Towards a Model Selection Rule for Quantum State Tomography
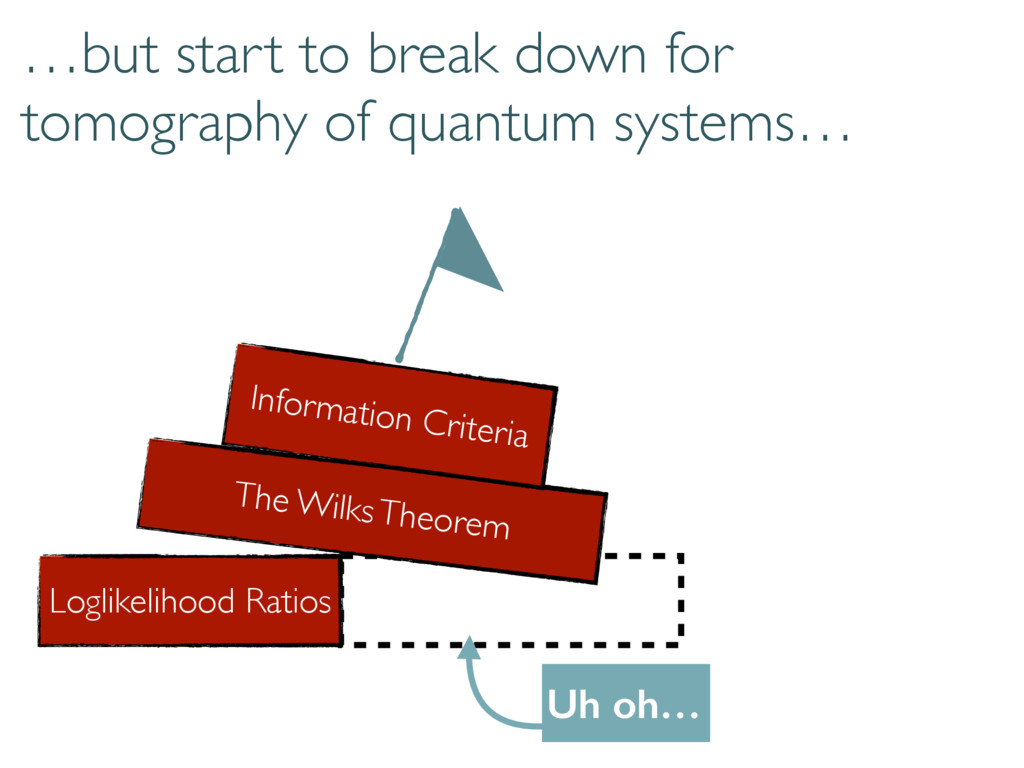
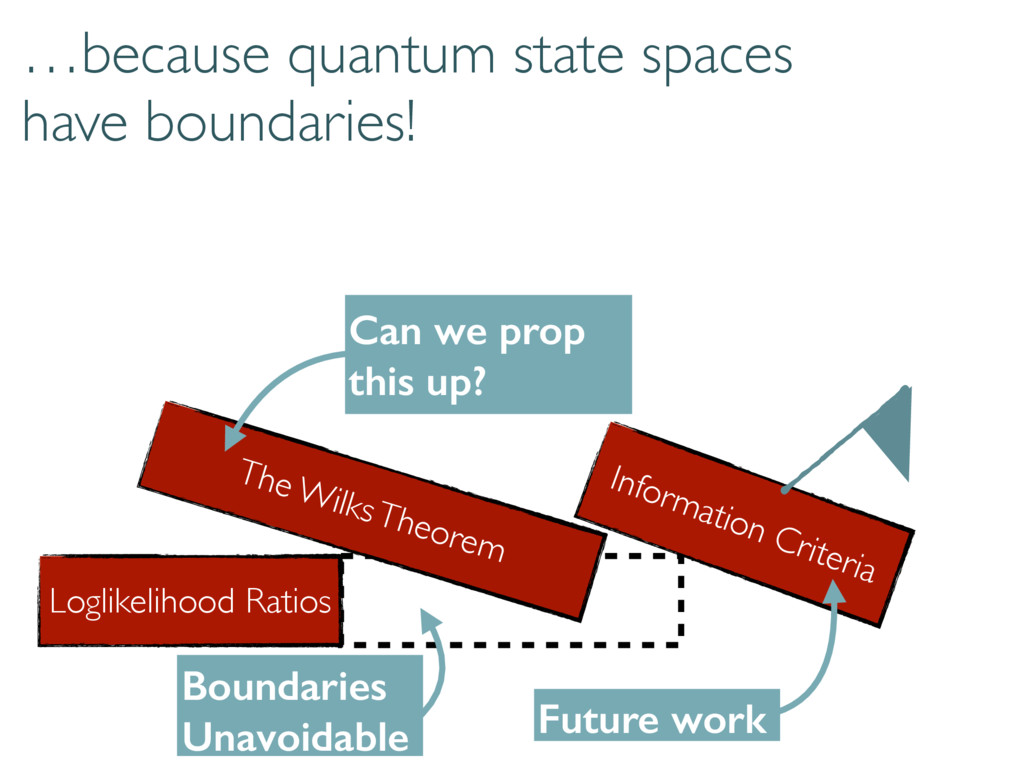
How can we use model selection to make quantum state tomography better? I discuss how a commonly-used technique, loglikelihood ratios, run into problems because the state space has boundaries.
L Scholten @Travis_Sch Center for Quantum Information and Control, UNM Center for Computing Research, Sandia National Labs SQuInT Workshop 2016 February 19 Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. CCR Center for Computing Research
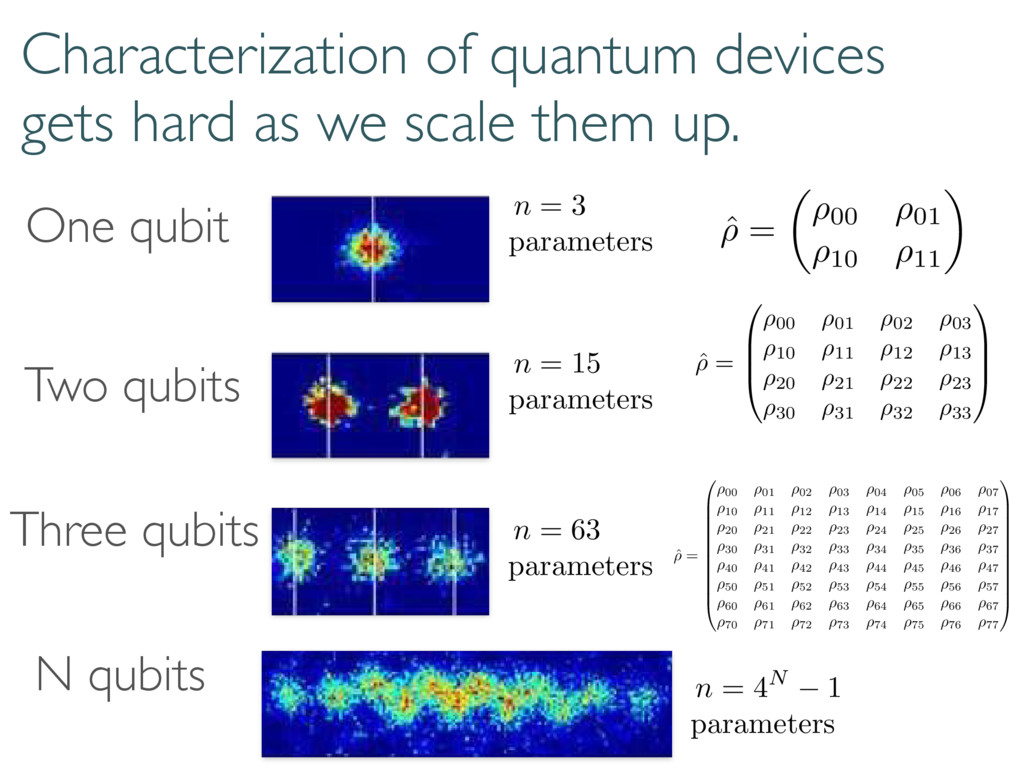
up. One qubit Two qubits N qubits Three qubits ˆ ⇢ = ✓ ⇢00 ⇢01 ⇢10 ⇢11 ◆ ˆ ⇢ = 0 B B @ ⇢00 ⇢01 ⇢02 ⇢03 ⇢10 ⇢11 ⇢12 ⇢13 ⇢20 ⇢21 ⇢22 ⇢23 ⇢30 ⇢31 ⇢32 ⇢33 1 C C A ˆ ⇢ = 0 B B B B B B B B B B @ ⇢00 ⇢01 ⇢02 ⇢03 ⇢04 ⇢05 ⇢06 ⇢07 ⇢10 ⇢11 ⇢12 ⇢13 ⇢14 ⇢15 ⇢16 ⇢17 ⇢20 ⇢21 ⇢22 ⇢23 ⇢24 ⇢25 ⇢26 ⇢27 ⇢30 ⇢31 ⇢32 ⇢33 ⇢34 ⇢35 ⇢36 ⇢37 ⇢40 ⇢41 ⇢42 ⇢43 ⇢44 ⇢45 ⇢46 ⇢47 ⇢50 ⇢51 ⇢52 ⇢53 ⇢54 ⇢55 ⇢56 ⇢57 ⇢60 ⇢61 ⇢62 ⇢63 ⇢64 ⇢65 ⇢66 ⇢67 ⇢70 ⇢71 ⇢72 ⇢73 ⇢74 ⇢75 ⇢76 ⇢77 1 C C C C C C C C C C A n = 3 parameters n = 15 parameters n = 63 parameters n = 4N 1 parameters
tomography) = sets of density matrices ˆ ⇢ = 0 @ 1 A Restrict estimate to a subspace ˆ ⇢ = 0 @ 1 A Restrict rank of estimate ˆ ⇢ = N 1 X j,k=0 ⇢jk |jihk| ˆ ⇢ = r 1 X j=0 j | j ih j | Nontrival ways:
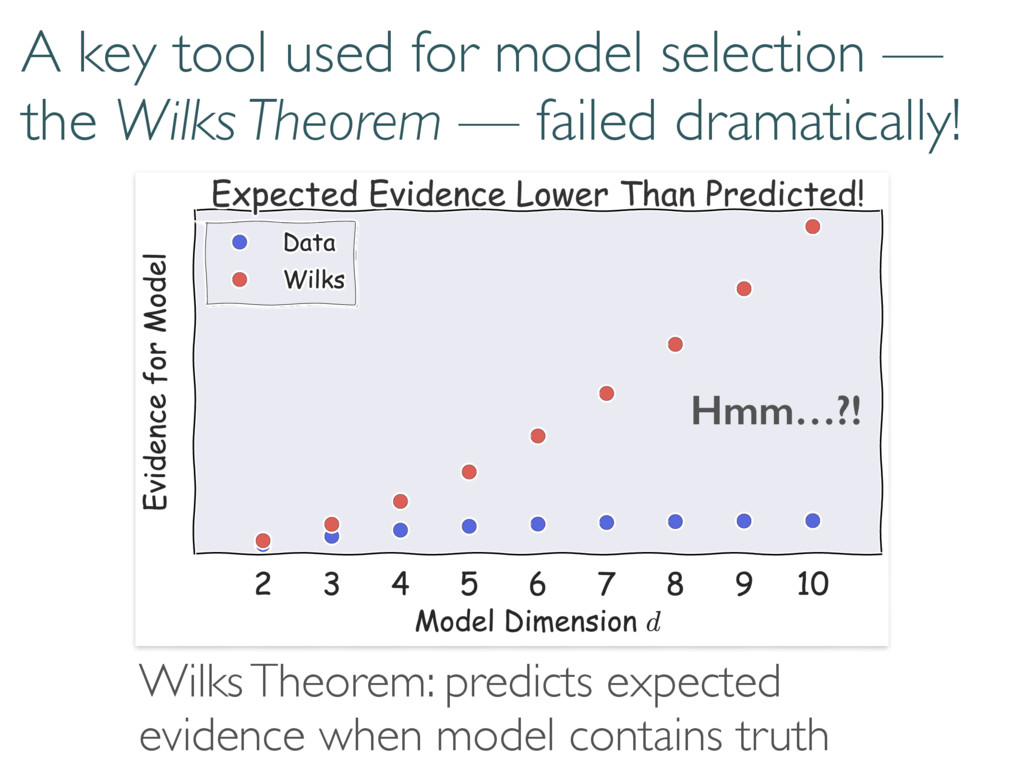
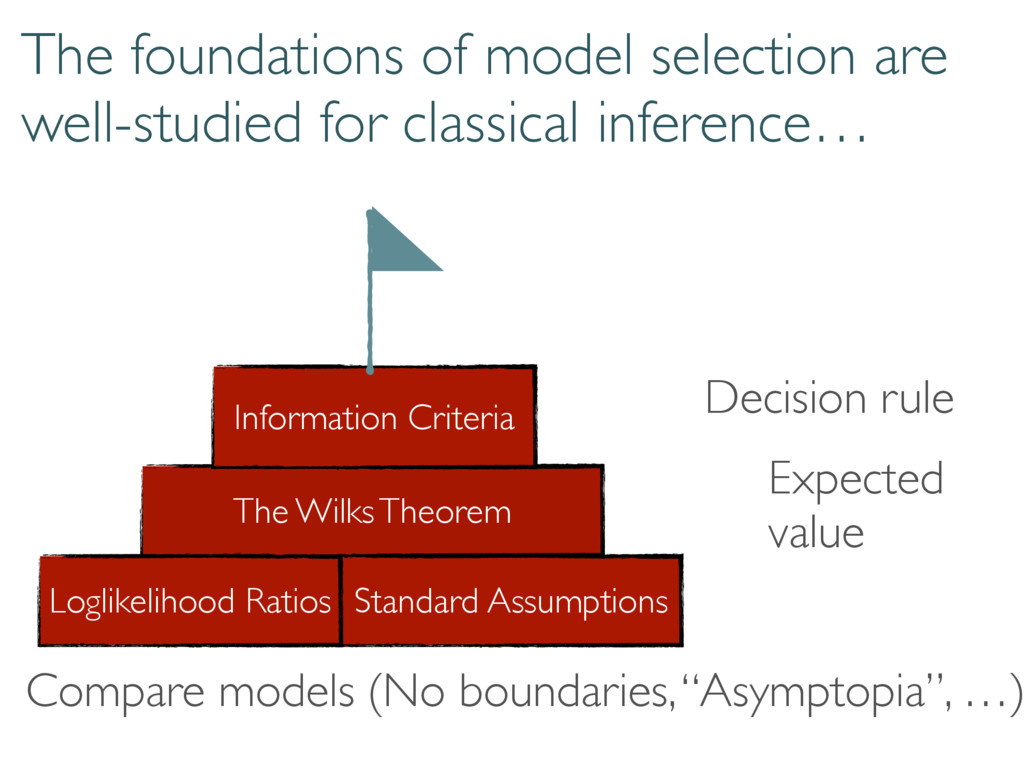
Dimension Travis L Scholten APS March Meeting 5 March 2015 Tomography is hard Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. Let’s make it easier… Doing so in infinite dimensional Hilbert space is harder Finding the best model seemed straightforward. “Just use loglikelihood ratios and the Wilks Theorem” “Information criteria?”
