Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[CS Foundation] AIML - 2 - Regression
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
x-village
August 14, 2018
Programming
63
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[CS Foundation] AIML - 2 - Regression
x-village
August 14, 2018
More Decks by x-village
See All by x-village
[CS Foundation] Web - 6 - Flask Introduction
xvillage
0
280
[CS Foundation] AIML - 5 - Deep Learning
xvillage
1
120
[CS Foundation] Web - 7 - CRUD in Flask
xvillage
0
140
[CS Foundation] Web - 4 - JavaScript Web Course
xvillage
0
52
[CS Foundation] Web - 5 - Database
xvillage
0
68
[CS Foundation] AIML - 3 - Common Issue
xvillage
1
170
[CS Foundation] AIML - 4 - Classification
xvillage
0
51
[CS Foundation] Web - 1 - Web Course intro
xvillage
2
38
[CS Foundation] Web - 2 - HTML and CSS Web Course
xvillage
0
62
Other Decks in Programming
See All in Programming
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
190
今さら聞けない .NET CLI
htkym
0
120
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
350
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
280
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
910
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
160
PostgreSQL 18で考えるUUID主キー
kazuhiro1982
0
350
yield再入門 #phpcon
o0h
PRO
0
740
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1k
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
210
Featured
See All Featured
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
The SEO identity crisis: Don't let AI make you average
varn
0
520
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Faster Mobile Websites
deanohume
310
32k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Done Done
chrislema
186
16k
Between Models and Reality
mayunak
4
380
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
AI/ML - Regression Lo Pang-Yun Ting X-Village
Outline • Introduction of regression • Linear regression • Gradient
descent • Ordinary least square 2
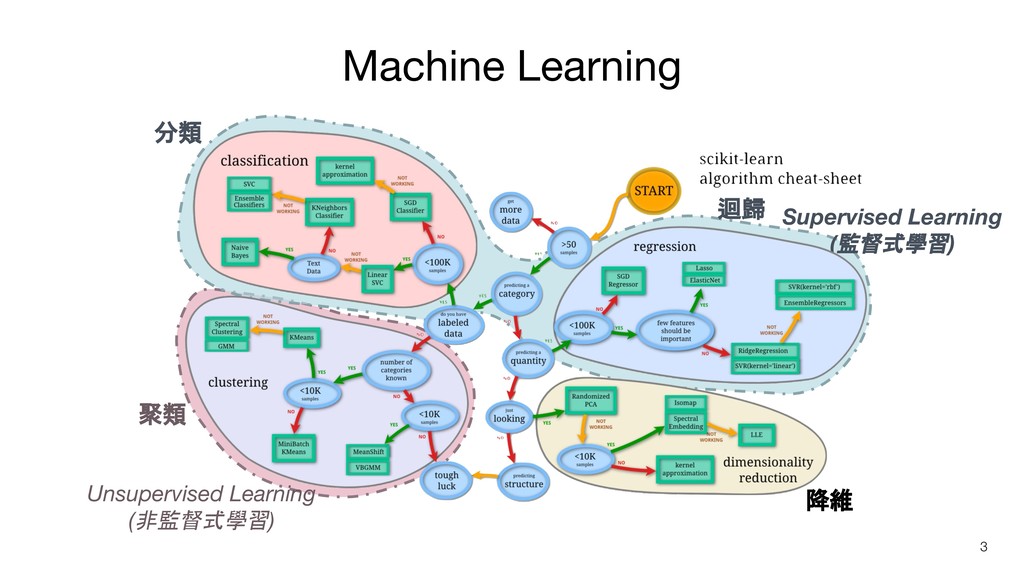
Unsupervised Learning (非監督式學習) Supervised Learning (監督式學習) Machine Learning 聚類 分類
迴歸 降維 3
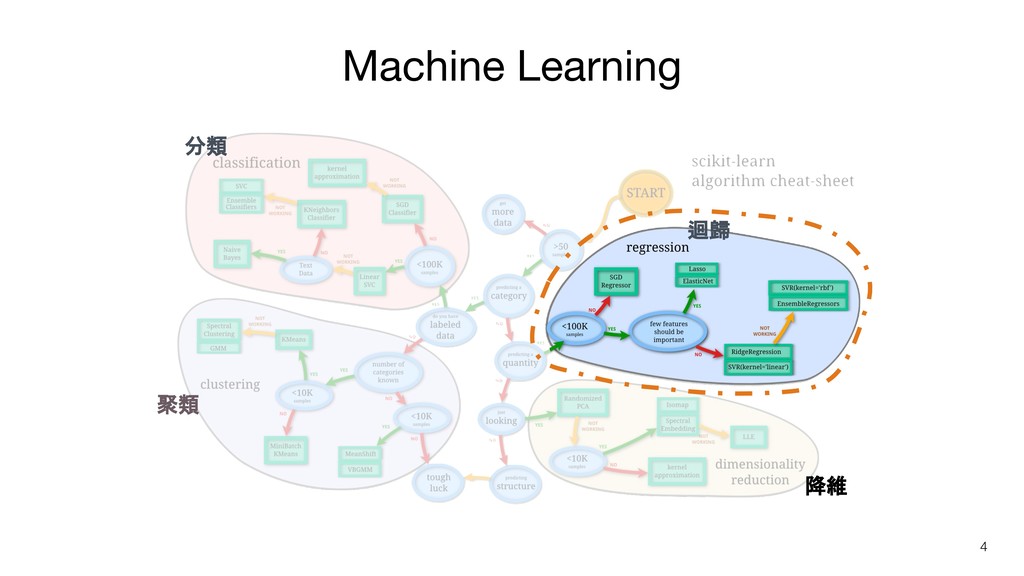
Machine Learning 聚類 分類 迴歸 降維 4
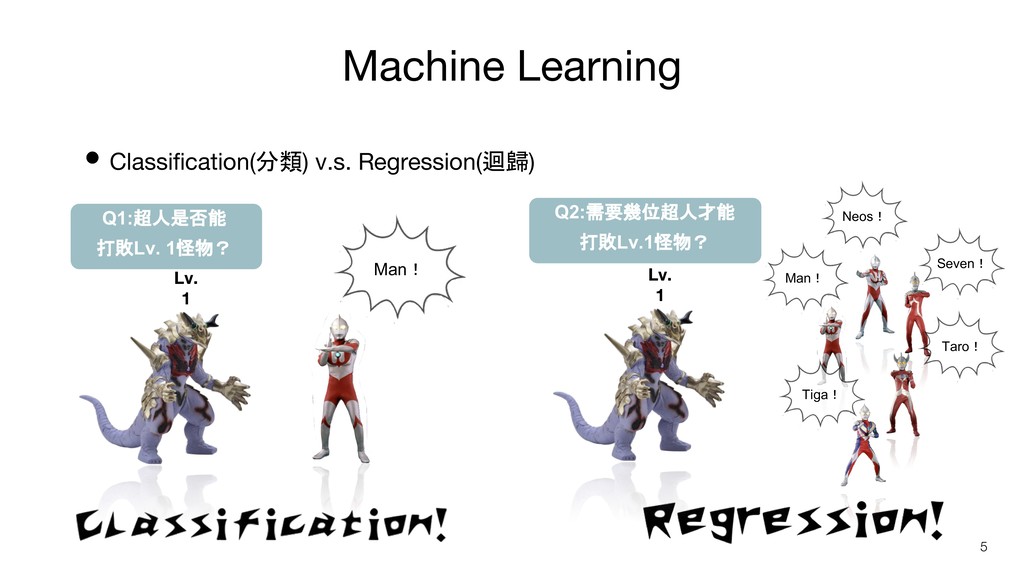
Machine Learning • Classification(分類) v.s. Regression(迴歸) Lv. 1 Lv. 1
Man! Q1:超人是否能 打敗Lv. 1怪物? 5 Seven! Neos! Man! Taro! Tiga! Q2:需要幾位超人才能 打敗Lv.1怪物?
