Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
事前学習モデル chiTra の活用方法 at WAP NLP Tech Talk #5
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
WAP
April 28, 2022
Technology
380
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
事前学習モデル chiTra の活用方法 at WAP NLP Tech Talk #5
WAP
April 28, 2022
More Decks by WAP
See All by WAP
単語分散表現と事前学習モデル - chiVe _ chiTra 利活用のための下準備 at WAP NLP Tech Talk #5
waptech
0
1.5k
単語分散表現 chiVeの活用方法 at WAP NLP Tech Talk #5
waptech
0
690
Sudachi Family近況報告 at WAP NLP Tech Talk #5
waptech
0
280
Sudachi近況報告 at WAP NLP Tech Talk #4
waptech
1
560
日本語形態素解析器 SudachiPy の 現状と今後について
waptech
5
8.3k
企業(ワークスアプリケーションズ)での研究開発の楽しさと苦労
waptech
0
420
Sudachi辞書のつくり方
waptech
4
2.7k
chiVe_実用的な日本語単語ベクトル実現にむけて_20201208.pdf
waptech
2
660
Other Decks in Technology
See All in Technology
穢れた技術選定について
watany
19
6.2k
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
490
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
280
そのドキュメント、自動化しませんか?
yuksew
1
420
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
310
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
500
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
140
発表と総括 / Presentations and Summary
ks91
PRO
0
190
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
170
Featured
See All Featured
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Agile that works and the tools we love
rasmusluckow
331
22k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The Limits of Empathy - UXLibs8
cassininazir
1
530
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Side Projects
