Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
chiVe_実用的な日本語単語ベクトル実現にむけて_20201208.pdf
Search
WAP
December 09, 2020
Research
660
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
chiVe_実用的な日本語単語ベクトル実現にむけて_20201208.pdf
WAP
December 09, 2020
More Decks by WAP
See All by WAP
単語分散表現と事前学習モデル - chiVe _ chiTra 利活用のための下準備 at WAP NLP Tech Talk #5
waptech
0
1.5k
事前学習モデル chiTra の活用方法 at WAP NLP Tech Talk #5
waptech
0
380
単語分散表現 chiVeの活用方法 at WAP NLP Tech Talk #5
waptech
0
690
Sudachi Family近況報告 at WAP NLP Tech Talk #5
waptech
0
280
Sudachi近況報告 at WAP NLP Tech Talk #4
waptech
1
560
日本語形態素解析器 SudachiPy の 現状と今後について
waptech
5
8.3k
企業(ワークスアプリケーションズ)での研究開発の楽しさと苦労
waptech
0
420
Sudachi辞書のつくり方
waptech
4
2.7k
Other Decks in Research
See All in Research
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
730
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
420
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
240
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4.1k
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
340
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
450
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
We Are The Robots
honzajavorek
0
280
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Bash Introduction
62gerente
615
220k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
How to build a perfect <img>
jonoalderson
1
5.8k
Thoughts on Productivity
jonyablonski
76
5.3k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Code Reviewing Like a Champion
maltzj
528
40k
Transcript
chiVe: 実用的な日本語単語ベクトル実現にむけて ワークス徳島人工知能NLP研究所 竹林佑斗 2020.12.08 WAP NLP Tech Talk #1
~ Sudachi辞書と単語ベクトル ~
ワークス徳島人工知能NLP研究所 竹林佑斗 経歴: 和歌山高専 → 大阪大学(大学院) → ワークス徳島(2019~) 関わったこと: -
ニューラル機械翻訳(在学中) - チャットボットの研究・開発 趣味: キャンプ、多肉植物、旅行 2 自己紹介
• chiVe: 実用的な日本語単語ベクトル • chiVeの実用面での課題 • chiVeの更なる改良 概要 3 github.com/WorksApplications/chiVe
chiVe GitHub 検索
chiVe: 実用的な日本語単語ベクトル チャ イ ブ 4
• コンピュータにとって単語は記号 • 処理が難しい ◦ 例)すだち、かぼす、いぬ ◦ 「違うこと」しかわからない • コンピュータが扱えるように数値で表現
◦ 単語間の距離も使える ◦ すだち <--> かぼす ◦ すだち <-------------> いぬ → 単語ベクトル 5 単語ベクトルとは すだち かぼす ゆこう いぬ ねこ 単語ベクトル空間 さる
事前学習済みの単語ベクトル • コーパス(ラベル無しデータ)から、単語間の共起に基づき獲得 ◦ 単語ごとの、数百次元程度の実数値ベクトル ◦ word2vec, GloVe, fastText など
• 様々なタスクで活用可能 ◦ 「対象タスクと直接関係がない(大規模)コーパス」を活用 • 公開リソースを利用することで、手軽に恩恵を得られる 6
主な日本語の分散表現リソース 7 学習コーパス 付記 nwjc2vec NWJC 100億語規模コーパスNWJCを利用、基本的に研究目的に限る hottoSNS-w2v SNS, Wikipedia,
Web 大規模なSNSやWebデータで学習、基本的に研究目的に限る 朝日新聞単語ベクトル 朝日新聞 朝日新聞のテキストで学習、基本的に研究目的に限る HR領域向け単語ベクトル 求人データ 求人検索エンジン「スタンバイ」のデータ Wikipedia2Vec Wikipedia 記事とリンクから、単語とエンティティの分散表現 係り受けに基づく 日本語単語埋込 Wikipedia 単語系列の前後ではなく係り受け関係 fastText Wikipedia, CommonCrawl サブワード(文字n-gram)、157言語 BPEmb Wikipedia Byte Pair Encodingによる教師無し分割、275言語
Sudachi Vector 実用で使えるものを目指す • 性能 • ライセンス 8 chiVeとは チャイブ(エゾネギ)
ユリ科 ネギ属 チャイブ
chiVe: 実用的な日本語単語ベクトル • 100億語規模の超大規模Webコーパス NWJC (国語研) • 形態素解析器 Sudachi による複数粒度分割
9 Sudachiによる複数粒度分割の例 A単位 管 理 会 B単位 C単位 チャ イ ブ 選 挙 委 員 管 理 選 挙 委 員 会 選 挙 管 理 委 員 会
chiVe の作成方法(真鍋+ 2020) 1. テキストの前処理 2. 文分割(A, B, C単位でそれぞれ) 3.
