Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
immutable database
Search
xorphitus
October 07, 2015
Programming
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
immutable database
Datomic の紹介です。
xorphitus
October 07, 2015
More Decks by xorphitus
See All by xorphitus
オリジナリティのあるGitLabを標準に近づける
xorphitus
1
790
マイクロサービスを作ろう
xorphitus
0
150
コンテナ起動への道
xorphitus
0
170
型システムを学ぼうとした結果
xorphitus
0
79
M-x doctor
xorphitus
0
170
型で数を表そう
xorphitus
0
110
AOT と direct linking
xorphitus
0
85
CFS入門
xorphitus
0
87
HyperLogLog
xorphitus
0
130
Other Decks in Programming
See All in Programming
yield再入門 #phpcon
o0h
PRO
0
750
Lean は証明の正しさを確認するためだけのツールって思ってませんか?
inoueasei
1
110
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
170
PostgreSQL 18で考えるUUID主キー
kazuhiro1982
0
410
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
910
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.7k
FDEが実現するAI駆動経営の現在地
gonta
2
220
共通化で考えるべきは、実装より公開する型だった
codeegg
0
280
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
160
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
280
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
8
3.4k
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
360
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
The Invisible Side of Design
smashingmag
301
52k
Embracing the Ebb and Flow
colly
88
5.1k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Six Lessons from altMBA
skipperchong
29
4.3k
How GitHub (no longer) Works
holman
316
150k
The Cult of Friendly URLs
andyhume
79
7k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Side Projects
sachag
455