Regression 6 • What is ‘regression’ analysis (迴歸分析)? 是一種統計學上分析數據的方法,目的在於了解兩個或多個變數間是否相關、 相關方向與強度,並建立數學模型以便觀察特定變數來預測研究者感興趣的變
數。(from wiki)
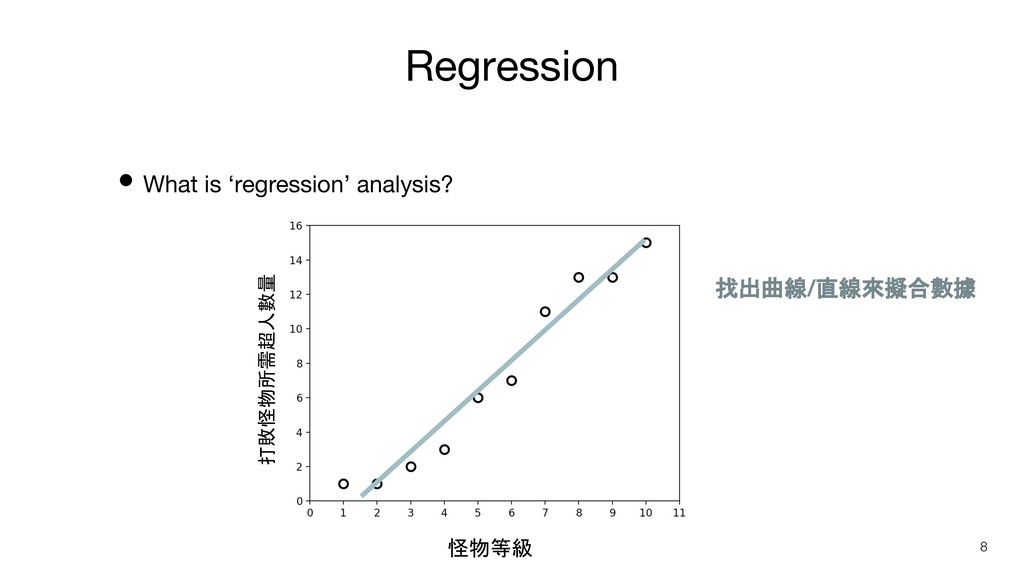
Regression • What is ‘regression’ analysis? 怪物等級 1 2 3
4 5 6 7 8 9 10 打敗怪物所需超人數量 1 1 2 3 6 7 11 13 13 15 7
Regression • What is ‘regression’ analysis? 8 怪物等級 打敗怪物所需超人數量 找出曲線/直線來擬合數據
Regression Features: x(i) = [x 1, … x d ]
Outputs: y(i) linear regression (線性迴歸) polynomial regression (多項式迴歸) 9
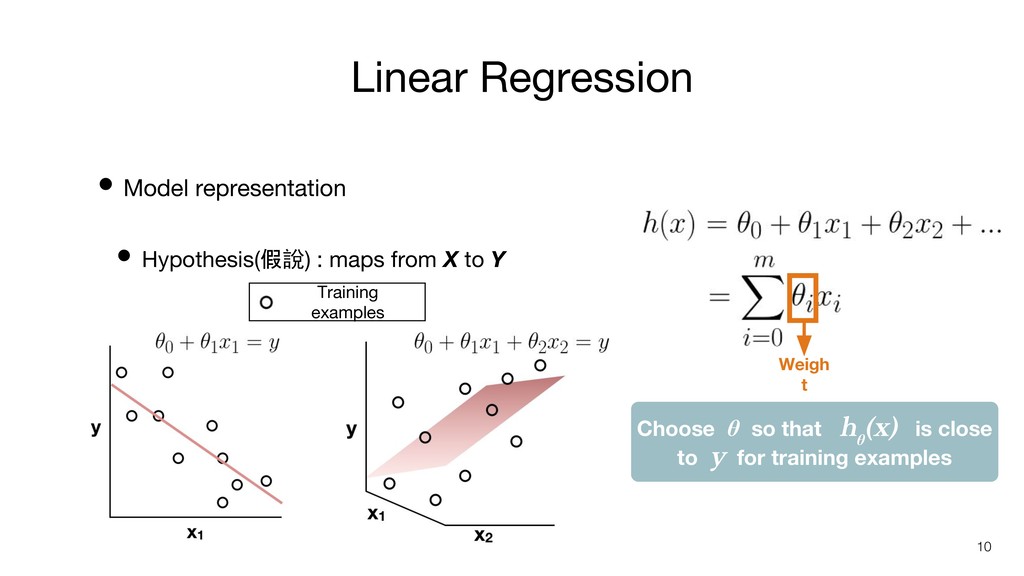
Linear Regression • Model representation • Hypothesis(假說) : maps from
X to Y Choose θ so that h θ (x) is close to y for training examples Training examples 10 Weigh t
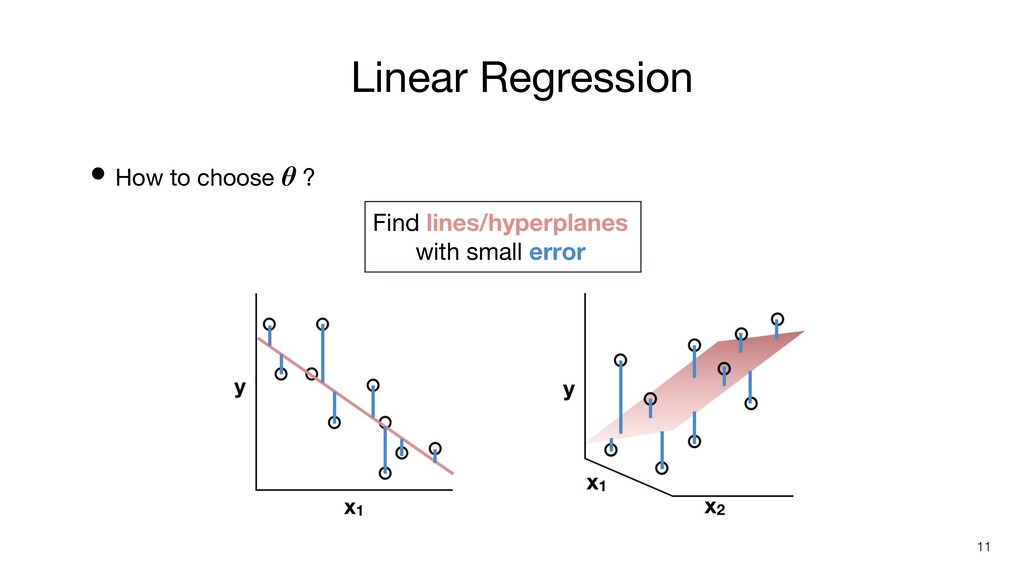
Linear Regression • How to choose θ ? Find lines/hyperplanes
with small error 11