sachag
455
43k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Test your architecture with Archunit
thirion
1
2.3k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Transcript
© 2022 Works Applications Systems Co., Ltd. 事前学習モデル chiTra の活用方法
林 政義
© 2022 Works Applications Systems Co., Ltd. 自己紹介 2 林
政義(はやし まさよし) 経歴 ~ 2018.03 東京大学 杉山研究室 (情報理工学系研究科 コンピュータ科学専攻) 修士課程 修了 2018.04 ~ 株式会社ワークスアプリケーションズ 現在の所属は 株式会社ワークスアプリケーションズ・システムズ データエンジニアリング / 自然言語処理技術の研究開発に従事 そのほか 北海道出身・東京在住 テレワーク最高! 吹奏楽畑(打楽器)
© 2022 Works Applications Systems Co., Ltd. アウトライン chiTra とは
事前学習モデルについて chiTra の特徴 実タスクへの活用 タスクに合わせた調整:ファインチューニング 実例:livedoorニュース分類 その他の応用例 3
© 2022 Works Applications Systems Co., Ltd. chiTraモデルとは 事前学習モデルについて
chiTra の特徴
© 2022 Works Applications Systems Co., Ltd. chiTra とは? chiTra:
Sudachi Transformers Transformers対応の形態素解析器および事前学習済み大規模言語モデル Hugging Face Transformers: ニューラル言語モデルを扱う OSS 文章そのままは大きいので、トークン (モデル用の単語)に分割して扱うのが一般的 → Sudachi による分割の単位で入出力を扱えるようにしたい chiTra モデル (v1.0) これを用いて作成した事前学習済み BERT モデル Apache 2.0 ライセンスで一般公開、商用利用も可能 国立国語研究所の大規模コーパス NWJC で学習 Sudachi の正規化情報を利用し表記ゆれに頑健 → 特長の詳細は後のスライドで改めて解説します 5
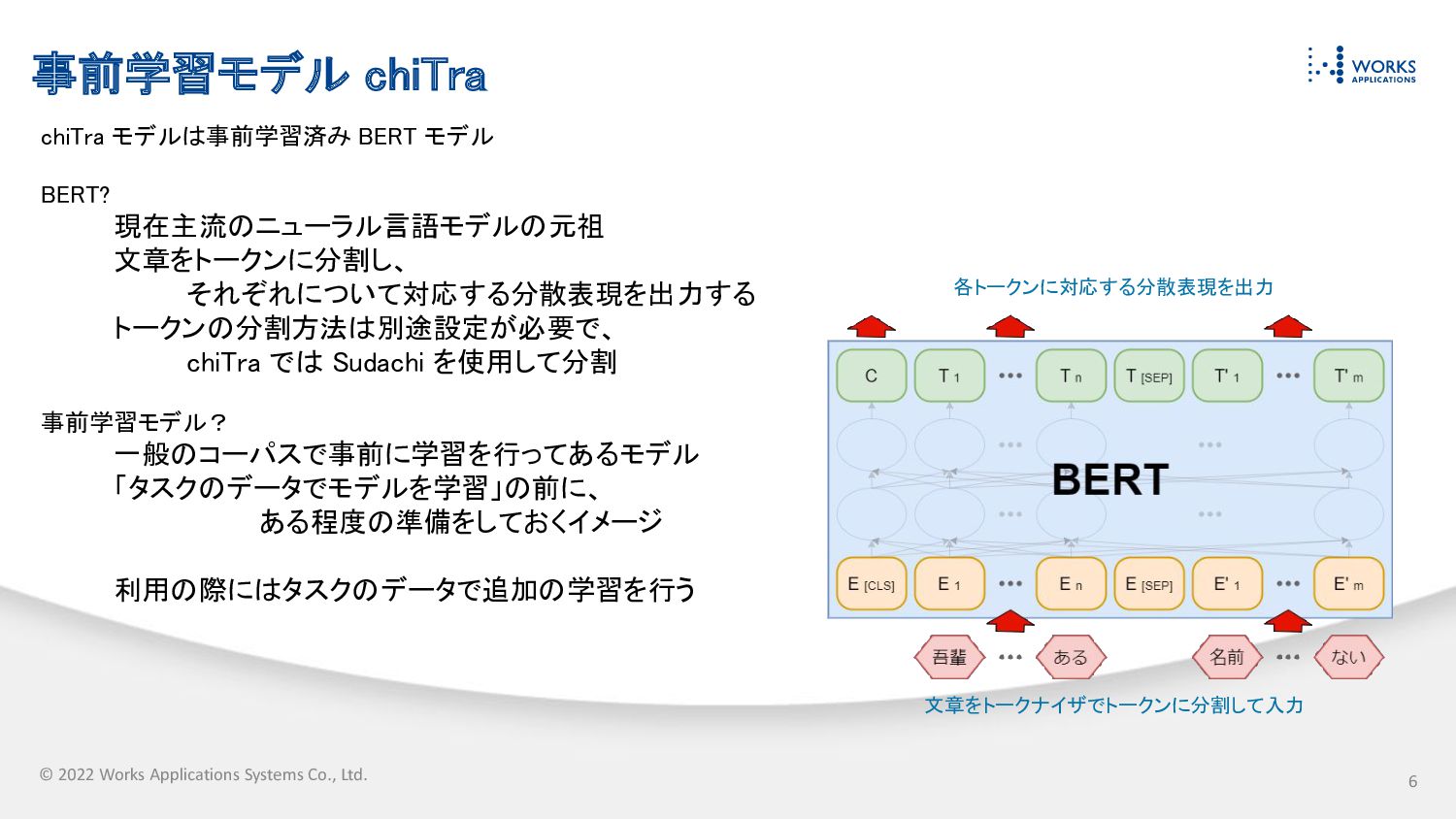
© 2022 Works Applications Systems Co., Ltd. 事前学習モデル chiTra chiTra
モデルは事前学習済み BERT モデル BERT? 現在主流のニューラル言語モデルの元祖 文章をトークンに分割し、 それぞれについて対応する分散表現を出力する トークンの分割方法は別途設定が必要で、 chiTra では Sudachi を使用して分割 事前学習モデル? 一般のコーパスで事前に学習を行ってあるモデル 「タスクのデータでモデルを学習」の前に、 ある程度の準備をしておくイメージ 利用の際にはタスクのデータで追加の学習を行う 文章をトークナイザでトークンに分割して入力 各トークンに対応する分散表現を出力 6
© 2022 Works Applications Systems Co., Ltd. 事前学習モデル chiTra 事前学習では何を学習している?
