to graduate ;) • Working on program transformations focusing on data representation • Author of miniboxing, which improves generics performance by up to 20x • Contributed to the Scala compiler and to the scaladoc tool. @ @VladUreche @VladUreche [email protected] scala-miniboxing.org
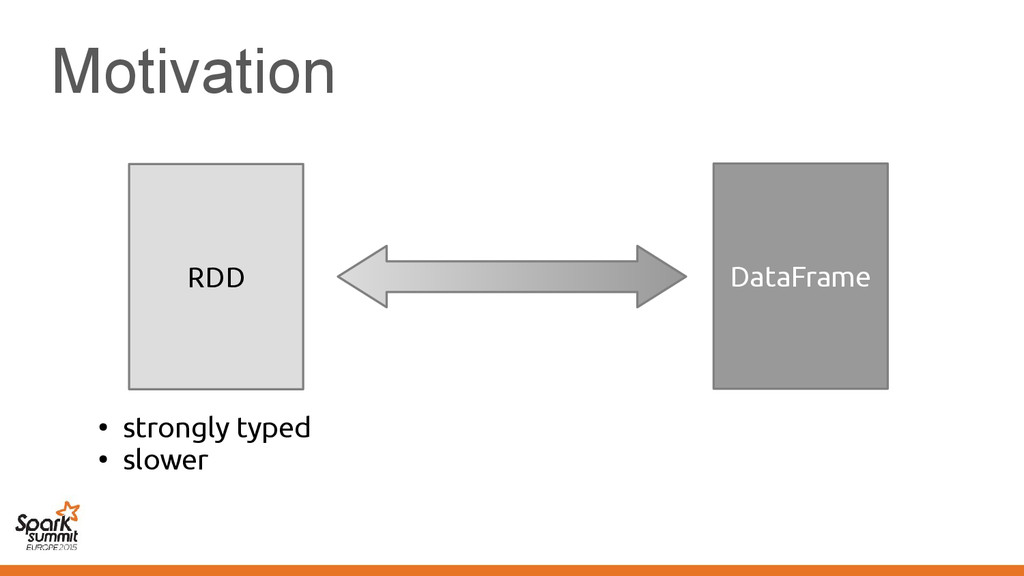
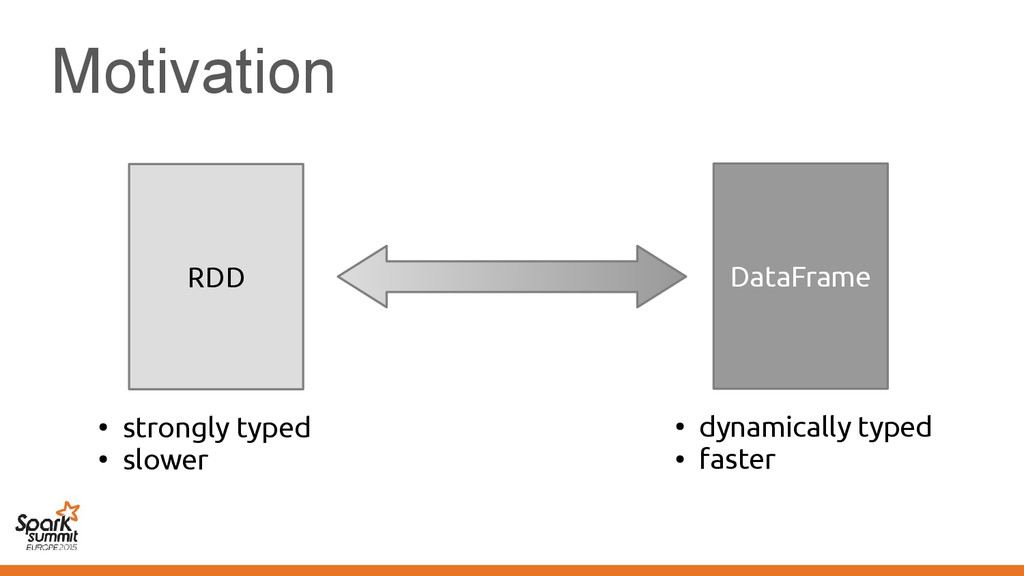
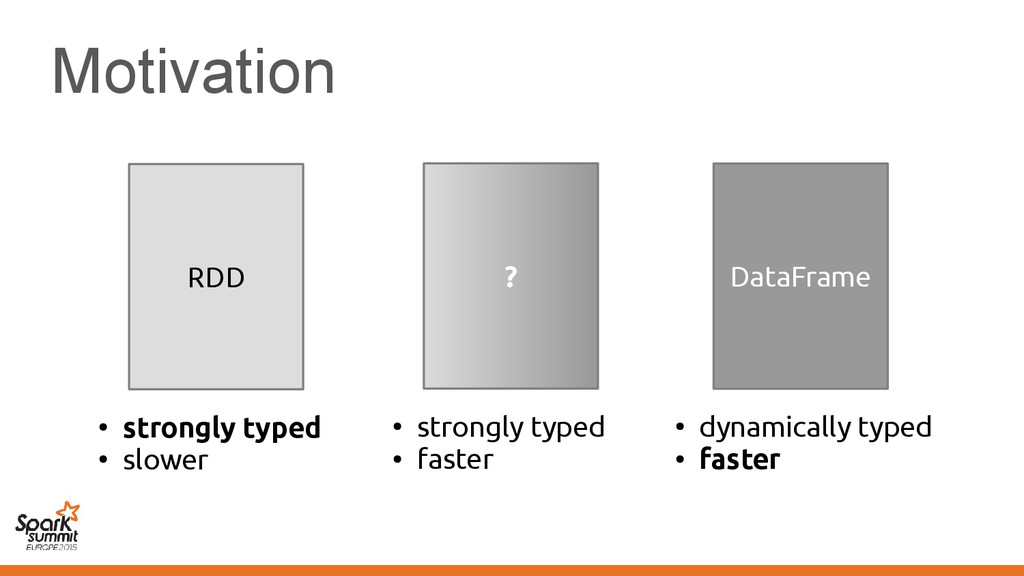
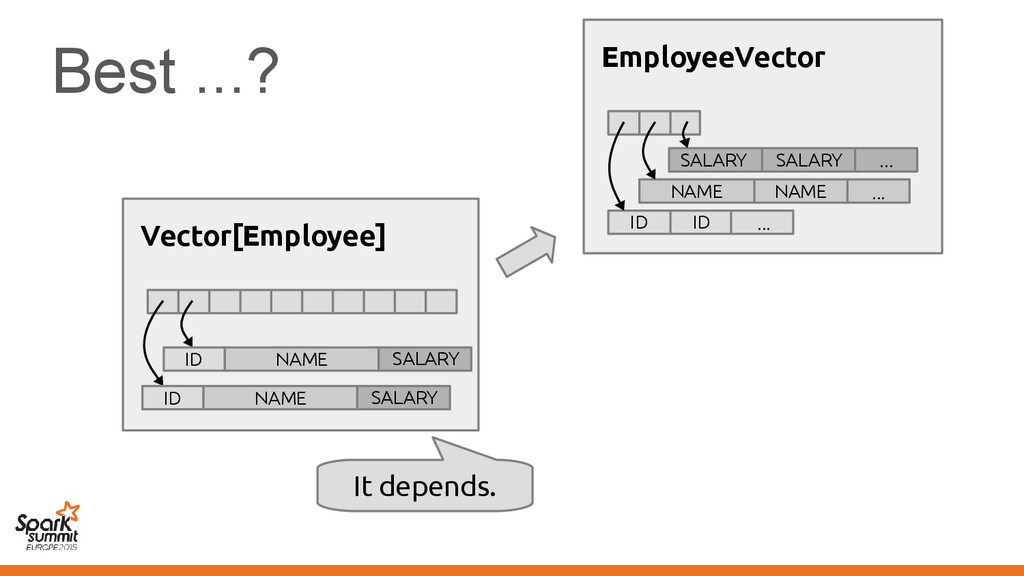
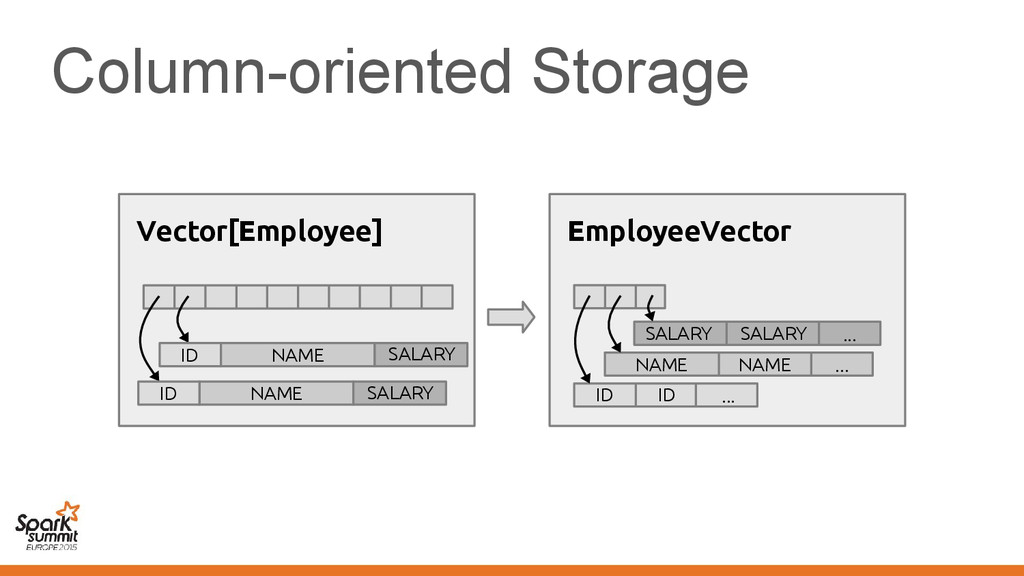
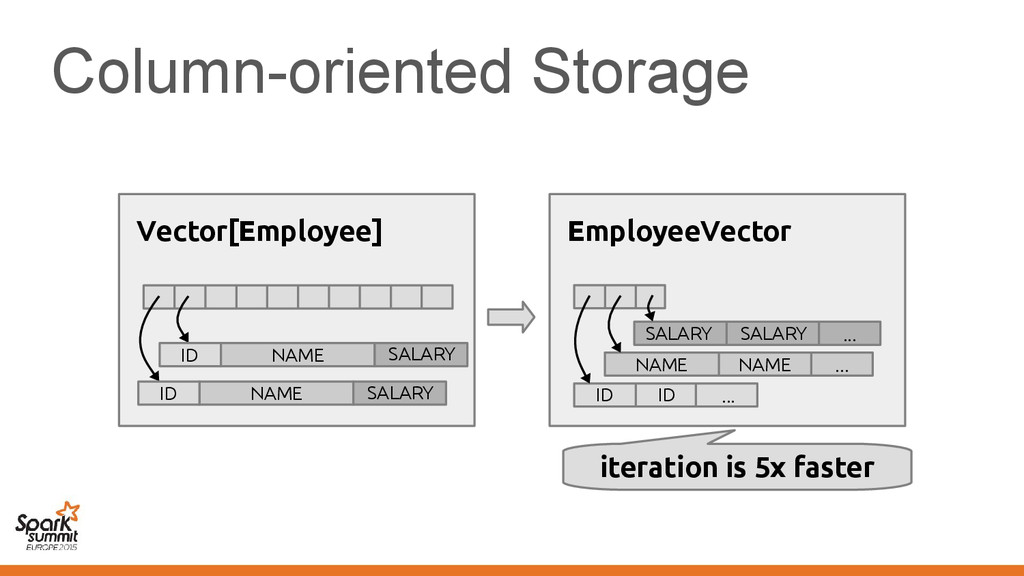
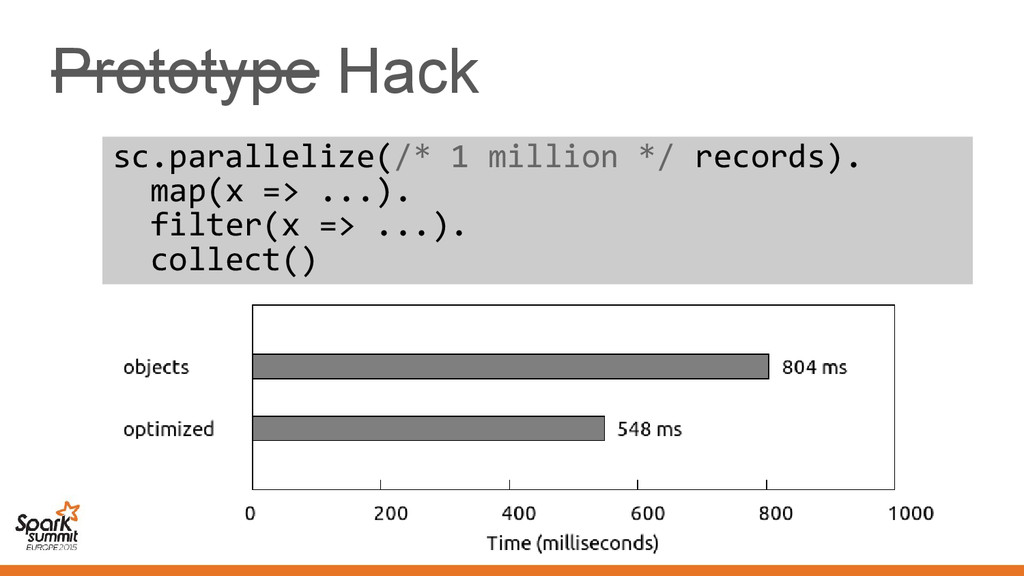
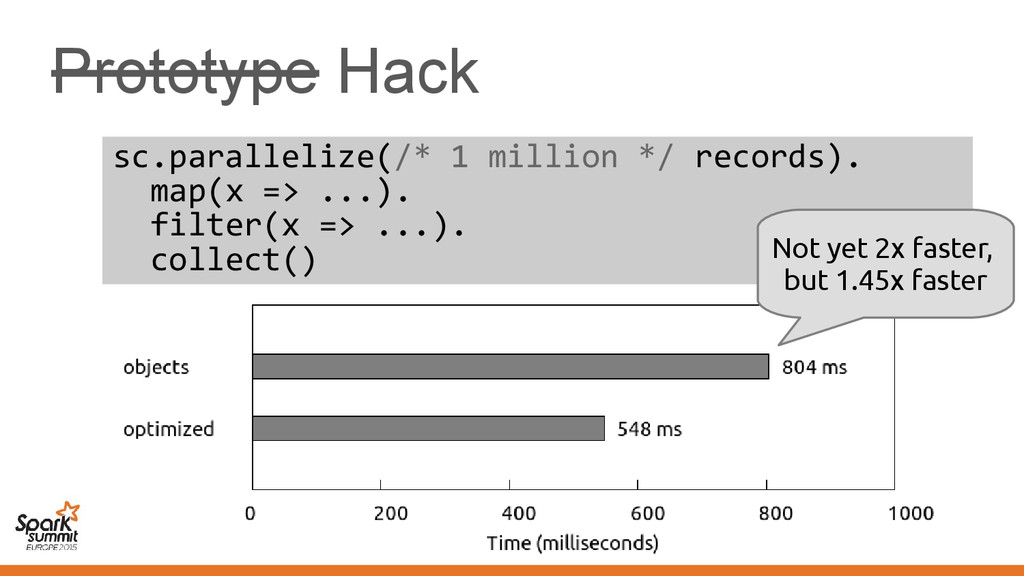
makes Vector[Employee] suboptimal • Not limited to Vector, other classes also affected – Spark pain point: Functions/closures – We'd like a "structured" representation throughout
makes Vector[Employee] suboptimal • Not limited to Vector, other classes also affected – Spark pain point: Functions/closures – We'd like a "structured" representation throughout Challenge: No means of communicating this to the compiler
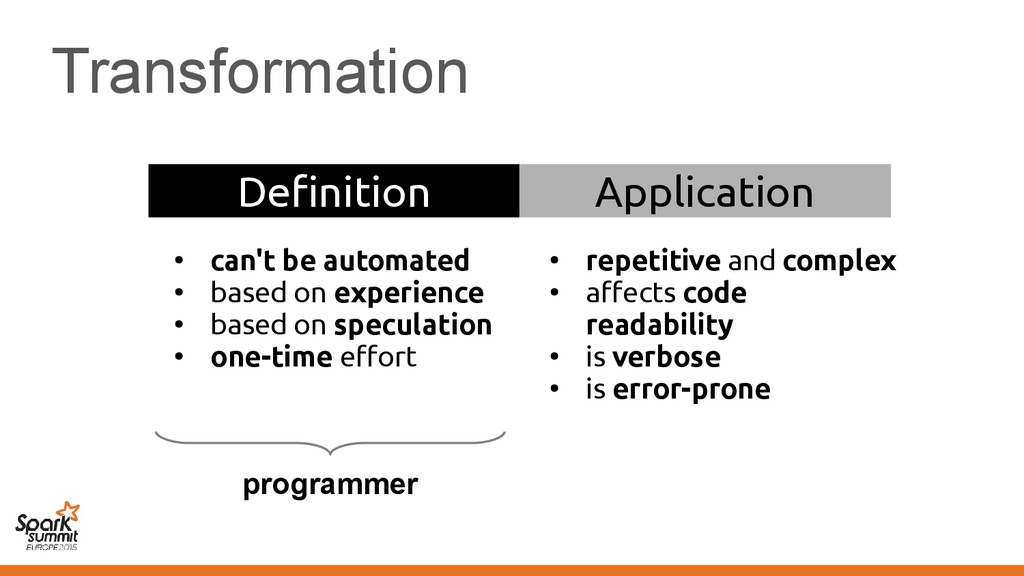
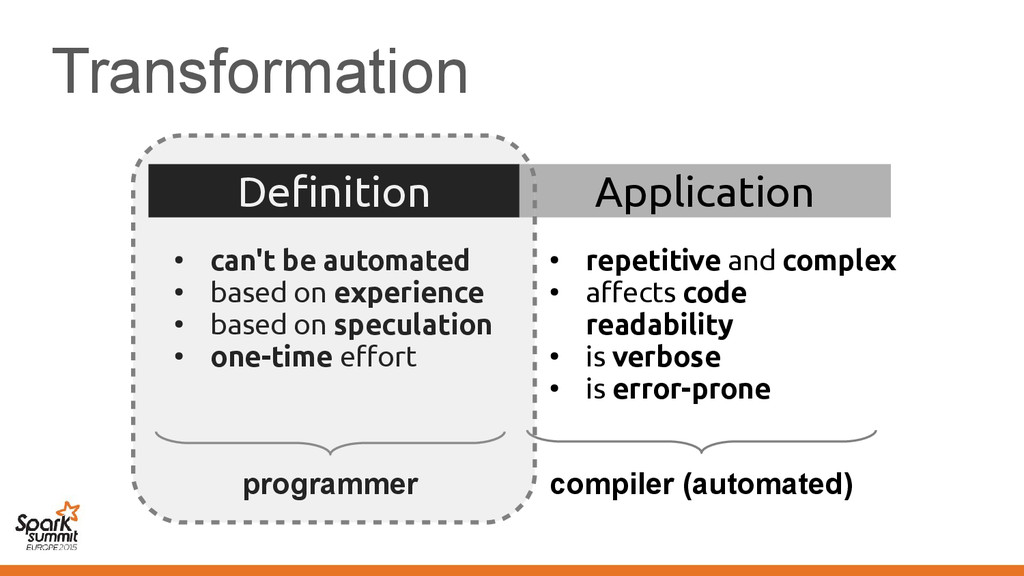
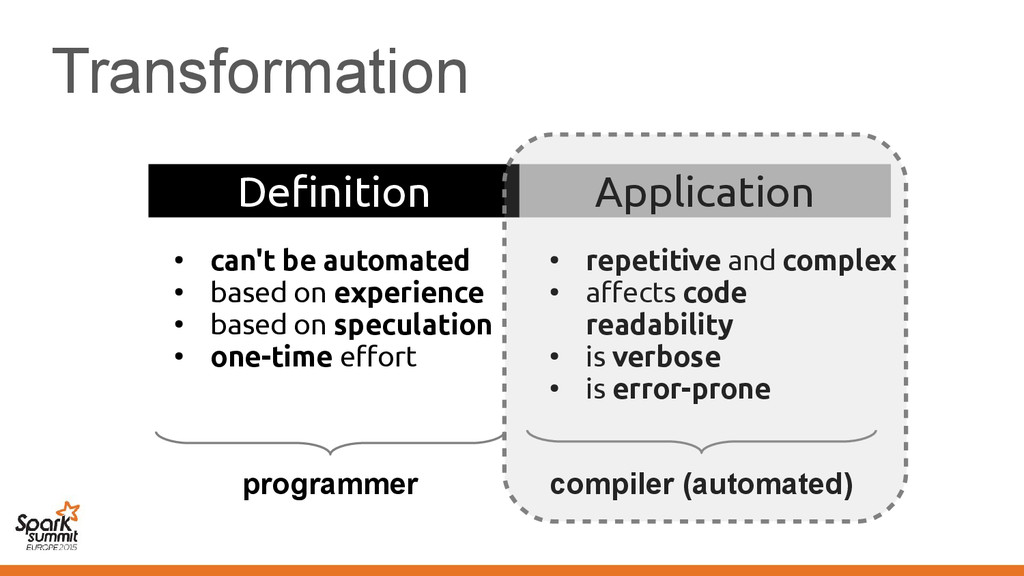
on experience • based on speculation • one-time effort • repetitive and complex • affects code readability • is verbose • is error-prone compiler (automated)
on experience • based on speculation • one-time effort • repetitive and complex • affects code readability • is verbose • is error-prone compiler (automated)
on experience • based on speculation • one-time effort • repetitive and complex • affects code readability • is verbose • is error-prone compiler (automated)
on experience • based on speculation • one-time effort • repetitive and complex • affects code readability • is verbose • is error-prone compiler (automated)
ID NAME SALARY class Vector[T] { … } NAME ... NAME EmployeeVector ID ID ... ... SALARY SALARY class NewEmployee(...) extends Employee(...) ID NAME SALARY DEPT
ID NAME SALARY class Vector[T] { … } NAME ... NAME EmployeeVector ID ID ... ... SALARY SALARY class NewEmployee(...) extends Employee(...) ID NAME SALARY DEPT
ID NAME SALARY class Vector[T] { … } NAME ... NAME EmployeeVector ID ID ... ... SALARY SALARY class NewEmployee(...) extends Employee(...) ID NAME SALARY DEPT Oooops...