Linear Regression • Definition of cost function 預測 真實 誤差
mean square error (MSE) Cost Function J(θ 0 , θ 1 ) minimize J(θ 0 , θ 1 ) 12 h θ (x) Hypothesis
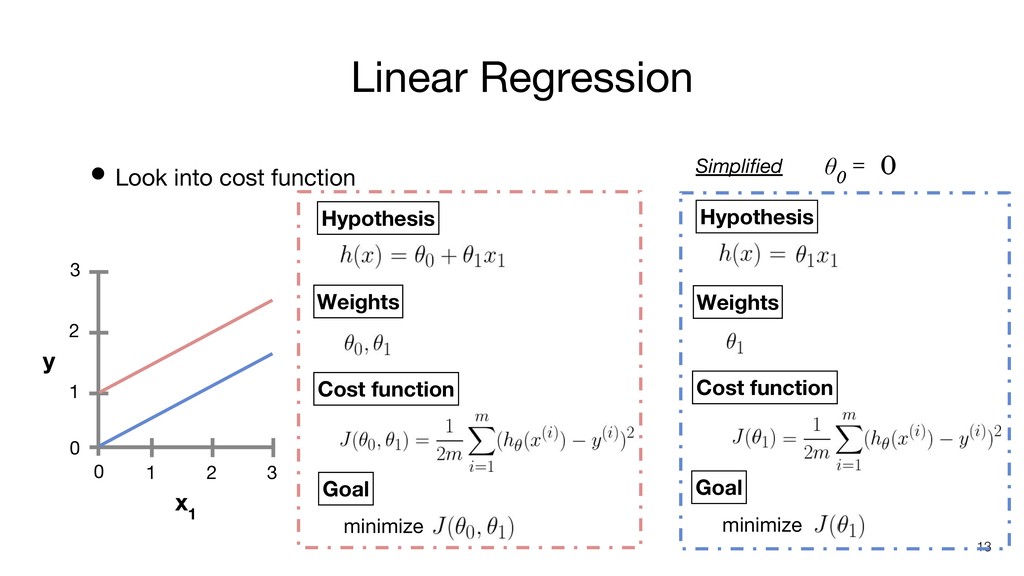
Linear Regression • Look into cost function x 1 y
0 1 2 3 0 1 2 3 θ 0 = 0 Simplified 13 Goal Hypothesis Weights Cost function minimize Goal Hypothesis Weights Cost function minimize
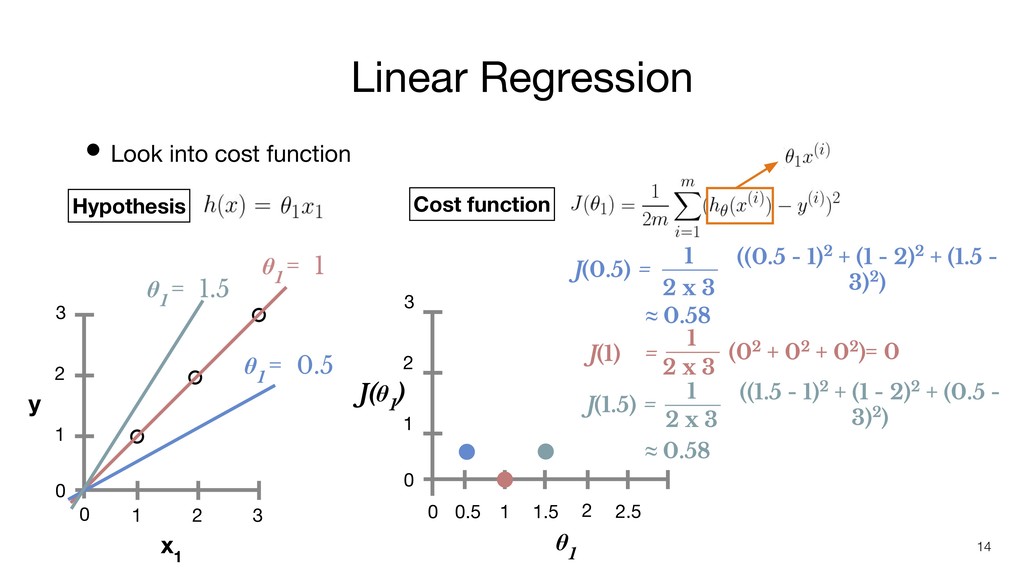
Linear Regression x 1 y 0 1 2 3 0
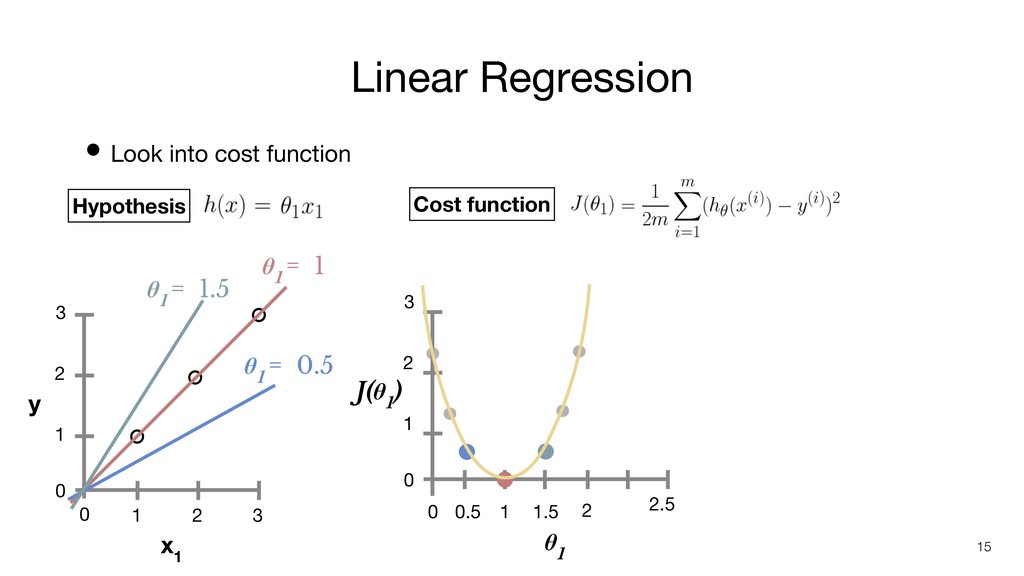
1 2 3 • Look into cost function 0 0.5 1 1.5 0 1 2 3 J(θ 1 ) θ 1 = 1 Hypothesis Cost function 2 2.5 θ 1 θ 1 = 0.5 θ 1 = 1.5 14 (02 + 02 + 02) 1 2 x 3 J(1) = ((0.5 - 1)2 + (1 - 2)2 + (1.5 - 3)2) 1 2 x 3 J(0.5) = ≈ 0.58 ((1.5 - 1)2 + (1 - 2)2 + (0.5 - 3)2) 1 2 x 3 J(1.5) = ≈ 0.58 = 0
Linear Regression x 1 y 0 1 2 3 0