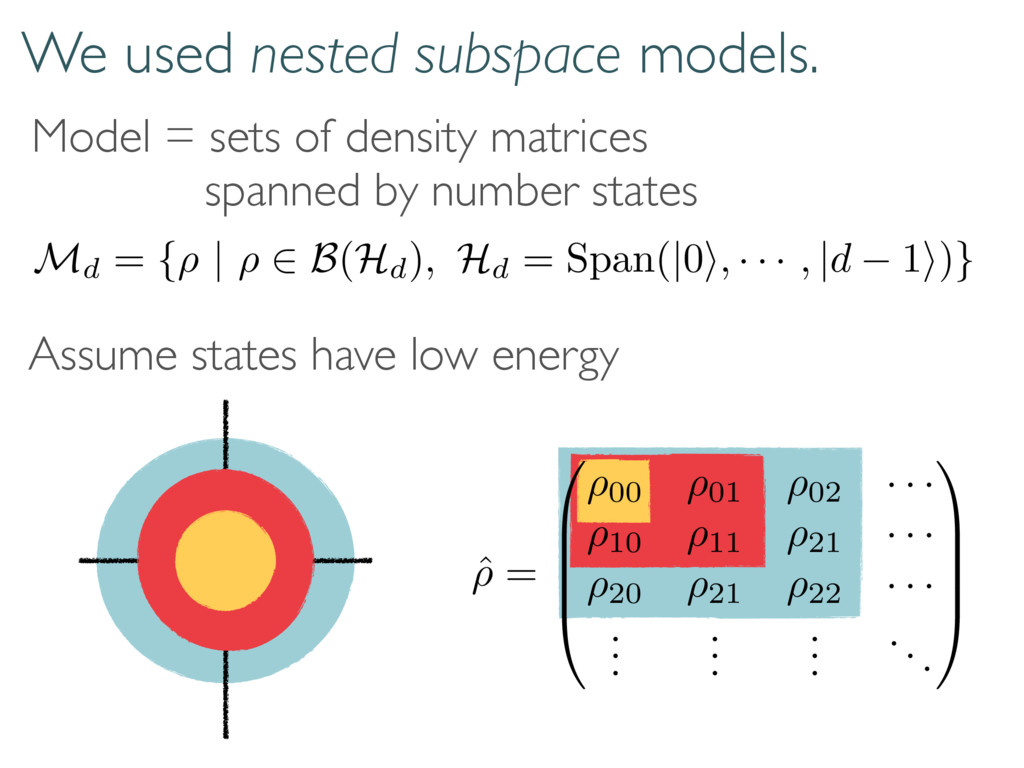
· ⇢10 ⇢11 · · · . . . . . . ... 1 C A Continuous-variable (CV) systems are a nice sandbox for model selection. Finite data…infinite parameters! How do we find a small, yet good model?
B B @ ⇢00 ⇢01 ⇢02 · · · ⇢10 ⇢11 ⇢21 · · · ⇢20 ⇢21 ⇢22 · · · . . . . . . . . . ... 1 C C C A Model = sets of density matrices spanned by number states Md = {⇢ | ⇢ 2 B(Hd), Hd = Span(|0i, · · · , |d 1i)} Assume states have low energy
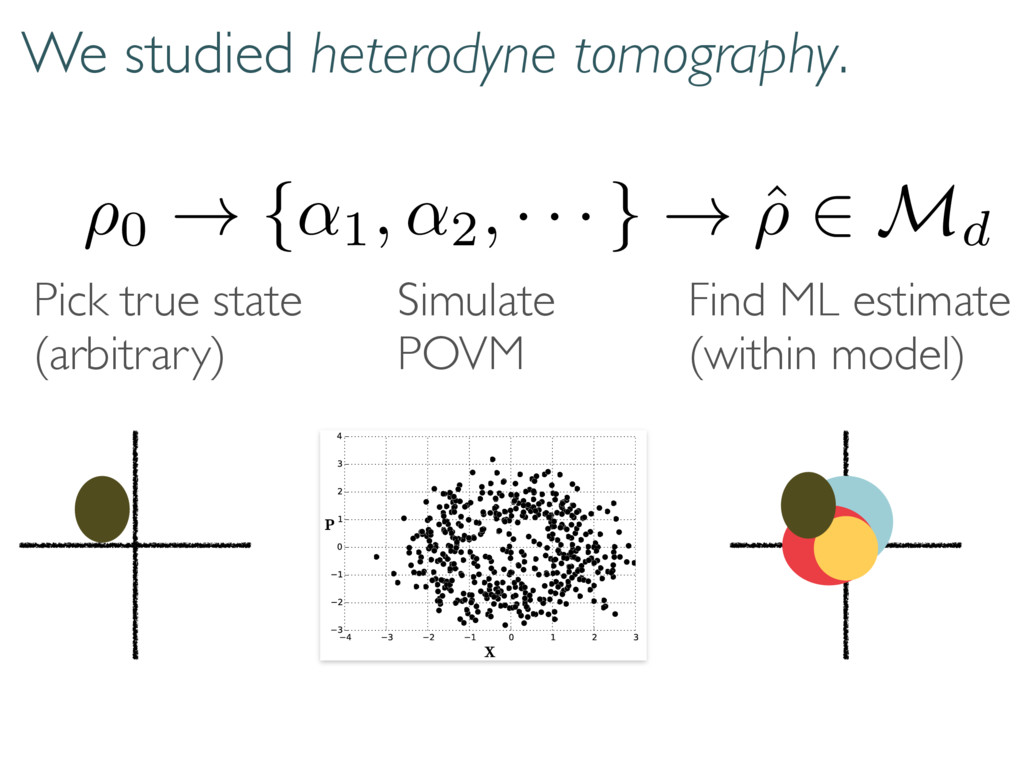