Inlined immediately after the parser – Definitions are visible outside the "scope" • Mark locally closed parts of the code – Incoming/outgoing values go through conversions – You can reject unexpected values
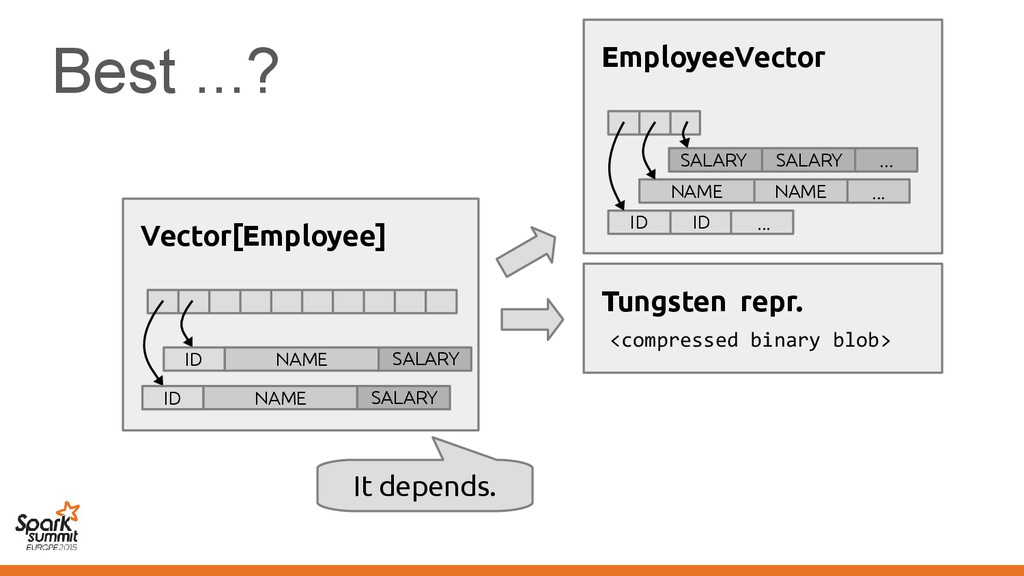
100 } Tungsten repr. <compressed binary blob> NAME ... NAME EmployeeVector ID ID ... ... SALARY SALARY It depends. Vector[Employee] ID NAME SALARY ID NAME SALARY
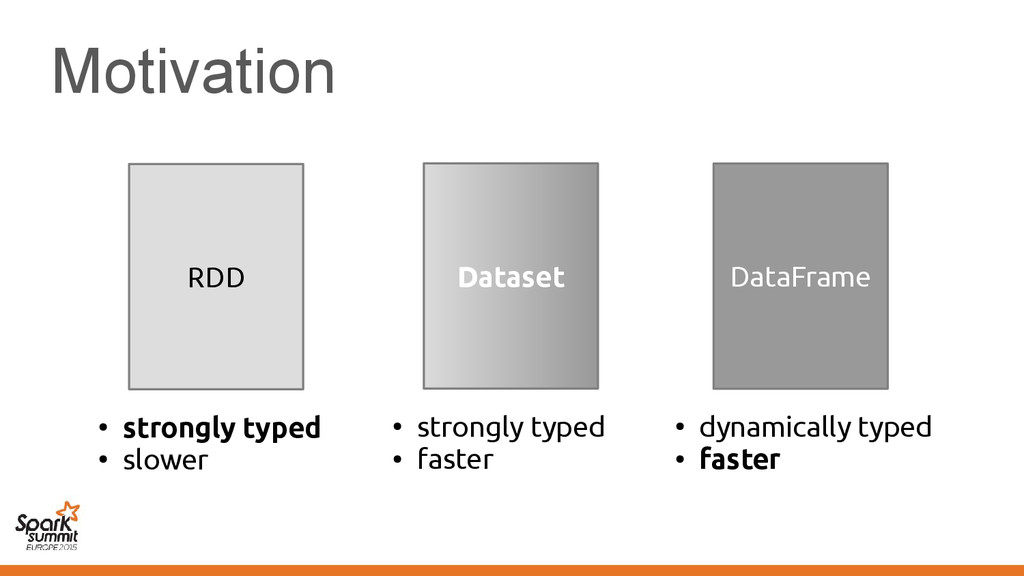
