and merchants • shutl.it C2C platform • customers can chose between a delivery either: within 90 minutes of purchase or a 1 hour window of their choice Tuesday, 28 May 13
and merchants • shutl.it C2C platform • customers can chose between a delivery either: within 90 minutes of purchase or a 1 hour window of their choice (same day or any day) Tuesday, 28 May 13
and merchants • shutl.it C2C platform • customers can chose between a delivery either: within 90 minutes of purchase or a 1 hour window of their choice (same day or any day) • fastest delivery to date 15:00 min Tuesday, 28 May 13
and merchants • shutl.it C2C platform • customers can chose between a delivery either: within 90 minutes of purchase or a 1 hour window of their choice (same day or any day) • fastest delivery to date 15:00 min • SOA with services built using jRuby, sinatra, mongoDB and neo4j Tuesday, 28 May 13
• code base too complex and unmaintanable • api response time growing too large the more data was added problems with our previous attempt (v1): Tuesday, 28 May 13
• code base too complex and unmaintanable • api response time growing too large the more data was added • our fastest delivery was quicker then our slowest query! problems with our previous attempt (v1): Tuesday, 28 May 13
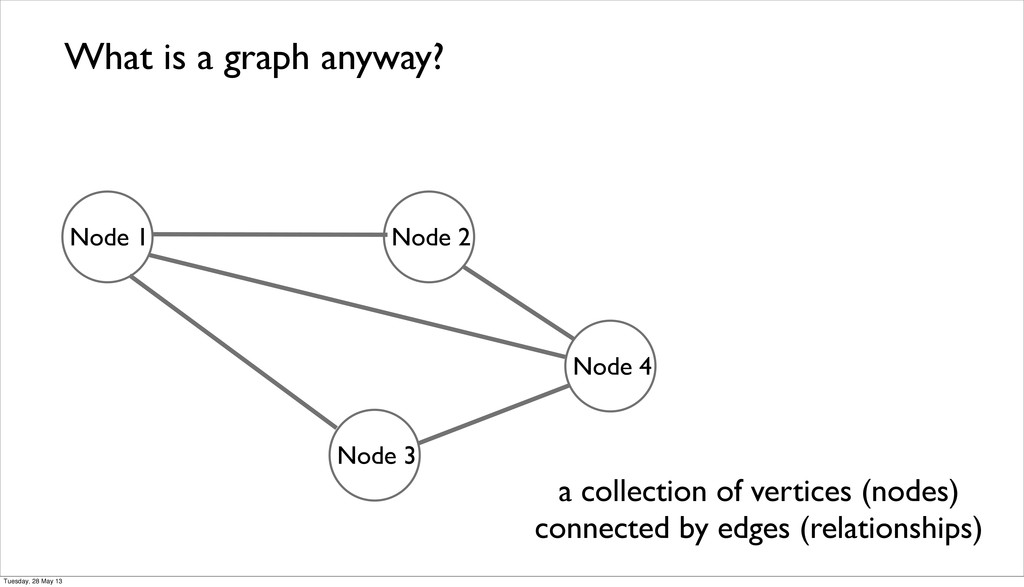
