を持たせるフェーズ • 大 規模な計算資源と 大 規模なデータセットを必要とする • 学習データはWebからのクロールデータが 一 般的 LLaMA: Open and E ffi cient Foundation Language Models 19 Webのクロールデータ CommonCrawlの整形データ 技術者を中 心 とするQ&A
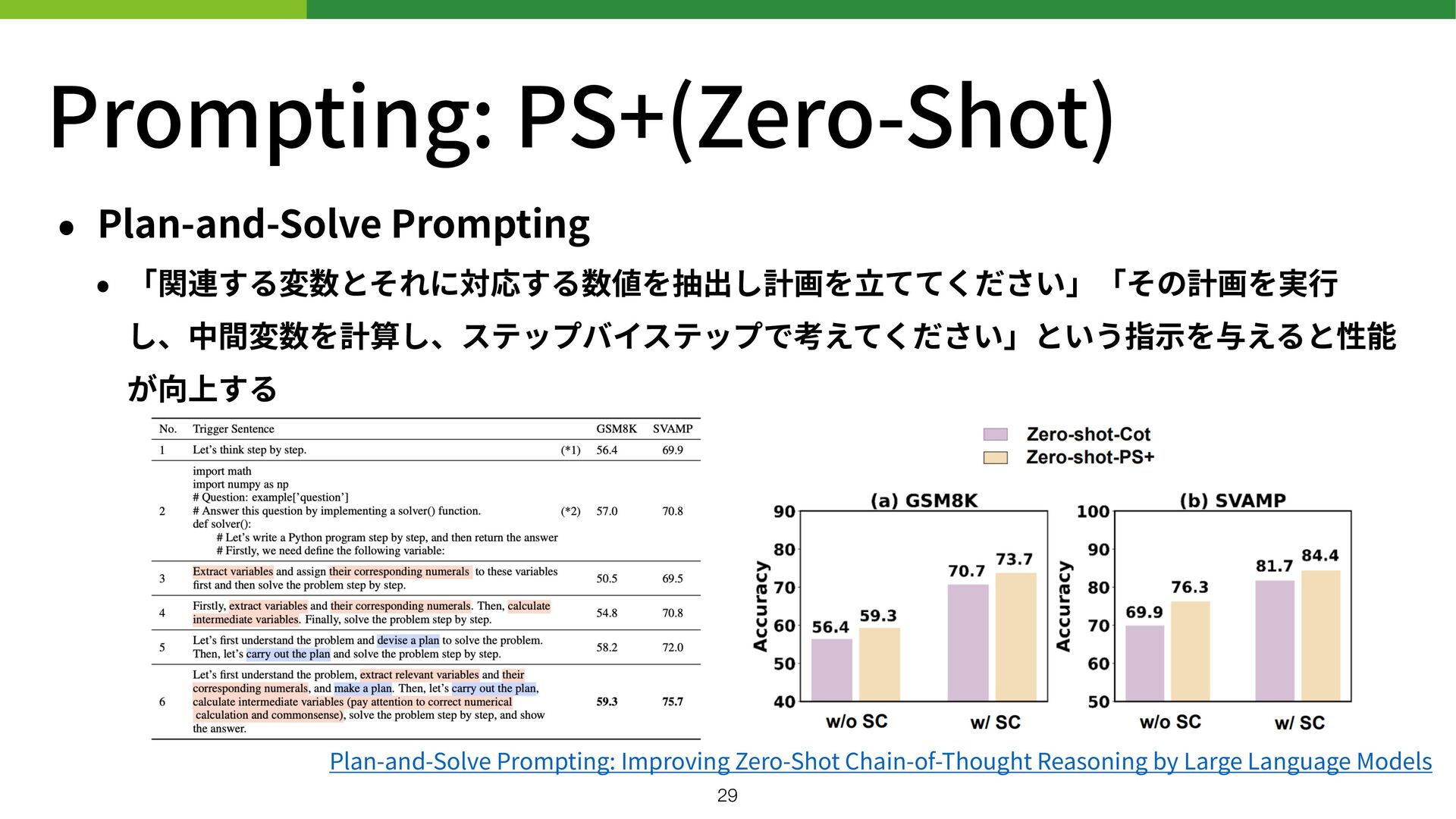
し、中間変数を計算し、ステップバイステップで考えてください」という指 示 を与えると性能 が向上する Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models 29
