reasonably fast • Regexes match basic constructs like numbers, keywords, operators • Often relies on common patterns in programming language grammars ◦ Keywords, paired delimiters, strings, comments ◦ Example: Emacs only supports delimiters up to two characters without fancy features • Can add features until it highlights everything you want ◦ Multi-line strings/comments: special paired delimiter functionality ◦ String escapes: ability to set rules to run while between delimiters ◦ Heredocs: feature to put capture group from start regex into end regex • Give standardized names to language constructs for themes: ◦ Vim examples: Comment, String, Keyword, Type, Function
• Vim • Textmate: Plist-based tmLanguage format • Sublime Text 2: Same grammars as Textmate • Atom: Basically tmLanguage grammars translated to JSON • Visual Studio Code: similar to Atom • Textmate 2: Original Textmate format with some extensions • Sublime Text 3: a new YAML-based stack parser format
specific: ◦ constant.numeric.ruby ◦ support.function.builtin.ruby ◦ entity.name.class.js • First few levels are standardized so themes work on any language ◦ https://www.sublimetext.com/docs/3/scope_naming.html • Later parts allow themes to customize and enhance highlighting for individual languages and constructs.
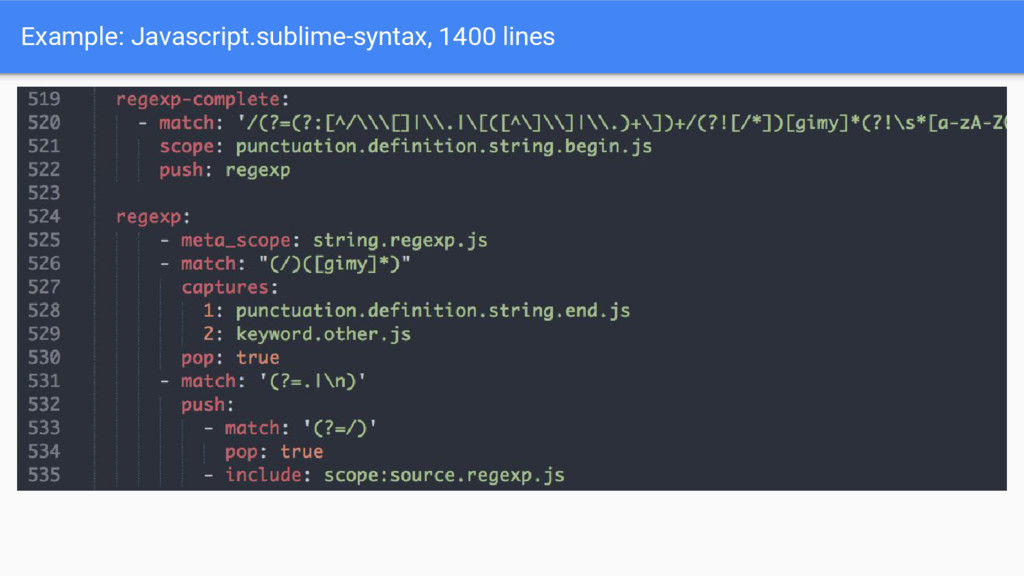
“string.quoted.double.ruby” and “string.unquoted.heredoc.ruby” • Nested scopes in a scope stack ◦ “source.python keyword” can highlight any keyword in a python file differently • Exclude selectors ◦ “source.ruby string - string source” highlights strings, but not code nested in string interpolation. • Way more power for themes than Vim-style simple classes • Atom just translates scopes to HTML classes and uses CSS selectors
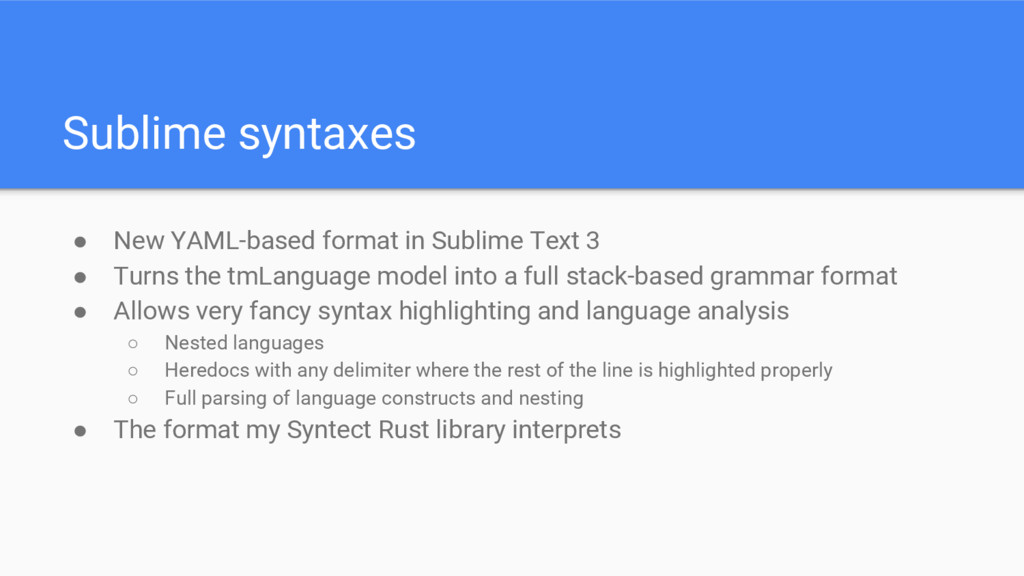
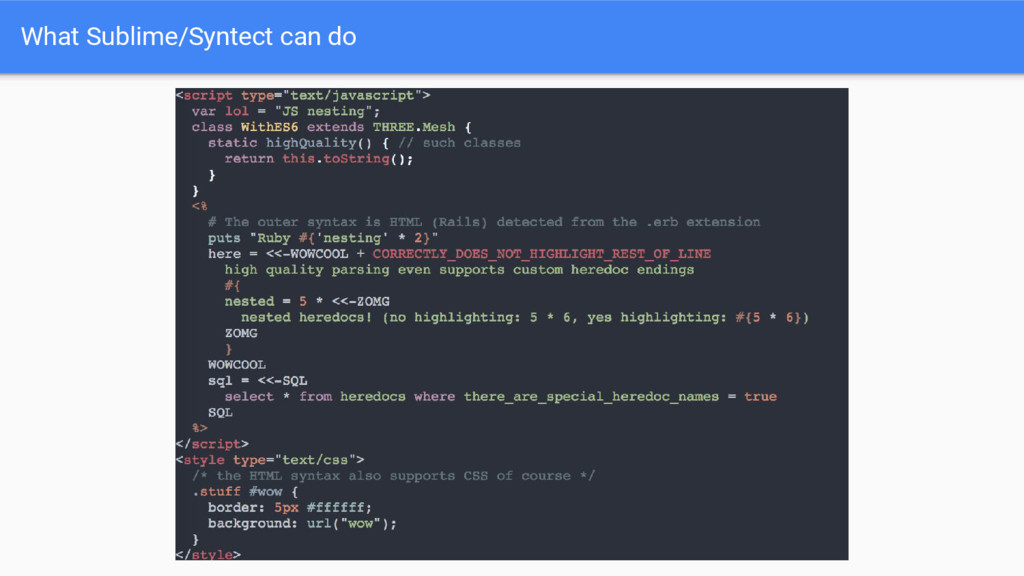
• Turns the tmLanguage model into a full stack-based grammar format • Allows very fancy syntax highlighting and language analysis ◦ Nested languages ◦ Heredocs with any delimiter where the rest of the line is highlighted properly ◦ Full parsing of language constructs and nesting • The format my Syntect Rust library interprets
