Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Sudachi辞書のつくり方
Search
WAP
December 09, 2020
Research
2.7k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Sudachi辞書のつくり方
WAP
December 09, 2020
More Decks by WAP
See All by WAP
単語分散表現と事前学習モデル - chiVe _ chiTra 利活用のための下準備 at WAP NLP Tech Talk #5
waptech
0
1.5k
事前学習モデル chiTra の活用方法 at WAP NLP Tech Talk #5
waptech
0
380
単語分散表現 chiVeの活用方法 at WAP NLP Tech Talk #5
waptech
0
690
Sudachi Family近況報告 at WAP NLP Tech Talk #5
waptech
0
280
Sudachi近況報告 at WAP NLP Tech Talk #4
waptech
1
560
日本語形態素解析器 SudachiPy の 現状と今後について
waptech
5
8.3k
企業(ワークスアプリケーションズ)での研究開発の楽しさと苦労
waptech
0
420
chiVe_実用的な日本語単語ベクトル実現にむけて_20201208.pdf
waptech
2
660
Other Decks in Research
See All in Research
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
180
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
890
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
120
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
230
typst の使い方:言語学を研究する学生のために
gitomochang
0
520
LLM Compute Infrastructure Overview
karakurist
2
1.5k
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
170
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
120
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
710
Featured
See All Featured
Practical Orchestrator
shlominoach
191
11k
Git: the NoSQL Database
bkeepers
PRO
432
67k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Chasing Engaging Ingredients in Design
codingconduct
0
240
