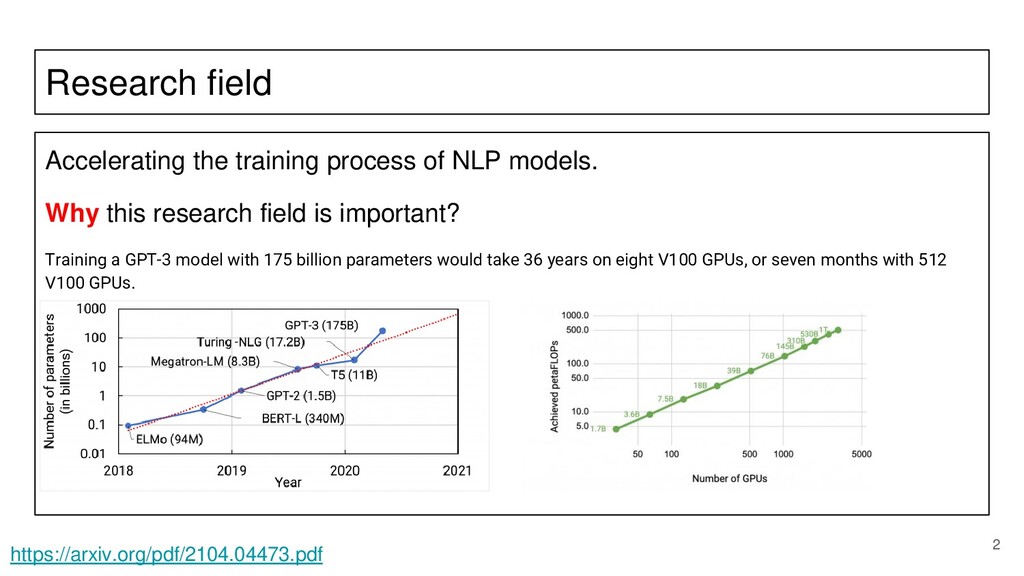
In this slide, I give an overview of efficient NLP research direction.
The reason why this research direction is important and should be considered.
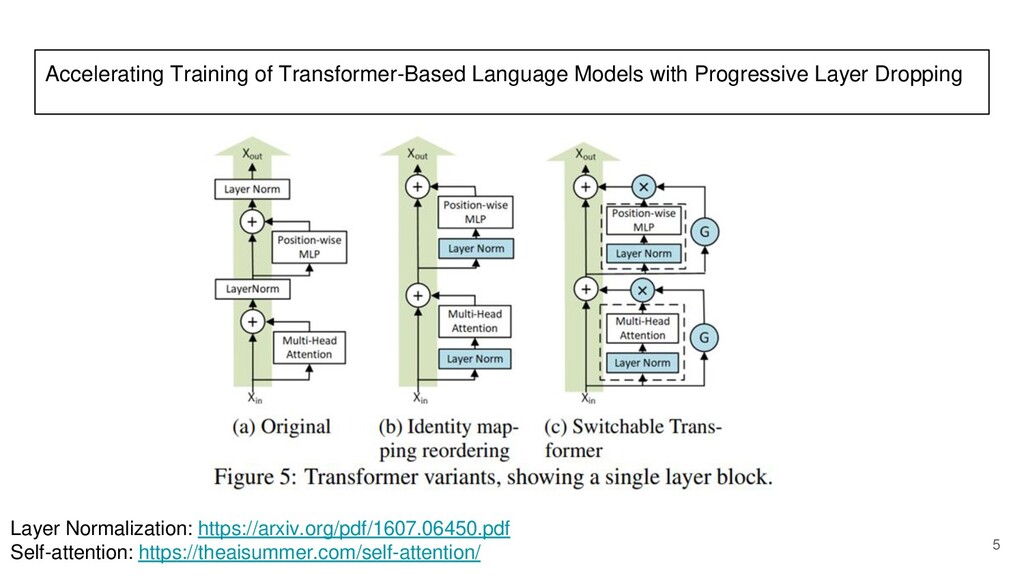
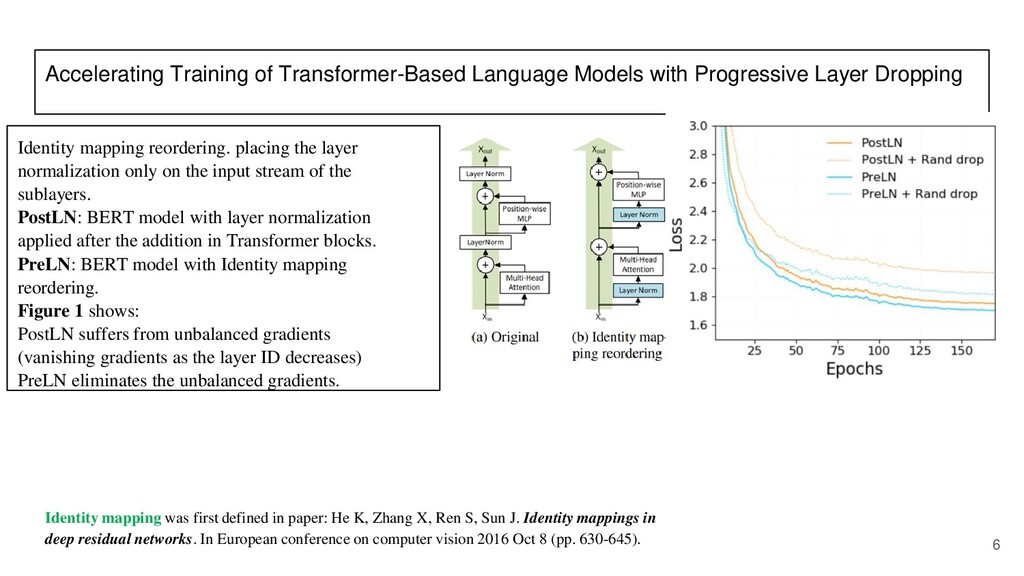
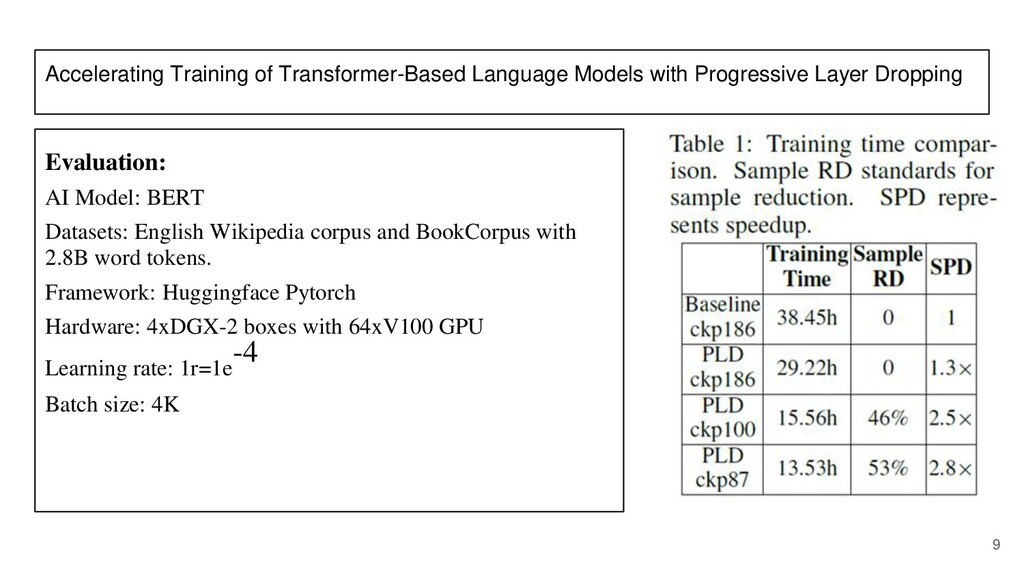
