Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Datadogはじめました! in 大阪; Moneyforward Session
Search
umisora
February 28, 2019
Technology
3.2k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Datadogはじめました! in 大阪; Moneyforward Session
Datadogはじめました! in 大阪 - connpass
https://datadog.connpass.com/event/119412/
に登壇した時の資料です。
umisora
February 28, 2019
More Decks by umisora
See All by umisora
三度のスクラムを失敗した私が選んだ四度目のスクラムはコーチングを頼む事だった。
umisora
5
3.7k
A lot of Bots in Money Forward
umisora
0
460
企画をして実現するテクニック
umisora
1
660
MoneyForward Developers’ Stories Kyoto
umisora
0
1.9k
「なんとなく、ずっと東京かな」 を変えた子育て
umisora
0
87
Other Decks in Technology
See All in Technology
オートマトンと字句解析でRoslynを読む
tomokusaba
0
130
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
180
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
440
害獣害虫を自動判別! ペストコントロール支援ビジネス成功のヒント【SORACOM Discovery 2026】
soracom
PRO
0
130
CloudWatchから始めるAWS監視
butadora
0
300
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
3
280
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
AI時代の強いチームの作り方
yuukiyo
12
7.5k
データ組織の転換期 一足飛びしない段階的戦略
leveragestech
PRO
0
120
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
270
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
220
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
Odyssey Design
rkendrick25
PRO
2
740
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
YesSQL, Process and Tooling at Scale
rocio
174
15k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
We Are The Robots
honzajavorek
0
290
The browser strikes back
jonoalderson
0
1.4k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
猫好きによる犬の飼い方 2019/02/29 村上 勝俊
名前 : 村上 勝俊 経歴 : インフラエンジニア マネーフォワード京都拠点所属 自己紹介
スライドは公開します。 QAタイムを最後に取ります。 スライドについては写真、TwitterOKですが、 私は写真が苦手です(笑) ※ QRリーダーのご用意をお願いします。 ※ 今日の登壇について
• マネーフォワードとは • 利用事例 • 運用の知見 • QA Time 今日の発表
