Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ゼロから始めるニューラルネットワーク CNN編
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Yamamoto
June 05, 2024
Technology
150
0
Share
ゼロから始めるニューラルネットワーク CNN編
KC3 2023の学生勉強会に登壇した際に使用したスライドです。
Yamamoto
June 05, 2024
More Decks by Yamamoto
See All by Yamamoto
DMMのインターンで Go言語はじめてみた
yamamotoeigo
0
180
ふんわり理解するロジスティック回帰
yamamotoeigo
0
95
Other Decks in Technology
See All in Technology
Redmine次期バージョン7.0の注目新機能解説 — UI/UX強化と連携強化を中心に
vividtone
1
190
20260516_SecJAWS_Days
takuyay0ne
2
520
Gaussian Splattingの実用化 - 映像制作への展開
gpuunite_official
0
200
キャリア25年目にしてTypeScript に出会うまで - 「型」を通じて振り返るプログラミング言語遍歴 / Meeting TypeScript After 25 Years in Tech - Looking Back at My Programming Language Journey Through "Types"
bitkey
PRO
1
110
ECSのTerraformモジュールにコントリビュートした話
harukasakihara
0
250
Swift Sequence の便利 API 再発見
treastrain
1
290
実践 TanStack Start ― 新規プロダクトを開発して確立した、サーバーとクライアント境界の設計パターン / Practical TanStack Start Server-Client Boundary Patterns
kaminashi
1
130
How to learn AWS Well-Architected with AWS BuilderCards: Security Edition
coosuke
PRO
0
180
Claude Code / Codex / Kiro に AWS 権限を 渡すとき、何を設計すべきか
k_adachi_01
6
1.9k
20260515 ⾃分のアカウントとプライバシーを守る認証と認可の話〜利⽤者向け〜
oidfj
0
800
SpeechTranscriber + AIによる文字起こし機能
kazuki1220
0
120
【関西製造業祭り2026春】現場を変える技術はここまで来た〜世界最大の製造業見本市から持って帰ってきたもの〜
