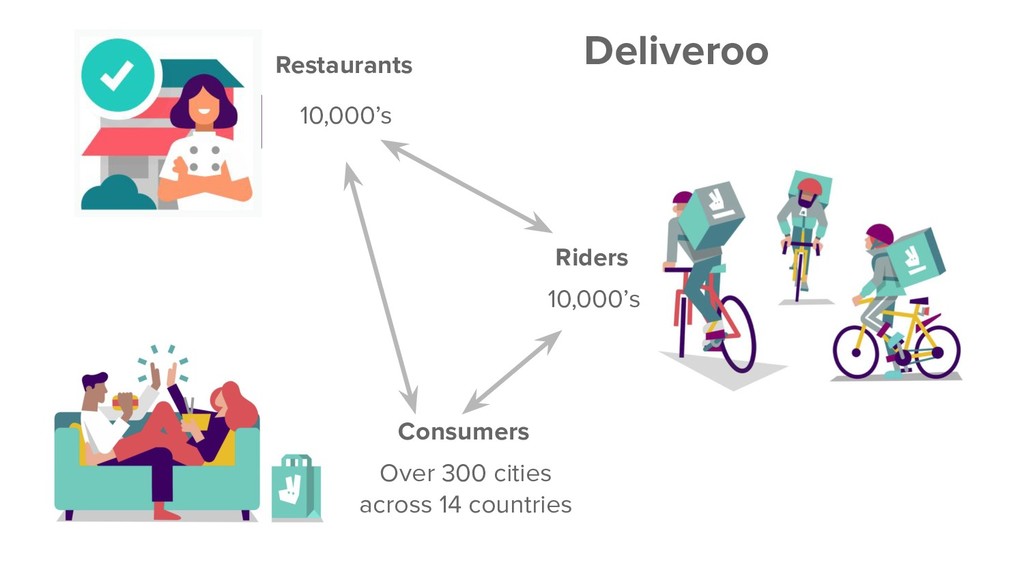
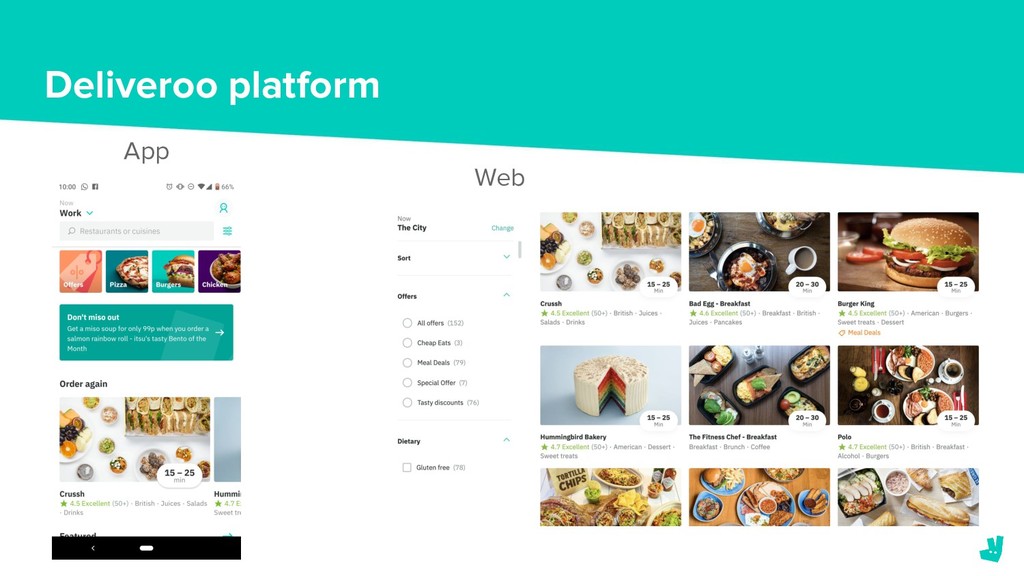
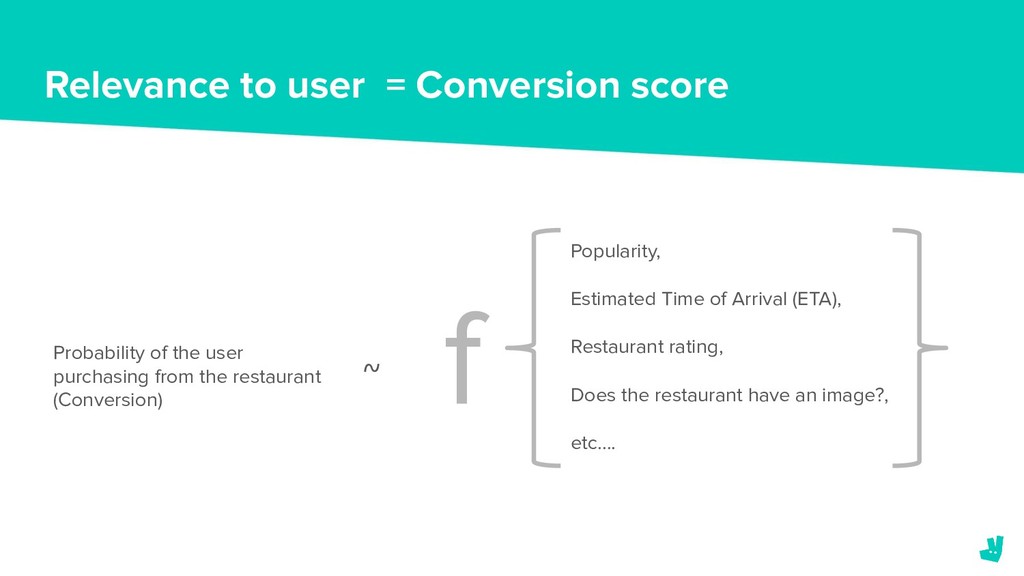
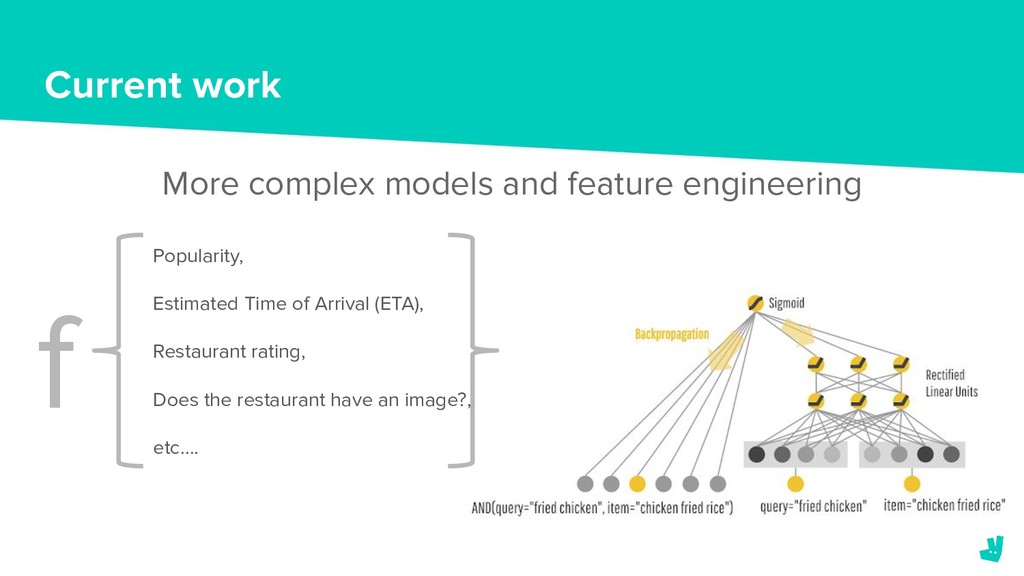
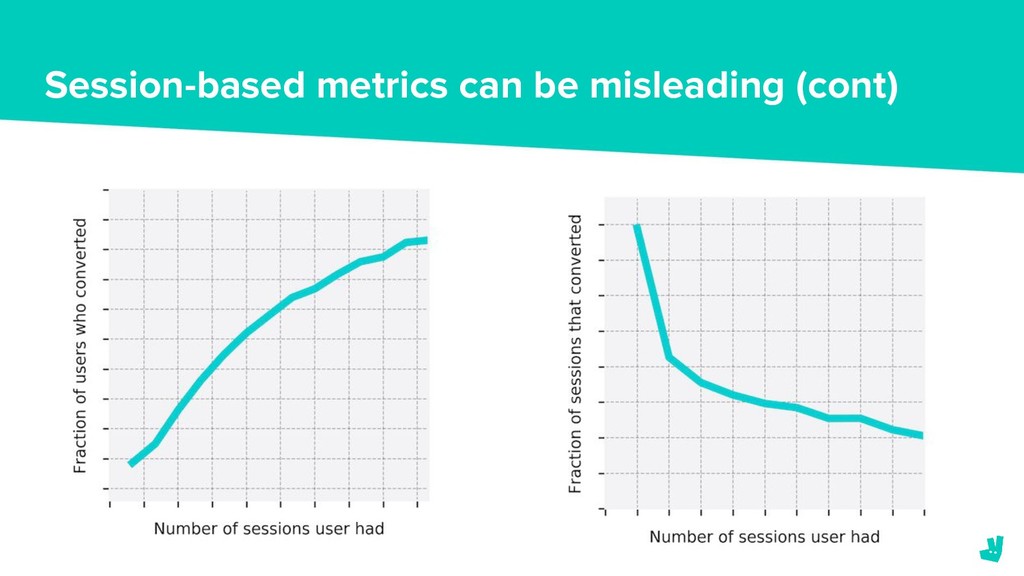
When a consumer opens the Deliveroo app they have the option to pick