すべてをskip-gramで学習 10
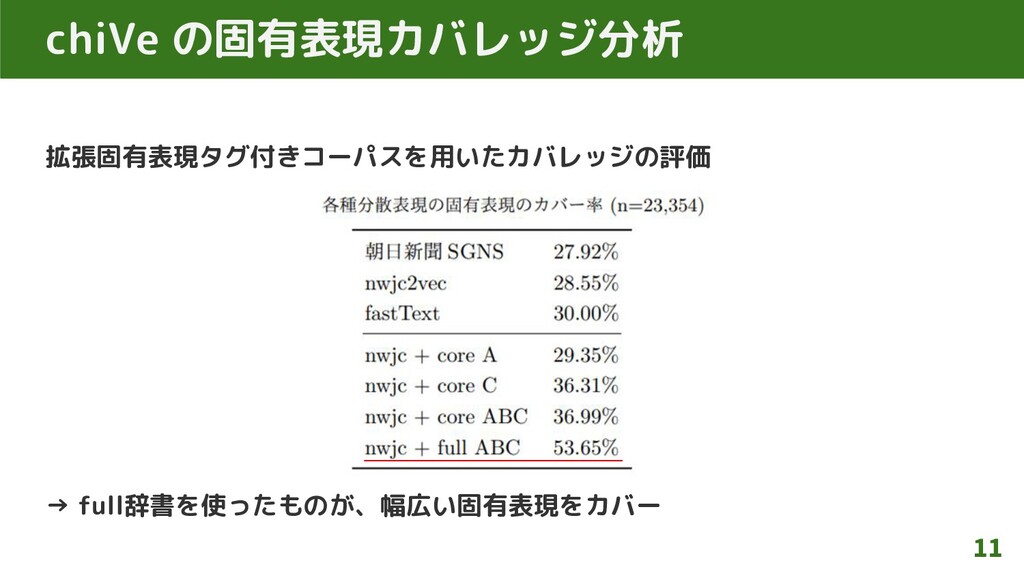
chiVe の固有表現カバレッジ分析 拡張固有表現タグ付きコーパスを用いたカバレッジの評価 → full辞書を使ったものが、幅広い固有表現をカバー 11
→ 複数の分割粒度を同時に学習に使用した方がより高い性能 chiVe の単語間類似度タスクの実験結果 12
阿波 - 徳島 + 高知 = 土佐 13 アナロジータスクの例 vectors.most_similar(positive=["阿波",
"高知"], negative=["徳島"], topn=5) # [('土佐', 0.620033860206604), # ('阿波踊り', 0.5988592505455017), # ('よさこい祭り', 0.5783430337905884), # ('安芸', 0.564490556716919), # ('高知県', 0.5591559410095215)] 徳島 阿波 単語ベクトル空間 高知 土佐
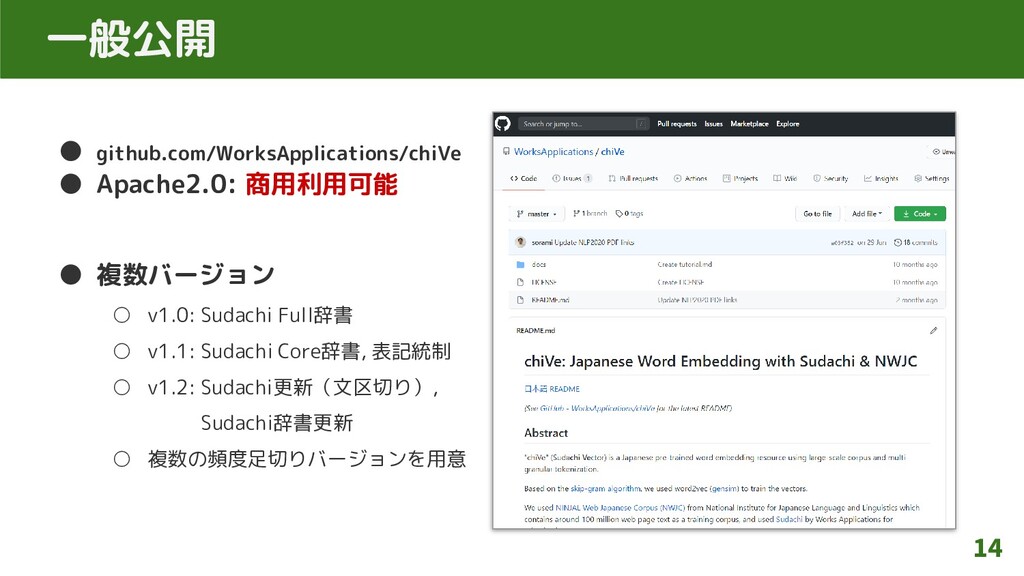
一般公開 • github.com/WorksApplications/chiVe • Apache2.0: 商用利用可能 • 複数バージョン ◦ v1.0:
Sudachi Full辞書 ◦ v1.1: Sudachi Core辞書, 表記統制 ◦ v1.2: Sudachi更新(文区切り), Sudachi辞書更新 ◦ 複数の頻度足切りバージョンを用意 14
まとめ • chiVeは100億語規模の巨大なコーパスを使っている • Sudachi A単位, B単位, C単位すべての語を持つ • mc=5では約320万の語彙に対応
• Apache 2.0 ライセンスで一般公開、商用利用可能 15
chiVe の実用面での課題 (伸びしろ) 16
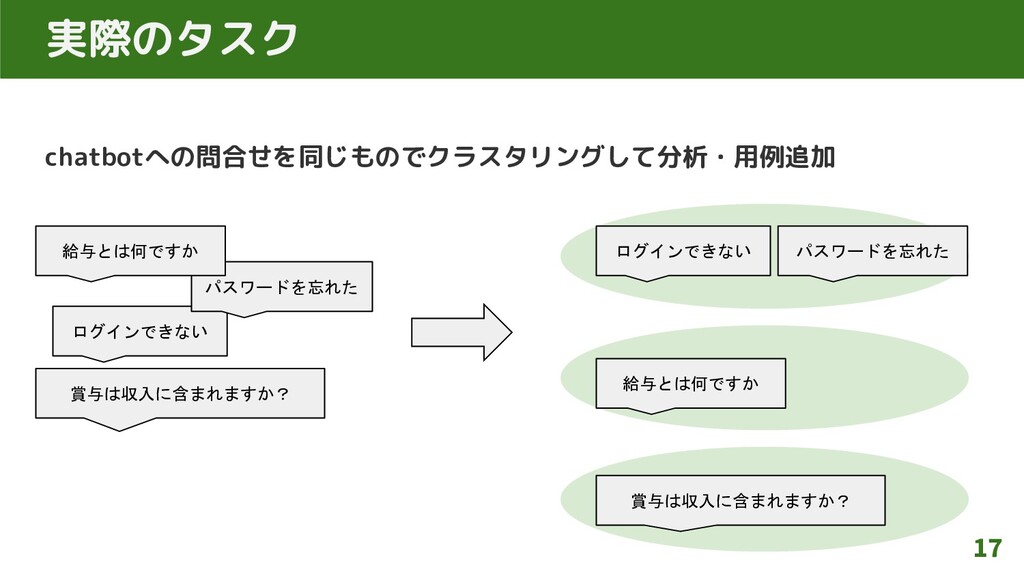
chatbotへの問合せを同じものでクラスタリングして分析・用例追加 17 実際のタスク 給与とは何ですか 賞与は収入に含まれますか? ログインできない パスワードを忘れた 賞与は収入に含まれますか? ログインできない パスワードを忘れた
給与とは何ですか
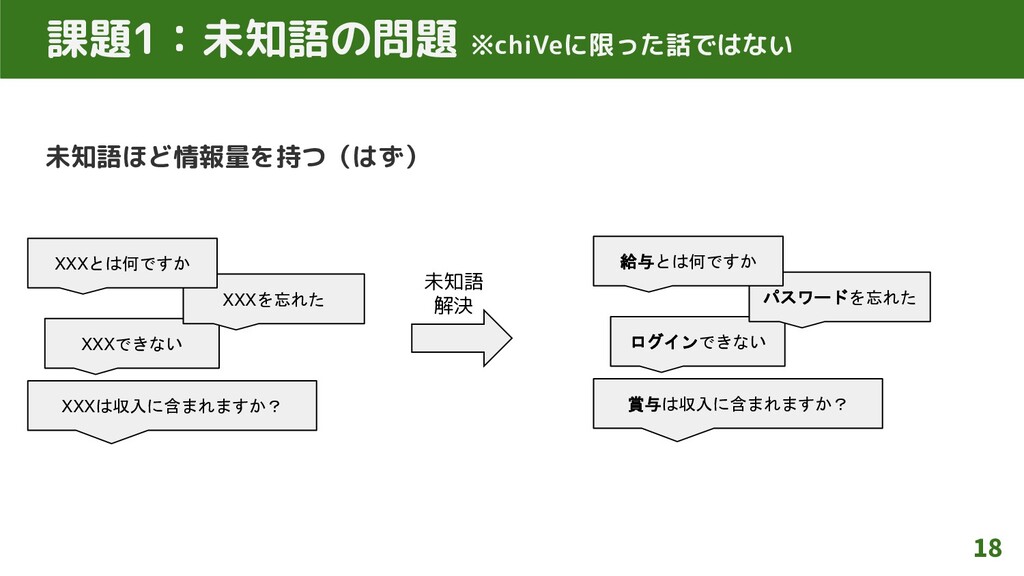
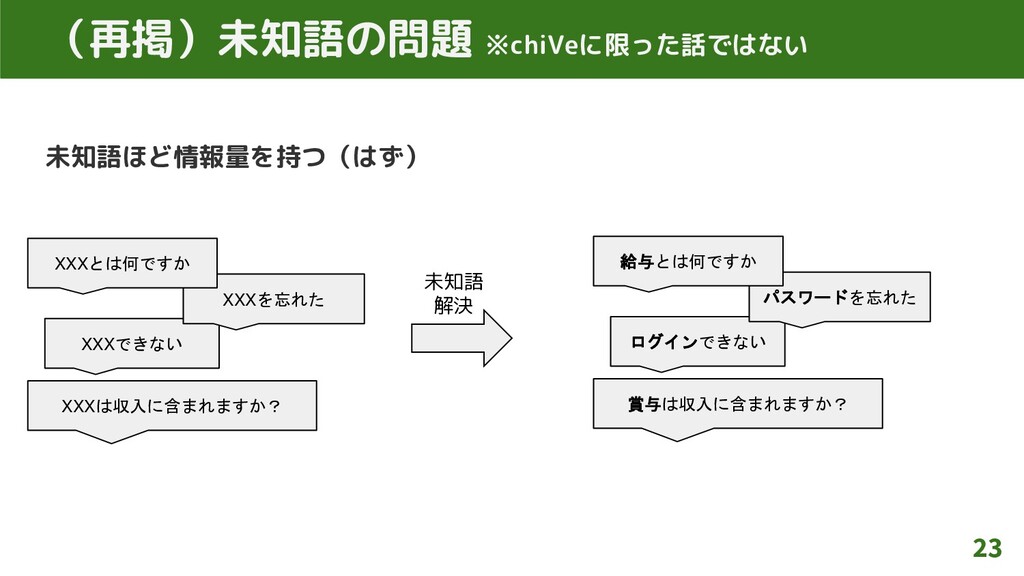
未知語ほど情報量を持つ(はず) 18 課題1:未知語の問題 ※chiVeに限った話ではない XXXは収入に含まれますか? XXXできない XXXを忘れた XXXとは何ですか 賞与は収入に含まれますか? ログインできない
