Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AI・機械学習応用論2020
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Y. Yamamoto
PRO
October 29, 2020
Technology
460
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AI・機械学習応用論2020
とある企業向けの出張講義資料です.
Y. Yamamoto
PRO
October 29, 2020
More Decks by Y. Yamamoto
See All by Y. Yamamoto
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
720
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.5k
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.4k
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.4k
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.6k
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.4k
機械学習 - SVM
trycycle
PRO
2
1.2k
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
Other Decks in Technology
See All in Technology
GoでCコンパイラを作った話
repunit
0
150
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
270
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
25
11k
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
520
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
4.5k
OPENLOGI Company Profile for engineer
hr01
1
74k
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
220
Featured
See All Featured
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
The Curse of the Amulet
leimatthew05
2
13k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
Crafting Experiences
bethany
1
230
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Being A Developer After 40
akosma
91
590k
We Are The Robots
honzajavorek
0
280
How to build a perfect <img>
jonoalderson
1
5.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
AI・機械学習応用論 山本 祐輔 静岡大学 情報学部 講師
[email protected]
出張講座2020 2020年11月11日 本スライドは,クリエイティブ・コモンズ・ライセンス国際4.0のもとで,
ライセンスされています.
講義スタイル Hands-onデモ with Python 0:00 1:30 0:30 座学 デモ &
演習 座学 デモ & 演習 座学 デモ & 演習 座学 座学 クラスタリング はじめての機械学習 時系列分析 1コマの構成 「各種分析⼿法を使うと何が起こるか」の体験に焦点を当てる 1日の構成 上記スタイルで4つのトピックを学習 2 機械学習応用事例
講座で使⽤するもの(1/2) 配布スライド(座学用) Google Colaboratory 3
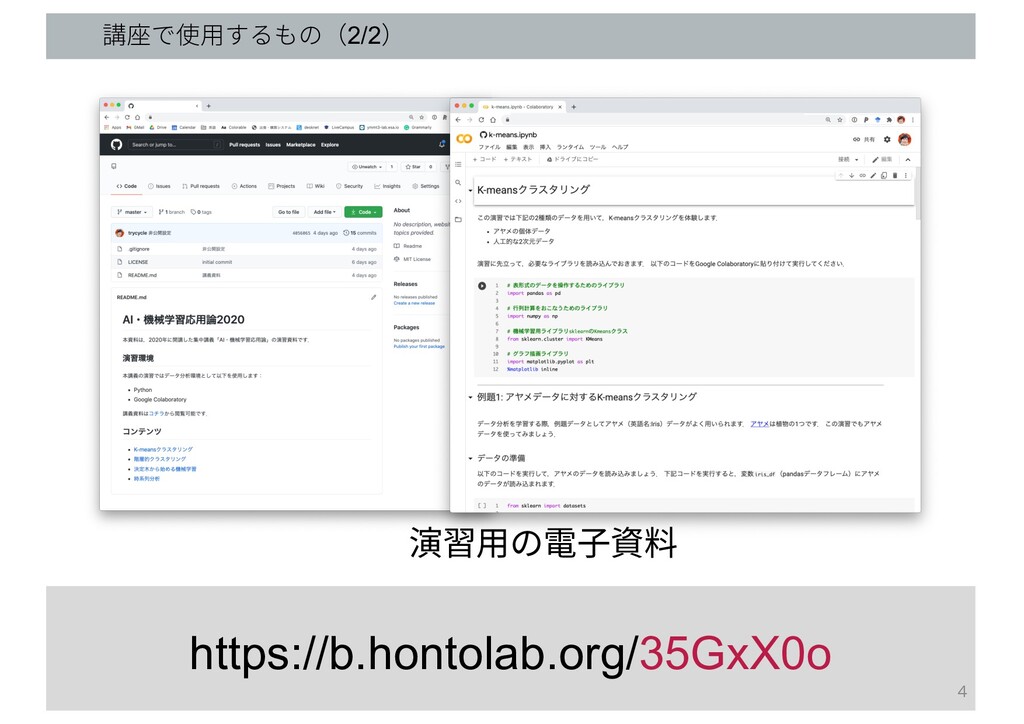
講座で使⽤するもの(2/2) https://b.hontolab.org/35GxX0o 演習⽤の電⼦資料 4
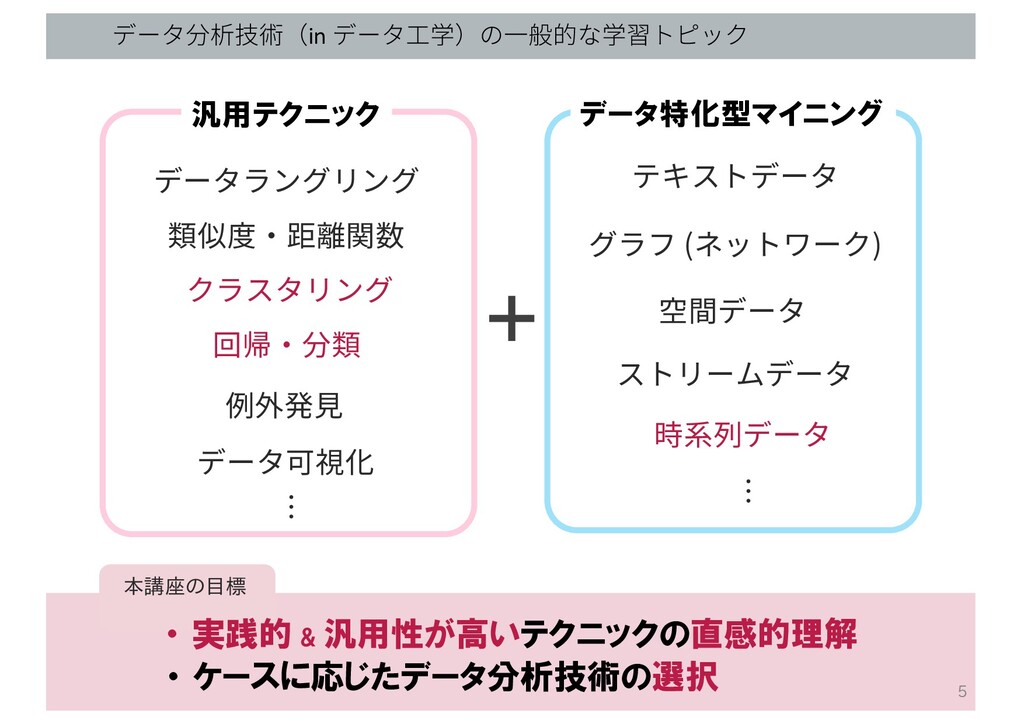
データ分析技術(in データ⼯学)の⼀般的な学習トピック データラングリング 類似度・距離関数 クラスタリング 例外発⾒ 回帰・分類 テキストデータ グラフ (ネットワーク)
時系列データ ストリームデータ 空間データ 汎用テクニック データ特化型マイニング … データ可視化 本講座の目標 ・ 実践的 & 汎用性が高いテクニックの直感的理解 ・ ケースに応じたデータ分析技術の選択 5 …
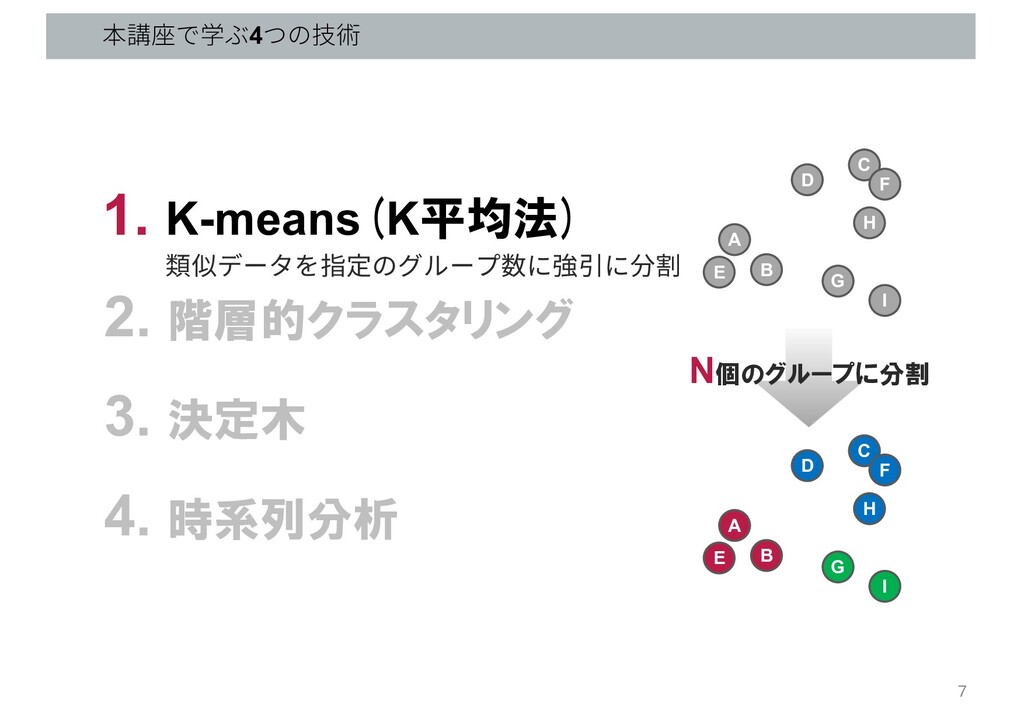
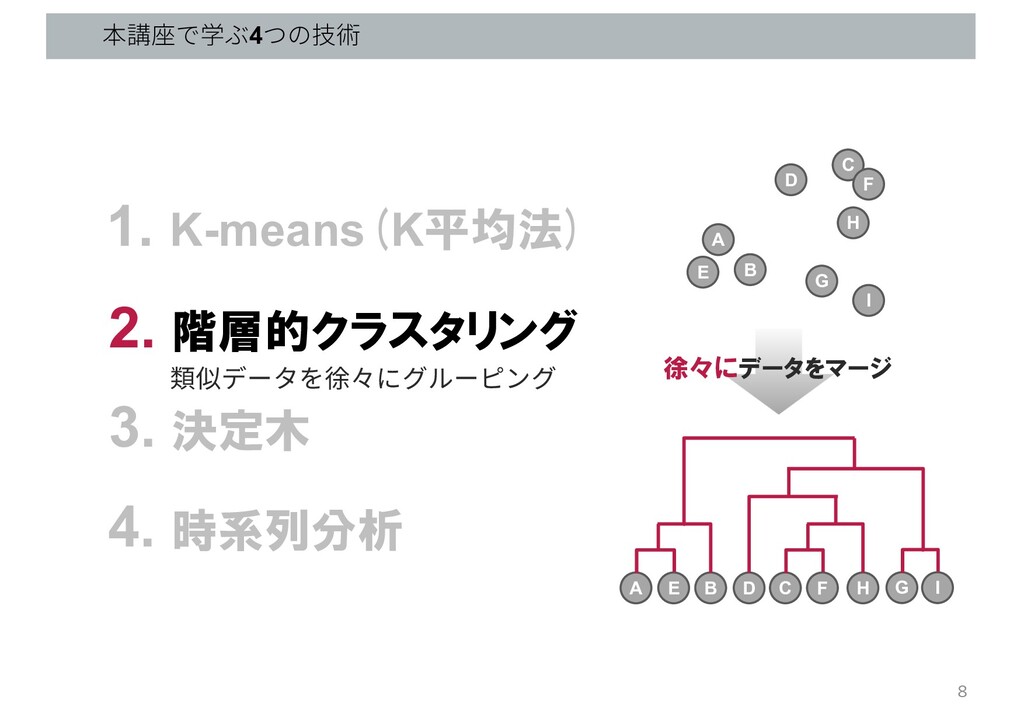
