Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
計算量オーダーの話
Search
tsuda.a
May 25, 2024
Programming
460
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
計算量オーダーの話
計算量オーダーについて説明してみました。
tsuda.a
May 25, 2024
More Decks by tsuda.a
See All by tsuda.a
Git を GUI で 使う話
tsudaahr
0
110
マジカルインクリメントと指数表記
tsudaahr
0
260
バックアップしていますか?
tsudaahr
0
150
RDB以前のファイル設計の話でもしようか(ぇ
tsudaahr
0
160
NPUわからん
tsudaahr
0
220
クラウド初学者が抱える不安について
tsudaahr
0
340
キューとは何か
tsudaahr
0
290
等幅は死んだ(ぇ
tsudaahr
0
140
いくら眺めてもエラーの理由がわからないコードについて
tsudaahr
0
230
Other Decks in Programming
See All in Programming
Vite+ Unified Toolchain for the Web
naokihaba
0
740
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.8k
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
190
AIエージェントで 変わるAndroid開発環境
takahirom
2
490
技術記事、 専門家としてのプログラマ、 言語化
mizchi
14
7.4k
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
220
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
260
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
250
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
170
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
150
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
190
Featured
See All Featured
Documentation Writing (for coders)
carmenintech
77
5.4k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
Agile that works and the tools we love
rasmusluckow
331
22k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Practical Orchestrator
shlominoach
191
11k
Music & Morning Musume
bryan
47
7.3k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
920
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Transcript
計算量オーダーの話 LTDD 2024-5 #2 中国地方DB勉強会 #1 @tsuda_ahr
最初に免責 • 概念的なわかりやすさ(?)を重視して、誇張した表現を多用しています。 • いやその表現、誇張を超えて嘘だよね、みたいなのもあります。-_-; • なので正しくはこうだ!みたいなものは、各自調査/発信してください(汗
情報処理技術者試験の問題例 (1) https://www.ipa.go.jp/shiken/mondai-kaiotu/ug65p90000002h5m-att/2012h24a_fe_am_qs.pdf • 平成24年秋の基本情報技術者試験 午前問題より