(RDBS lack relationships) • domain modelling is simplified because adding new ‘subgraphs‘ doesn’t affect the existing structure and queries (additive model) Tuesday, 28 May 13
(RDBS lack relationships) • domain modelling is simplified because adding new ‘subgraphs‘ doesn’t affect the existing structure and queries (additive model) • white board friendly Tuesday, 28 May 13
(RDBS lack relationships) • domain modelling is simplified because adding new ‘subgraphs‘ doesn’t affect the existing structure and queries (additive model) • white board friendly • schema-less Tuesday, 28 May 13
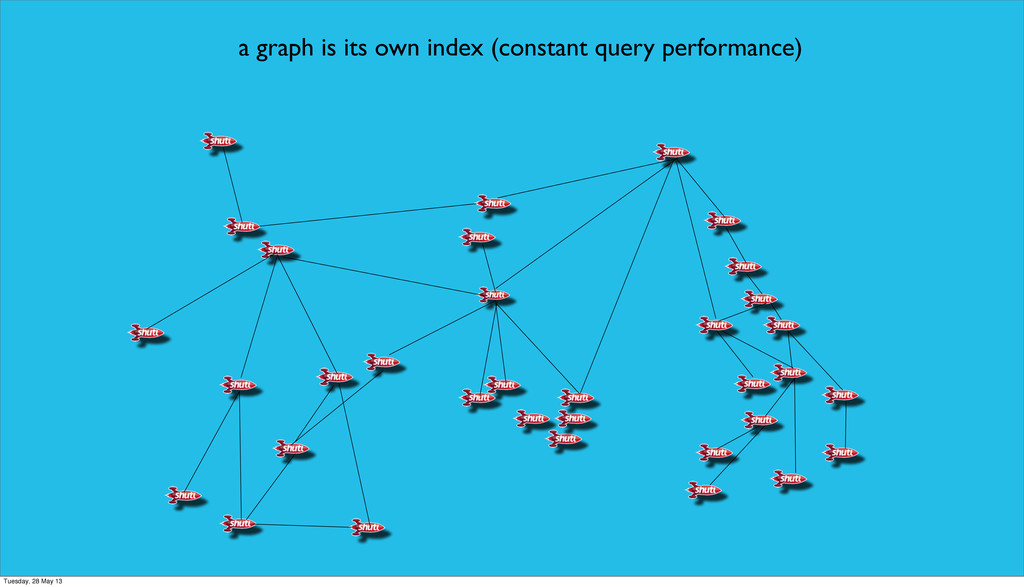
(RDBS lack relationships) • domain modelling is simplified because adding new ‘subgraphs‘ doesn’t affect the existing structure and queries (additive model) • white board friendly • schema-less • db performance remains relatively constant because queries are localized to its portion of the graph. O(1) for same query Tuesday, 28 May 13
(RDBS lack relationships) • domain modelling is simplified because adding new ‘subgraphs‘ doesn’t affect the existing structure and queries (additive model) • white board friendly • schema-less • db performance remains relatively constant because queries are localized to its portion of the graph. O(1) for same query • traversals of relationships are easy and very fast Tuesday, 28 May 13
