Learning problems 3. Steps needed to solve them 4. How two classification algorithms work a. K-Nearest Neighbors b. Support Vector Machines 5. Evaluating an algorithm a. Overfitting 6. Demo 7. What follows 6
Batteries included • Lots of libraries ◦ For everything, not just Machine Learning ◦ Bindings to integrate with other languages • Community ◦ Very active scientific community ◦ Used in academia & industry 7
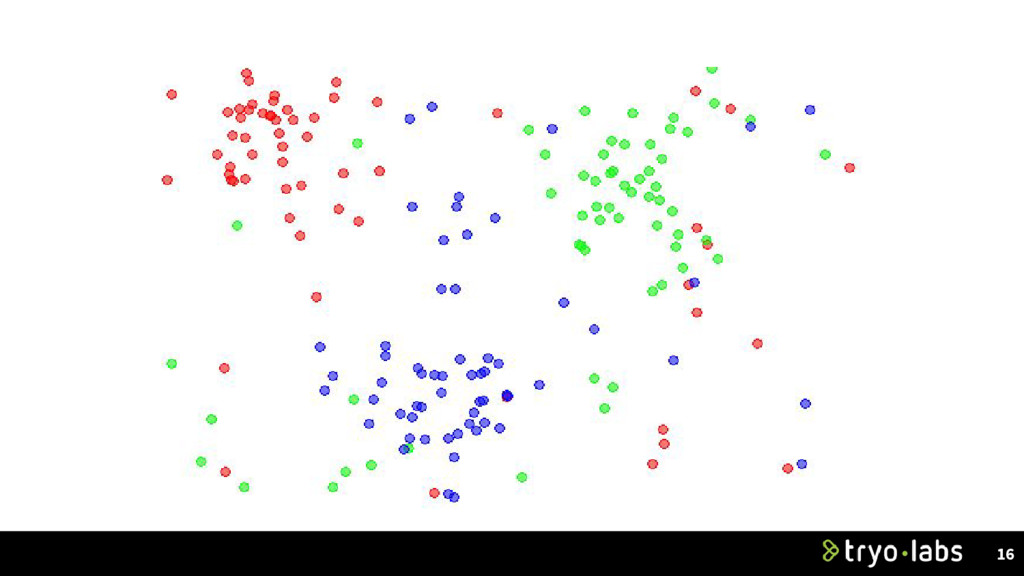
which we know the desired output. • Two types: ◦ Classification (discrete variables, ie. spam/no spam) ◦ Regression (continuous output, ie. temperature) 9 Unsupervised • Discover latent relationships in the data • Two types: ◦ Dimensionality reduction (curse of dimensionality) ◦ Clustering Also have semi-supervised (use labeled and unlabeled data).
task, need to go through: 1. Data gathering 2. Data processing & feature engineering 3. Algorithm & training 4. Applying model to make predictions (evaluate, improve) 10
need to put humans to work :( ◦ Ie. Manual labelling for supervised learning ◦ Domain knowledge. Maybe even experts. ◦ Can leverage Mechanical Turk / CrowdFlower. • May come for free, or “sort of” ◦ Ie. Machine Translation. ◦ Categorized articles in Amazon, etc. • The more the better ◦ Some algorithms need large amounts of data to be useful (ie. neural networks). 11