1 2 3 • Look into cost function 0 0.5 1 1.5 0 1 2 3 J(θ 1 ) θ 1 = 1 Hypothesis Cost function 2 2.5 θ 1 θ 1 = 0.5 θ 1 = 1.5 15
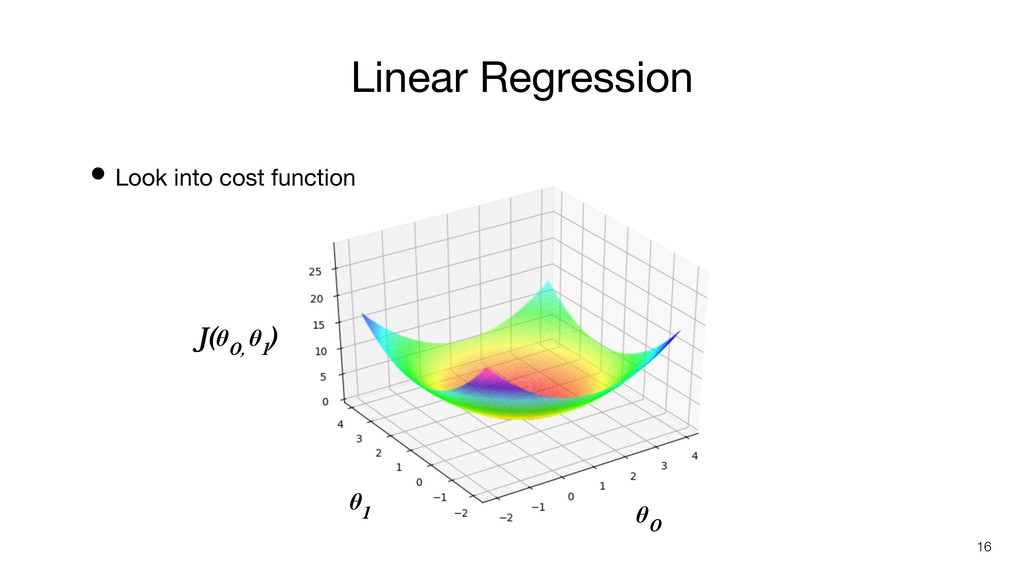
Linear Regression • Look into cost function 16 θ 1
θ 0 J(θ 0, θ 1 )
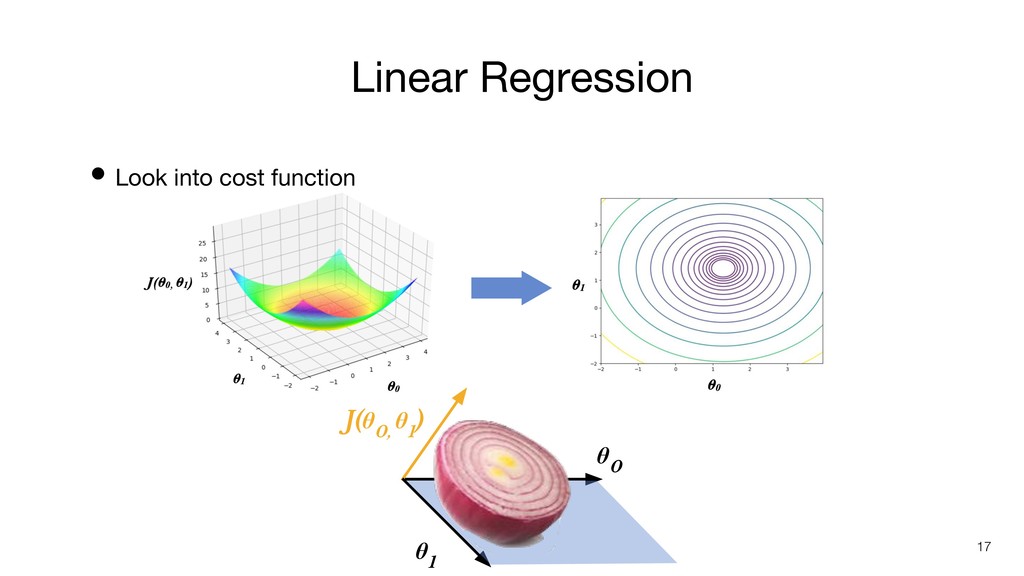
• Look into cost function J(θ 0, θ 1 )
θ 1 θ 0 17 Linear Regression
Minimize The Cost Function
Linear Regression • Optimize linear regression • Gradient descent •
Ordinary least square 19
Linear Regression • Optimize linear regression • Gradient descent •
Ordinary least square 20
• Gradient descent (梯度下降法) Gradient Descent 21 Cost function J(θ
0, θ 1 ) Goal J(θ 0, θ 1 ) minimize OUTLINE • Start with some θ 0 , θ 1 • Keep changing θ 0 , θ 1 to reduce J(θ 0, θ 1 ) until we hopefully end up at a minimum
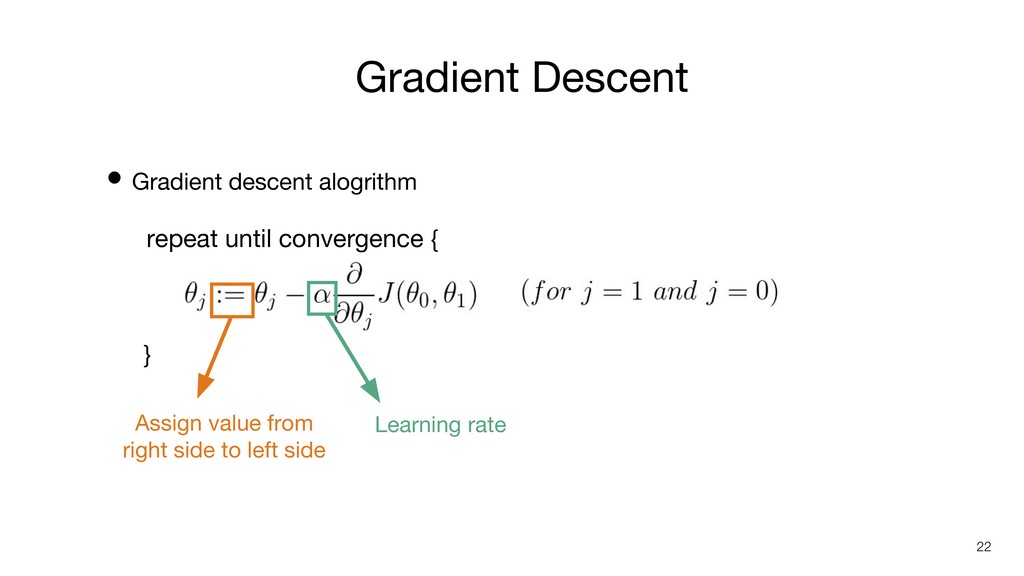
