1
Pandas v1 • Convert string datatypes from “object” to “category” or “string” • Category: a string variable with a few possible values Reduced dataframe size by 20% # Original size: 203.8+ MB
v1 & for index, row in df.iterrows(): ' 6) Serialize your data Alternative ile formats to csv include: • Feather —> df.to_feather() • Parquet —> df.to_parquet() • Pickle —> df.to_pickle() • Hdf5 —> df.to_hdf() Use vectorized operations instead!
backend - very e icient! • Better support for strings • Better support for missing values • Zero-copy data access • E icient data transfer between different systems The Apache Arrow Revolution Pandas >= v2.0
NumPy Backend PyArrow Backend Speed Up Read parquet ile 141 ms 87 ms 1.6x Calculate mean ( loat64) 3.56 ms 1.73 ms 2.1x Endswith (string) 471 ms 14.1 ms 31.6x Aggregated count 97.2 ms 39.5 ms 2.5x Aggregated mean 102 ms 70 ms 1.5x First three rows from Pandas 2.0 and the Arrow Revolution by Marc Garcia Pandas >= v2.0
“data frames” and “series” (same as Pandas) • Uses Apache Arrow in the backend • Written in Rust • Supports multi-threading • Supports lazy evaluation and query optimization • Streaming API allows for out-of-core processing Polars Overview
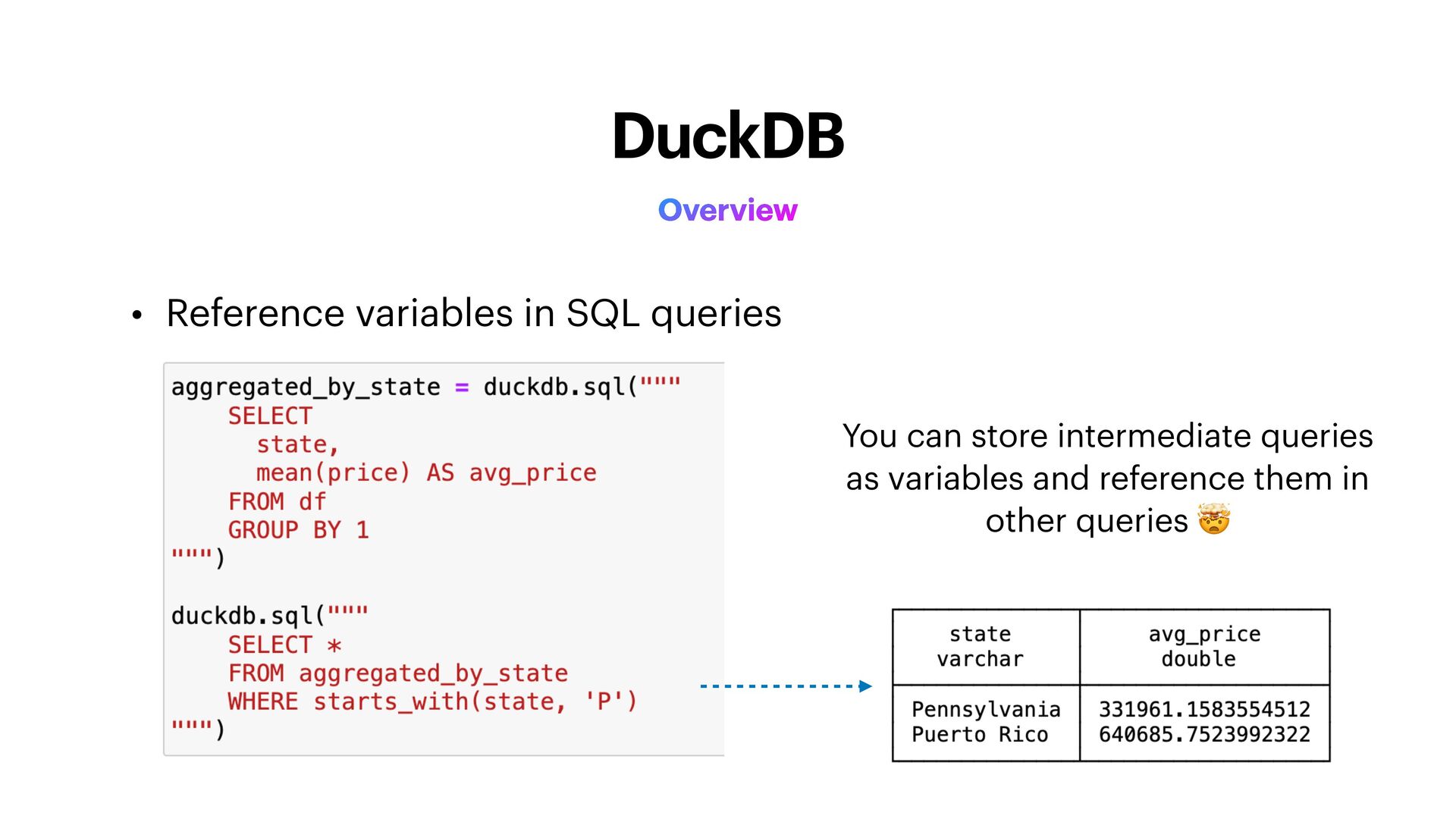
collect() materializes the LazyFrame into a DataFrame • Query is optimized behind the scenes • e.g. iltering before aggregating • Dataframes can be converted to LazyFrames by calling the LazyFrame class: pl.LazyFrame(df) Eager vs Lazy Evaluation
instead of all at once • Streaming is supported for several operations: • filter, slice, head • with_columns • group_by • join • unique • sort • explode, melt • ❗ Still in active development Streaming API
in 2019 by Mühleisen and Raasveldt • Written in C++ and has client APIs in several languages • Uses a columnar-vectorized SQL query processing engine • Query optimization behind the scenes • Interoperable with Apache Arrow Overview
2008 2020 2019 Latest version* (as of May 2024) 2.2.2 0.20.27 0.10.3 Downloads last month 215.6M 6.9M 3.5M Total number of stars 42.1K 26.6K 17.2K Merged PRs last month 273 255 175 Total number of contributors 3.2K 407 316 *Data was queried on May 15, 2024
caution! My very uno icial benchmark test 3.5GB data local Pandas v2 Polars DuckDb DuckDb (without materializing to Arrow object) Aggregated count 1.18 s 487 ms 770 ms 149 µs Aggregated mean 44.7 s 499 ms 767 ms 148 µs
Pandas v1 and v2 - Polars - DuckDB • Things to consider when making a decision: - Size of data - Learning curve and amount of spare time to learn a new syntax - Knowledge base of contributors and peer reviewers • My recommendation: try them all! Which package is best?
Docs • pandas 2.0 and the Arrow revolution (part I) by Marc Garcias • Apache Arrow and the “10 Things I Hate About pandas” by Wes McKinney • DuckDB: Bringing analytical SQL directly to your Python shell (PyData Presentation) by Pedro Holanda • Comprehensive Guide To Optimize Your Pandas Code by Eyal Trabelsi • Pandas 2.0 and its Ecosystem (Arrow, Polars, DuckDB) by Simon Späti
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Jill Cates [email protected] GitHub @topspinj](https://files.speakerdeck.com/presentations/5792c889efb94e909f332edc7bd17d80/slide_49.jpg){kind=link}
{kind=link}