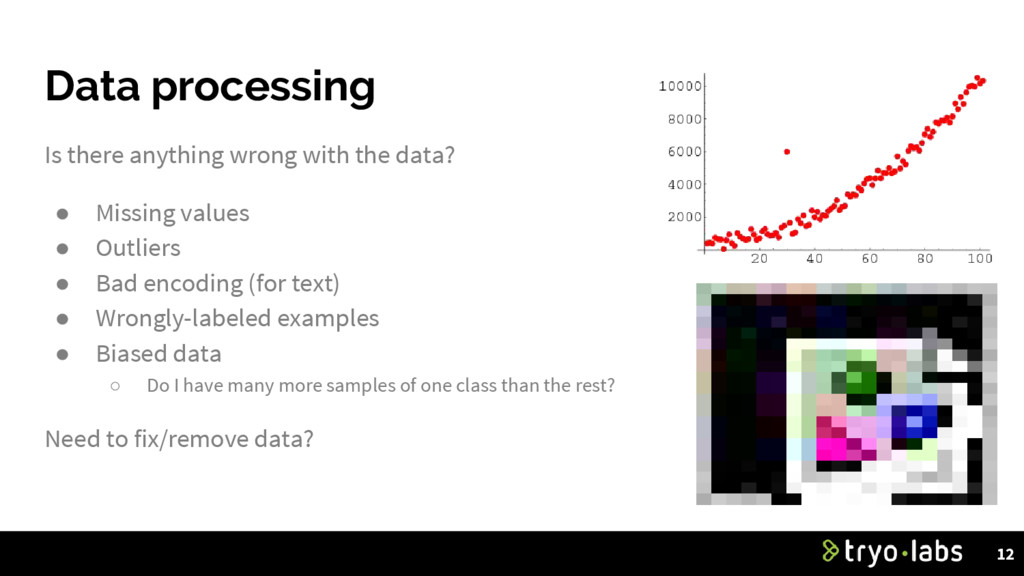
Missing values • Outliers • Bad encoding (for text) • Wrongly-labeled examples • Biased data ◦ Do I have many more samples of one class than the rest? Need to fix/remove data? 12
individual measurable property of a phenomenon being observed Our inputs are represented by a set of features. Eg: • To classify spam email, features could be: ◦ Number of times some word appears (ie. pharmacy) ◦ Number of words that have been ch4ng3d like this. ◦ Language of the email ◦ Number of emojis 13 Buy ch34p drugs from the ph4rm4cy now :) :) :) :) (1, 2, English, 4) Feature engineering
• Not adding “new” data per-se ◦ Making it more useful ◦ With good features, most algorithms can learn faster • It can be an art ◦ Requires thought and knowledge of the data Two steps: • Variable transformation (eg. dates into weekdays, normalizing) • Feature creation (eg. n-grams for texts, if word is capitalized to detect names, etc) 14