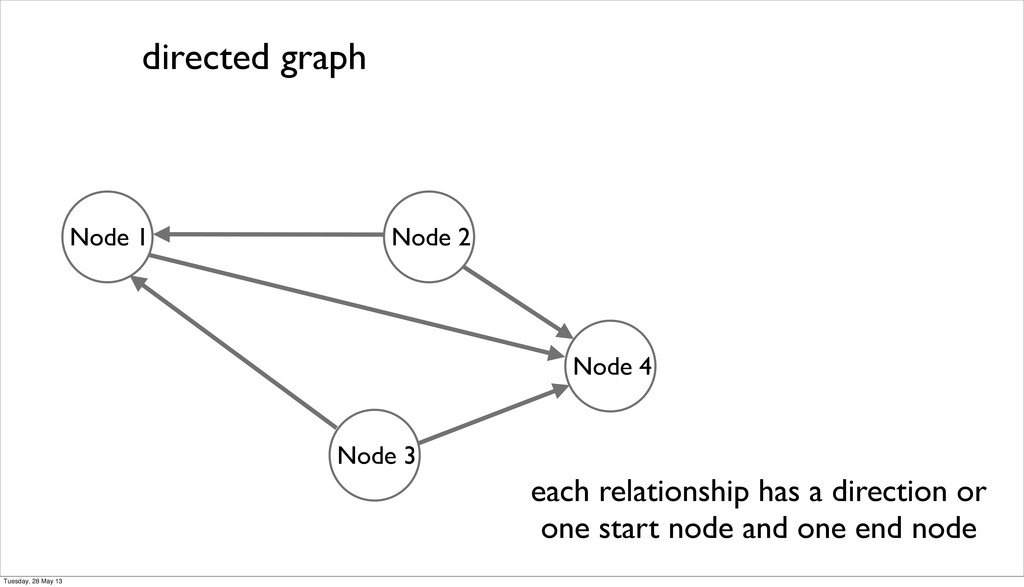
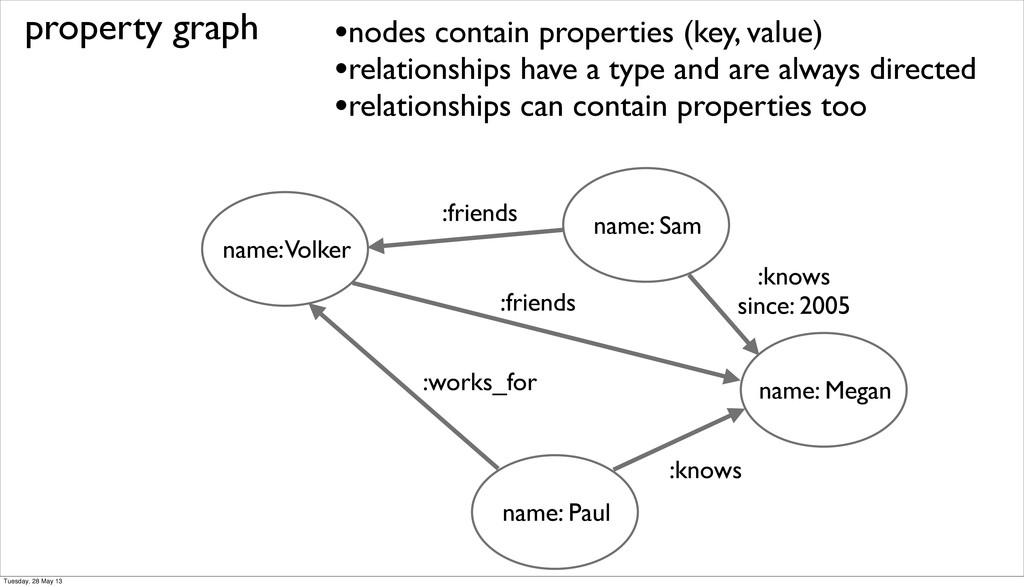
have a type and are always directed •relationships can contain properties too name: Sam :friends name: Megan :knows since: 2005 name: Paul :friends :works_for :knows Tuesday, 28 May 13
in the same jvm • we can use jruby as we know ruby very well already • lots of good ruby libraries are available, we chose the neo4j gem by Andreas Ronge (https://github.com/andreasronge/neo4j) Tuesday, 28 May 13
in the same jvm • we can use jruby as we know ruby very well already • lots of good ruby libraries are available, we chose the neo4j gem by Andreas Ronge (https://github.com/andreasronge/neo4j) • it speaks cypher Tuesday, 28 May 13
in the same jvm • we can use jruby as we know ruby very well already • lots of good ruby libraries are available, we chose the neo4j gem by Andreas Ronge (https://github.com/andreasronge/neo4j) • it speaks cypher • the guys from neotech are awesome Tuesday, 28 May 13
gem is available we can use cypher and traversal only the code running the db has access to the db access via rest api and cypher language independent and code doesn’t need to run on JVM not as performant only works with cypher transaction is on a per query basis need to write model wrappers for ourselves Tuesday, 28 May 13