the file: • Starting with the position at the beginning of the line • Loop to find all the tokens on the line: ◦ Try matching each regex against the line from the current position forwards ◦ Take the one that matches closest to the current position, break if nothing matched ◦ Execute the associated action. Could be: ▪ Assigning a highlighting type to the matched substring ▪ If it’s a delimiter, push or pop a context of regexes from the parsing stack ◦ Move the current position to the end of the current match
each token we have to match every regex on the string • It’s slow, but there’s lots of optimizations we can do: ◦ Cache regex matches so that we remember if a regex matched a line and where ◦ Only output the places tokens start and end so that we don’t copy strings too much • It can get stuck in infinite push/pop loops: need to detect them • Need to support inheriting regexes in a stack for nested languages • If you don’t lazily compile the regexes while highlighting your editor will take forever to start up.
spent in the regex engine • Textmate grammars assume the Oniguruma regex engine ◦ Lookaheads, look-behinds, atomic groups, named captures… ◦ Suffers from catastrophic backtracking taking exponential time in some cases • Sublime Text 3 has its own custom absurdly fast regex engine ◦ Only works on regexes that can be represented as DFAs ◦ Matches multiple regexes in one pass • I’m working on using an engine based on Rust’s regex crate for syntect ◦ Reduces catastrophic backtracking by using a DFA engine where possible ◦ Theoretically increased performance, so far it just matches Oniguruma
syntax highlighting: ◦ Syntect takes 680ms, or 13,000 lines per second ◦ Sublime Text 3 dev build takes 90ms • Comparisons that also include rendering one screen of text: ◦ Sublime Text 3 dev build takes ~200ms ◦ Textmate 2, Spacemacs and Visual Studio Code all take ~2 seconds ◦ Atom takes 6 seconds • These comparisons aren't totally fair, except the one to Sublime Text since that is using the same theme and the same complex definition for ES6 syntax.
text further on • Can suspend the highlighting process between lines • On keystroke, re-highlight that line and every further line on screen • Kick off a background job to re-highlight the rest of the file • Can stop if the state stack for a line didn’t change. • Bounds the latency for highlighting to only ~100 lines = ~7ms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}