大規模コーパスから汎用的な言語表現を学習 文章を理解できればタスクも解けるはず → ここでは文の穴埋めができるようにする 様々な文章表現からトークンの現れ方を学習する そのため学習コーパスは大きい方が良いとされる 文の穴埋め:Masked Language Modeling 文章中の隠された部分を復元するように学習 文章の全体を見て文脈からトークンを推定する 文脈に合った分散表現を出力 多義語でも文脈に沿った分散表現を出力できる ex. アップル(果物/社名) 「吾輩は[MASK]である」を入力 「吾輩は猫である」に復元するよう学習 7
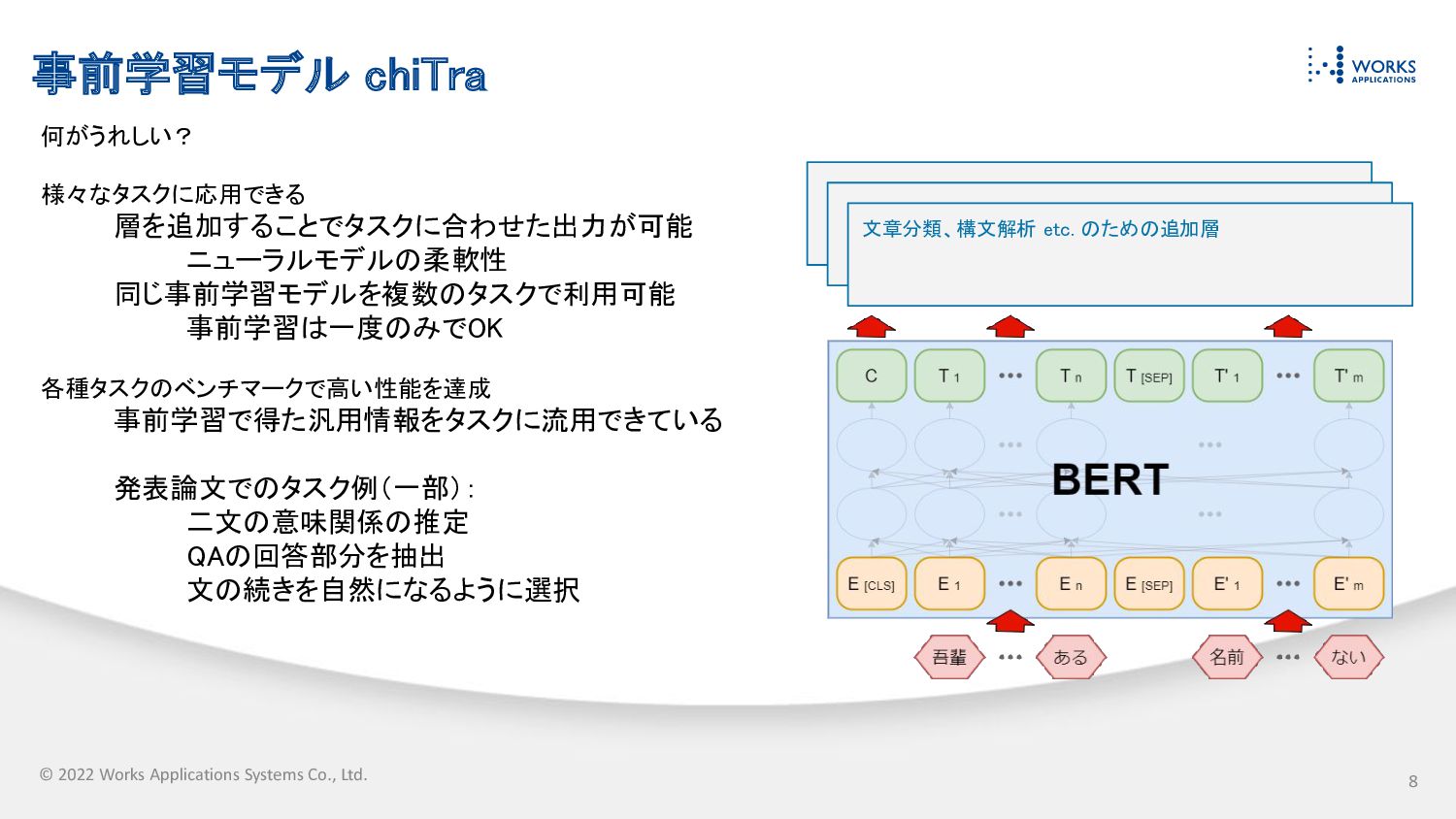
© 2022 Works Applications Systems Co., Ltd. 何がうれしい? 様々なタスクに応用できる
層を追加することでタスクに合わせた出力が可能 ニューラルモデルの柔軟性 同じ事前学習モデルを複数のタスクで利用可能 事前学習は一度のみでOK 各種タスクのベンチマークで高い性能を達成 事前学習で得た汎用情報をタスクに流用できている 発表論文でのタスク例(一部): 二文の意味関係の推定 QAの回答部分を抽出 文の続きを自然になるように選択 文章分類、構文解析 etc. のための追加層 事前学習モデル chiTra 8
© 2022 Works Applications Systems Co., Ltd. chiTra モデルの特長 事前学習済み
BERT モデル Apache 2.0 ライセンスで一般公開 商用利用可能 Hugging Face Transformers フレームワークから利用可能 ニューラル言語モデルを扱うOSSで、サンプル等も充実 国立国語研究所の大規模コーパス NWJC(100億語超規模)で事前学習 より広範な言語表現を学習 他公開モデルでは日本語Wikipedia (1億語規模)の採用が多い 単語正規化込みでの学習(独自) 文章をトークンへ分割する際、Sudachi 辞書の情報を使って表記を正規化 「引越してからすだちを届けます」 →「引っ越ししてから酢橘を届けます」 表記ゆれのある入力を安定して扱える 例の二文は同じものとしてモデルに扱われ、出力も同じになる 9