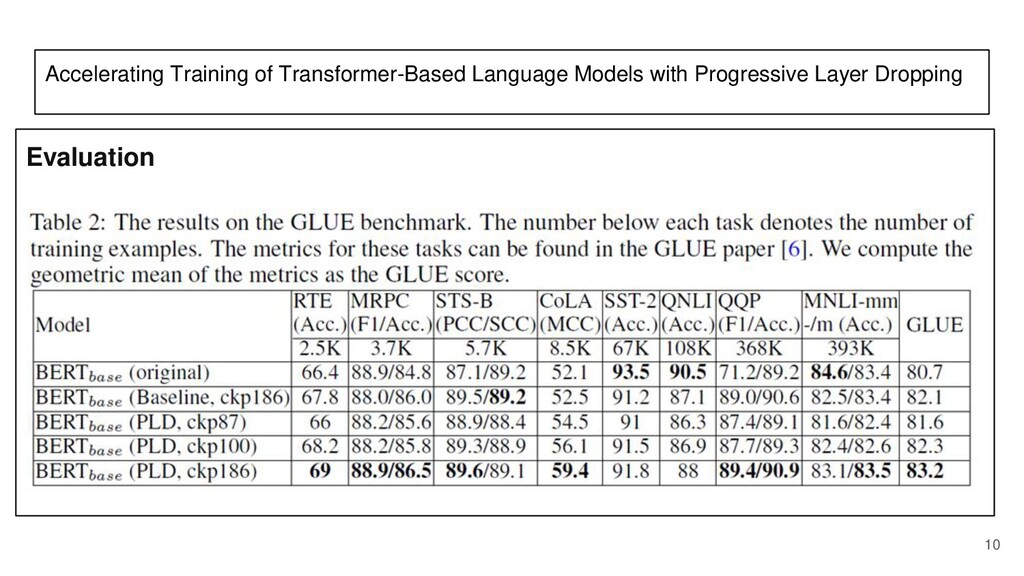
After that, there is a paper reading section about the paper: "Accelerating Training of Transformer Based Language Models with Progressive Layer Dropping" that was published at NeurIPS 2020.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}