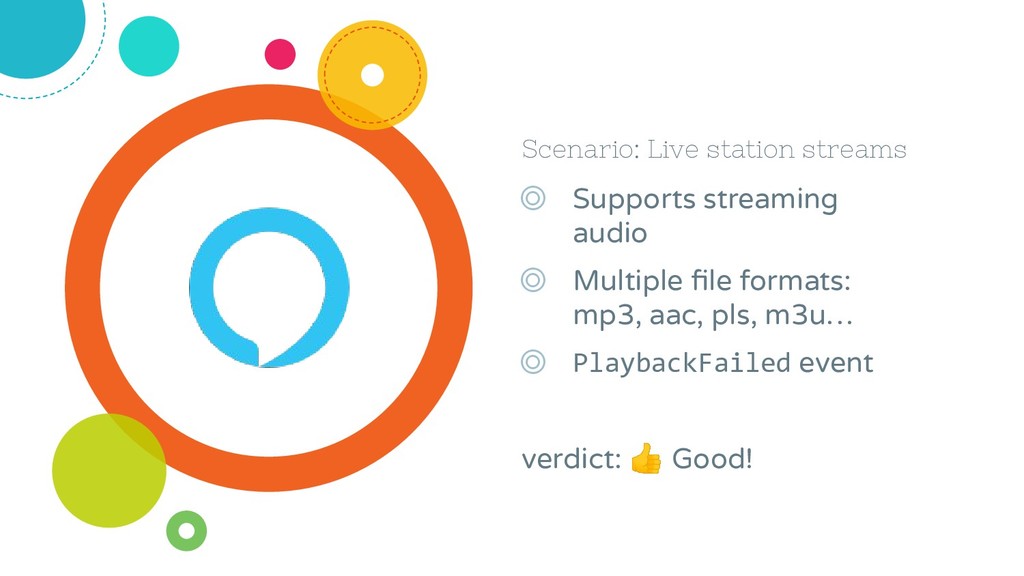
At NPR, our interest in voice-based interfaces is obvious; they're a natural fit for our content, which has always taken an audio-first approach. Yet our expectations of voice platforms' capabilities to serve top-notch audio-first experiences have not always meshed with reality. Most of these platforms were designed primarily as vehicles for Text-to-Speech (TTS) interactions, and the ability to play audio beyond the 120 seconds or so allowed by an SSML tag comes with a distinct set of challenges, ranging from hard platform limitations to implementation quirks, documentation oversights, suboptimal user experiences, and essential features that are still missing. While we've proven that it isn't impossible to build a great audio-first experience, the journey it took to get there was almost entirely uphill.
Join a developer from NPR as she discusses the good, the bad, and the ugly of audio-first development on the Amazon Alexa and Google Assistant platforms. Along the way, she'll share her vision of what an ideal audio-first developer platform might look like.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Keep in touch: @xiehan [email protected] please don't contact](https://files.speakerdeck.com/presentations/6f62778c5ef04a54a23657223f287d0c/slide_17.jpg){kind=link}