Q k (s',a')] Q-Learning In MDP: In RL (Model-Free): ✤ Receive a sample (s,a,s’,r) ✤ Consider your old estimate: Q(s,a) ✤ Consider your new sample estimate (sample suggest Q-value): ✤ Incorporate the new estimate into a running average: Q(s,a) ← (1−α)Q(s,a)+α ⋅sample sample = Q suggest (s,a) = R(s,a,s')+γ max a' Q(s',a') From CS188x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
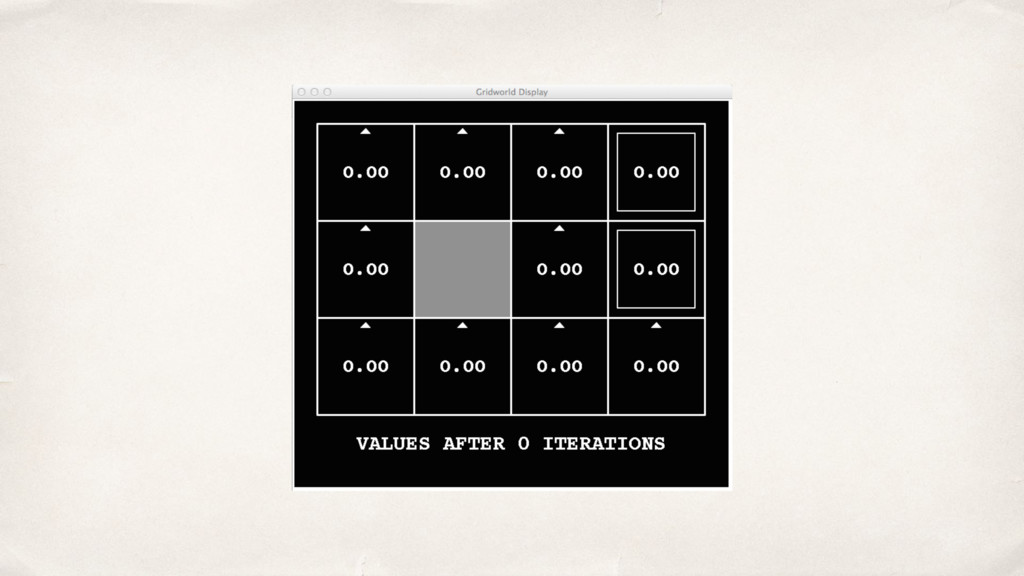{kind=link}
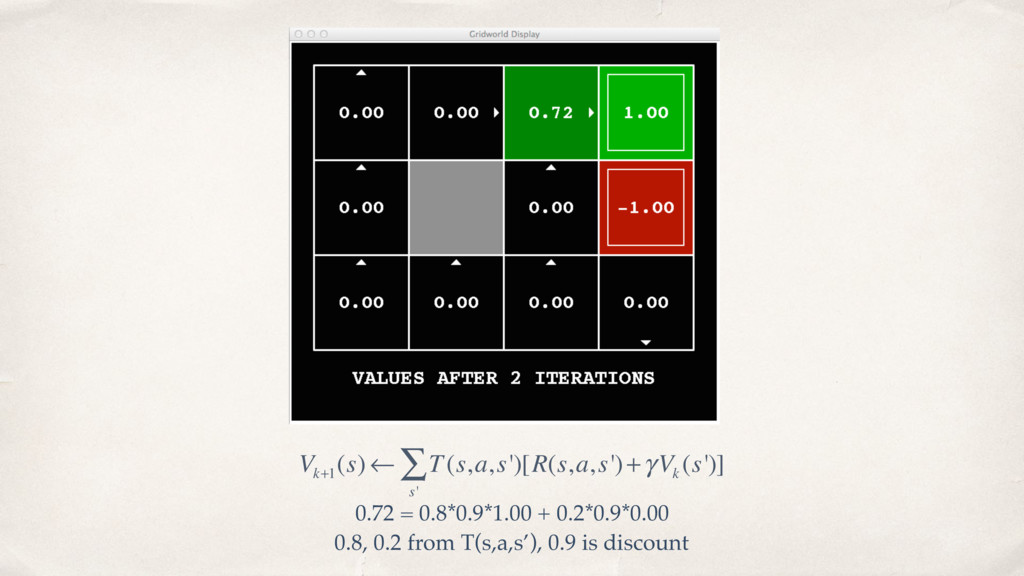{kind=link}
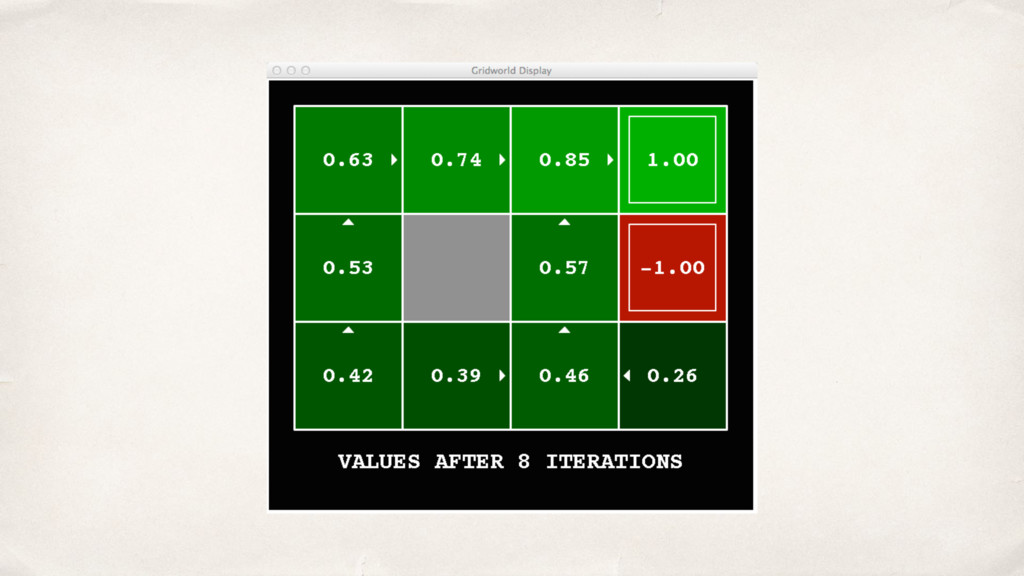
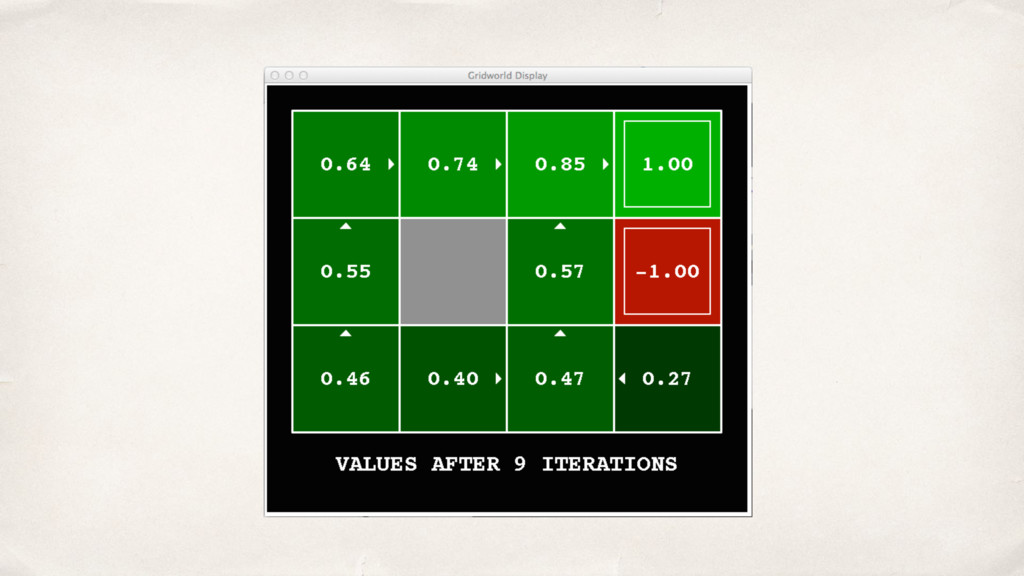