情報処理技術者試験の問題例 (2) • 令和6年春 応用情報技術者試験 午後問題 問3 より
O(n), O(n2) ってなんだ? • 計算量の指標 • データが n 件あったとき、何回計算するか?
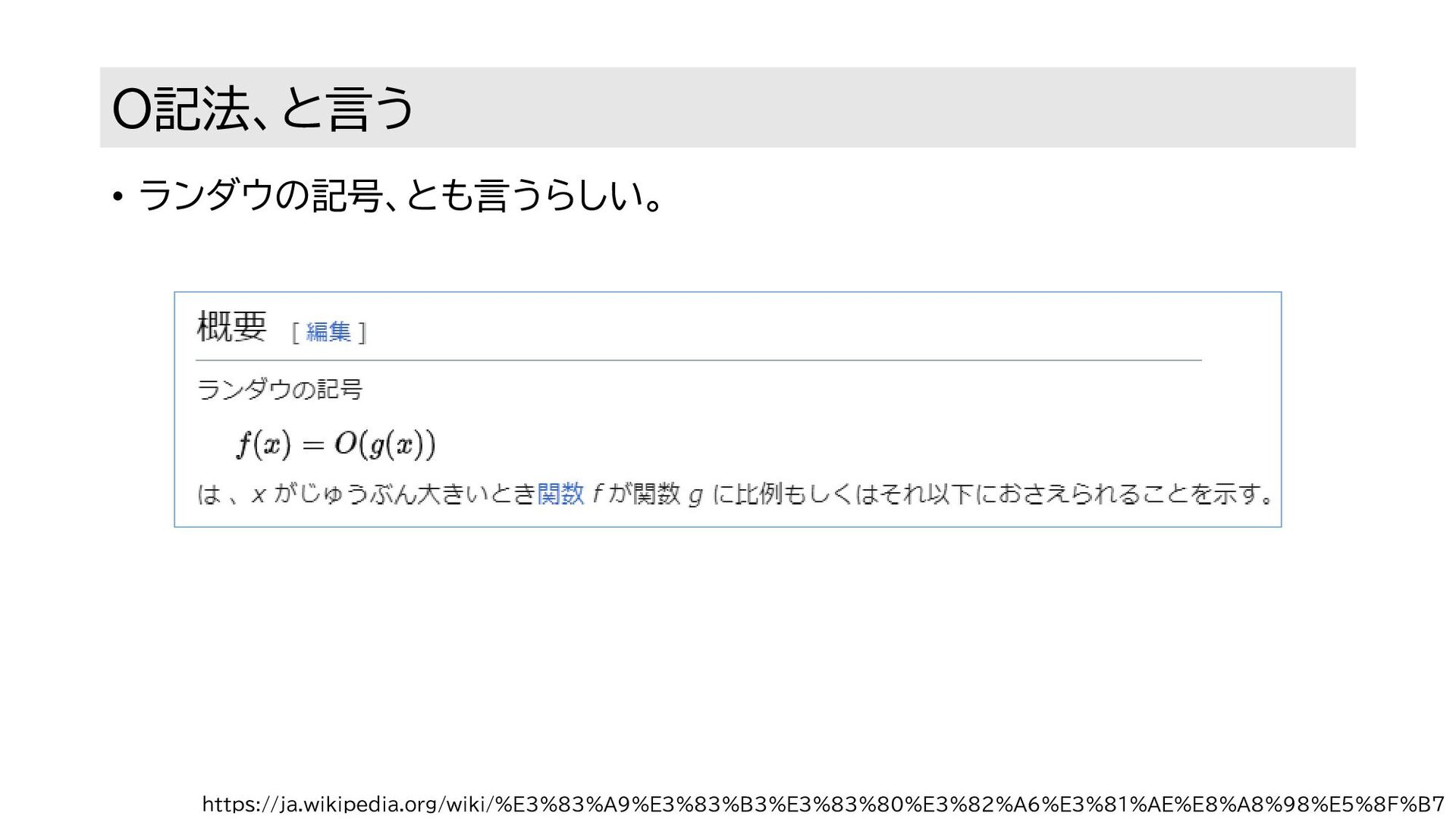
O記法、と言う • ランダウの記号、とも言うらしい。 https://ja.wikipedia.org/wiki/%E3%83%A9%E3%83%B3%E3%83%80%E3%82%A6%E3%81%AE%E8%A8%98%E5%8F%B7
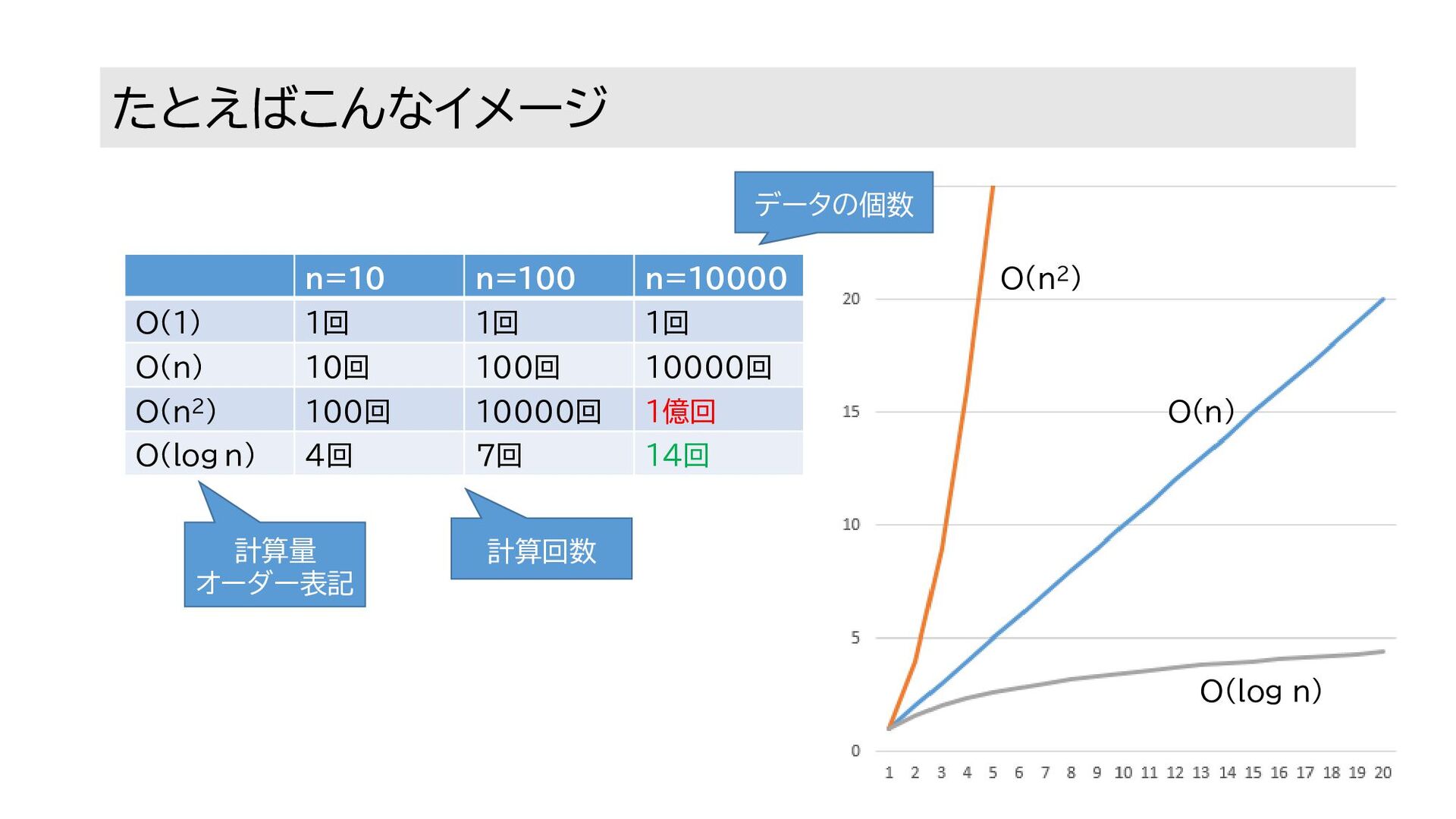
たとえばこんなイメージ n=10 n=100 n=10000 O(1) 1回 1回 1回 O(n) 10回
100回 10000回 O(n2) 100回 10000回 1億回 O(log n) 4回 7回 14回 データの個数 計算回数 計算量 オーダー表記 O(n) O(n2) O(log n)
例1) 配列へのアクセス • 添え字を指定すれば一発でアクセスできるので、計算量オーダーは O(1) • 例)要素 5 のデータを参照したい 0
1 2 3 4 5 6 7 8 9 ・・・ AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH IIII JJJJ
例2) 線形探索 • n 件あれば、n 回ループする可能性があるので、計算量オーダーは O(n) • 例) “HHHH”
を探したい (上の要素から順に探す) 0 1 2 3 4 5 6 7 8 9 ・・・ AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH IIII JJJJ
ん?平均回数でみると、O(0.5n)になるのでは? • 係数部分は省略するらしいです。 • なので 0.000001n だろうと 10000000n だろうと O(n)