• マネーフォワードとは • 利用事例 • 運用の知見 • QA Time 今日の発表
“マネーフォワードとは”
会社紹介
サービス紹介
会社紹介
会社紹介
会社紹介 ユーザーのためになることを、まずやってみる。 そこから失敗も成功もすべて受け止めて、前に進み続ける。 最初の一歩を自ら踏み出す事を最も大事にしよう。
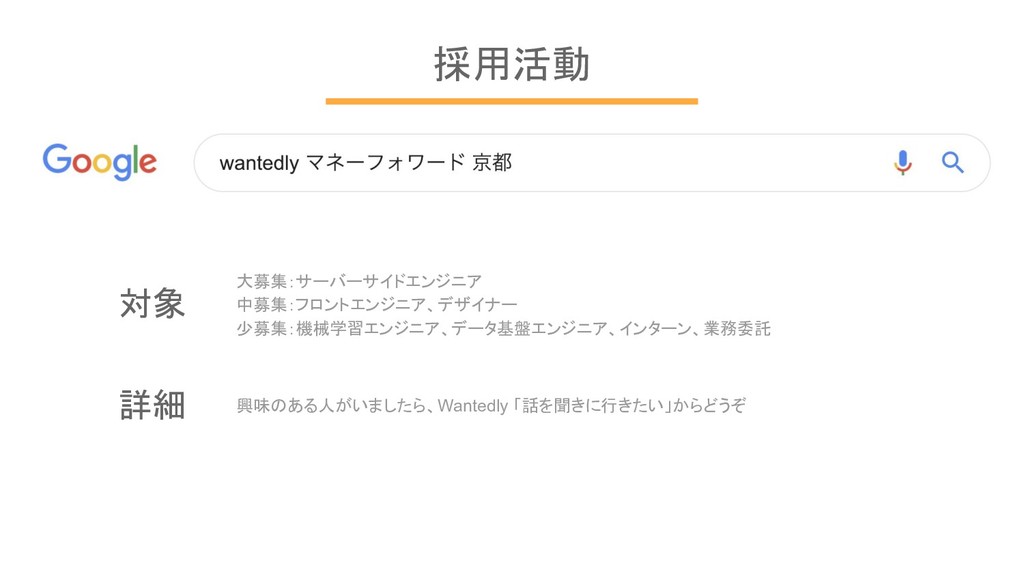
採用活動 大募集:サーバーサイドエンジニア 中募集:フロントエンジニア、デザイナー 少募集:機械学習エンジニア、データ基盤エンジニア、インターン、業務委託 興味のある人がいましたら、Wantedly 「話を聞きに行きたい」からどうぞ 対象 詳細
“サービスとシステム”
サービス紹介
システム ※ 非常にデフォルメされています。
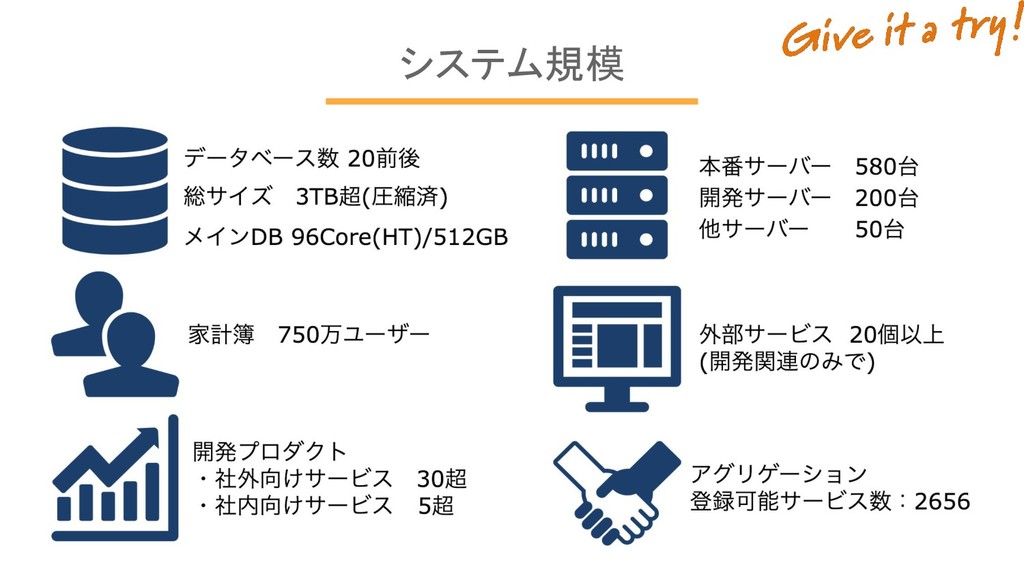
システム規模
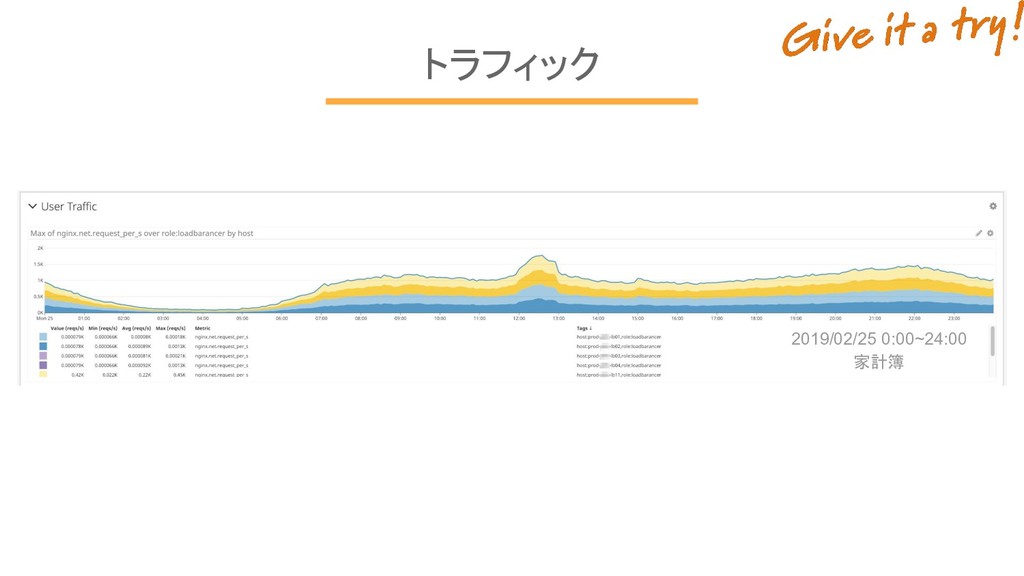
トラフィック 2019/02/25 0:00~24:00 家計簿
システム監視 [Xymon監 視](https://www.skyhobbit.co.jp/xymon/index_c2_s2.html ※ 本番ではない
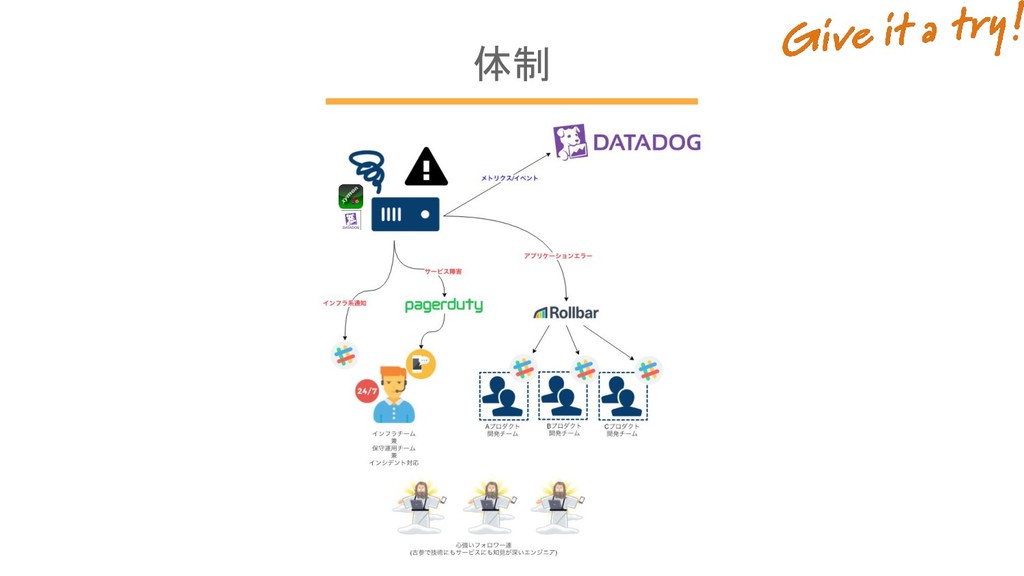
体制
“利用事例”
起きている問題 高負荷クエリ、広域DBロック、ネットワーク障害、急激なCPU,Memの使用・枯渇等の様々な障害 が起きてシステムダウンや詰まりが起きるが経路が複雑で特定に時間がかかる 開発案件毎にミドルウェアの種類が増えていくがメトリクスが取得できない 監視ボードから原因追うのが専門職状態 (AppEngrがとっつきにくい) 細かいメトリクスの確認(丸め)や過去の数字との比較ができない マルチクラウド時に監視システムの保守や経路確保が辛い XymonのインストールがOS変わると動かない。 カスタムプラグイン書くの…?誰が使うねん。
