Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ふんわり理解するロジスティック回帰
Search
Yamamoto
June 05, 2024
Technology
95
0
Share
ふんわり理解するロジスティック回帰
所属する団体で使用予定のスライドです。
Yamamoto
June 05, 2024
More Decks by Yamamoto
See All by Yamamoto
DMMのインターンで Go言語はじめてみた
yamamotoeigo
0
180
ゼロから始めるニューラルネットワーク CNN編
yamamotoeigo
0
150
Other Decks in Technology
See All in Technology
RedmineをAIで効率的に使う検証
yoshiokacb
0
150
Loadbalancing exporter internals
ymotongpoo
1
120
The Bag-of-Documents Model for Query Understanding and Retrieval
dtunkelang
0
170
O'Reilly Infrastructure & Ops Superstream: Platform Engineering for Developers, Architects & the Rest of Us
syntasso
0
310
AI時代に、 データアナリストがデータエンジニアに異動して
jackojacko_
0
1.1k
"うちにはまだ早い"は本当? ─ 小さく始めるPlatform Engineering入門
harukasakihara
7
640
続 運用改善、不都合な真実 〜 物理制約のない運用改善はほとんど無価値 / 20260518-ssmjp-kaizen-no-value-without-physical-constraints
opelab
2
270
Pythonでベイズモデリング
soogie
0
140
【禁断】Obsidianの第二の脳に「知の巨人」と呼ばれた師匠の脳をロードしてみた
nagatsu
0
710
AWS運用におけるAI Agent活用術 / JAWS-UG 神戸 #11 LT大会
genda
1
310
なぜ、IAMロールのプリンシパルに*による部分マッチングが使えないのか? / 20260518-ssmjp-iam-role-principal
opelab
2
140
JaSSTに関わることで変わった人生観 #jasstnano
makky_tyuyan
0
160
Featured
See All Featured
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
380
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
10k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
300
The Invisible Side of Design
smashingmag
302
52k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.7k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.4k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
