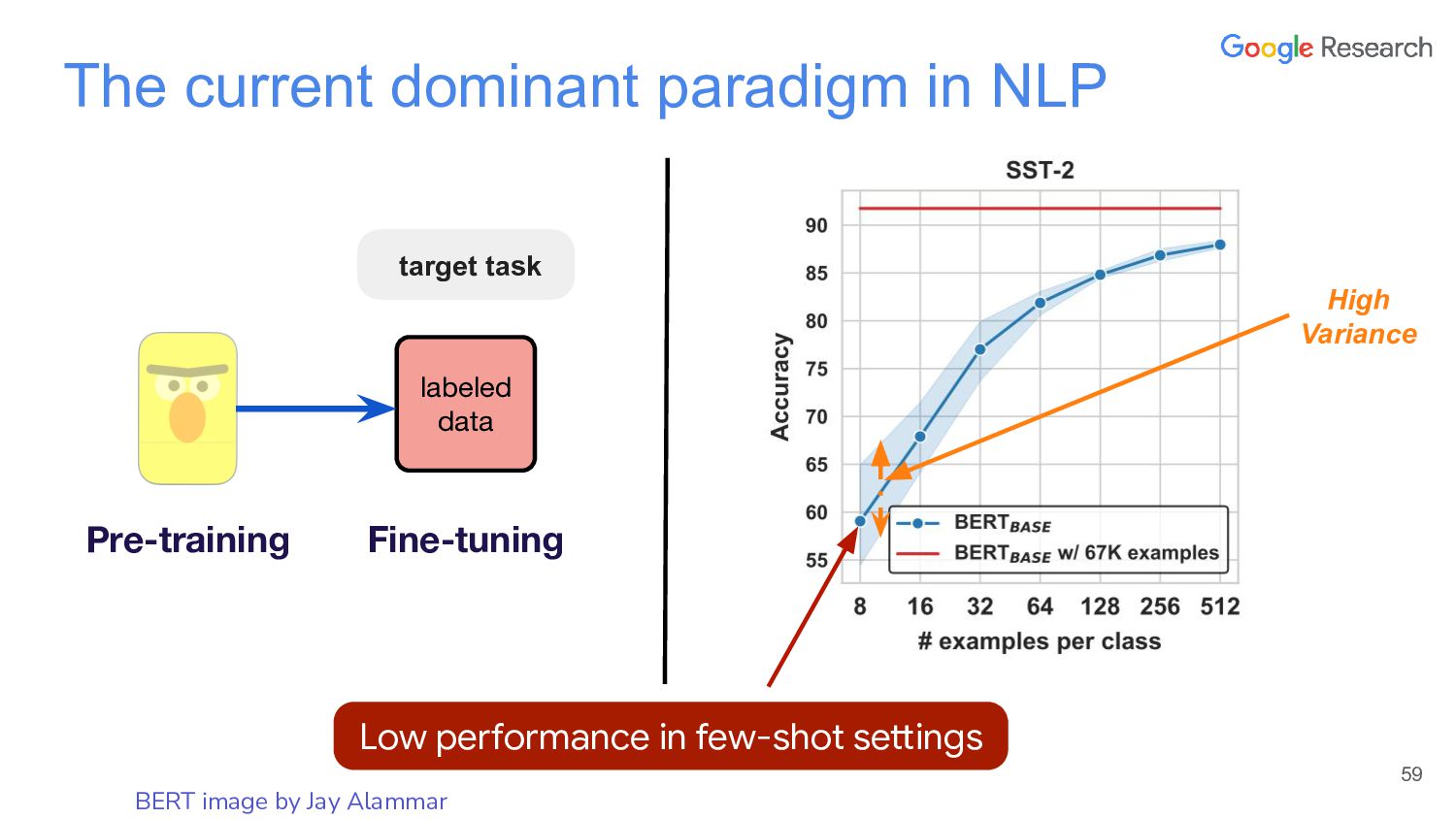
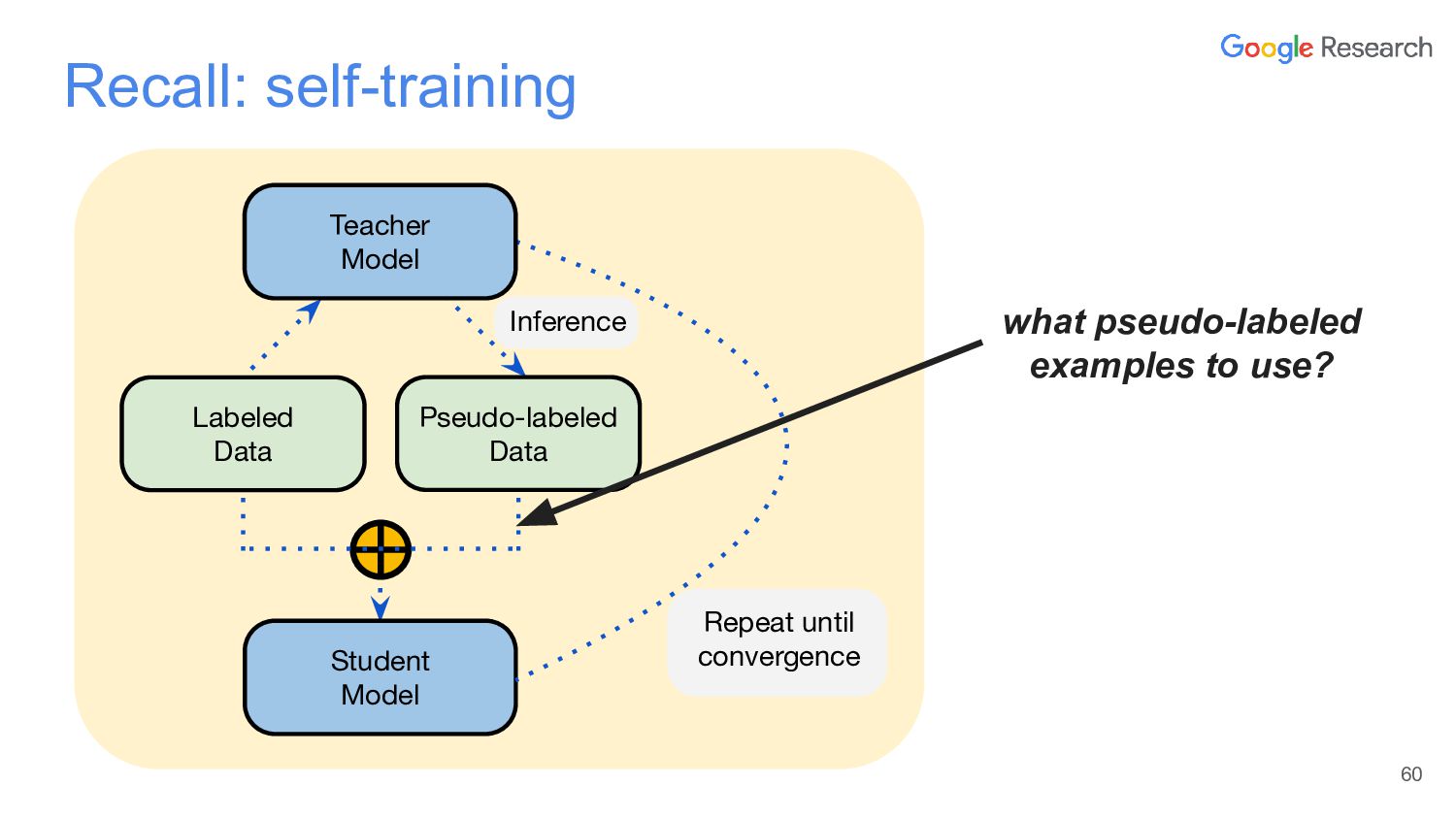
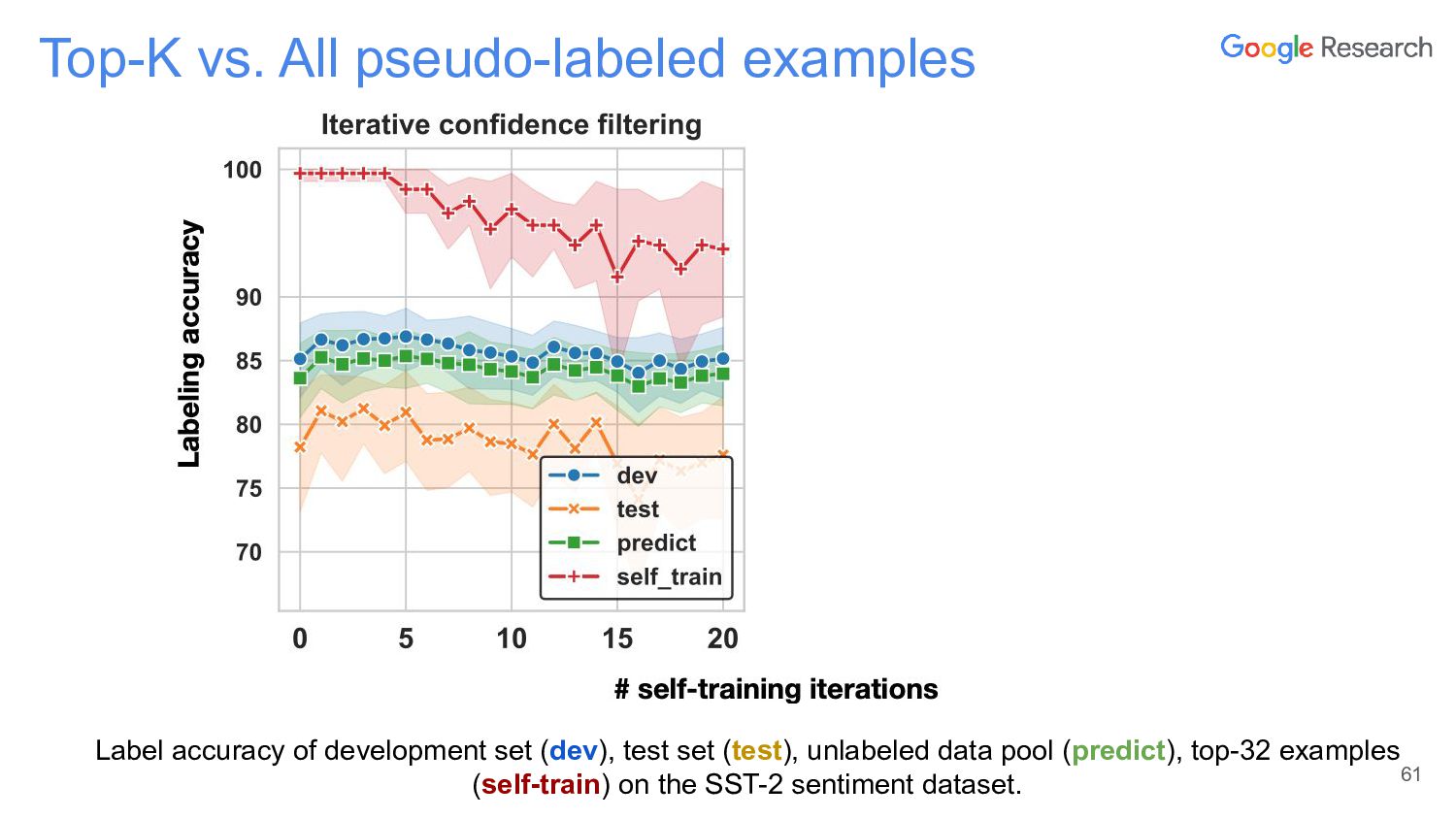
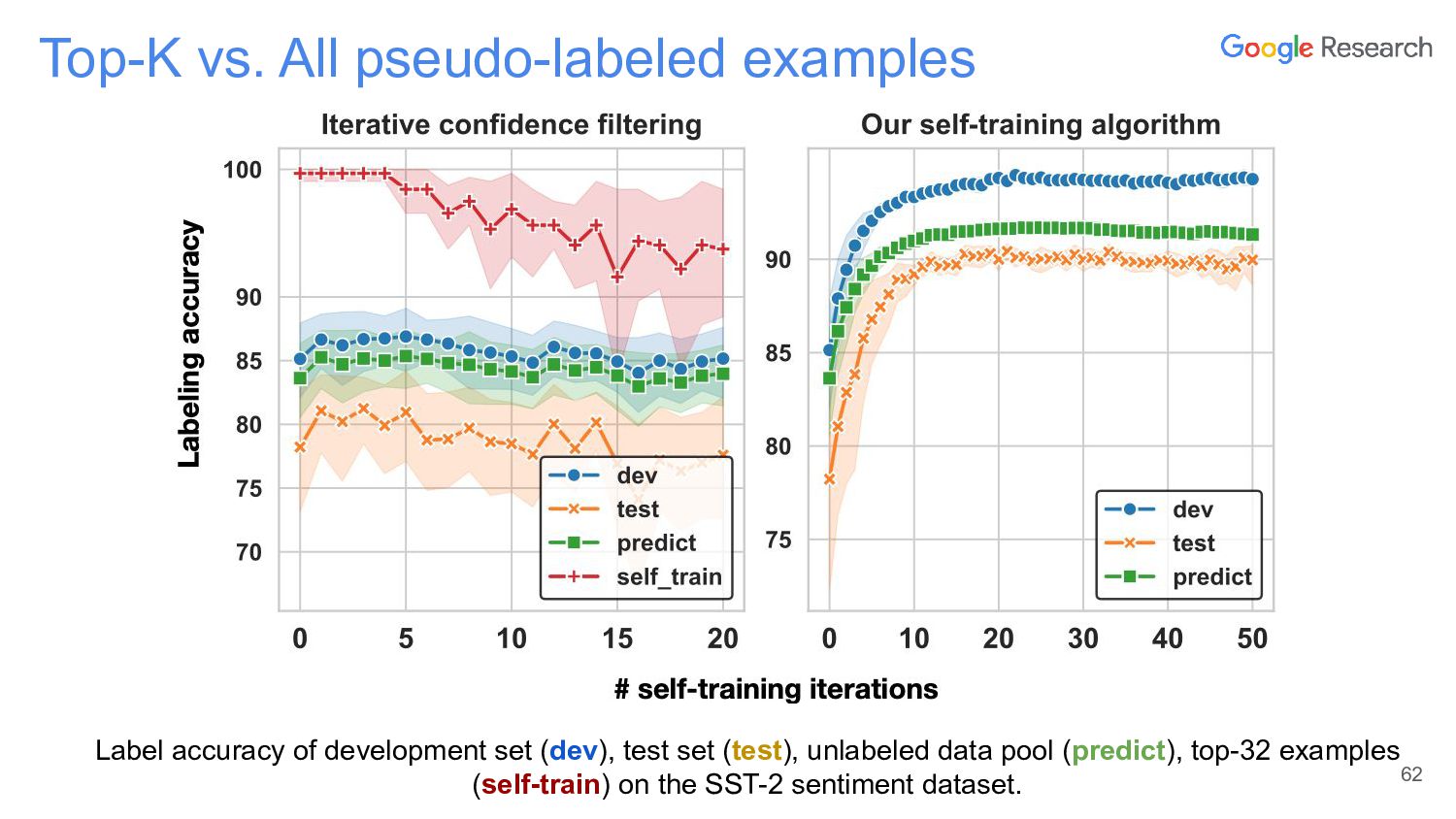
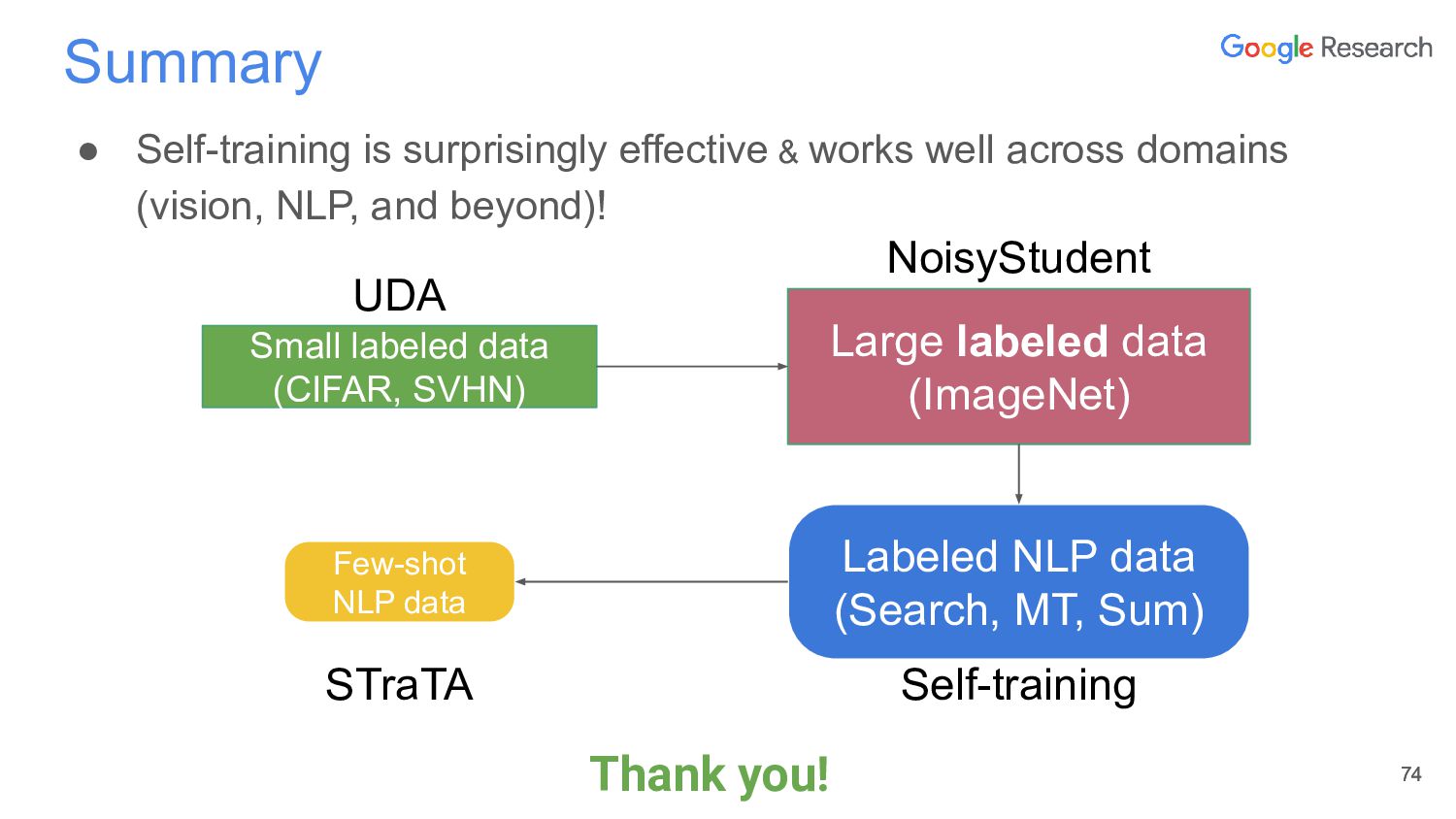
In this talk, I will discuss the story of a classic semi-supervised learning approach, self-training, which has been quite successful lately. The talk starts first with NoisyStudent, a simple self-training method that has advanced state-of-the-art results on vision at the time and yielded surprising improvements on robustness benchmarks. I’ll then transition to NLP to talk about STraTA, an approach that combines self-training and task augmentation to achieve strong results in few-shot NLP settings, where only a handful of training examples are available.