コンテナに対応していない。 モチベーションわかない、モチベーションわかない。モチベーションわかない。 システム トラブル 運用苦労 誰も障害対応に参加してこれない 開発チームからの主体的なアクションが取りづらい
我々の目指す所 スケールするサービスに柔軟に対応し、 適切に権限を移譲し サービス開発チームが、自律的に保守運用に関われる状態にしたい。 DevチームとOpsチームがハートフルでDevOpsじゃなくて、 自律的にDevもOpsもやる時代。 それがクオリティとスピードにつながる。という考え方。
“そこでDatadogですよ”
• マネーフォワードとは • 利用事例 • 運用の知見 • QA Time 今日の発表
メトリクスはとにかく取る事だけを考えたら良い。 エンジニアは見る事だけを考えればいい。 監視サービスの運用と保守はお任せ。 接続要件も単一。 監視ツールの開発・拡張は巨人の肩にのる。 使いたいな、見たいなと思った時には既に機能が存在する。 監視を工夫して運用する事からの開放
活用事例① (インテグレーション) 圧倒的な数の連携ミドルウェア、OS、XaaS More than 250 built-in integrations
活用事例① (インテグレーション) 標準でテンプレートが用意されていて穴埋めする だけで監視が開始できる。 誰でも設定できる。 監視対象として対応可能か?も判断できる。 エンジニアから自立的に具体的な設定や設定依 頼をしてくれる様になった。
活用事例② (XaaSインテグレーション) 他社XaaSのメトリクスも取れる。 もちろんAWS、GCP、Azure等の各クラウドの監視 サービスも連携可能 (XaaSインテグレーションはコストがかからないケー スが多いのでコスト面でやりくりしたい時にはおすす め)
活用事例② (XaaSインテグレーション) 例えば • Fastly連携は無料 • AWSはEC2とECSを連携しなければ無料 • Prometheus使ってたとしてもDatadogに投入可 能(メトリクス次第では低コスト