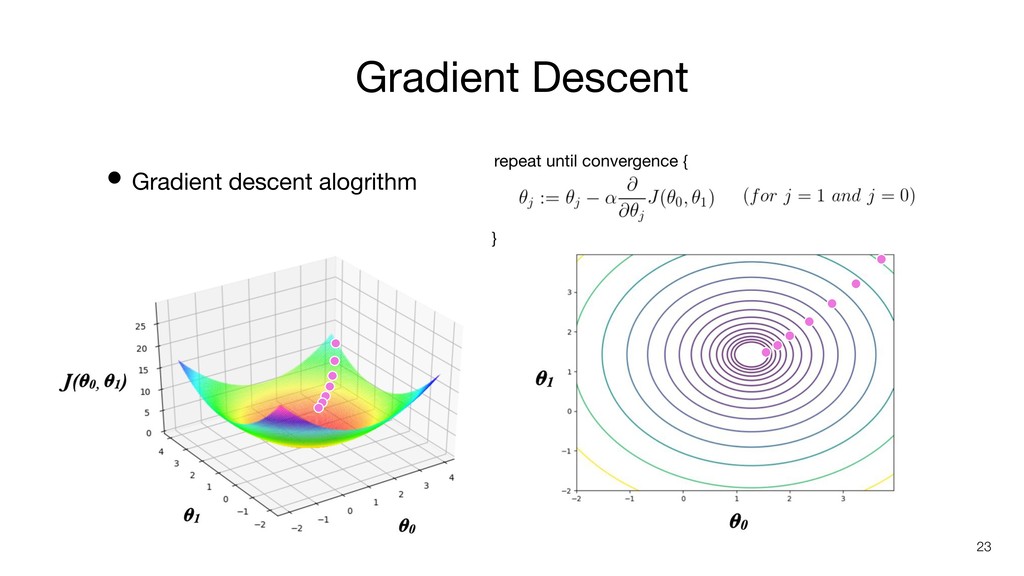
repeat until convergence { } • Gradient descent alogrithm Gradient
Descent 22 Learning rate Assign value from right side to left side
• Gradient descent alogrithm Gradient Descent 23
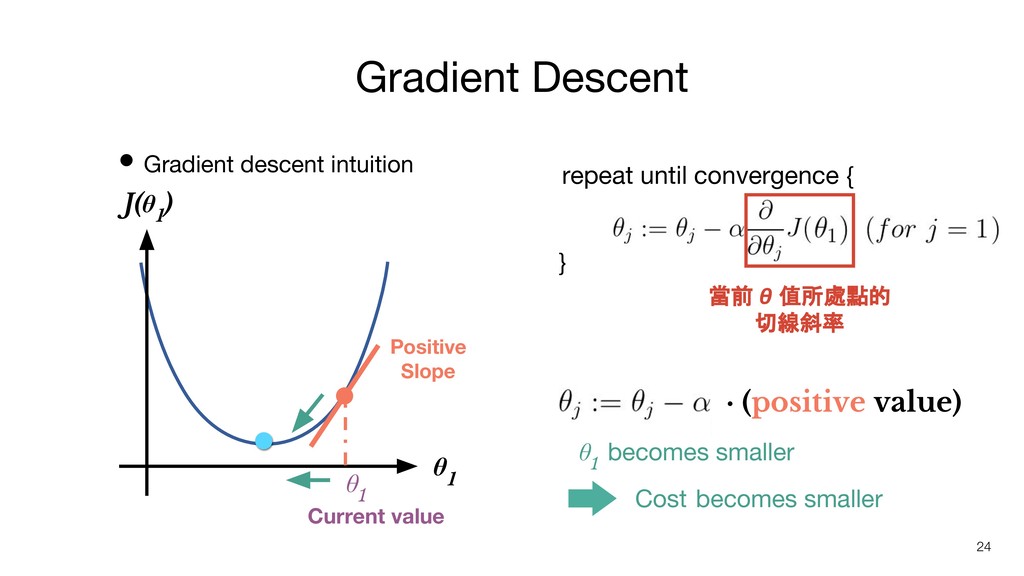
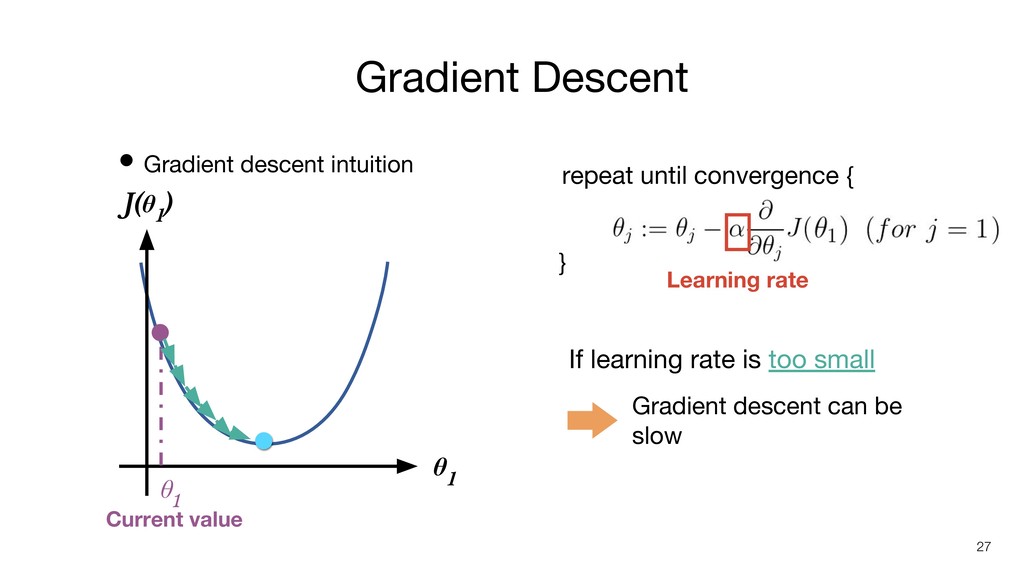
• Gradient descent intuition Gradient Descent 24 J(θ 1 )
θ 1 · (positive value) Positive Slope repeat until convergence { } 當前 θ 值所處點的 切線斜率 θ 1 Current value θ 1 becomes smaller Cost becomes smaller
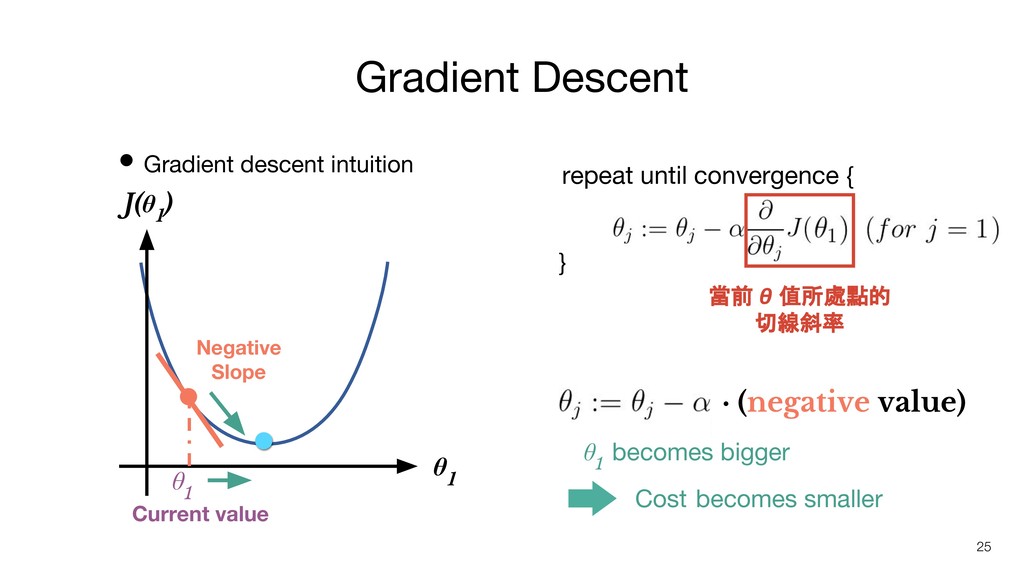
• Gradient descent intuition Gradient Descent 25 J(θ 1 )
θ 1 · (negative value) Negative Slope repeat until convergence { } 當前 θ 值所處點的 切線斜率 θ 1 Current value θ 1 becomes bigger Cost becomes smaller
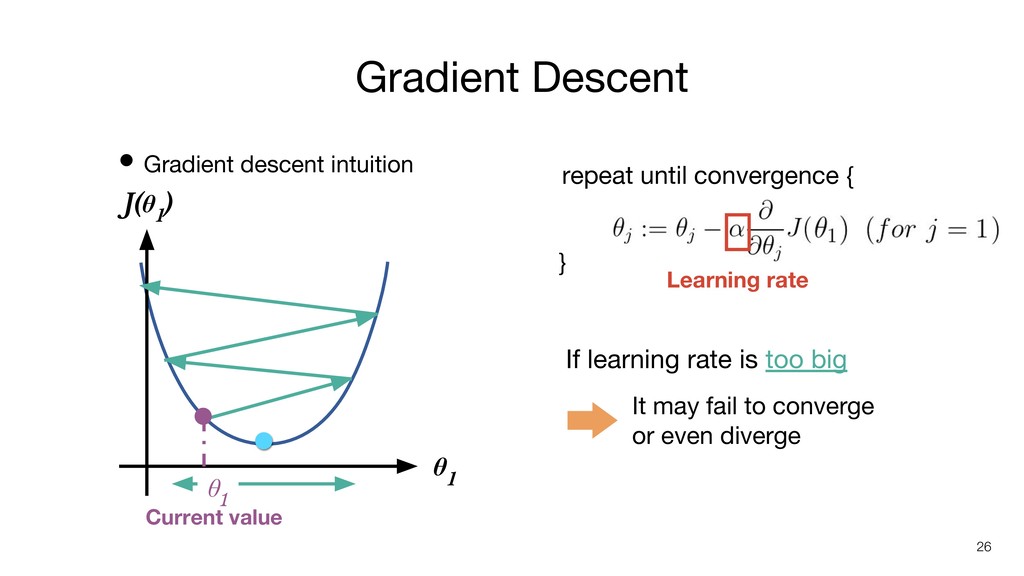
