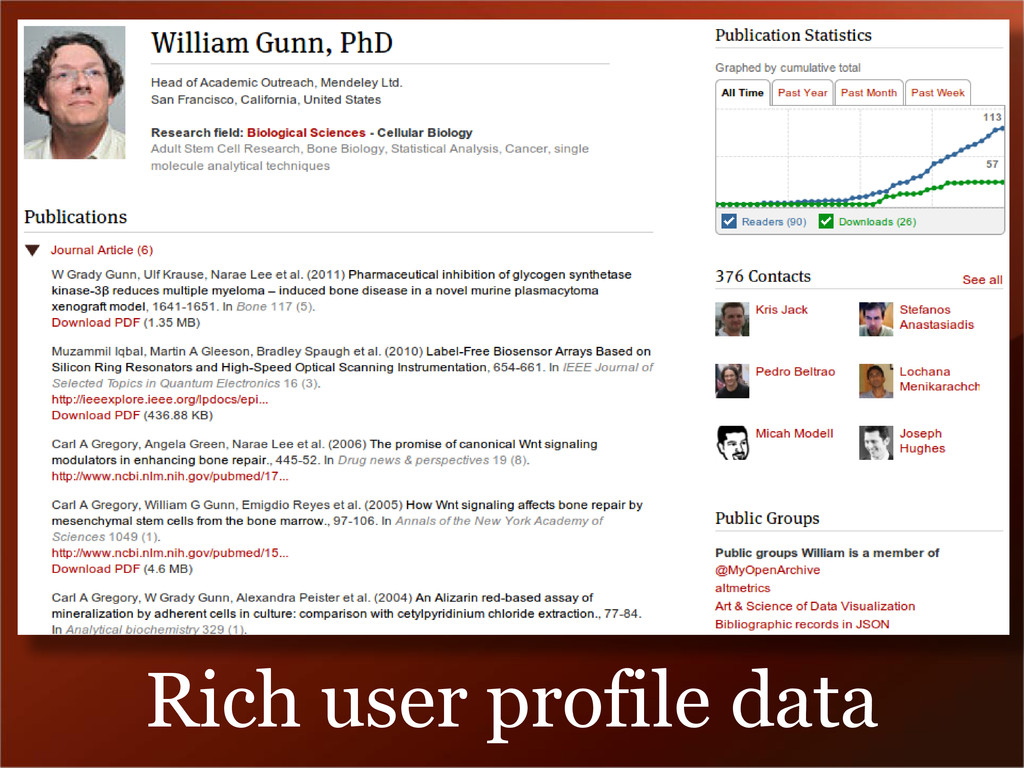
active in online science communities since 1995 Established the community program at Mendeley – 1700 advisors from 650 schools in 60 countries. Lead the outreach to librarian, academic research, and tech communities
the content similarity of academic papers • Performing text disambiguation and entity recognition to differentiate between and relate similar in-text entities and authors of research papers. • Developing semantic technologies and semantic web languages with the focus of metadata integration/validation • Investigate profiling and user analysis technologies, e.g. based on search logs and document interaction. • We will also improve folksonomies and through that, ontologies of