) Introducing Prometheus support for Datadog Agent 6 | Datadog https://www.datadoghq.com/blog/monitor-prometheus-metrics/ • そう。Jenkinsもね。 Monitor Jenkins jobs with Datadog | Datadog https://www.datadoghq.com/blog/monitor-jenkins-datadog/
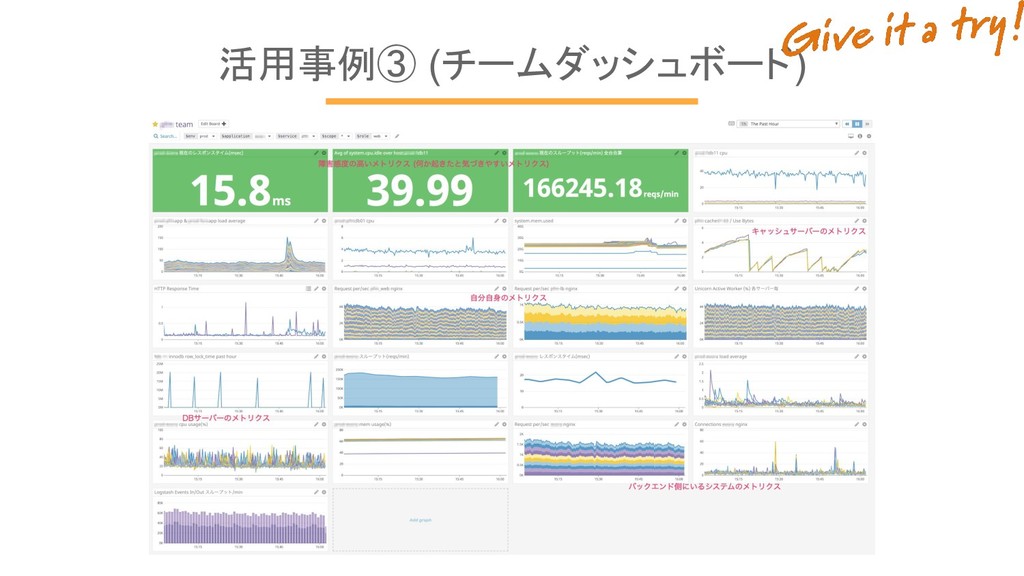
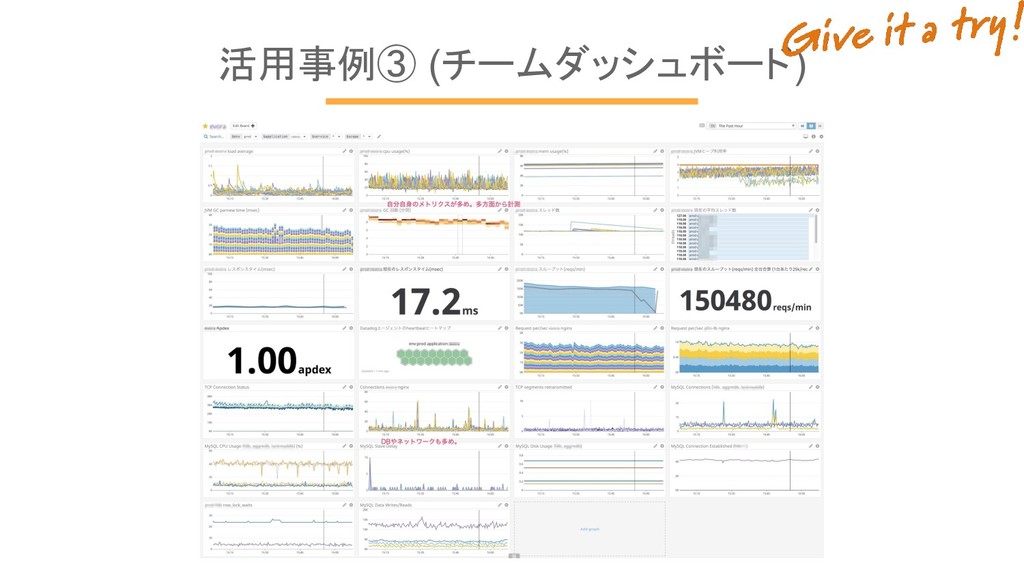
活用事例③ (チームダッシュボード) 情報さえ与えればエンジニアは自分達で追い始める。 “メトリクス”は大好物。 DatadogはViewの動きが速いので高評価 過去のデータ保存期間が長いのも稀有
活用事例③ (チームダッシュボード)
活用事例③ (チームダッシュボード)
活用事例③ (チームダッシュボード) チームにサイネージを用意
活用事例③ (チームダッシュボード) • 自分たちでアラートを設定し始める。 • ダッシュボードを育て始める。 • 障害やヒヤリハットを糧としてモニタリングが自律的に育つ。 ダッシュボードを手配した事で。 インフラチームに頼まれる作業は0!
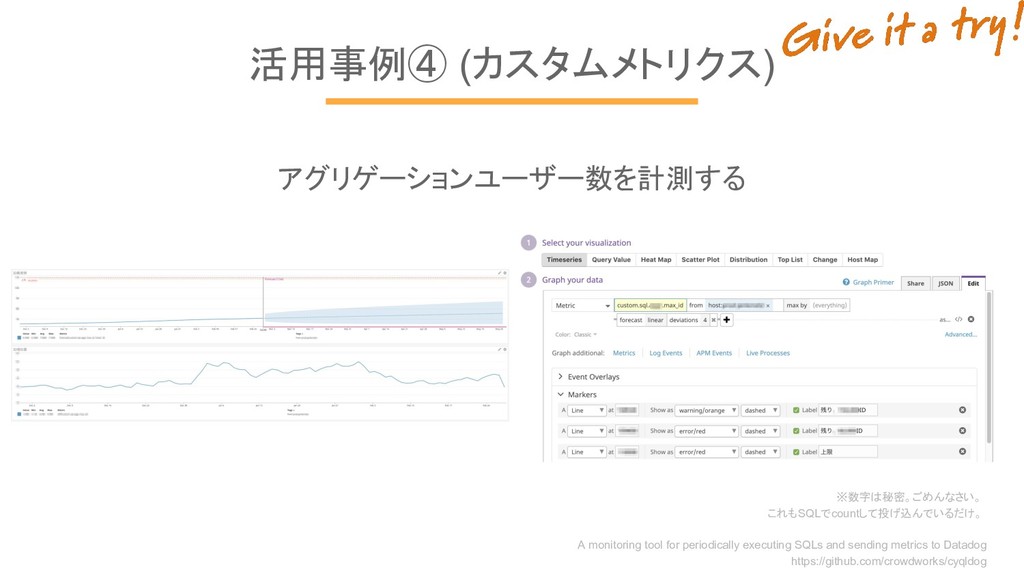
活用事例④ (カスタムメトリクス) それでも、対応してないサービスやミドルウェアが ありますよね。 自作も比較的簡単なので一例を紹介。 参考:Agent Checkの書き方 https://docs.datadoghq.com/ja/guides/agent_checks/
活用事例④ (カスタムメトリクス) 参考:Agent Checkの書き方 https://docs.datadoghq.com/ja/guides/agent_checks/
活用事例④ (カスタムメトリクス) UnicornのWorkerの状態を計測する