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
380
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
A Soul's Torment
seathinner
6
3.1k
It's Worth the Effort
3n
188
29k
Transcript
Sudachi辞書のつくり方 株式会社ワークスアプリケーションズ ワークス徳島人工知能NLP研究所 高岡一馬
2 自己紹介 • 奈良先端科学技術大学院大学で自然言語処理をまなぶ 形態素解析器茶筌と出会う • 2004-2016年 株式会社ジャストシステム かな漢字変換、テキストマイニングなどに従事 2つの形態素解析器の開発にたずさわる
• 2016年- 株式会社ワークスアプリケーションズ 形態素解析器Sudachiを開発
3 徳島って • 四国の右下 • 人口72万人(徳島市25万人) • 電車のない唯一の県
4 実務でつかう形態素解析
5 実務でつかえる形態素解析器 プロプラエタリ OSS • 処理系 MeCabとそのクローン • 辞書 IPADic
/ UniDic NEologd
6 MeCabをつかうと よいところ • 速い • カスタマイズの柔軟性(辞書、未知語処理) つらいところ • 単機能
前処理、後処理が必須 区切り、品詞(連接ID)以外は辞書次第
7 実務で必要になる機能 • 文字正規化(表記統制) • 語彙正規化(表記統制) • 未知語処理 • 文区切り
• 記号類や非テキストのクリーニング • 典型的な誤解析の訂正(再学習はほぼ不可能) • 読み付与 • 同義語 などなど 非NLPerにはむずかしい & ノウハウが共有されていない
8 未知語の処理 ただしい区切りをあたえる • 未知の未知語 • 既知の未知語 部分は知っているが全体は未知 例)既知語「世界的」、未知語「地球 /
的」 読み推定
9 辞書の比較 IPADic • 区切りが直観にあう • メンテナンスされていない UniDic • 解析精度がよい(見かけ上)
• 区切りが直観的でない • 短すぎる
10 辞書の比較 NEologd • 膨大な語彙 • 読み推定 • 癖がつよい 検索などには向いている
11 なので形態素解析器を(また)つくった • 処理系と辞書を一体で • プラグイン機構による処理のパッケージ化 よくつかう機能の提供 ノウハウの共有 • 目的にあわせた複数粒度分割
• 文字、単語の正規化 • 同義語辞書との連携
12 辞書のつくり方
13 表記正規化 文字正規化 • いわゆる半角・全角、組み立て文字、記号類 例)㈱、ー―-‐ • 異体字 例)辺、邉、邊 語彙正規化 • 単語単位での正規化
• 送り仮名 例)組み替え、組替え、組替 • 誤用 例)シュミレーション
14 正規化と代表表記 正規化 • 一意であればよい 代表表記 • 「代表」をきめる • どの表記が代表的なのか
15 代表表記のきめかた 機械的:頻度による決定 • 一貫性がない • 頻度が直観に反する場合 • 頻度がとれない場合 •
特定のIMEを再現しているだけかも 人手で • 根拠 • ルール 例)生物名はカタカナ きりん→キリン、象→ゾウ
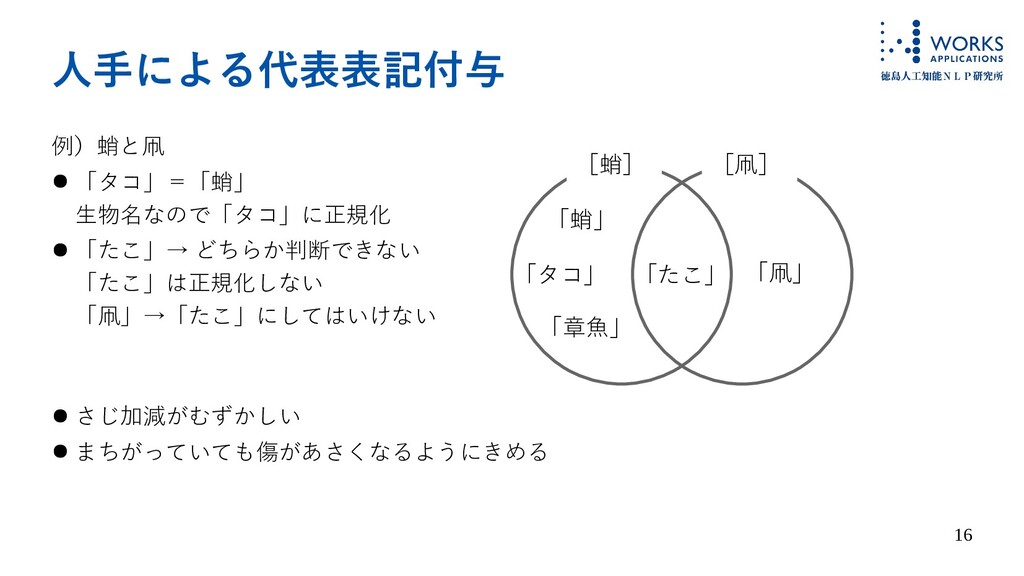