• Support Vector Machines (SVM) • Decision Tree • Random Forests • k-Nearest Neighbors • Neural Networks (Deep learning) Unsupervised / dimensionality reduction • PCA • t-SNE • k-means • DBSCAN They all understand vectors of numbers. Data are points in multi-dimensional space. 15
a natural number k >= 1 (parameter of the algorithm) • Given the sample X we want to label: ◦ Calculate some distance (ie. euclidean) to all the samples in the training set. ◦ Keep the k samples with the shortest distance to X. These are the nearest neighbors. ◦ Assign to X whatever class the majority of the neighbors have. 17
is an active area of research. • Naive brute-force approach computes distance to all points, need to keep entire dataset in memory at classification time (no offline training). • Need to experiment to get the right k. There are other algorithms that use approximations to deal with these inefficiencies. 19
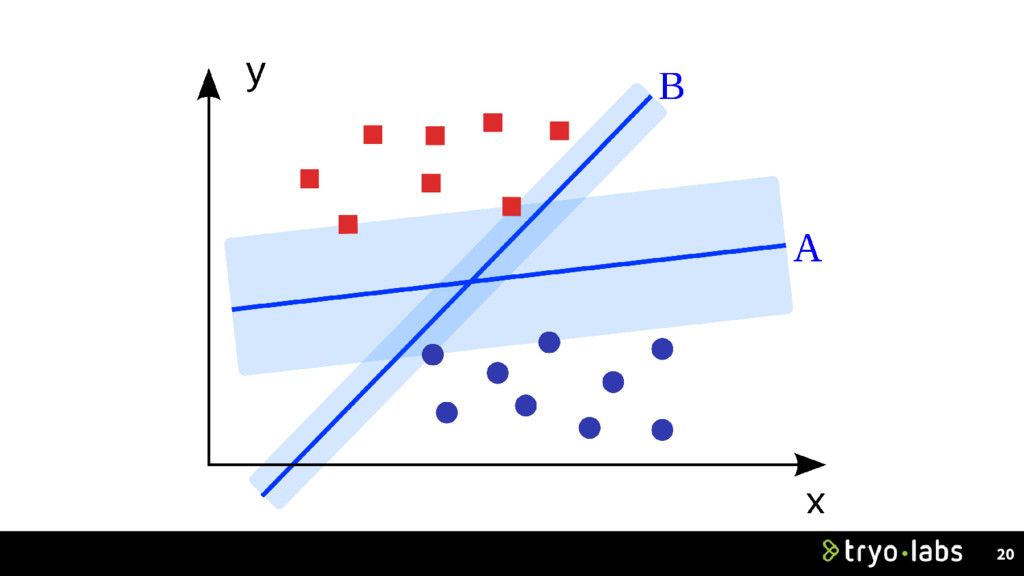
space. • There are infinite planes that can separate blue & red dots. • SVM finds the optimal hyperplane to separate the two classes (the one that leaves the most margin). 21
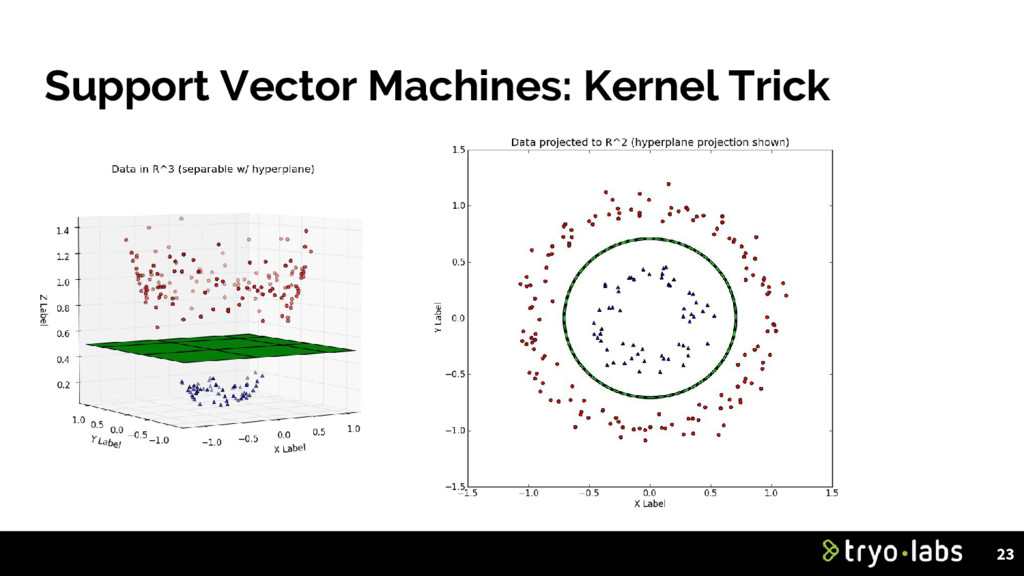