活用事例④ (カスタムメトリクス) アグリゲーションユーザー数を計測する ※数字は秘密。ごめんなさい。 これもSQLでcountして投げ込んでいるだけ。 A monitoring tool for periodically
executing SQLs and sending metrics to Datadog https://github.com/crowdworks/cyqldog
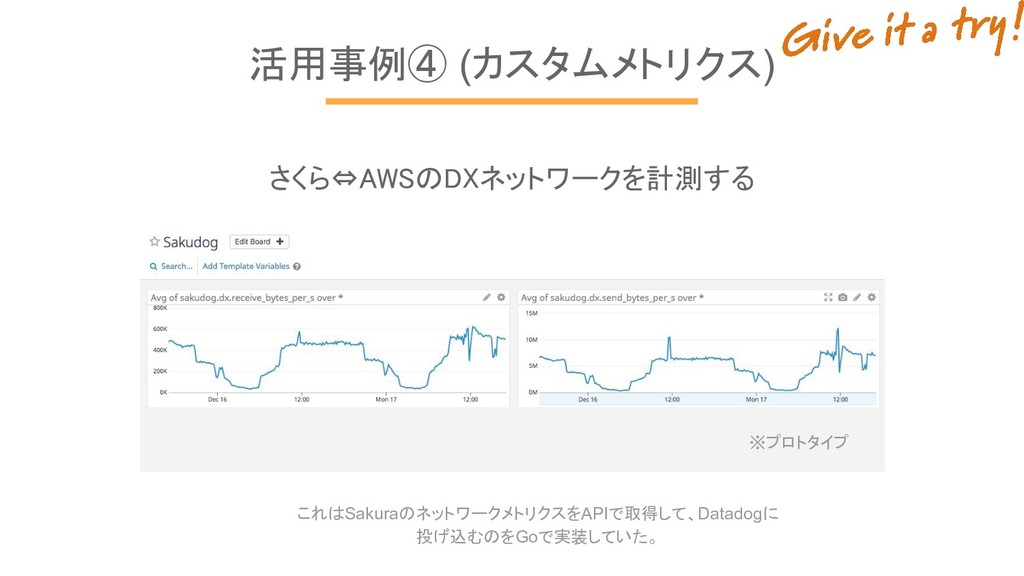
活用事例④ (カスタムメトリクス) さくら⇔AWSのDXネットワークを計測する ※プロトタイプ これはSakuraのネットワークメトリクスをAPIで取得して、Datadogに 投げ込むのをGoで実装していた。
活用状況 機能 利用 コメント SystemMonitoring ◎ 本番環境積極利用中 APM △ NewRelicが主流の為、率先しては利用してない。
LogManagement △ 利用したいが手がまわっていない。 Service Map ✕ APMを使わないと使えない。まだそこまで成熟してない。 Synthetics ◯ βの不安定さが解消されたら外形監視は乗り換え予定 外形監視、ログイン監視、 API監視、証明書監視に対応 Notebook △ 障害テストやパフォーマンステストで記録として偶に使ってい る。Slack通知してそのPostを引用して会話する事や、 esaにレ ポートをまとめる事が多いのであんまり。 過去データが消えると困るものだけスナップしている。
• マネーフォワードとは • 利用事例 • 運用の知見 • QA Time 今日の発表
良かった事 導入が簡単。メトリクスの取得も簡単なので気軽に取ればいい。 データが多いほど感謝される。Provisionが出来てれば as a Codeもやりやすそう。 マルチクラウドにおいて本領発揮。 監視システムの保守不要!! タグ便利。 反映&描画が速い。グラフが綺麗。もだ〜ん。