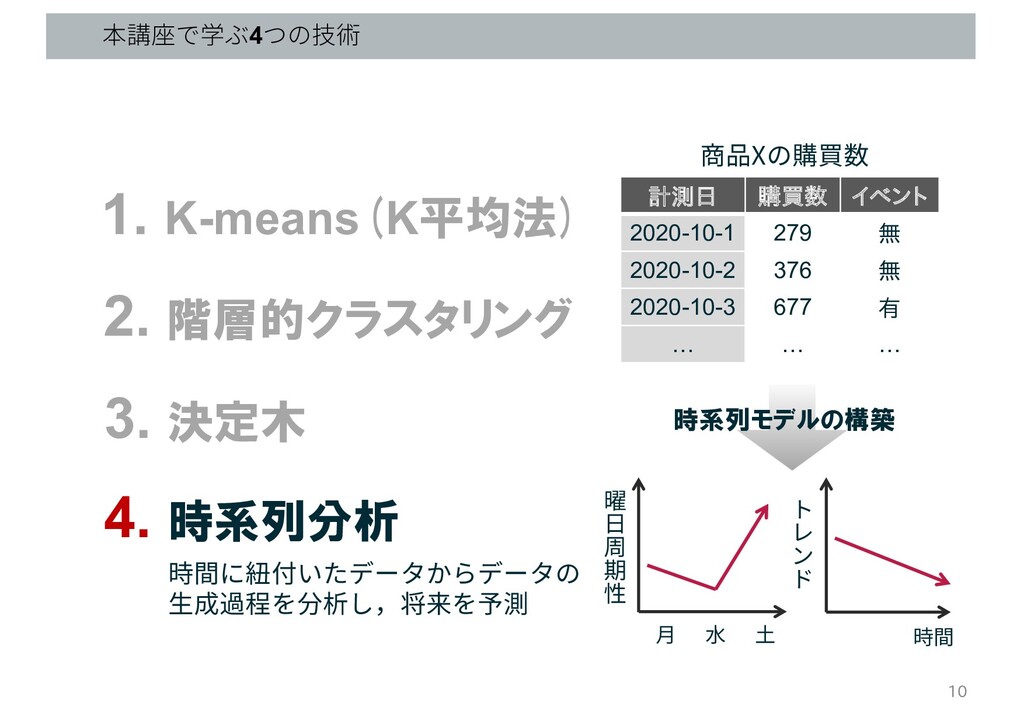
本講座で学ぶ4つの技術 1. K-means(K平均法) 2. 階層的クラスタリング 3. 決定木 4. 時系列分析 6
本講座で学ぶ4つの技術 1. K-means(K平均法) 2. 階層的クラスタリング 3. 決定木 4. 時系列分析 A
B D C E F G H I A B D C E F G H I N個のグループに分割 類似データを指定のグループ数に強引に分割 7
本講座で学ぶ4つの技術 1. K-means(K平均法) 2. 階層的クラスタリング 3. 決定木 4. 時系列分析 A
B D C E F G H I A B D C E F G H I 徐々にデータをマージ 類似データを徐々にグルーピング 8
本講座で学ぶ4つの技術 1. K-means(K平均法) 2. 階層的クラスタリング 3. 決定木 4. 時系列分析 結果を予測するための分岐ルールを構築
毒 柄色 柄形 臭い あり 紫 直線 あり なし 朱 末広 刺激 … … … … キノコの記録 毒キノコを分類するルールを抽出 臭い あり なし 柄の色が緑 yes no 毒あり1% 毒あり100% … 9
本講座で学ぶ4つの技術 1. K-means(K平均法) 2. 階層的クラスタリング 3. 決定木 4. 時系列分析 時間に紐付いたデータからデータの
⽣成過程を分析し,将来を予測 10 時系列モデルの構築 計測日 購買数 イベント 2020-10-1 279 無 2020-10-2 376 無 2020-10-3 677 有 … … … 商品Xの購買数 時間 ⽉ 曜 ⽇ 周 期 性 ⽔ ⼟
本⽇の講座でやらないこと l各種データ分析技術の数学的理解 l最適化(パラメータチューニング) l分析結果の評価方法 l前処理(データラングリング) lディープラーニングの詳細解説 11
参考図書 画像出典2: https://www.amazon.co.jp/dp/B07GYS3RG7/ 画像出典1: https://www.amazon.co.jp/dp/B00MWODXX8 12
1 指定されたグループ数に強引にデータを分割する K-meansクラスタリング
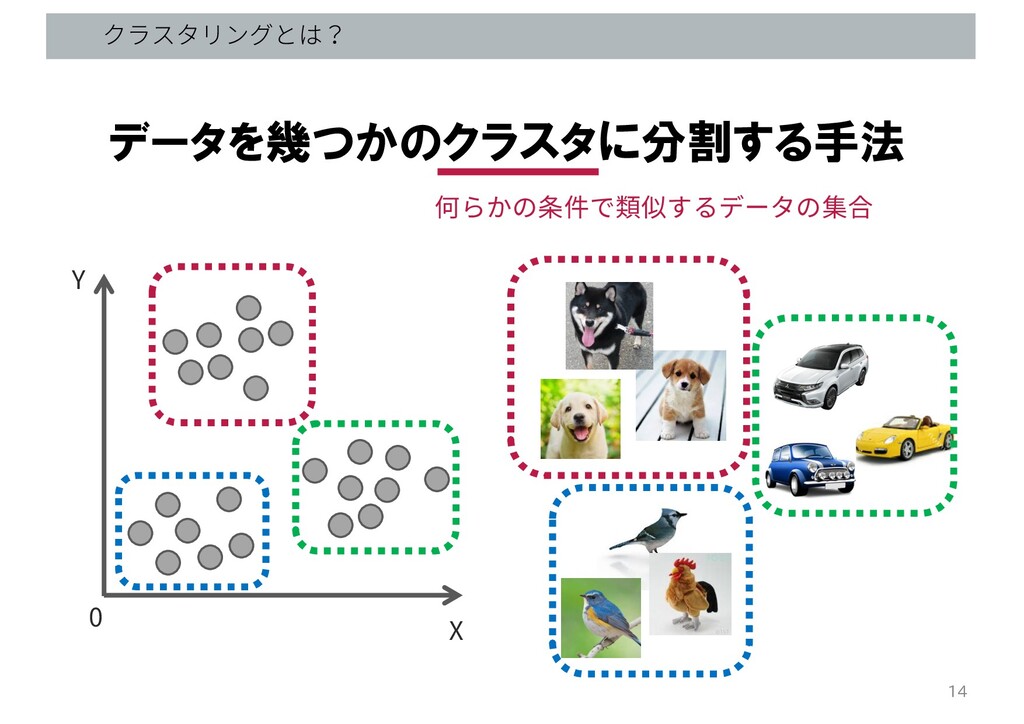
データを幾つかのクラスタに分割する手法 何らかの条件で類似するデータの集合 クラスタリングとは? X Y 0 14
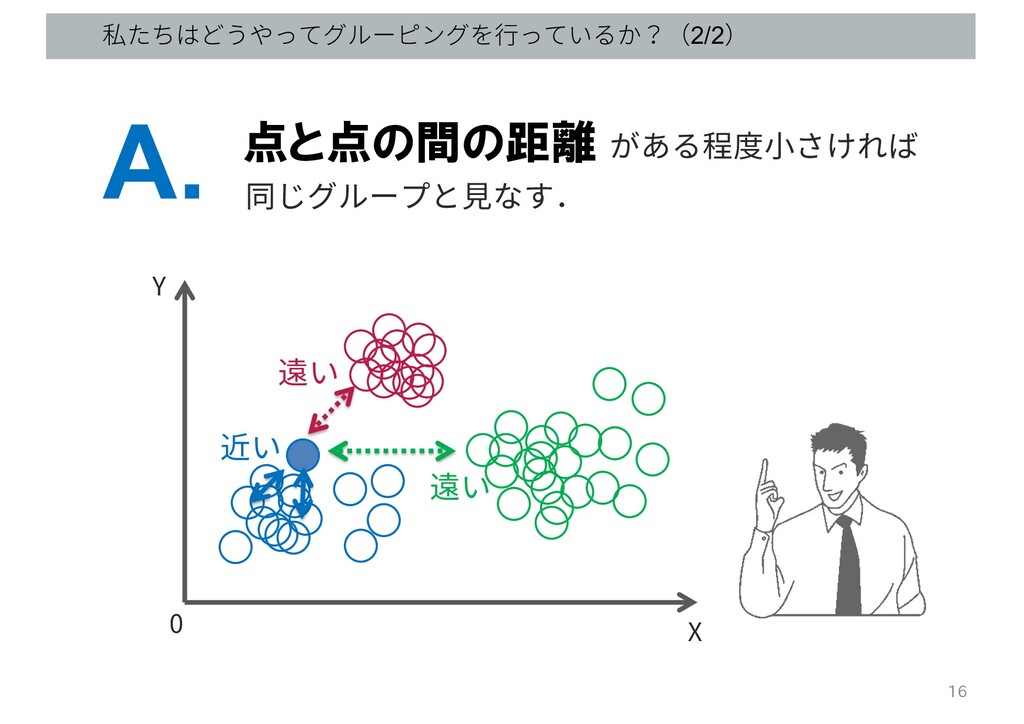
私たちはどうやってグルーピングを⾏っているか?(1/2) 私たちは,直感的には何にもとづき 以下のデータをグルーピングするか? Q. X Y 0 15
私たちはどうやってグルーピングを⾏っているか?(2/2) 点と点の間の距離 A. X Y 0 がある程度⼩さければ 同じグループと⾒なす. 近い 遠い
遠い 16
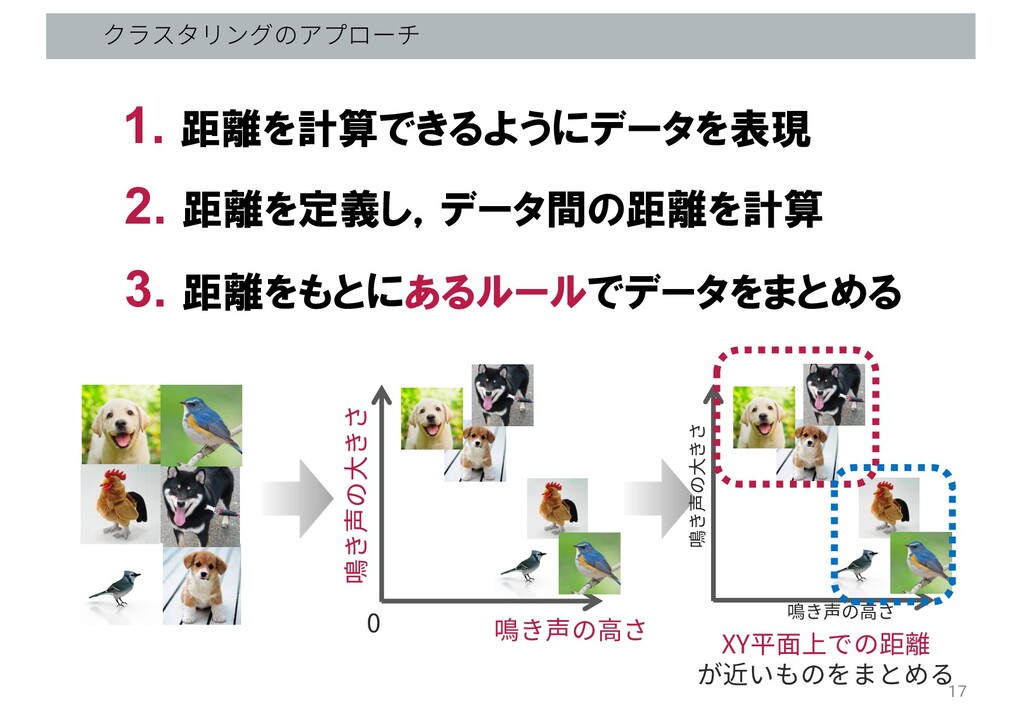
クラスタリングのアプローチ 1. 距離を計算できるようにデータを表現 2. 距離を定義し,データ間の距離を計算 3. 距離をもとにあるルールでデータをまとめる 鳴き声の⾼さ 0 鳴き声の⼤きさ
鳴き声の⾼さ 鳴き声の⼤きさ XY平⾯上での距離 が近いものをまとめる 17
クラスタリングのアプローチ 1. 距離を計算できるようにデータを表現 2. 距離を定義し,データ間の距離を計算 3. 距離をもとにあるルールでデータをまとめる 鳴き声の⾼さ 0 鳴き声の⼤きさ
鳴き声の⾼さ 鳴き声の⼤きさ XY平⾯上での距離 が近いものをまとめる ポイント クラスタリング手法の違いはデータをまとめるルールにある 18
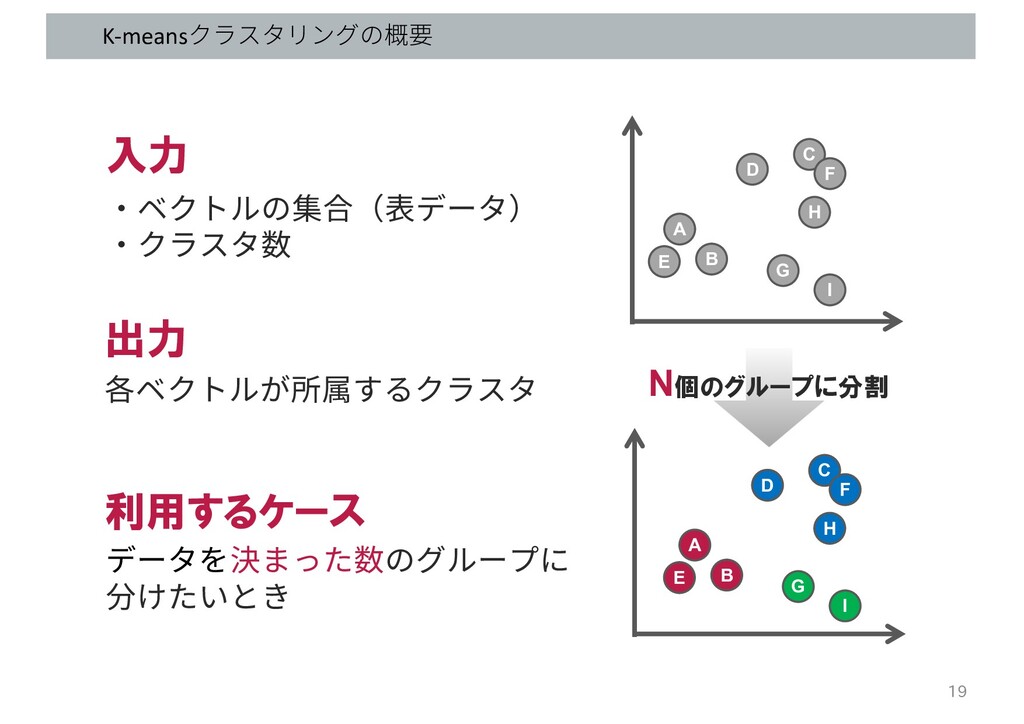
K-meansクラスタリングの概要 A B D C E F G H I
A B D C E F G H I 入力 ・ベクトルの集合(表データ) ・クラスタ数 出力 各ベクトルが所属するクラスタ 利用するケース データを決まった数のグループに 分けたいとき 19 N個のグループに分割
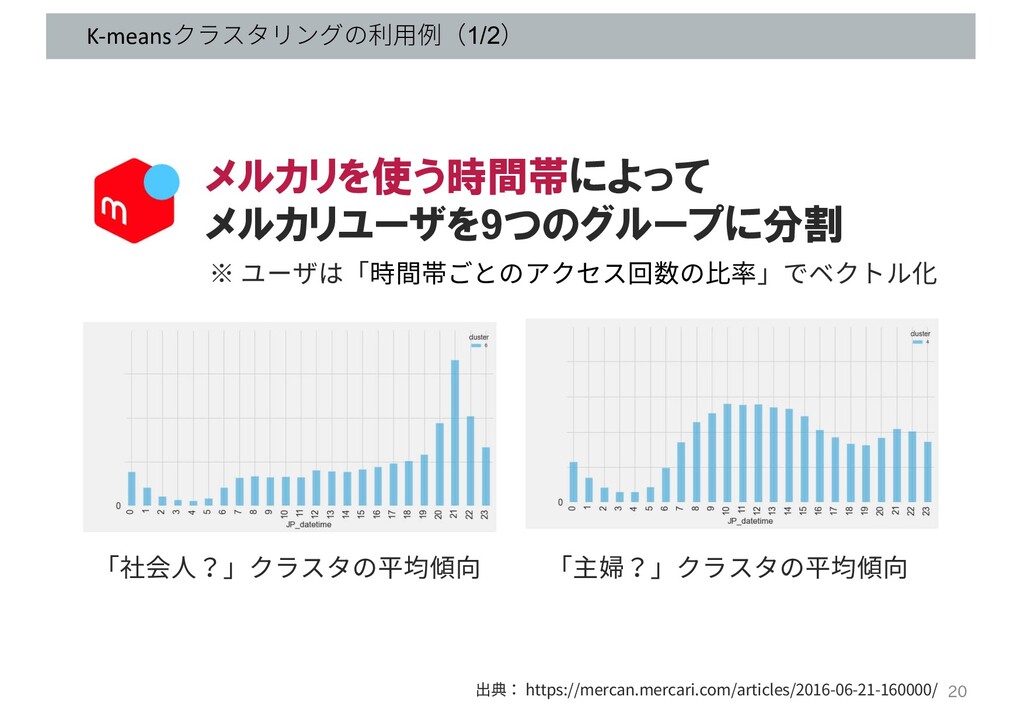
K-meansクラスタリングの利⽤例(1/2) 出典: https://mercan.mercari.com/articles/2016-06-21-160000/ 「社会⼈?」クラスタの平均傾向 「主婦?」クラスタの平均傾向 メルカリを使う時間帯によって メルカリユーザを9つのグループに分割 ※ ユーザは「時間帯ごとのアクセス回数の⽐率」でベクトル化 20
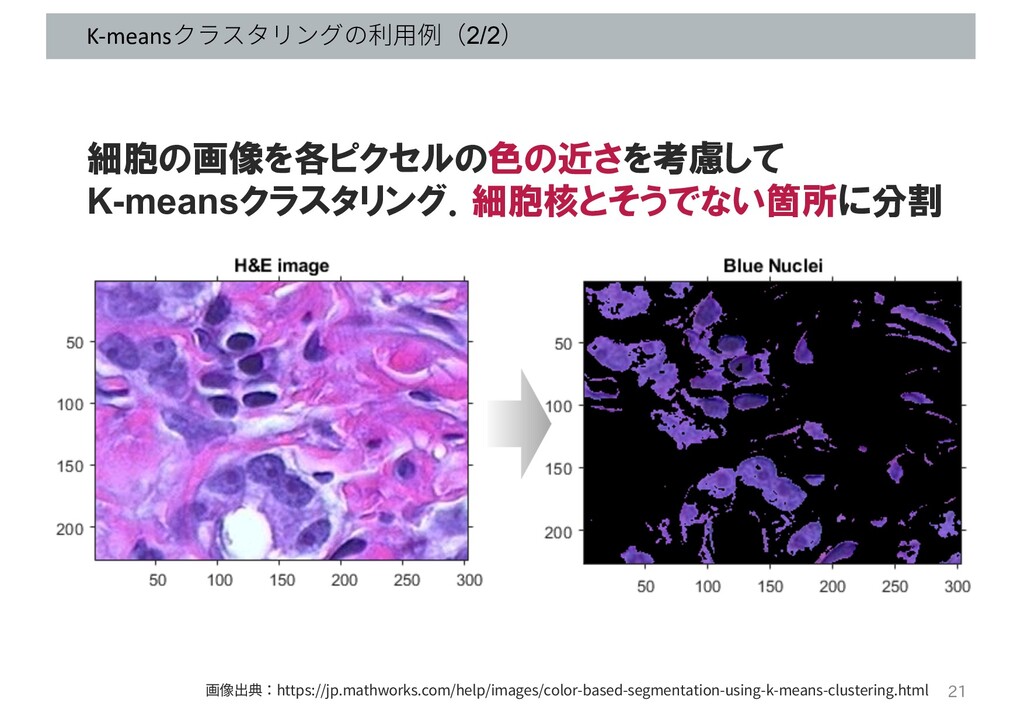
K-meansクラスタリングの利⽤例(2/2) 画像出典:https://jp.mathworks.com/help/images/color-based-segmentation-using-k-means-clustering.html 細胞の画像を各ピクセルの色の近さを考慮して K-meansクラスタリング.細胞核とそうでない箇所に分割 21
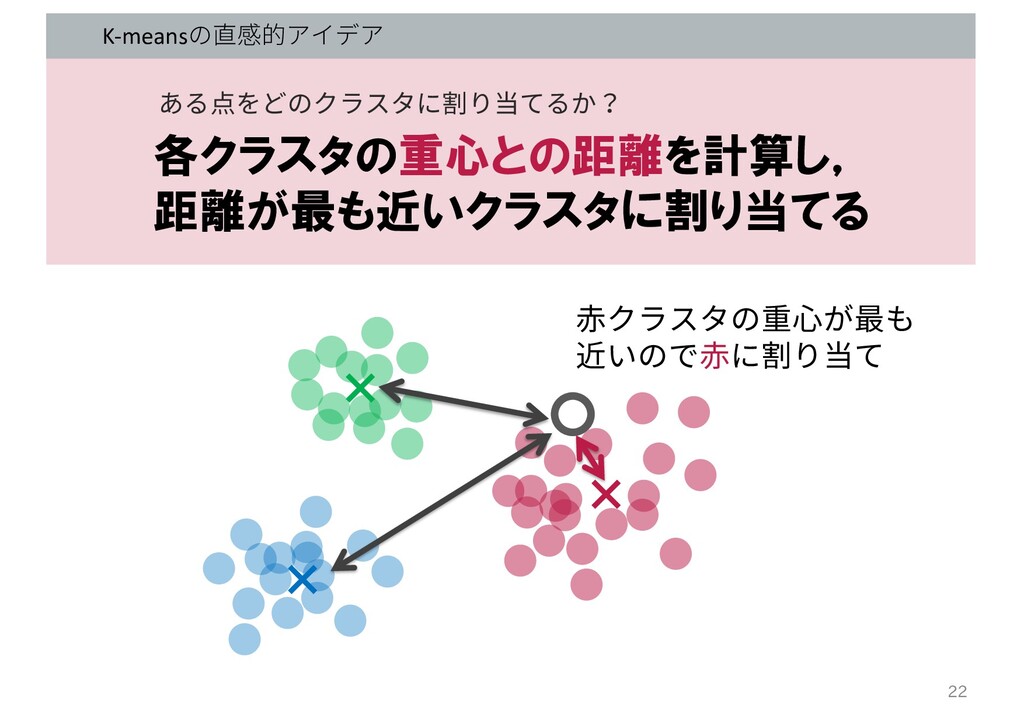
K-meansの直感的アイデア + + + ⾚クラスタの重⼼が最も 近いので⾚に割り当て 各クラスタの重心との距離を計算し, 距離が最も近いクラスタに割り当てる ある点をどのクラスタに割り当てるか? 22