65
54k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
550
The Mindset for Success: Future Career Progression
greggifford
PRO
0
330
Game over? The fight for quality and originality in the time of robots
wayneb77
1
170
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
460
Transcript
ロジスティック回帰 総合理⼯学研究科エレクトロニクス系⼯学研究室 ⼤規模情報処理システム研究室 ⼭本 瑛悟
話すこと ロジスティック回帰について シグモイド関数について パラメータの最適化について
話すこと ロジスティック回帰について シグモイド関数について パラメータの最適化について
ロジスティック回帰とは ロジスティック回帰について • ロジスティック回帰は基本的にはニ値分類に使⽤される • 「回帰」と呼ばれているが実際は「分類」である。 回帰と分類 • 分類:離散値を出⼒する(クラスとかカテゴリとか) •
回帰:連続値を出⼒する(テストの点数とか売り上げとか)
線形回帰とロジスティック回帰 線形回帰とロジスティック回帰の⼤きな違い • 線形回帰:(連続値である)予測値を出⼒する • ロジスティック回帰:発⽣確率を出⼒する 例) 線形回帰:Aさんのテストの点数を予測 ロジスティック回帰:Aさんがテストに合格するかを予測
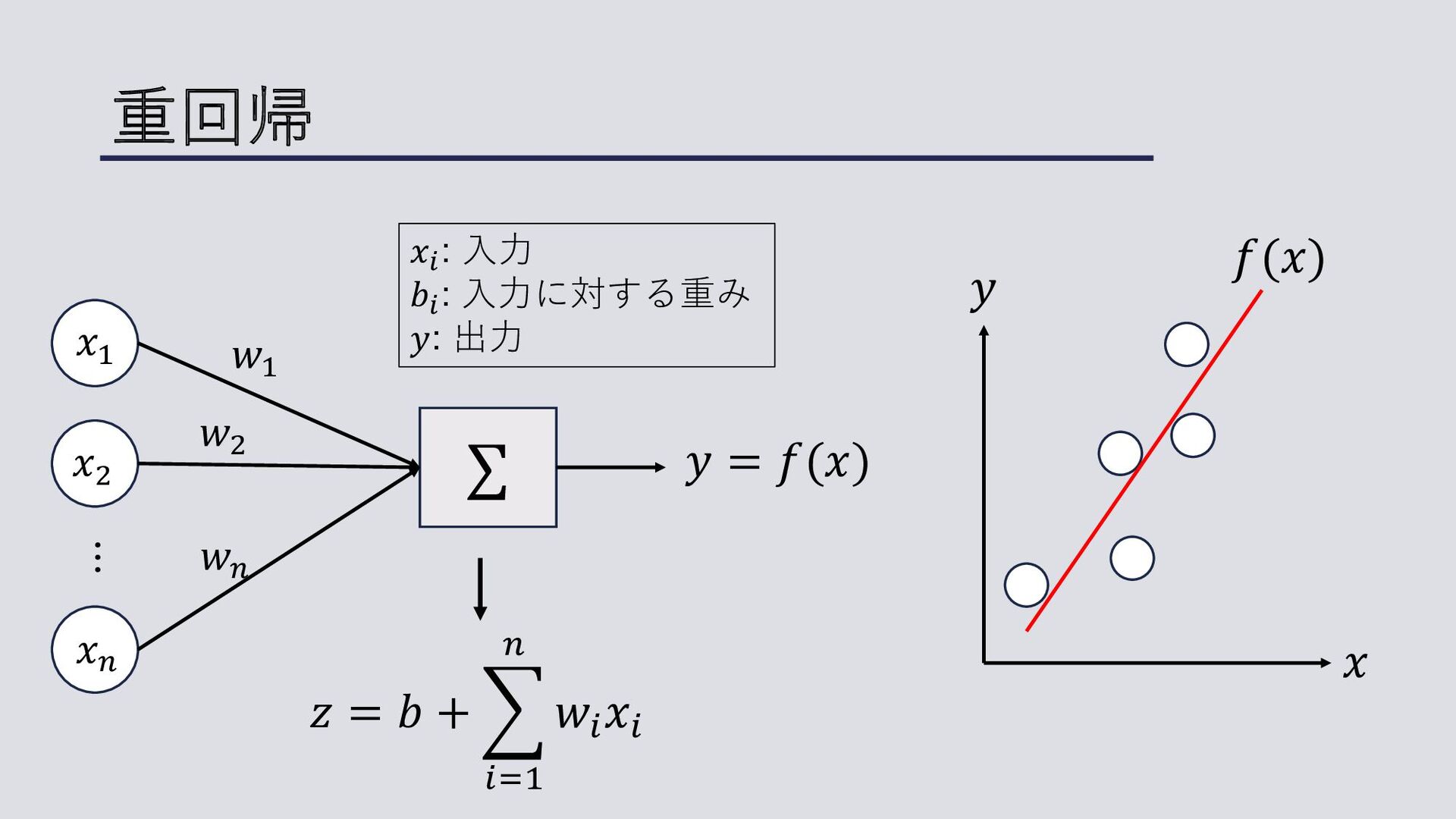
重回帰 ⋯ 𝑥! 𝑥" 𝑥# ∑ 𝑤" 𝑤! 𝑤# 𝑦
= 𝑓(𝑥) 𝑥! : ⼊⼒ 𝑏! : ⼊⼒に対する重み 𝑦: 出⼒ 𝑧 = 𝑏 + * !"# $ 𝑤! 𝑥! 𝑥 𝑦 𝑓(𝑥)
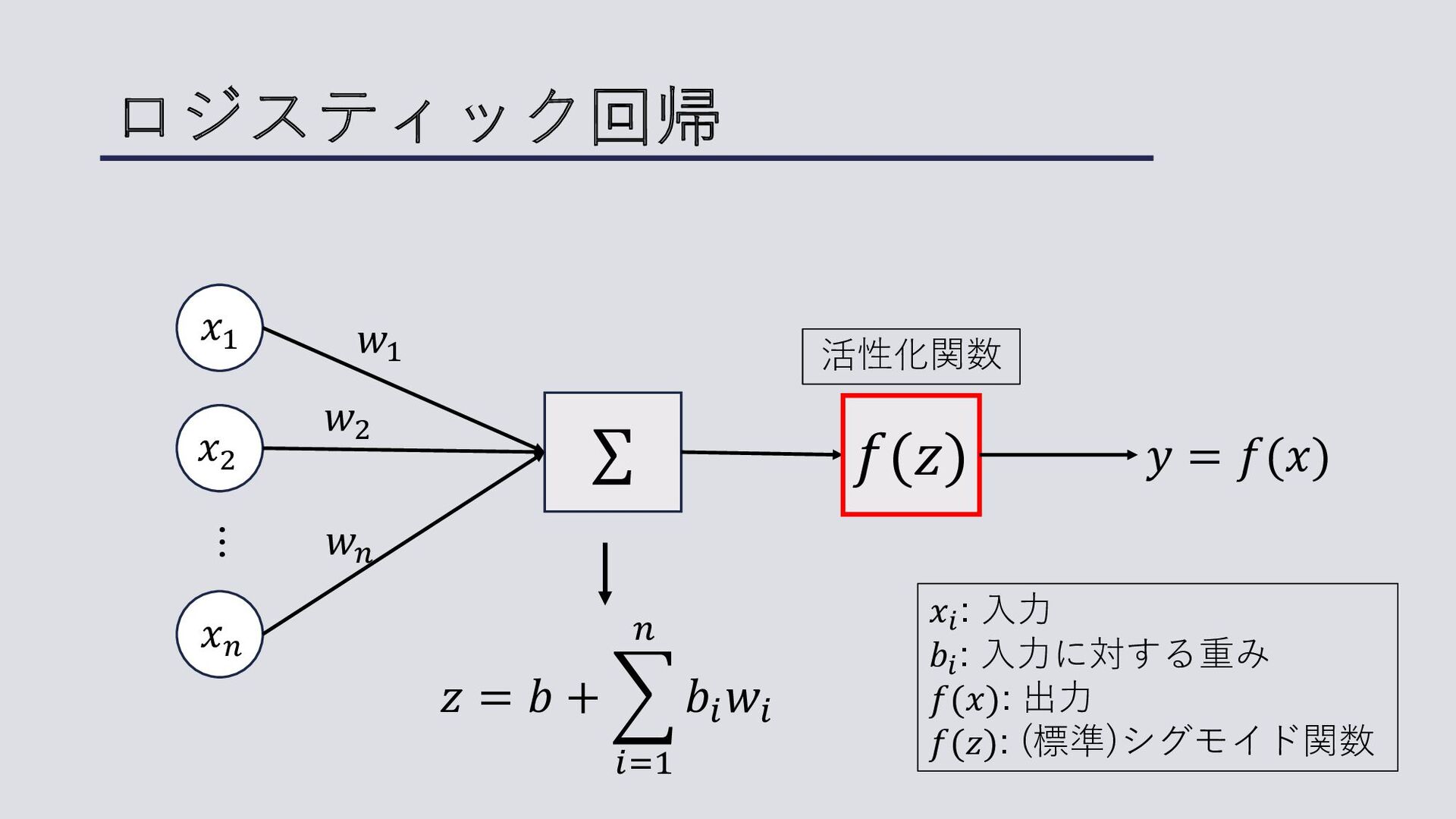
ロジスティック回帰 ⋯ 𝑥! 𝑥" 𝑥# ∑ 𝑤" 𝑤! 𝑤# 𝑦
= 𝑓(𝑥) 𝑥! : ⼊⼒ 𝑏! : ⼊⼒に対する重み 𝑓(𝑥): 出⼒ 𝑓(𝑧): (標準)シグモイド関数 𝑧 = 𝑏 + * !"# $ 𝑏! 𝑤! 𝑓(𝑧) 活性化関数
話すこと ロジスティック回帰について シグモイド関数について パラメータの最適化について
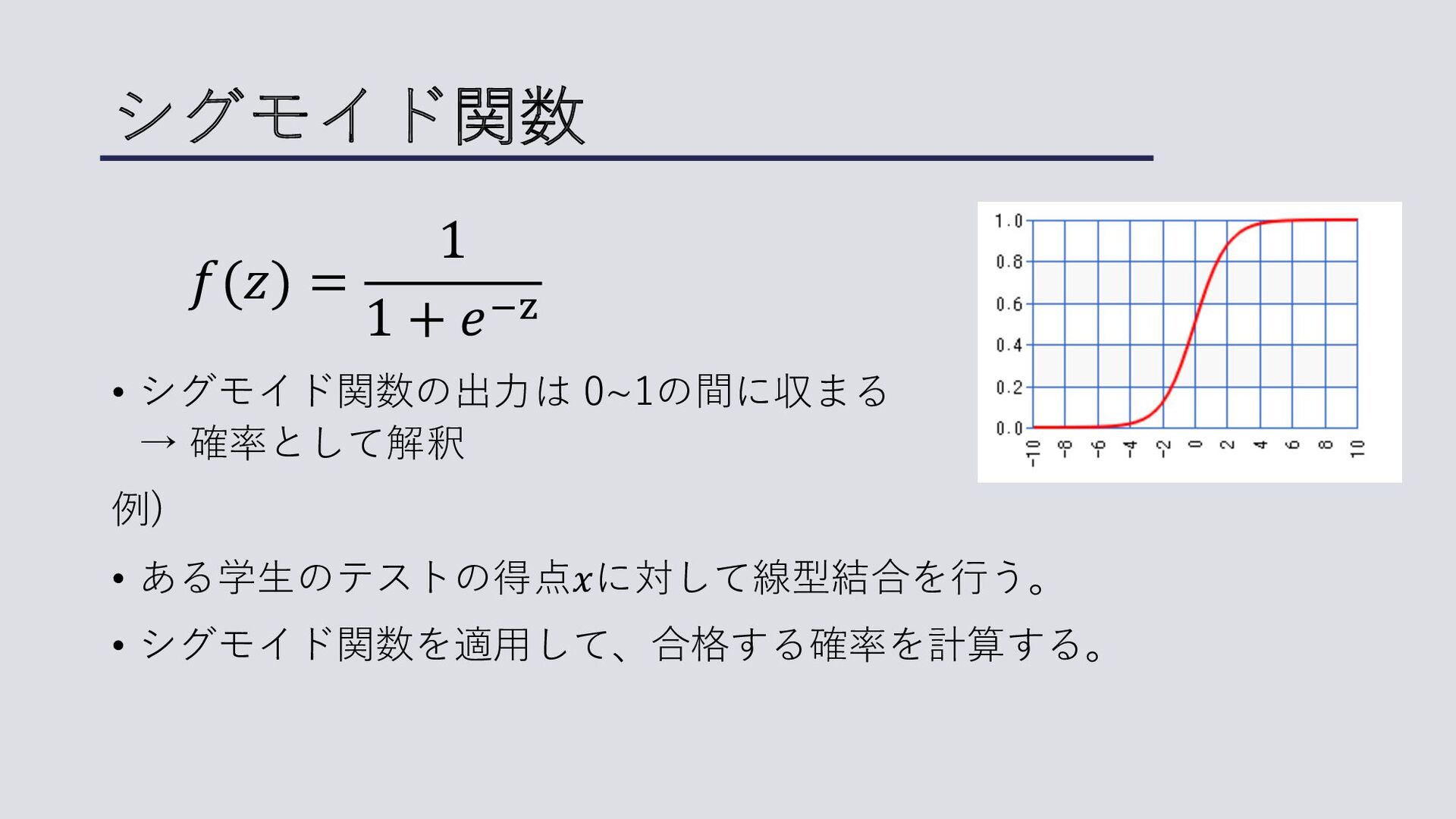
シグモイド関数 • シグモイド関数の出⼒は 0~1の間に収まる → 確率として解釈 例) • ある学⽣のテストの得点𝑥に対して線型結合を⾏う。 •
シグモイド関数を適⽤して、合格する確率を計算する。 𝑓(𝑧) = 1 1 + 𝑒"#
シグモイド関数の理解 オッズ • ある事象が起こる確率と起こらない確率の⽐ → ある事象の起こりやすさ • 事象が起こる確率を𝑝とした場合以下の式で表される 𝑝 1
− 𝑝
シグモイド関数の理解 試験の合否のオッズを考える。 試験に合格:𝑝 試験に不合格:1 − 𝑝 𝑝 1 − 𝑝
合格数 1 8 不合格数 8 1 オッズ 0.125 𝟏 𝟖 8