チームにフィットしたグラフが作れる。勝手に作れる。 公式Docが充実しているのでメトリクスも自分で調査できる。 Slackの通知の実装もシュッ。アラートも自分たちで育てられる。 障害箇所の把握が簡単になった(すぐに原因調査や関連グラフに取り掛かれる様になった。) 長期間データが残っている (15秒間隔データが15ヶ月) インフラチーム 開発チーム 安定して自主的にやれる環境が整った。 インフラエンジニアのボトルネックも解消した。
良かった事 コンテナ化、Serverless化、HPC、分散技術等を 取り入れてもDatadogで付き合っていけそうなのが頼もしい。 インフラの進化が激しい時代に入ったが、 インフラの進化に追従するための非機能要件(※)の工数が 非常に大きくなりがち。 メインが進化するまでは可能な限り外注したい。 ※ 監視、バックアップ、運用、セキュリティ、保守ツール、ジョブスケジューラー等々
辛かった事 ダッシュボード難しい。 コスト高い。 開発環境に入れられない!!(高いから) confの管理が難しい。 ダッシュボード難しい。 外形監視がなかった。(※) タグ管理便利だけど難しい。 外部サービスのメトリクスの連携速度が遅い。(瞬発力が必要なメトリクスのアラートに使えない) インフラチーム
開発チーム もっと安かったら総入れ替えするのに!! ※ Syntheticsβが来たので解消予定。但しまだ不安定。
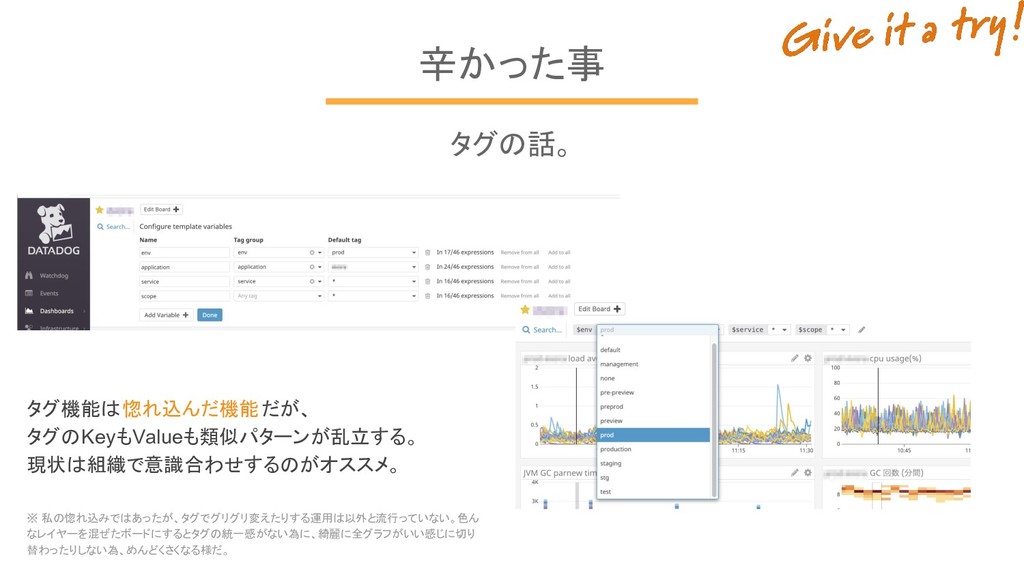
辛かった事 タグの話。 ※ 私の惚れ込みではあったが、タグでグリグリ変えたりする運用は以外と流行っていない。色ん なレイヤーを混ぜたボードにするとタグの統一感がない為に、綺麗に全グラフがいい感じに切り 替わったりしない為、めんどくさくなる様だ。 タグ機能は惚れ込んだ機能だが、 タグのKeyもValueも類似パターンが乱立する。 現状は組織で意識合わせするのがオススメ。
辛かった事(ご提案) 何より安くなると進めやすい。総入れ替えしやすい。 特に開発環境が致命的に辛い。 ので、データ保存期間が3dayくらいで、 アラート設定がn個までとか制約があってもいいので Free or ディスカウントが欲しいです!!!!!!!!!!
