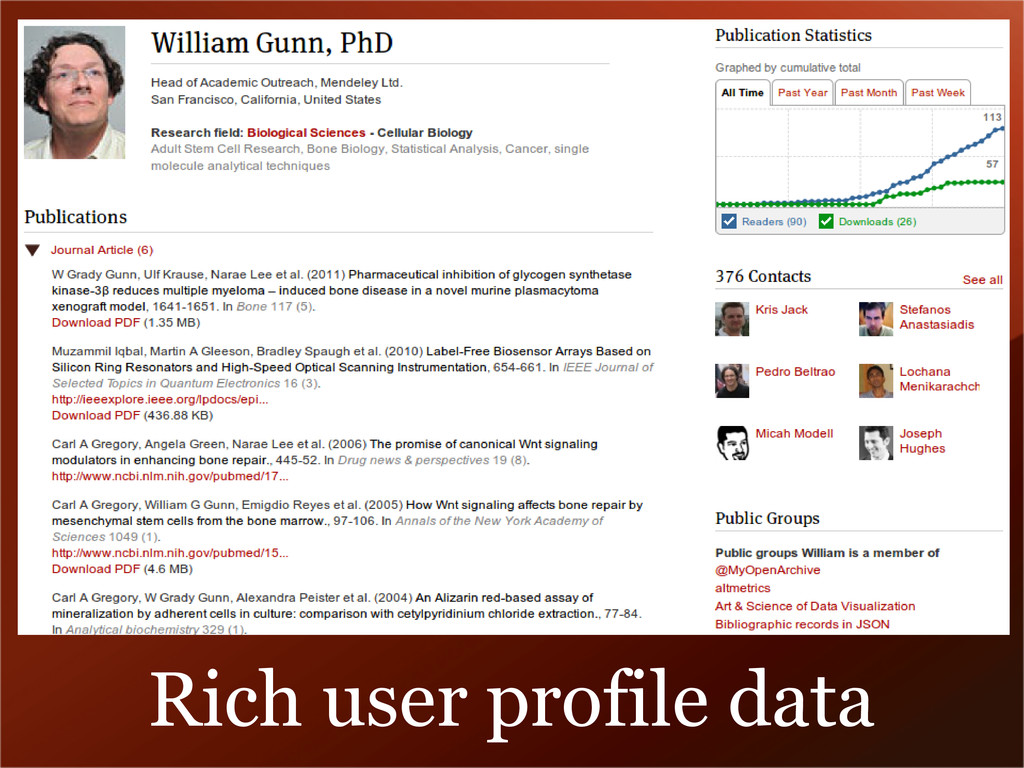
Big Data and Bibliometrics: Crowdsourcing the World’s Largest Open Database of Research
This presentation was delivered at O'Reilly's Strata conference in Santa Clara on how Mendeley is using technologies such as Hadoop and Mahout for scaling and recommendation.