と表現する らしい。
例3) ソート(バブルソート) • 二重ループになるので、計算量オーダーは O(n2) n = len(body) for x
in range(0, n) : for y in range(1, n) : if (body[y - 1] > body[y]) : body[y - 1], body[y] = body[y], body[y - 1] 二重ループ Python によるコード例
ループのネストが増えると? • 三重ループだと O(n3), 四重ループだと O(n4)・・・という感じになってい きます。
log が出てくるケースは? • O(log n) とか O(n log n) とか書かれているのは何?
例4) 二分岐探索 • 二分岐探索について考えてみます。 注) 二分岐探索(Binary Tree)は、データベースでよくつかわれている B 木とは 違います。
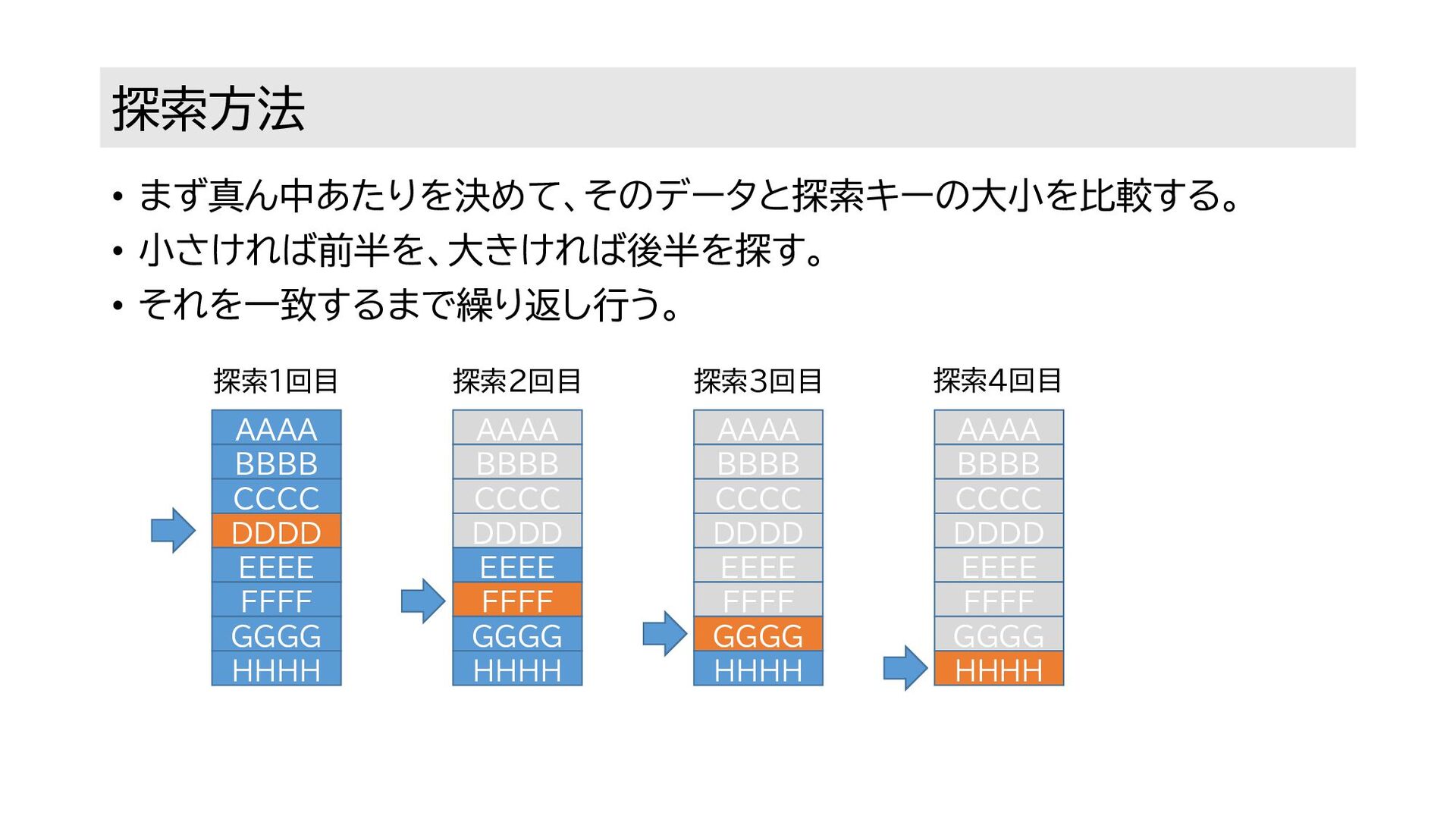
前提 • HHHH を探したい。(=探索キー) • ただし、探索対象はソート済みとする。 • 探索対象は以下。 AAAA BBBB
CCCC DDDD EEEE FFFF GGGG HHHH 探索対象
探索方法 • まず真ん中あたりを決めて、そのデータと探索キーの大小を比較する。 • 小さければ前半を、大きければ後半を探す。 • それを一致するまで繰り返し行う。 AAAA BBBB CCCC
DDDD EEEE FFFF GGGG HHHH AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH AAAA BBBB CCCC DDDD EEEE FFFF GGGG HHHH 探索1回目 探索2回目 探索3回目 探索4回目
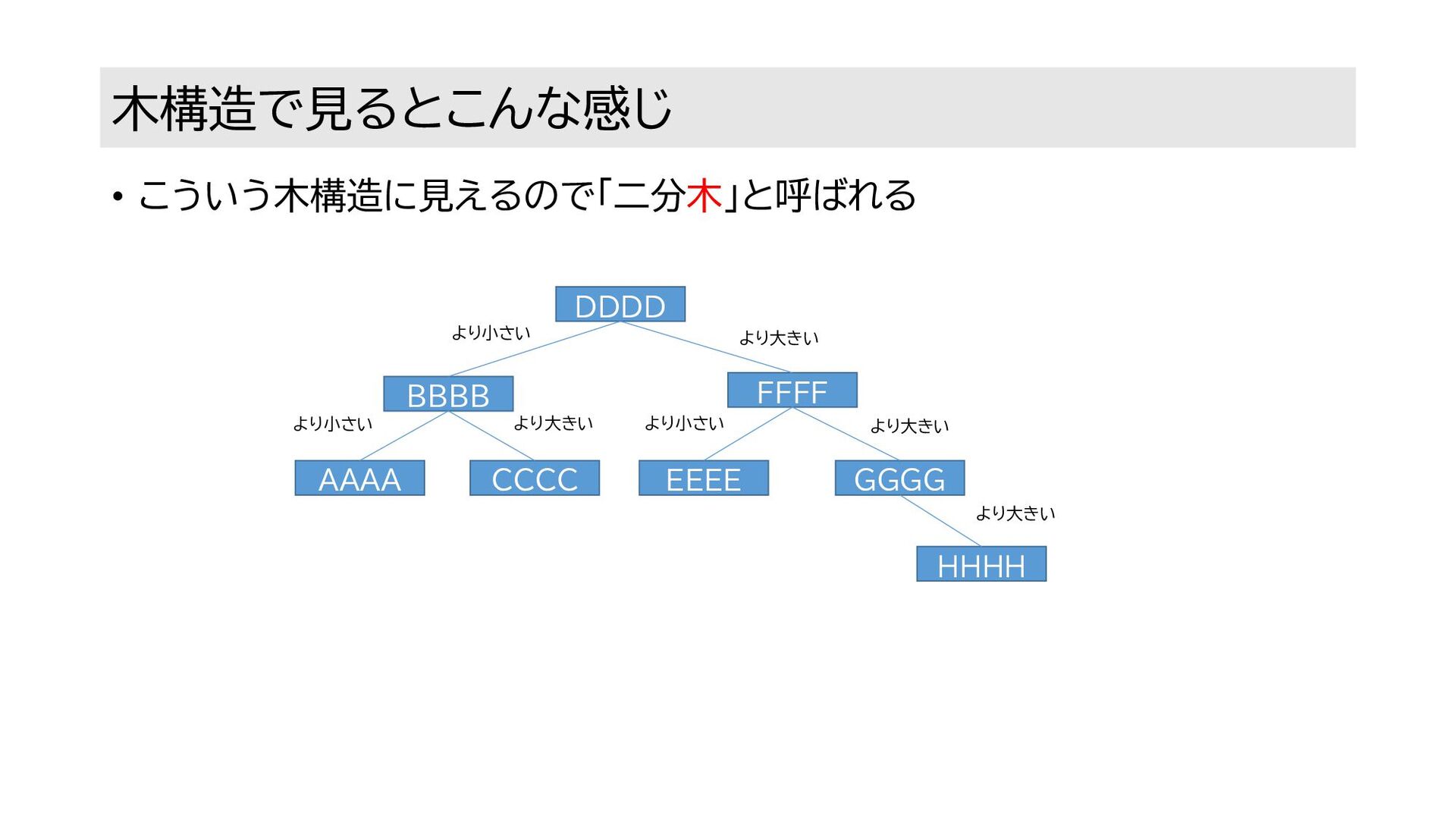
木構造で見るとこんな感じ • こういう木構造に見えるので「二分木」と呼ばれる AAAA BBBB CCCC DDDD EEEE FFFF GGGG
HHHH より小さい より大きい より小さい より小さい より大きい より大きい より大きい