“グッド(?)・プラクティス”
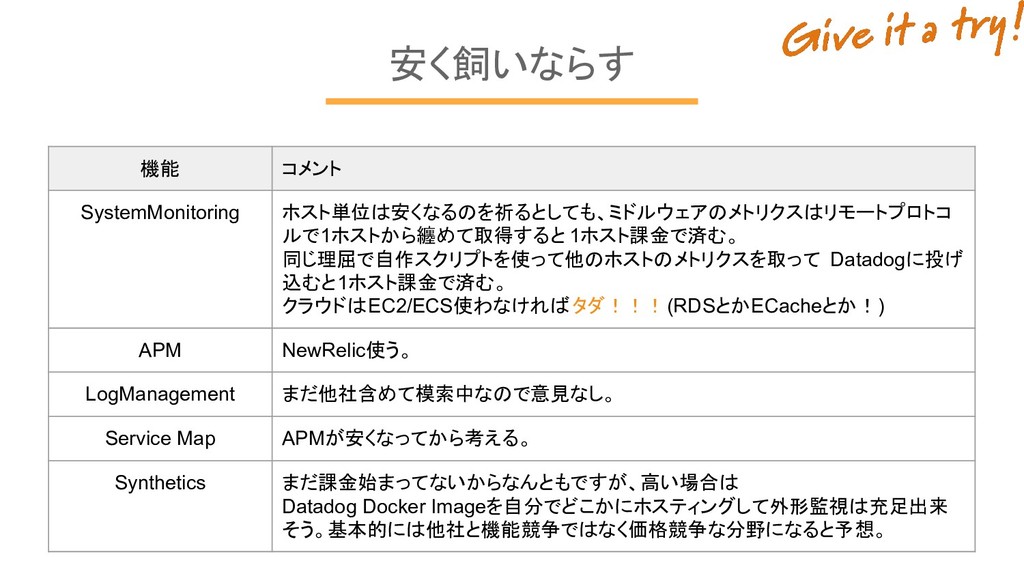
安く飼いならす 機能 コメント SystemMonitoring ホスト単位は安くなるのを祈るとしても、ミドルウェアのメトリクスはリモートプロトコ ルで1ホストから纏めて取得すると 1ホスト課金で済む。 同じ理屈で自作スクリプトを使って他のホストのメトリクスを取って Datadogに投げ 込むと1ホスト課金で済む。
クラウドはEC2/ECS使わなければタダ!!!(RDSとかECacheとか!) APM NewRelic使う。 LogManagement まだ他社含めて模索中なので意見なし。 Service Map APMが安くなってから考える。 Synthetics まだ課金始まってないからなんともですが、高い場合は Datadog Docker Imageを自分でどこかにホスティングして外形監視は充足出来 そう。基本的には他社と機能競争ではなく価格競争な分野になると予想。
アンバサダー 啓蒙活動について。 • 開発チームにはグラフとか、メトリクスとか、深く知っていきたい奴が必ずいる。 その人にいいViewとデータを提供すると自律的に動き始める。唆しオススメ • お悩み相談/グラフ作成の寺子屋をやると加速する。 • ダッシュボードの作成も最初手伝うと非常に良い。 •
任意のグラフもガンガン検索可能だと広まれば障害調査/パフォーマンス調査では Datadogが優位にたてる。障害調査の時には 「それDatadogで見れるで」って言って調べてあげると「ええやんこれ。」
Thank you!
引用表記 画像/ドキュメント: Modern monitoring & analytics | Datadog https://www.datadoghq.com/ Datadog
Docs https://docs.datadoghq.com/ Datadogでメトリクスの監視を始めよう! https://docs.datadoghq.com/ja/ Datadog fastly yamagoya_summit2017 https://www.slideshare.net/MasahiroHattori2/datadog-fastly-yamagoyasummit2017/26 Monitor Jenkins jobs with Datadog | Datadog https://www.datadoghq.com/blog/monitor-jenkins-datadog/ 製図ロゴ/イラスト: Untitled Diagram - draw.io https://www.draw.io/ システム構成図やプレゼンテーション資料などで自由に使える「さくらのアイコンセット」を公開いたしました。 | さくらのナレッジ https://knowledge.sakura.ad.jp/4724/ かわいいフリー素材集 いらすとや https://www.irasutoya.com/ VPS|ドメイン取るならお名前 .com https://www.onamae.com/server/vps/?btn_id=sv04 WordPress https://ja.wordpress.org/ Error Tracking & Crash Reporting for Software Developers - Rollbar https://rollbar.com/ PagerDuty https://www.pagerduty.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}