find what changed • But, there are many ways to describe the differences • Diff algorithms try to find the shortest description of the changes • The number of different diffs is exponential, so we need to be smart • Dynamic Programming is how we make diffing feasible
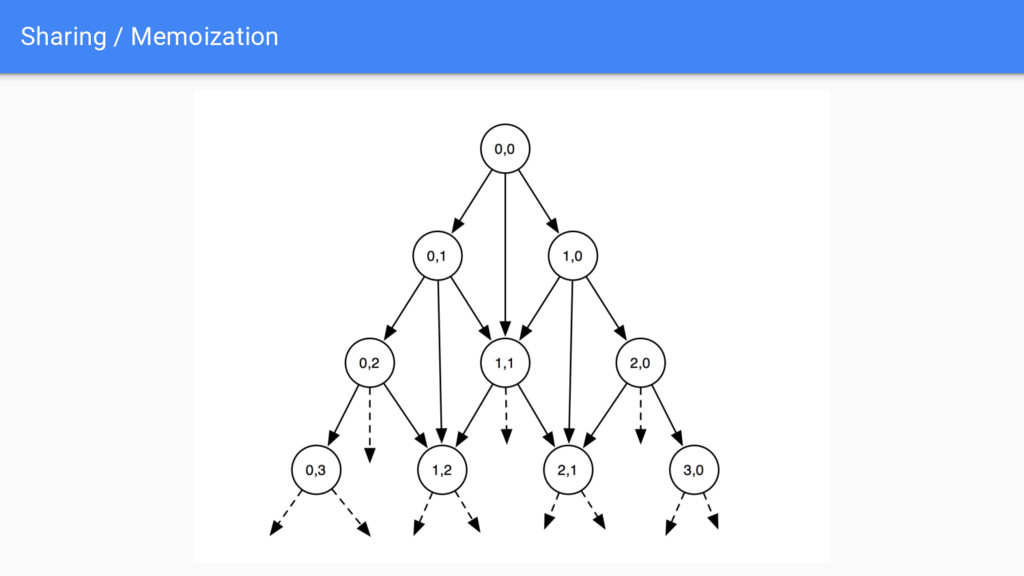
change count between A and B • We define best_cost(A,B) as the min change count between A and B • Now there’s three recursive possibilities: ◦ Same: best_cost(A,B) = best_cost(A[1..],A[1..]) if A[0] == B[0] ◦ Insert: best_cost(A,B) = 1+best_cost(A,B[1..]) ◦ Delete: best_cost(A,B) = 1+best_cost(A[1..], B) ◦ Base case: best_cost(“”,””) = 0 • Problem: this is exponential, but best_cost gets called with the same parameters a lot!
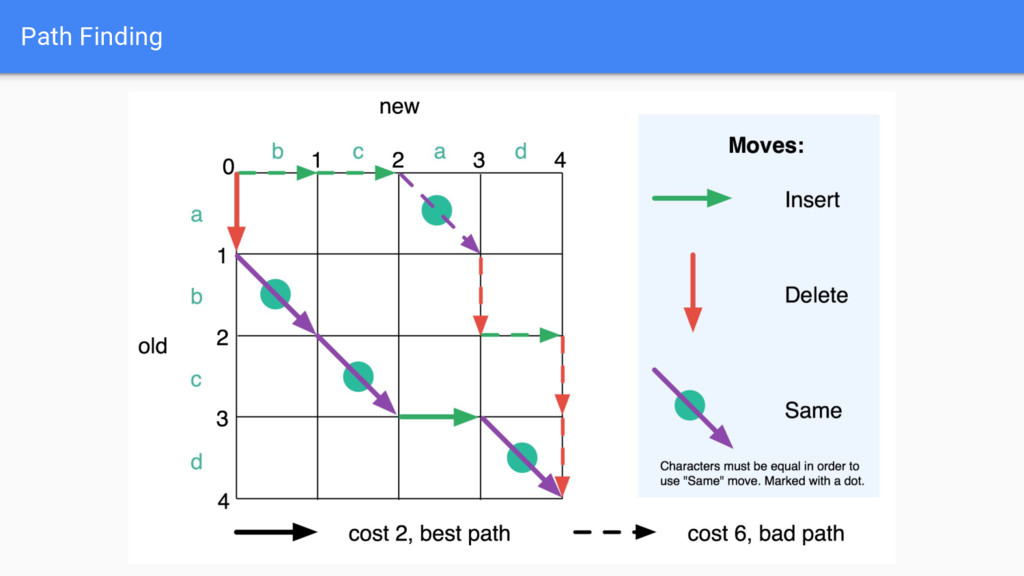
programming problems on grids and path finding on a grid. • … At least for a large class of diff-like problems. • If we want to come up with a new diff-like algorithm, we can think of it as a path finding problem. • Then translate to a memoized recursive algorithm when we want to implement it.
fast! This is really tricky. • I read a bunch of tree diffing papers, none were relevant. • Insertions and deletions can happen at multiple levels • It’s nicer (less characters) to group adjacent changes in one :date-switch
it as a path finding problem let me fit the problem in my head. • Allowed me to easily sketch ideas and edge cases in my notebook. • I came up with an algorithm by thinking of the different costs in my problem and the situations they applied, and coming up with a corresponding set of moves.
all cases we could think of. • But it was too slow, empirically something like O(n^3) in the file size. • Jane Street had files that were 10,000+ lines long, so this was a problem. • I spent a bunch of time profiling, caching and optimizing and got it down to O(n^2 log(n)) with a low constant factor. • But it still took ~6 minutes to run on our largest file :-(
a big algorithmic improvement. • Real life diff algorithms use specialized insights to improve their time complexity to something like O(n + d^2) where d is the amount changed. • But these special algorithms were hard to understand and generalize.
problem back to a memoized recursive search to implement it, we were just coding a depth first search path finding algorithm! • What if we used a better path finding algorithm instead? • Early on when I started thinking about the problem as path finding, I had a simple idea that I scrawled in my notes for later: A* • The A* algorithm is a path finding algorithm frequently used in games because it uses a heuristic to work much much faster.
Wikipedia and learned that all I needed was a heuristic that never underestimated the remaining distance to the destination. • It turned out that the maximum of the remaining size on either side worked. • Now it mostly searched near the diagonal of the grid. • Made my program run instantly on the largest files, being linear-ish in file size but still ~O(n + d^2 log(d)) where d is amount of changes. • Used a hash table for memoization so space use was also linear-ish.
problems: • It can make it easier to think of solutions to new problems. • It’s easy to adapt to new problems by just adding/changing the moves. • You can easily accelerate it with A* instead of having to think of fancy algorithm-specific tricks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}