• Gradient descent intuition Gradient Descent 26 J(θ 1 )
θ 1 repeat until convergence { } Learning rate If learning rate is too big It may fail to converge or even diverge θ 1 Current value
• Gradient descent intuition Gradient Descent 27 J(θ 1 )
θ 1 repeat until convergence { } Learning rate If learning rate is too small Gradient descent can be slow θ 1 Current value
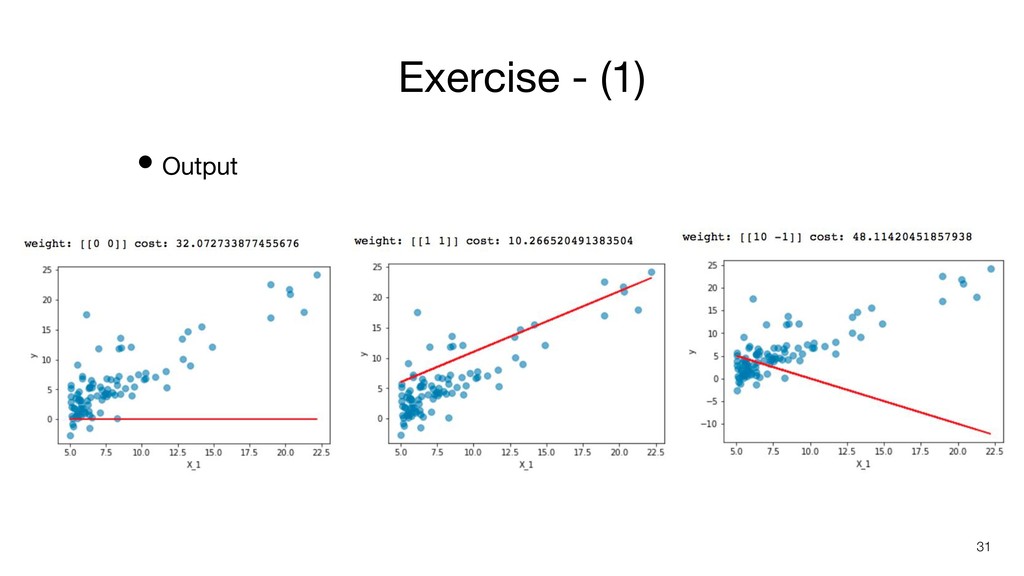
Exercise - (1) • TASK: Implement linear regression • Sample
code 28
Exercise - (1) • Requirements 1. 完成 hypothesis function 和
cost function 29 Hypothesis Cost function
Exercise - (1) • Requirements 2. 分別測試 (θ 0 θ
1 ) = (0, 0), (1, 1), (10, -1),印出算出的cost值 3. 觀察不同 θ 值所得到的regression line和cost之間的關係 30
Exercise - (1) • Output 31
Linear Regression • Optimize linear regression • Gradient descent •