K-meansのアルゴリズム(1/12) 各データをランダムにクラスタに割り当て 1. 23
K-meansのアルゴリズム(2/12) 各データをランダムにクラスタに割り当て 1. 24
K-meansのアルゴリズム(3/12) 各クラスタの重心を計算する 2. + + + 25
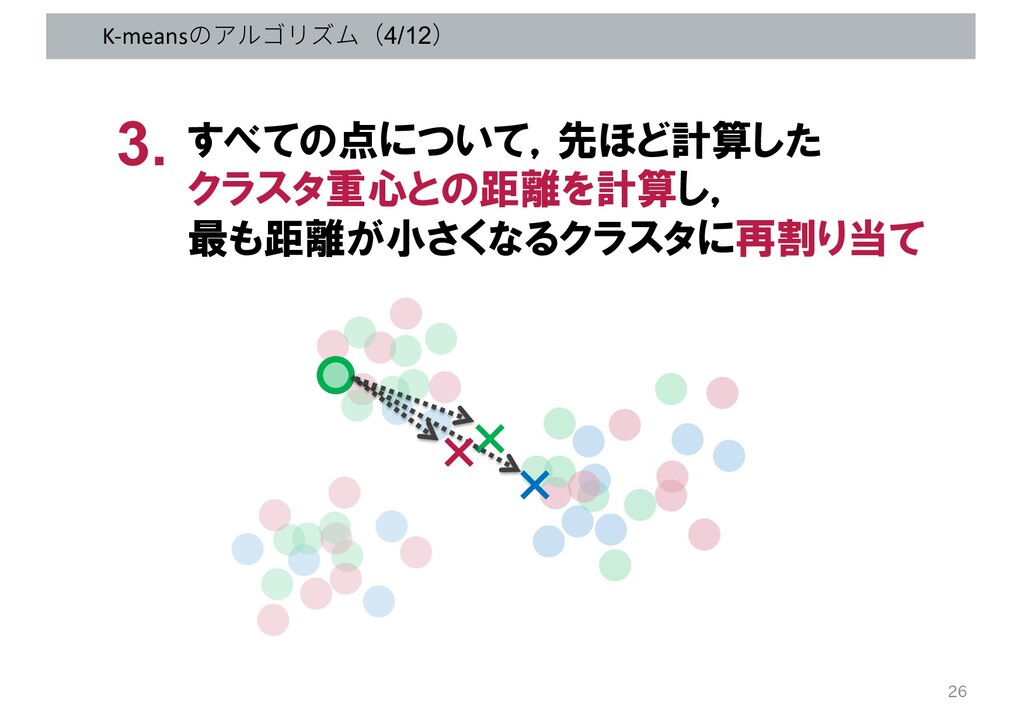
K-meansのアルゴリズム(4/12) すべての点について,先ほど計算した クラスタ重心との距離を計算し, 最も距離が小さくなるクラスタに再割り当て 3. + + 26 +
K-meansのアルゴリズム(5/12) すべての点について,先ほど計算した クラスタ重心との距離を計算し, 最も距離が小さくなるクラスタに再割り当て 3. + + 27 +
K-meansのアルゴリズム(6/12) すべての点について,先ほど計算した クラスタ重心との距離を計算し, 最も距離が小さくなるクラスタに再割り当て 3. + + 28 +
K-meansのアルゴリズム(7/12) すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. + + + 29
K-meansのアルゴリズム(8/12) すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. + + + 30
K-meansのアルゴリズム(9/12) すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. + + + 31
K-meansのアルゴリズム(10/12) すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. + + + 32
K-meansのアルゴリズム(11/12) すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. + + + 33
K-meansのアルゴリズム(12/12) + + + すべての点のクラスタ割り当てが 変わらなくなるまでステップ2と3を繰り返す 4. 34
Hands-on & 演習タイム 以下のURLにアクセスして, K-meansクラスタリングを体験しましょう https://b.hontolab.org/3mL2Xn4 35
2 類似するデータを徐々にグルーピングする 階層的クラスタリング
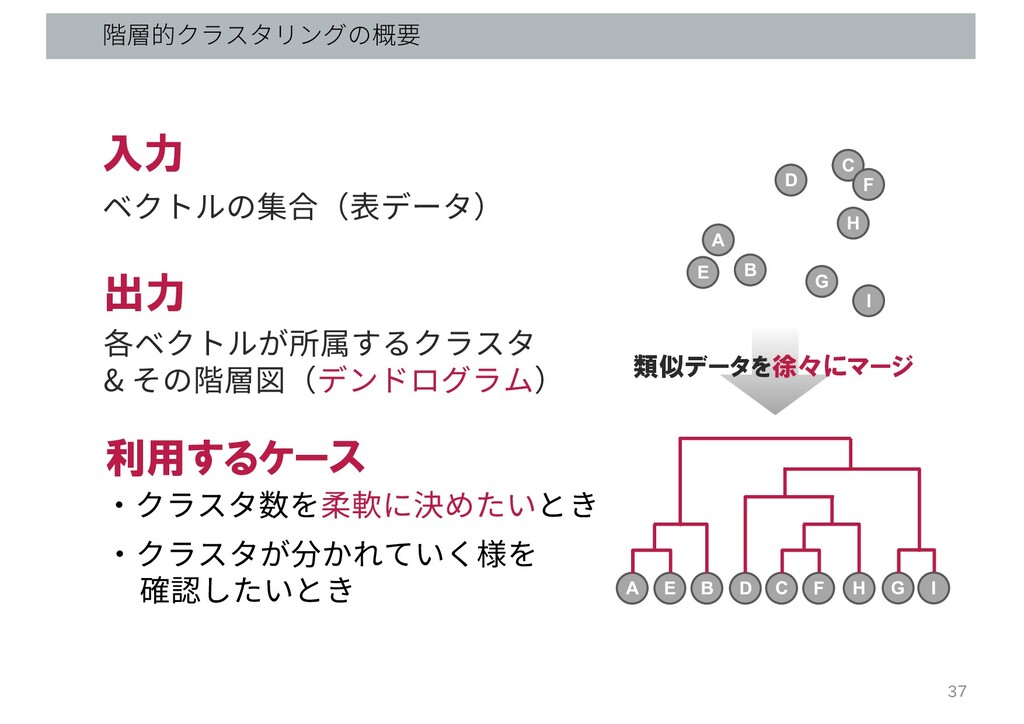
階層的クラスタリングの概要 入力 ベクトルの集合(表データ) 出力 各ベクトルが所属するクラスタ & その階層図(デンドログラム) 利用するケース A B
D C E F G H I A B D C E F G H I 類似データを徐々にマージ ・クラスタ数を柔軟に決めたいとき ・クラスタが分かれていく様を 確認したいとき 37
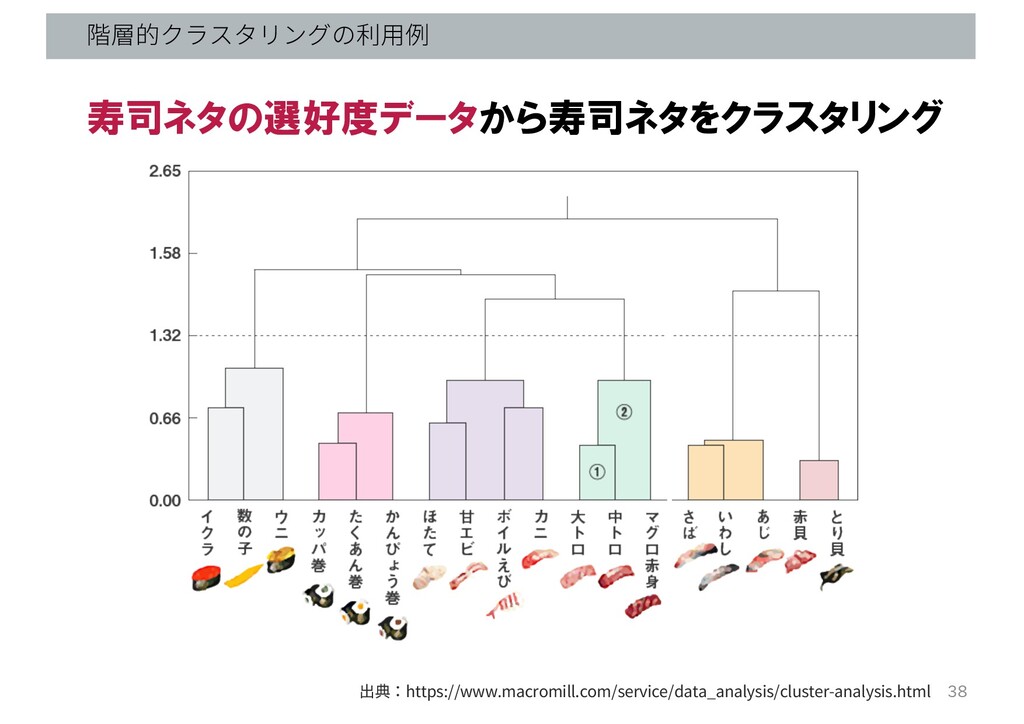
階層的クラスタリングの利⽤例 出典:https://www.macromill.com/service/data_analysis/cluster-analysis.html 寿司ネタの選好度データから寿司ネタをクラスタリング 38
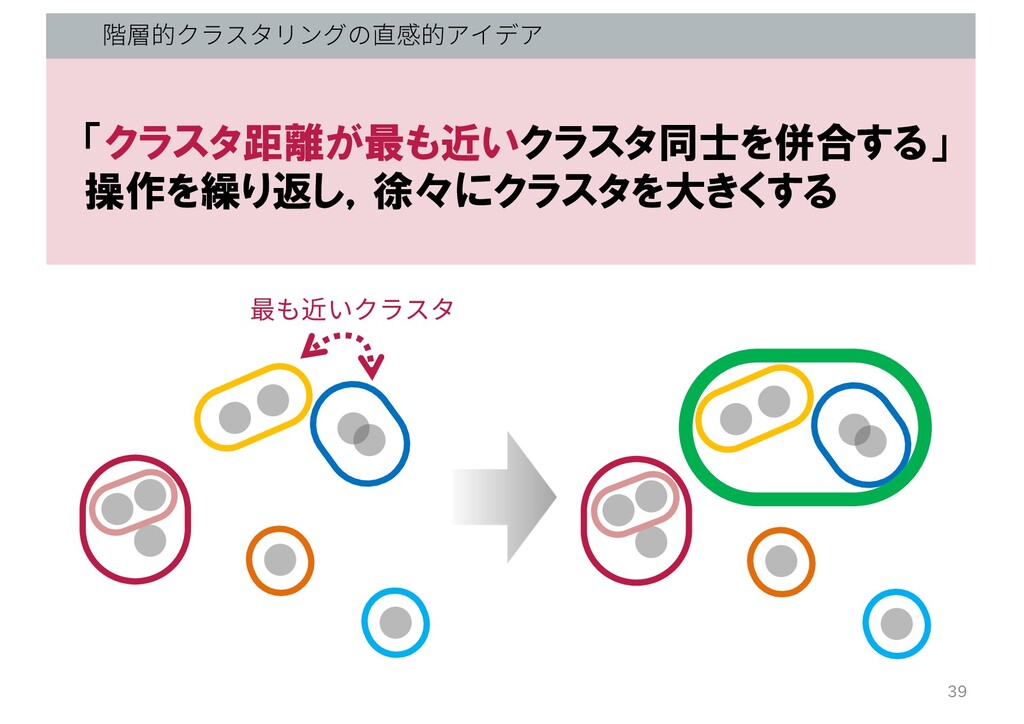
階層的クラスタリングの直感的アイデア 「クラスタ距離が最も近いクラスタ同士を併合する」 操作を繰り返し,徐々にクラスタを大きくする 最も近いクラスタ 39
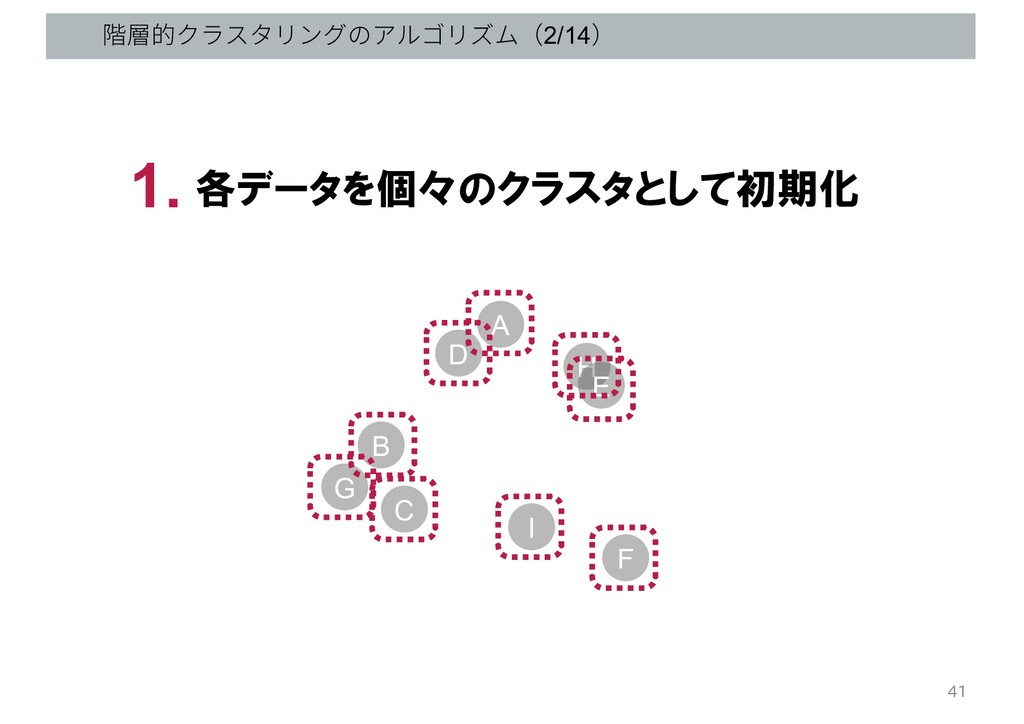
階層的クラスタリングのアルゴリズム(1/14) 各データを個々のクラスタとして初期化 1. G B C D A H E
I F 40
階層的クラスタリングのアルゴリズム(2/14) 各データを個々のクラスタとして初期化 1. G B C D A H E
I F 41
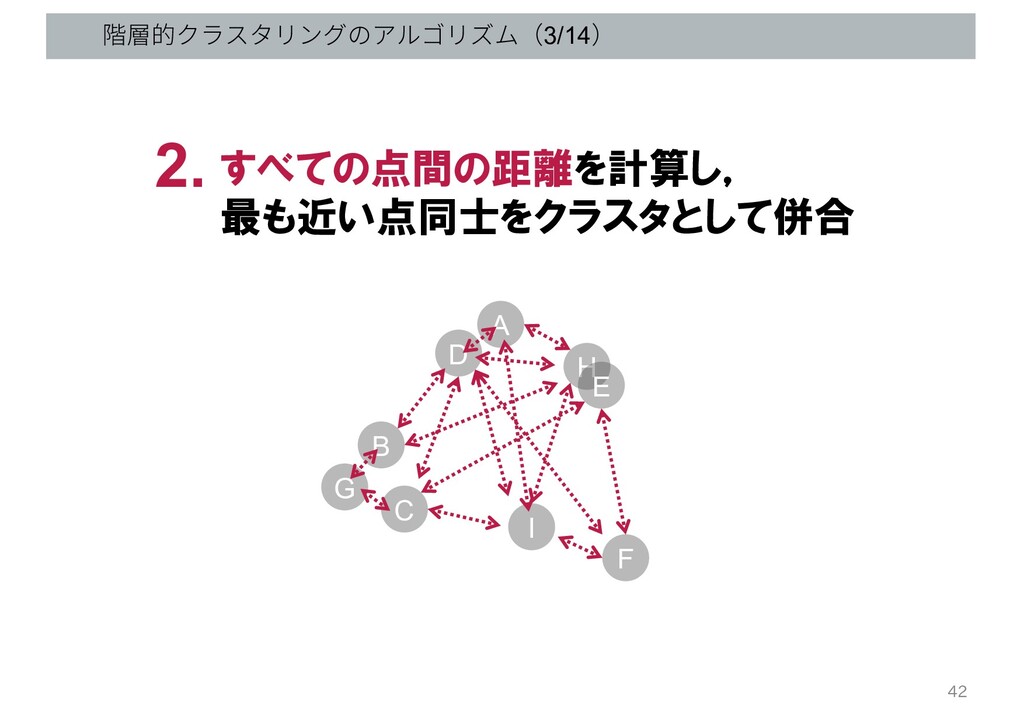
階層的クラスタリングのアルゴリズム(3/14) G B C D A H E I F
すべての点間の距離を計算し, 最も近い点同士をクラスタとして併合 2. 42
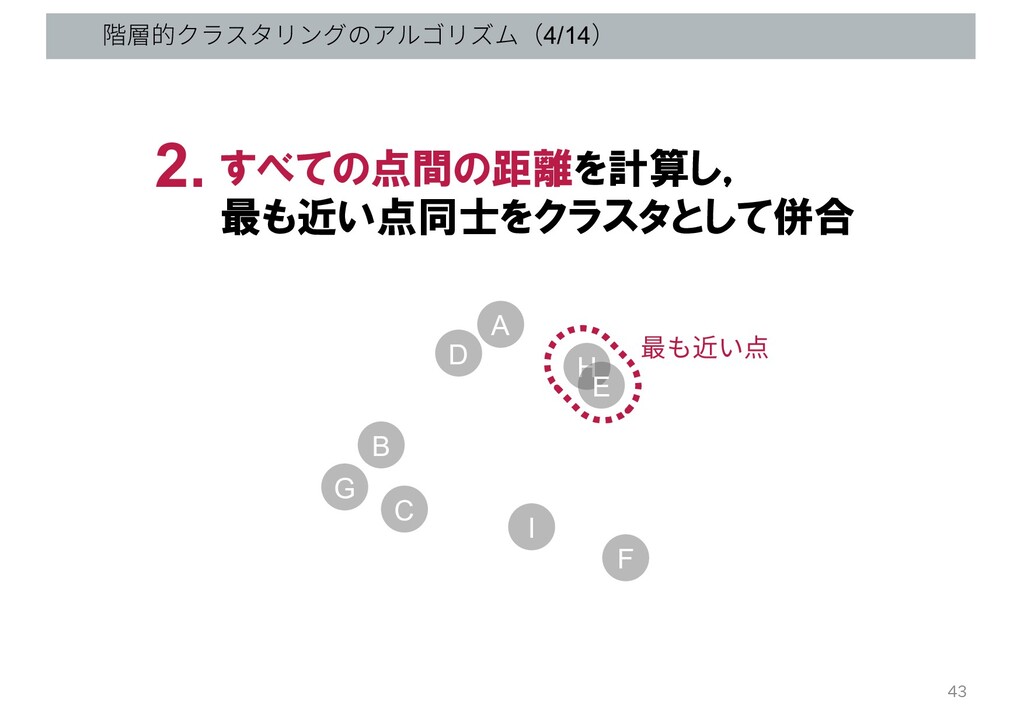
階層的クラスタリングのアルゴリズム(4/14) G B C D A H E I F
最も近い点 すべての点間の距離を計算し, 最も近い点同士をクラスタとして併合 2. 43
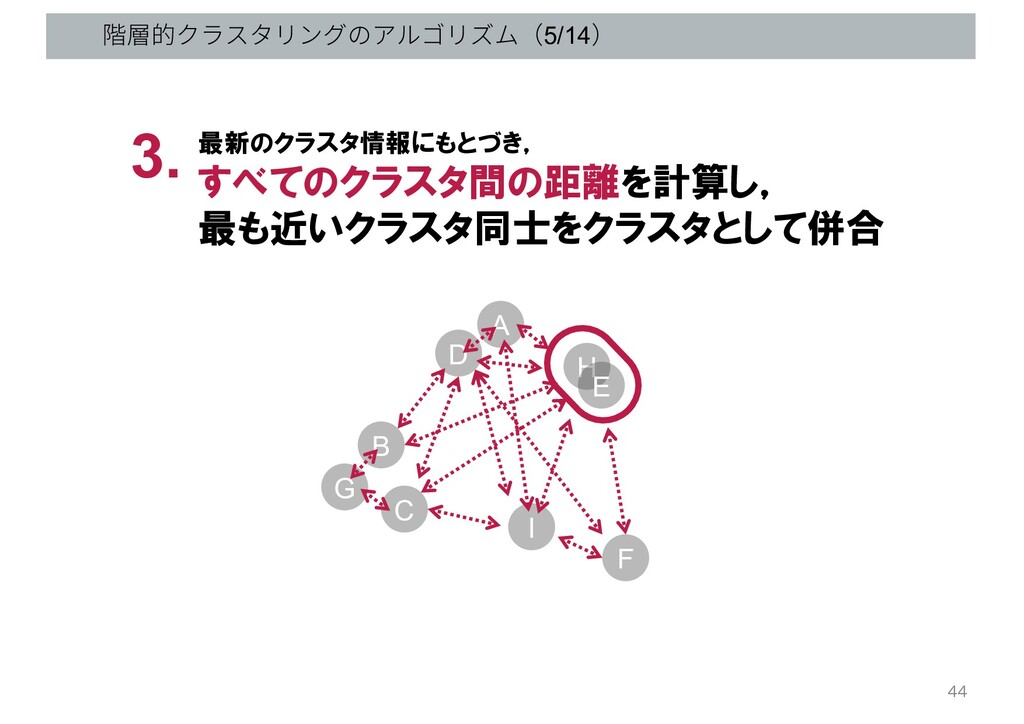
階層的クラスタリングのアルゴリズム(5/14) G B C D A H E I F
最新のクラスタ情報にもとづき, すべてのクラスタ間の距離を計算し, 最も近いクラスタ同士をクラスタとして併合 3. 44
階層的クラスタリングのアルゴリズム(6/14) 最新のクラスタ情報にもとづき, すべてのクラスタ間の距離を計算し, 最も近いクラスタ同士をクラスタとして併合 3. G B C D A
H E I F 最もクラスタ(点) 45
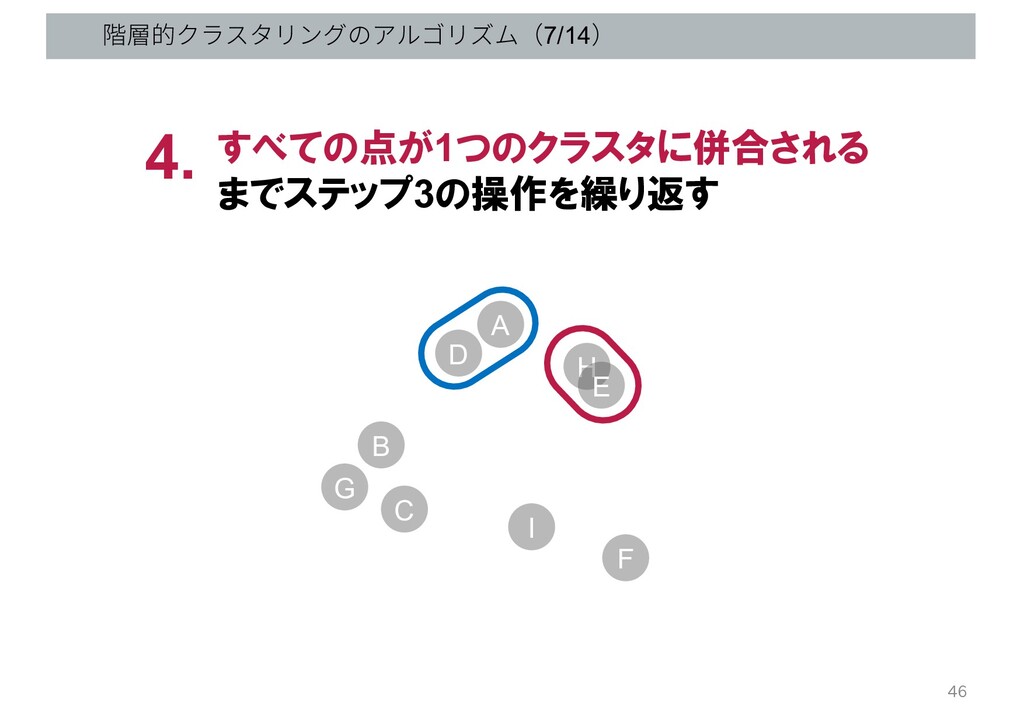
階層的クラスタリングのアルゴリズム(7/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 46