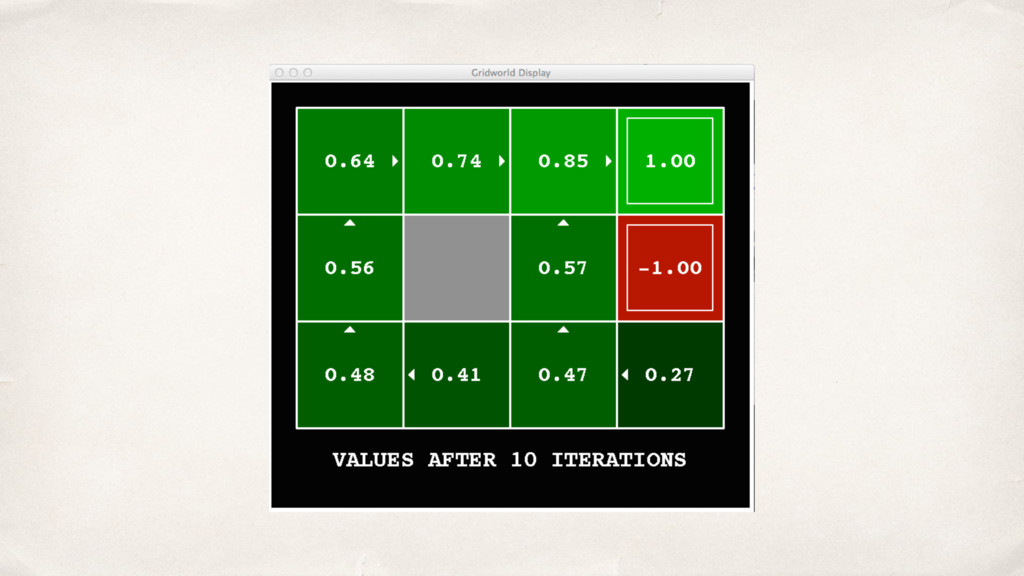
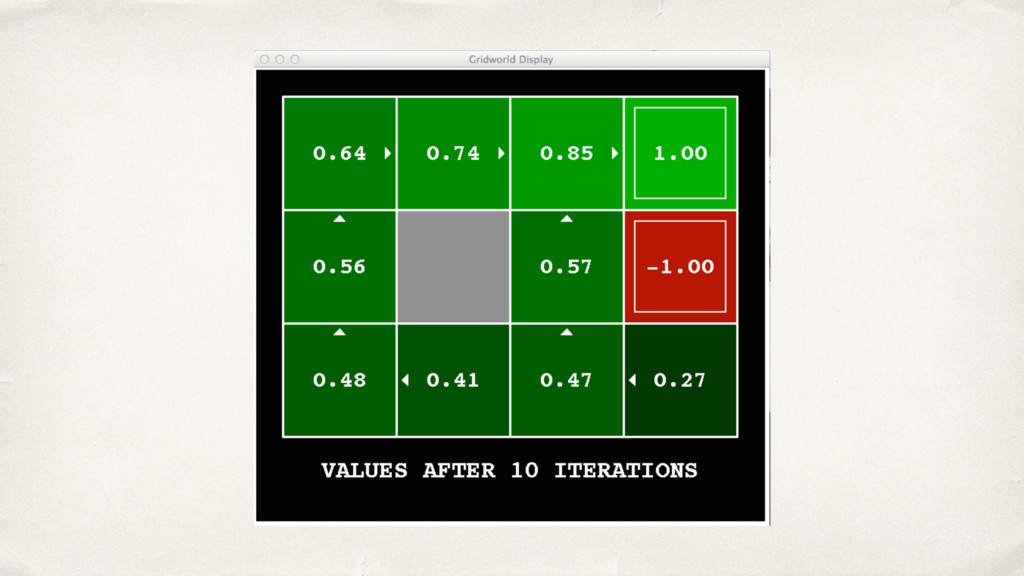
![0.52=0.8*0.9*0.72 + 0.2*0.9*0.00 V k+1 (s) ← T(s,a,s')[R(s,a,s')+γV k (s')]](https://files.speakerdeck.com/presentations/2b0ad1af004f4266b693269e394f35cf/slide_15.jpg){kind=link}
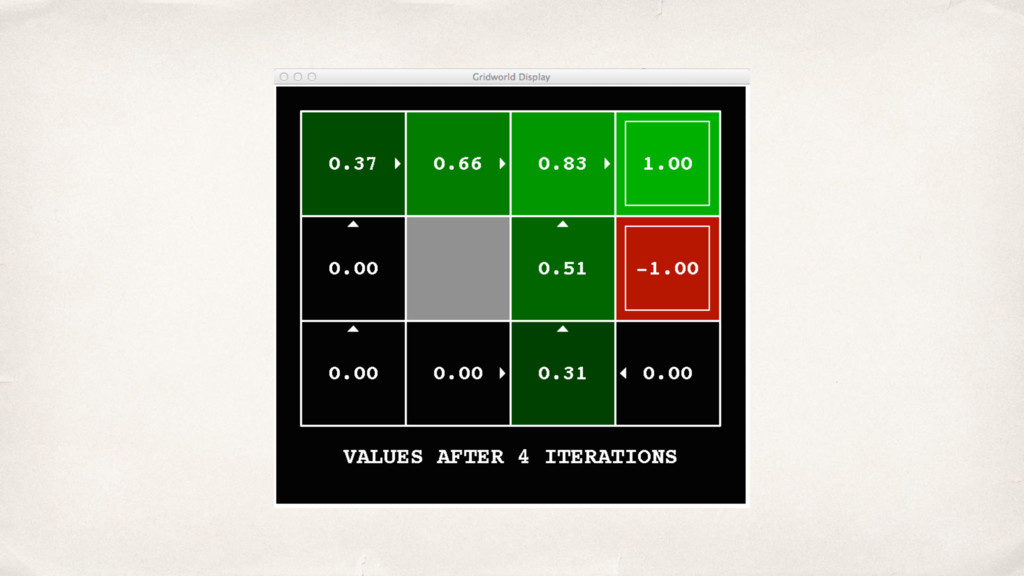{kind=link}