· } ! ˆ ⇢ 2 Md Pick true state (arbitrary) Simulate POVM Find ML estimate (within model) Doing so in infinite dimensional Hilbert space is harder. From measurements on a continuous variable system, we estimate… 484 Simulated Heterodyne Measurement Outcomes
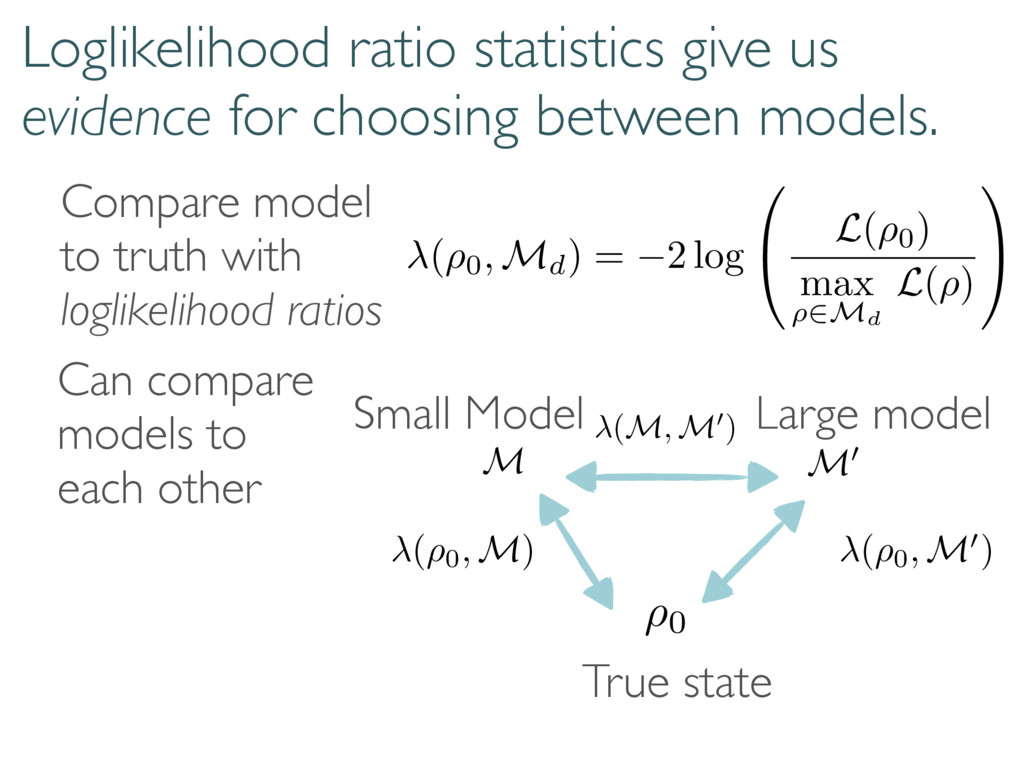
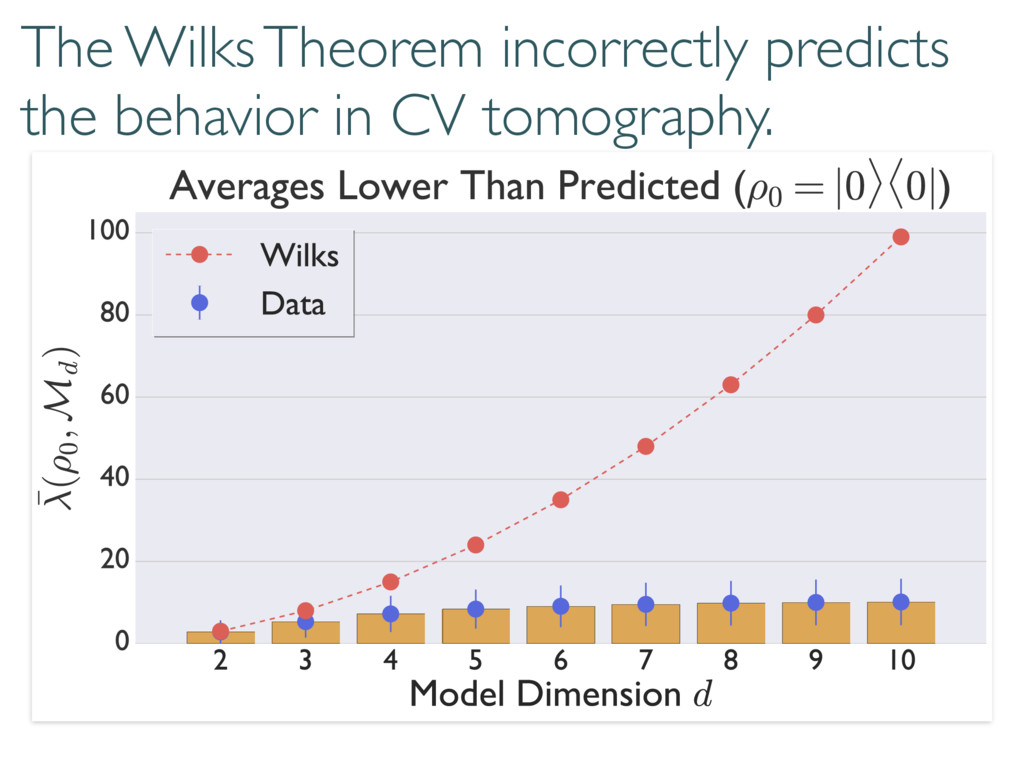
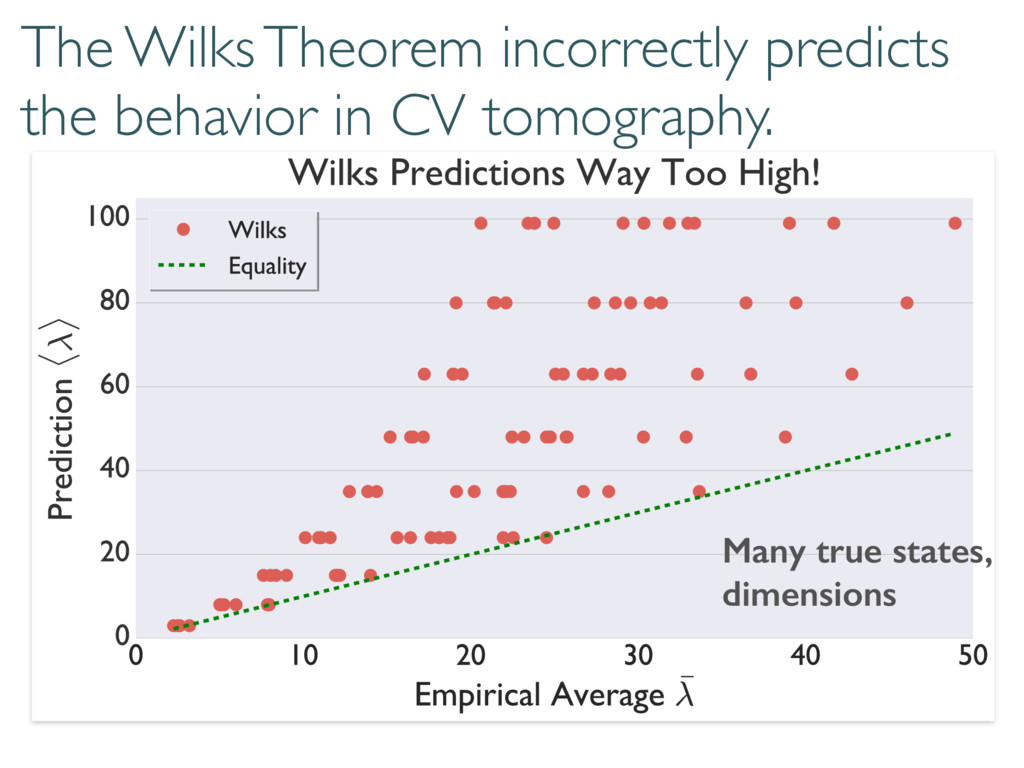
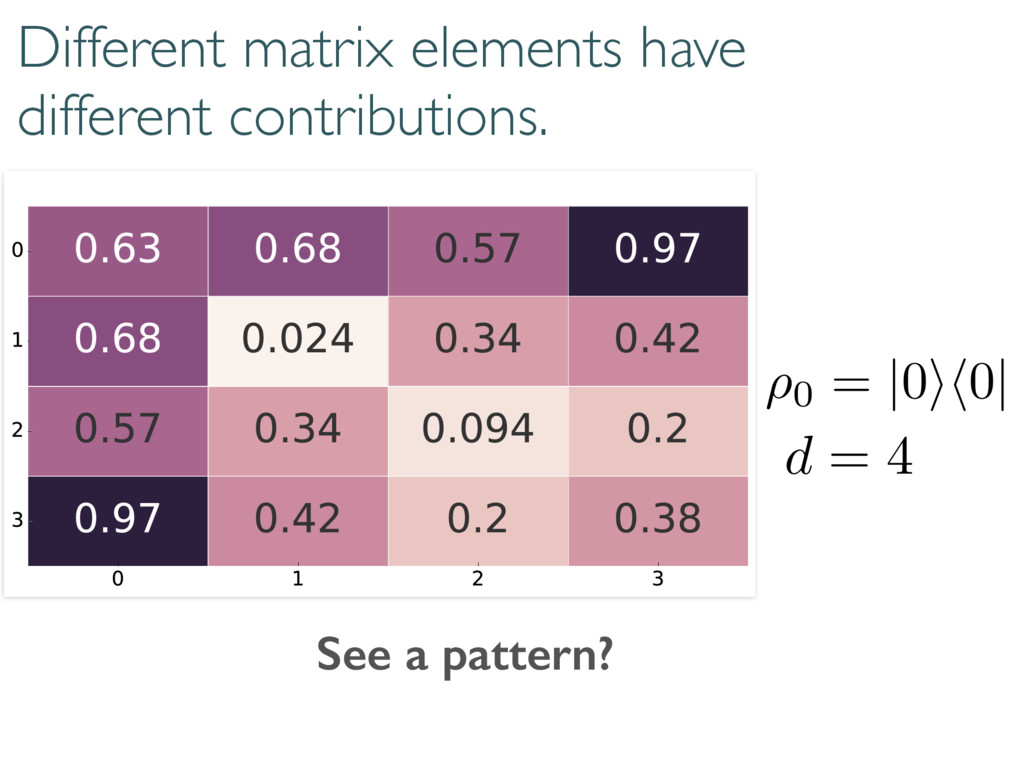
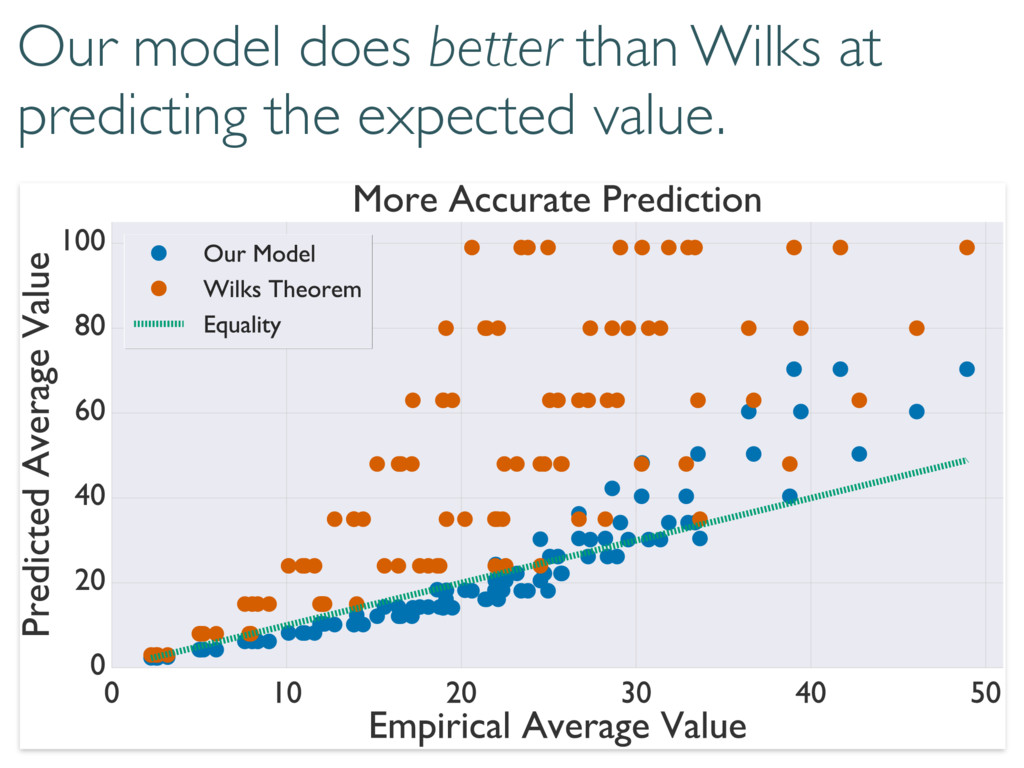
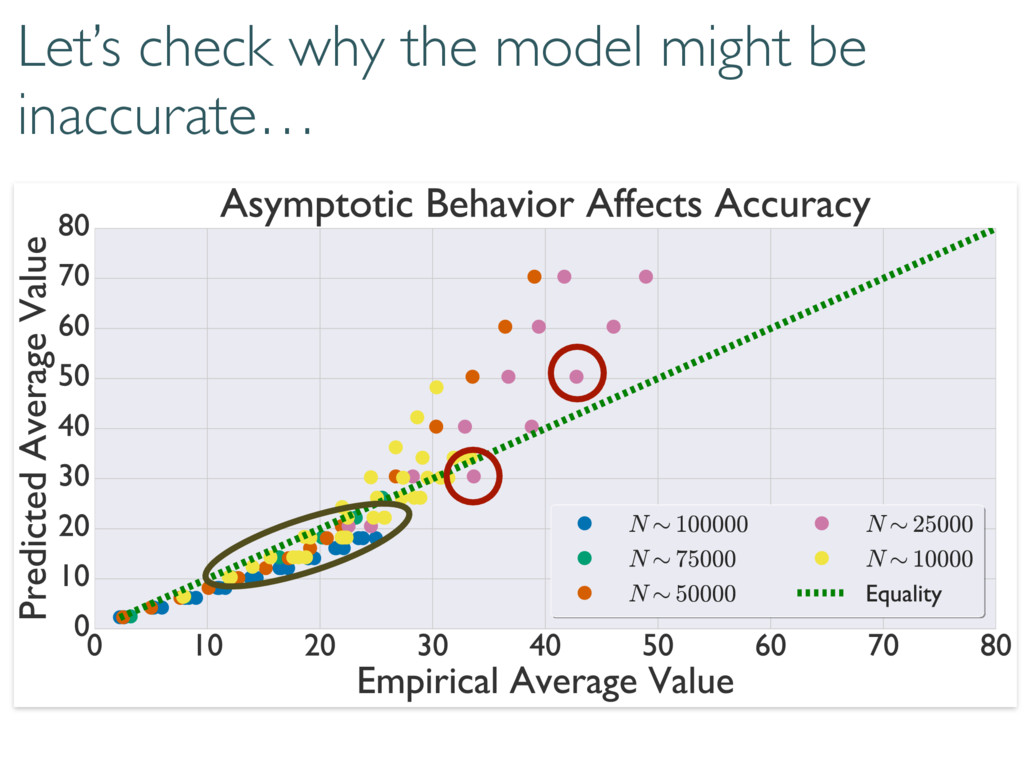