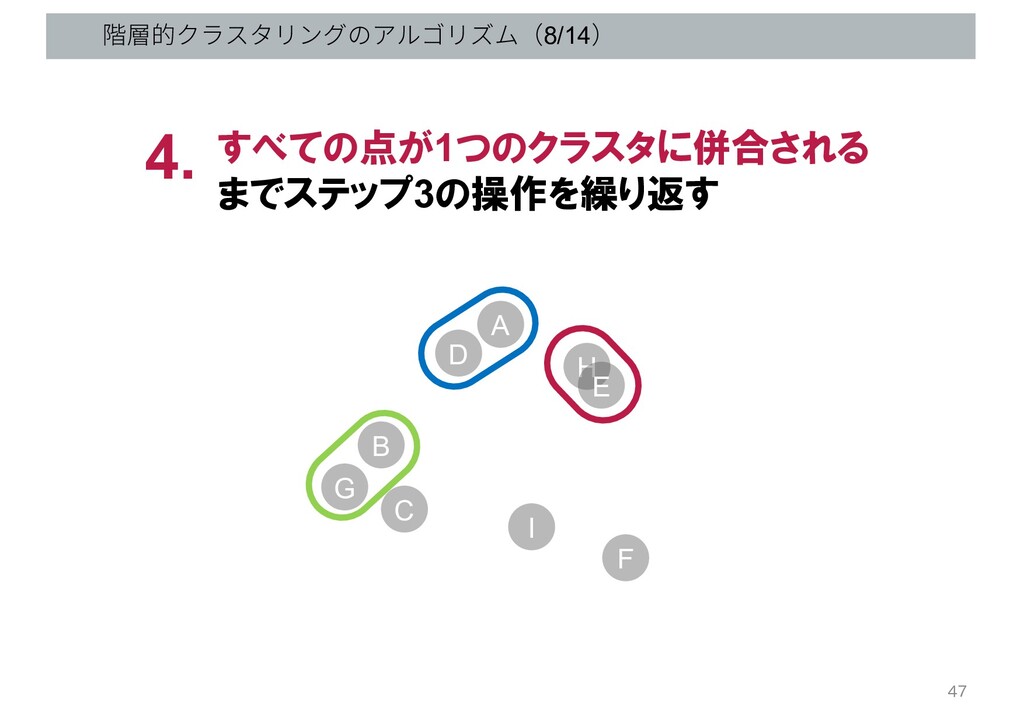
階層的クラスタリングのアルゴリズム(8/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 47
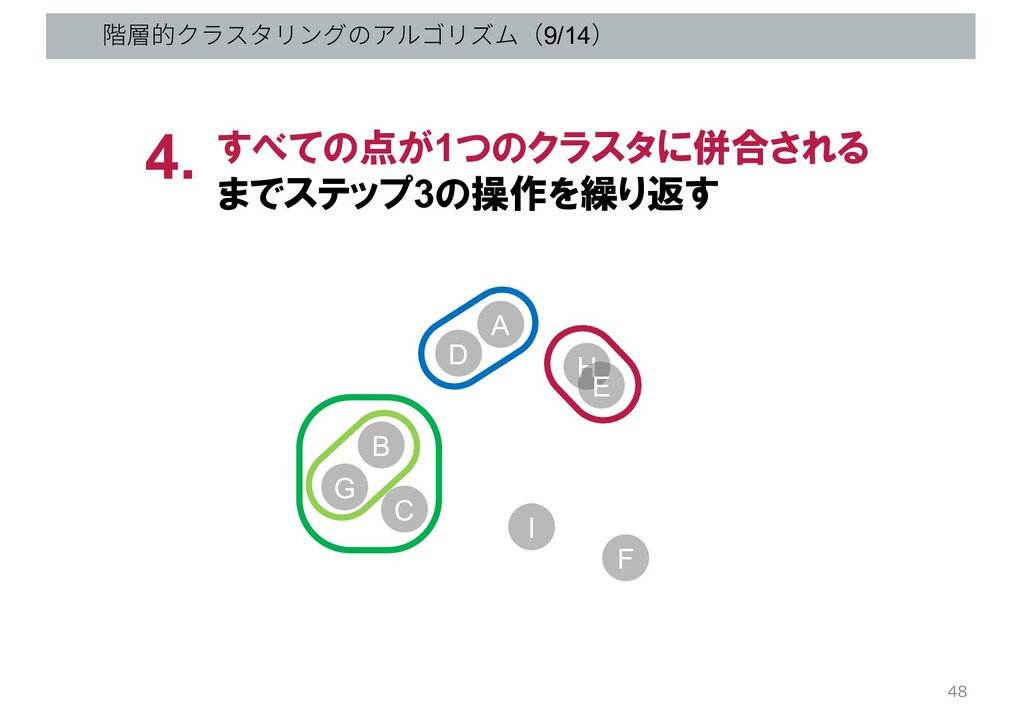
階層的クラスタリングのアルゴリズム(9/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 48
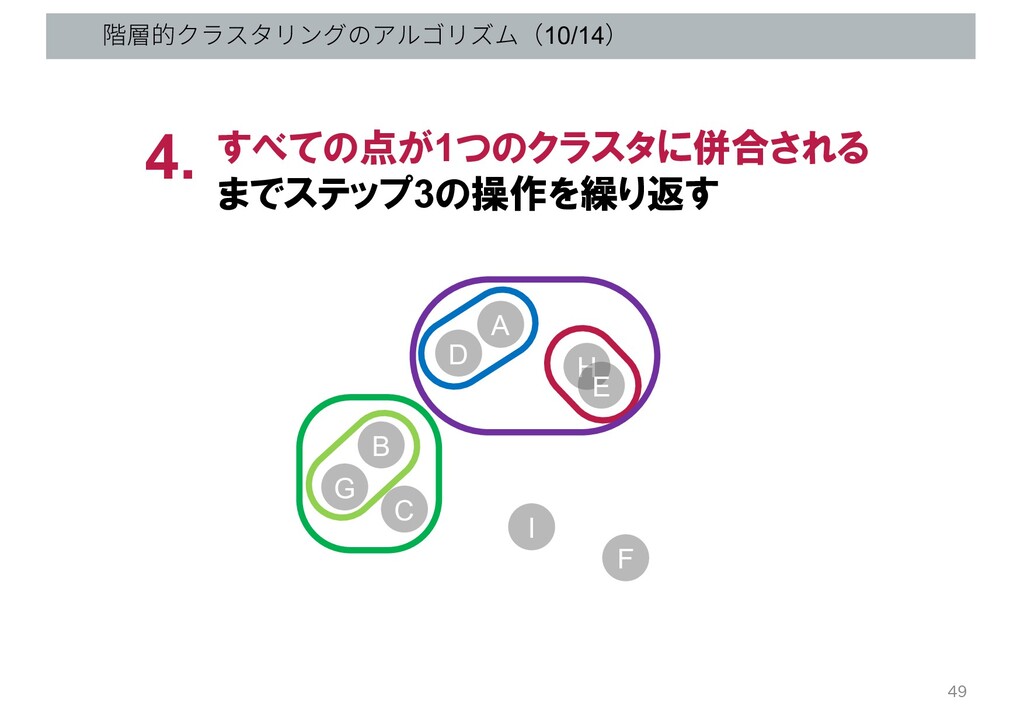
階層的クラスタリングのアルゴリズム(10/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 49
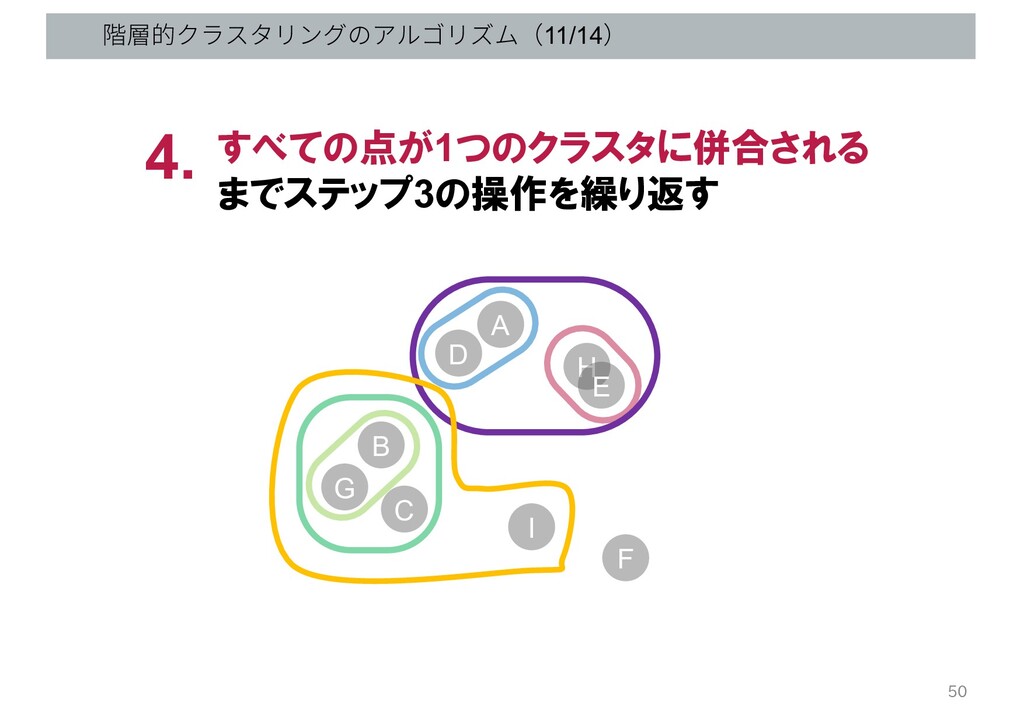
階層的クラスタリングのアルゴリズム(11/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 50
階層的クラスタリングのアルゴリズム(12/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 51
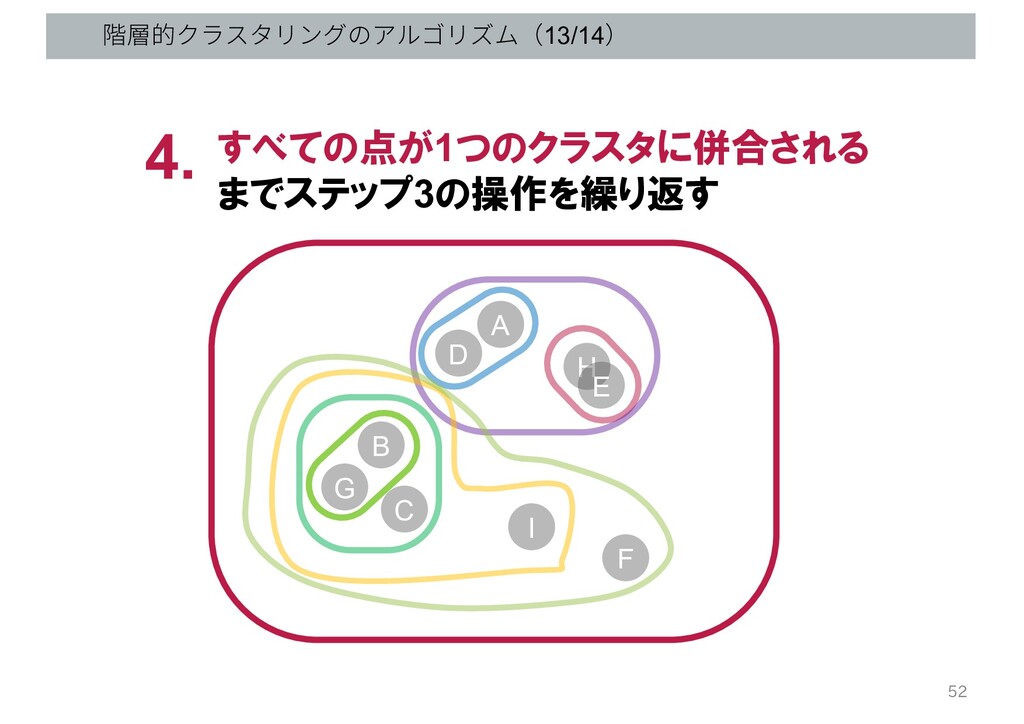
階層的クラスタリングのアルゴリズム(13/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 52
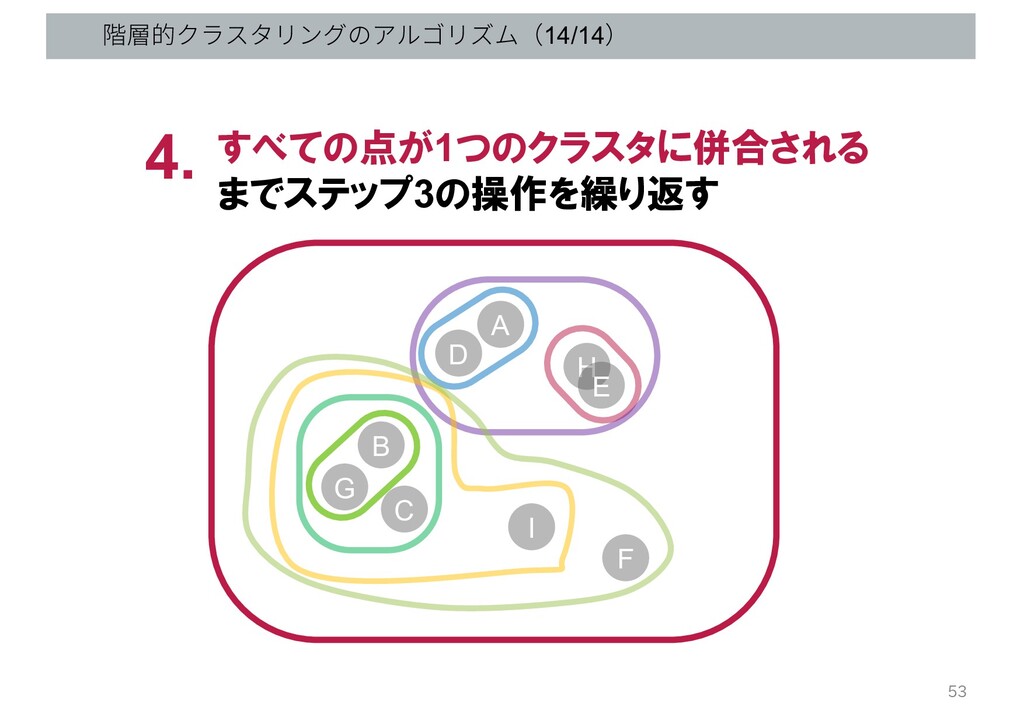
階層的クラスタリングのアルゴリズム(14/14) すべての点が1つのクラスタに併合される までステップ3の操作を繰り返す 4. G B C D A H
E I F 53
デンドログラム • クラスタが併合されていく様子を表した樹形図 • 適当な高さで木を切ることで,任意の数のクラスタを抽出可 A E H B D
G I C F 54
素朴な疑問1 クラスタ間の距離は どう計算(定義)するのか? Q. D A H E ? 55
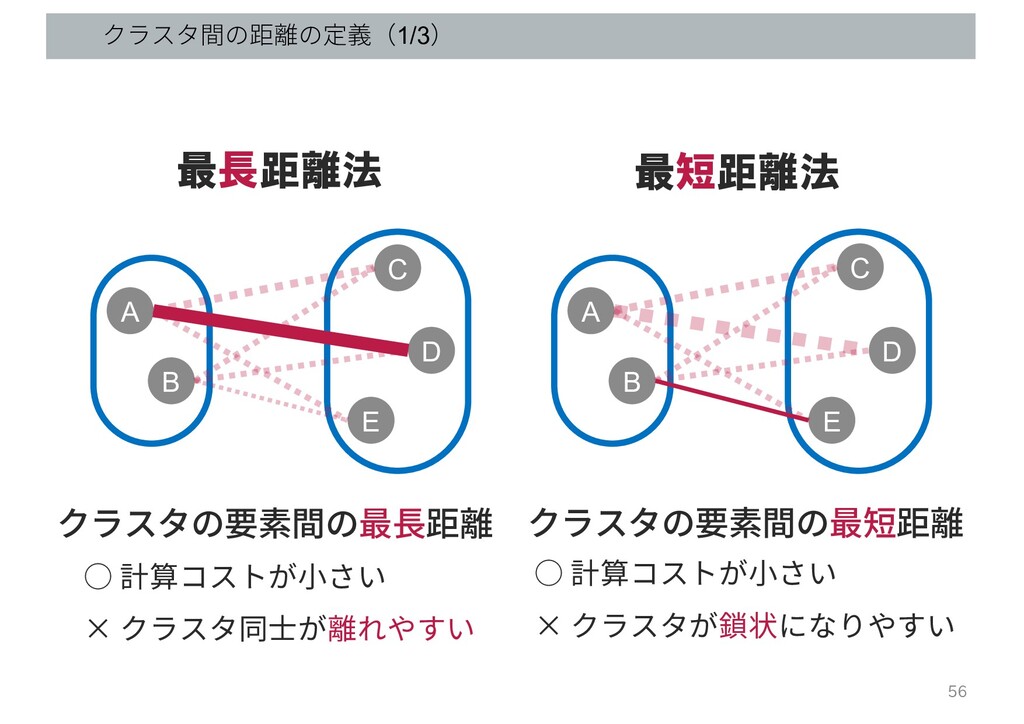
クラスタ間の距離の定義(1/3) 最長距離法 最短距離法 B A C D E B A
C D E クラスタの要素間の最⻑距離 クラスタの要素間の最短距離 ◦ 計算コストが⼩さい × クラスタ同⼠が離れやすい ◦ 計算コストが⼩さい × クラスタが鎖状になりやすい 56
クラスタ間の距離の定義(2/3) 重心法(セントロイド法) B A C D E クラスタの重⼼間の距離 × 計算コストが⼤きい
× 平均化により要素の散らばり情報が失われる × × 57
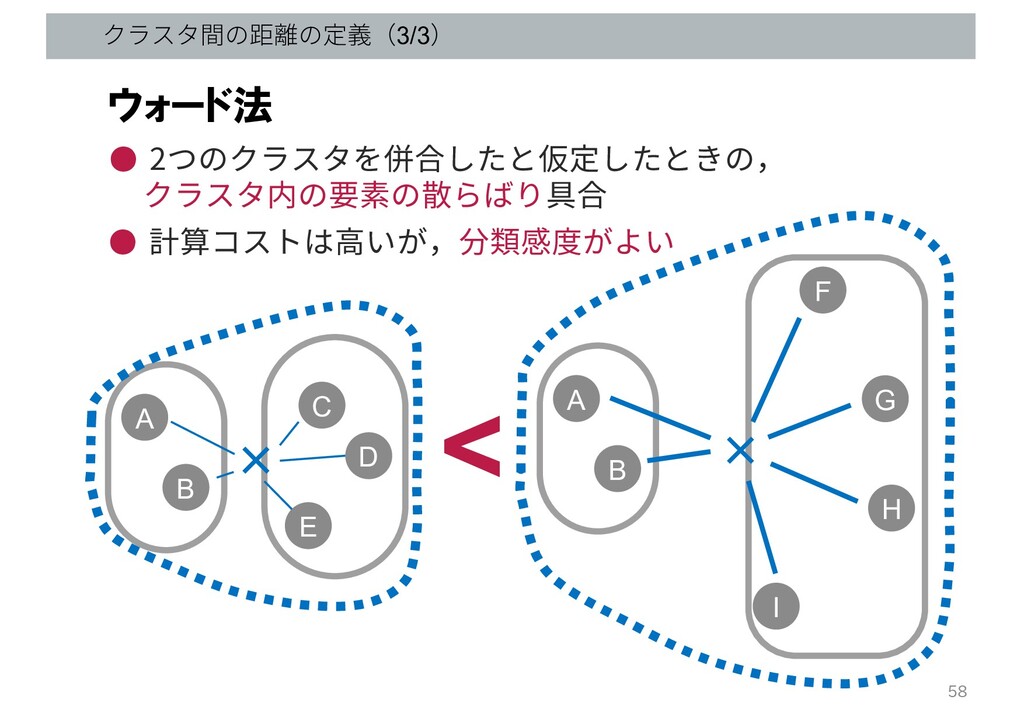
クラスタ間の距離の定義(3/3) B A C D E B A F G
I H ウォード法 • 2つのクラスタを併合したと仮定したときの, クラスタ内の要素の散らばり具合 < • 計算コストは⾼いが,分類感度がよい × × 58
素朴な疑問2 データ点の距離は どう計算(定義)するのか? Q. B A ? 59
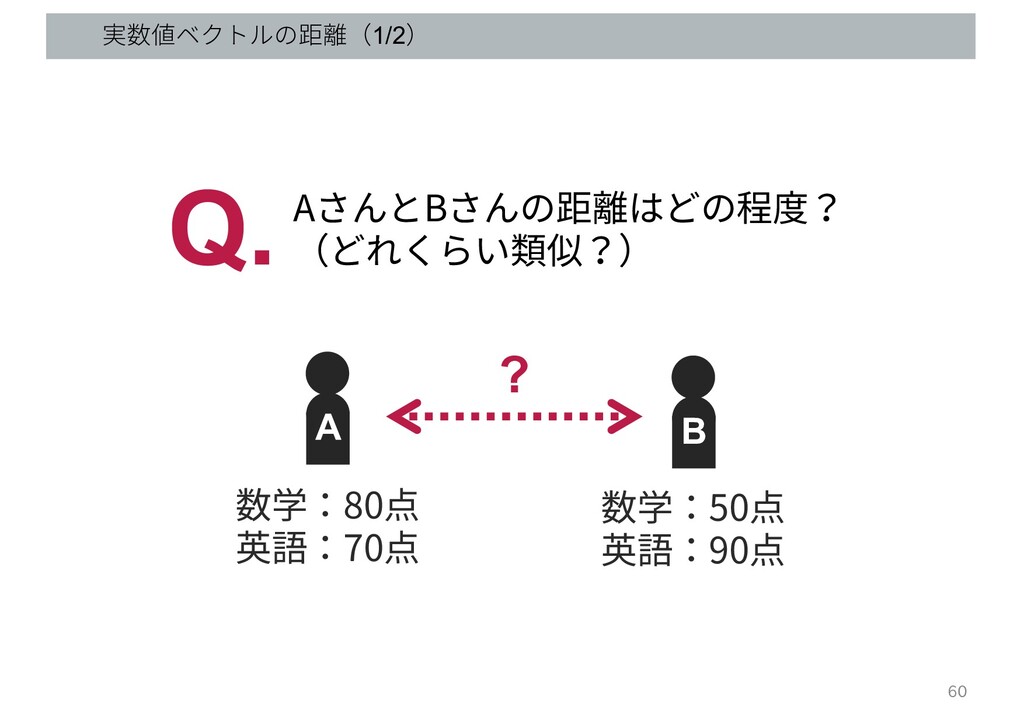
実数値ベクトルの距離(1/2) A B 数学:80点 英語:70点 数学:50点 英語:90点 AさんとBさんの距離はどの程度? (どれくらい類似?) Q.
? 60
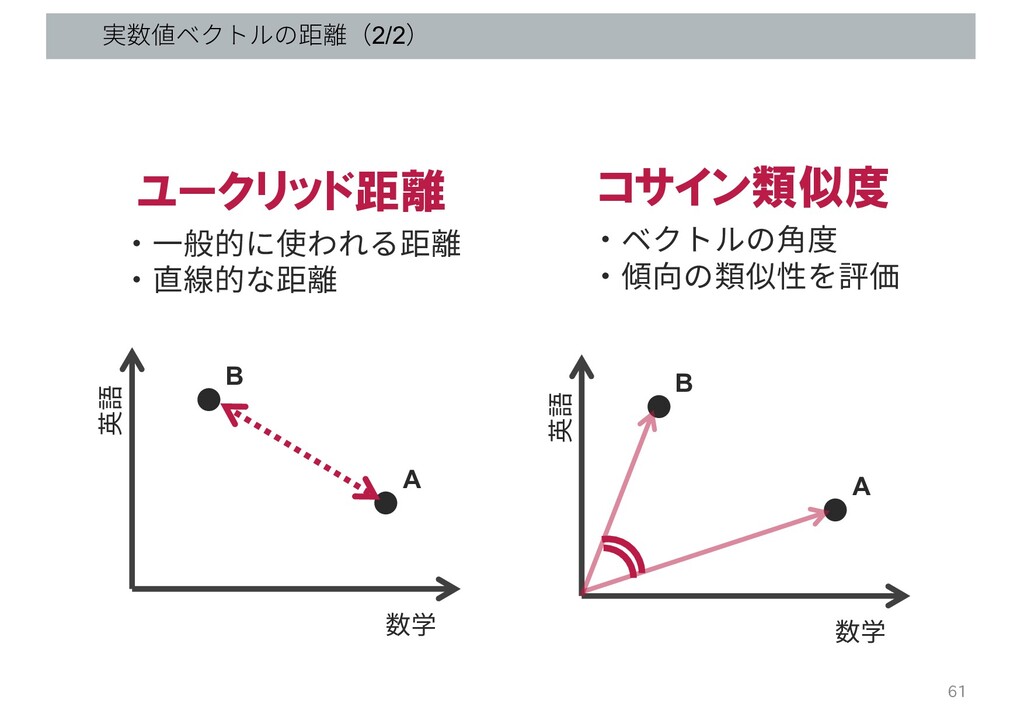
実数値ベクトルの距離(2/2) 数学 英語 • • A B 数学 英語 •
• A B ユークリッド距離 ・⼀般的に使われる距離 ・直線的な距離 コサイン類似度 ・ベクトルの⾓度 ・傾向の類似性を評価 61
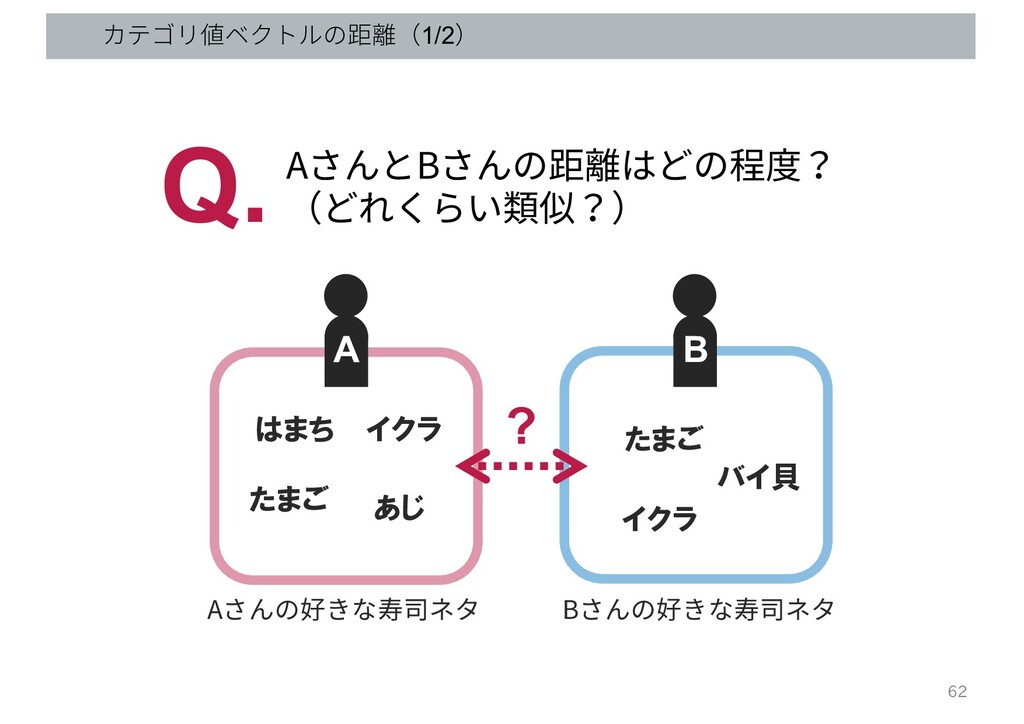
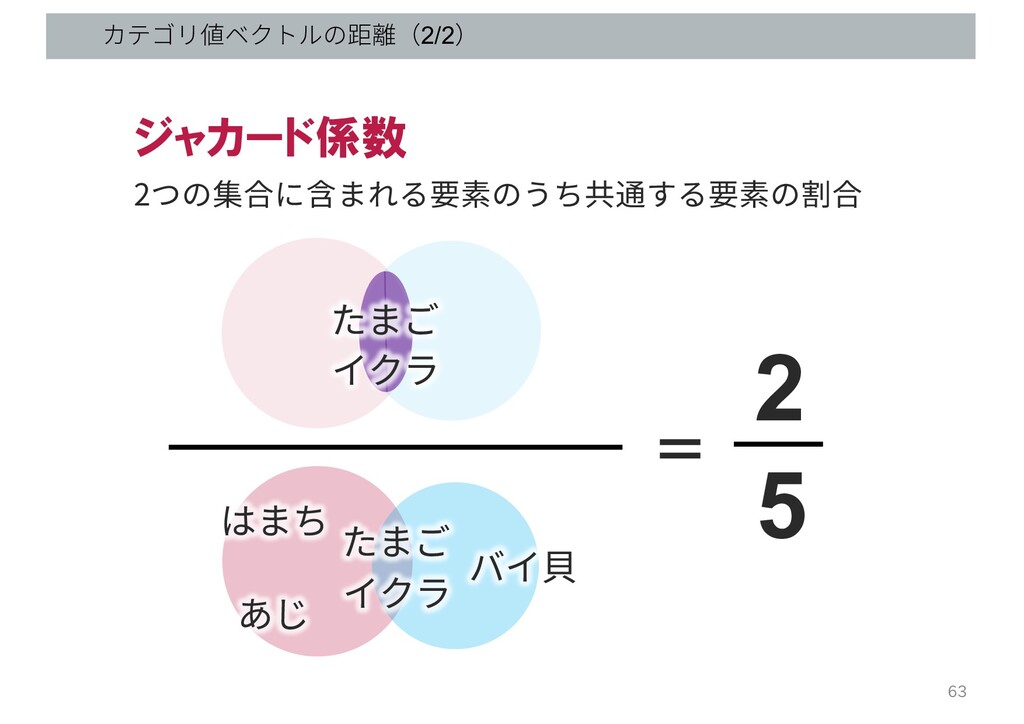
カテゴリ値ベクトルの距離(1/2) B AさんとBさんの距離はどの程度? (どれくらい類似?) Q. ? A Aさんの好きな寿司ネタ Bさんの好きな寿司ネタ はまち
あじ たまご イクラ たまご バイ貝 イクラ 62
カテゴリ値ベクトルの距離(2/2) ジャカード係数 2つの集合に含まれる要素のうち共通する要素の割合 たまご はまち イクラ たまご あじ バイ⾙ イクラ
= 5 2 63
Hands-on & 演習タイム 以下のURLにアクセスして, 階層的クラスタリングを体験しましょう https://b.hontolab.org/2TJd9jh 64
クラスタリング⼿法の⽐較 K-means 階層的クラスタリング ケース クラスタ数を指定してデー タを分割したい データが分割される様子を 確認したい クラスタ数の指定 Yes
No 計算量 ◦ △ クラスタの形状 超球状 超球状(クラスタ 距離の定義による) メリット 良い意味で単純 クラスタが作られる 様子が把握できる (デンドログラム) デメリット クラスタ数の指定が必要 データ数が多いと 解釈が難しい 65
より性能がよいクラスタリング⼿法 K-means X-means EMアルゴリズム クラスタ数指定なし & ⾼速化 • データが複数クラスタに属してもOK •
クラスタの形状を柔軟に 66
3 結果を予測するためのルールを構築 決定木から始める機械学習