パスワードを忘れた 給与とは何ですか 未知語 解決
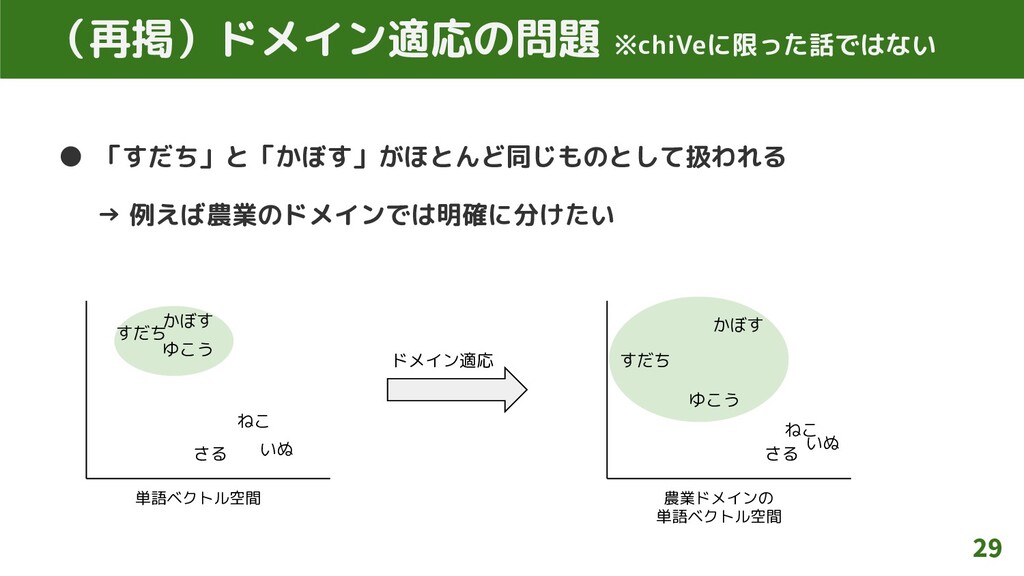
• 「すだち」と「かぼす」がほとんど同じものとして扱われる → 例えば農業のドメインでは明確に分けたい 19 課題2:ドメイン適応の問題 ※chiVeに限った話ではない すだち かぼす ゆこう
いぬ ねこ 単語ベクトル空間 さる すだち かぼす ゆこう いぬ ねこ 農業ドメインの 単語ベクトル空間 さる ドメイン適応
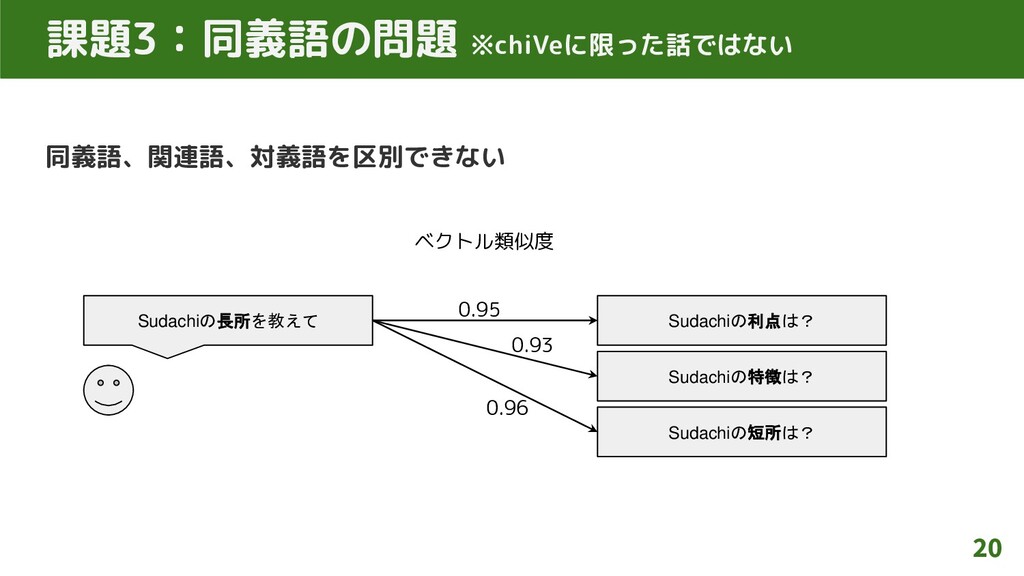
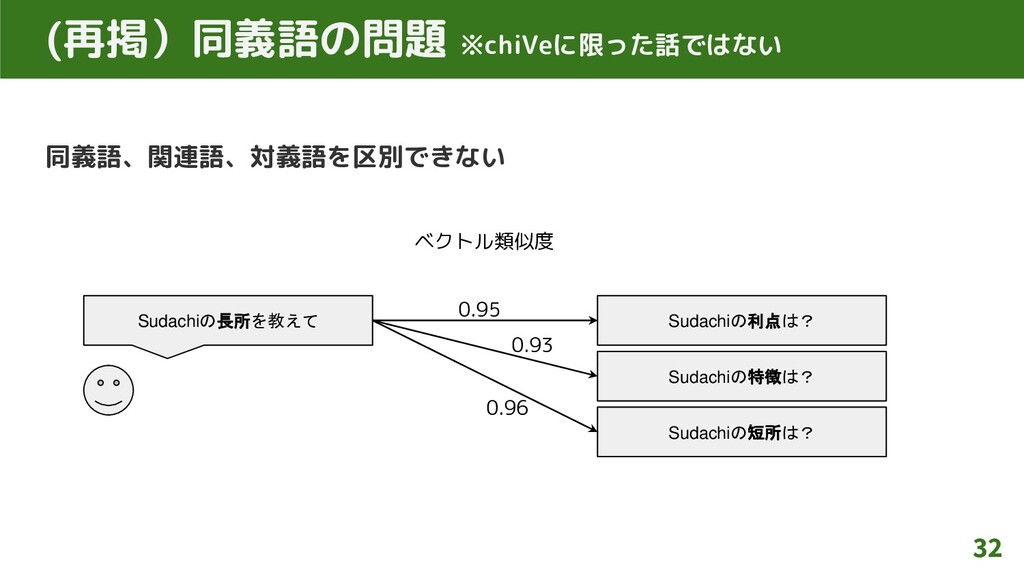
同義語、関連語、対義語を区別できない 20 課題3:同義語の問題 ※chiVeに限った話ではない Sudachiの長所を教えて Sudachiの利点は? Sudachiの特徴は? Sudachiの短所は? ベクトル類似度 0.95
0.93 0.96
更なる改良 21
chiVe の更なる改良へ向けて 品質と利便性の向上へ向けて継続的に取り組んでいる 22 1. 未知語の問題 → 未知語を生成 2. ドメイン適応の問題
→ データを拡充 3. 同義語の問題 → 同義語辞書の活用