43k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
350
Transcript
イミュータブルな データベース @xorphitus (2015-10)
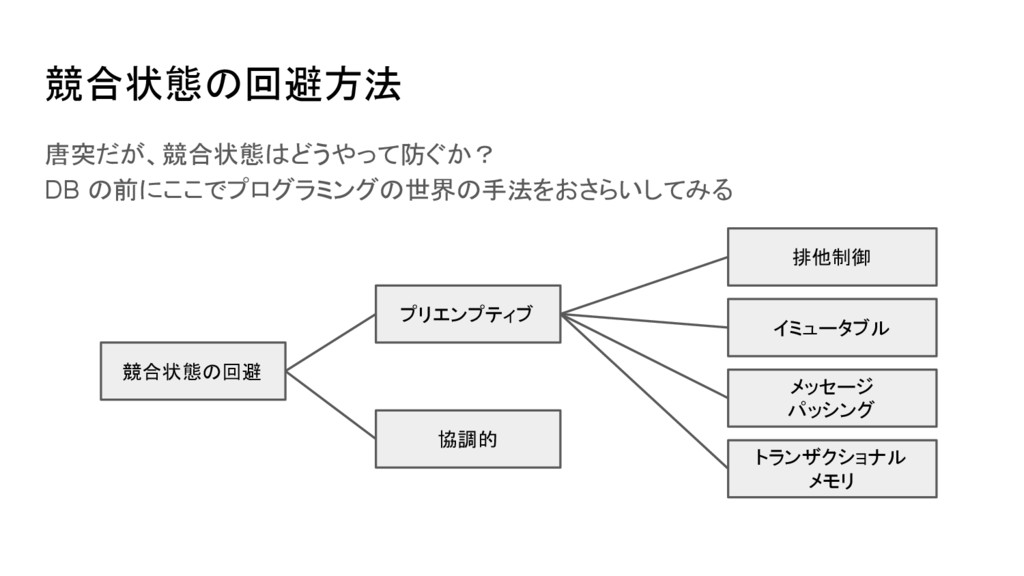
競合状態の回避方法 唐突だが、競合状態はどうやって防ぐか? DB の前にここでプログラミングの世界の手法をおさらいしてみる プリエンプティブ 協調的 排他制御 イミュータブル メッセージ パッシング
トランザクショナル メモリ 競合状態の回避
じゃあ、DB もイミュータブルだな
それはつまり
None
Datomic とは • CRUDのうち C と R しかない ◦ 一度作られたデータはイミュータブルである
• 追記型 ◦ 変更は、同一 ID で新しいレコードを追加する ◦ ただし PostgreSQL と違って過去の履歴を全て保持 するモデル ◦ 削除は、同一 ID で打ち消しを意味するレコードを追加する • クエリは Datalog という Prolog のサブセット • プロプライエタリ というスペックなのだが、その背後には独自の論理モデルがある模様
Datomic の思想 • これまでの DB は場所指向だった ◦ PLOP (Place-Oriented Programming)
◦ リソースが希少だった時代、新しい情報は、古い情報のあった場所に上書きすることで、空間 (ディ スクとメモリ) を節約する必要があった ▪ 情報は場所に紐付いた存在となった ▪ そして DB サーバは、場所の管理を頑張らないといけなくなった • いや、今そんな貧しい時代じゃねえし ◦ だいたい、ここでいう「場所」って情報と関係ない概念だよね ◦ あと、過去にあった情報、すなわちその時点における事実は変わらない ▪ 例えば、人間が引っ越しをしても過去の住所が UPDATE されるわけではない • 場所指向をやめたらかっこいいアーキテクチャにできるよ! ◦ いまここ
場所指向で何が悪い? • DB サーバの担ってる以下の責任を、一箇所で行う必要が出てくる ◦ トランザクション ◦ データ一貫性の維持 ◦ インデキシング
◦ ストレージの I/O ◦ クエリの受け付け • ディスクとメモリの何処に何があるか、を各々が把握して動く状態 ◦ PostgreSQL 的な追記型アーキテクチャでも上記は同じ場所に配置されていて問題解決していな い ◦ また、App から分断された世界が作られることでインピーダンスミスマッチが起きる • これらを分解したい ◦ 各々がシンプルになり、特定の処理に特化でき、好きな場所に再配置可能 ◦ (分散っぽい話になってきた )
で、場所指向をやめる • 新しいデータは、一方的に蓄積していこう ◦ 一度積まれたデータの更新・削除はもう考えない ◦ 少し低いレイヤで起きていることは、 RDB でいう履歴テーブルみたいな状態 ◦
富豪的な時代になったものである • こうした一方的なデータストレージに対し、それっぽい抽象 I/F つけたら諸々分離で きるんじゃね? ◦ …と、いうことなんじゃないかな ◦ 質問は受け付けません
ちなみにデータモデルはこんな感じ • 田中さんの fact を追加 ◦ {id: 1, name: ‘田中’,
address: ‘東京都渋谷区神南’} • 田中さんが引っ越したので fact をさらに追加 ◦ {id: 1, name: ‘田中’, address: ‘東京都神田錦町’} • で、2 レコードになる ◦ 最初の fact は immutable ◦ クエリでは、特に指定がなければ現在の fact が取得される ◦ 過去に遡って取得もできる