© 2022 Works Applications Systems Co., Ltd. chiTraモデルの活用 タスクに合わせた調整:ファインチューニング
実例:livedoorニュース分類 その他の応用例
© 2022 Works Applications Systems Co., Ltd. ファインチューニング ファインチューニング? タスクのデータを用いてモデルに追加の学習を加えること
そのままでは文の穴埋めに特化した状態 タスクで必要な形にさらにチューニングする BERT系モデルの利用では標準的な方法 一般の機械学習ではモデルは固定し後段の部分のみ学習することが多い ニューラルモデルの柔軟性 具体的には何を行う? タスクに必要な出力の形式に合わせてモデルに層を追加 タスクデータでモデル 全体(BERT部分含む)を学習 パラメータの探索 追加学習の際のパラメータ設定が最終的な性能に影響 → 適切なものを探索する必要がある 機械学習一般で必要 11 文章分類、構文解析 etc. のための追加層
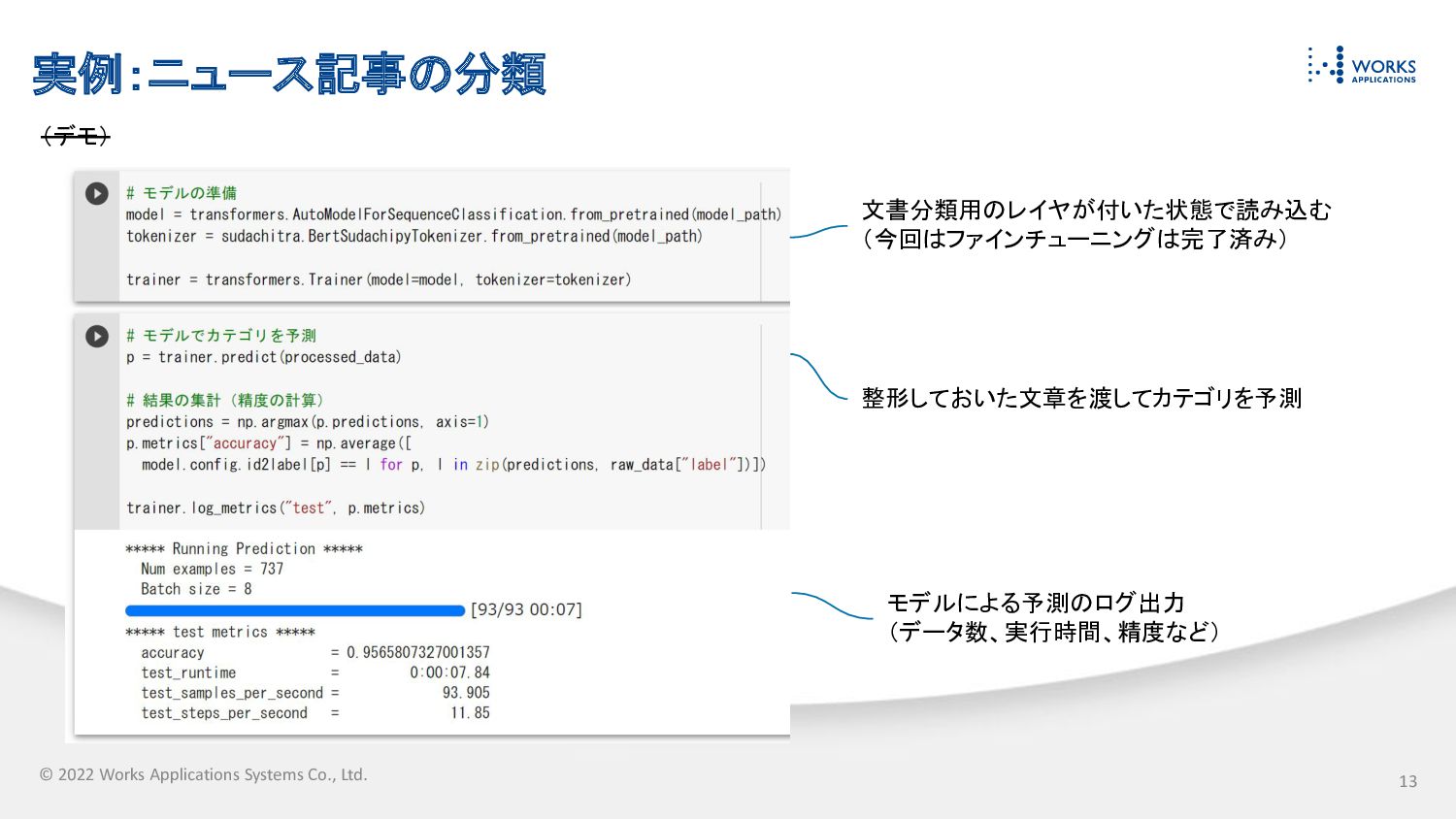
© 2022 Works Applications Systems Co., Ltd. 実例:ニュース記事の分類 livedoor ニュースコーパスを使用
9カテゴリのニュース記事 7367件を収集・整形したデータセット サンプル(タイトルのみ): トピックニュースカテゴリ:「ジャンプ連載漫画が終了に、ユーザが新たな提案!?」 家電チャンネルカテゴリ:「【ニュース】電力使用量9日が8社管内で今夏最高」 文書分類問題 記事本文を入力として、どのカテゴリのものなのかを判定する 90% (6630件) を使ってファインチューニング、残りの10% (737件) で性能を評価 12
© 2022 Works Applications Systems Co., Ltd. 実例:ニュース記事の分類 (デモ) 13
文書分類用のレイヤが付いた状態で読み込む (今回はファインチューニングは完了済み) 整形しておいた文章を渡してカテゴリを予測 モデルによる予測のログ出力 (データ数、実行時間、精度など)