未知語ほど情報量を持つ(はず) 23 (再掲)未知語の問題 ※chiVeに限った話ではない XXXは収入に含まれますか? XXXできない XXXを忘れた XXXとは何ですか 賞与は収入に含まれますか? ログインできない
パスワードを忘れた 給与とは何ですか 未知語 解決
改良トピック1. 未知語の取り扱い 未知語(事前学習用コーパスに存在しない語)は大きな課題 • ナイーブな対処法 ◦ その語を無視する ◦ ランダムな「未知語ベクトル」を割り当てる •
未知語がタスクにおいて重要な場合、精度へ大きく影響 • 全ての語を含むコーパスを用意することは非現実的 24
未知語に関する先行研究 未知語の「構成要素」から推定 • 漢字部首, 読み, バイト列, … Sudachi A単位がある! 25
MIMICK (Pinter+ 2017) 文字から未知語ベクトルを生成 ※ 図は(Pinter+ 2017)より引用
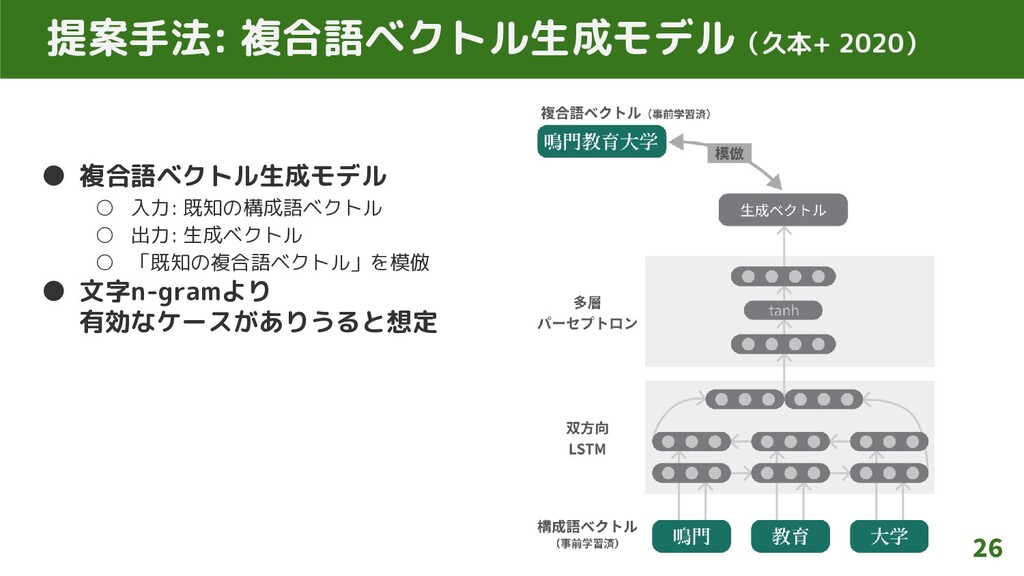
提案手法: 複合語ベクトル生成モデル(久本+ 2020) • 複合語ベクトル生成モデル ◦ 入力: 既知の構成語ベクトル ◦ 出力:
生成ベクトル ◦ 「既知の複合語ベクトル」を模倣 • 文字n-gramより 有効なケースがありうると想定 26