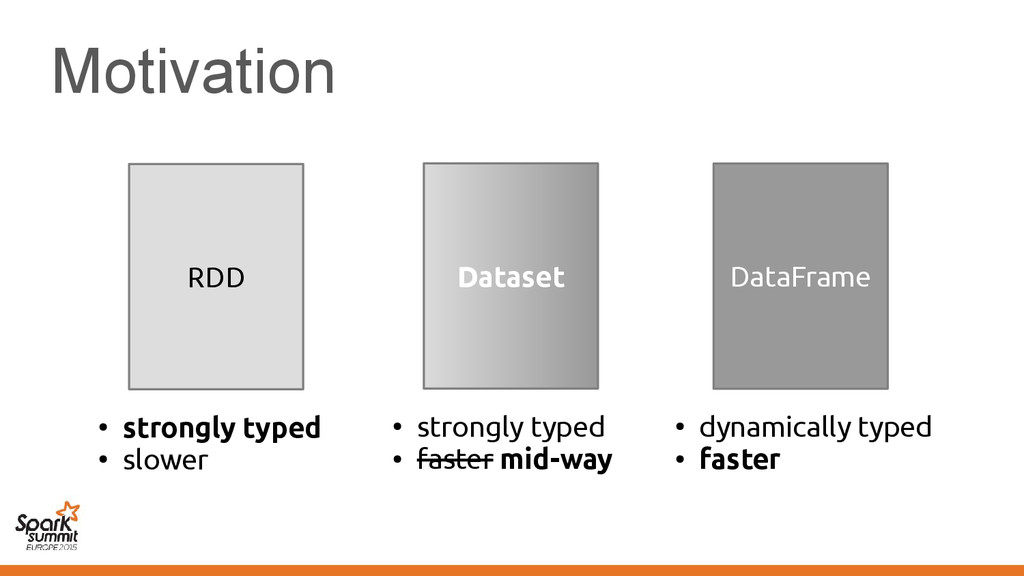
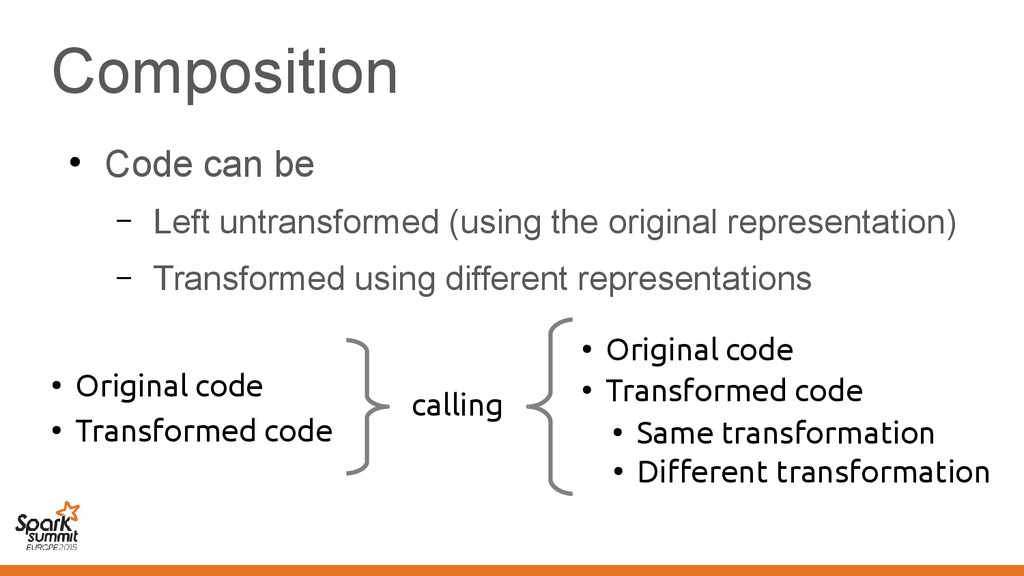
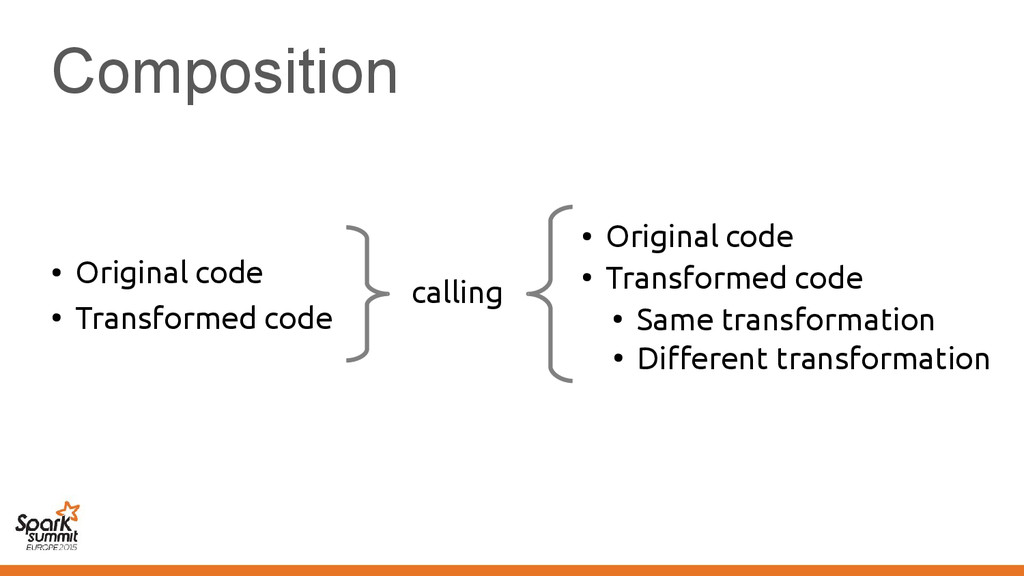
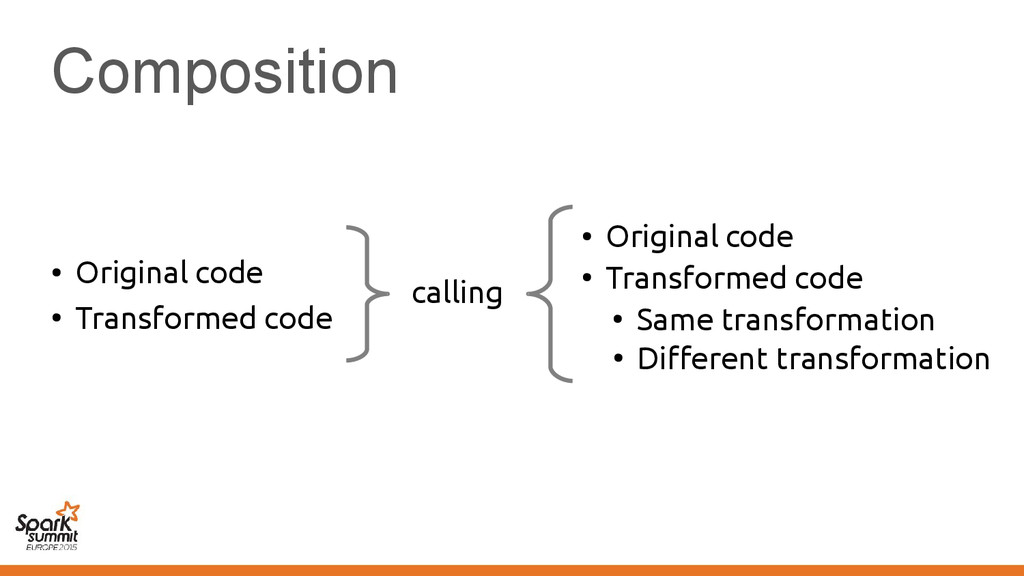
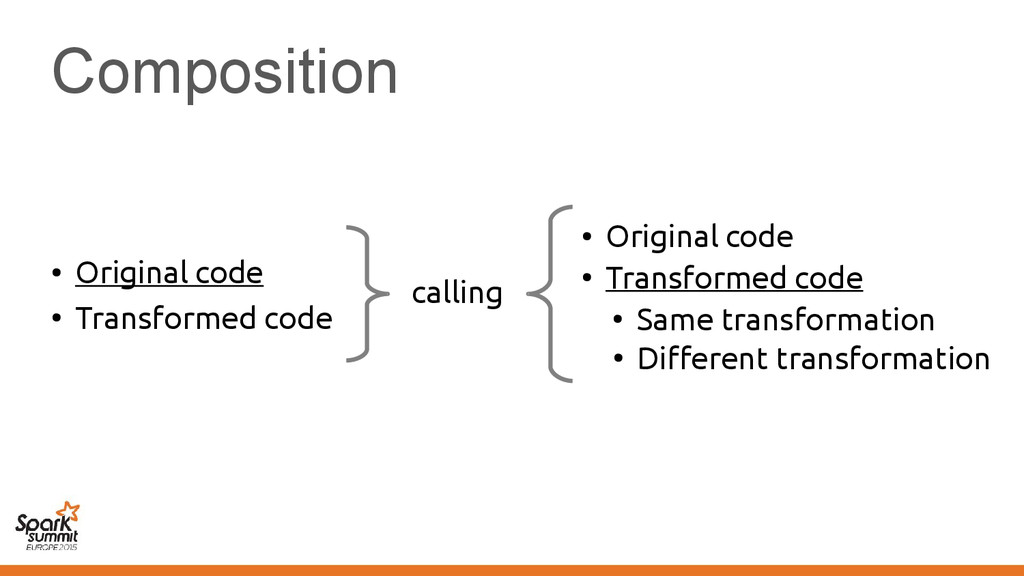
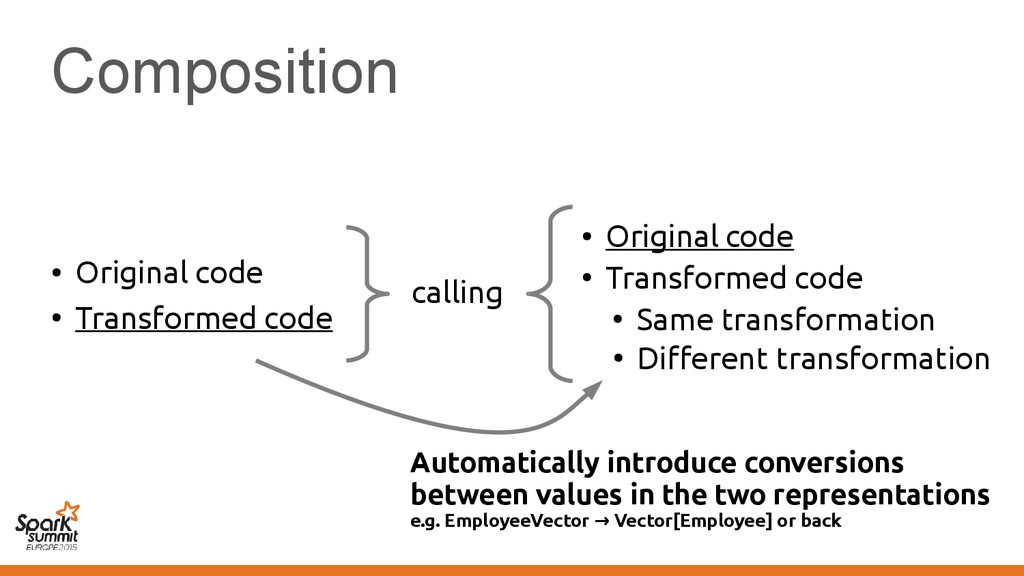
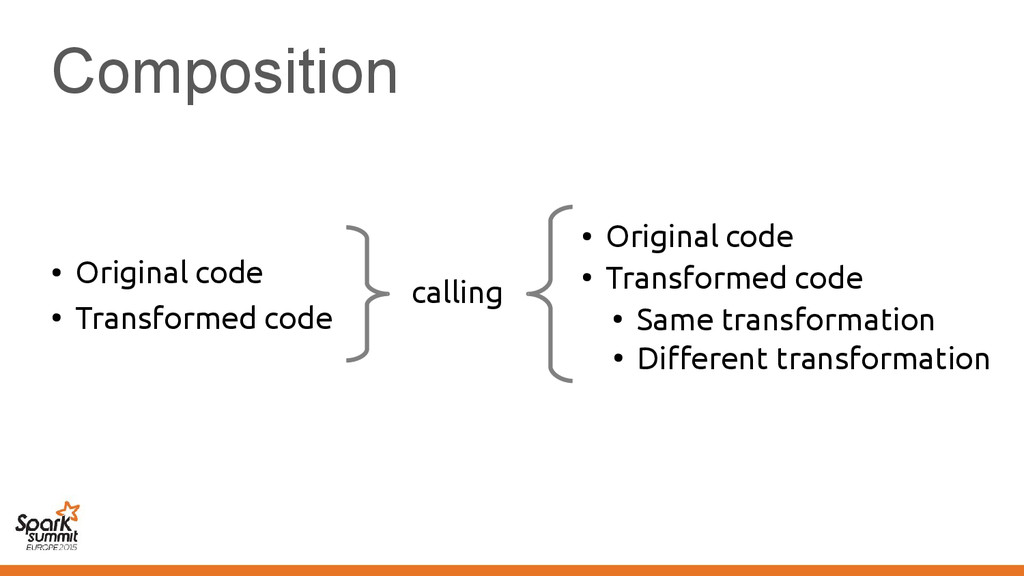
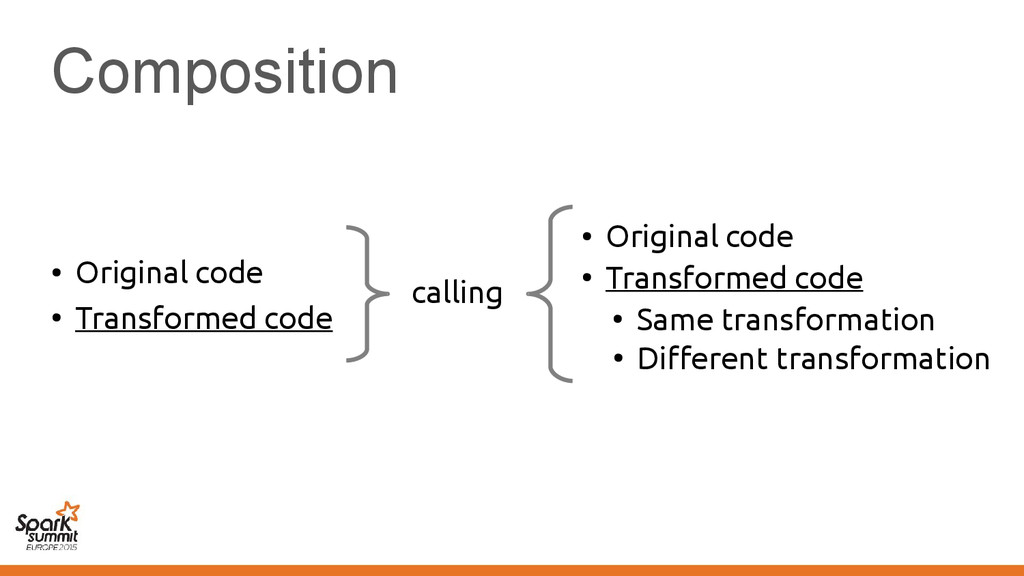
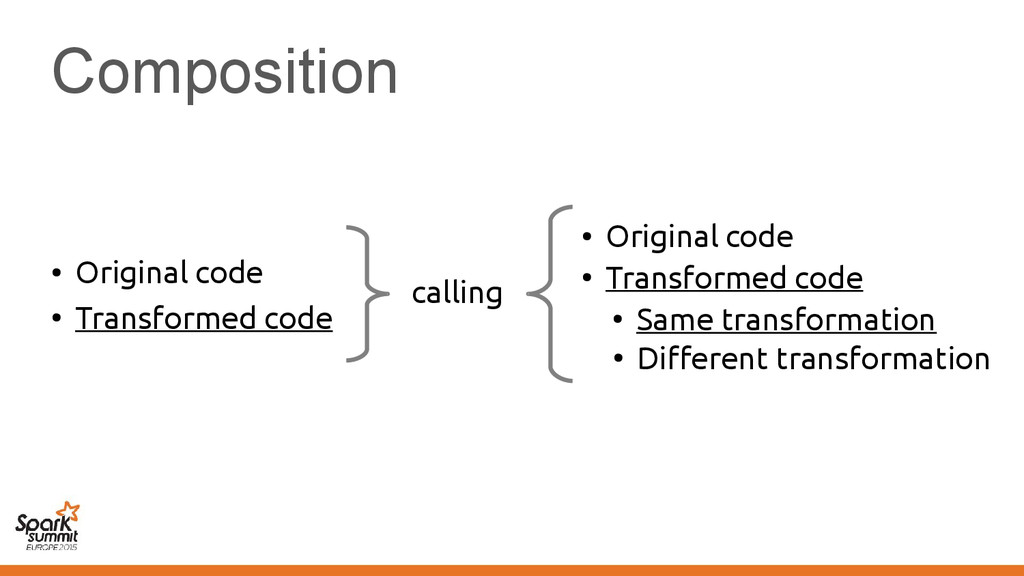
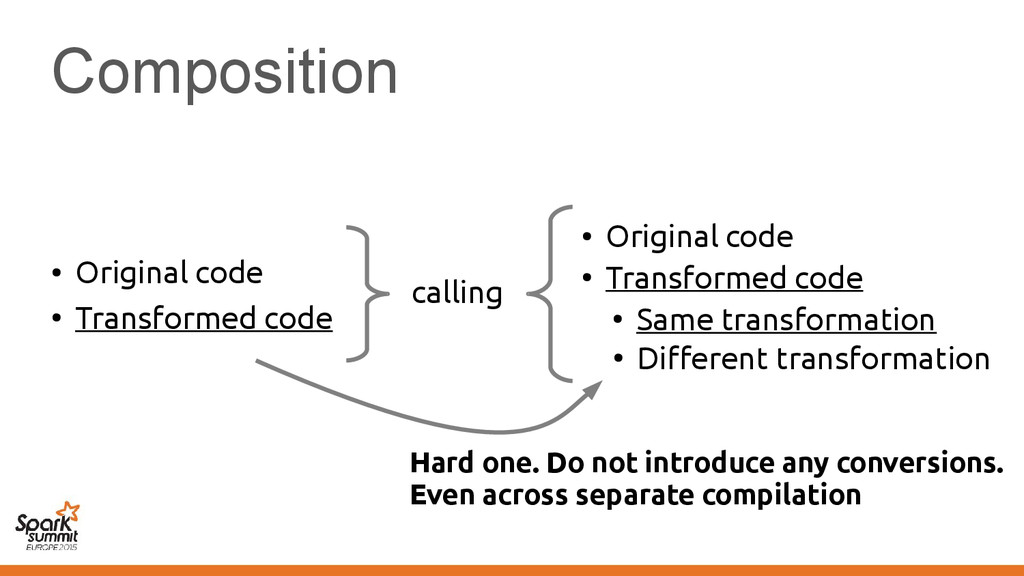
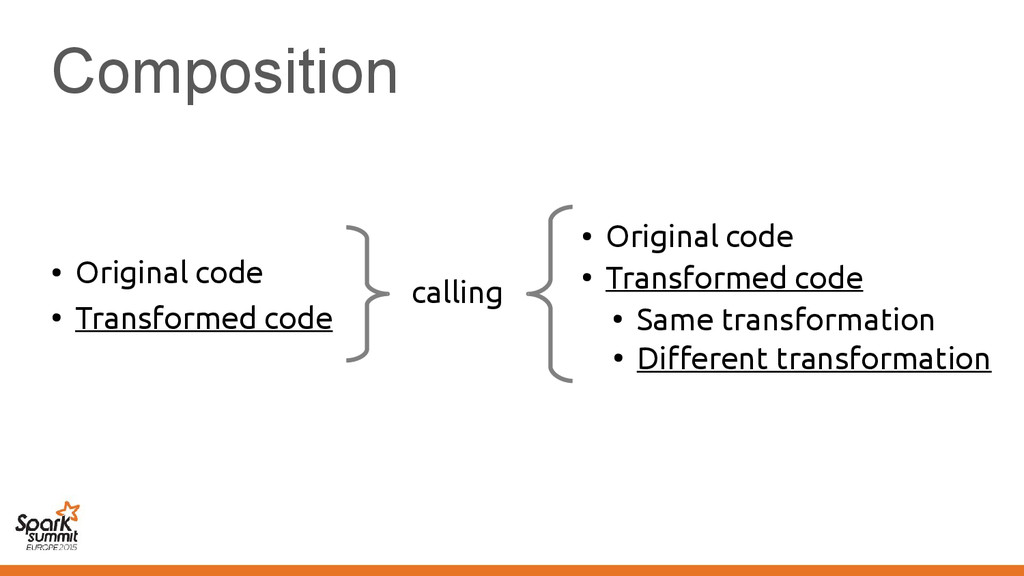
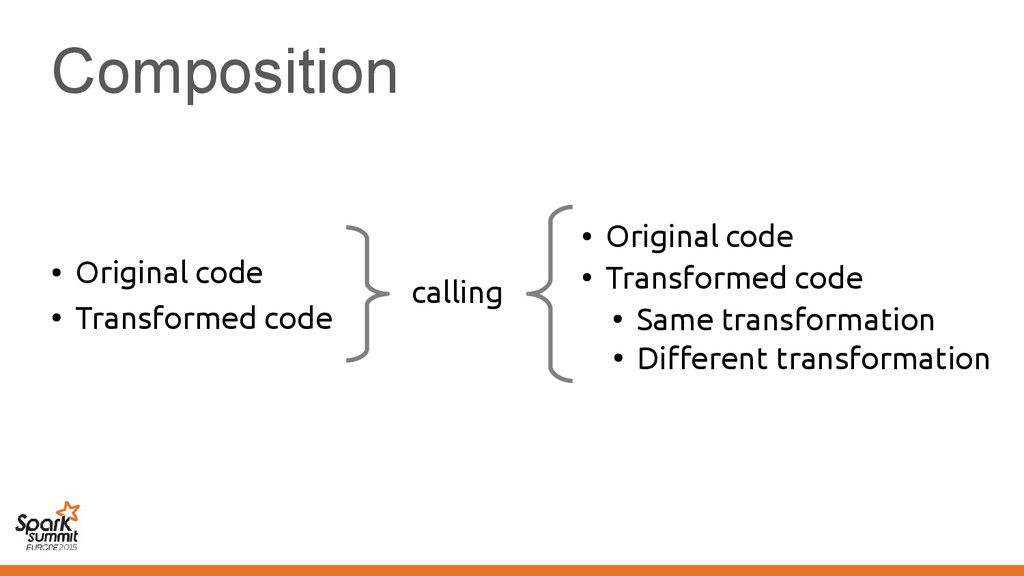