text. • Finally, tagging behaviour will be analysed to improve tag recommendations and strategies. • http://team-project.tugraz.at/blog/
to add to LOD repositories and light-weight ontologies. • Crowd-sourcing enabled semantic enrichment & integration techniques for integrating facts contained in unstructured information into the LOD cloud • Federated, provenance-enabled querying methods for fact discovery in LOD repositories • Web-based visual analysis interfaces to support human based analysis, integration and organisation of facts • Socio-economic factors – roles, revenue-models and value chains – realisable in the envisioned ecosystem. • http://code-research.eu/
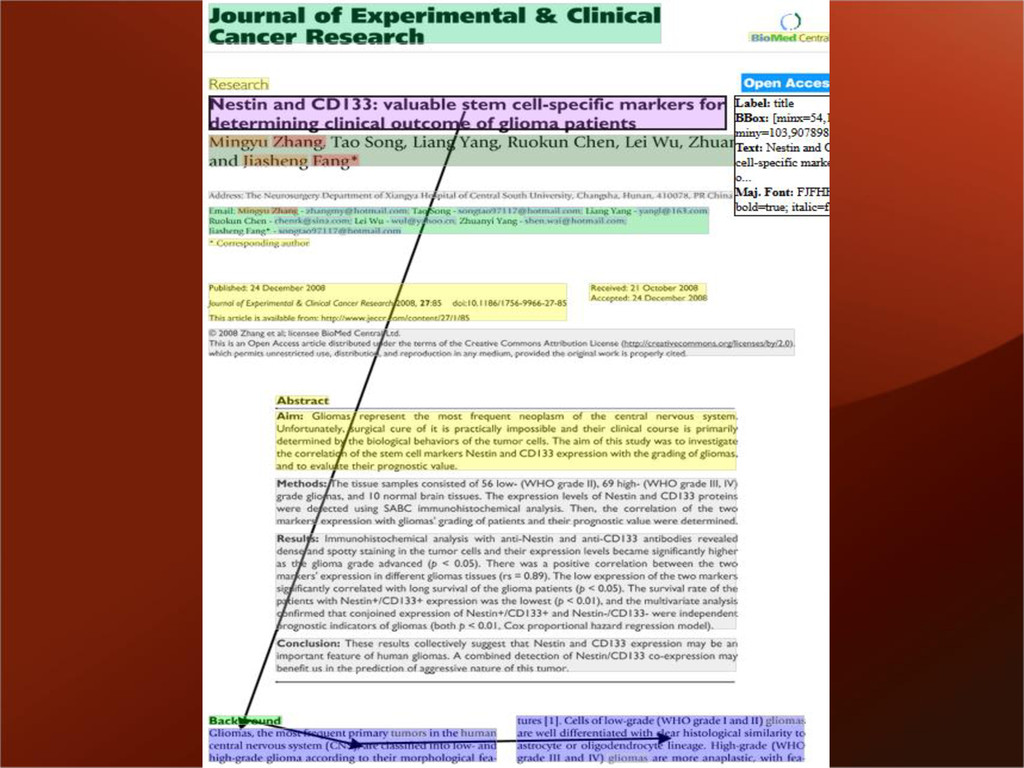
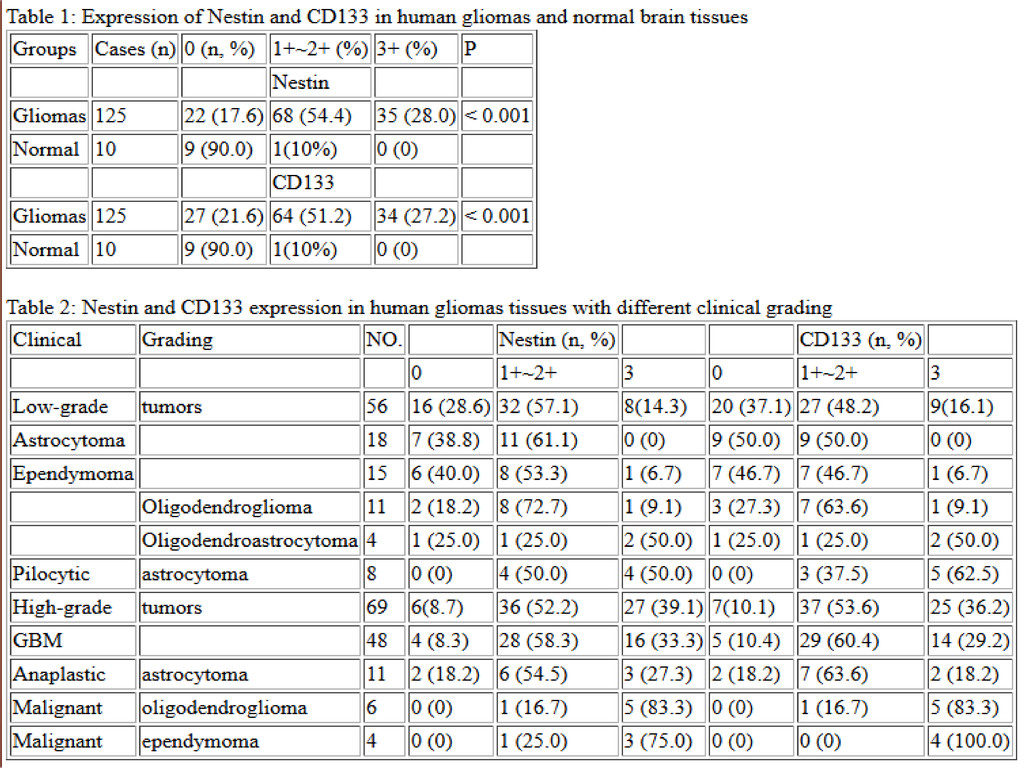