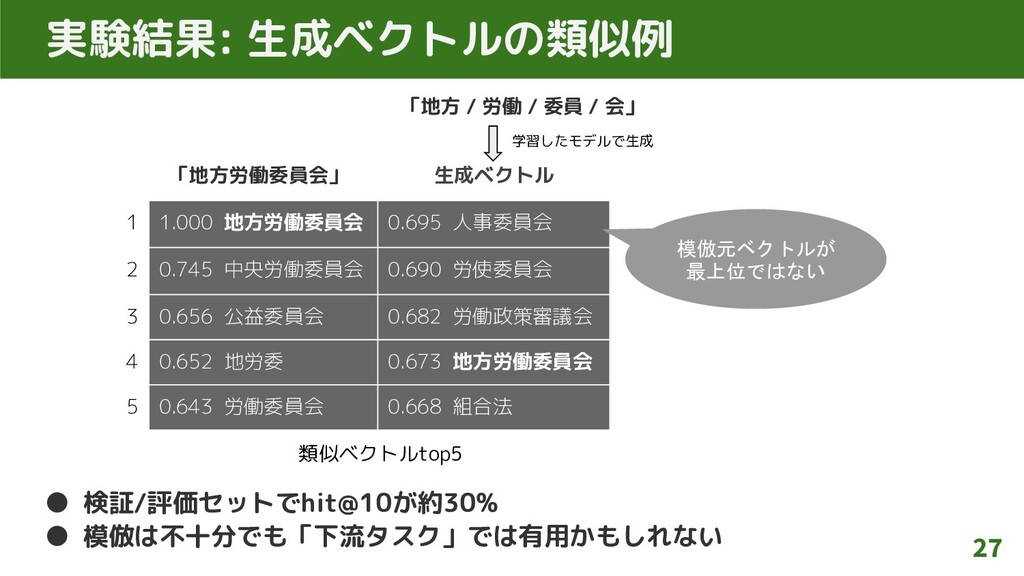
生成ベクトル 1 1.000 地方労働委員会 0.695 人事委員会 2 0.745 中央労働委員会 0.690
労使委員会 3 0.656 公益委員会 0.682 労働政策審議会 4 0.652 地労委 0.673 地方労働委員会 5 0.643 労働委員会 0.668 組合法 実験結果: 生成ベクトルの類似例 「地方労働委員会」 27 • 検証/評価セットでhit@10が約30% • 模倣は不十分でも「下流タスク」では有用かもしれない 模倣元ベクトルが 最上位ではない 「地方 / 労働 / 委員 / 会」 学習したモデルで生成 類似ベクトルtop5
提案手法の問題点と今後の予定 • 実用上の難点 ◦ 未知語が「既知の構成語」から構成されている必要がある ◦ 構成語系列のスパンを特定する必要がある ◦ 利用時にモデルによる生成が必要 •
今後の予定 ◦ 改良機構の模索、成功・失敗例の分析 ◦ 文字・サブワードレベルからの未知語対応 ◦ 品詞(名詞句、複合動詞、...)や文字種(漢字、カタカナ語、...)に適した手法 の検討 28
• 「すだち」と「かぼす」がほとんど同じものとして扱われる → 例えば農業のドメインでは明確に分けたい 29 (再掲)ドメイン適応の問題 ※chiVeに限った話ではない すだち かぼす ゆこう