from a huge variety of restaurants. Depending on their location, the number of available restaurants can vary from 10’s to almost 1,000 (and counting.) However, as there is limited screen space on a consumer’s device we want to make sure that the restaurants that we surface first are the most relevant.
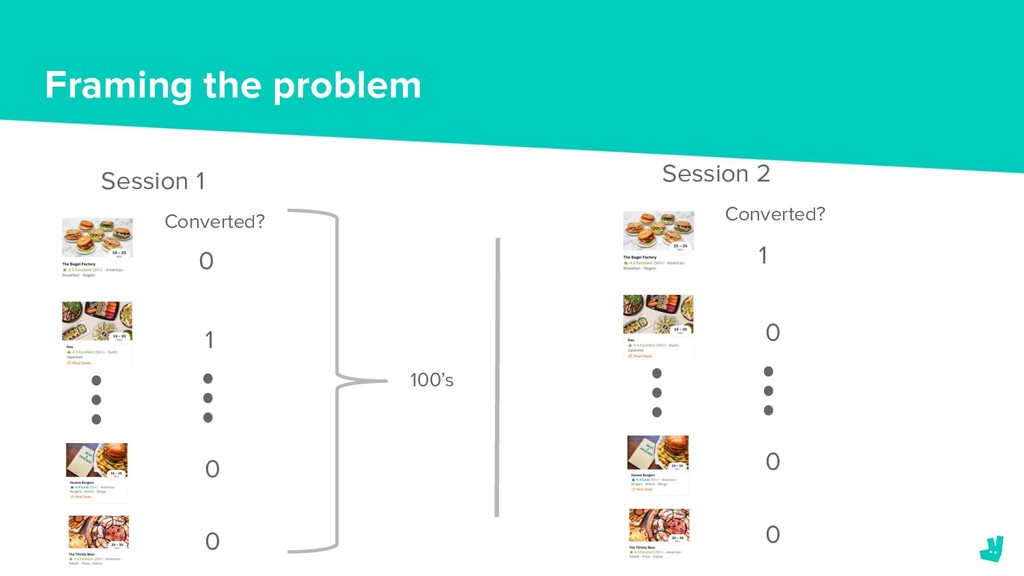
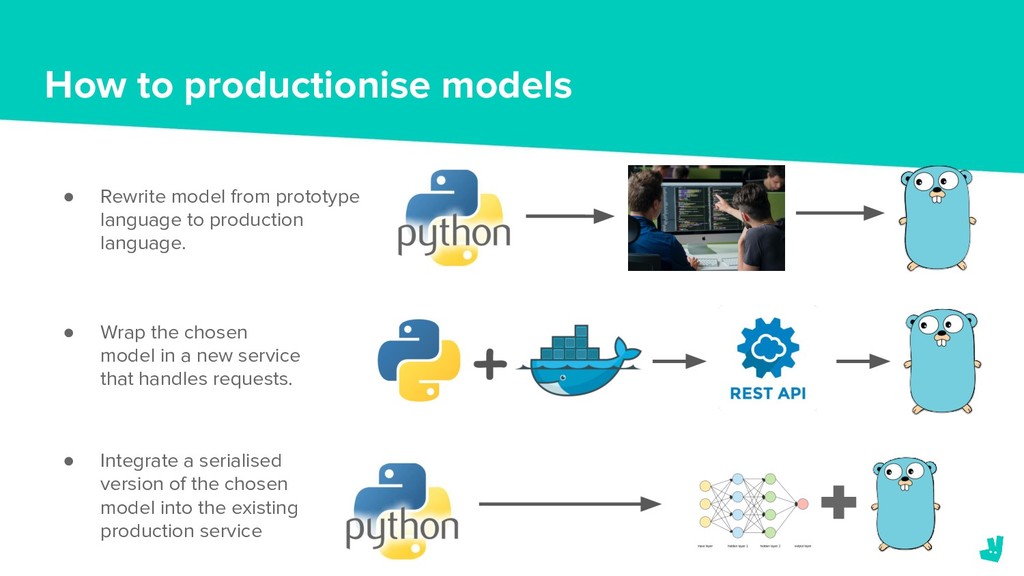
In October last year we formed a team to address this problem. We needed to decide on the tools and infrastructure to build and deploy these models as well as how we were going to frame the ranking problem.