© 2022 Works Applications Systems Co., Ltd. 実例:ニュース記事の分類 単純な実装で高精度 分類用の層を足しただけのシンプルなモデル+ファインチューニングのみ
さらに調整を行う余地がある 計算コストは大きい 実用的にはGPUはほぼ必須 深層学習モデルの宿命 なお事前学習には数日~数週間が必要 モデルの規模に対して本来必要な学習をスキップできているとも言える 分類精度 計算機 評価時間(737件) ファインチューニング時間 (論文推奨の18パラメタを探索) 0.957 GPU 使用 約 8 秒 (秒間 90件強) 1 時間程度 0.957 CPU のみ 約22分 (秒間 0.5件強) - 14
© 2022 Works Applications Systems Co., Ltd. その他の応用例 文章分類 文章を一定のカテゴリに分類する
ex. 何に関する文章かで分類、レビュー文での評価の高低を計測 該当箇所の選択 文章内で条件に当てはまる範囲を探す ex. 質問の回答にあたる部分を選択 「日本の現首相は誰?」「新型コロナ対策をめぐり、 岸田総理大臣は…」 項目の選択 いくつかの選択肢のうち最も適当なものを選ぶ ex. 最も自然な文章になるものを選択 「雨の予報だったので」→「ご飯を食べた」「 傘を持っていった」「…」 トークン単位の処理 文書全体ではなくトークンごとに処理を行う ex. 文中のキーワードをそれぞれラベル付け 「大リーグエンゼルスチーム名の大谷翔平人名選手は13日日時、…」 15
© 2022 Works Applications Systems Co., Ltd. さらなる応用 より発展的なタスク 前ページの例は比較的シンプルなもの
コードサンプルも存在している さらに複雑な問題への応用もありうる 前例を複数組み合わせる より長い・多くの文書の処理 テキスト以外の業務データの併用 ex. 画像や音声、売上などの数値データ モデル自体への追加の調整 モデルの方に調整を加えることで性能を向上させる研究も存在する 特定の分野に特徴的な表現の現れ方に反応できるようにする このスライド内での「モデル」 / 服飾系の分野における「モデル」 語彙・トークン分割を変更して扱えるようにする 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}