いぬ ねこ 単語ベクトル空間 さる すだち かぼす ゆこう いぬ ねこ 農業ドメインの 単語ベクトル空間 さる ドメイン適応
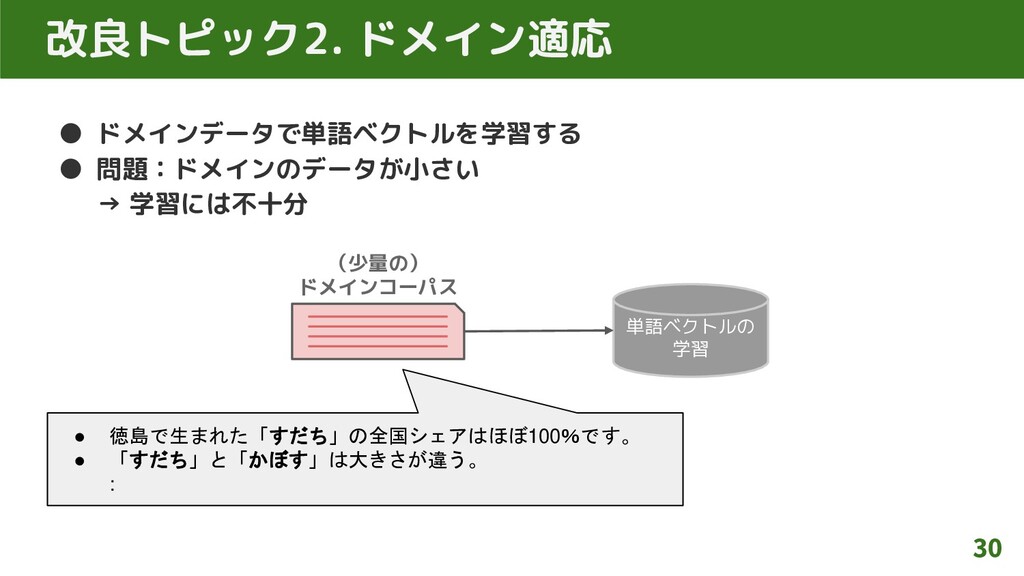
改良トピック2. ドメイン適応 • ドメインデータで単語ベクトルを学習する • 問題:ドメインのデータが小さい → 学習には不十分 30 単語ベクトルの
学習 (少量の) ドメインコーパス • 徳島で生まれた「すだち」の全国シェアはほぼ100%です。 • 「すだち」と「かぼす」は大きさが違う。 :
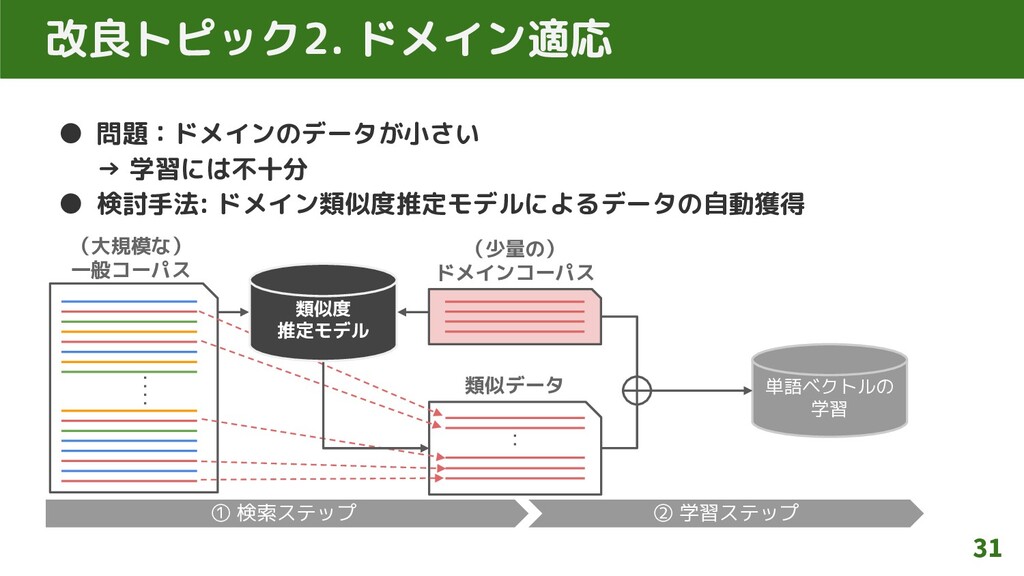
改良トピック2. ドメイン適応 • 問題:ドメインのデータが小さい → 学習には不十分 • 検討手法: ドメイン類似度推定モデルによるデータの自動獲得 31
単語ベクトルの 学習 (大規模な) 一般コーパス (少量の) ドメインコーパス 類似データ ① 検索ステップ ② 学習ステップ 類似度 推定モデル
同義語、関連語、対義語を区別できない 32 (再掲)同義語の問題 ※chiVeに限った話ではない Sudachiの長所を教えて Sudachiの利点は? Sudachiの特徴は? Sudachiの短所は? ベクトル類似度 0.95