In this talk we’ll explain how we’re using Tensorflow to train and deploy our models. We’ll also discuss the challenges that we’ve faced in tackling the ranking problem and outline the solutions that we’ve implemented or proposed to overcome them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
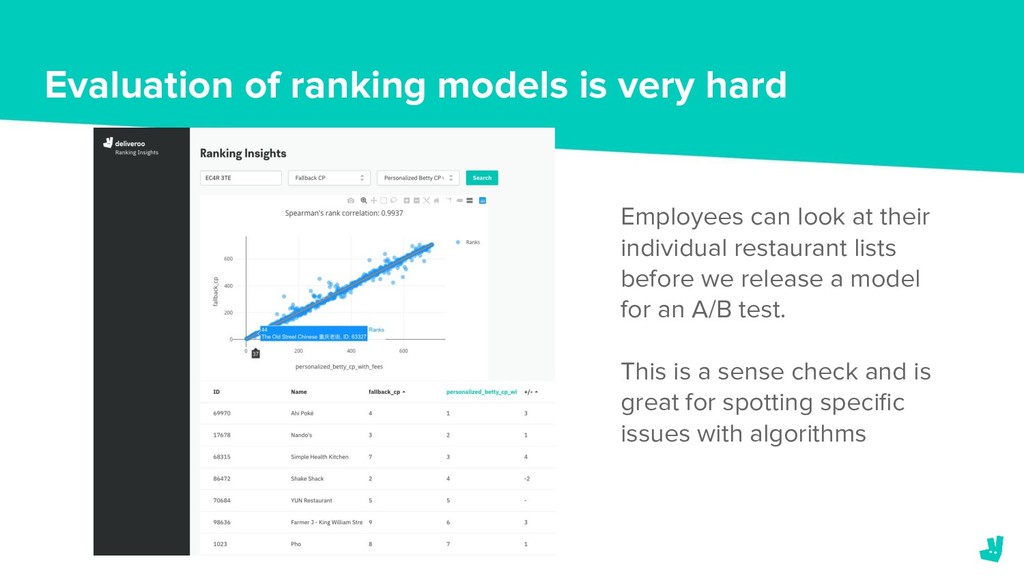{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
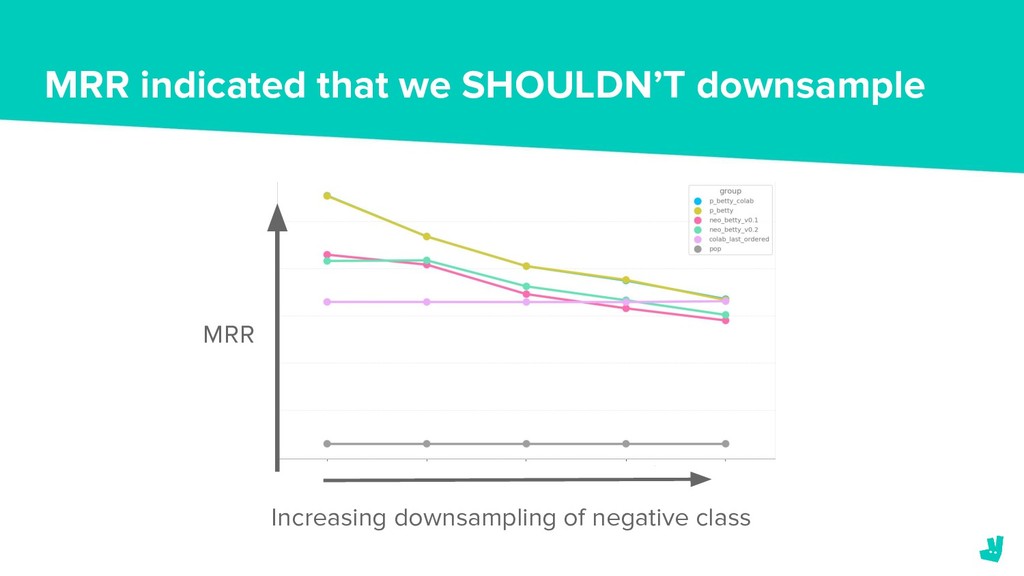{kind=link}
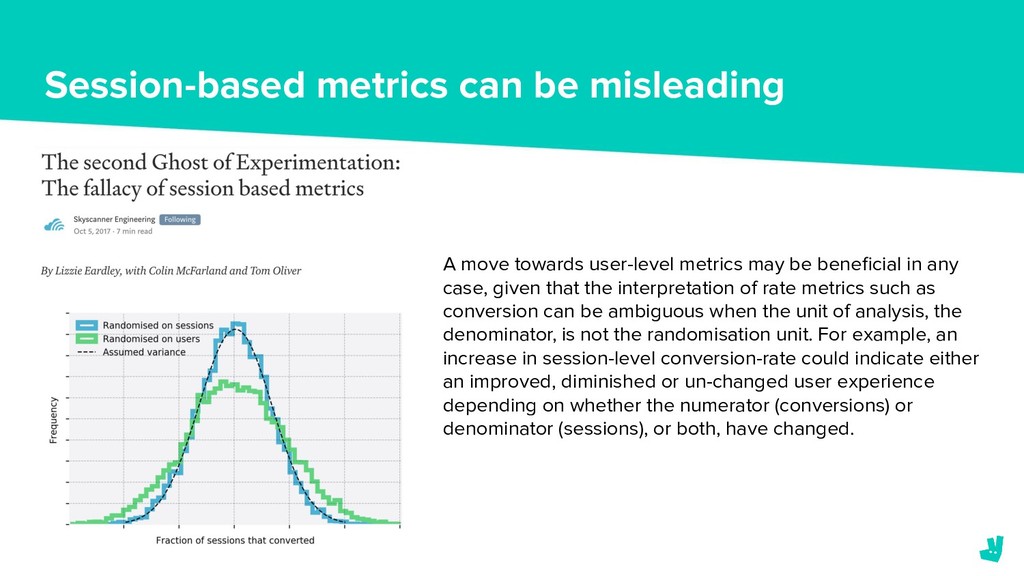{kind=link}
{kind=link}