シグモイド関数の理解 試験の合否のオッズを考える。 試験に合格:𝑝 試験に不合格:1 − 𝑝 𝑝 1 − 𝑝
合格数 1 8 不合格数 8 1 オッズ 0.125 𝟏 𝟖 8 1 2 < 𝑝 0 ≤ 𝑝 ≤ 1 2 :(1, +∞) : [0, 1]
シグモイド関数の理解 ロジット変換(ロジット関数) 𝑦 = log 𝑝 1 − 𝑝 •
対数関数を使うと尺度を合わせることができる → 対数を取ると対称性が出るので⽐較しやすくなる 勝利数 1 8 敗北数 8 1 ロジット 関数 -2.0794 2.0794
線形回帰とロジスティック回帰 線形回帰とロジスティック回帰の⼤きな違い • 線形回帰:(連続値である)予測値を出⼒する • ロジスティック回帰:発⽣確率を出⼒する 例) 線形回帰:Aさんのテストの点数を予測 ロジスティック回帰:Aさんがテストに合格するかを予測
(標準)シグモイド関数の理解 ロジット関数の逆関数を取る 𝑦 = log 𝑝 1 − 𝑝 𝑒%
= 𝑝 1 − 𝑝 (1 − 𝑝)𝑒% = 𝑝
(標準)シグモイド関数の理解 𝑦 = log 𝑝 1 − 𝑝 𝑒$ =
𝑝 1 − 𝑝 (1 − 𝑝)𝑒$ = 𝑝 𝑒% = 𝑝(1+𝑒%) 𝑝 = 𝑒% 1 + 𝑒% 𝑝 = 𝑒% 3 𝑒&% 1 3 𝑒&% + 𝑒% 3 𝑒&% 𝑝 = 1 𝑒&% + 1
話すこと ロジスティック回帰について シグモイド関数について パラメータの最適化について
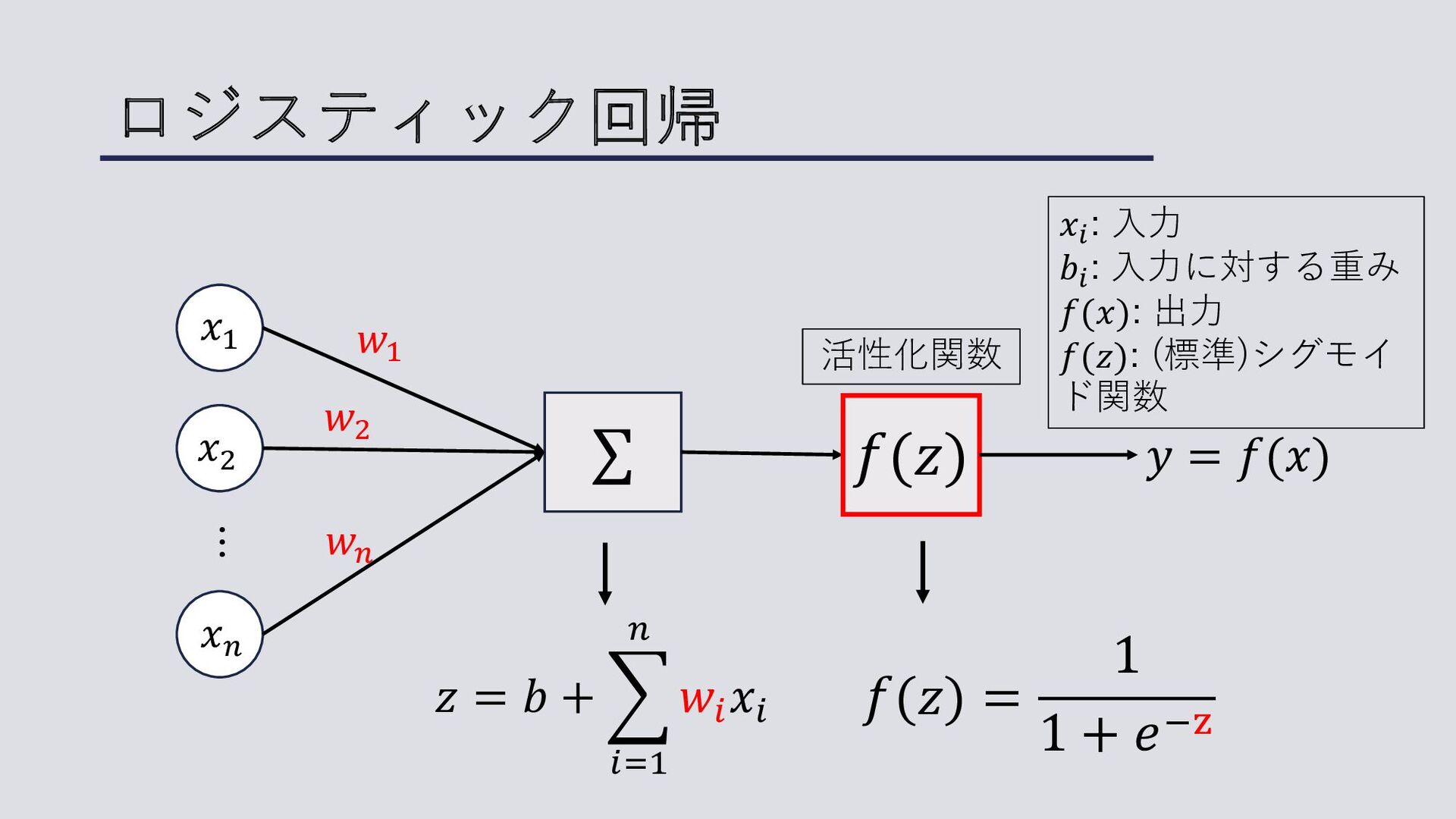
ロジスティック回帰 ⋯ 𝑥! 𝑥" 𝑥# ∑ 𝑤" 𝑤! 𝑤# 𝑦