be difficult and we had to write our own tools • migrations of schemaless dbs are more difficult to stay on top of and require special solutions in the case of graph dbs Tuesday, 28 May 13
be difficult and we had to write our own tools • migrations of schemaless dbs are more difficult to stay on top of and require special solutions in the case of graph dbs • seeding an embedded database is hard Tuesday, 28 May 13
be difficult and we had to write our own tools • migrations of schemaless dbs are more difficult to stay on top of and require special solutions in the case of graph dbs • seeding an embedded database is hard • graph db partioning is almost impossible and the whole graph needs to be in memory Tuesday, 28 May 13
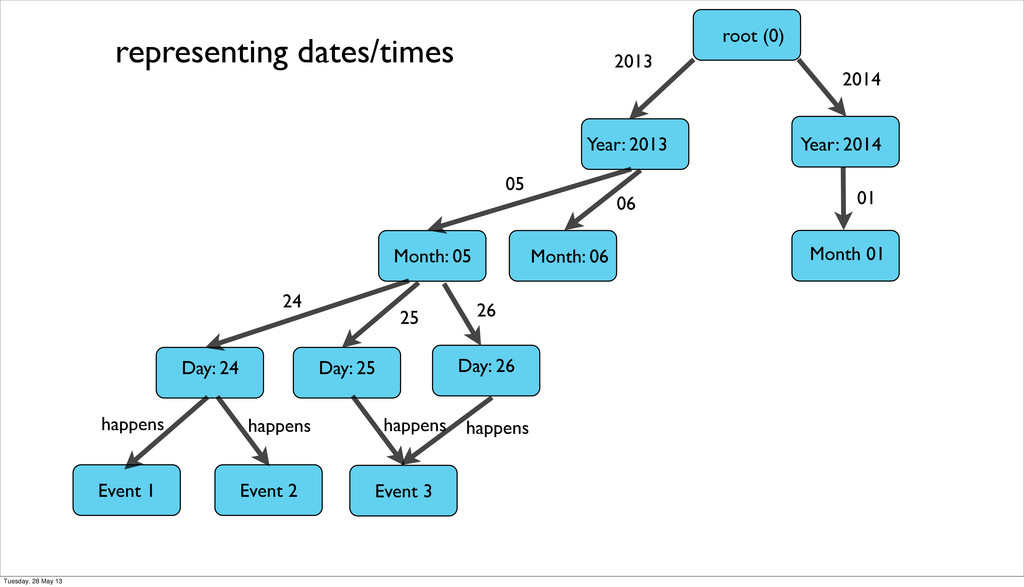
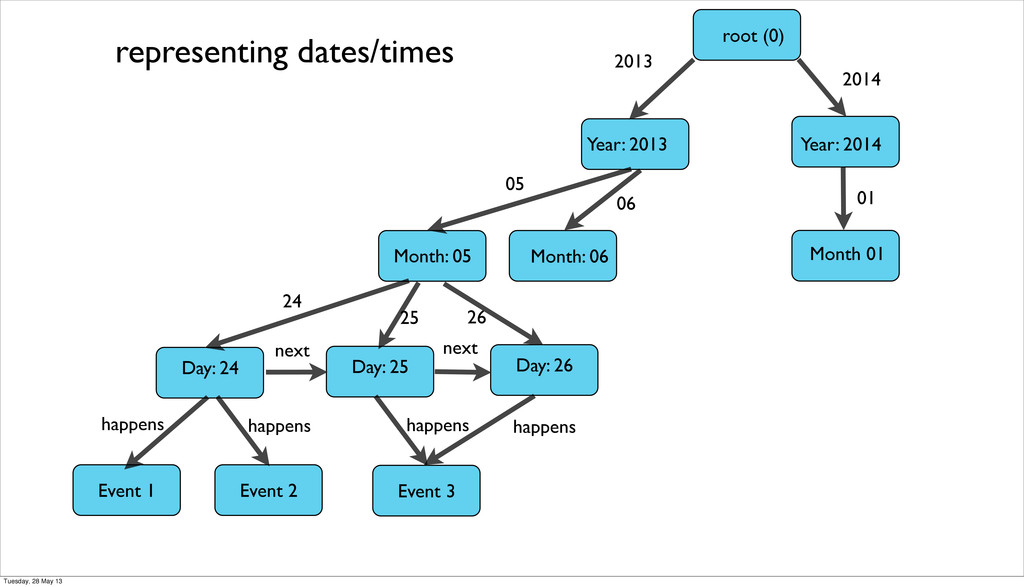
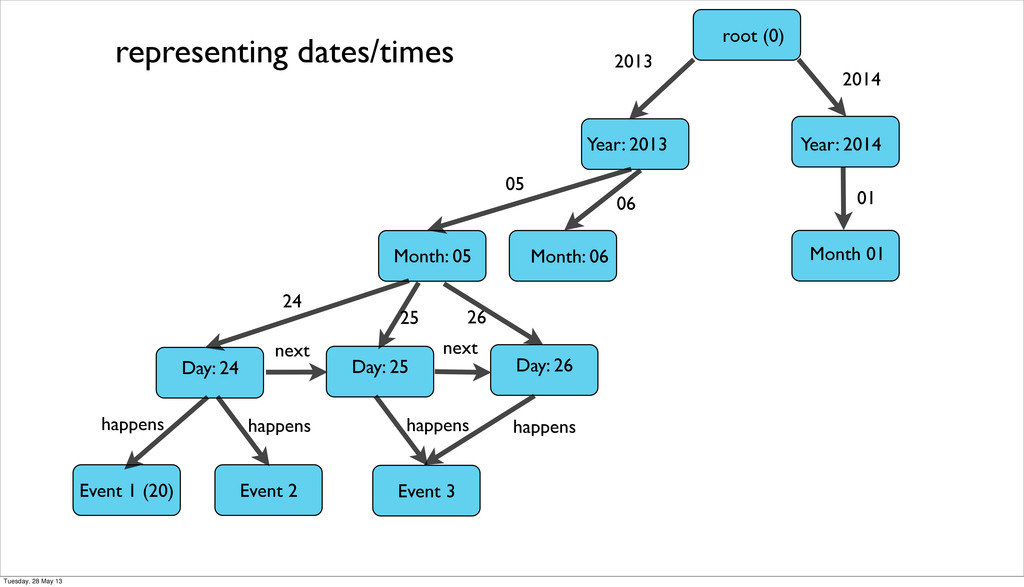
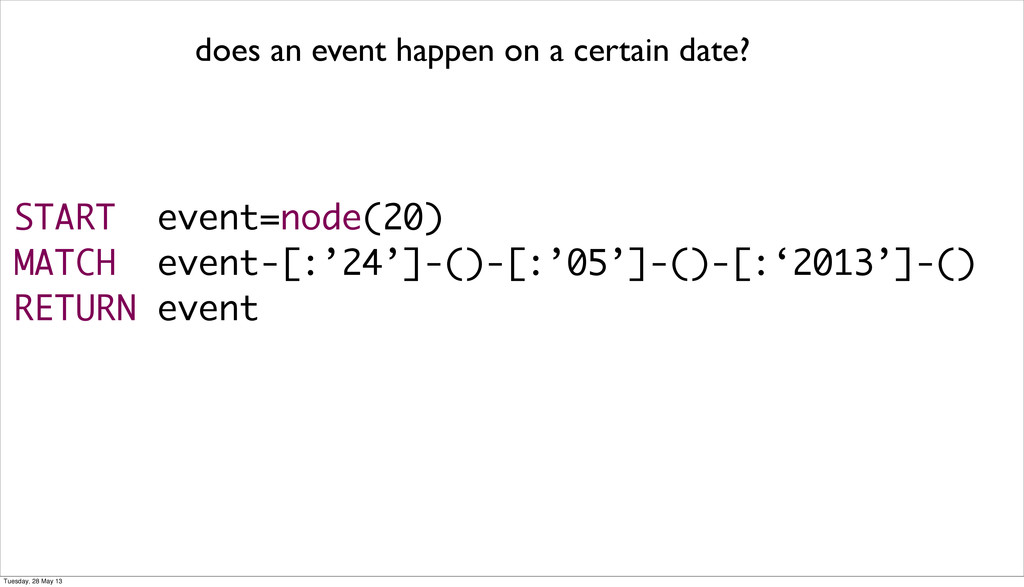
be difficult and we had to write our own tools • migrations of schemaless dbs are more difficult to stay on top of and require special solutions in the case of graph dbs • seeding an embedded database is hard • graph db partioning is almost impossible and the whole graph needs to be in memory • encoding Dates and Times that are stored in UTC and work across timezone is non-trivial Tuesday, 28 May 13
