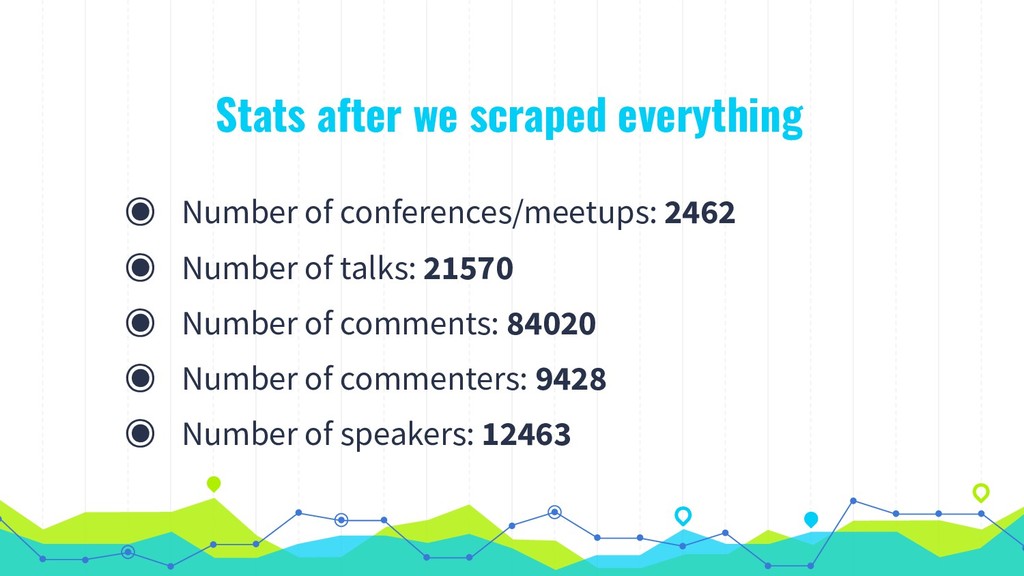
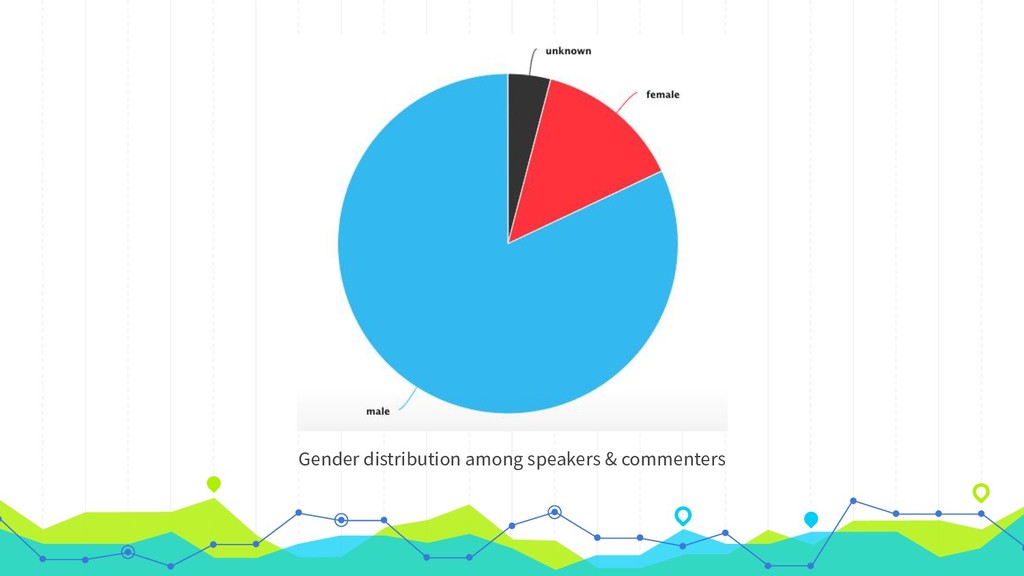
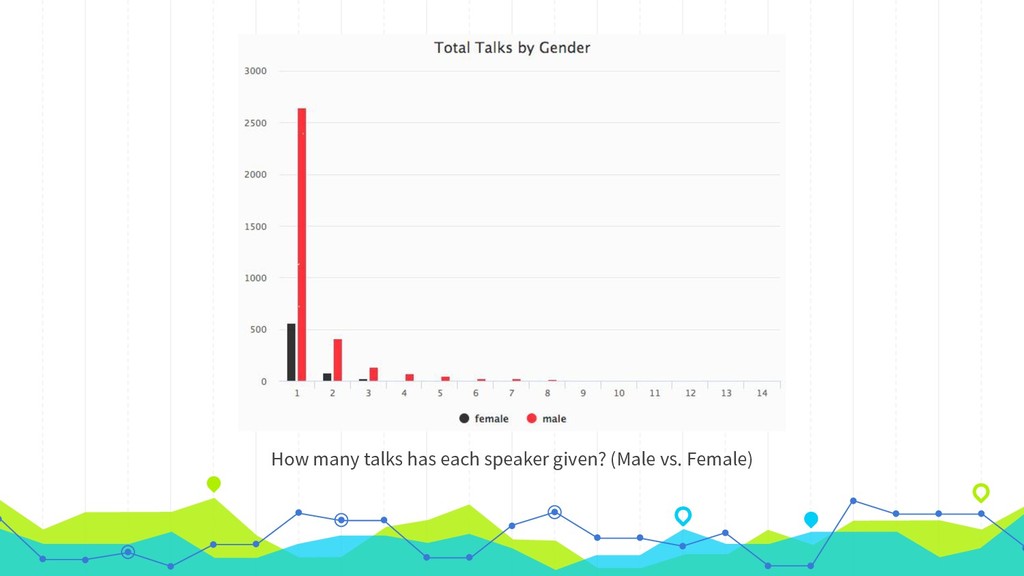
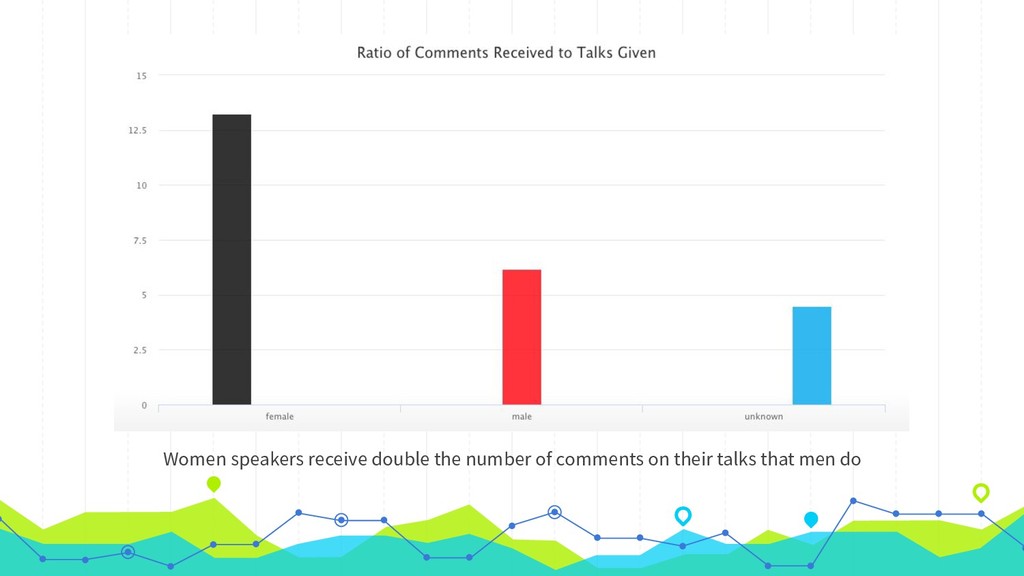
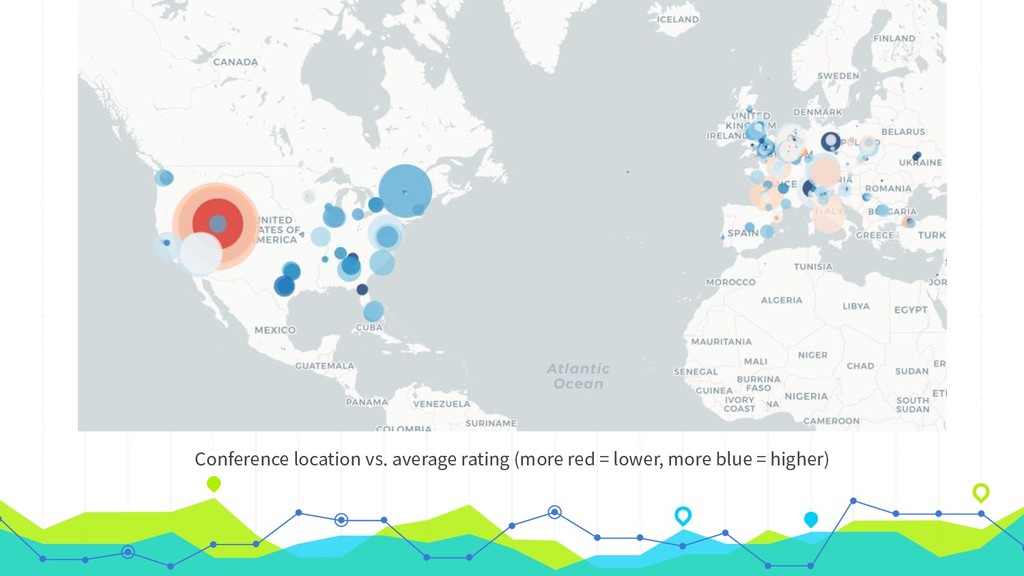
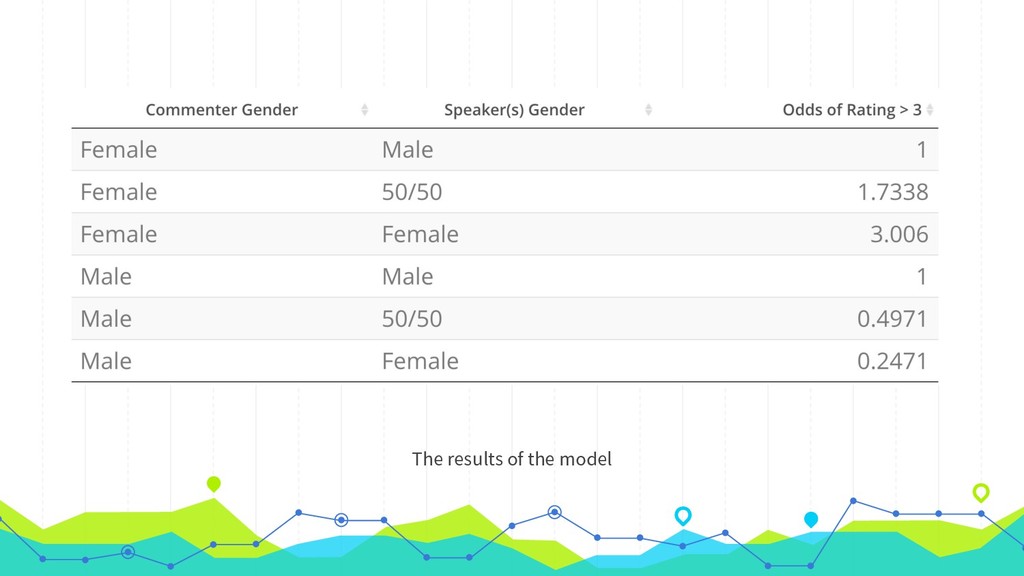
Like many PHP conferences, phpDay has a long tradition of using the platform joind.in to collect attendee feedback on the talks, used both by speakers to improve their respective presentations, as well as by the conference organizers to make decisions about tracks, talks, and speakers in the future. While joind.in isn’t exclusive to PHP conferences, it has its roots in that community, and so that is where its usage is most prevalent. Since its longtime maintainers recently announced their intention to step down and decommission the web server, making way for a new leadership team to step in and breathe new life into the project, now is a great time to take a meta look at joind.in and what it says about the PHP community. In addition to the web interface that you’re likely familiar with, joind.in has a public API that exposes virtually all the data it collects, including every single comment on every single talk at every single event in the system. In August 2018, during one of my company’s semiannual hack weeks, I partnered with our data scientist and one of our data analysts to analyze all of the comments and accompanying ratings revealed by the API. Come learn how we did it and, more importantly, what we learned as a result, and what lessons this might hold for us all as PHP community members.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}