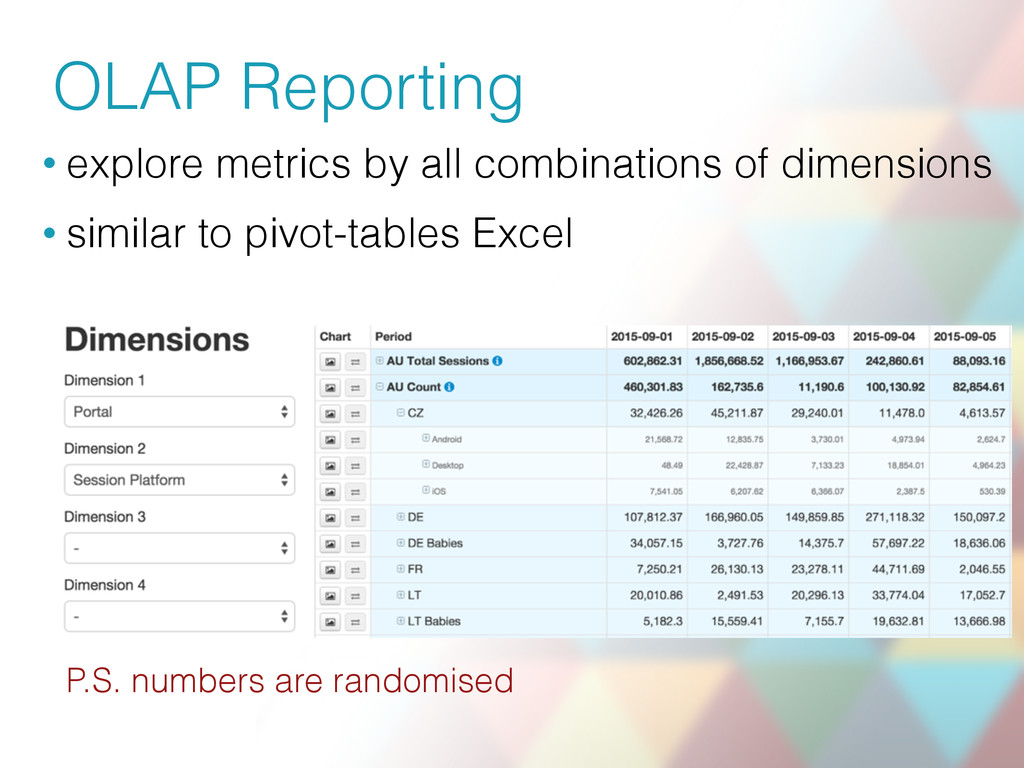
Once Vinted.com (a peer-to-peer marketplace to sell, buy and swap clothes) grew larger, demanding more advanced analytics, we needed a simple, yet scalable and flexible data-cubing engine. The existing alternatives (e.g. Cubert, Kylin, Mondrian) seemed not to fit, being too complex or not flexible enough, so we ended up building our own with Spark. We'll present:
- how DataFrames have proven to be the most flexible tool for fact preparation and cube input (c.f. typesafe Parquet-Avro schemas)
- how we support multivalued dimensions
- how we use Algebird aggregators for defining and computing our metrics
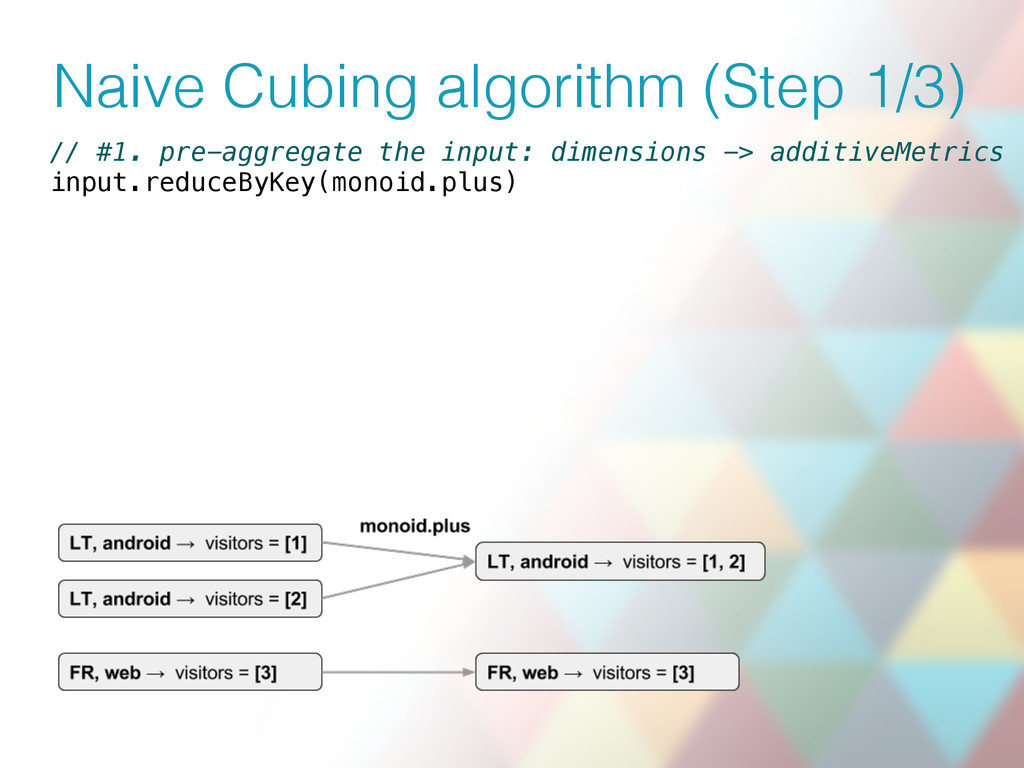
- how simple it is to get good cubing performance by pre-aggregating input before cubing with help of Algebird aggregators that are Semigroup-additive for free
- our HBase key design and optimizations such as bulk-loading to HBase, and how we read the cube back from HBase
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}