be difficult and we had to write our own tools • migrations of schemaless dbs are more difficult to stay on top of and require special solutions in the case of graph dbs • seeding an embedded database is hard • graph db partioning is almost impossible and the whole graph needs to be in memory • encoding Dates and Times that are stored in UTC and work across timezone is non-trivial • nested datastructure (hashes and array) can’t be stored and need to be converted to json Tuesday, 28 May 13
neo4j • easy to learn and intuitive • enables the user to specify specific patterns to query for (something that looks like ‘this’) • inspired partly by SQL (WHERE and ORDER BY) and SPARQL (pattern matching) Tuesday, 28 May 13
neo4j • easy to learn and intuitive • enables the user to specify specific patterns to query for (something that looks like ‘this’) • inspired partly by SQL (WHERE and ORDER BY) and SPARQL (pattern matching) • focuses on what to query for and not how to query for it Tuesday, 28 May 13
neo4j • easy to learn and intuitive • enables the user to specify specific patterns to query for (something that looks like ‘this’) • inspired partly by SQL (WHERE and ORDER BY) and SPARQL (pattern matching) • focuses on what to query for and not how to query for it • switch from a mySQl world is made easier by the use of cypher instead of having to learn a traversal framework straight away Tuesday, 28 May 13
lookups or by element IDs. • MATCH: The graph pattern to match, bound to the starting points in START. • WHERE: Filtering criteria. • RETURN: What to return. • CREATE: Creates nodes and relationships. • DELETE: Removes nodes, relationships and properties. • SET: Set values to properties. • FOREACH: Performs updating actions once per element in a list. • WITH: Divides a query into multiple, distinct parts cypher clauses Tuesday, 28 May 13
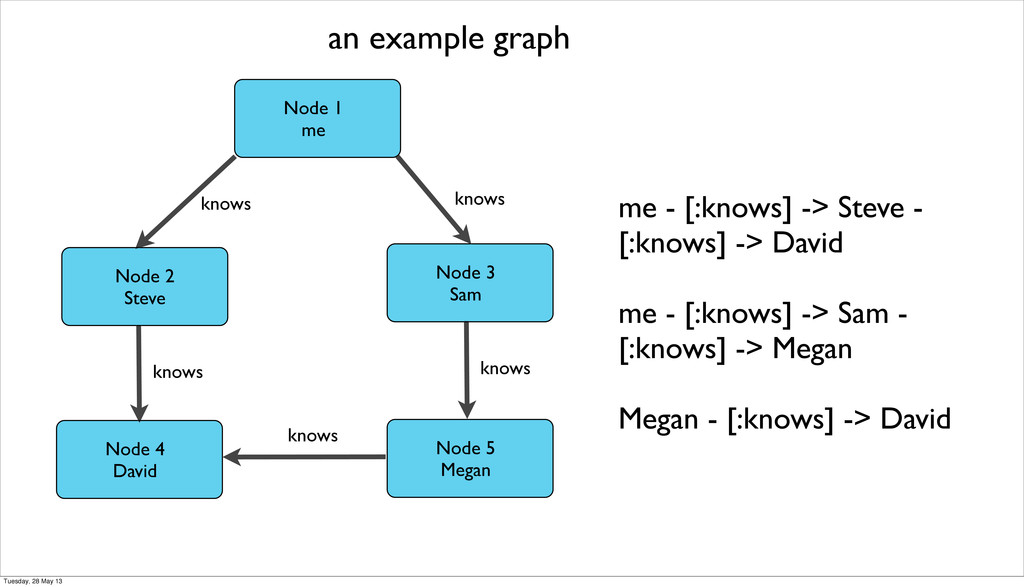
3 Sam Node 4 David Node 5 Megan me - [:knows] -> Steve - [:knows] -> David me - [:knows] -> Sam - [:knows] -> Megan Megan - [:knows] -> David knows knows knows knows knows Tuesday, 28 May 13
tests on the api and practice tdd/bdd • setting up ‘scenarios’ for an integration test was difficult and slow with existing tools • we decided to built our own dsl based on the geoff notation developed by Nigel Small to allow for the setting up of scenarios and for the import of data from mysql Tuesday, 28 May 13
graphs in a human readable form (A) {"name": "Alice"} (B) {"name": "Bob"} (A)-[:KNOWS]->(B) and provides a java interface to insert them into an existing graph Tuesday, 28 May 13