= 𝑓(𝑥) 𝑥! : ⼊⼒ 𝑏! : ⼊⼒に対する重み 𝑓(𝑥): 出⼒ 𝑓(𝑧): (標準)シグモイ ド関数 𝑧 = 𝑏 + * !"# $ 𝑤! 𝑥! 𝑓(𝑧) 活性化関数 𝑓(𝑧) = 1 1 + 𝑒"#
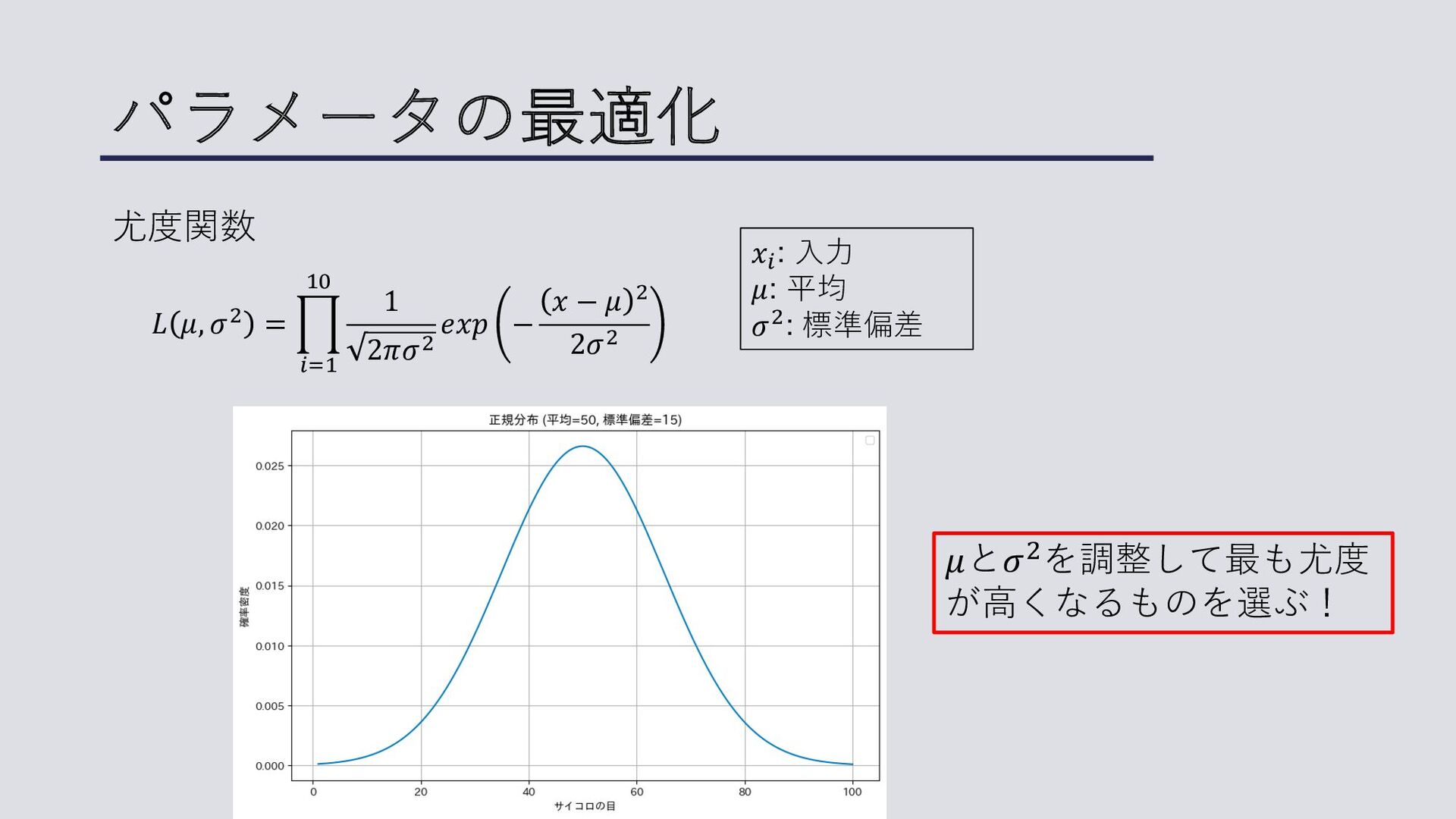
パラメータの最適化 • ロジスティック回帰では最尤推定法を⽤いる。 • 最尤推定法は確率論的モデルのパラメータを変化させて、観測デー タにもっともよくあてはまるところを探索する⼿法。 例) • 1~100の実数の⽬が出る不思議なサイコロを10回降る •
正規分布に従うと仮定 • このサイコロはどんな⽬を出しやすい?出しにくい?
パラメータの最適化 𝑓 𝑥 = 1 2𝜋𝜎! 𝑒𝑥𝑝 − 𝑥 −
𝜇 ! 2𝜎! 正規分布の確率密度関数 𝑥! : ⼊⼒ 𝜇: 平均 𝜎$: 標準偏差 𝐿 𝜇, 𝜎! = 9 %&" "' 1 2𝜋𝜎! 𝑒𝑥𝑝 − 𝑥% − 𝜇 ! 2𝜎! 尤度関数
パラメータの最適化 𝑥! : ⼊⼒ 𝜇: 平均 𝜎": 標準偏差 𝐿 𝜇,
𝜎" = . !#$ $% 1 2𝜋𝜎" 𝑒𝑥𝑝 − 𝑥 − 𝜇 " 2𝜎" 尤度関数 𝜇と𝜎$を調整して最も尤度 が⾼くなるものを選ぶ!
シグモイド関数の理解 オッズ • ある事象が起こる確率と起こらない確率の⽐ → ある事象の起こりやすさ • 事象が起こる確率を𝑝とした場合以下の式で表される 𝑝 1
− 𝑝
(標準)シグモイド関数の理解 𝑦 = log 𝑝 1 − 𝑝 𝑒$ =
𝑝 1 − 𝑝 (1 − 𝑝)𝑒$ = 𝑝 𝑒% = 𝑝(1+𝑒%) 𝑝 = 𝑒% 1 + 𝑒% 𝑝 = 𝑒% 3 𝑒&% 1 3 𝑒&% + 𝑒% 3 𝑒&% 𝑝 = 1 𝑒&% + 1
最尤推定法 𝐿 𝑤, 𝑏 = & !"# $ 𝑝 !