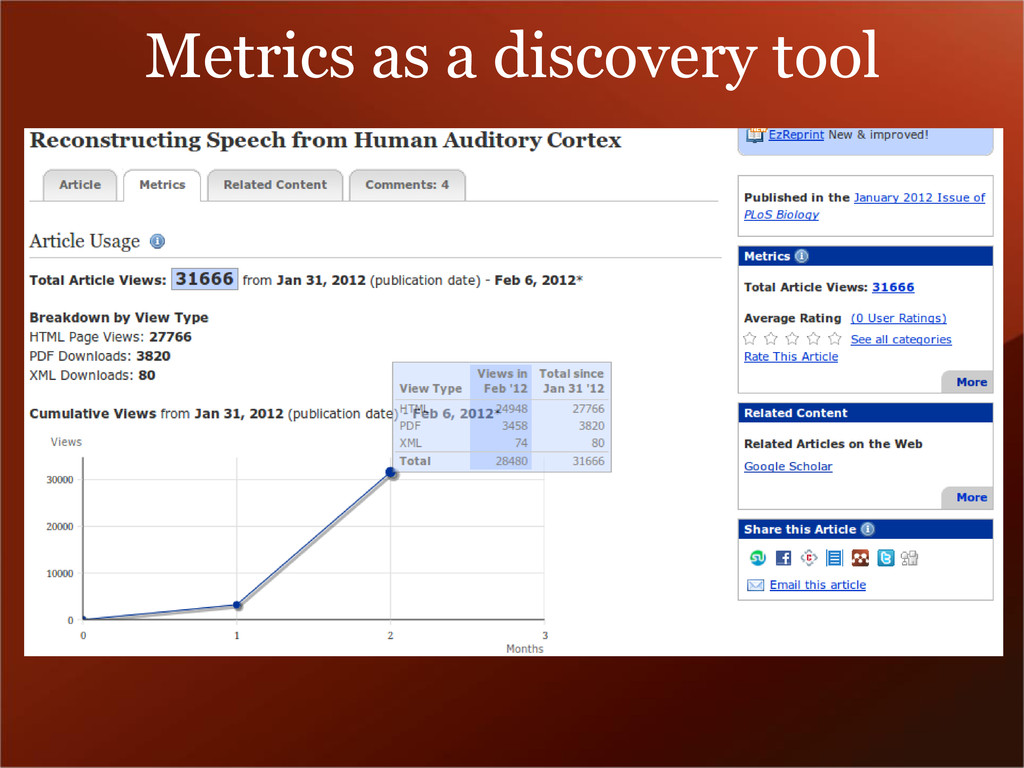
started the Reproducibility Initiative • working with Figshare & PLOS to host data & replication reports • building open datasets backing high- impact work • extending the “executable paper” concept to biomedical research
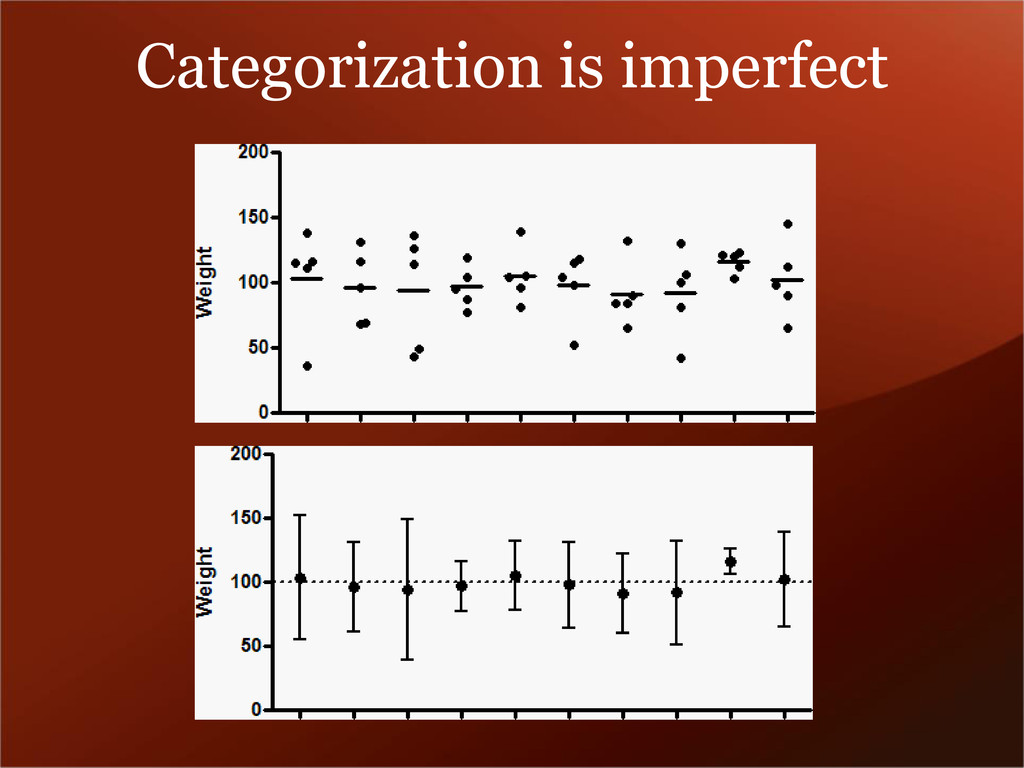
these examples show that the main motivation for people to get data (pictures, bookmarks, etc) off their computers and on the web is because it helps them find more of the same. Communities must be open if they are to thrive.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.mendeley.com [email protected] @mrgunn](https://files.speakerdeck.com/presentations/d0dcf630e8df013004a94ee73f409c14/slide_25.jpg){kind=link}