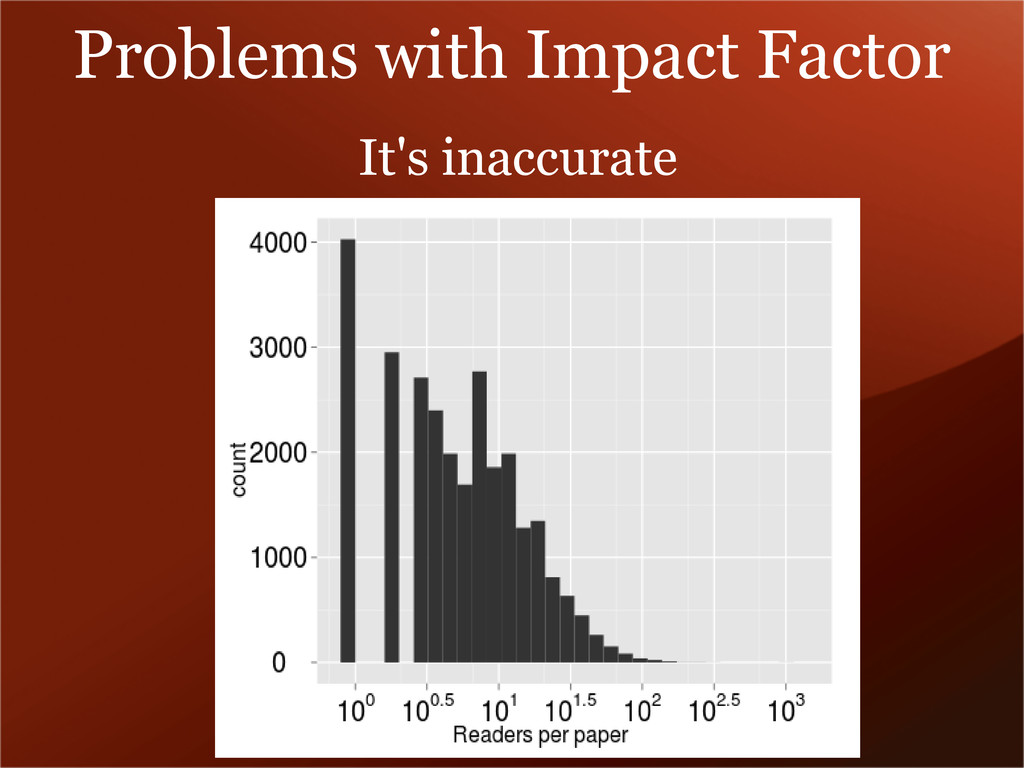
of the impact factor game...has no obligation to be accountable to... the authors and readers of scientific research. During discussions with Thomson Scientific over which article types in PLoS Medicine the company deems as “citable,” it became clear that the process of determining a journal's impact factor is unscientific and arbitrary.”
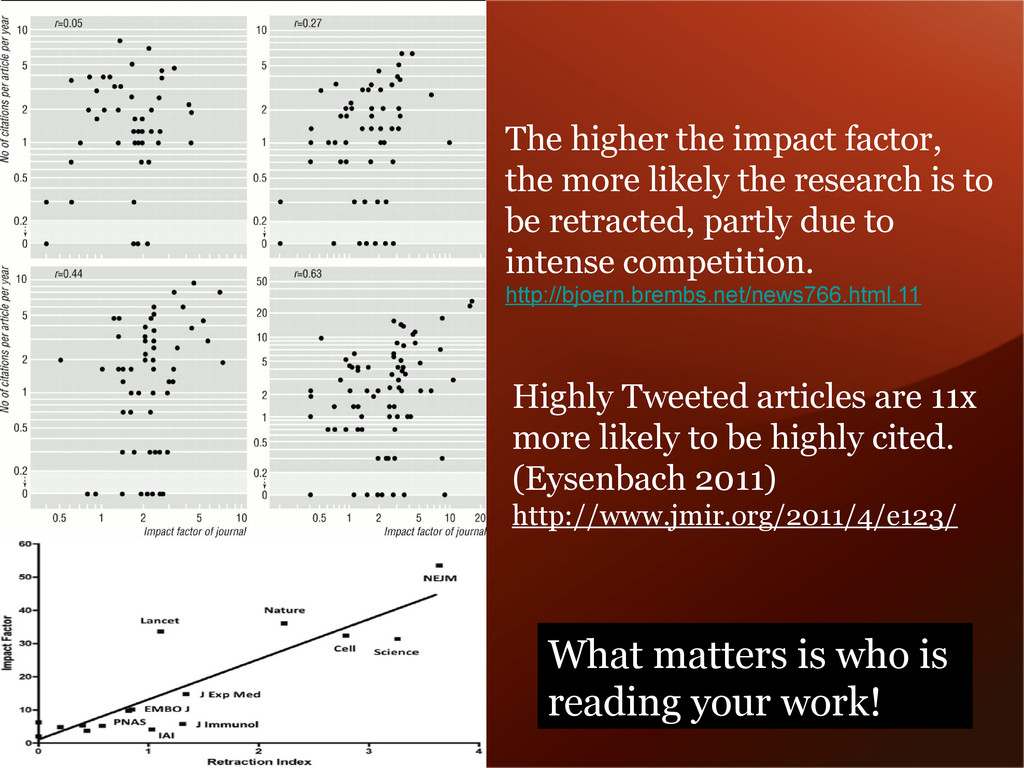