Ordinary least square 32
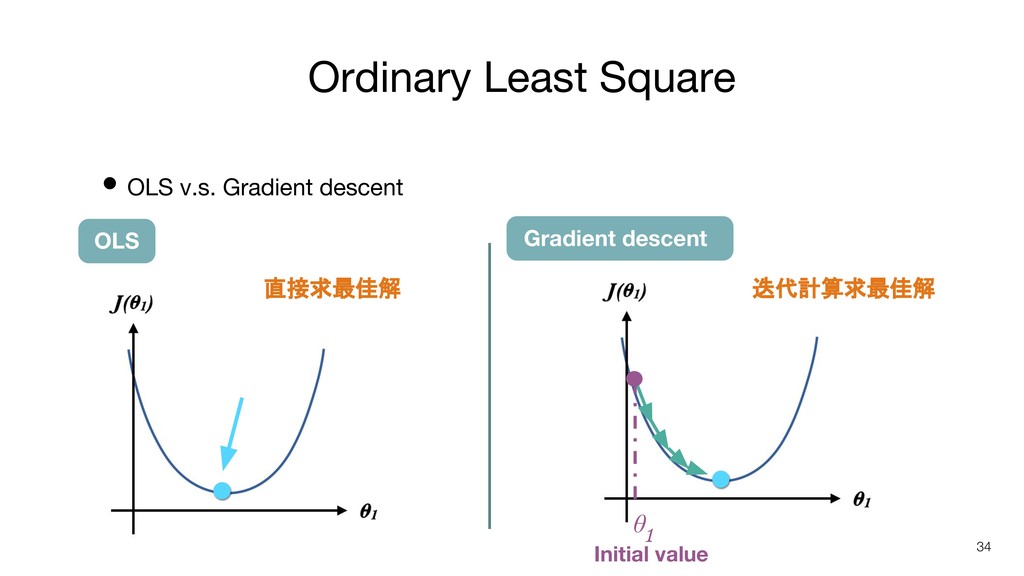
Ordinary Least Square • Ordinary least square (最小平方法/最小二乘法) 33 repeat
until convergence { } Solve Gradient descent Cost function OLS
Ordinary Least Square • OLS v.s. Gradient descent 34 Gradient
descent OLS θ 1 Initial value 直接求最佳解 迭代計算求最佳解
Example • sklearn - LinearRegression 35 Use OLS to optimize
linear regression
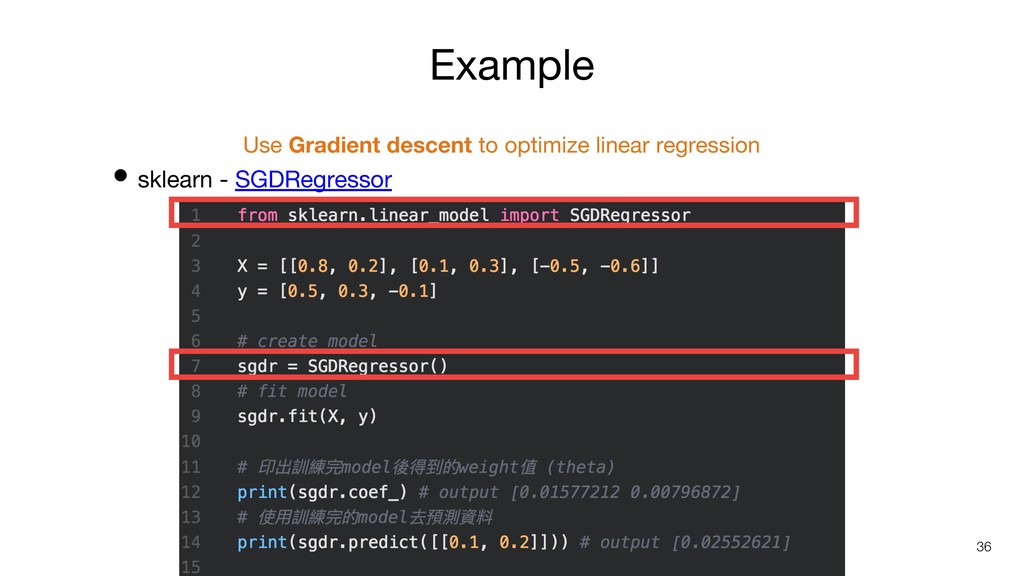
Example • sklearn - SGDRegressor 36 Use Gradient descent to
optimize linear regression
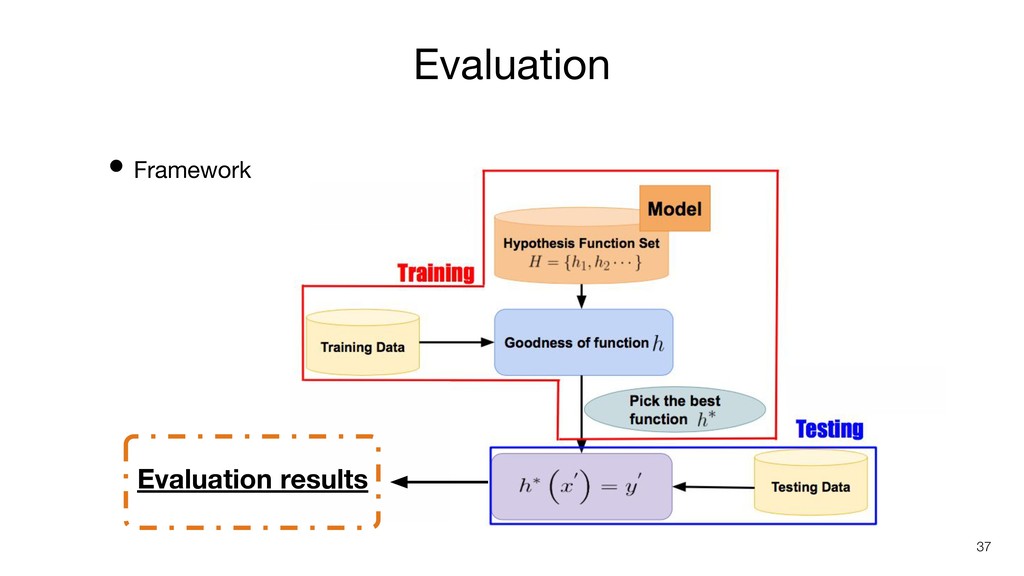
Evaluation 37 • Framework Evaluation results
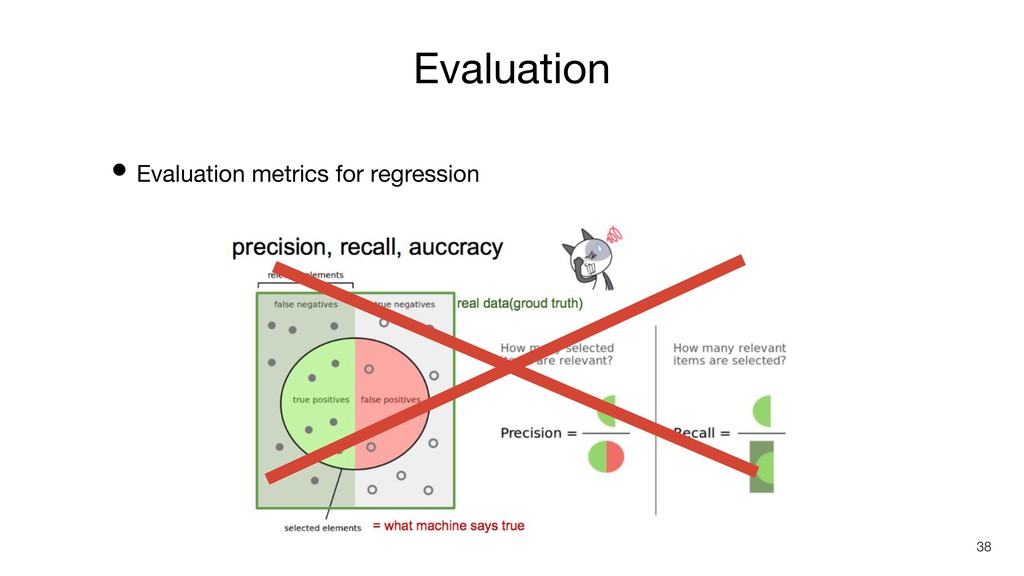
Evaluation • Evaluation metrics for regression 38
Evaluation • Evaluation metrics for regression 39 • Mean square
error (MSE) • Root mean square error (RMSE) • Mean absolute error (MAE) 預測 真實 • 預測值和真實值的差值 • 越小越好
Evaluation • Evaluation metrics for regression 40 • R-squared score
(R2 score) • 預測值和真實數據的擬合程度 • 最佳值為1
Example • sklearn - mean_squared_error, mean_absolute_error, r2_score 41
Exercise - (2) • TASK: Use sklearn to implement linear
regression • Sample code • Requirements • 使用 Exercise - (1) 的數據來訓練LinearRegression( ) and SGDRegressor( ) • 印出兩種方法訓練完後得到的weight值 (θ) • 觀察兩種方法的結果 42
Exercise - (3) 43 • TASK: Use sklearn.metrics to evaluate
models • Requirements • 印出Exercise - (2)兩個models的RMSE (測試的資料先用training data替代)
Exercise - (3) 44 • Output
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Regression Features: x(i) = [x 1, … x d ]](https://files.speakerdeck.com/presentations/08f72308eb3c498e956e32b63aefe4b6/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}