16 人手による代表表記付与 例)蛸と凧 • 「タコ」=「蛸」 生物名なので「タコ」に正規化 • 「たこ」→ どちらか判断できない 「たこ」は正規化しない
「凧」→「たこ」にしてはいけない • さじ加減がむずかしい • まちがっていても傷があさくなるようにきめる [蛸] 「蛸」 「タコ」 「章魚」 「たこ」 「凧」 [凧]
17 正規化と語分割 例)松葉ガニ • 原則)生物名はカタカナ • A単位「松葉 / ガニ」 •
「ガニ」と「カニ」が同一視できない → 「蟹」に正規化
18 生成処理への流用 サジェストや文生成にもつかいたい → 解析処理とはちがった問題 • 代表性 ユーザからみて奇異な表記は出せない UniDic 語彙素は原則漢字表記「ちりばめる」→「鏤める」
• 規範性 誤用の抑制、不快語の扱い
19 Sudachiの分割単位 A単位 • UniDic相当(互換性) • カバレッジの確保 B単位 • ひとにとって一番自然な単位(にしたい)「心的辞書」
C単位 • 固有表現 • 検索や外延の認識
20 分割情報の付与 語構成は2次元的 徳島研究所 徳島 研究所 研究 所 C単位 B単位
A単位
21 分割情報の付与 県立美術館前駅 県立美術館前 駅 県立美術館 前 県立 美術館 美術
館 C単位分割「県立美術館前駅」 B単位分割「県立 / 美術館 / 前 / 駅」 A単位分割「県立 / 美術 / 館 / 前 / 駅」
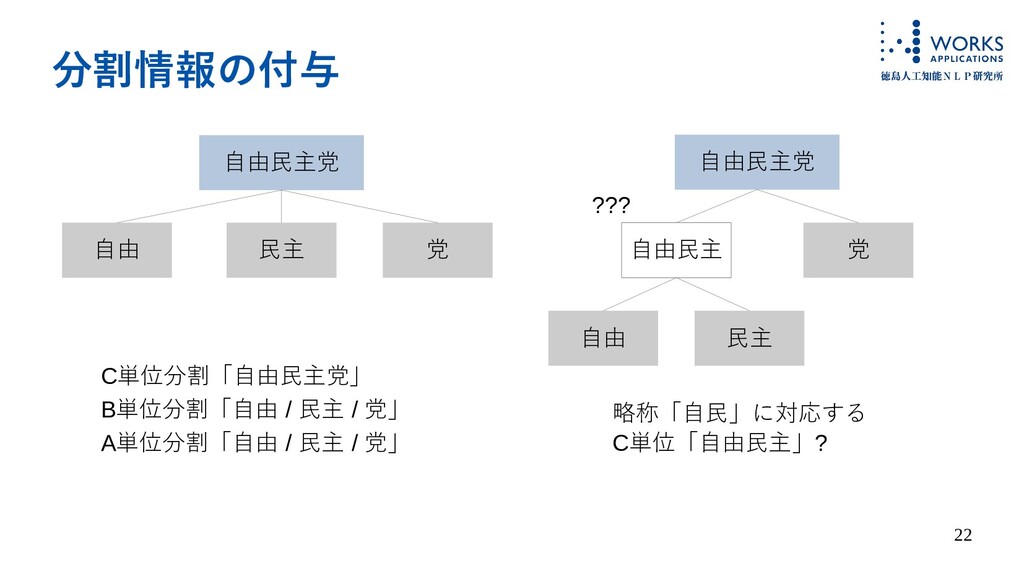
22 分割情報の付与 自由民主党 自由 民主 党 C単位分割「自由民主党」 B単位分割「自由 / 民主
/ 党」 A単位分割「自由 / 民主 / 党」 自由民主党 自由民主 民主 党 自由 略称「自民」に対応する C単位「自由民主」? ???
23 語構成と分割 多段分割 vs 分割レベルの固定 • Sudachiでは分割レベルを3つに固定 • 多段にすればすべての分割を導出できる 分割に意味づけがないのでつかいにくい
24 他のリソースとの連携 形態素解析を他の処理とつなげていきたい • 辞書をつかう意味 語の同定 → 他の資源と直接むすびつけられる 同義語辞書との連携 •
Sudachi同義語辞書 同義語処理ライブラリChikkarもGitHubで公開中
25 実務でつかえる同義語辞書とは 本当に必要なのは同義語なのか? 例)「Suica」と書かれたテキストを他のICカード名でも検索 できるようにしたい タスクによって解像度がちがう 例)一般ドメイン:「借金」≒「債務」≒「負債」 会計・法律ドメイン: • 債務:金銭や物品の給付、なんらかの行為をする義務がある
• 負債:企業が第三者に支払う義務があるもの • 借金:金銭消費貸借契約をかわしてお金をかりる
26 実務でつかえる同義語辞書とは なにを同義とみなすかは自明ではない • 「同義」にこだわらない Is-a, part-ofなども • タスクを意識する なやみだすと泥沼に
ドメインによってちがう • システム辞書は抑制的に • 専門辞書で踏み込む
27 まとめ 実務でつかえる形態素解析器 • コア以外の機能も重要 人手での辞書チューニングが必須 • 総合的な判断が必要 • 原則をまげることも
辞書ベースだからできること • 他リソースとの結合
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}