Bio:
Thang Luong is currently a Staff Research Scientist at Google Brain. He obtained his PhD in Computer Science from Stanford University where he pioneered the development of neural machine translation at both Google and Stanford. Dr. Luong has served as area chairs at ACL and NeuRIPS and is an author of many scientific articles and patents with over 18K citations. He is a co-founder of the Meena Project, now Google LaMDA chatbot, and VietAI, a non-profit organization that builds a community of world-class AI experts in Vietnam.
Slides link (hosted by permission of Thang): https://speakerdeck.com/wingnus/the-curious-case-of-self-training-from-vision-to-language-and-beyond
YouTube Video recording: https://youtu.be/WZXvJF995pM
Seminar page: https://wing-nus.github.io/nlp-seminar/speaker-thang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
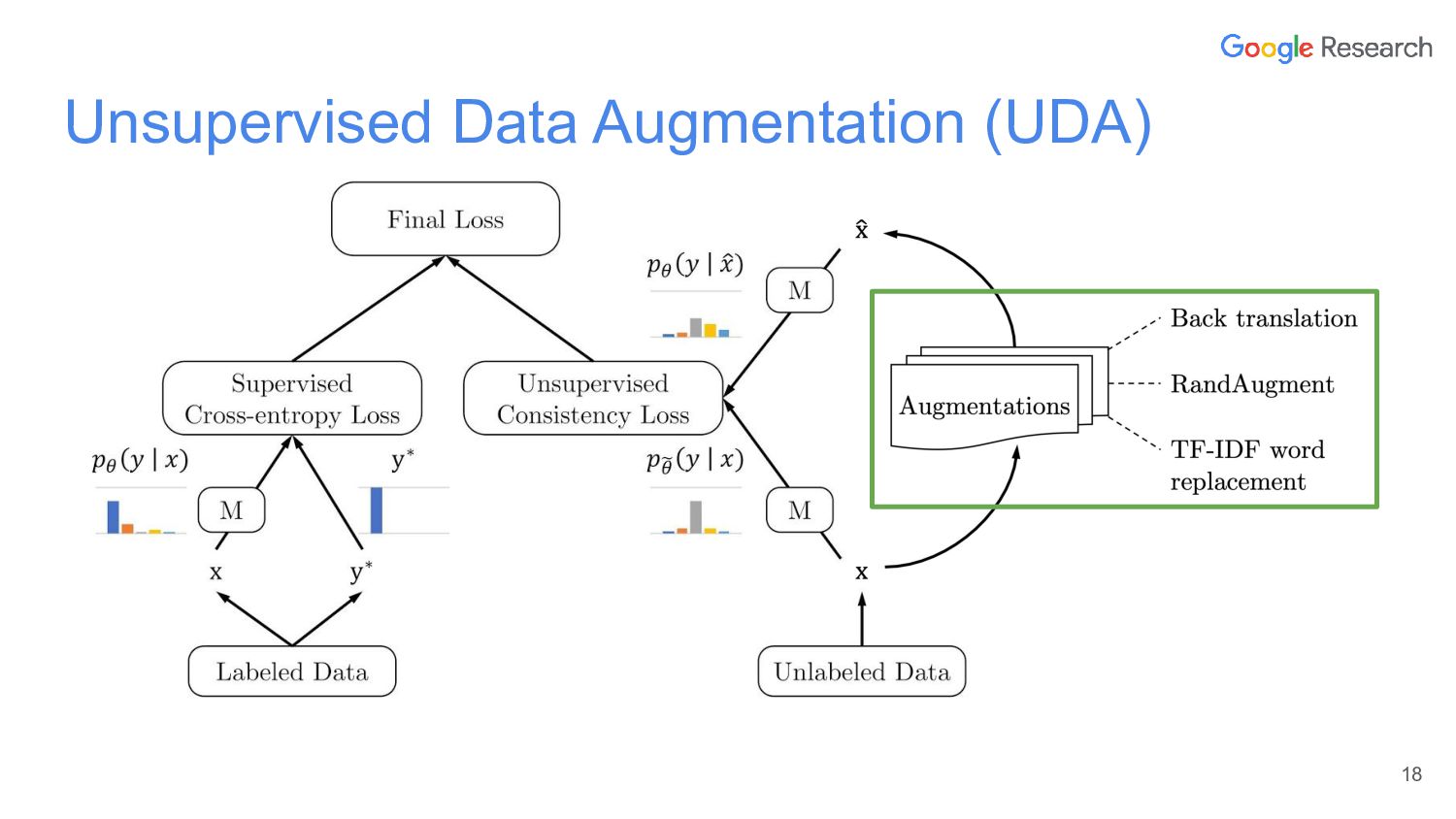{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
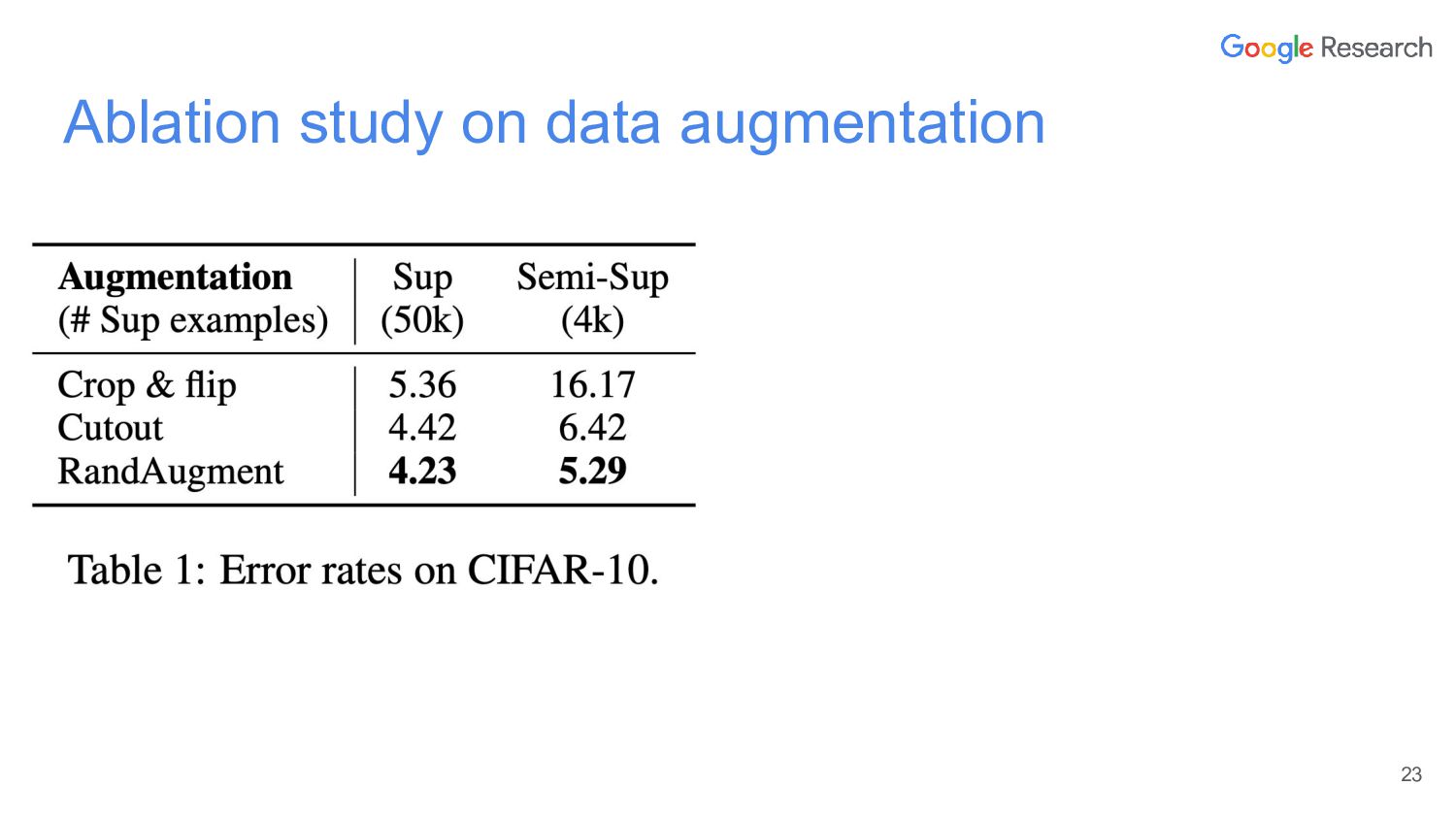{kind=link}
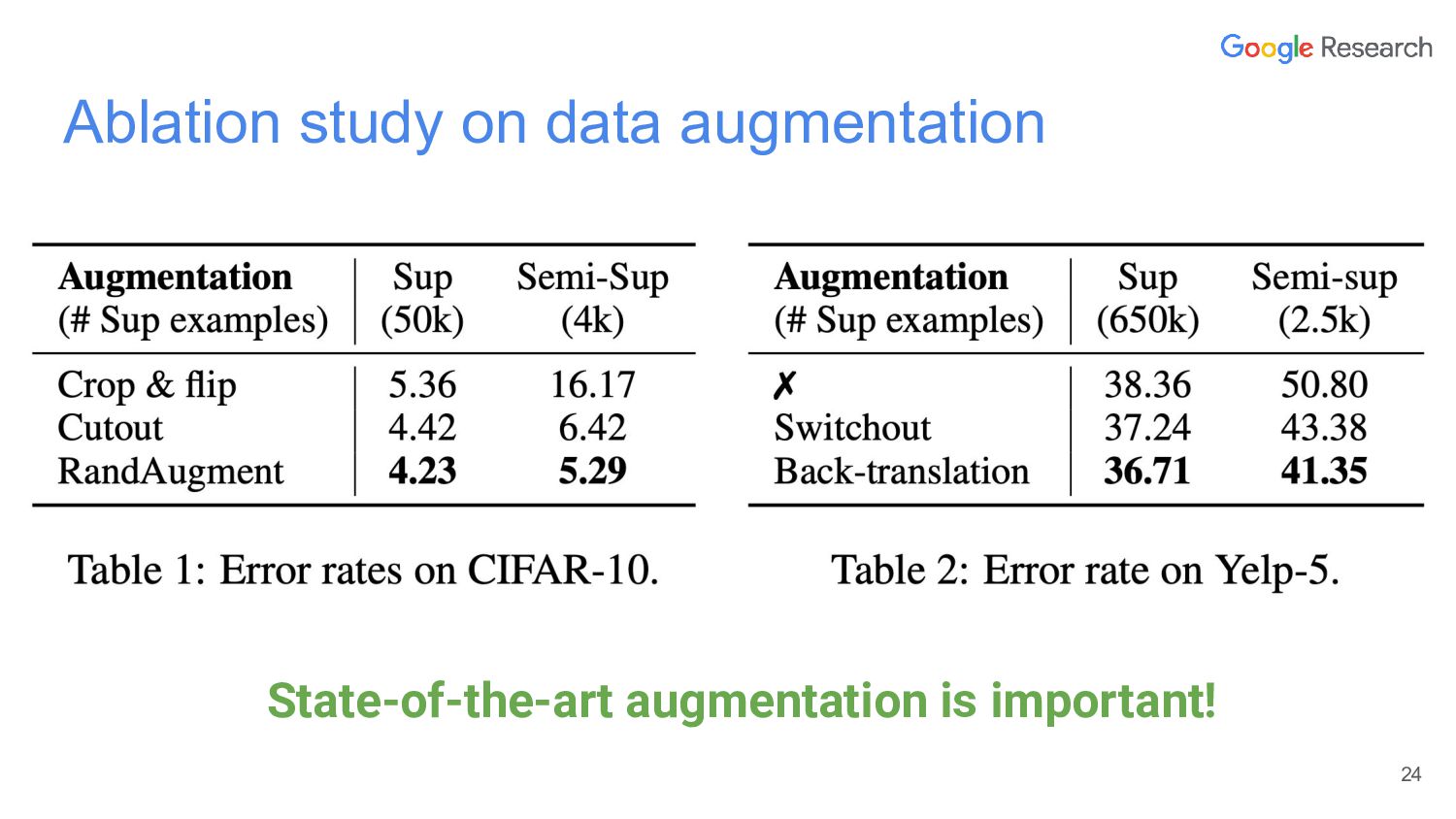{kind=link}
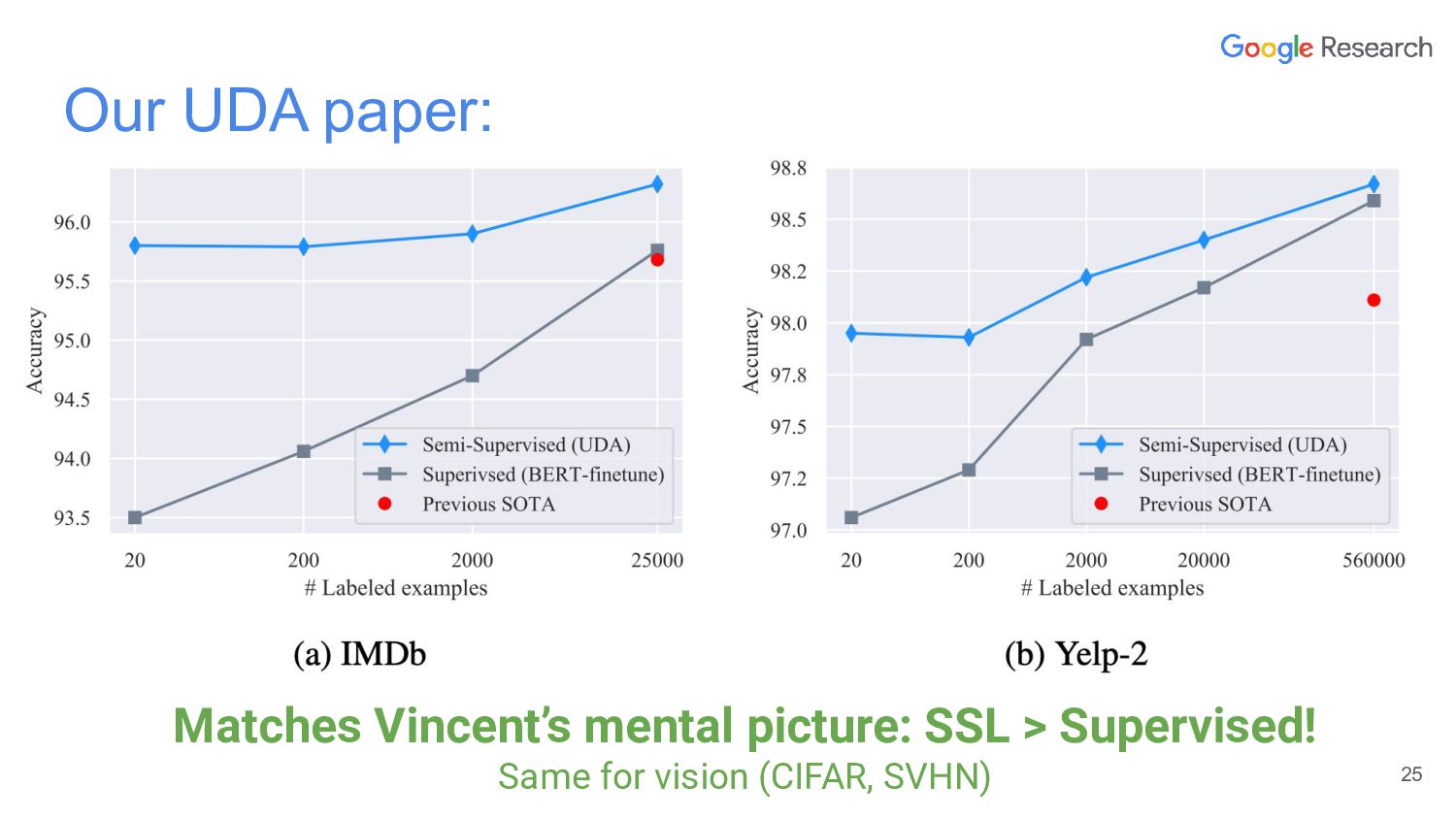{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