{kind=link}
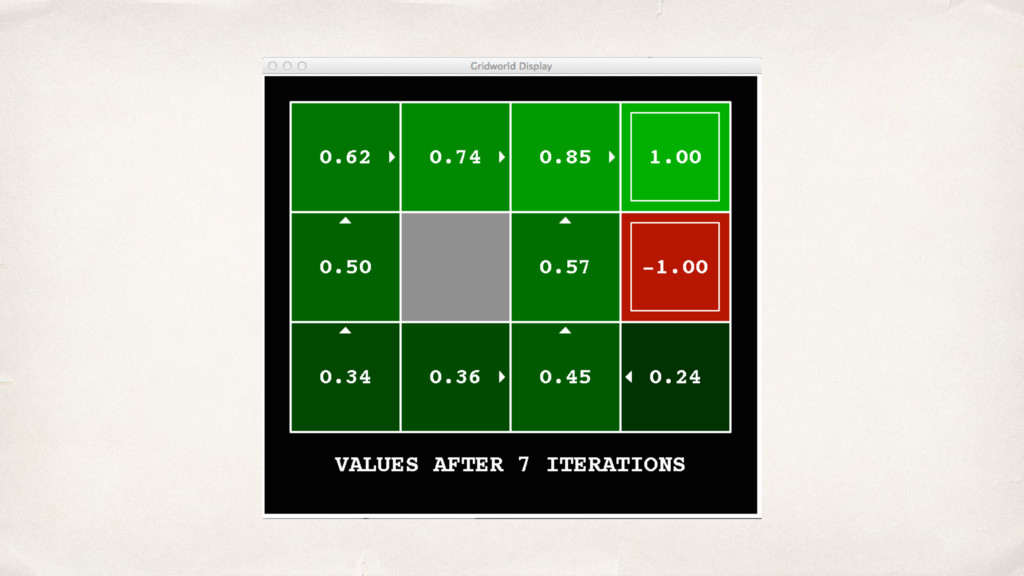{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
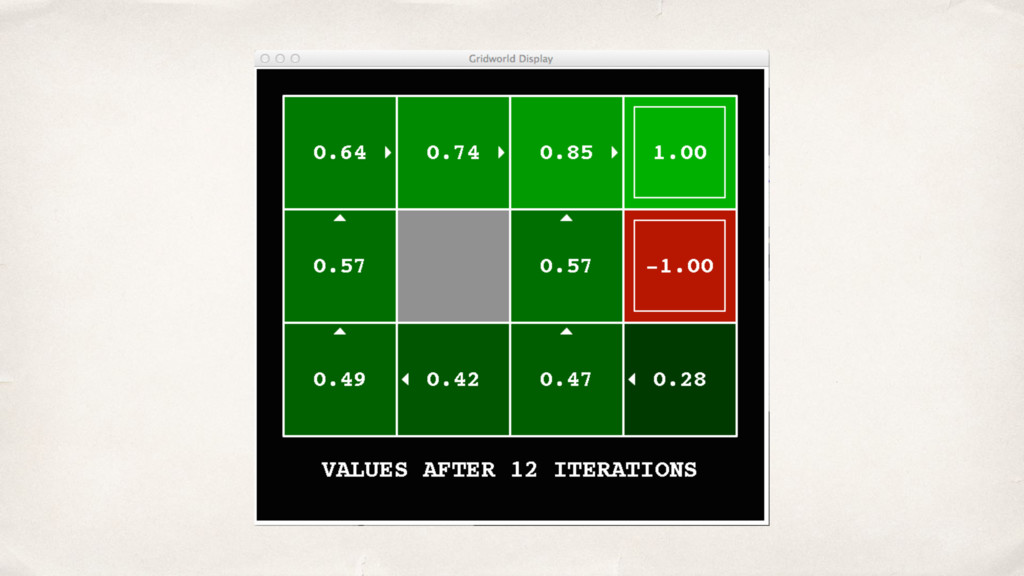{kind=link}
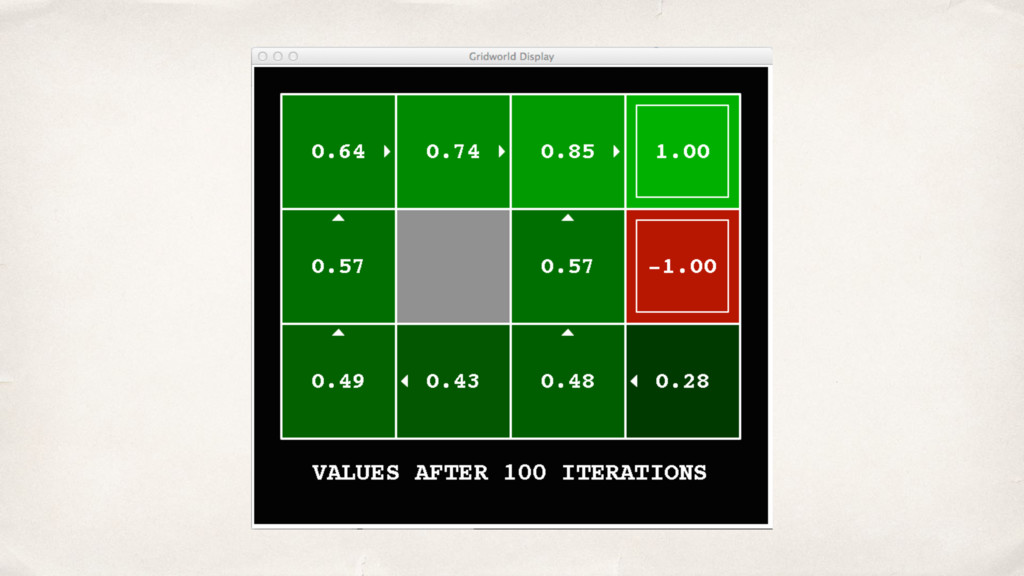{kind=link}
{kind=link}
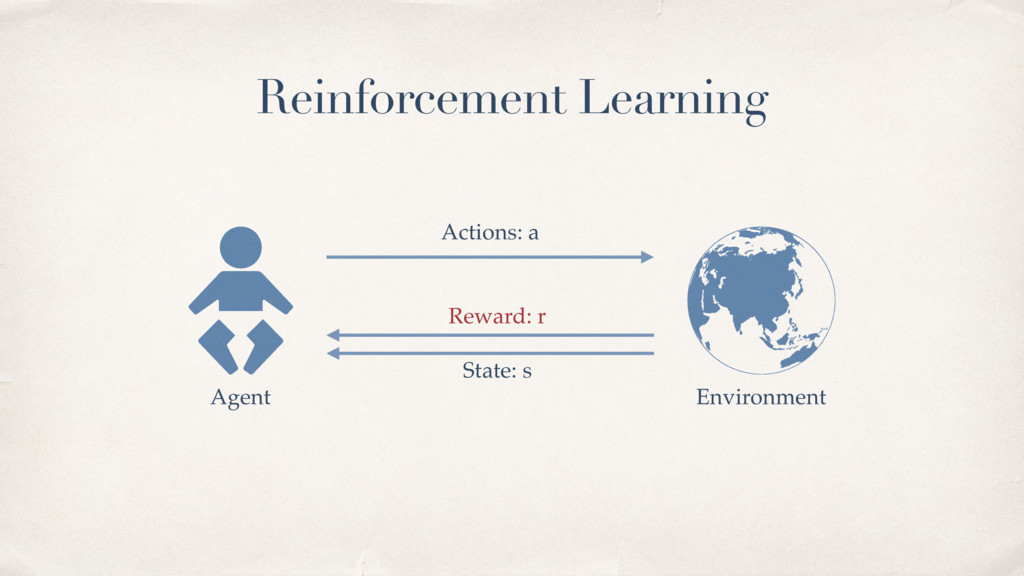{kind=link}