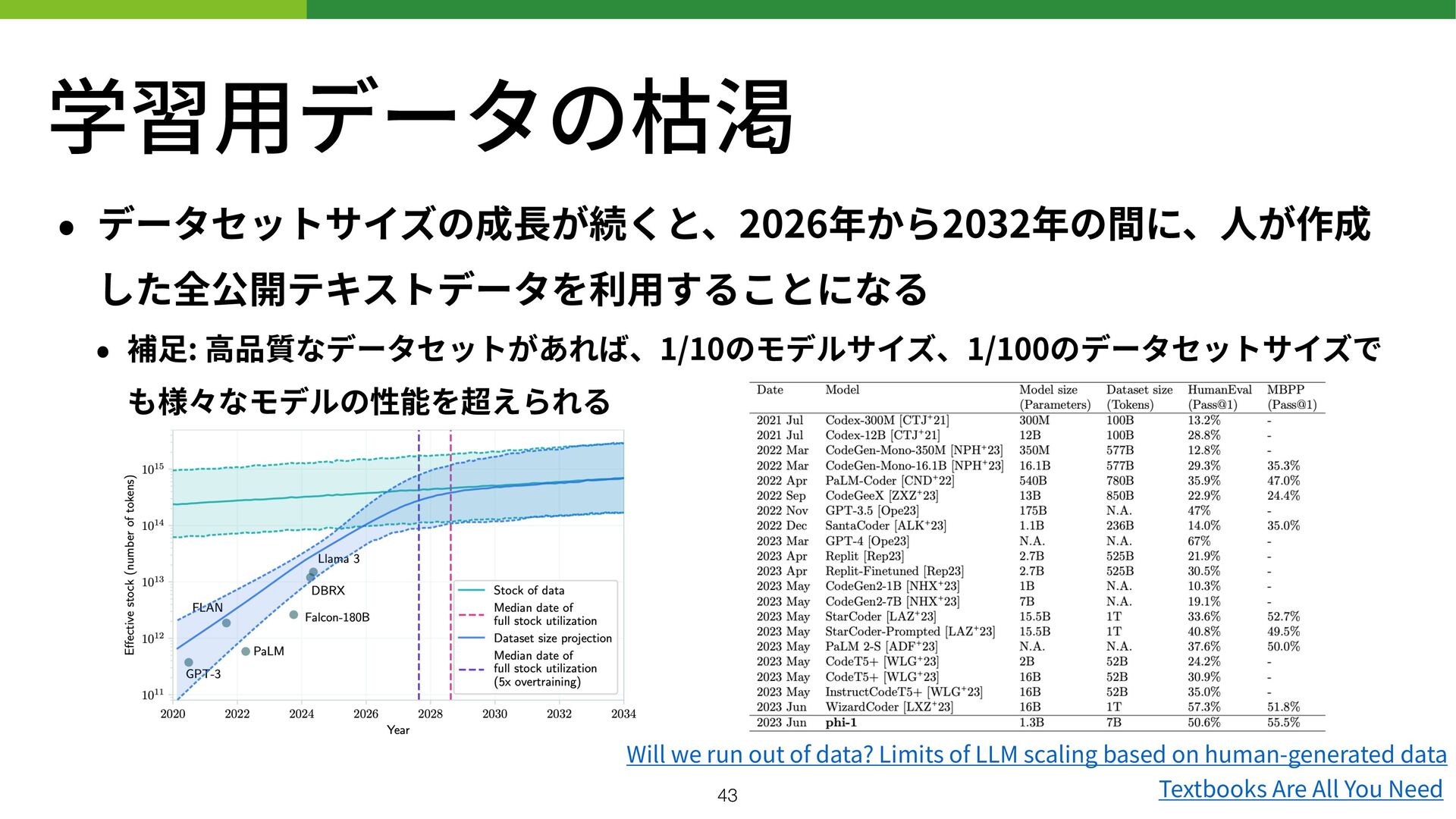
用 することになる • 補 足 : 高 品質なデータセットがあれば、1/10のモデルサイズ、1/100のデータセットサイズで も様々なモデルの性能を超えられる Will we run out of data? Limits of LLM scaling based on human-generated data Textbooks Are All You Need 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}