AI! ⼈⼯知能! ディープラーニング!! ???? 画像出典:NHKスペシャル「AIに聞いてみた どうすんのよ!? ニッポン」 画像出典:https://www.amazon.co.jp/dp/B07JYYCG1D 68
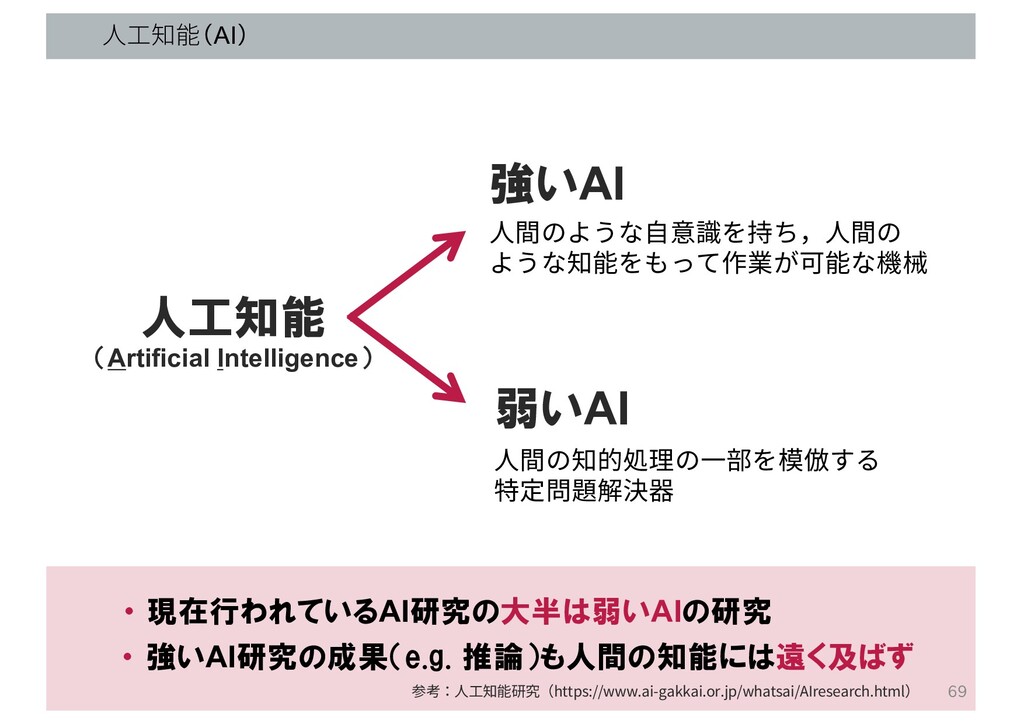
⼈⼯知能(AI) 人工知能 強いAI 弱いAI (Artificial Intelligence) ⼈間のような⾃意識を持ち,⼈間の ような知能をもって作業が可能な機械 ⼈間の知的処理の⼀部を模倣する 特定問題解決器
・ 現在行われているAI研究の大半は弱いAIの研究 参考:⼈⼯知能研究(https://www.ai-gakkai.or.jp/whatsai/AIresearch.html) ・ 強いAI研究の成果(e.g. 推論)も人間の知能には遠く及ばず 69
⼈⼯知能の研究トピック 人工知能 推論 探索 機械学習 知識表現 … 教師あり学習 教師なし学習 強化学習
・クラスタリング ・データ圧縮 ・分類 ・回帰 70
分類問題 画像出典:https://ja.wikipedia.org/wiki/ハタタテダイ 全長が25cmくらいで,長く伸びた白いヒレ. 白い体に2本の黒い帯.背びれが黄色い. この特徴がある魚は「ハタタテダイ」! 対象を分類する特徴を機械にどう学習させるか? 71
教師あり学習(1/2) ふぐ ブリ 鯛 鰹 大量のラベル付データ 機械学習 アルゴリズム ◦◦の識別に必要となる 特徴と分類ルール
画像出典: https://jp.mathworks.com/help/deeplearning/examples/visualize-features-of-a-convolutional-neural-network.html 全長が25cmくらいで, 長く伸びた白いヒレ. 白い体に2本の黒い帯. 背びれが黄色い. これは「ハタタテダイ」 大量のラベル(答え)付データを与えて ラベルを分類する特徴とルールを抽出(学習)する 72
教師あり学習(2/2) ふぐ ブリ 鯛 鰹 大量のラベル付データ 機械学習 アルゴリズム 画像出典: https://jp.mathworks.com/help/deeplearning/examples/visualize-features-of-a-convolutional-neural-network.html
大量のラベル(答え)付データを与えて ラベルを分類する特徴とルールを抽出(学習)する ⼈間が理解できる必要はない ◦◦の識別に必要となる 特徴と分類ルール 73
LINNE LENS 画像出典:https://global-square.com/blog/linne-lens_display_fish_info/ 74
75
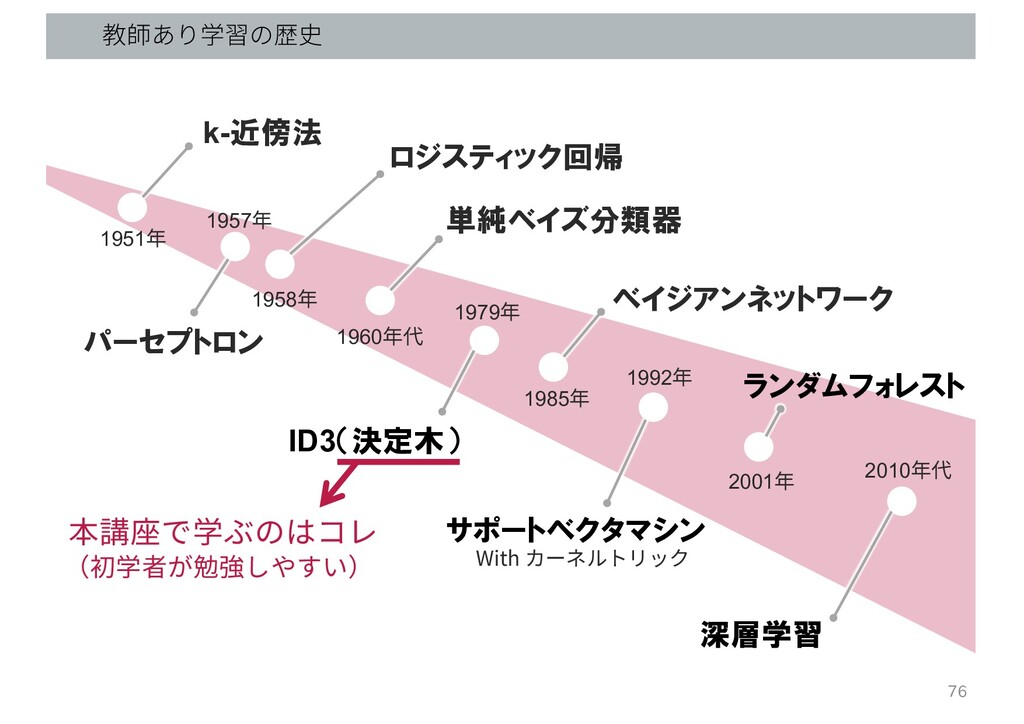
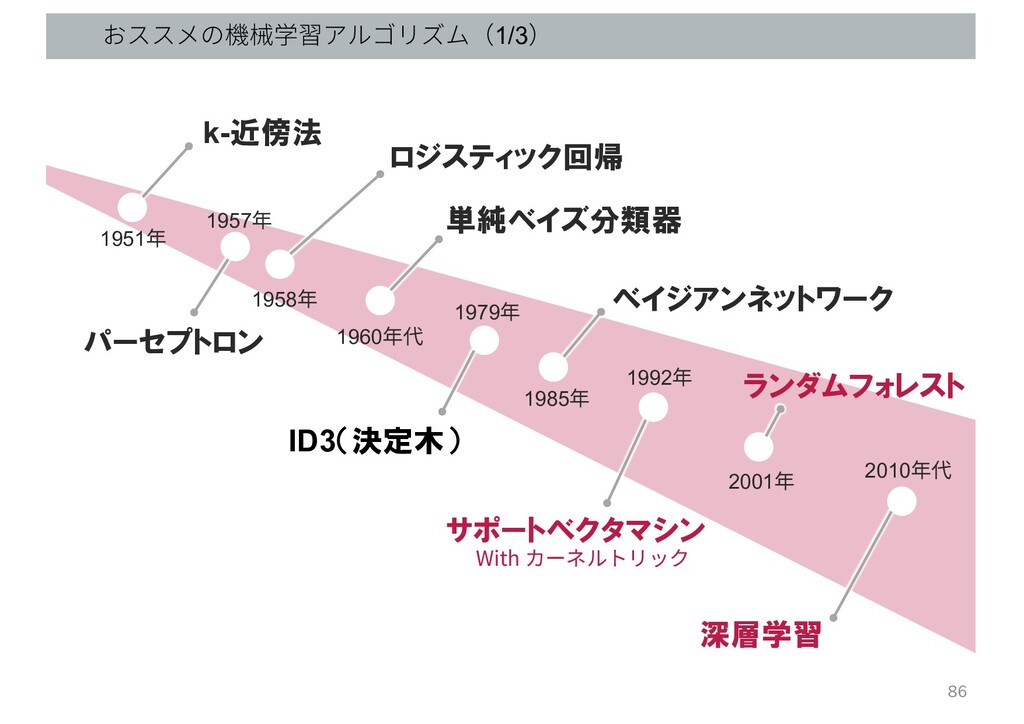
教師あり学習の歴史 ロジスティック回帰 サポートベクタマシン With カーネルトリック ID3(決定木) パーセプトロン 単純ベイズ分類器 ランダムフォレスト k-近傍法
ベイジアンネットワーク 深層学習 1958年 1957年 1951年 1979年 1985年 1992年 1960年代 2001年 2010年代 本講座で学ぶのはコレ (初学者が勉強しやすい) 76
決定⽊の概要 入力 分類ラベルのついた ベクトルの集合(表データ) 出力 ラベルを予測するための ルールを要約した⽊ 利用するケース 予測モデルに加えて, 分類ルールを確認したいとき
毒 柄色 柄形 臭い あり 紫 直線 あり なし 朱 末広 刺激 … … … … キノコの記録 毒キノコを分類するルールを抽出 臭い あり なし 柄の色が緑 yes no 毒あり1% 毒あり100% … 77
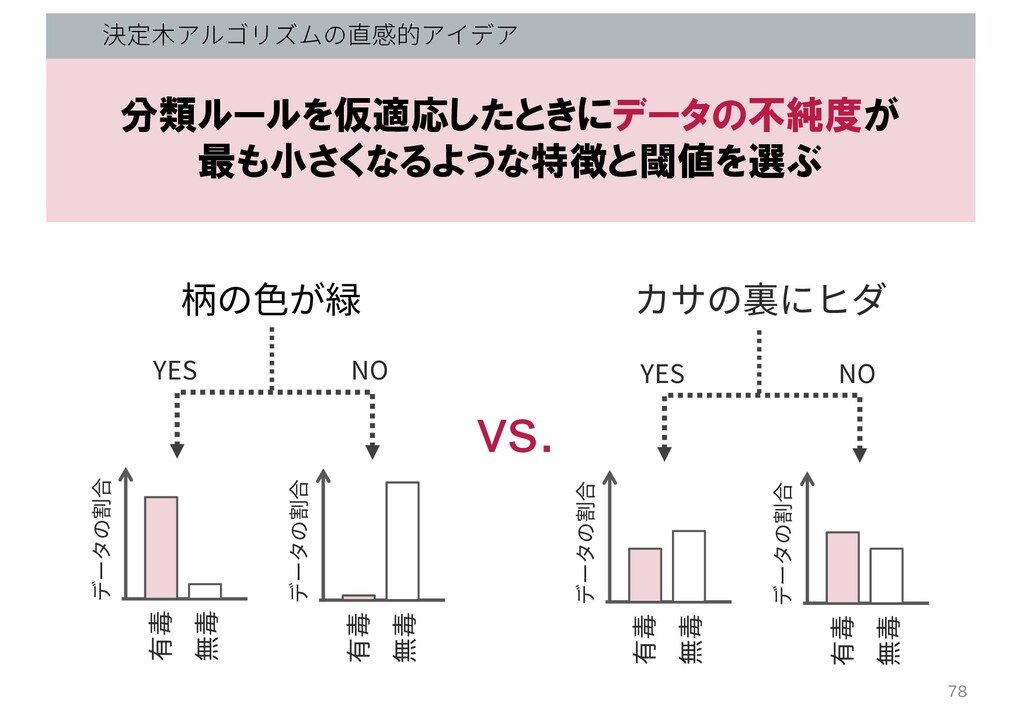
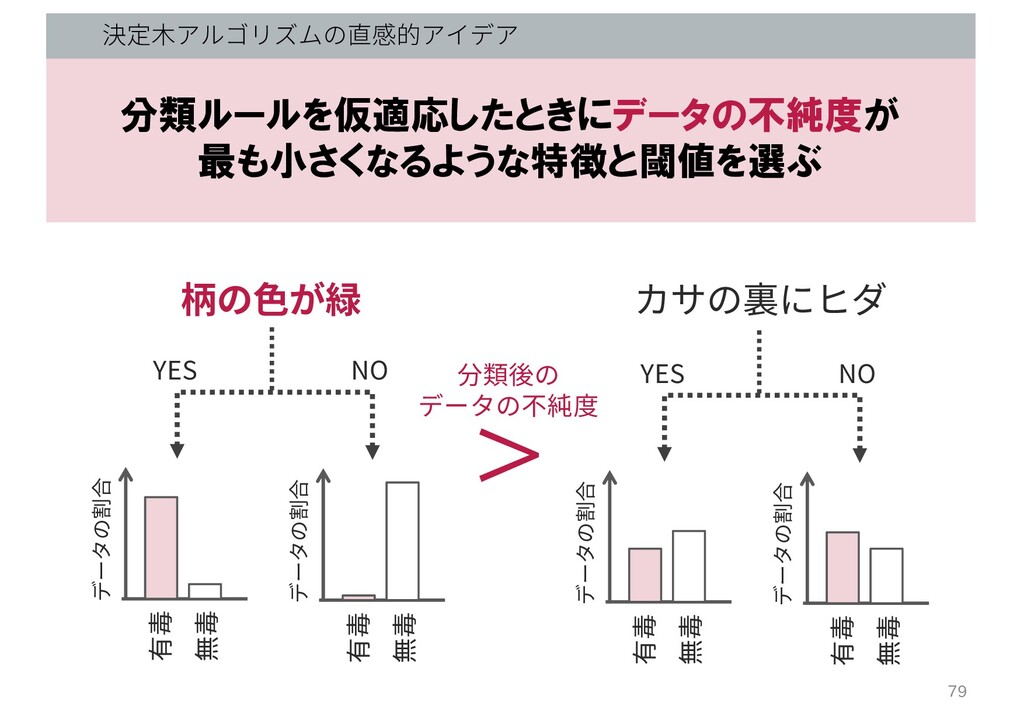
決定⽊アルゴリズムの直感的アイデア 分類ルールを仮適応したときにデータの不純度が 最も小さくなるような特徴と閾値を選ぶ 柄の⾊が緑 有毒 無毒 データの割合 有毒 無毒 データの割合
YES NO カサの裏にヒダ 有毒 無毒 データの割合 有毒 無毒 データの割合 YES NO vs. 78
決定⽊アルゴリズムの直感的アイデア 分類ルールを仮適応したときにデータの不純度が 最も小さくなるような特徴と閾値を選ぶ 柄の⾊が緑 有毒 無毒 データの割合 有毒 無毒 データの割合
YES NO カサの裏にヒダ 有毒 無毒 データの割合 有毒 無毒 データの割合 YES NO > 分類後の データの不純度 79
決定⽊のアルゴリズム 1. 3. ステップ2で選択したルールでデータを分割 2. 4. 5. 分割の必要がなくなったら終了 全データについて,各特徴による分割パターン をすべて調査
データの不純度にもとづき,最適な分割ルール をひとつ選択 分割されたデータ群に対して,上記⼿順を 繰り返し適⽤ 80
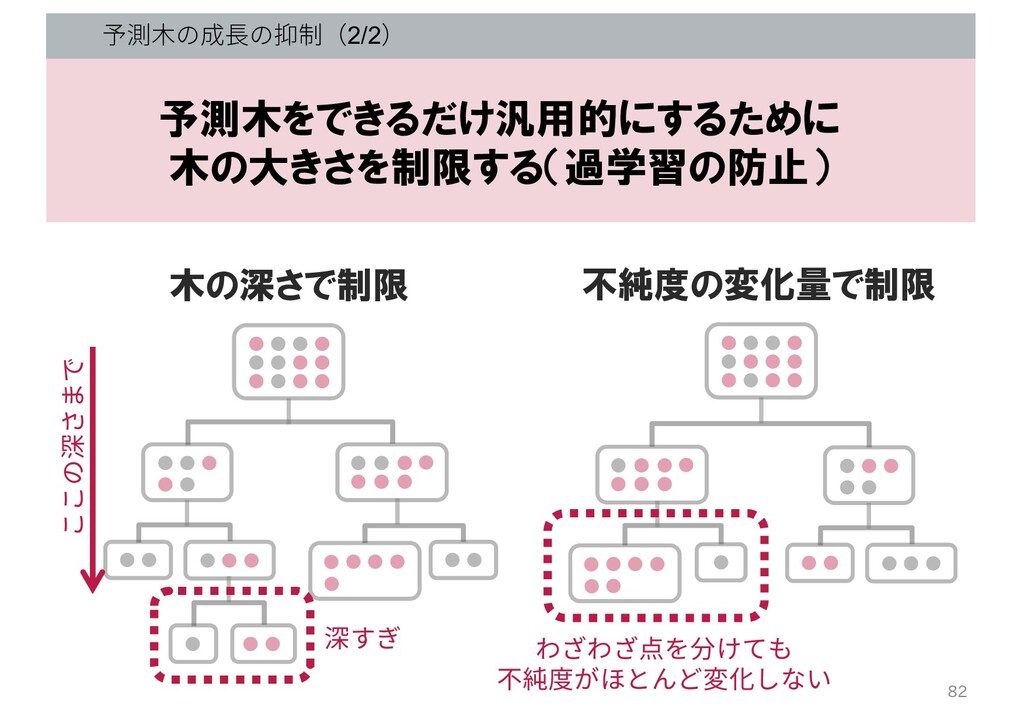
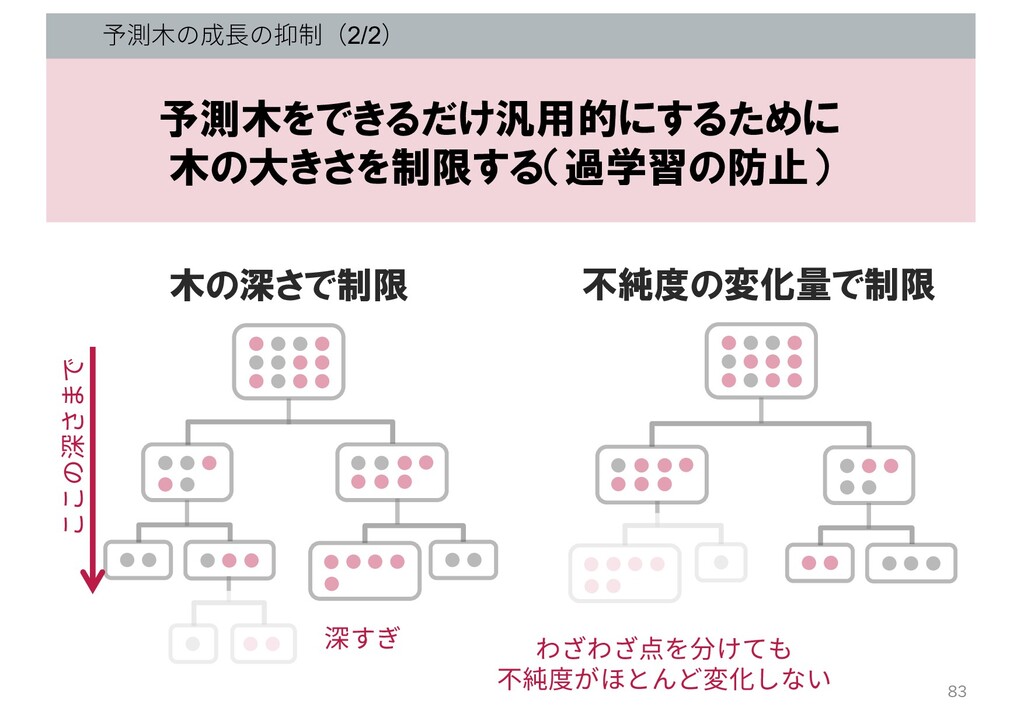
予測⽊の成⻑の抑制(1/2) 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) • ⽊の葉っぱに含まれているデータの数 • 不純度の変化量 • ⽊の深さ •