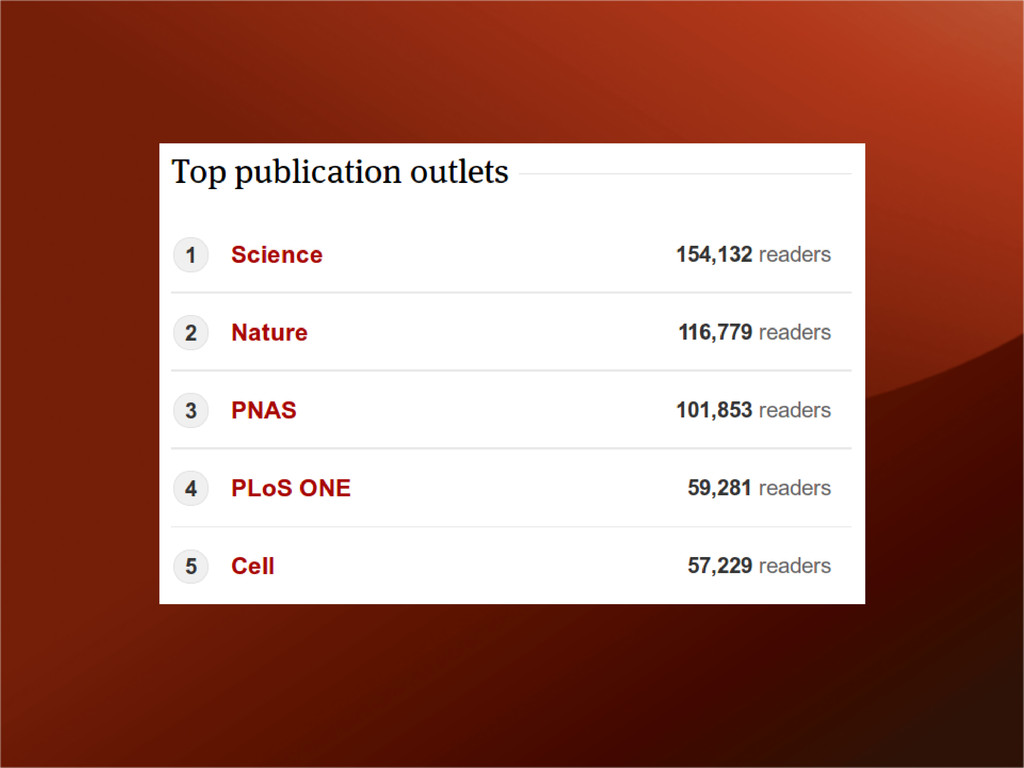
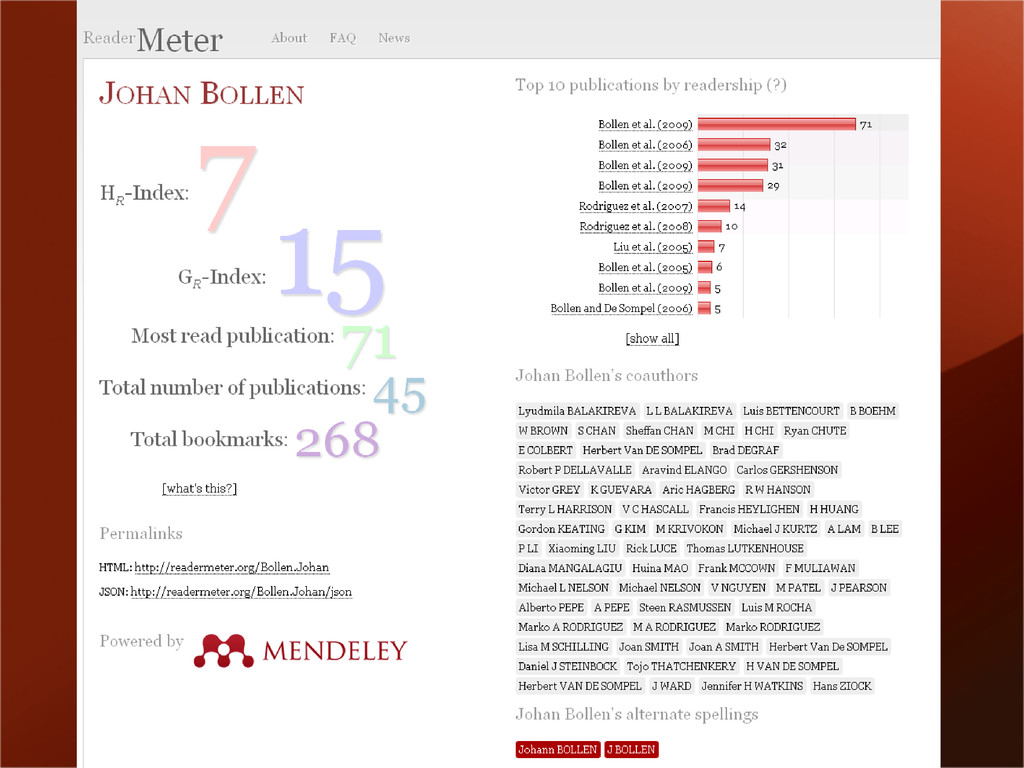
cited. (Eysenbach 2011) http://www.jmir.org/2011/4/e123/ The higher the impact factor, the more likely the research is to be retracted, partly due to intense competition. http://bjoern.brembs.net/news766.html.11 What matters is who is reading your work!
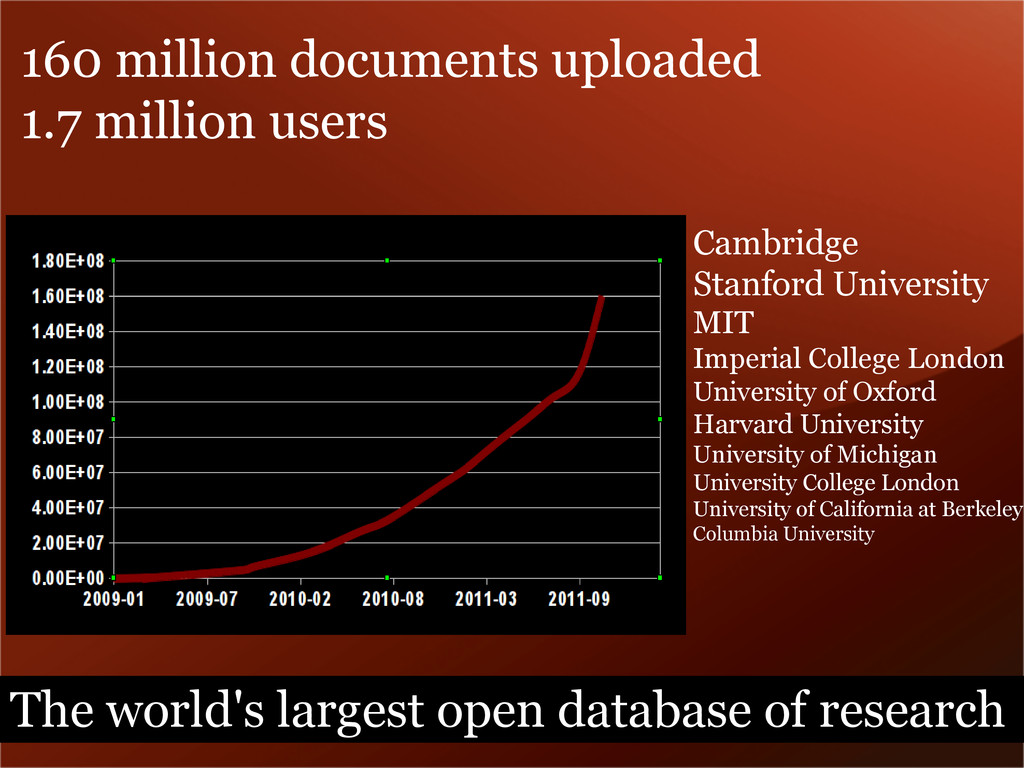