Compare model to truth with loglikelihood ratios ( ⇢0, Md) = 2 log 0 @ L ( ⇢0) max ⇢2Md L ( ⇢ ) 1 A (⇢0, M0) (M, M0) ⇢0 M M0 (⇢0, M) Can compare models to each other True state Small Model Large model
The Wilks Theorem: ⇢0 We want to know these numbers! N h i Compare model to truth with loglikelihood ratios ( ⇢0, Md) = 2 log 0 @ L ( ⇢0) max ⇢2Md L ( ⇢ ) 1 A ⇢0 2 Md =) ⇠ 2 d2 1
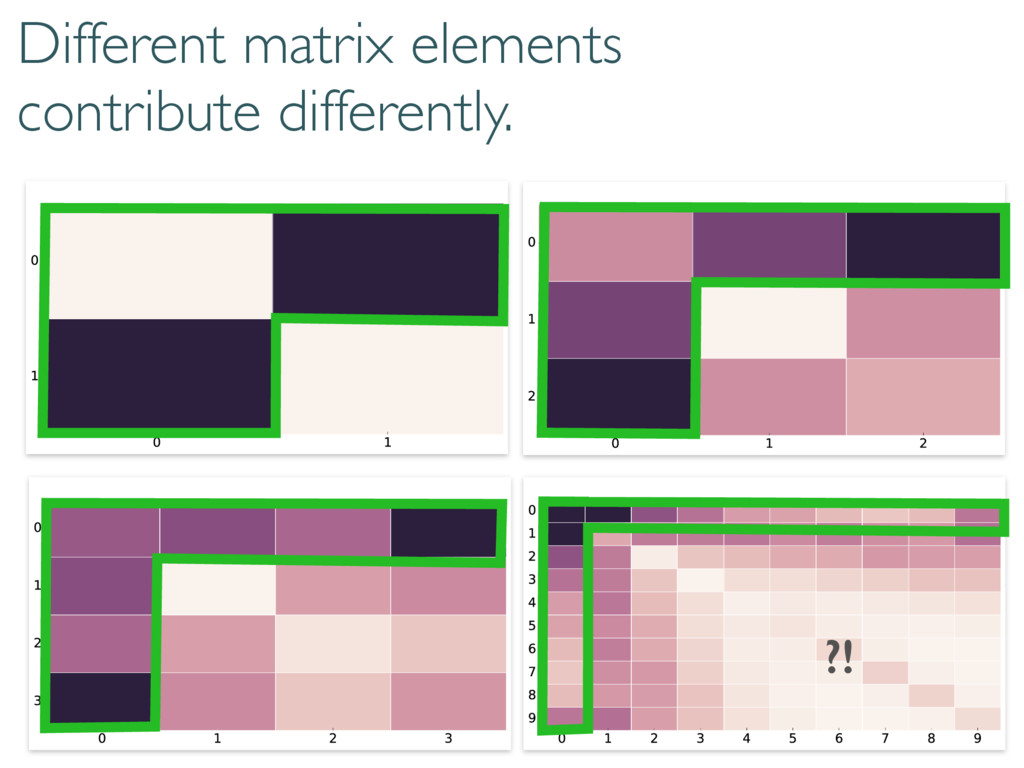