it into the db • it is open source • it works together with FactoryGirl (https://github.com/thoughtbot/factory_girl) • it supports only the graph structure of the neo4j gem at the moment • we haven’t solved all the issues with event listeners yet geoff gem (https://github.com/shutl/geoff) Tuesday, 28 May 13
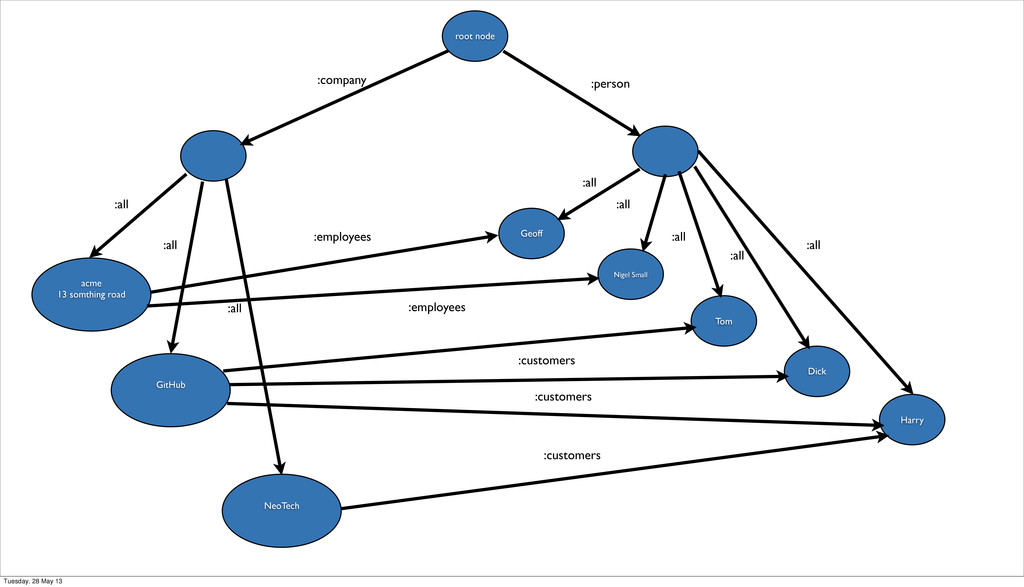
outgoing :employees do person 'Geoff' person 'Nigel' do name 'Nigel Small' end end end company 'Github' do outgoing :customers do person 'Tom' person 'Dick' person 'Harry' end end person 'Harry' do incoming :customers do company 'NeoTech' end end end geoff gem (https://github.com/shutl/ geoff) Tuesday, 28 May 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![START me=node(1) MATCH me-[:knows]->()-[:knows]->fof RETURN fof the query Tuesday, 28](https://files.speakerdeck.com/presentations/d1850910a9ce01304aa17a425d98a4eb/slide_58.jpg){kind=link}
![START me=node(1) MATCH me-[:knows*2..]->fof WHERE fof.name =~ 'Da.*' RETURN fof](https://files.speakerdeck.com/presentations/d1850910a9ce01304aa17a425d98a4eb/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS? Volker Pacher [email protected] www.shutl.com Tuesday, 28 May 13](https://files.speakerdeck.com/presentations/d1850910a9ce01304aa17a425d98a4eb/slide_73.jpg){kind=link}