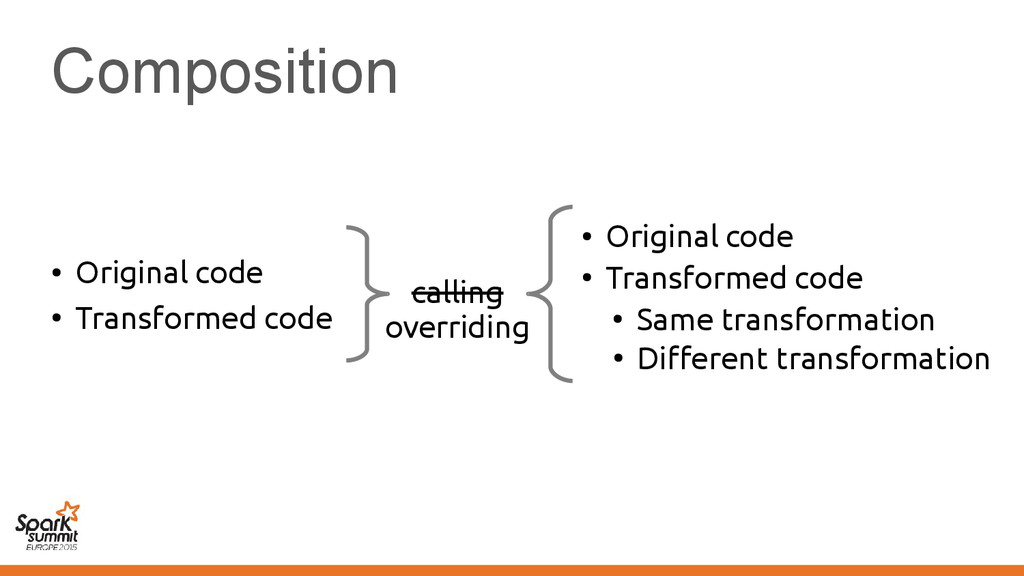
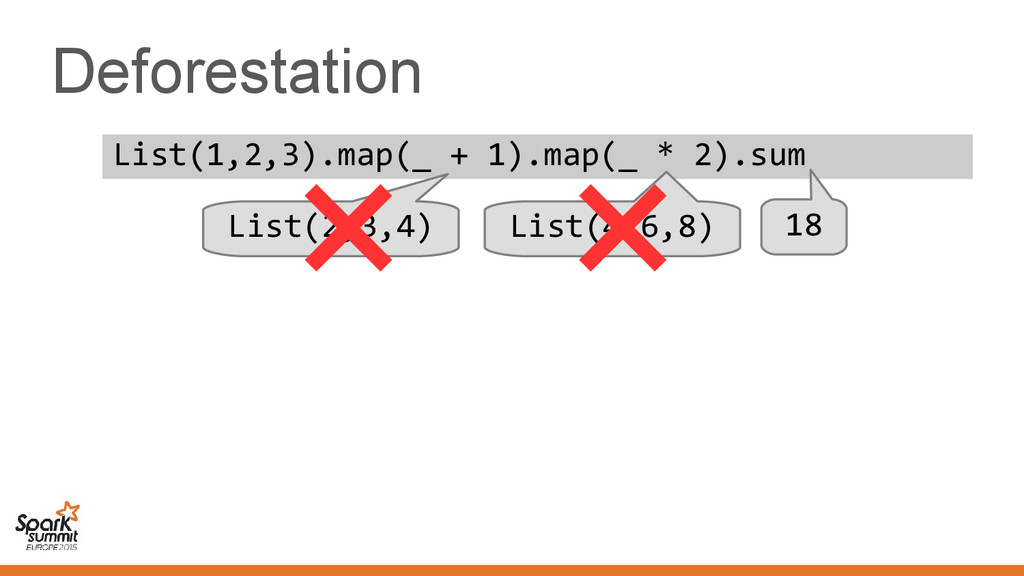
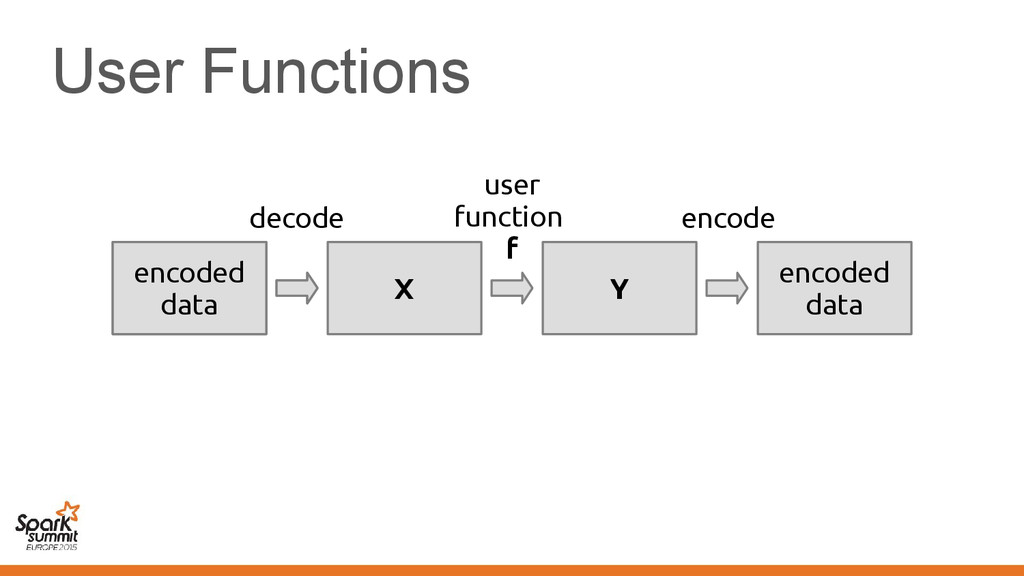
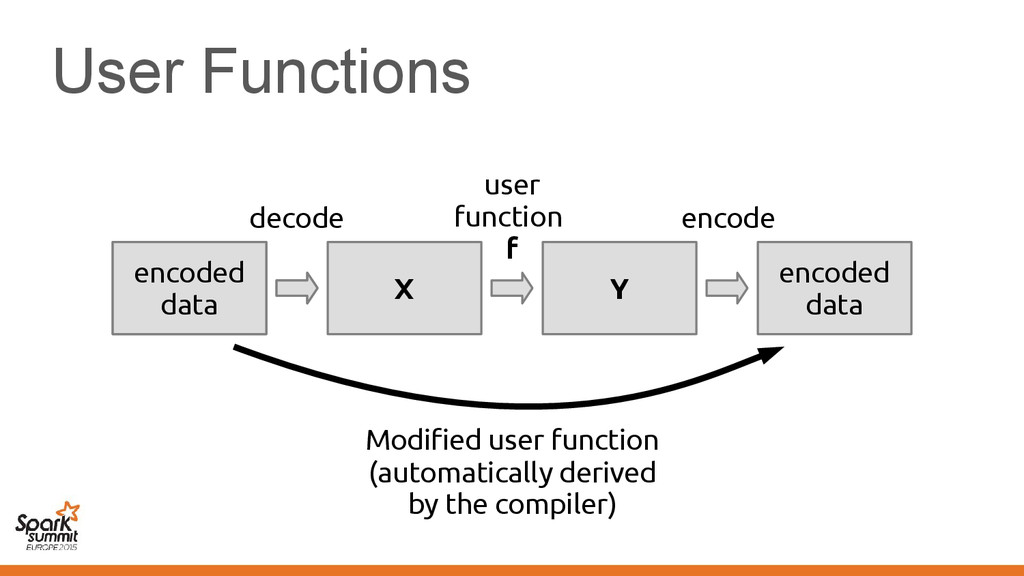
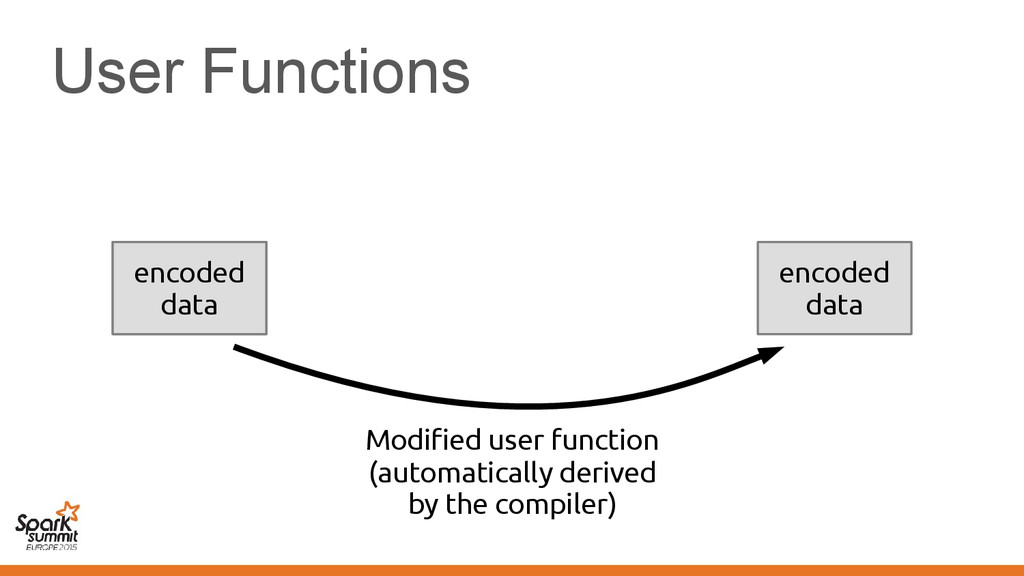
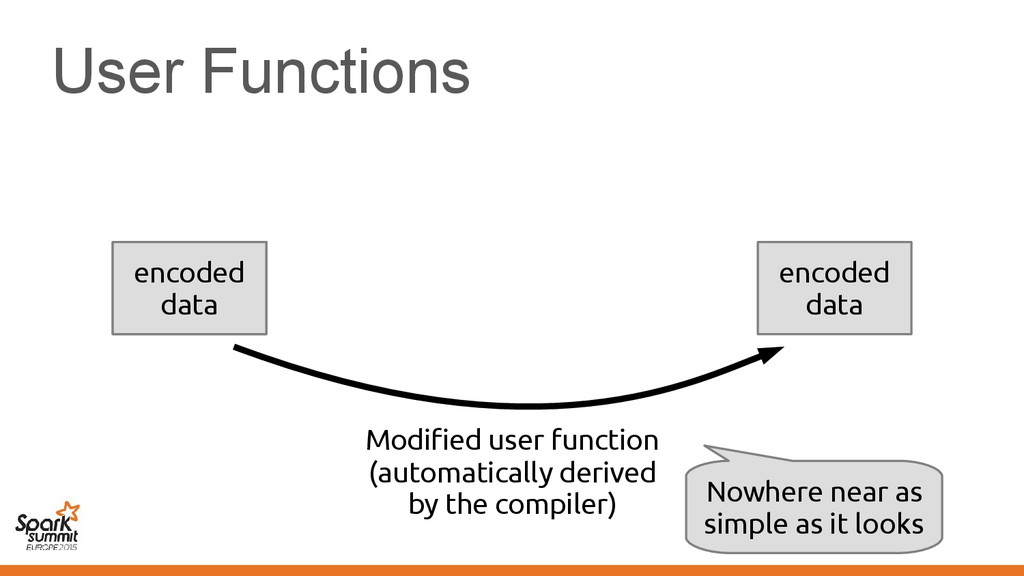
original representation) – Transformed using different representations calling • Original code • Transformed code • Original code • Transformed code • Same transformation • Different transformation