Wilks: Information and fluctuations align & saturate (classical) Cramer-Rao bound Where does this go wrong in tomography? h i ⇡ Tr(hHFi) ⇡ Tr(hHihFi) ⇡ Tr(hHihHi 1) ⇡ d2 1
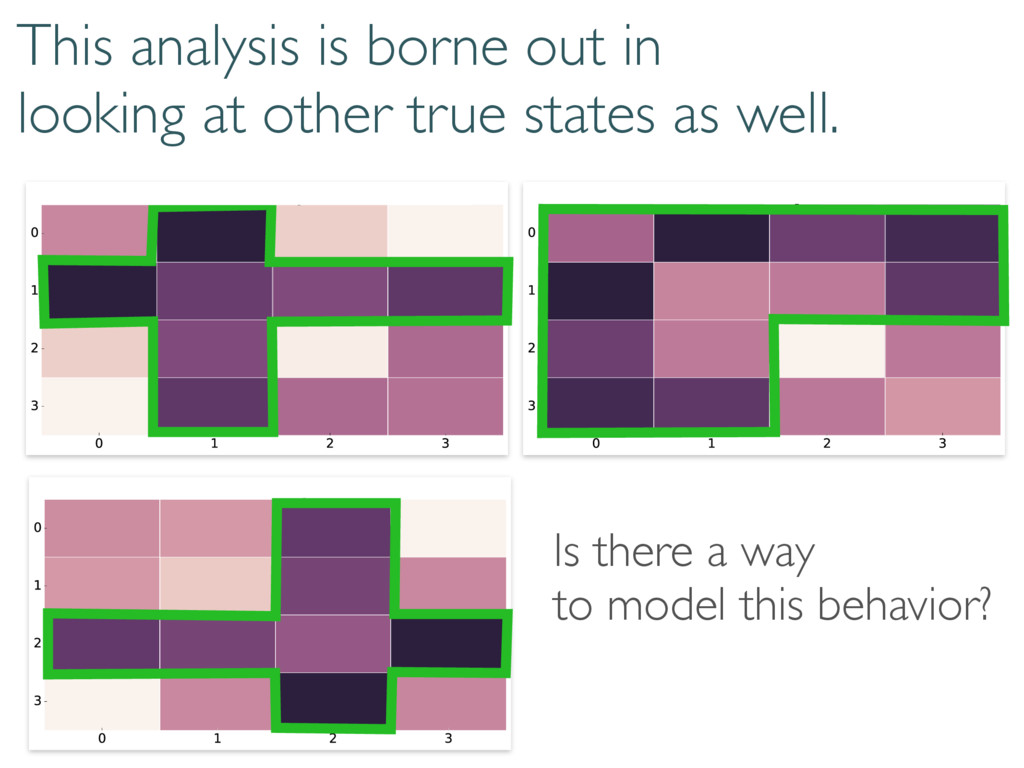
What are these numbers? Can we make sense of them? Qubits & Wilks: h i ⇡ Tr(hHFi) ⇡ Tr(hHihFi) ⇡ Tr( p hHihFi p hHi | {z } ) 0 B B @ 0 1 1 1 1 C C A ! 0 B B @ .5 .5 1 1 .5 .5 1 C C A ! ✓ .5 1 1 .5 ◆
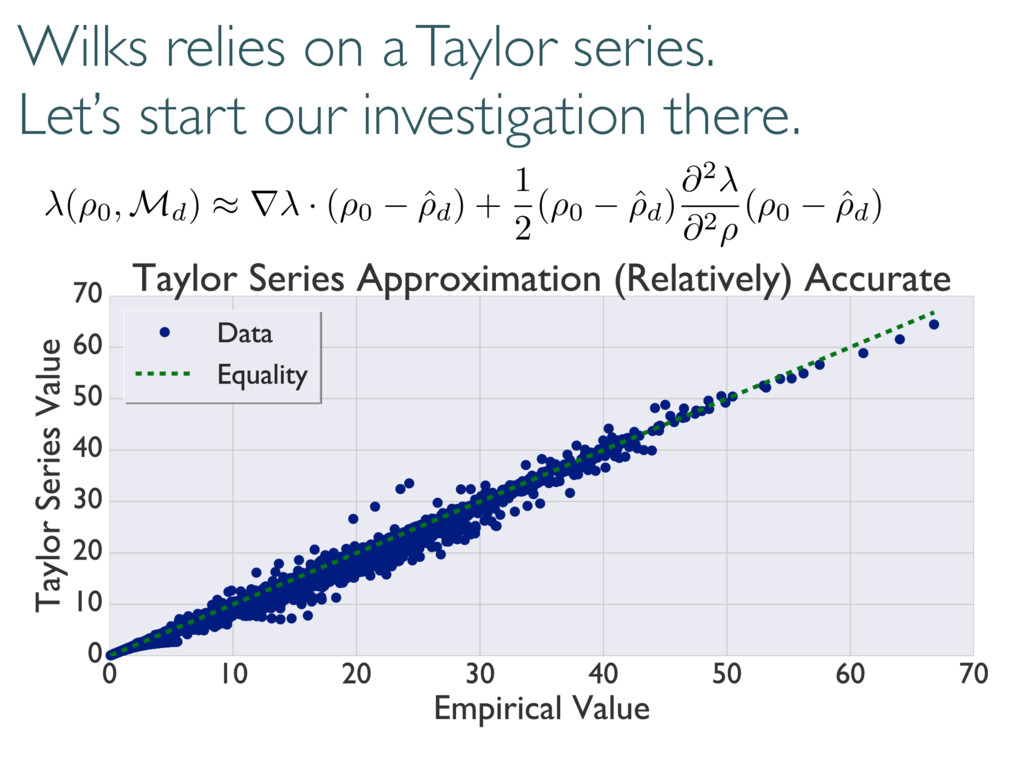
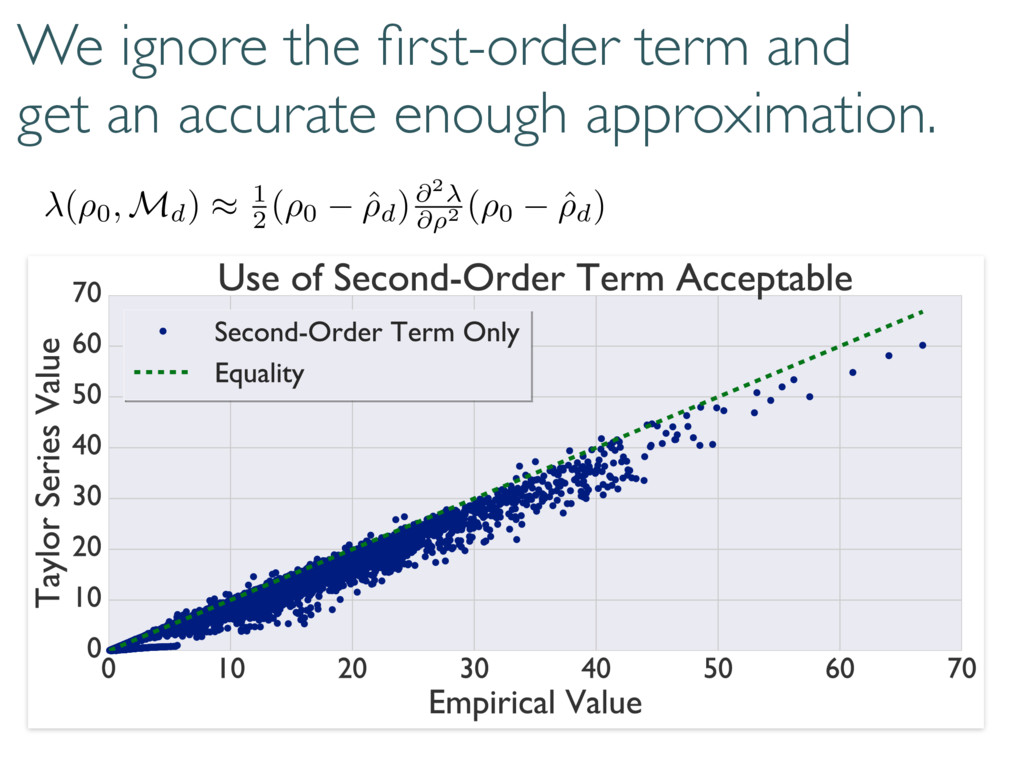
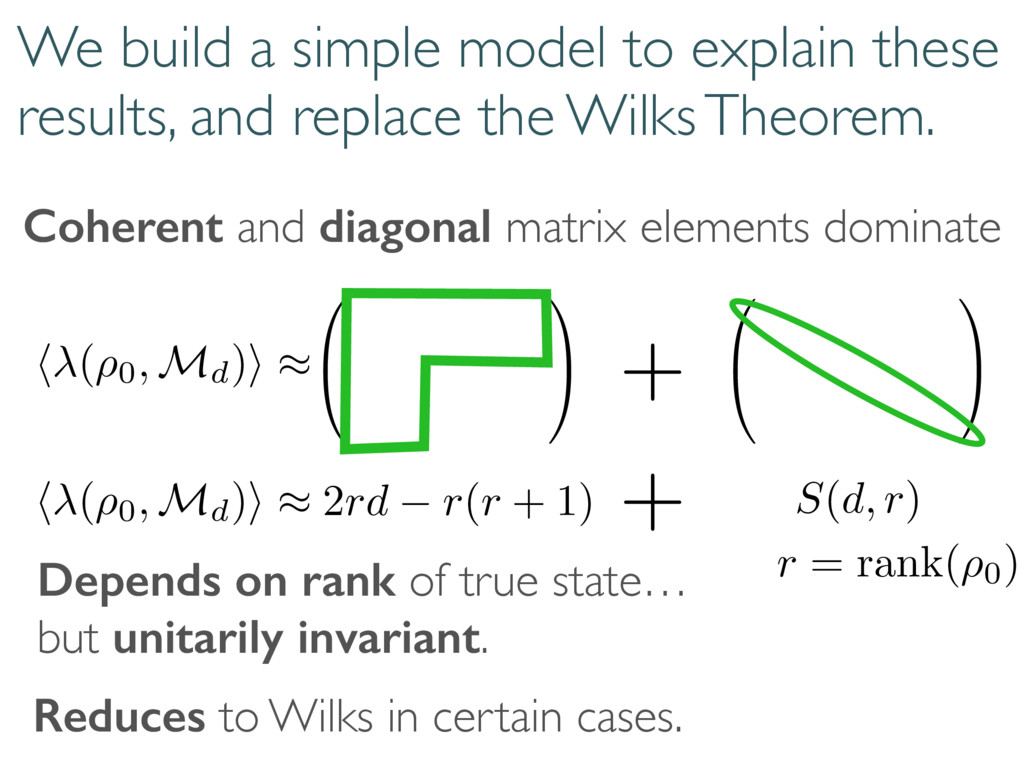
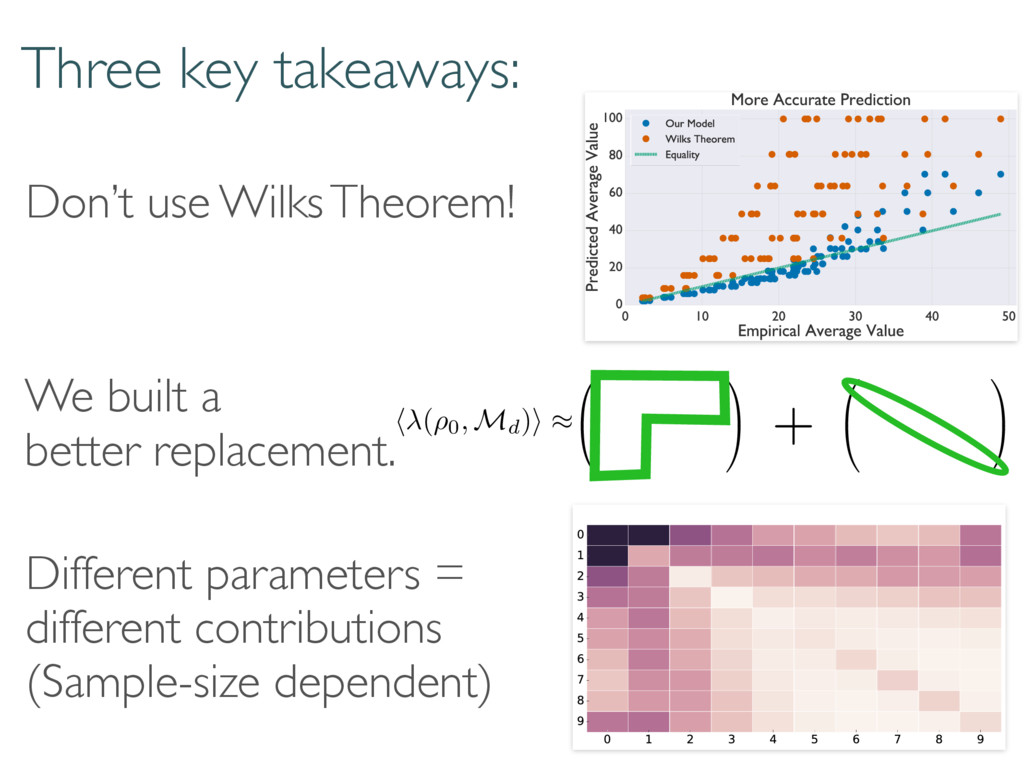