the points that are the most difficult to tell apart (other classifiers pay attention to all the points). • We call them the support vectors. • Decision boundary doesn’t change if we add more samples that are outside the margin. • Can achieve good accuracy with fewer training samples compared to other algorithms. Only works if data is linearly separable. • If not, can use a kernel to transform it to a higher dimension. 22
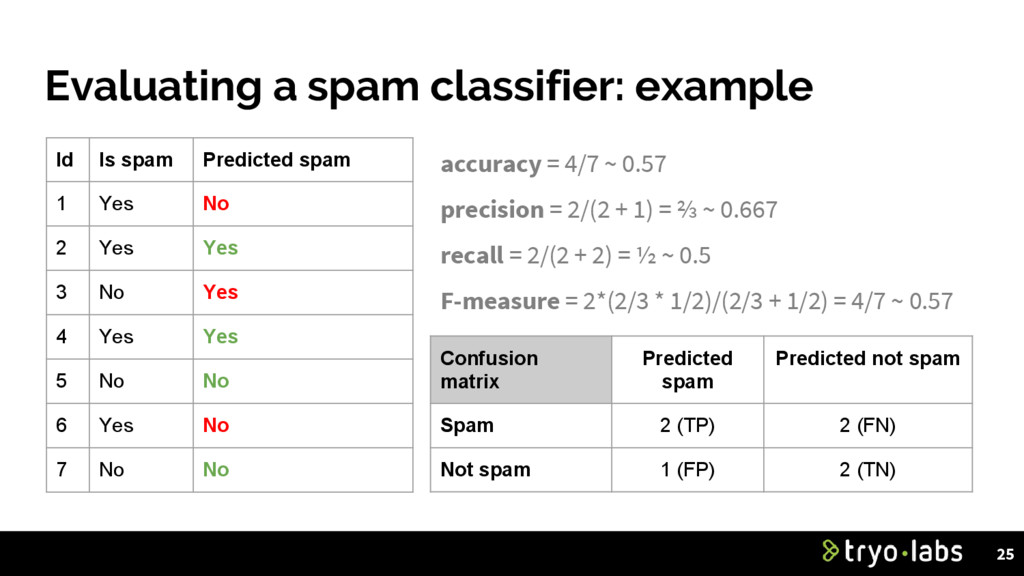
• Accuracy ◦ What % of samples did it get right? • Precision / Recall ◦ True Positives, True Negatives, False Positives, False Negatives ◦ Precision = TP / (TP + FP) (out of all the classifier labeled positive, % that actually was) ◦ Recall = TP / (TP + FN) (out of all the positive, how many did it get right?) ◦ F-measure (harmonic mean, 2 * Precision * Recall / (Precision + Recall)) • Confusion matrix • Many others 24
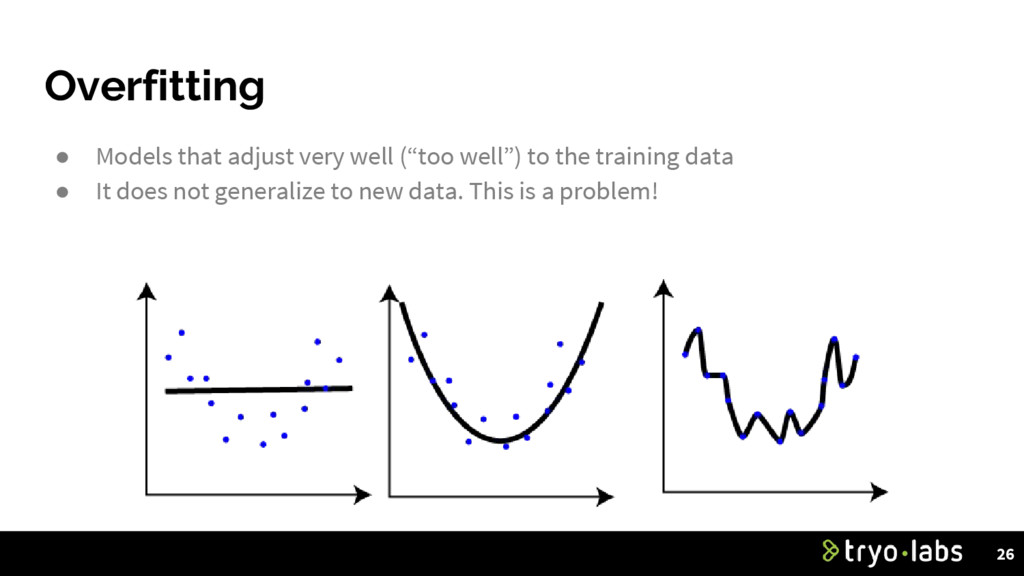
is better than complex ◦ Fewer parameters to tune can bring better performance. ◦ Eliminate degrees of freedom. Eg. polynomial ◦ Regularization (penalize complexity) • K-fold cross validation (different train/test partitions) • Get more training data! 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}