で、なんやかんや色々あって
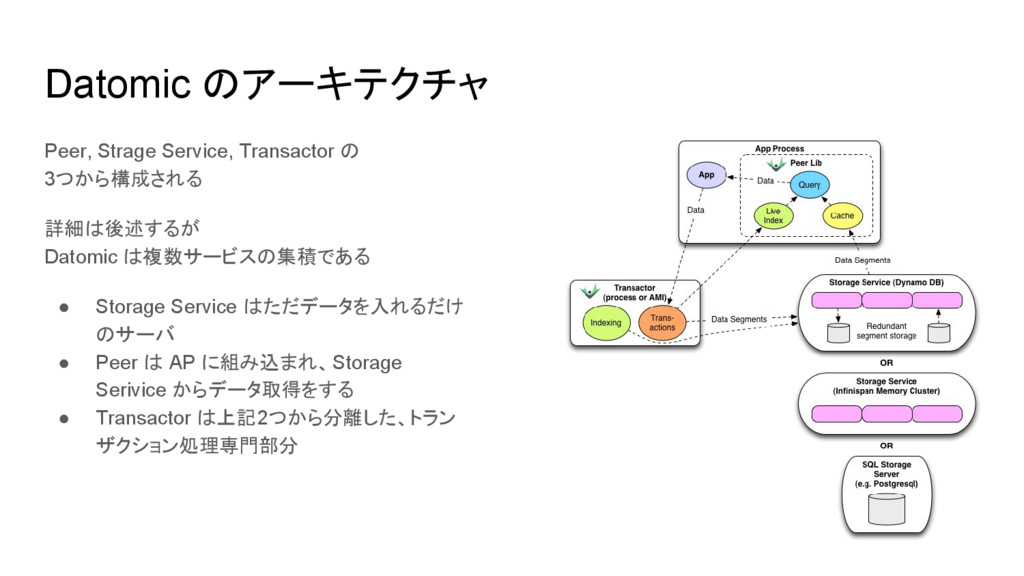
Datomic のアーキテクチャ Peer, Strage Service, Transactor の 3つから構成される 詳細は後述するが Datomic
は複数サービスの集積である • Storage Service はただデータを入れるだけ のサーバ • Peer は AP に組み込まれ、Storage Serivice からデータ取得をする • Transactor は上記2つから分離した、トラン ザクション処理専門部分
Peer のお仕事 • App のプロセスに (ライブラリとして) 組み込まれて動作するもので • Query を処理して
• Storage Service から該当するデータを取得し • App のメモリ内のキャッシュする ◦ 各 fact はイミュータブルからキャッシュし放題 ▪ キャッシュも背後のストレージも、 App からしたら意識することなく扱える • 一般的な RDB に対するメリット ▪ App のサーバを複数立てれば、 DB の Read 性能はスケールする ▪ ちなみに LRU ▪ この層に memcached を使うこともできるっぽい ◦ 新たな fact が積まれた場合、Transactor がそれを各 Peer にブロードキャストする (後述)
Transactor のお仕事 • Write (追記) は全て Transactor (ぶっちゃけSPOF的) が Peer
からの指示で担う ◦ Transactor は全ての処理をトランザクションとし、シリアルに行う ◦ なので Write 時にロックとらなくてもいいし、とってない • 何それ怖えー、となりそうだが、設計思想としては ◦ 他の処理は全部 Peer に寄せてるんだから Transactor クッソ軽い ◦ こいつ落ちても各 Peer は生きてるし Read は継続可能 ◦ Hot Standby 機を立ときゃいいわけだし ◦ そもそも Transactor が高負荷になるものに Datomic 使うのが間違いの元 ▪ 他の技術を使いましょう ◦ (あと、よく考えたら MySQL の Master だって似たようなもんだじゃね? ) • Write したら Peer にブロードキャストして Peer 内 Index を更新する
Strage Service のお仕事 • ファイルシステムを抽象化して ◦ Peer にデータを提供する ◦ Transactor
から書き込まれる • RDBMS や KVS (選択可能) が抽象化技術として使われる ◦ ファイルシステムに直接触ることはない
Storage Service 層ってどうなってるの? Backend に MySQL を選択するとこれだけ… CREATE TABLE datomic_kvs
( id varchar(640) NOT NULL, rev integer, map text, val longblob, CONSTRAINT pk_id PRIMARY KEY (id) ) ENGINE=INNODB
まとめのような何か • 旧来の RDBMS が一手に担っていた各部分が分散されるようになった • Write はシリアルに実行される ◦ 軽量な
Transactor が順次実行する • Read は App に分散される ◦ App のプロセス内で積極的にキャッシュし、各 App のノードはそこから読み出す ◦ クエリ処理〜データ取得 (キャッシュヒットすれば ) が分散処理される
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}