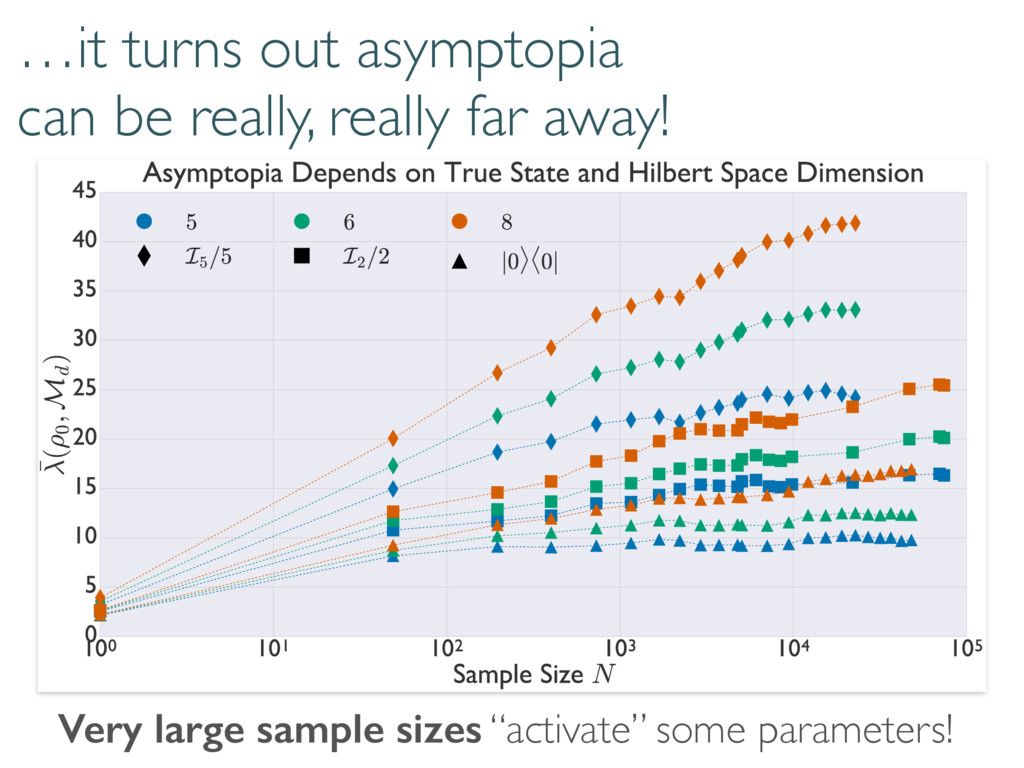
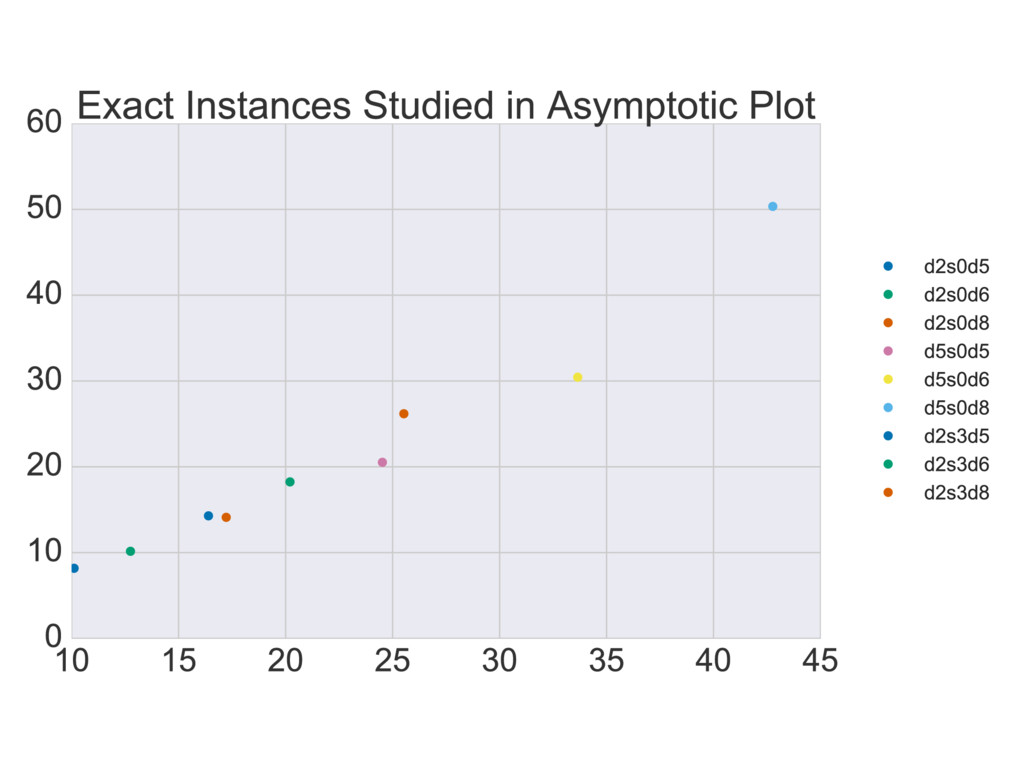
replace the Wilks Theorem. Coherent and diagonal matrix elements dominate 0 @ 1 A 0 @ 1 A + 2rd r(r + 1) S(d, r) Depends on rank of true state… but unitarily invariant. h (⇢0, Md)i ⇡ h (⇢0, Md)i ⇡ + r = rank(⇢0) Reduces to Wilks in certain cases.
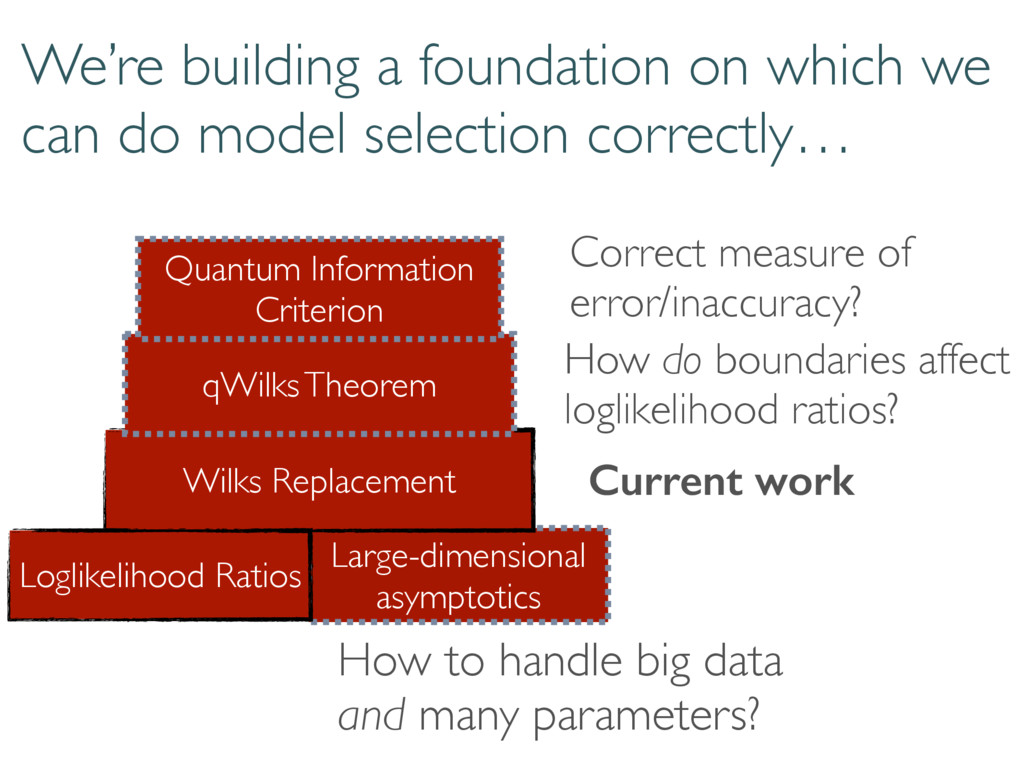
selection correctly… Large-dimensional asymptotics Wilks Replacement qWilks Theorem Quantum Information Criterion How do boundaries affect loglikelihood ratios? Correct measure of error/inaccuracy? How to handle big data and many parameters? Current work Loglikelihood Ratios
www.gnu.org/copyleft/fdl.html) or CC-BY-SA-3.0 (http:// creativecommons.org/licenses/by-sa/3.0/)], via Wikimedia Commons gmon qubit: By Michael Fang, John Martinis group. http:// web.physics.ucsb.edu/~martinisgroup/photos.shtml NIST Ion Trap: http://phys.org/news/2006-07-ion-large-quantum.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}