code • Transformed code • Same transformation • Different transformation Automatically introduce conversions between values in the two representations e.g. EmployeeVector Vector[Employee] or back →
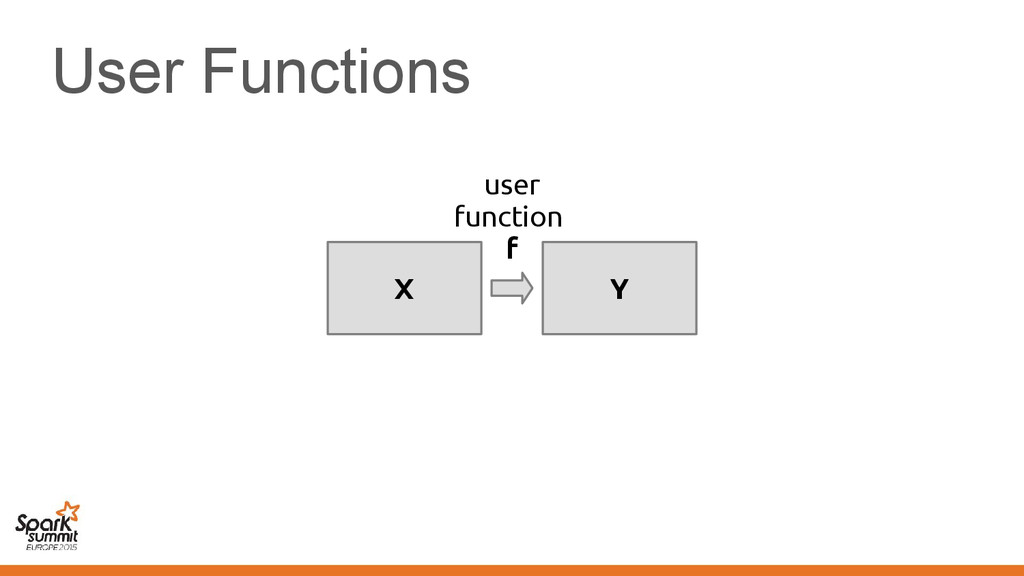
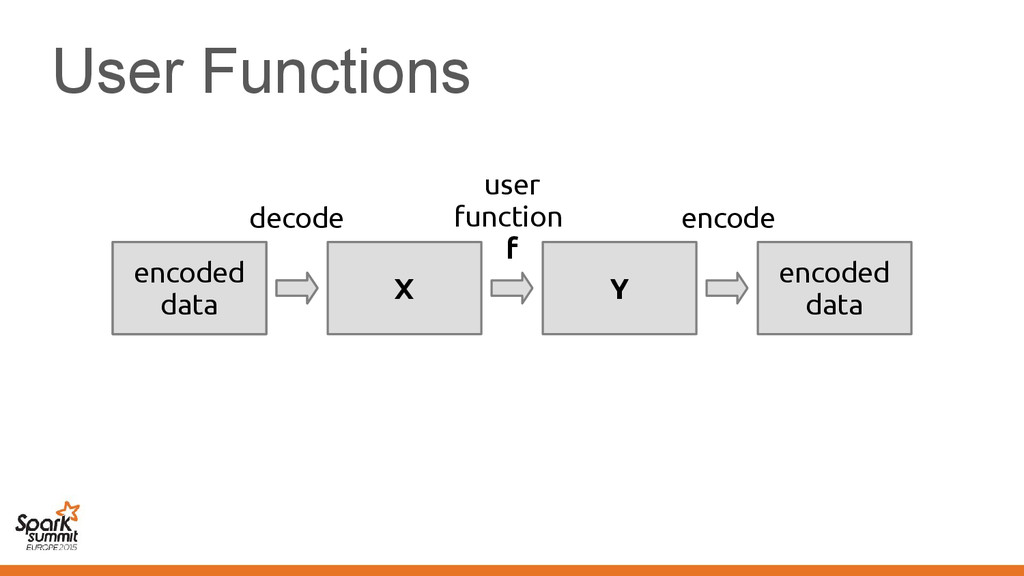
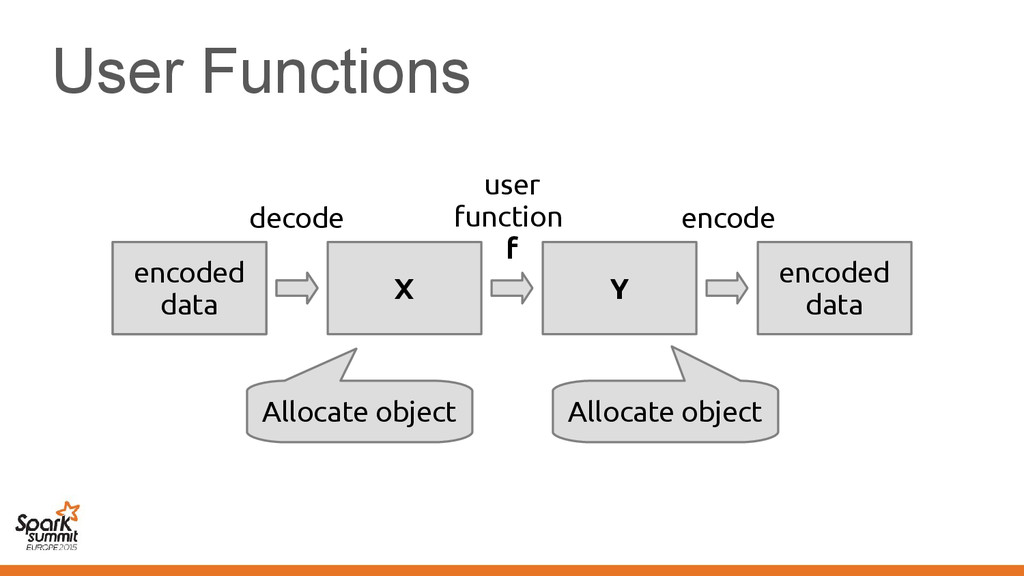
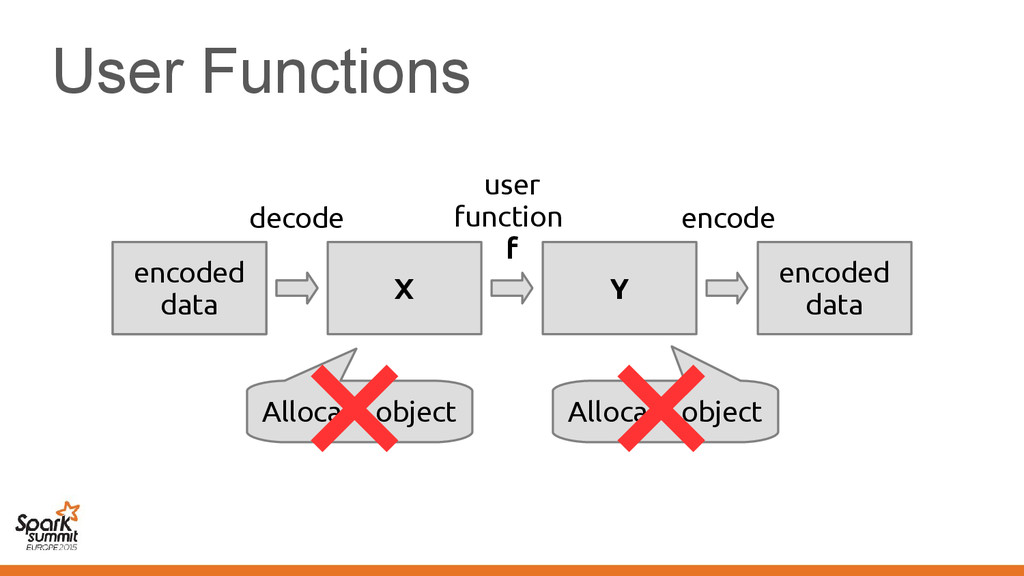
EmployeePrinter extends Printer[Employee] { def print(employee: Vector[Employee]) = ... } Method print in the class implements method print in the trait
{ class EmployeePrinter extends Printer[Employee] { def print(employee: Vector[Employee]) = ... } } The signature of method print changes according to the transformation it no → longer implements the trait
{ class EmployeePrinter extends Printer[Employee] { def print(employee: Vector[Employee]) = ... } } The signature of method print changes according to the transformation it no → longer implements the trait Taken care by the compiler for you!
