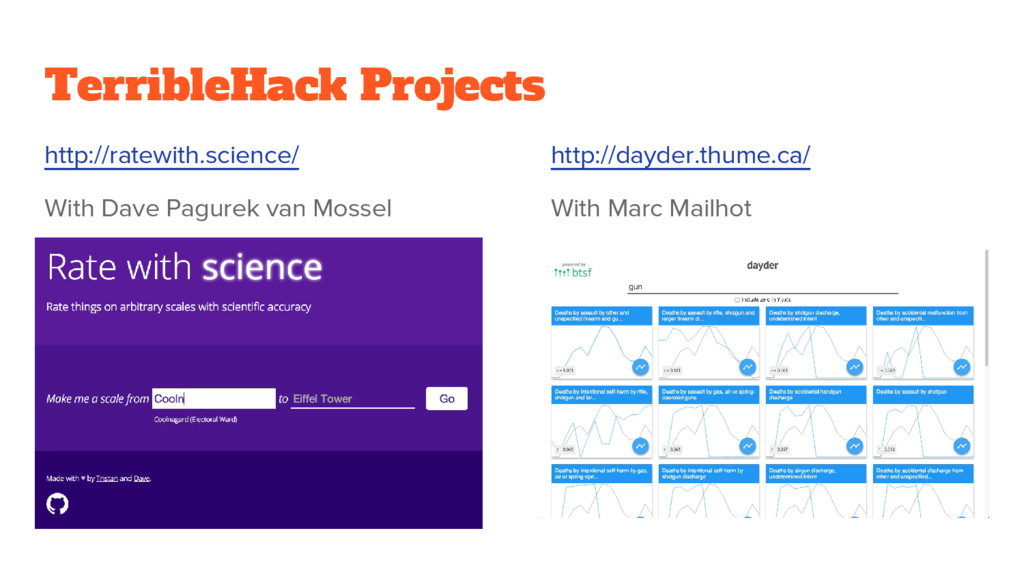
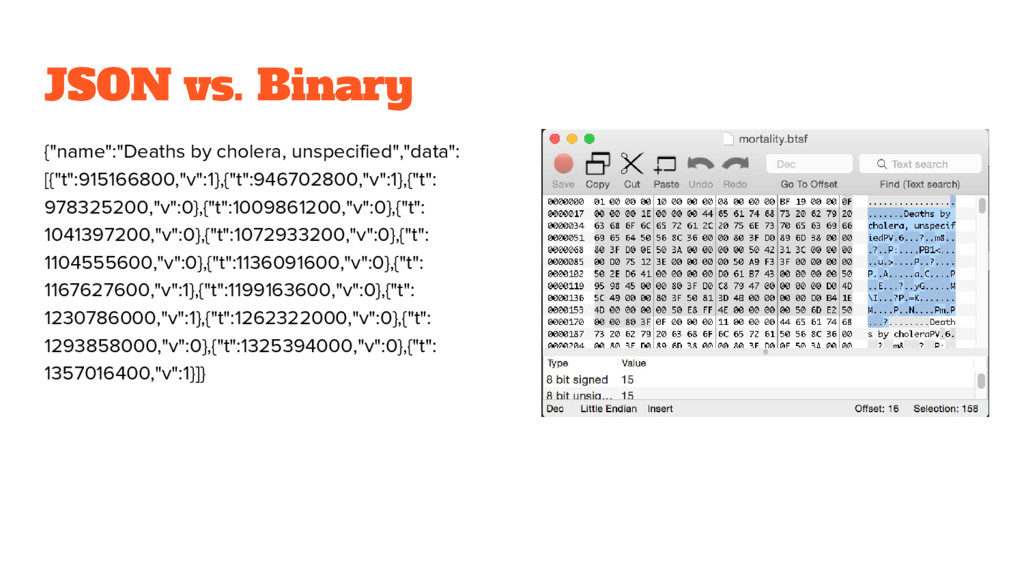
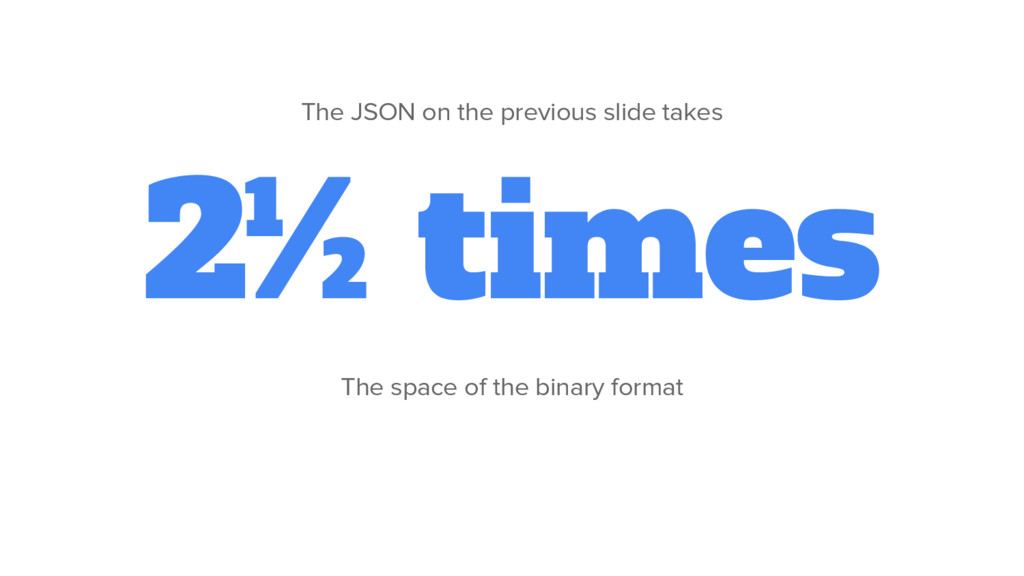
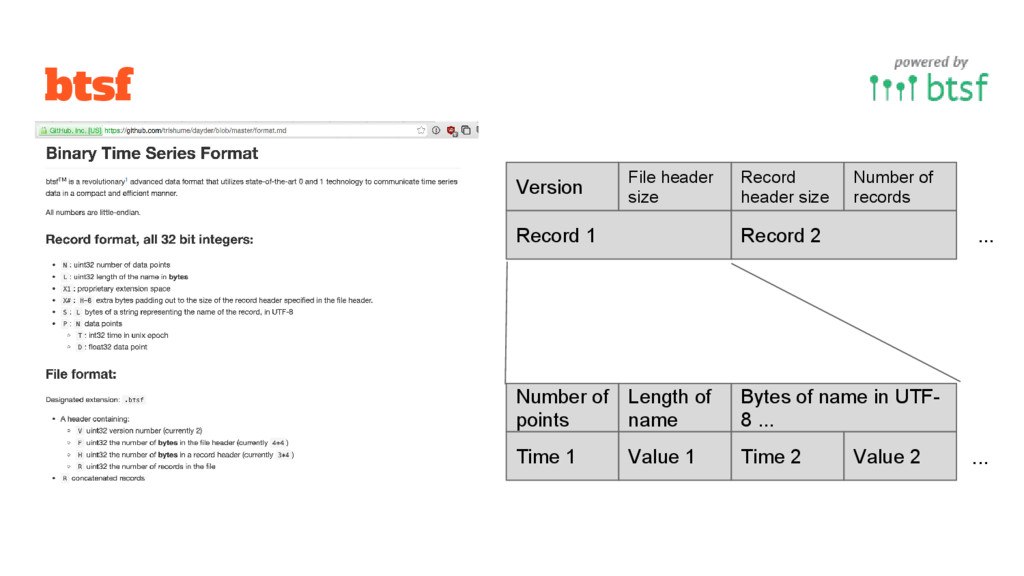
for efficient path finding directly on the format • Wikipedia link graph only 700MB • Can be memory mapped and casted to an array of uint32 http://dayder.thume.ca/ • Custom binary time series format • Stores tons of time series efficiently in one file • Allows 6591 time series records to be transmitted to JS client with one megabyte of data
◦ Faster network transmission ◦ Less disk space for large data sets • Can sometimes directly map them into memory ◦ Directly read binary format and avoid deserialization time • Really fast to serialize/deserialize • Almost every language can read them without a third party library ◦ No libraries means no time linking things, less reading docs and less dependencies • You feel like a pro
method on Array and the unpack method on String. • Python: The pack and unpack methods in the struct module. • C/C++: Casting pointers into byte arrays to the right type, or a library. • Rust: Some good third party libraries on crates.io ◦ https://github.com/BurntSushi/byteorder ◦ https://github.com/TyOverby/bincode • Javascript: ArrayBuffer, DataView, TextEncoder, TextDecoder ◦ Some of these are only in newer browsers but you can use polyfills for older ones (ordered by approximate ease of use easiest to hardest)
//en.wikipedia.org/wiki/Apache_Thrift ◦ Generates code for reading and writing binary data into language structures ◦ Available for tons of languages • Cap’n Proto: https://capnproto.org/ ◦ Can be accessed and used directly from memory, no serialization/deserialization step ◦ Exceedingly awesome, but only available for a few languages • BSON & MessagePack: http://msgpack.org/ http://bsonspec.org/ ◦ More compact JSON, but you still pay overhead for structure field names ◦ Available for TONS of • Avro: http://avro.apache.org/docs/1.3.0/ ◦ A middle ground that doesn’t redundantly encode names like MessagePack, but includes the schema once so that no external schema is necessary to decode it. ◦ Better for dynamic languages, approaches Thrift size on larger files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}