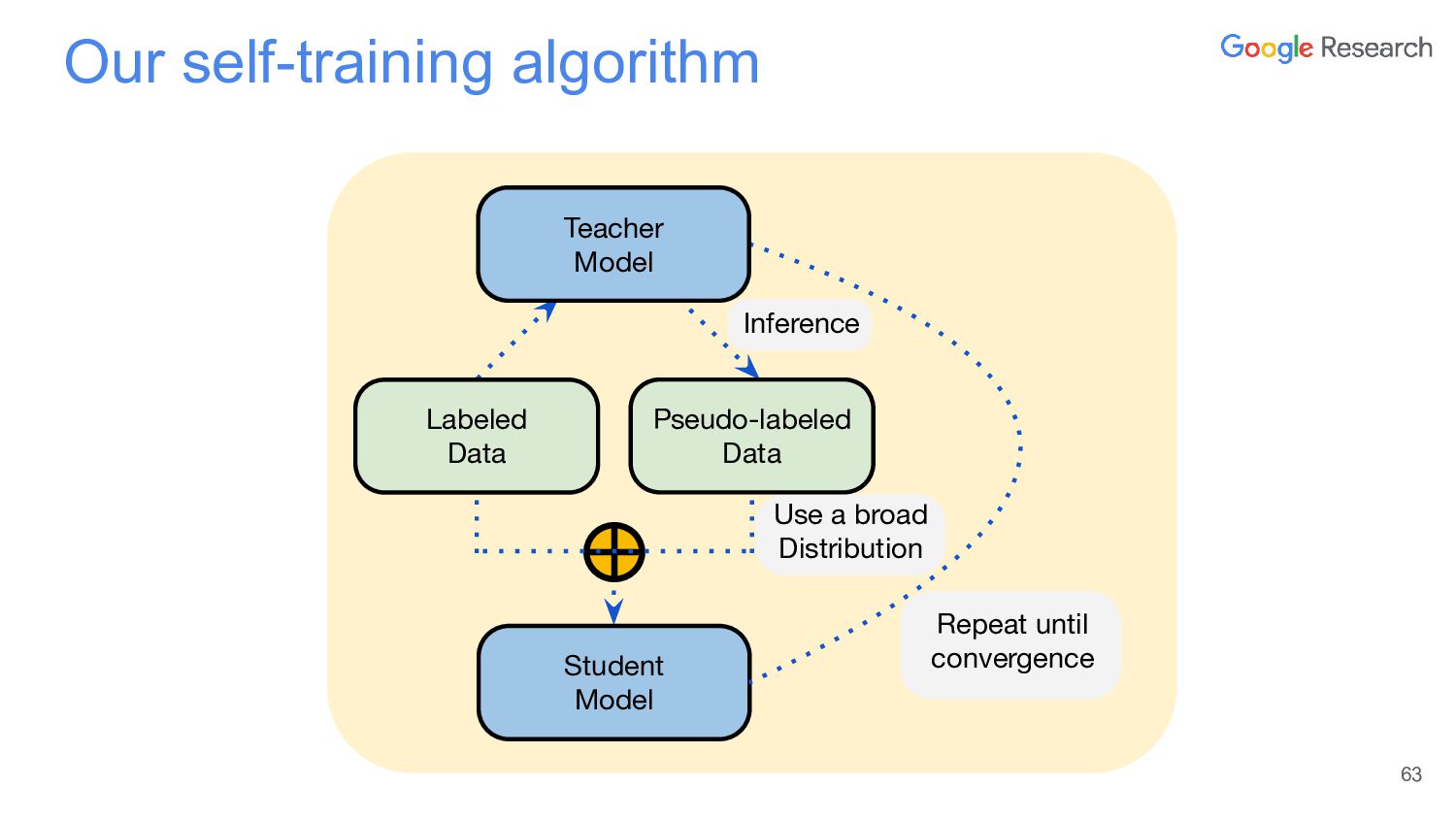{kind=link}
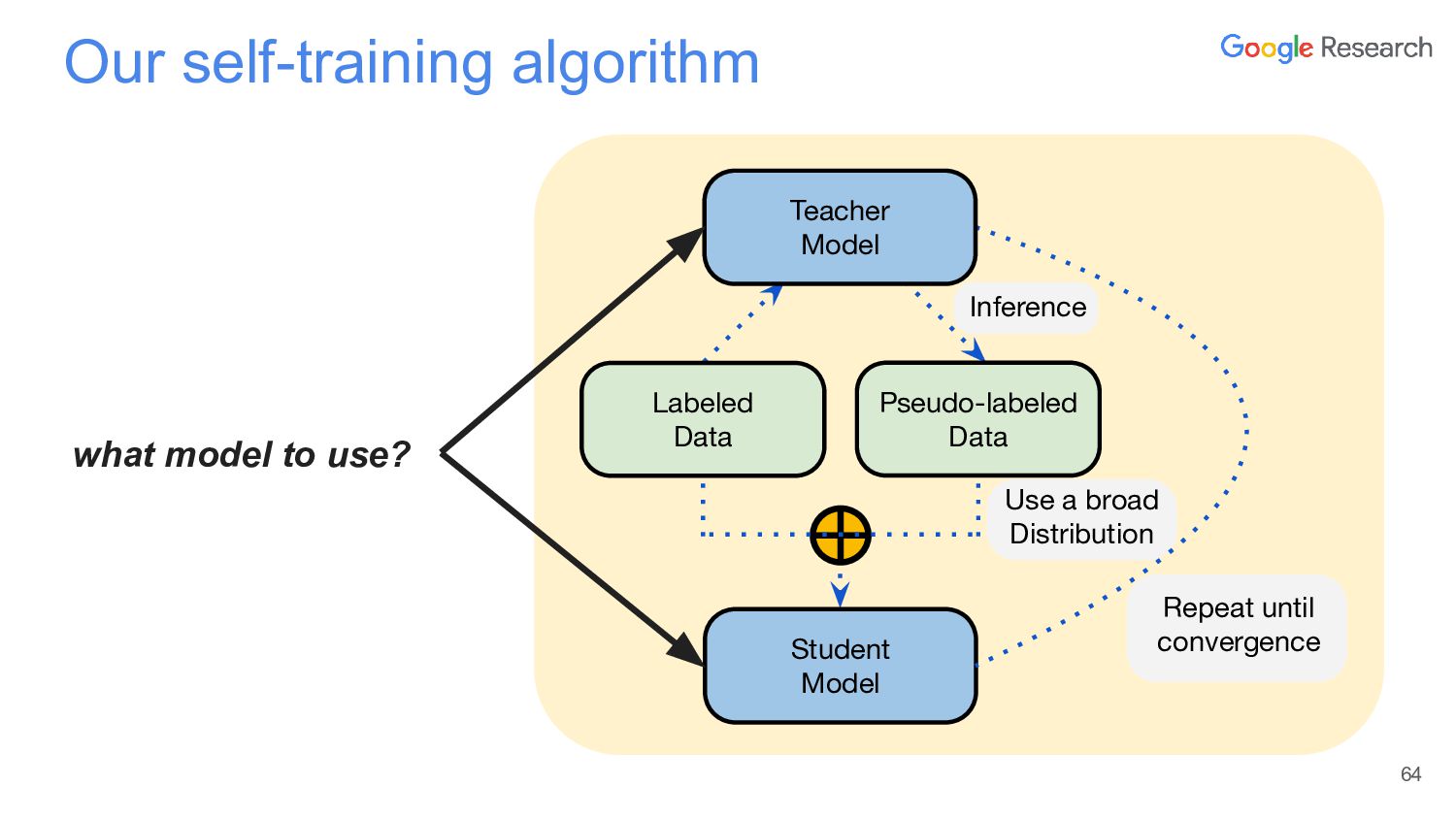{kind=link}
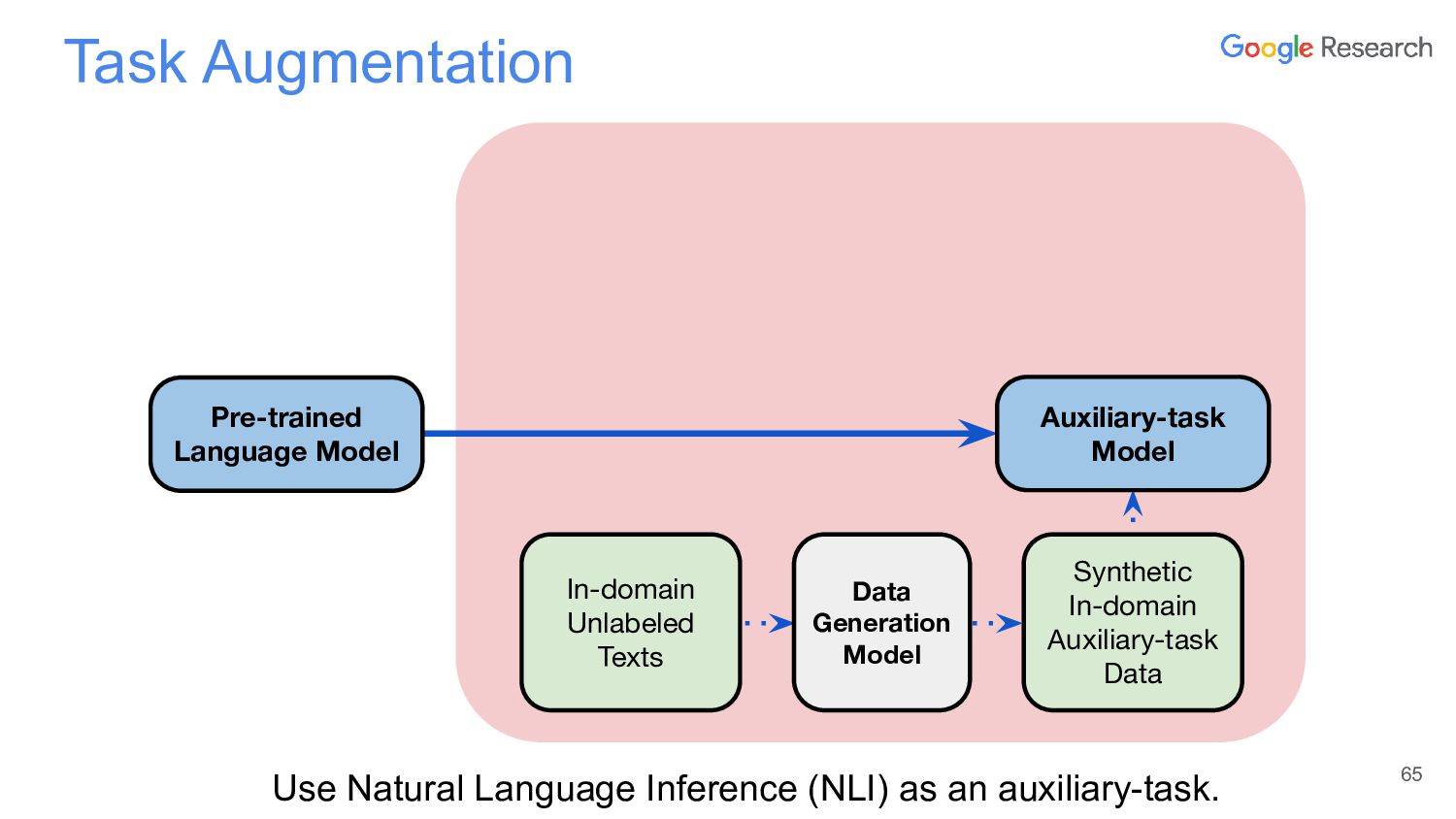{kind=link}
{kind=link}
{kind=link}
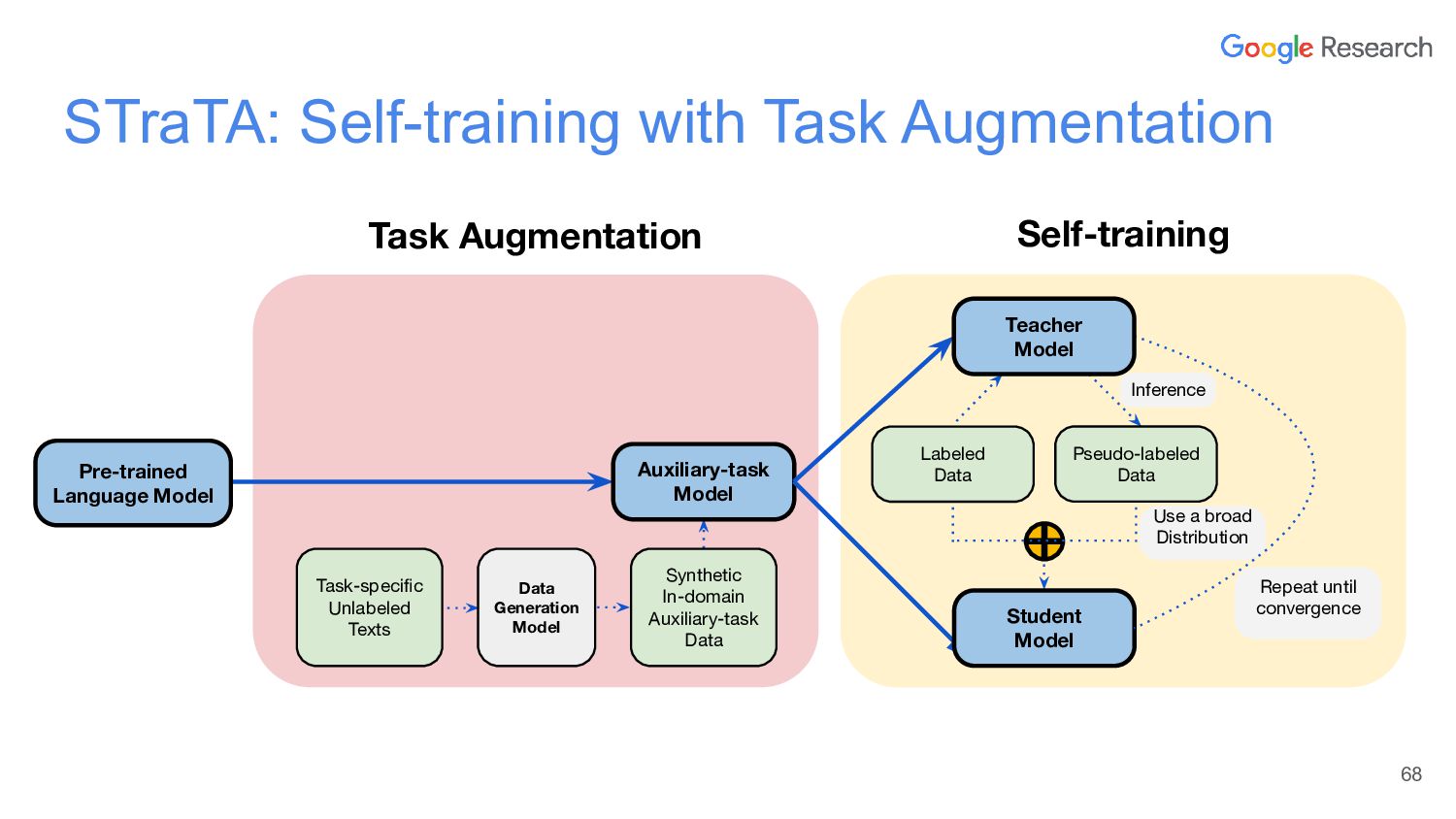{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}