5 (3,5) Tuples in Scala are specialized but are still objects (not value classes) = not as optimized as they could be (3,5) 3 5 Header reference 14x faster, lower heap requirements
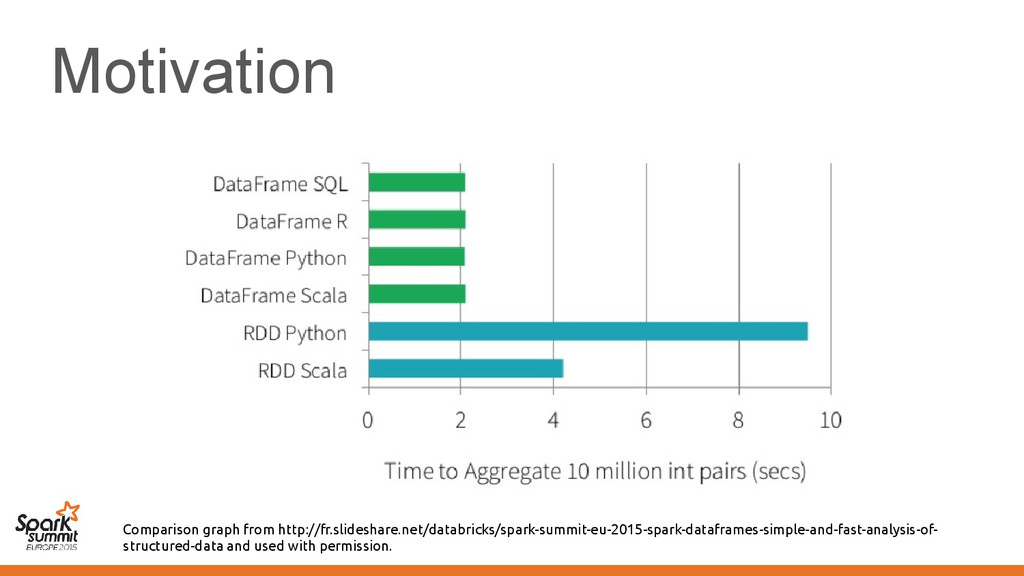
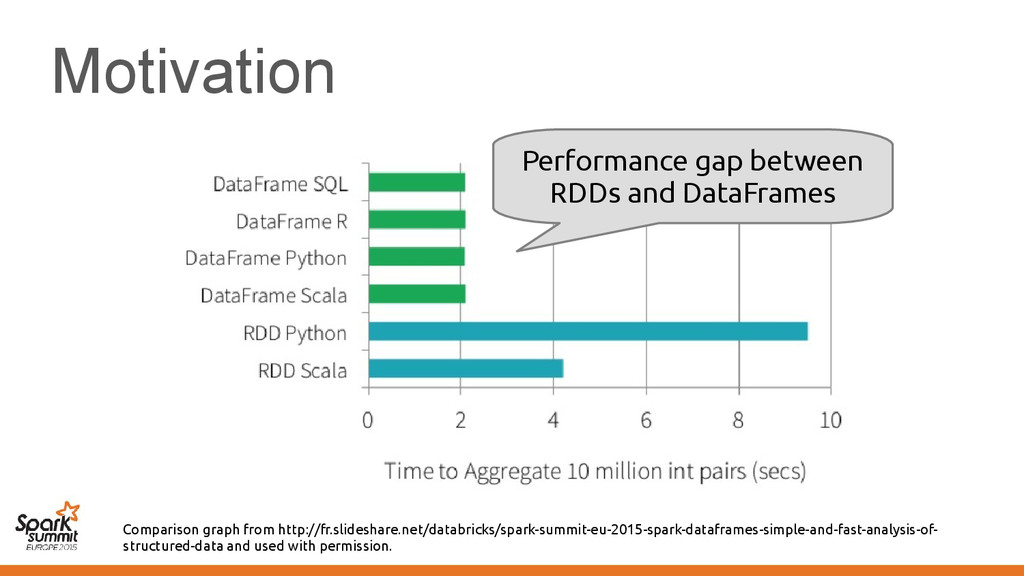
predicate push-down – DataFrames do code generation • Code is specialized for the data representation • Functions are specialized for the data representation
predicate push-down – RDDs do code generation • Code is specialized for the data representation • Functions are specialized for the data representation
predicate push-down – RDDs do code generation • Code is specialized for the data representation • Functions are specialized for the data representation This is what makes them slower
predicate push-down – Datasets do code generation • Code is specialized for the data representation • Functions are specialized for the data representation
• Solution: Issue compiler warnings – Explain why it's not possible: due to the method call – Suggest how to fix it: enclose the method in a scope • Reuse the machinery in miniboxing scala-miniboxing.org
box • Solution: – Adapt data-centric metaprogramming to Spark – Trade generality for simplicity – Do the right thing for most of the cases Where are we now?
data representation is configurable • It's very limited: – Custom data repr. only in map, filter and flatMap – Otherwise we revert to costly objects – Large parts of the automation still need to be done
low-level code – Can assume a (local) closed world – Can speculate based on profiles • Best optimizations break semantics – You can't do this in the JIT compiler! – Only the programmer can decide to break semantics
– :) Lots of power – :( Lots of responsibility • Scala compiler invariants • Object-oriented model • Modularity • Can we restrict macros so they're safer? – Data-centric metaprogramming
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Object Composition class Vector[T] { … }](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_16.jpg){kind=link}
![Object Composition class Vector[T] { … } The Vector collection](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_17.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY class Vector[T] {](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_18.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY class Vector[T] {](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_19.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY class Vector[T] {](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_20.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY class Vector[T] {](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_21.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY Vector[Employee] ID NAME](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_22.jpg){kind=link}
![Object Composition class Employee(...) ID NAME SALARY Vector[Employee] ID NAME](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_23.jpg){kind=link}
![A Better Representation Vector[Employee] ID NAME SALARY ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_24.jpg){kind=link}
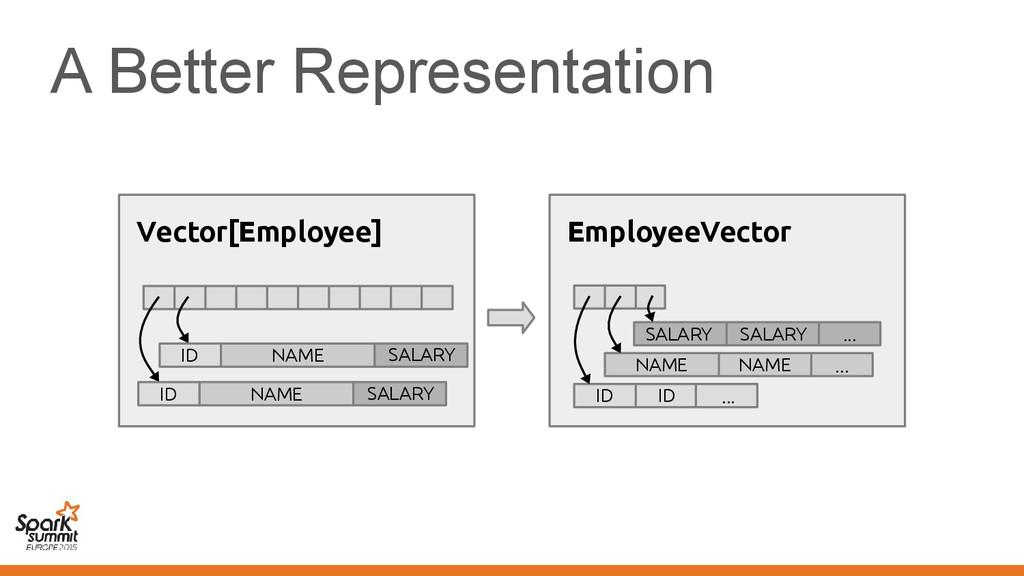{kind=link}
{kind=link}
![The Problem • Vector[T] is unaware of Employee](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_27.jpg){kind=link}
![The Problem • Vector[T] is unaware of Employee – Which](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_28.jpg){kind=link}
![The Problem • Vector[T] is unaware of Employee – Which](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_29.jpg){kind=link}
![The Problem • Vector[T] is unaware of Employee – Which](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_30.jpg){kind=link}
![The Problem • Vector[T] is unaware of Employee – Which](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_31.jpg){kind=link}
![The Problem • Vector[T] is unaware of Employee – Which](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Scenario class Employee(...) ID NAME SALARY class Vector[T] { …](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_52.jpg){kind=link}
![Scenario class Employee(...) ID NAME SALARY Vector[Employee] ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_53.jpg){kind=link}
![Scenario class Employee(...) ID NAME SALARY Vector[Employee] ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_54.jpg){kind=link}
![Scenario class Employee(...) ID NAME SALARY Vector[Employee] ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_55.jpg){kind=link}
![Scenario class Employee(...) ID NAME SALARY Vector[Employee] ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_56.jpg){kind=link}
![Scenario class Employee(...) ID NAME SALARY Vector[Employee] ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Scopes transform(VectorOfEmployeeOpt) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_62.jpg){kind=link}
![Scopes transform(VectorOfEmployeeOpt) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_63.jpg){kind=link}
![Scopes transform(VectorOfEmployeeOpt) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Best Representation? Vector[Employee] ID NAME SALARY ID NAME SALARY](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_68.jpg){kind=link}
![Best Representation? It depends. Vector[Employee] ID NAME SALARY ID NAME](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Scopes allow mixing data representations transform(VectorOfEmployeeOpt) { def indexSalary(employees: Vector[Employee],](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_73.jpg){kind=link}
![Scopes transform(VectorOfEmployeeOpt) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_74.jpg){kind=link}
![Scopes transform(VectorOfEmployeeCompact) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_75.jpg){kind=link}
![Scopes transform(VectorOfEmployeeJSON) { def indexSalary(employees: Vector[Employee], by: Float): Vector[Employee] =](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_76.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } class](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_95.jpg){kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } class](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_96.jpg){kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } class](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_97.jpg){kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } transform(VectorOfEmployeeOpt)](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_98.jpg){kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } transform(VectorOfEmployeeOpt)](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_99.jpg){kind=link}
![Scopes trait Printer[T] { def print(elements: Vector[T]): Unit } transform(VectorOfEmployeeOpt)](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_100.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Challenge: Internal API changes • Spark internals rely on Iterator[T]](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_139.jpg){kind=link}
![Challenge: Internal API changes • Spark internals rely on Iterator[T]](https://files.speakerdeck.com/presentations/055e99add67942a7a0c7582565b2f189/slide_140.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}