![Example: Learning to Walk Initial [Kohl and Stone, ICRA 2004]](https://files.speakerdeck.com/presentations/2b0ad1af004f4266b693269e394f35cf/slide_27.jpg){kind=link}
![Example: Learning to Walk Training [Kohl and Stone, ICRA 2004]](https://files.speakerdeck.com/presentations/2b0ad1af004f4266b693269e394f35cf/slide_28.jpg){kind=link}
![Example: Learning to Walk Finished [Kohl and Stone, ICRA 2004]](https://files.speakerdeck.com/presentations/2b0ad1af004f4266b693269e394f35cf/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example: Expected Age Known P(A) E[A] = P(a)⋅a a ∑](https://files.speakerdeck.com/presentations/2b0ad1af004f4266b693269e394f35cf/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
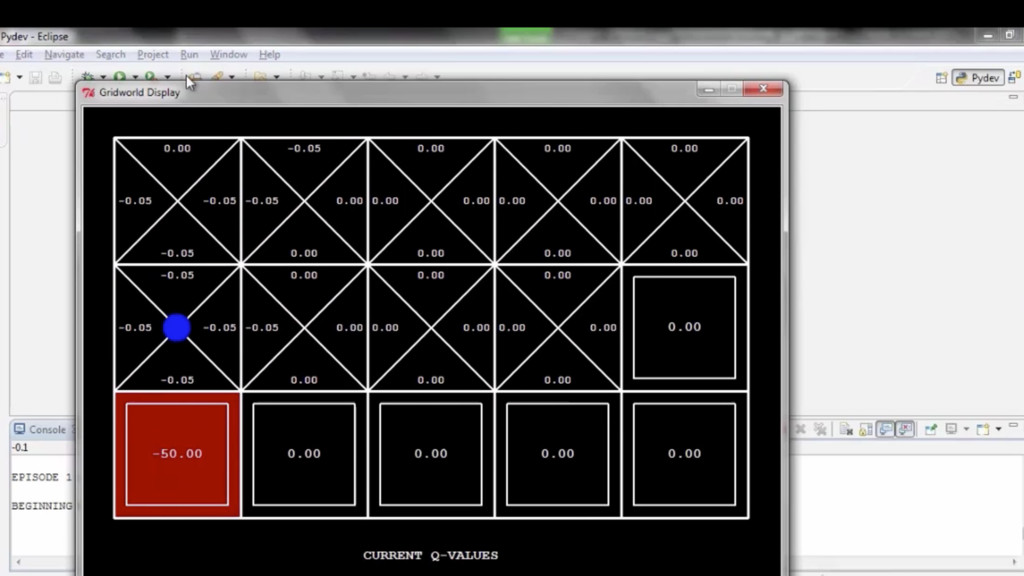{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
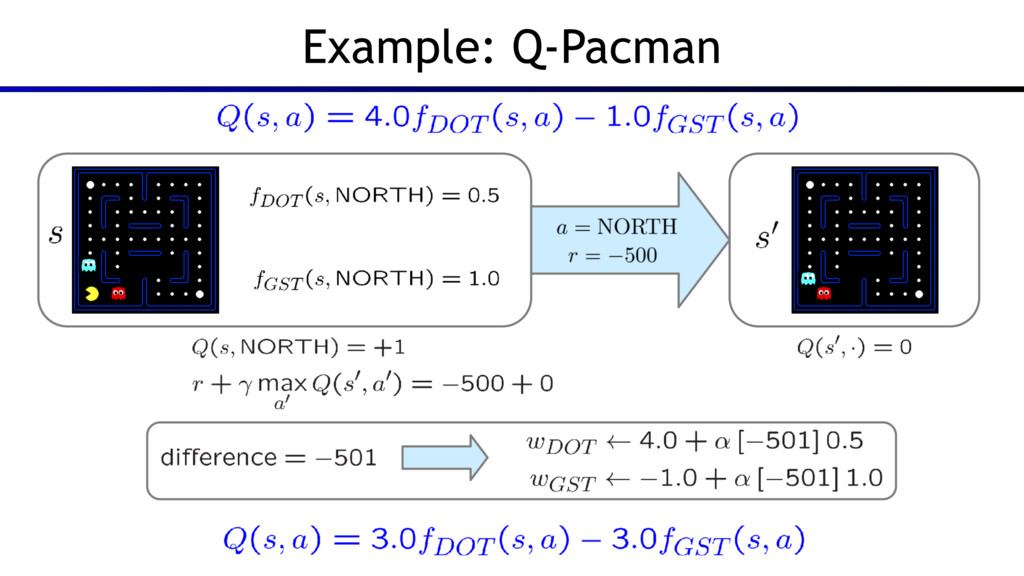{kind=link}
{kind=link}
{kind=link}