探索回数は? • たとえばデータが 8 の場合、4 回の検索でたどりついた。 • 16 の場合は 5
回 • 32 の場合は 6 回 • 65536の場合は? →たぶん 17 回 • 16777216の場合は? →たぶん 25回 • ということは、n = 2x のデータに対して x + 1 回でたどり着いている。 • n から x を求めたい場合 x = log 2 (n) となる。
さてデータベースの場合 • 探索にかかる時間は、 • フルスキャン → O(n) • インデックススキャン →O(log
n) みたいな感じです。
つまり、 • 100万件のデータがあった場合の最悪ケースの探索回数は以下 注) 実際のインデックスは二分木ではなく B 木だったり、ディスクに記録されている インデックスデータすべてをいきなりメモリ上に展開するわけでもなかったり、 ディスクからメモリに展開するためのディスク I/O
があったりその他云々いろい ろあるので、上記のような単純な話ではありません(汗 実行計画 探索方法 探索回数 テーブルフルスキャン 線形探索 100万回 インデックススキャン 木による探索 20回
圧倒的じゃないかインデックスは! • よし、じゃあインデックスを貼りまくれば万事解決!!
そんなわけない(汗 • 二分木探索のとき、必要だったのは「ソートされた」データでした。 • つまりインデックスにデータを追加するとき、インデックスのデータはソートさ れた状態を維持しなくてはならない。 • ソートされた状態を維持したままデータを追加するのはコストがかかる。 • したがってインデックスを作ると、検索
(select) のときは早いけど、データ の挿入(insert)や更新(update) のときに激重になる。
なので • インデックスを貼る場合は、検索頻度と更新頻度を考慮して、貼るカラムを選 定する必要があります。
こちらからは以上です • 探索とかソートする際は計算量を気にしましょう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}