⽊の葉っぱでの誤り率 81
予測⽊の成⻑の抑制(2/2) ここの深さまで 木の深さで制限 わざわざ点を分けても 不純度がほとんど変化しない 深すぎ 不純度の変化量で制限 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) 82
予測⽊の成⻑の抑制(2/2) ここの深さまで 木の深さで制限 不純度の変化量で制限 わざわざ点を分けても 不純度がほとんど変化しない 深すぎ 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) 83
Hands-on & 演習タイム 以下のURLにアクセスして, 決定木による教師あり学習を体験しましょう https://b.hontolab.org/3oMqm9b 84
機械学習の精度を⾼めるポイント 良質なデータ 学習データがゴミなら結果もゴミ データクリーニング データには⽋損しているものや不正なものが含まれるものしばしば データ変換 データの形式,単位,散らばり具合を考慮したデータ補正が重要 パラメータチューニング アルゴリズムの性能を最⼤限引き出すには,調整が必要 適切な手法の選択
データの性質を考慮した適切な学習アルゴリズムを選択すべし 85
おススメの機械学習アルゴリズム(1/3) ロジスティック回帰 サポートベクタマシン With カーネルトリック ID3(決定木) パーセプトロン 単純ベイズ分類器 ランダムフォレスト k-近傍法
ベイジアンネットワーク 深層学習 1958年 1957年 1951年 1979年 1985年 1992年 1960年代 2001年 2010年代 86
おススメの機械学習アルゴリズム(2/3) Q. ある程度データがあり,⼿軽に精度よく予測したい!! A. ランダムフォレスト Q. どんな特徴量が予測に効いているのか知りたい!! A. ランダムフォレスト 87
おススメの機械学習アルゴリズム(3/3) Q. 超⼤量にデータはあり,可能な限り精度を出したい!! A. ディープラーニング (計算資源と計算時間が必要) Q. データ数が少ないが,精度よく予測したい!! A. サポートベクターマシン
(パラメータチューニングが必要) これらの方針は絶対ではないので, データ特性をふまえて手法を選択する必要あり 88
4 未来に影響する要因を明らかにする 時系列分析
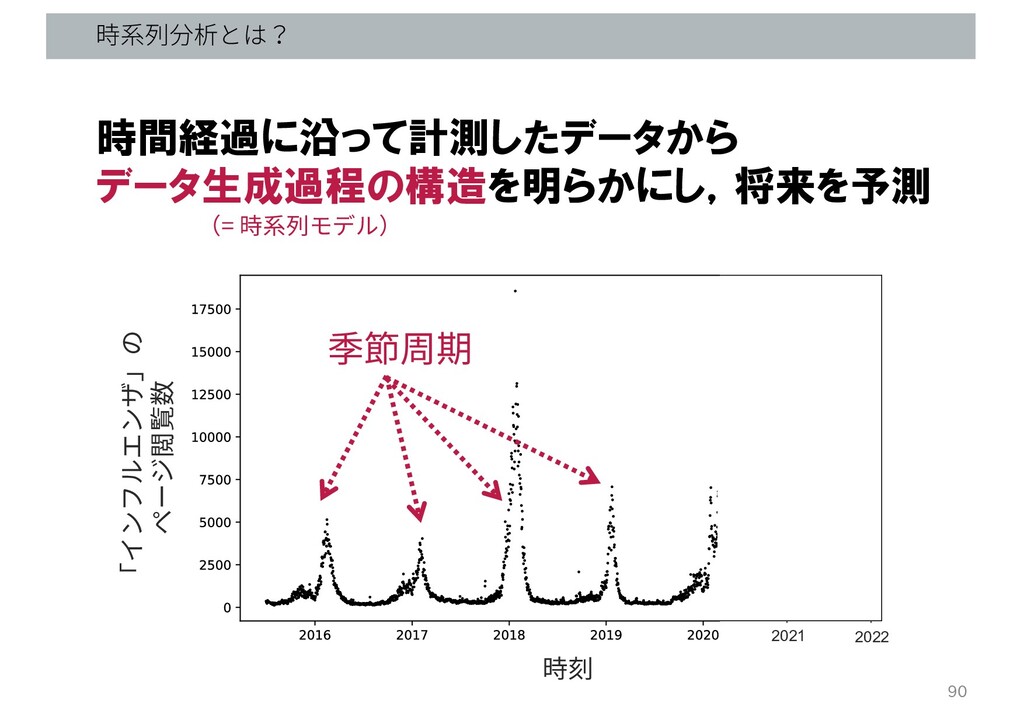
時刻 「インフルエンザ」の ページ閲覧数 2021 2022 時系列分析とは? 90 時間経過に沿って計測したデータから データ生成過程の構造を明らかにし,将来を予測 季節周期
(= 時系列モデル)
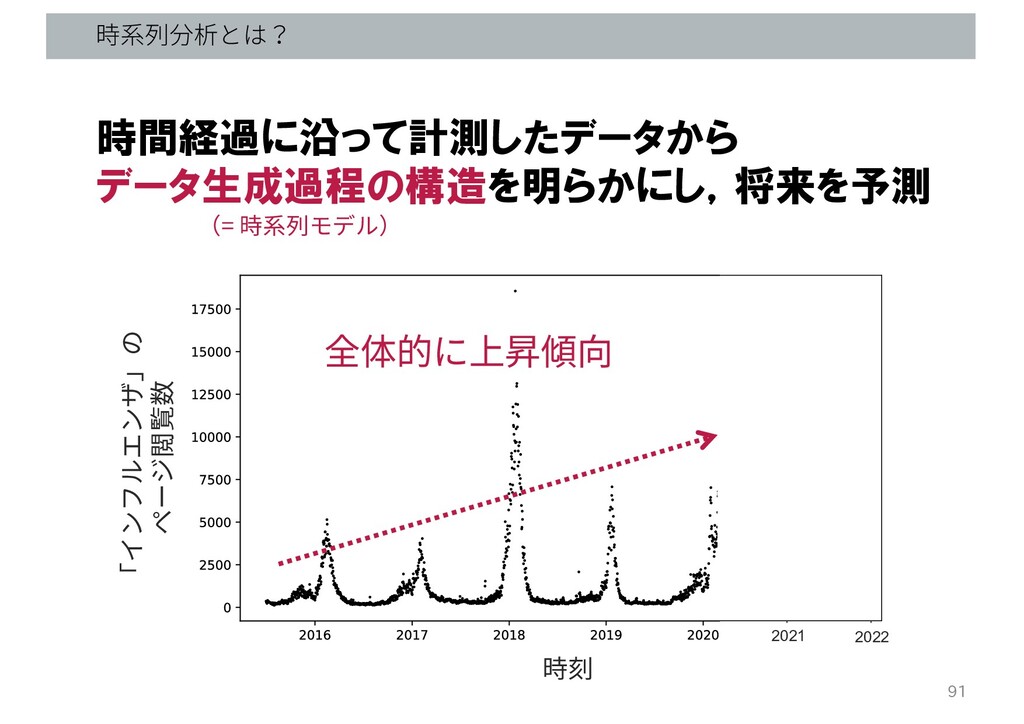
時刻 「インフルエンザ」の ページ閲覧数 2021 2022 時系列分析とは? 91 時間経過に沿って計測したデータから データ生成過程の構造を明らかにし,将来を予測 全体的に上昇傾向
(= 時系列モデル)
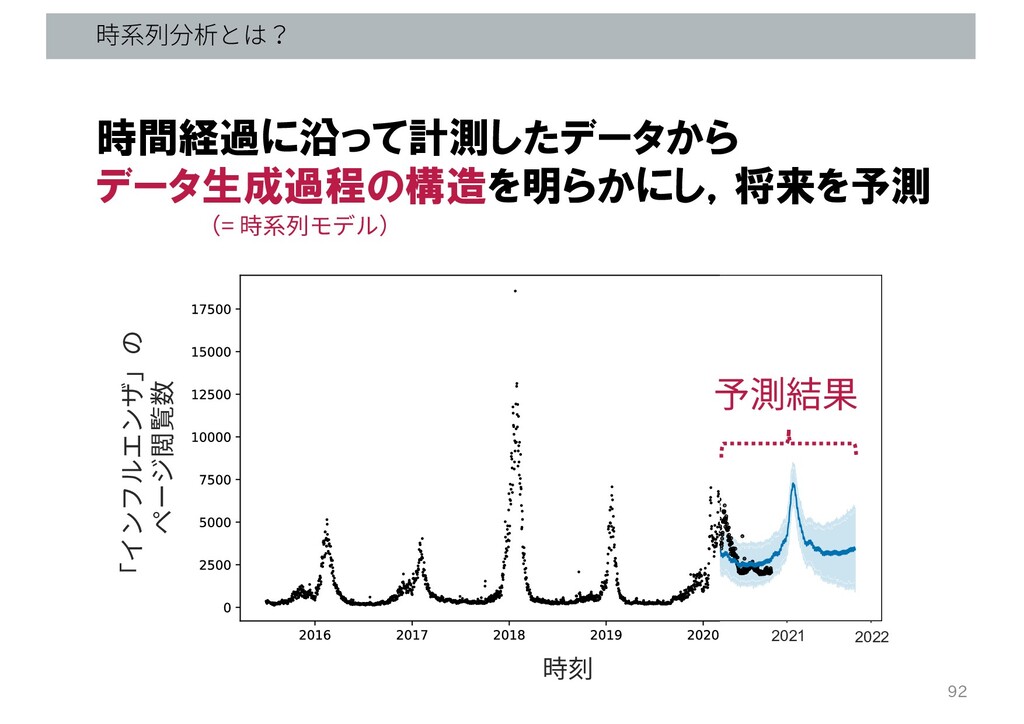
時系列分析とは? 92 時間経過に沿って計測したデータから データ生成過程の構造を明らかにし,将来を予測 時刻 「インフルエンザ」の ページ閲覧数 2021 2022 予測結果
(= 時系列モデル)
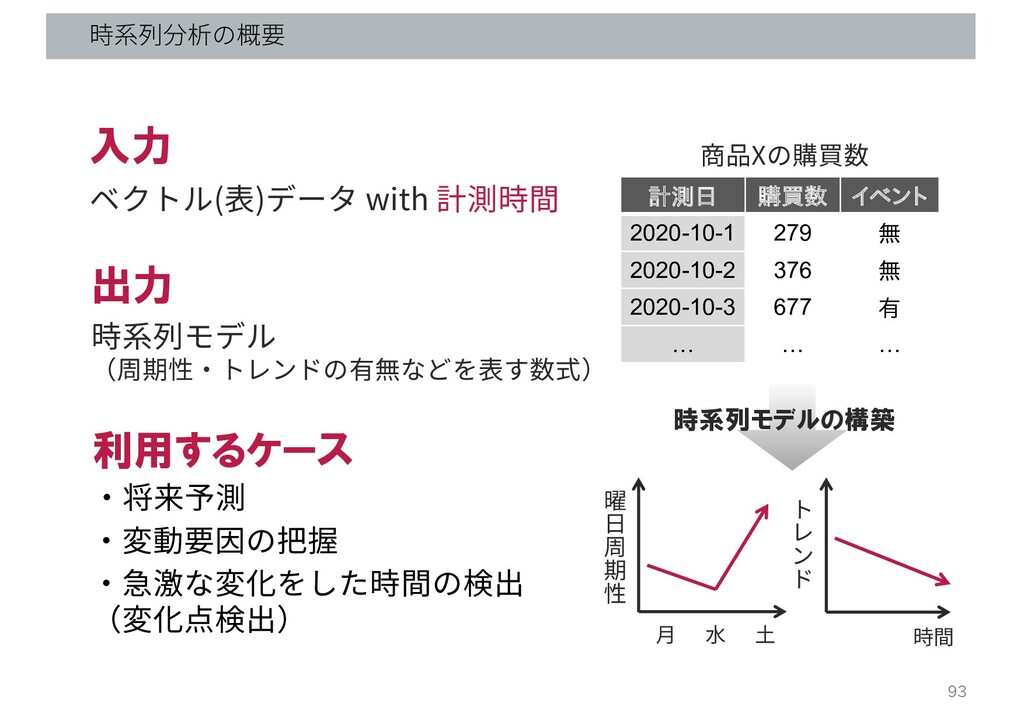
時系列分析の概要 入力 ベクトル(表)データ with 計測時間 出力 時系列モデル (周期性・トレンドの有無などを表す数式) 利用するケース 時系列モデルの構築
・将来予測 ・急激な変化をした時間の検出 (変化点検出) 93 ・変動要因の把握 計測日 購買数 イベント 2020-10-1 279 無 2020-10-2 376 無 2020-10-3 677 有 … … … 商品Xの購買数 時間 ⽉ 曜 ⽇ 周 期 性 ⽔ ⼟
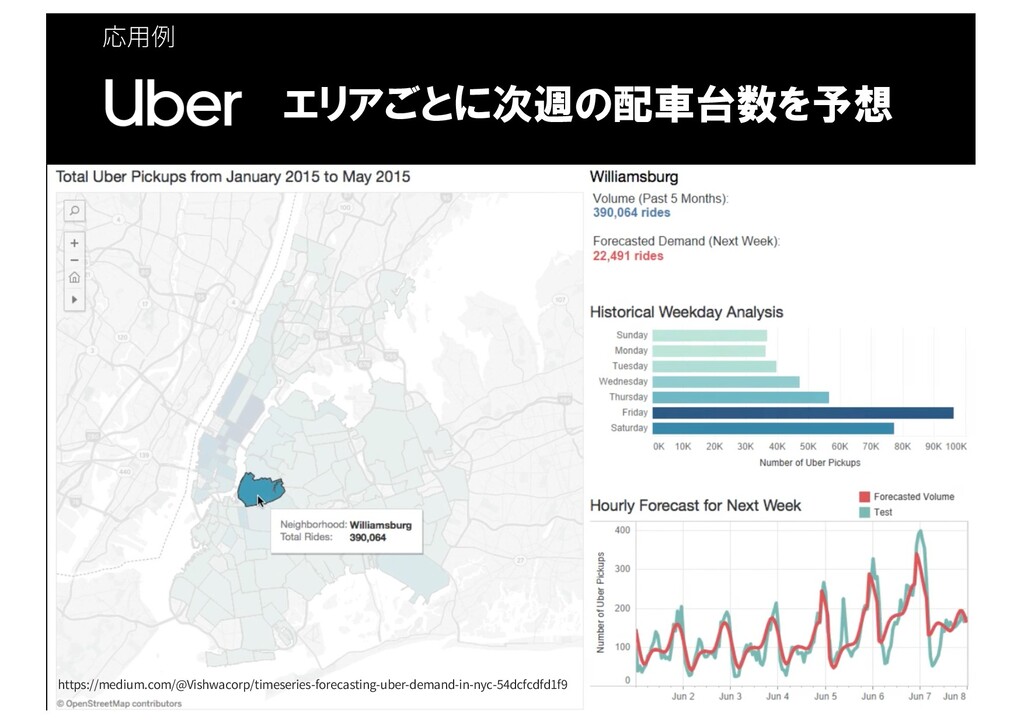
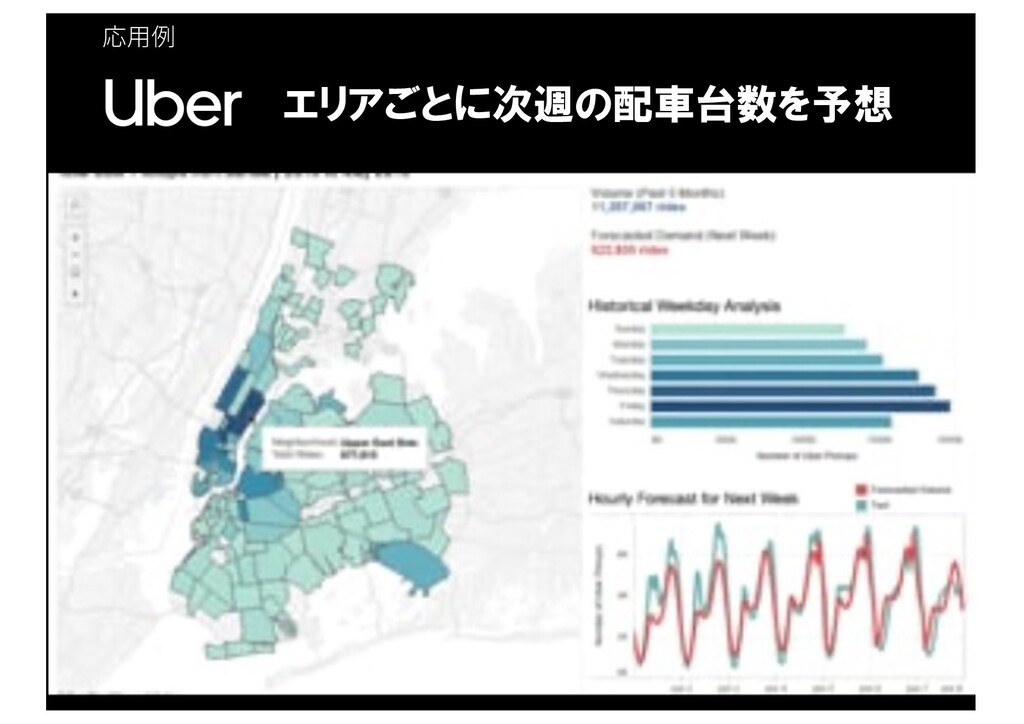
応⽤例 94 エリアごとに次週の配車台数を予想 https://medium.com/@Vishwacorp/timeseries-forecasting-uber-demand-in-nyc-54dcfcdfd1f9
応⽤例 95 エリアごとに次週の配車台数を予想 https://medium.com/@Vishwacorp/timeseries-forecasting-uber-demand-in-nyc-54dcfcdfd1f9
回帰分析(1/2) 96 平均歩数/⽇ 寿命 寿命 = a × 平均歩数 +
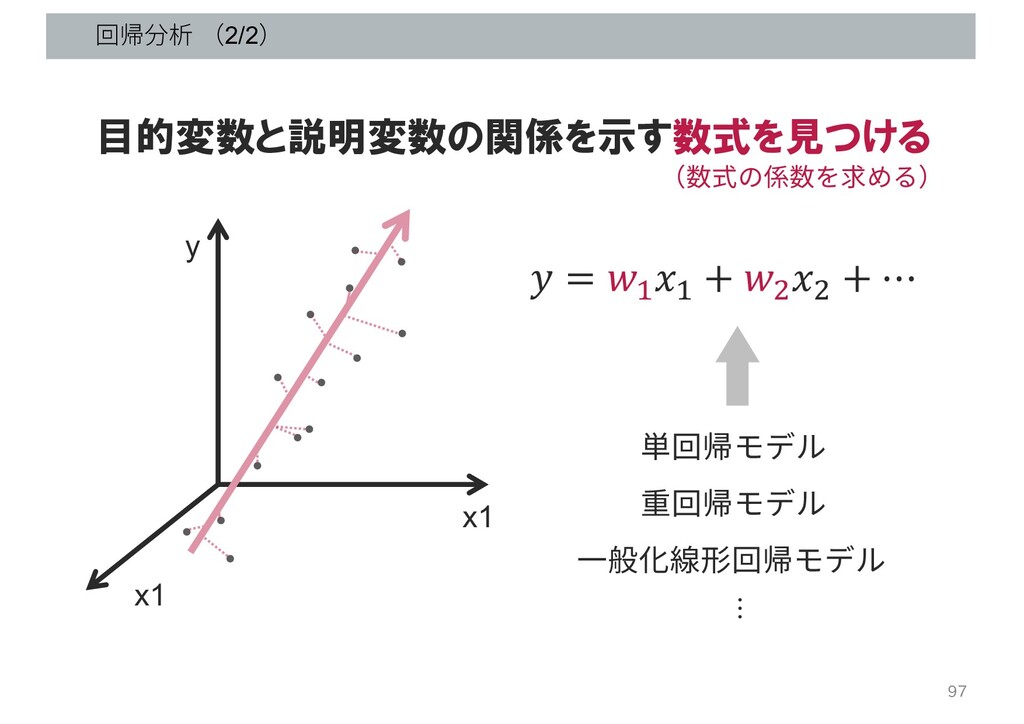
b 説明変数 ⽬的変数 目的変数と説明変数の関係を示す数式を見つける モデル
回帰分析 (2/2) 97 x1 y = ! ! + "
" + ⋯ 単回帰モデル (数式の係数を求める) 目的変数と説明変数の関係を示す数式を見つける x1 重回帰モデル ⼀般化線形回帰モデル …
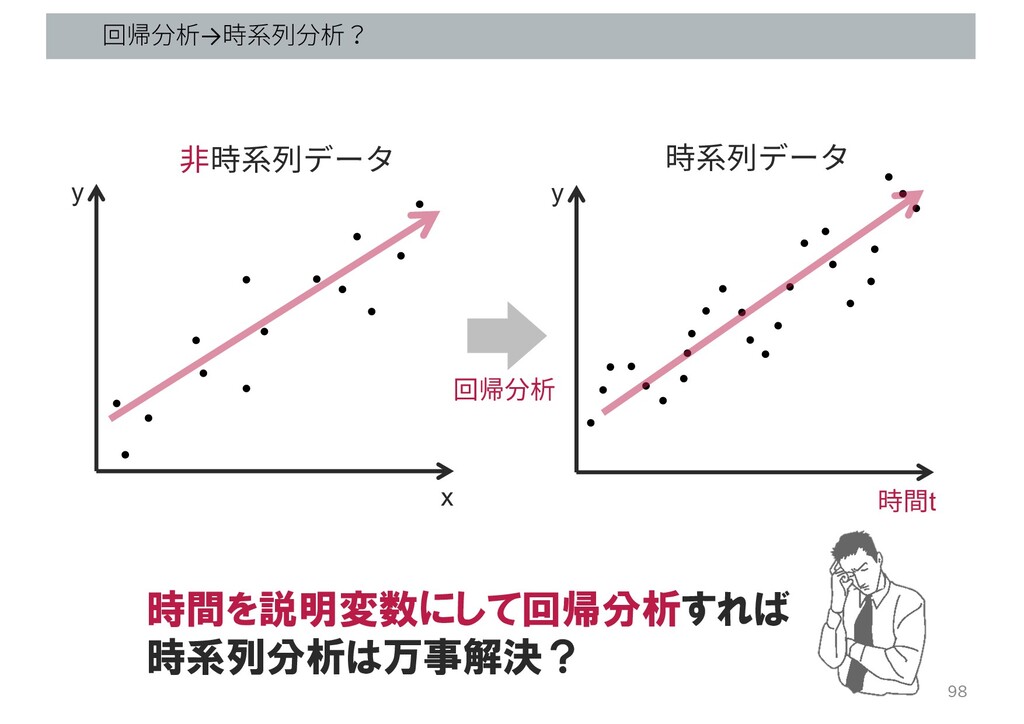
回帰分析→時系列分析? 98 x y 時間t y 回帰分析 ⾮時系列データ 時系列データ 時間を説明変数にして回帰分析すれば
時系列分析は万事解決?