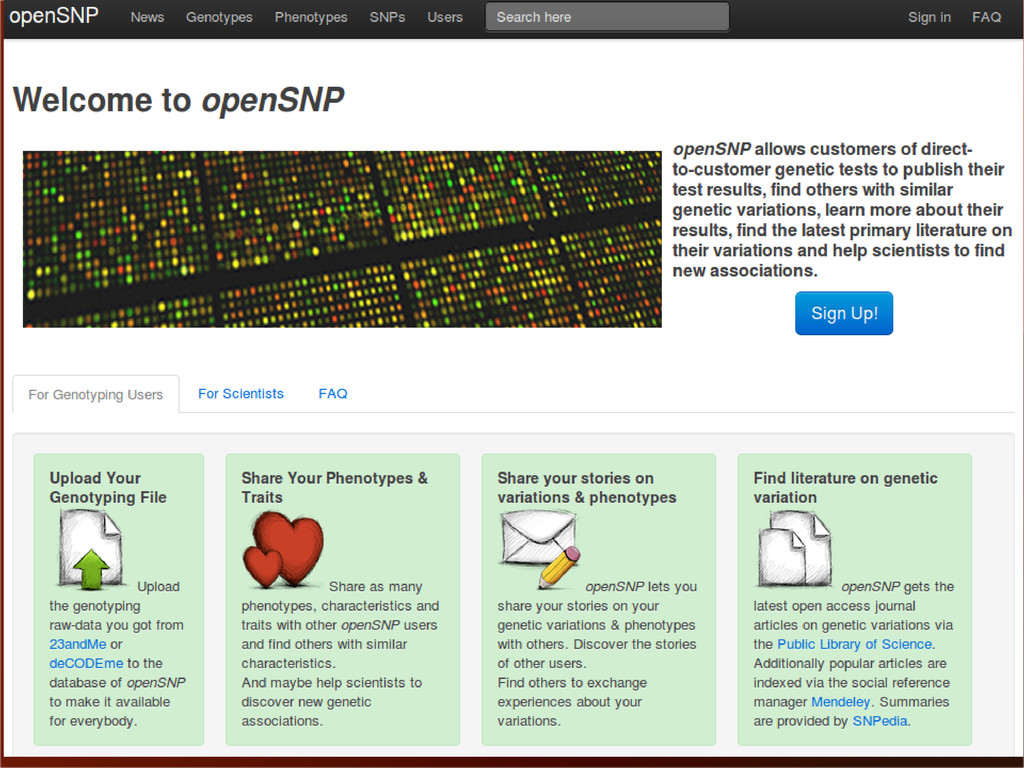
MIT Imperial College London University of Oxford Harvard University University of Michigan University College London University of California at Berkeley Columbia University The world's largest open database of research
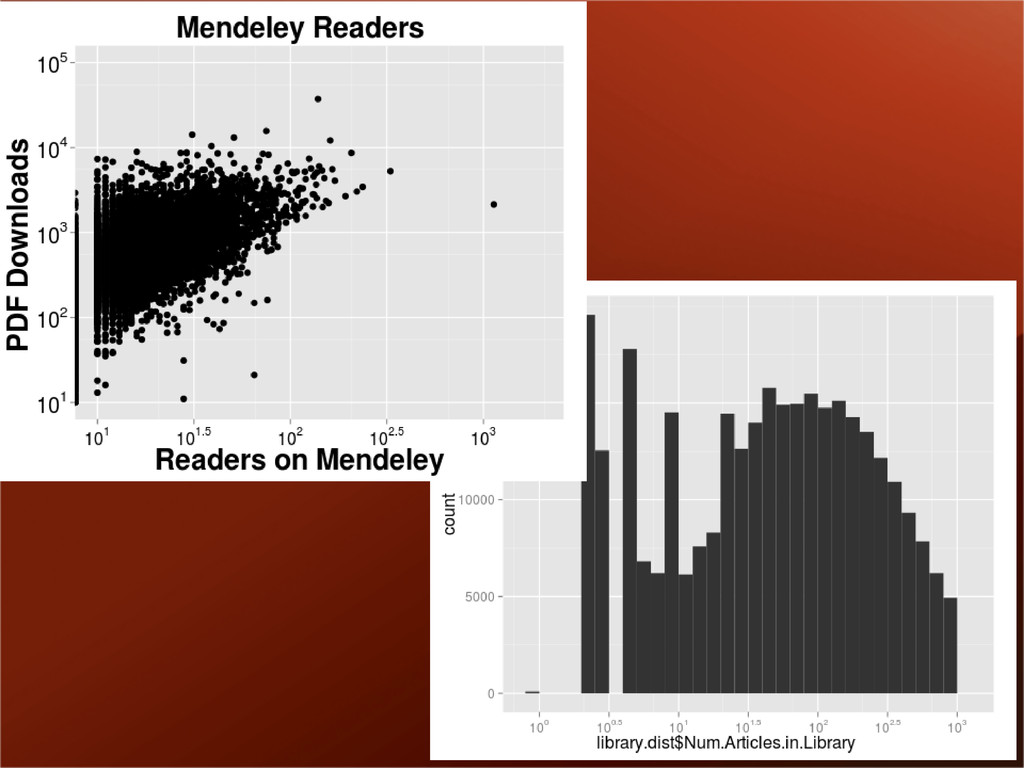
We trained a 2-stage SVM to achieve precision at .91 and recall at .94, beating all other approaches. Deduplication – To build the web catalog, we've got to cluster and de-duplicate 17TB+ of documents daily. Author name disambiguation – aka the “big Wang problem”.We tried a variety of approaches settling on a method of hierarchical agglomerative clustering.
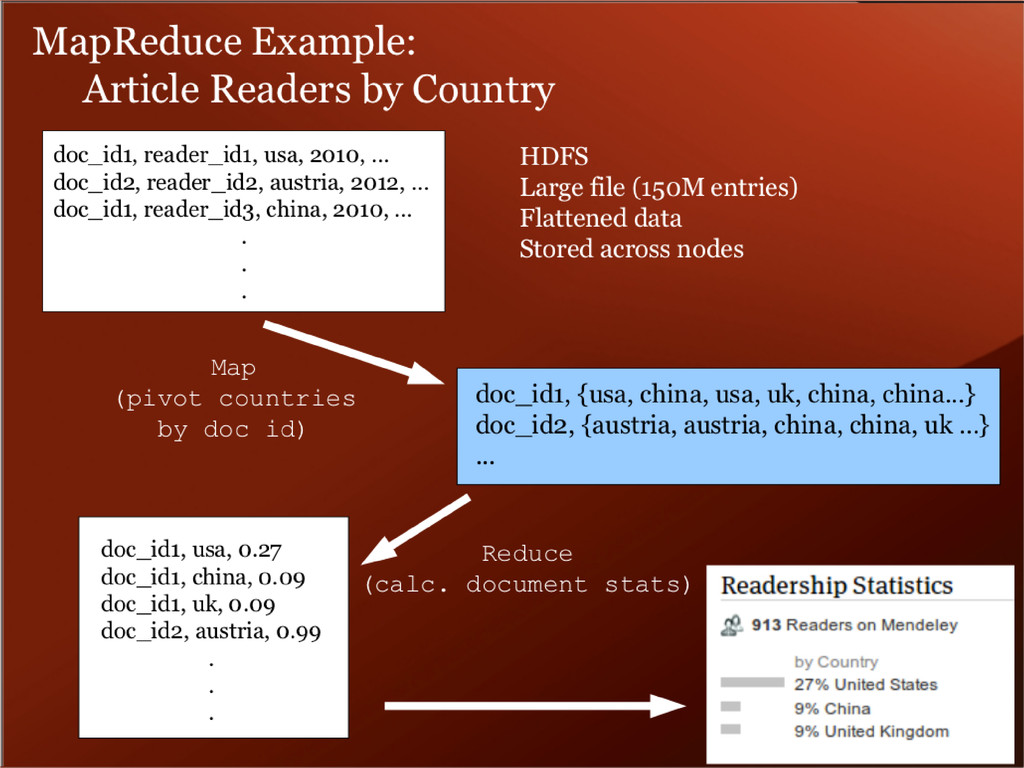
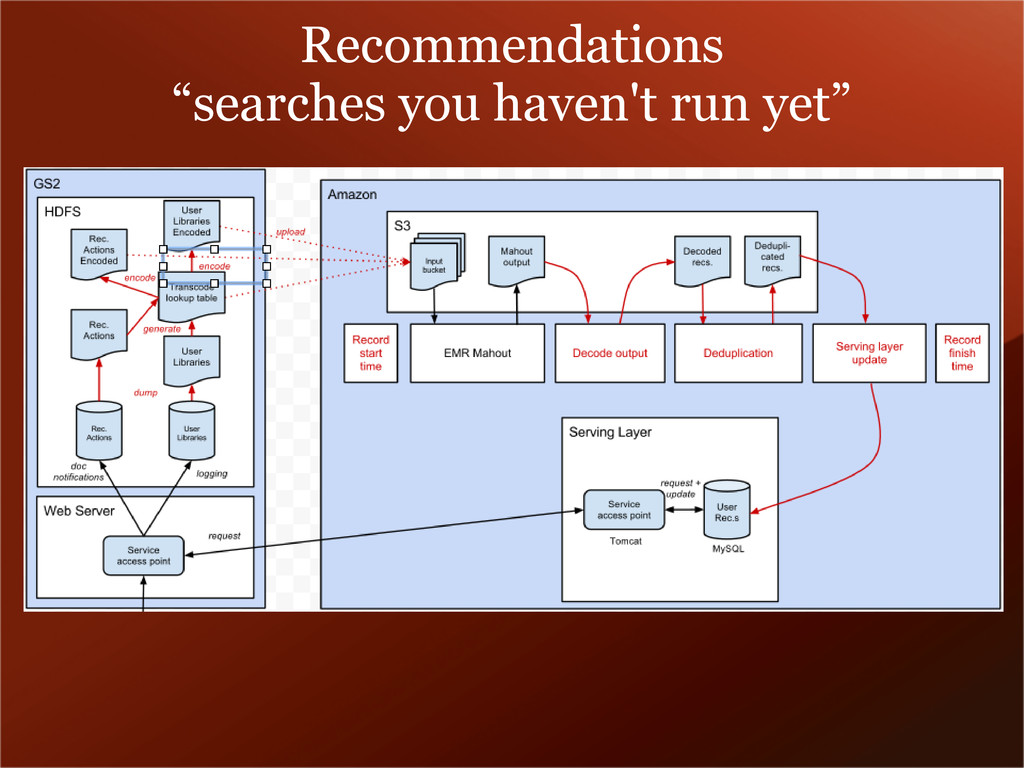
scalable processing as well as data storage, which made HDFS + MapReduce on AWS a pretty obvious choice. Stats Search good user experience enterprise-class search with easy setup vibrant open source community Scale SSDs for catalog search Caching index in RAM
pictures or audio because the descriptors are already text strings OCR doesn't work well Hashing works for trivial modifications, but not for discriminating pre-prints vs. post-prints. You don't necessarily know when you don't have a complete record. File hash check(SHA-1) Identifier check(e.g.PubMed id) Document fingerprint(fulltext) Metadata similarity check Update individual article page
Juan Enriquez MD Excel Venture Management John Wilbanks VP Science, Creative Commons Werner Vogels CTO Amazon.com Mendeley/PLoS API Binary Battle $16,001 for the best app
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}