Share
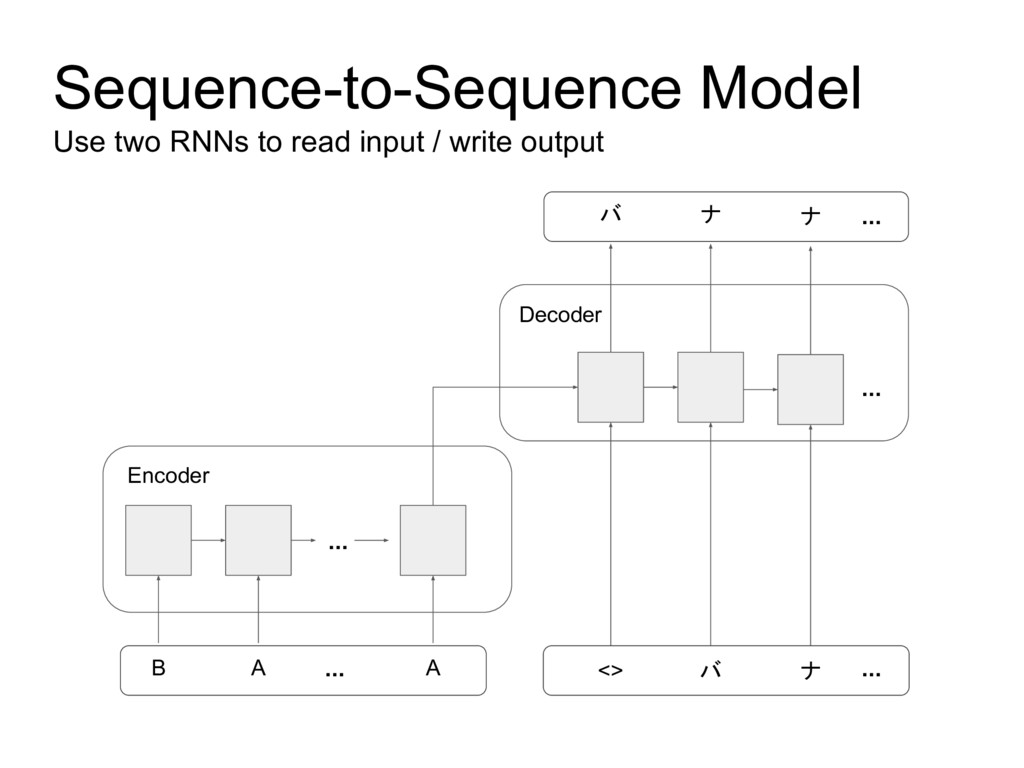
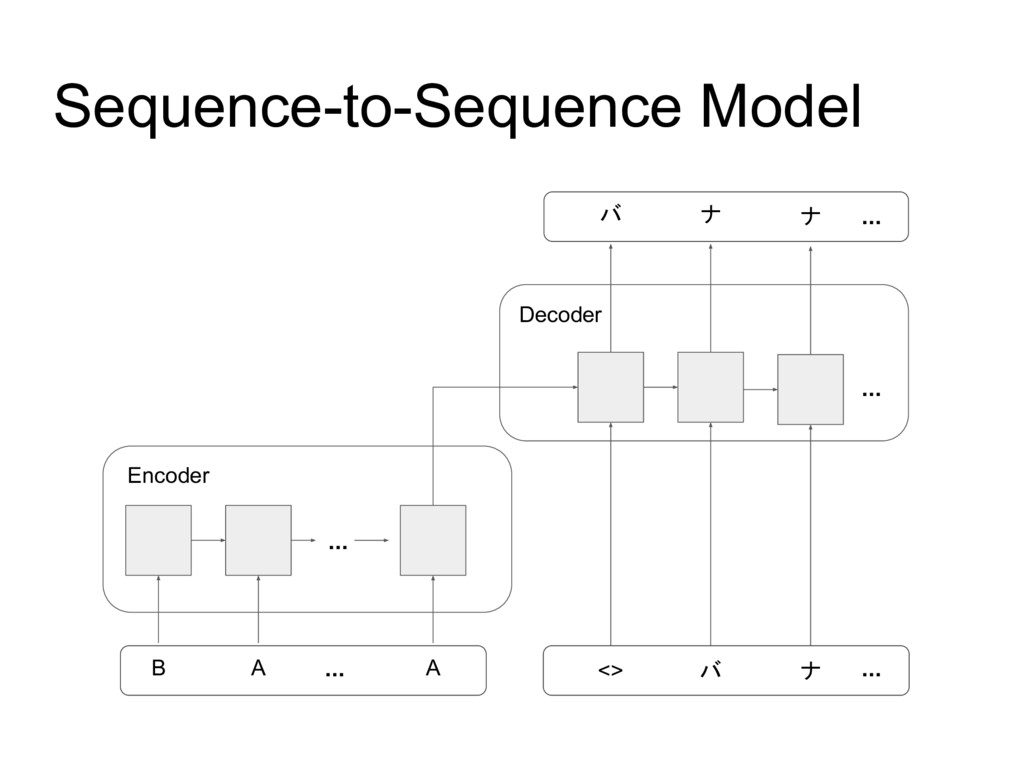
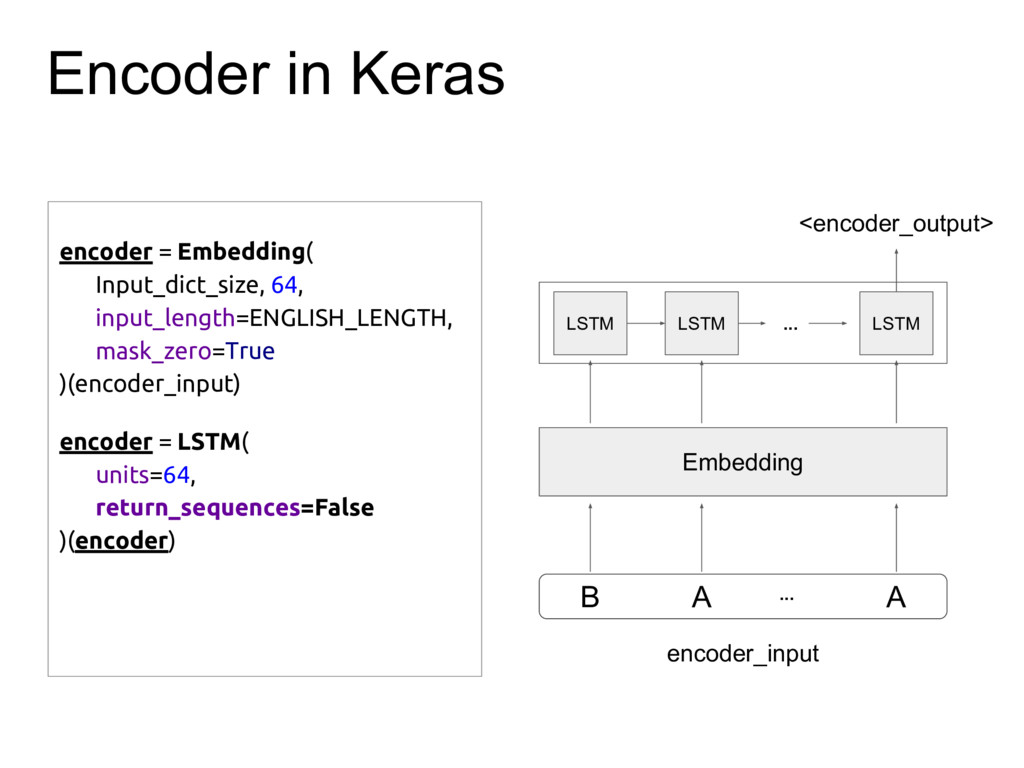
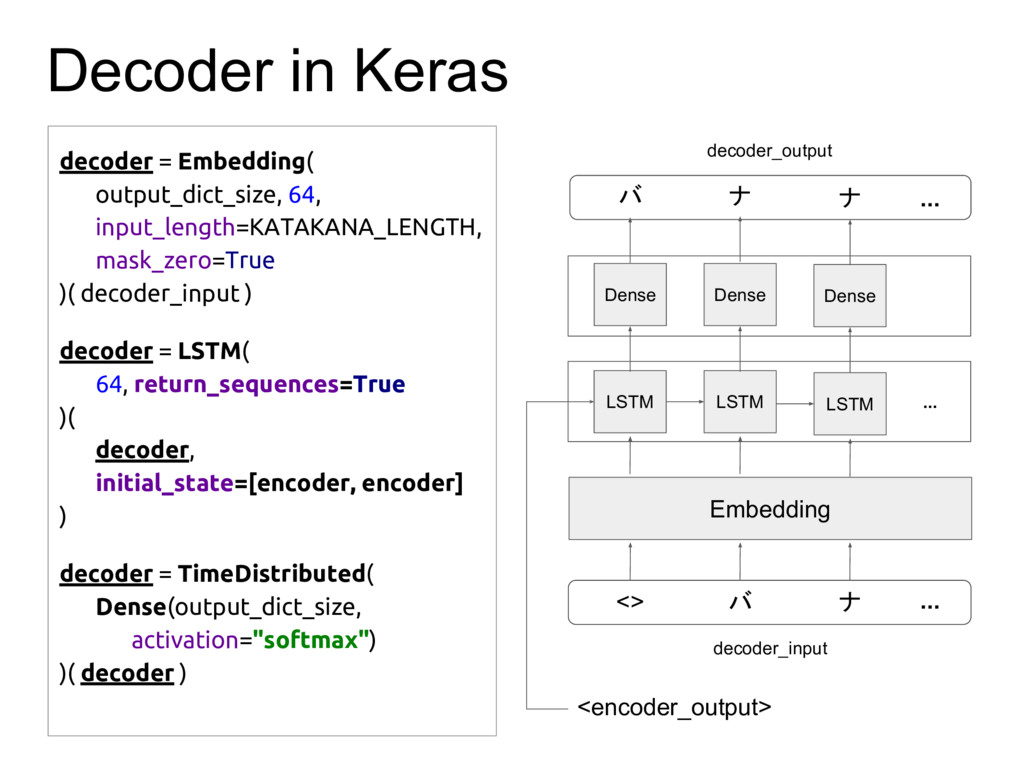
A presentation in TensorFlow Tokyo Meetup about building Sequence-to-Sequence model in Keras to write Katakana.
This presentation is originally from a blog post: https://wanasit.github.io/english-to-katakana-using-sequence-to-sequence-in-keras.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}