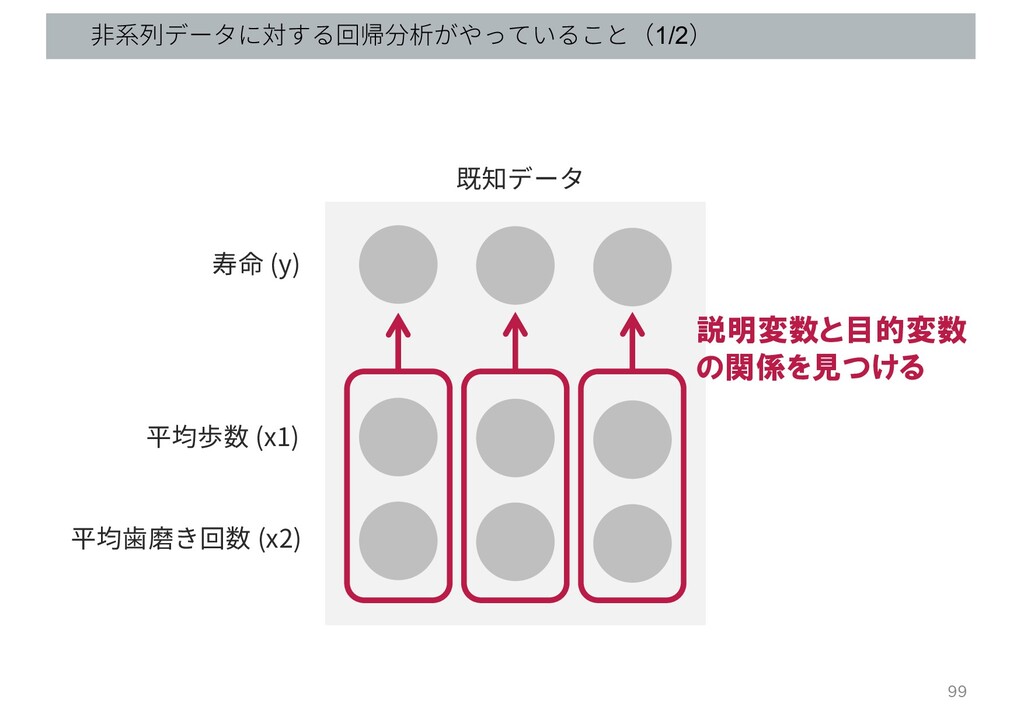
⾮系列データに対する回帰分析がやっていること(1/2) 99 寿命 (y) 平均歩数 (x1) 平均⻭磨き回数 (x2) 既知データ 説明変数と目的変数
の関係を見つける
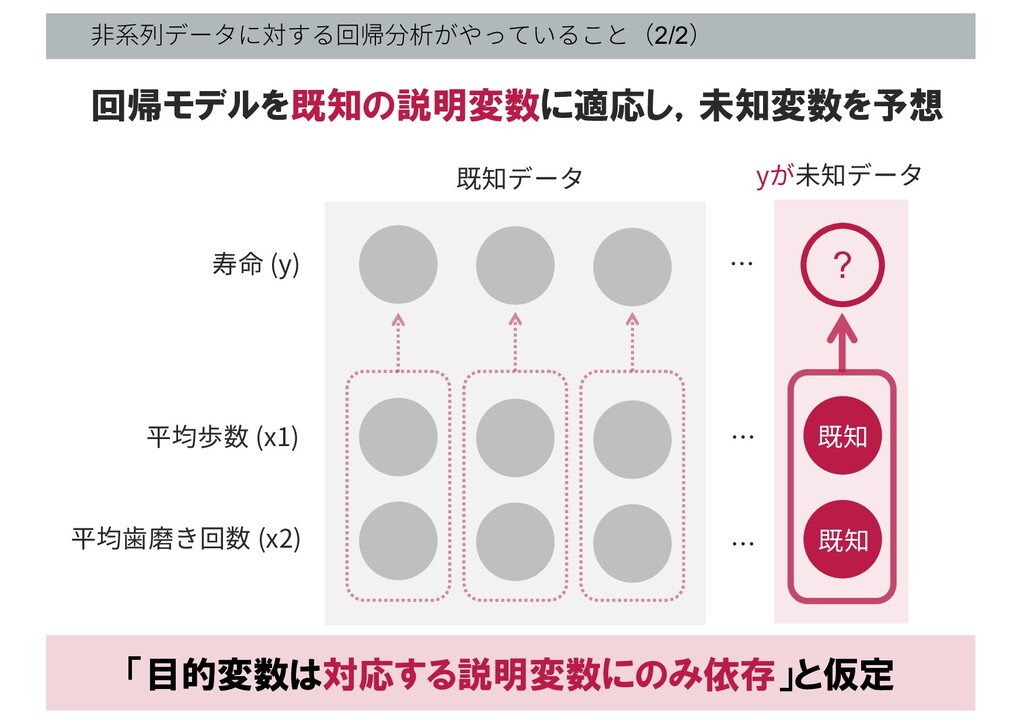
⾮系列データに対する回帰分析がやっていること(2/2) 100 … ? … … yが未知データ 寿命 (y) 平均歩数
(x1) 平均⻭磨き回数 (x2) 既知データ 既知 既知 回帰モデルを既知の説明変数に適応し,未知変数を予想 「目的変数は対応する説明変数にのみ依存」と仮定
時系列データの背後にあるルール 101 株価 (y) TV出演の有無(x) 既知データ 時刻(t) ある時刻の目的変数は「過去の状態」にも依存
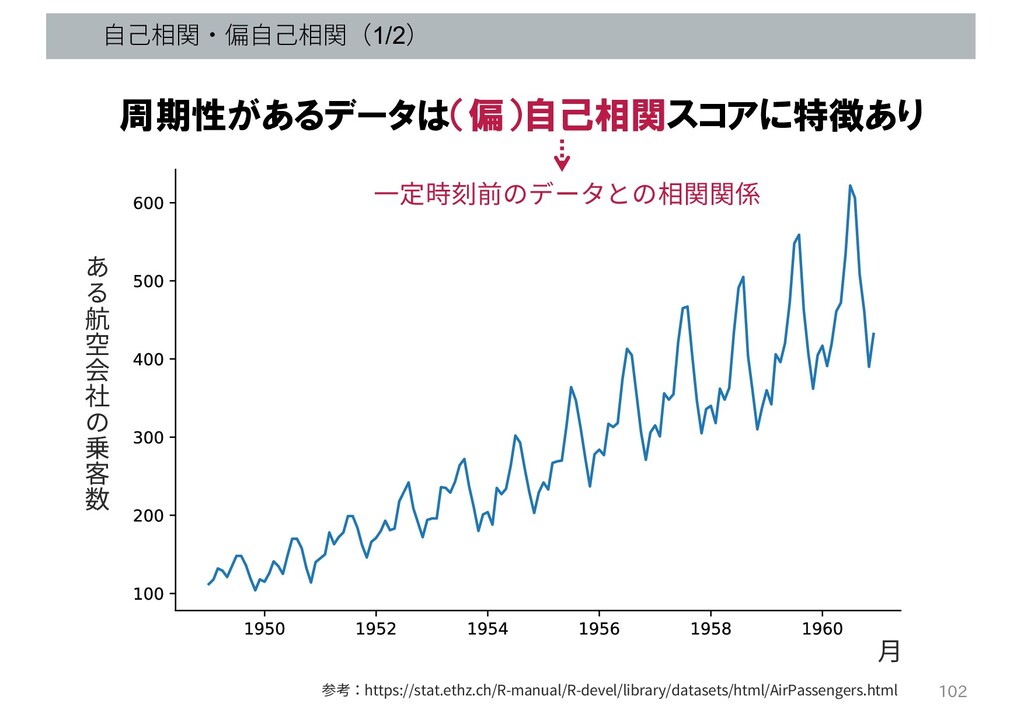
⾃⼰相関・偏⾃⼰相関(1/2) 102 航 空 会 社 乗 客 数 ⽉
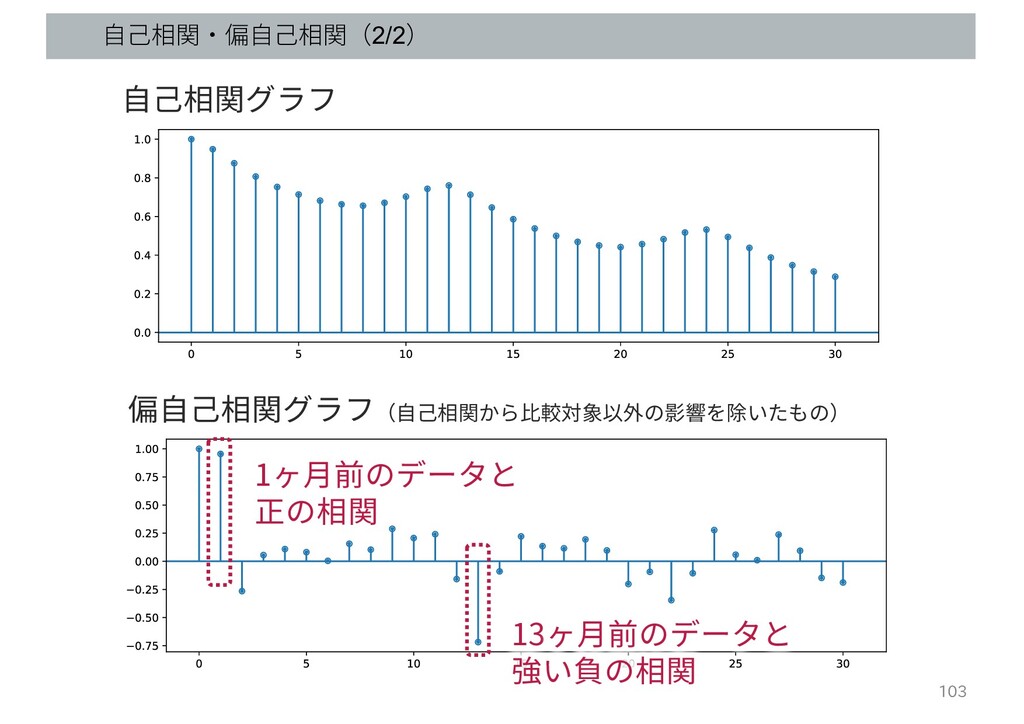
周期性があるデータは(偏)自己相関スコアに特徴あり ⼀定時刻前のデータとの相関関係 参考:https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/AirPassengers.html
⾃⼰相関・偏⾃⼰相関(2/2) 103 ⾃⼰相関グラフ 偏⾃⼰相関グラフ(⾃⼰相関から⽐較対象以外の影響を除いたもの) 1ヶ⽉前のデータと 正の相関 13ヶ⽉前のデータと 強い負の相関
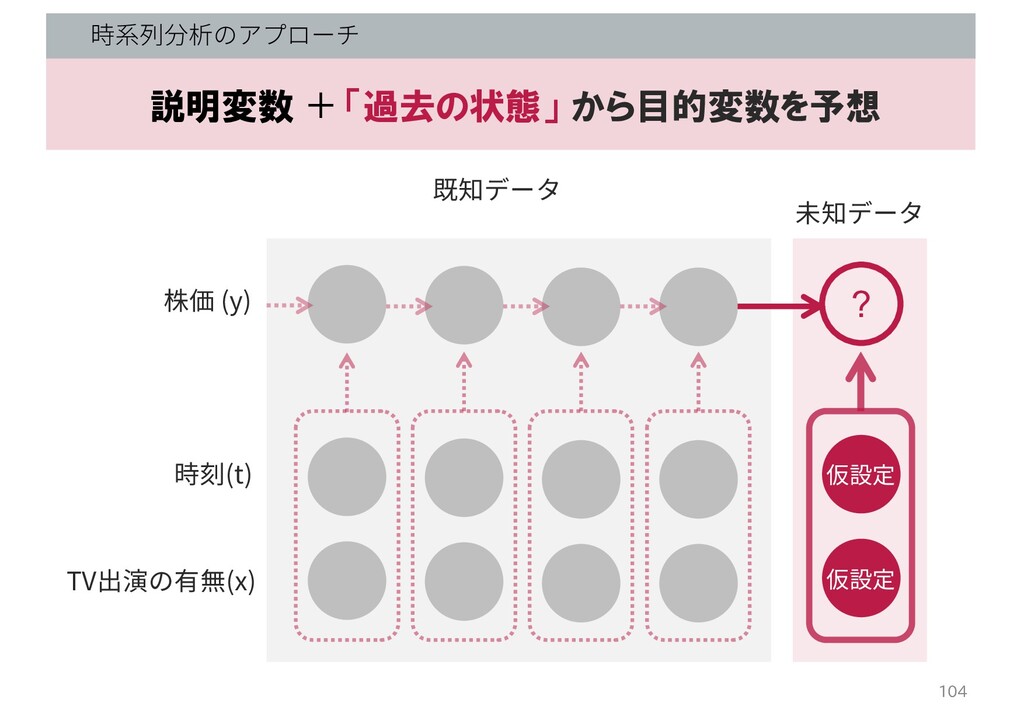
時系列分析のアプローチ 104 株価 (y) TV出演の有無(x) 既知データ 時刻(t) 説明変数 + 「過去の状態」
から目的変数を予想 ? 未知データ 仮設定 仮設定
時系列データの構造 105 時系列データ = 周期性 トレンド 外因性 + + +
ノイズ
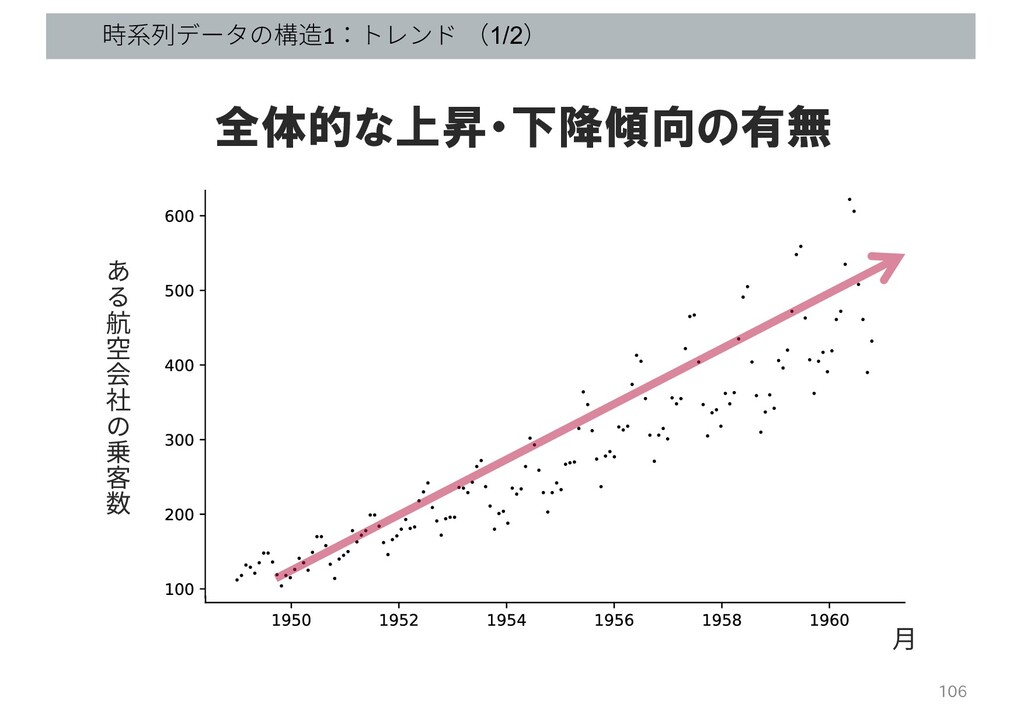
時系列データの構造1:トレンド (1/2) 106 航 空 会 社 乗 客 数
⽉ 全体的な上昇・下降傾向の有無
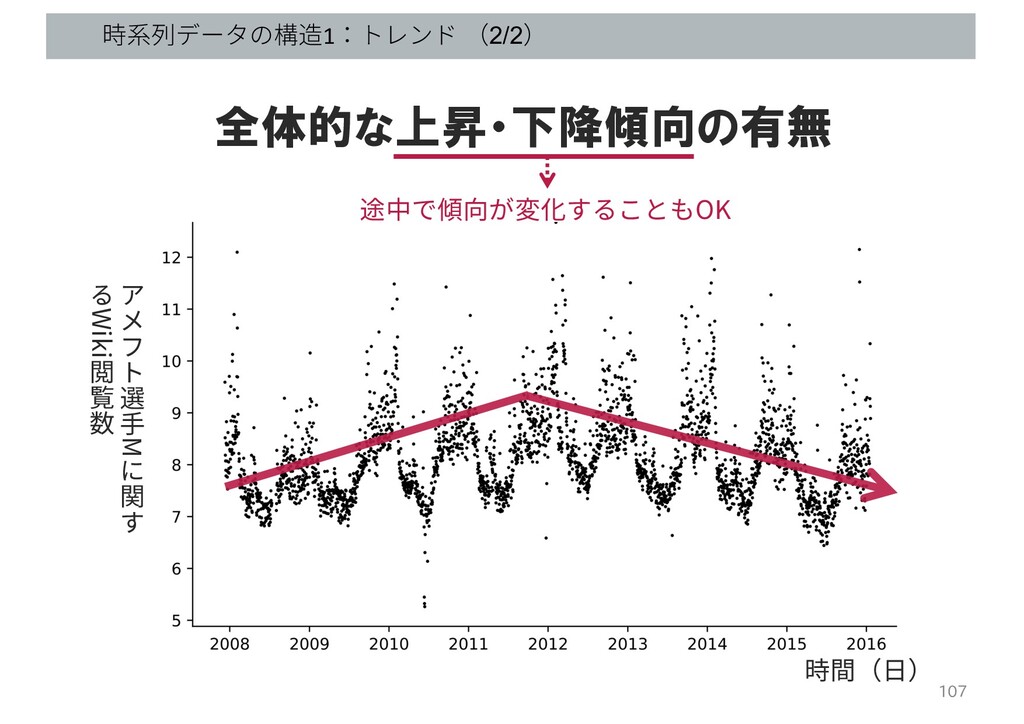
時系列データの構造1:トレンド (2/2) 107 選 ⼿ M 関 Wiki 閲 覧
数 時間(⽇) 全体的な上昇・下降傾向の有無 途中で傾向が変化することもOK
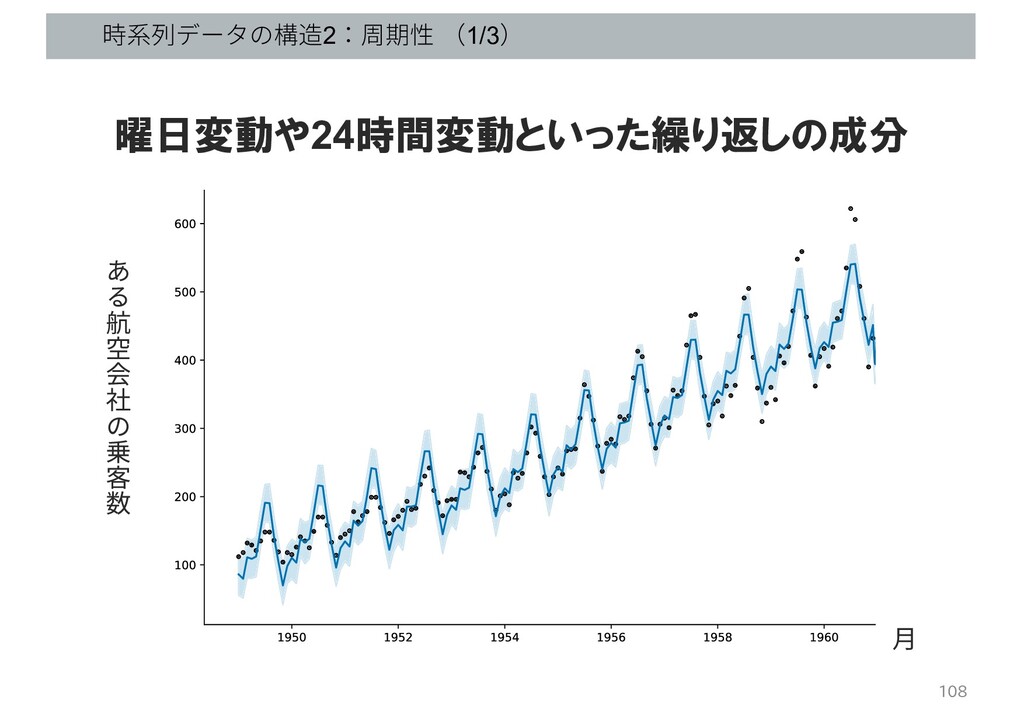
時系列データの構造2:周期性 (1/3) 108 航 空 会 社 乗 客 数
⽉ 曜日変動や24時間変動といった繰り返しの成分
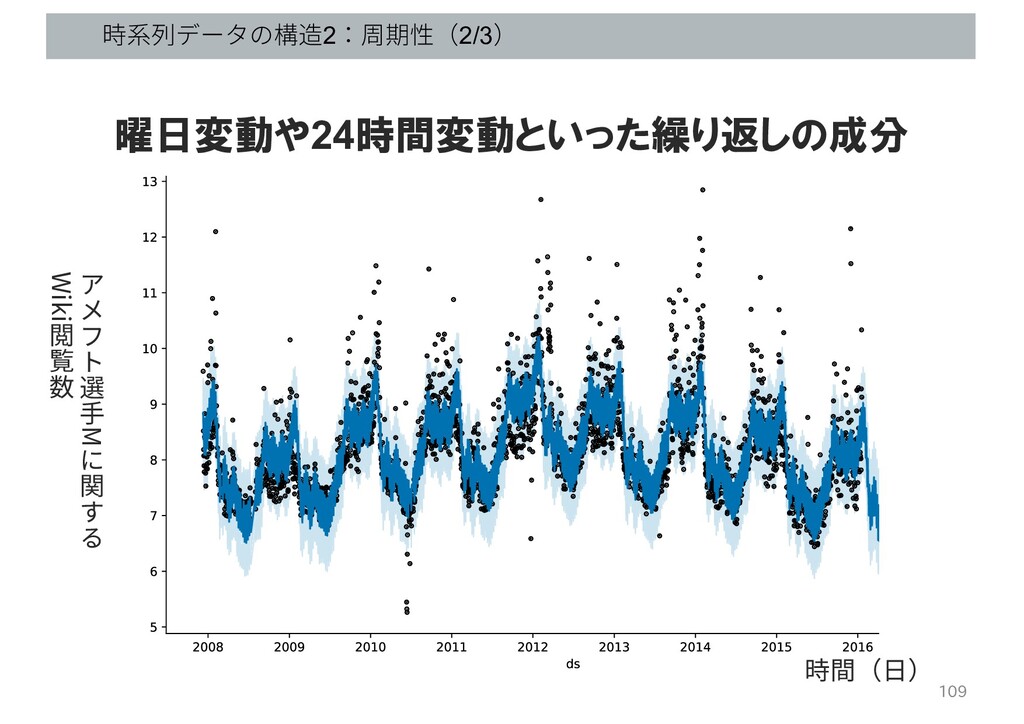
時系列データの構造2:周期性(2/3) 109 曜日変動や24時間変動といった繰り返しの成分 時間(⽇) 選 ⼿ M 関 Wiki 閲
覧 数
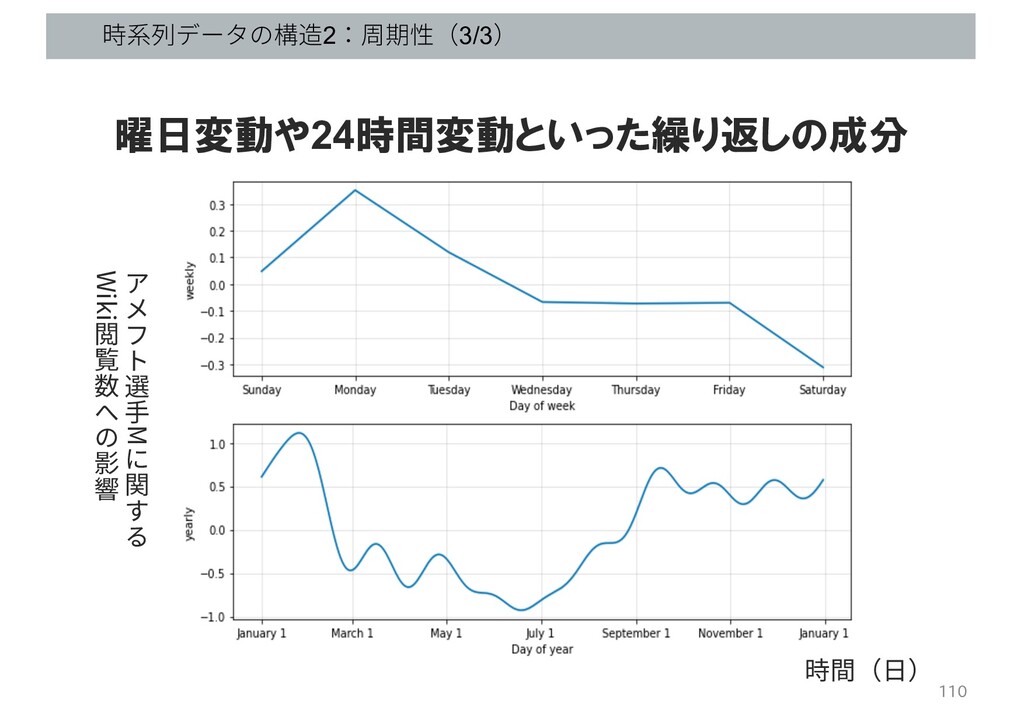
時系列データの構造2:周期性(3/3) 110 曜日変動や24時間変動といった繰り返しの成分 選 ⼿ M 関 Wiki 閲 覧
数 影 響 時間(⽇)
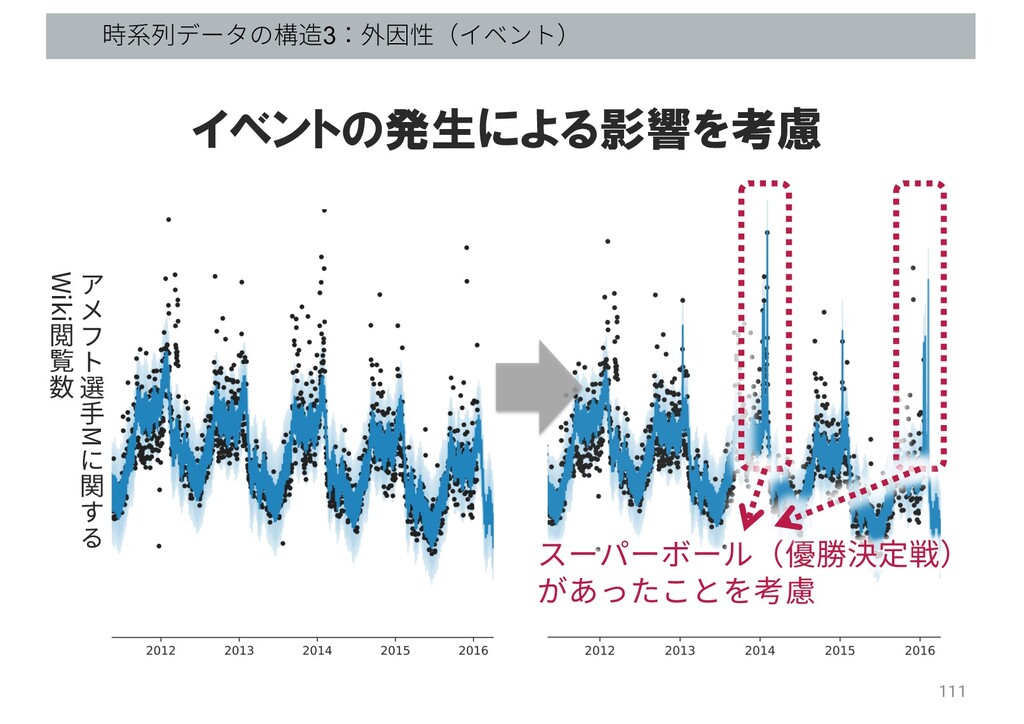
時系列データの構造3:外因性(イベント) 111 イベントの発生による影響を考慮 スーパーボール(優勝決定戦) があったことを考慮 選 ⼿ M 関 Wiki
閲 覧 数
時系列データの構造 112 時系列 データ 周期性 トレンド 外因性 + + +
ノイズ =
時系列分析の3つのアプローチ 113 Box Jenkins法 • AR/MAモデルなどの時系列分析専⽤モデルの組合せ • ⼿順が統⼀されている • 結果の解釈が難しい
状態空間モデル • 様々な統計モデルを組み合せで現象を柔軟に表現 • 結果の解釈がしやすい • 計算コストが⾼い 曲線フィッティング • データを強引に「トレンド+周期性+外因性」に分解 • 近年研究が進んでいる領域(e.g. Prophet,深層学習)
時系列分析の3つのアプローチ 114 Box Jenkins法 • AR/MAモデルなどの時系列分析専⽤モデルの組合せ • ⼿順が統⼀されている • 結果の解釈が難しい
状態空間モデル • 様々な統計モデルを組み合せで現象を柔軟に表現 • 結果の解釈がしやすい • 計算コストが⾼い 曲線フィッティング • データを強引に「トレンド+周期性+外因性」に分解 • 近年研究が進んでいる領域(e.g. Prophet,深層学習)
115 Facebook謹製の時系列分析ライブラリ # Python 1 data = pd.read_csv(“data.csv”) 2 Model
= Prophet() 3 model.fit(data) • 統計の知識が乏しくても⾼品質な時系列分析が可能 • 結果の解釈がしやすい • 扱いやすいライブラリ https://facebook.github.io/prophet/
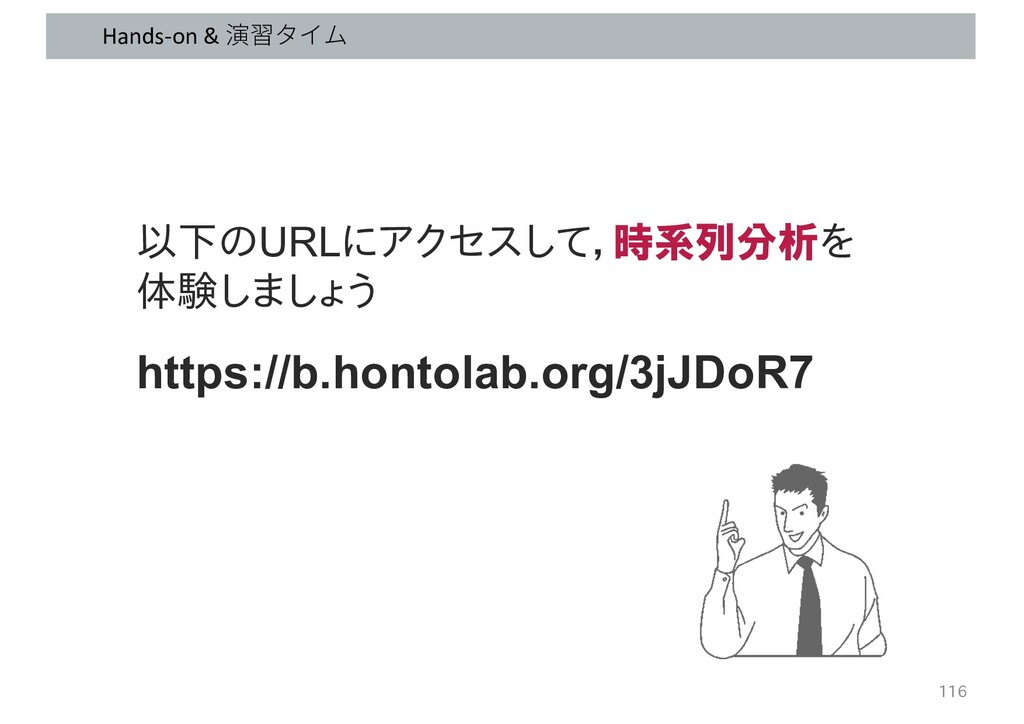
Hands-on & 演習タイム 以下のURLにアクセスして,時系列分析を 体験しましょう https://b.hontolab.org/3jJDoR7 116
データサイエンティストになるには? 5 騒がれているが,課題はたくさん
(再掲)21世紀に最も注⽬される職業であるデータサイエンス⼈材 https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century/ 118