%% 1 − 𝑝! #&%% 尤度関数 𝑥! : ⼊⼒ 𝑦! : ⼊⼒{0, 1} 𝑝! : シグモイド関数の出⼒ log 𝐿 𝑤, 𝑏 = log & !"# $ 𝑝 ! %% 1 − 𝑝! #&%% log 𝐿 𝑤, 𝑏 = - !"# $ 𝑦! log 𝑝! − 1 − 𝑦! log 1 − 𝑝! (ロジスティック回帰はベルヌーイ分布を仮定)
最尤推定法 • パラメータがどれだけモデルを説明できているか → モデルの予測が実際のラベルからどれだけ離れているか • クロスエントロピー誤差と呼ばれる。 • 解析的に解くことができない 𝐽
𝑤, 𝑏 = − log 𝐿 𝑤, 𝑏 = − - !"# $ 𝑦! log 𝑝! − 1 − 𝑦! log 1 − 𝑝!
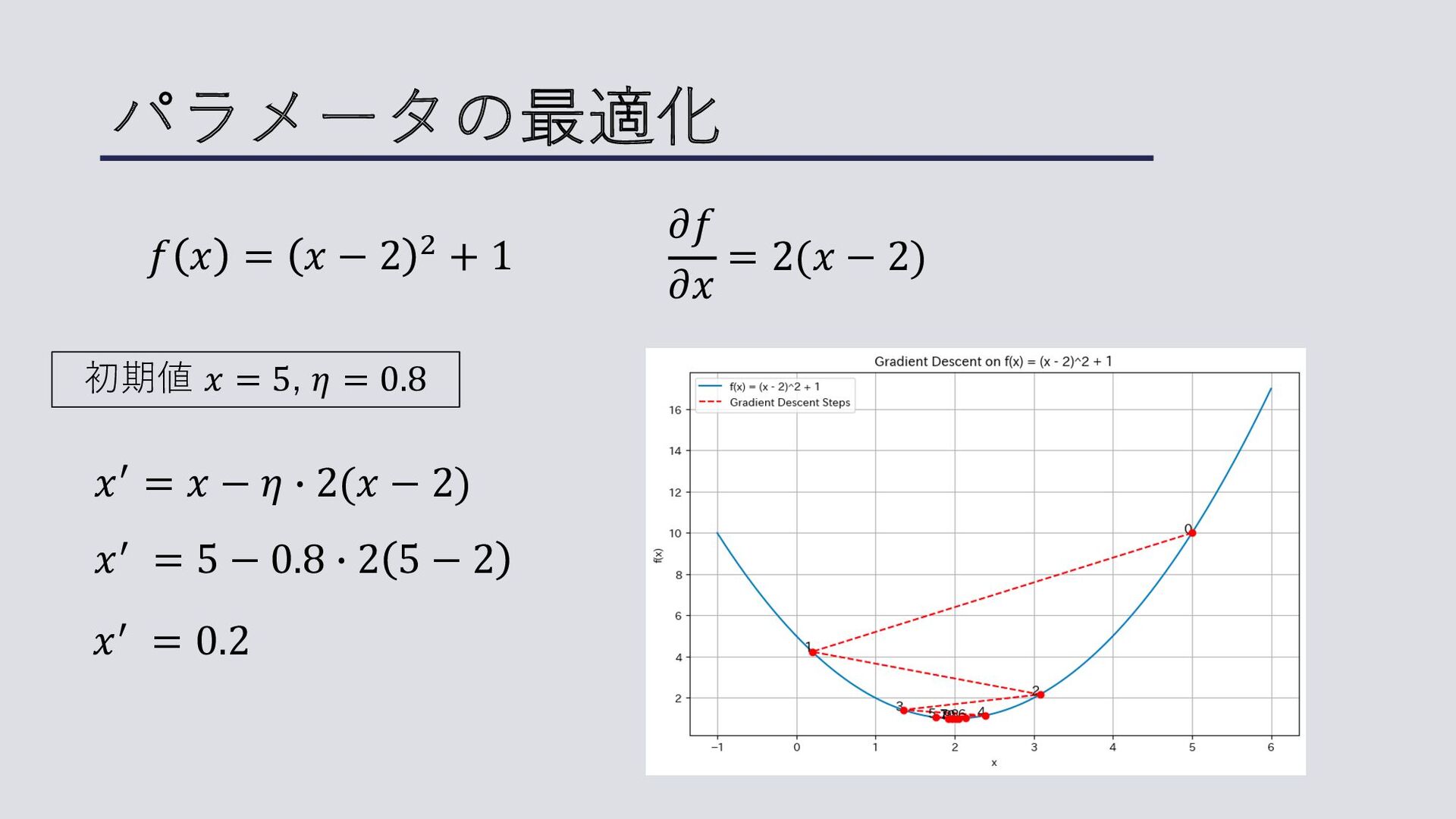
パラメータの最適化 前スライドの式は解析的に解けない → 勾配降下法などの数値解析的なアプローチ 勾配降下法 • ⽬的関数の勾配(微分)を利⽤して、関数が最も急速に減少する⽅ 向を探索するアプローチ • 最急降下法
