to determine their creditworthiness ▧ Lack of credit history ▧ Tiny data ▧ Enrich data with alternate data sources ▧ Statistical modelling to evaluate students initially. ▧ As the user activity increases, build machine learning models to predict creditworthiness.
for the next 6 months ▧ Complexity of data science algorithms ▧ No. of calls being serviced by the data science APIs ▧ Cost AWS instance x1, 8 GB ram, 4 cores
Go behind low hanging fruits first ▧ Need clever techniques ▧ Beware of data sanity with NoSQL ▧ Embracing data science early helps the business grow taller, stronger & sharper
behavior ▧ Business has amassed data over 2-3 years ▧ Educate team about data science & benefits ▧ Ideate & prioritize problems that can be solved ▧ RoI, pricing for new plugins
rows ▧ Parallel Analytics data warehouse ▧ Data pipelines, automated workflows ▧ Distributed machine learning models ▧ Prediction as a Service ▧ Cost Dedicated bare metal server 32 GB ram | 8 cores | 1 TB SSD
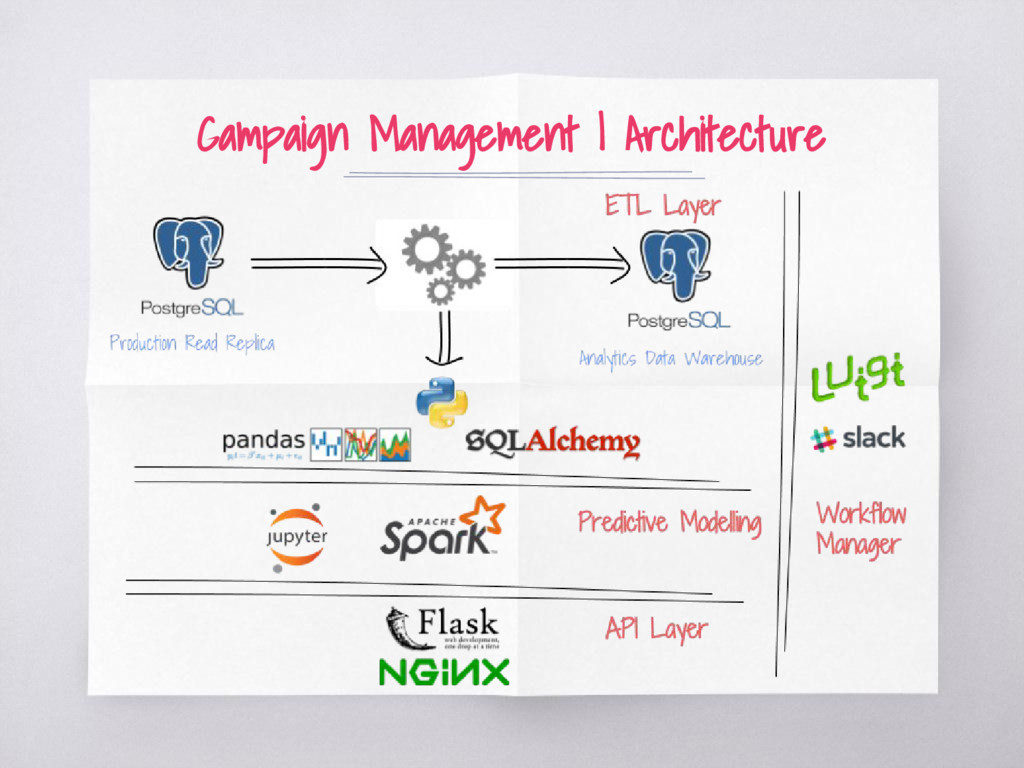
running queries ▧ Understand postgresql WALs ▧ Data pipelines break. Exception handling, notifications, logging is utmost important ▧ We wired luigi exceptions to slack for notifications ▧ Pandas transformations are slow for large datasets ▧ PySpark to the rescue! ▧ Use monitoring tools like Munin for profiling
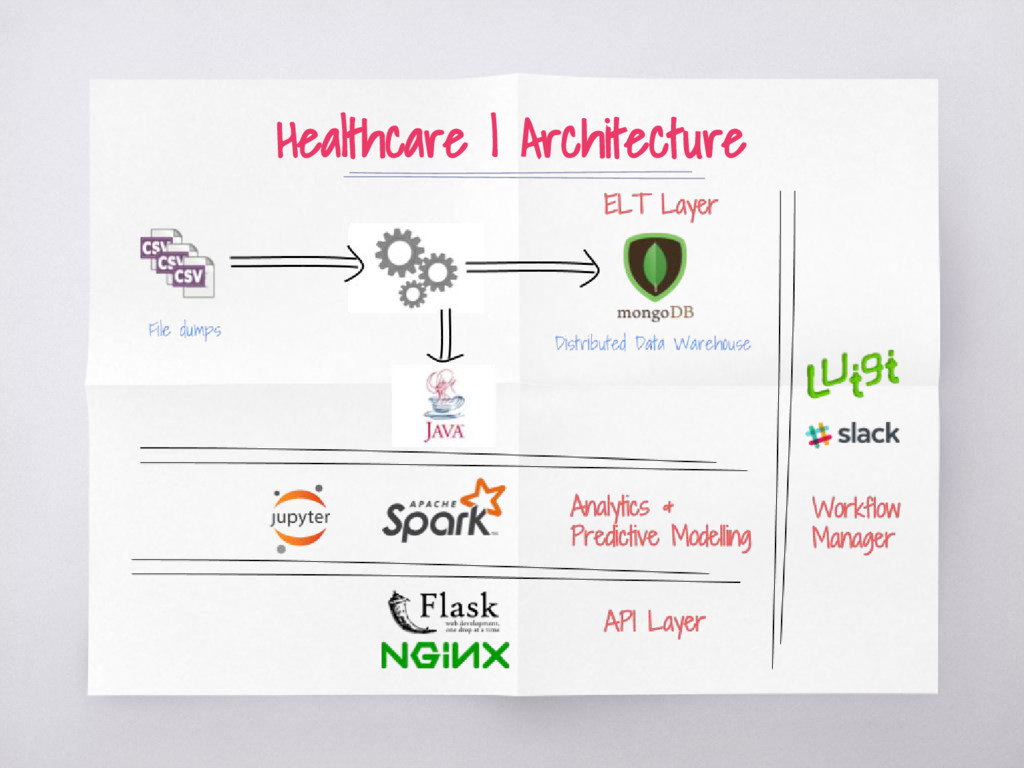
spend ▧ Medical claims - many data providers - no standard ▧ Data volume 500 M rows to start + high velocity ▧ Robust data ingestion, data cleaning system ▧ Data Security and HIPAA compliance ▧ Data pipeline is the heart of the platform
▧ Aim to parallelize tasks for ingestion ▧ Data redundancy is totally fine for data science ▧ Polyglot of services - Use the right tools ▧ Understand business expectations & landscape before jumping into architecture
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fin. Any questions? tweet : @unnati_xyz [email protected]](https://files.speakerdeck.com/presentations/67496c85f25e41b59a794acf6e0dabe6/slide_22.jpg){kind=link}