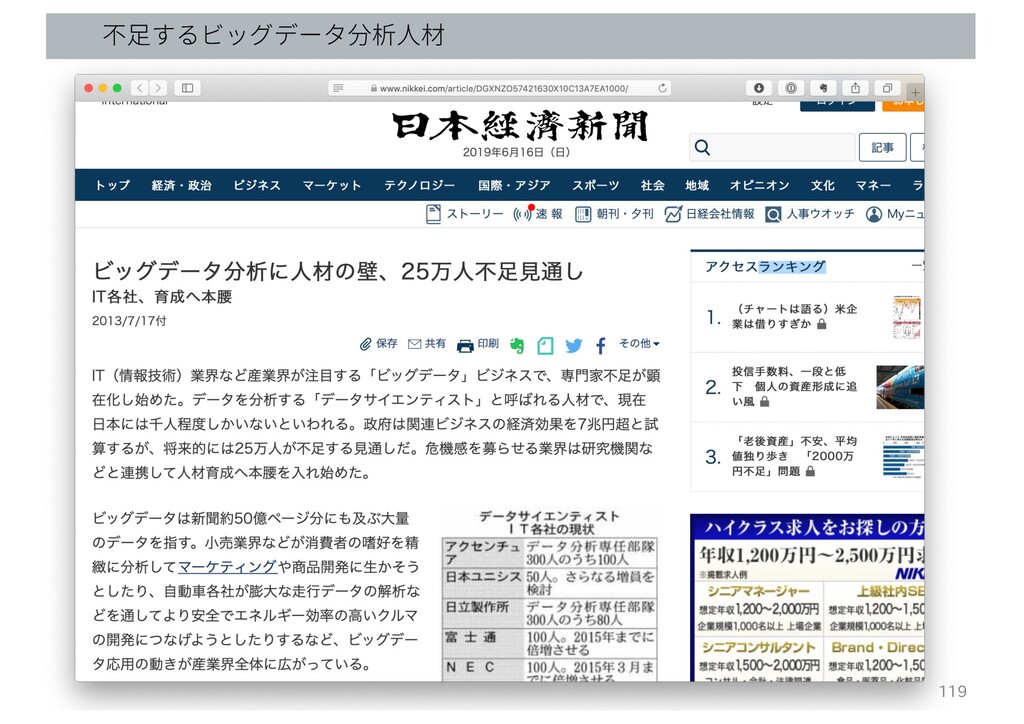
不⾜するビッグデータ分析⼈材 119
急ピッチで整備されるデータサイエンス教育環境 120
121 http://www.mi.u-tokyo.ac.jp/consortium/
データサイエンティストには どんなスキル・知識が求められるか? Q. 122
データサイエンス = 機械学習? = 統計学? = プログラミング? 123
データサイエンス = 機械学習? = 統計学? = プログラミング? = 計算機科学!! 124
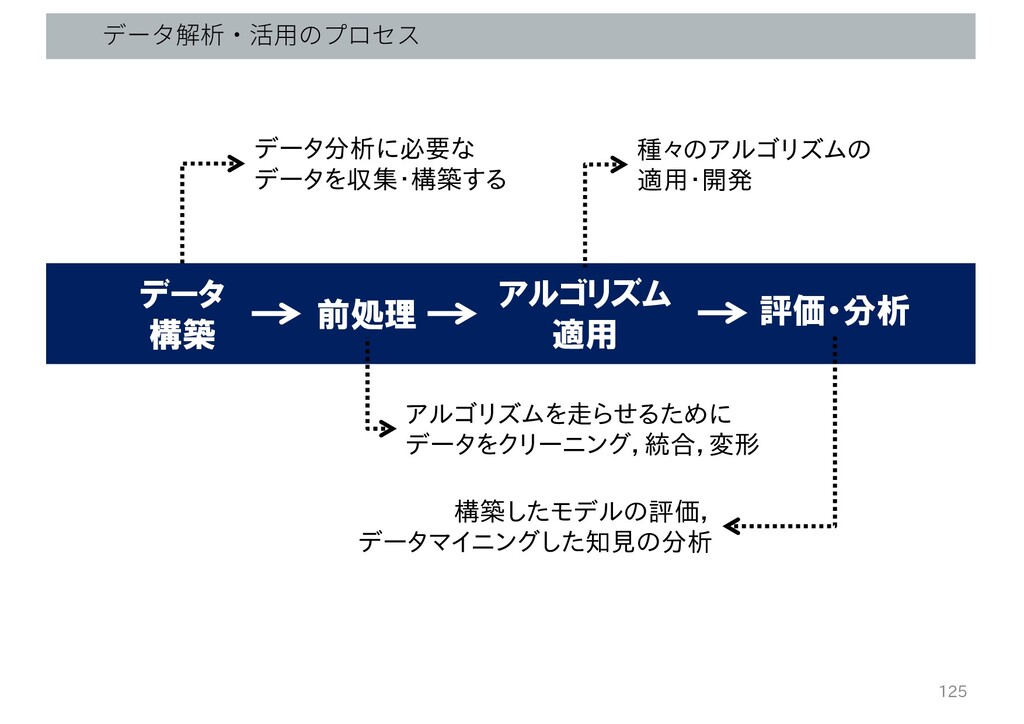
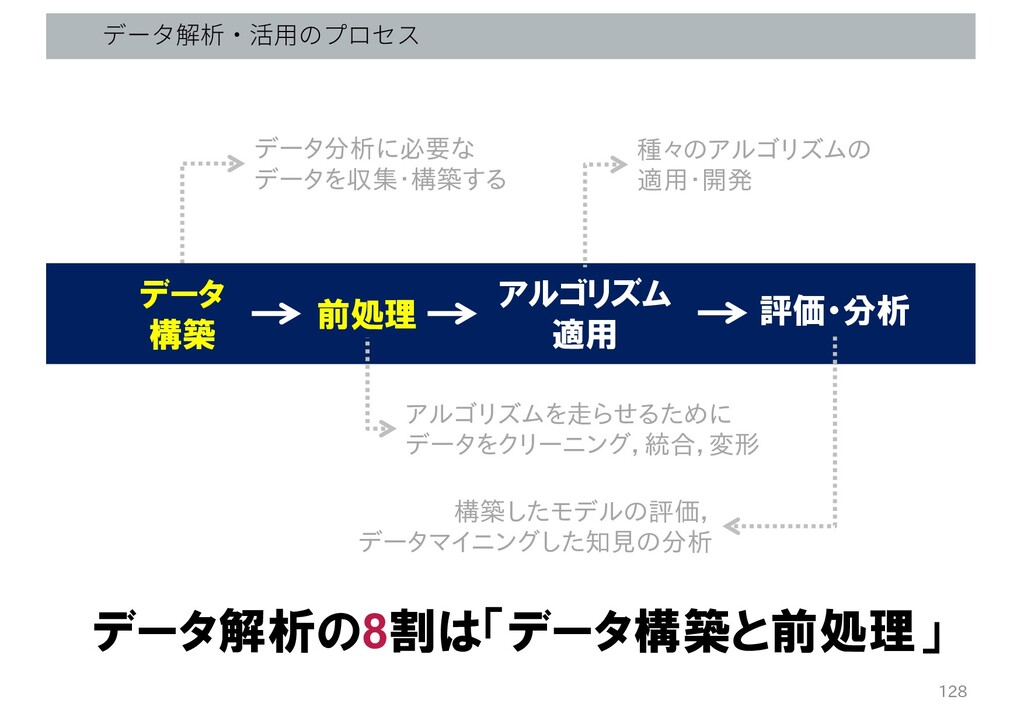
データ分析に必要な データを収集・構築する データ 構築 前処理 アルゴリズム 適用 評価・分析 データ解析・活⽤のプロセス アルゴリズムを走らせるために
データをクリーニング,統合,変形 種々のアルゴリズムの 適用・開発 構築したモデルの評価, データマイニングした知見の分析 125
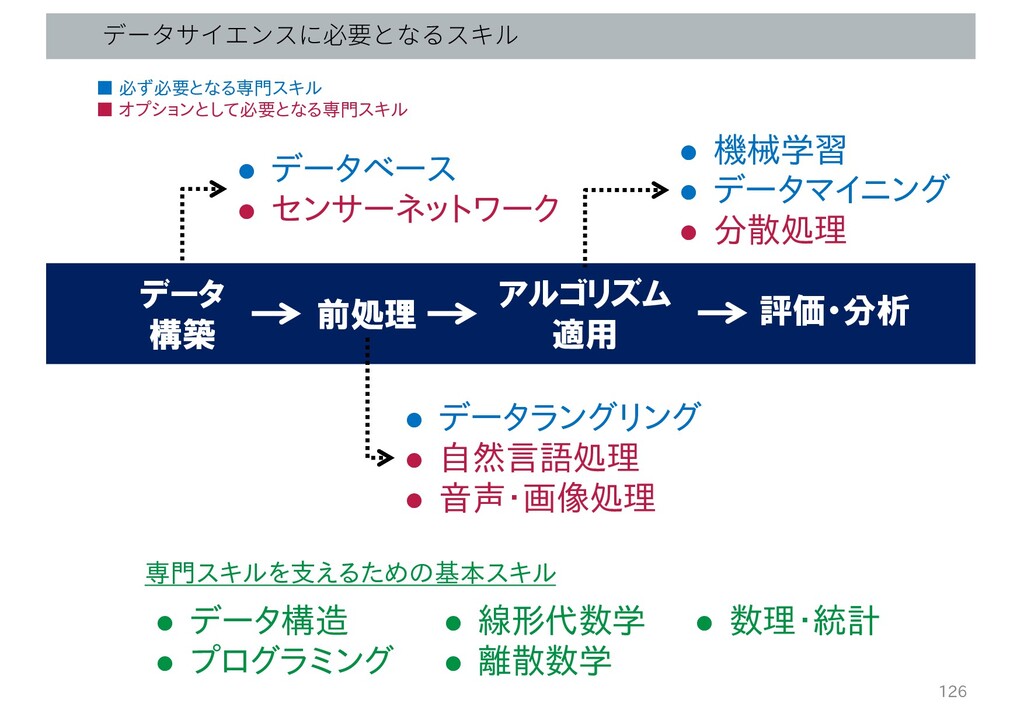
• データベース • センサーネットワーク データ 構築 前処理 アルゴリズム 適用 評価・分析
データサイエンスに必要となるスキル • データラングリング • 自然言語処理 • 音声・画像処理 • 機械学習 • データマイニング • 分散処理 ▪ 必ず必要となる専門スキル ▪ オプションとして必要となる専門スキル 専門スキルを支えるための基本スキル • データ構造 • プログラミング • 線形代数学 • 離散数学 • 数理・統計 126
• データベース • センサーネットワーク データ 構築 前処理 アルゴリズム 適用 評価・分析
データサイエンスに必要となるスキル • データラングリング • 自然言語処理 • 音声・画像処理 • 機械学習 • データマイニング • 分散処理 ▪ 必ず必要となる専門スキル ▪ オプションとして必要となる専門スキル 専門スキルを支えるための基本スキル • データ構造 • プログラミング • 線形代数学 • 離散数学 • 数理・統計 社会が考えるデータサイエンスはこれ 127
データ分析に必要な データを収集・構築する データ 構築 前処理 アルゴリズム 適用 評価・分析 データ解析・活⽤のプロセス アルゴリズムを走らせるために
データをクリーニング,統合,変形 種々のアルゴリズムの 適用・開発 構築したモデルの評価, データマイニングした知見の分析 データ解析の8割は「データ構築と前処理」 128
https://biz.trans-suite.jp/15958 https://jp.depositphotos.com/ https://ecotopia.earth/article-134/ 情報系学部を卒業して 憧れのデータサイエンティスト として就職!! 期待の新人 データサイエンティスト 職場にはビッグデータ活用という 概念がなく,データ分析できる
状況ではない. 職場にデータがない or ゴミデータの山 データサイエンスが定着しない企業の現実 データ分析は勉強したが,データ 収集・構築なんて習っていない 129
データサイエンスの不都合な真実 https://tjo.hatenablog.com/entry/2018/04/02/190000 o 同僚・上司からの期待感が 現実とマッチしない o 社内政治が最優先される o データに関わるもの全てを 扱う何でも屋扱いされる
o 他の事業から孤立した チームで働かされる 130
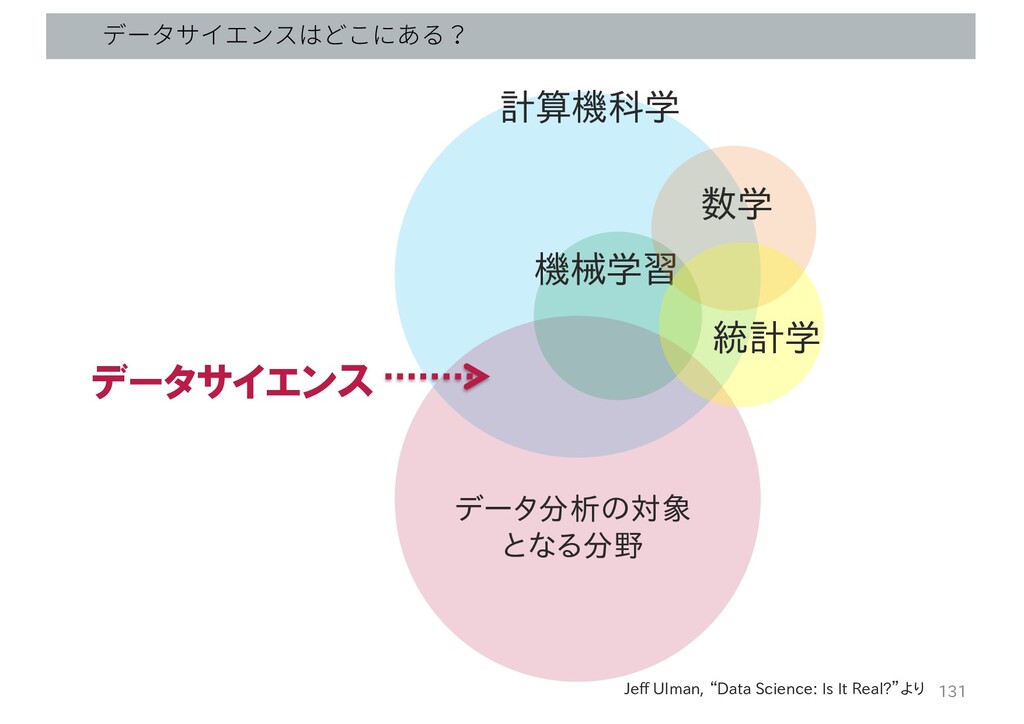
データサイエンスはどこにある? 機械学習 計算機科学 データ分析の対象 となる分野 数学 統計学 データサイエンス Jeff Ulman,
“Data Science: Is It Real?”より 131
学習モデルの構築もある程度AIにお任せできる 学習モデルの構築にはもはや人間は必要ない? 132
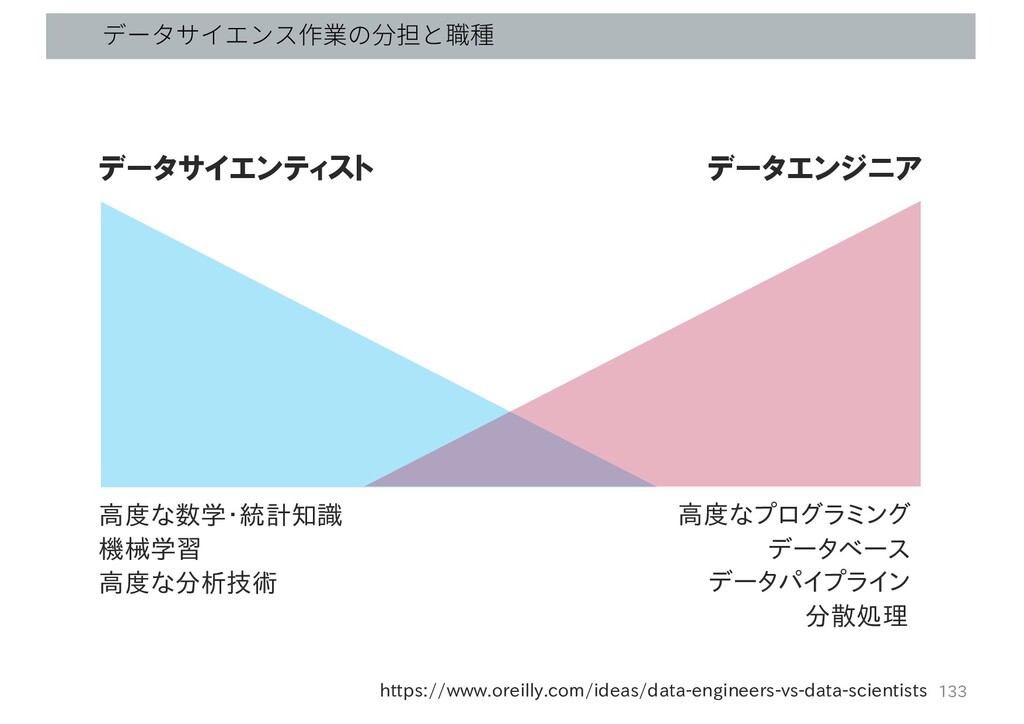
データサイエンス作業の分担と職種 データサイエンティスト データエンジニア 高度な数学・統計知識 機械学習 高度な分析技術 高度なプログラミング データベース データパイプライン 分散処理
133 https://www.oreilly.com/ideas/data-engineers-vs-data-scientists
データサイエンス作業の分担と職種 https://www.oreilly.com/ideas/data-engineers-vs-data-scientists データサイエンティスト データエンジニア 高度な数学・統計知識 機械学習 高度な分析技術 高度なプログラミング データベース データパイプライン
分散処理 機械学習エンジニア データラングリング 機械学習の運用 機械学習のチューニング 134
![AI・機械学習応用論 山本 祐輔 静岡大学 情報学部 講師 [email protected] 出張講座2020 2020年11月11日 本スライドは,クリエイティブ・コモンズ・ライセンス国際4.0のもとで,](https://files.speakerdeck.com/presentations/6c8ea76cf4664f33998d1d7ac283416c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}