0.93 0.96
改良トピック3. 同義語辞書の活用 • Sudachi同義語辞書 33
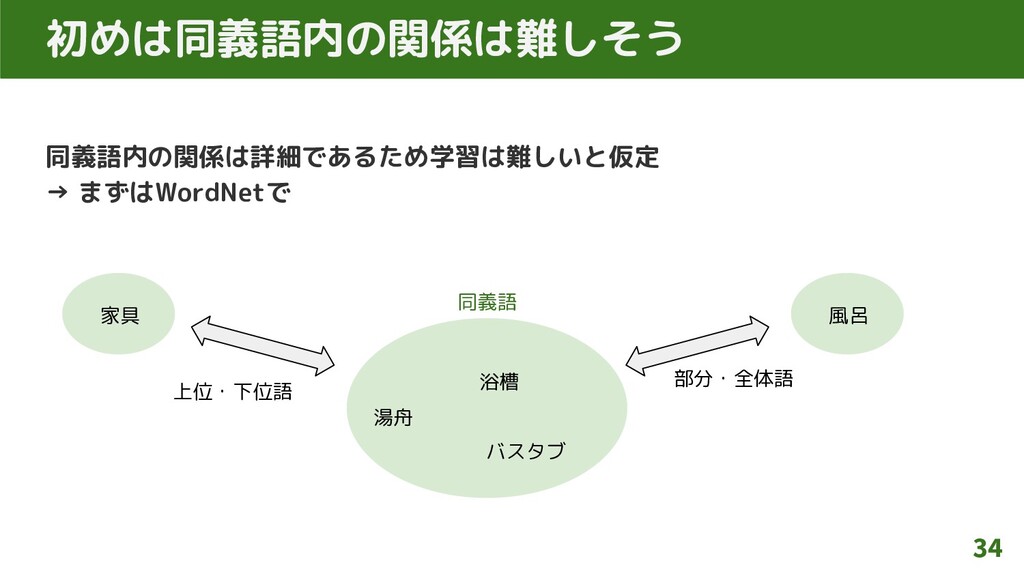
同義語内の関係は詳細であるため学習は難しいと仮定 → まずはWordNetで 34 初めは同義語内の関係は難しそう 風呂 部分・全体語 浴槽 湯舟 バスタブ
家具 上位・下位語 同義語
同義語資源からRelation Embeddingを獲得 TransE (Bordes+ 2013) を利用 35 h: 浴槽 t:
風呂 r: 全体語 head: 浴槽 tail: 風呂 relation : 全体語
まとめ • chiVe: 実用的な日本語単語ベクトル ◦ 100億語規模のWebコーパス NWJC ◦ 形態素解析器 Sudachi
による複数粒度分割 ◦ Apache 2.0 ライセンスで一般公開、商用利用可能 • chiVeの更なる改良 ◦ 未知語の取り扱い ◦ ドメイン適応 ◦ 同義語辞書の活用 36 github.com/WorksApplications/chiVe 質問・議論のための Slack もあります! chiVe GitHub 検索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}