• SGD • Adam
パラメータの最適化 最適化したいパラメータは 𝑤, 𝑏の⼆つなのでそれぞれについて微分する。 𝐽 𝑤, 𝑏 = − <
%&" # 𝑦% log 𝑝% − 1 − 𝑦% log 1 − 𝑝% 𝑤 ≔ 𝑤 − 𝜂 𝜕𝐽 𝜕𝑤 𝑏 ≔ 𝑏 − 𝜂 𝜕𝐽 𝜕𝑏 𝜂: 学習率
パラメータの最適化 𝑓 𝑥 = 𝑥 − 2 ! + 1
𝜕𝑓 𝜕𝑥 = 2(𝑥 − 2) 初期値 𝑥 = 5, 𝜂 = 0.8 𝑥5 = 𝑥 − 𝜂 A 2(𝑥 − 2) 𝑥5 = 5 − 0.8 A 2 5 − 2 𝑥5 = 0.2
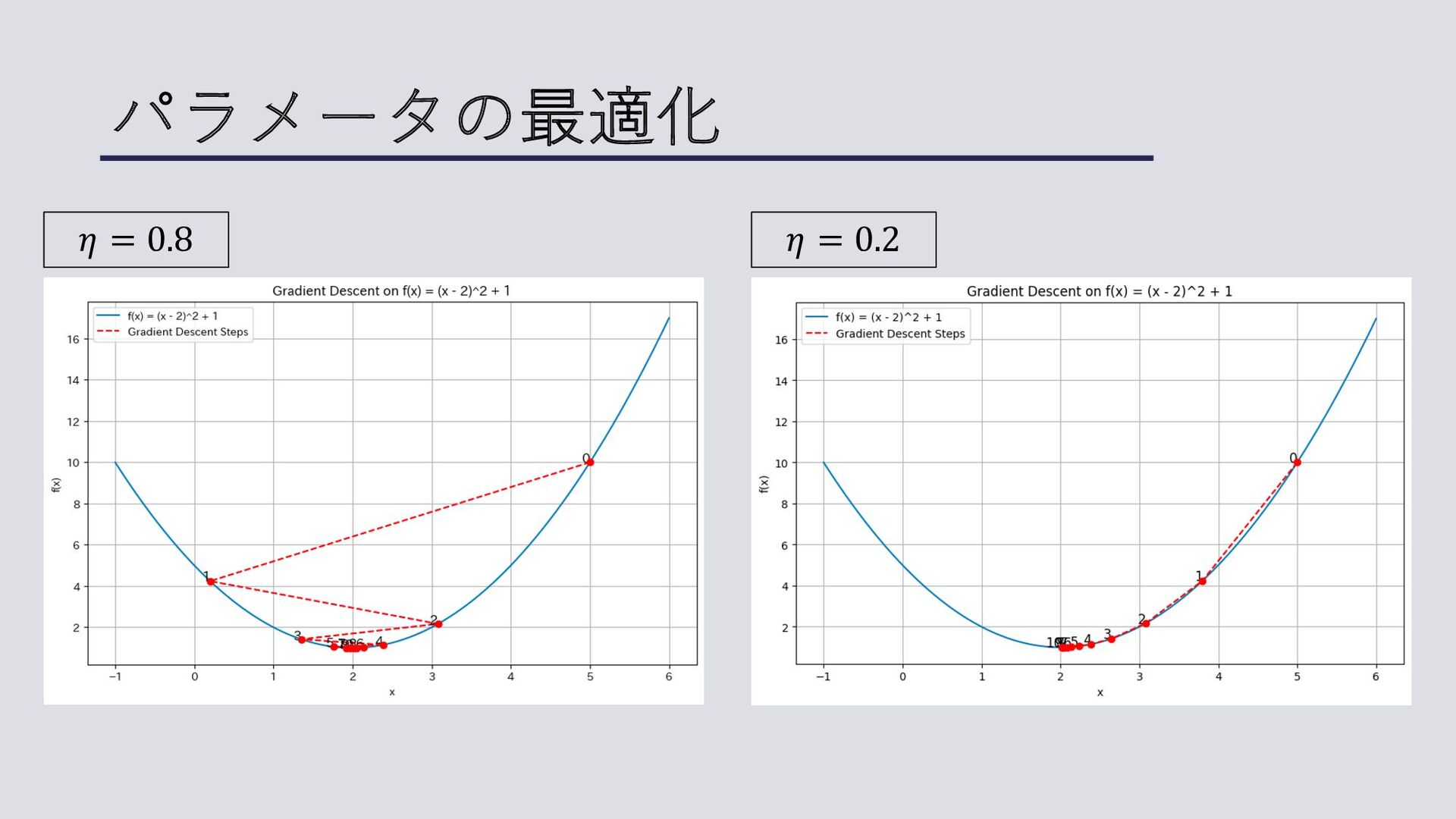
パラメータの最適化 𝜂 = 0.8 𝜂 = 0.2
おわり おさらい • ロジスティック回帰は確率を出⼒する。 → シグモイド関数によって0~1の実数値を出⼒ • 最尤推定法、勾配降下法を⽤いてパラメータを最適化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}