tanakaseiya
0
190
Featured
See All Featured
A Soul's Torment
seathinner
6
2.8k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
240
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
360
Color Theory Basics | Prateek | Gurzu
gurzu
0
310
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.4k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
560
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.4k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
200
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
400
It's Worth the Effort
3n
188
29k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Statistics for Hackers
jakevdp
799
230k
Transcript
ゼロから始める ニューラルネットワーク CNN編 KINDAI Info-Tech HUB ⼭本 瑛悟
始める前に • 勉強会中たびたび質問します(HTTP 200 OK) • スライドのこの⾊の単語・⽂章はぜひメモを︕ • 時間の都合上勉強会中は質問受け付けられないかも •
トイレや具合が悪くなった⼈は何も⾔わず⾏って頂いて⼤丈夫で す︕ • つまらねえなと思ったら寝るかYouTubeとかみててください
⽬次 • ⾃⼰紹介 • ニューラルネットワークの概要 • ニューラルネットワークの基礎 ~休憩~ • CNNの仕組み
• やってみよう ~説明編~ • やってみよう ~ハンズオン編~ 座学: 約60分 ハンズオン: 約30分
⾃⼰紹介 • 名前: ⼭本 瑛悟 • 所属: 近畿⼤学理⼯学部情報学科 • 団体:
KINDAI Info-Tech HUB/CSG • 学年: 学部4年 • 専⾨: ⼤規模ニューラルネットワークの分散処理 • やってたこと: web系, 深層学習, 強化学習, 深層強化学習 • ひとこと: はやおきつらい
ニューラルネットワークの概要 キーワード: 線形分類、⾮線形分類、パーセプトロン、ニューラルネットワーク
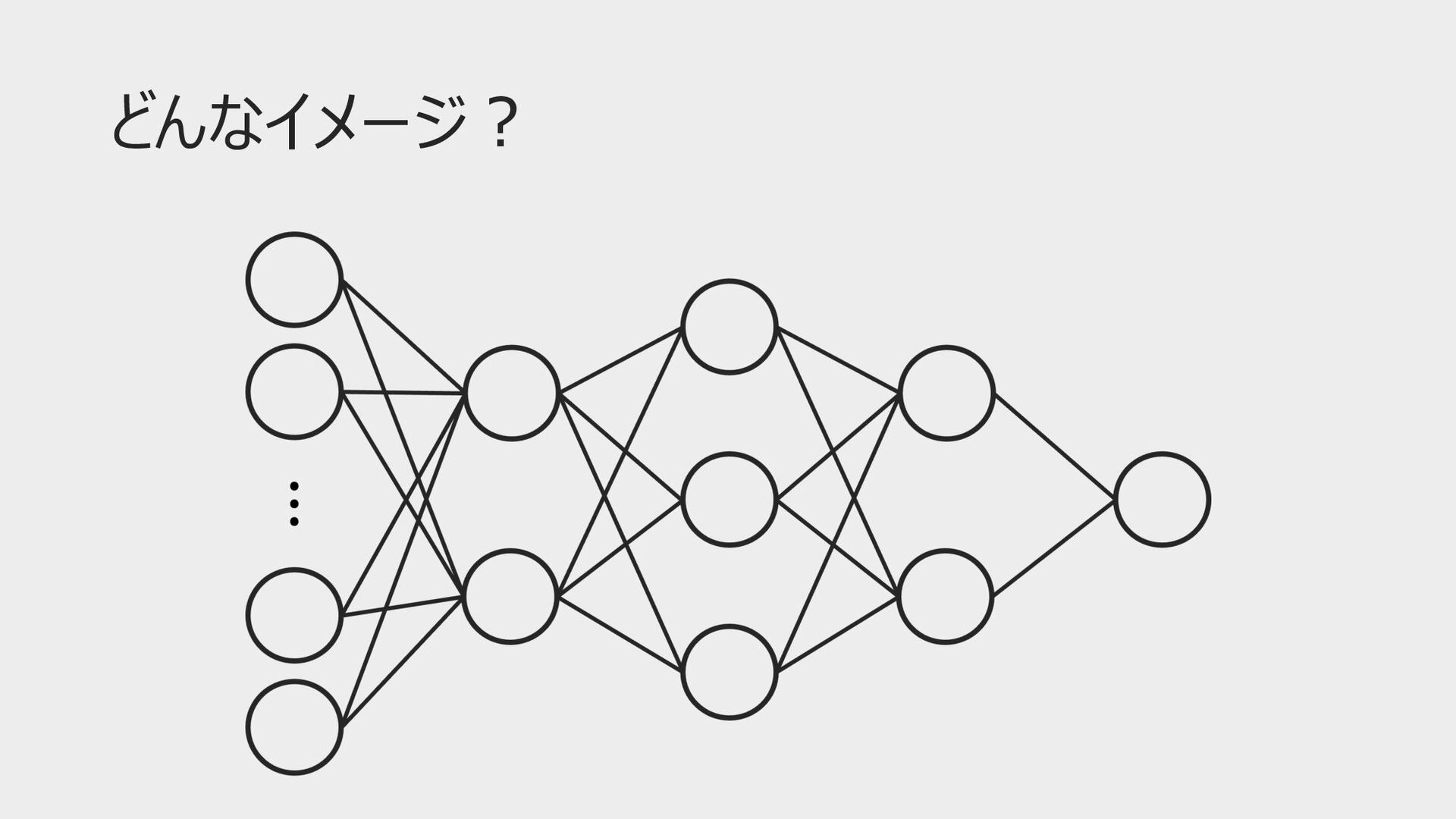
どんなイメージ︖
どんなイメージ︖ • ブラックボックス… • なんか胡散臭い • なんでもできる万能さん • かわいい •
なんもわからん • 完璧で究極のアイドル
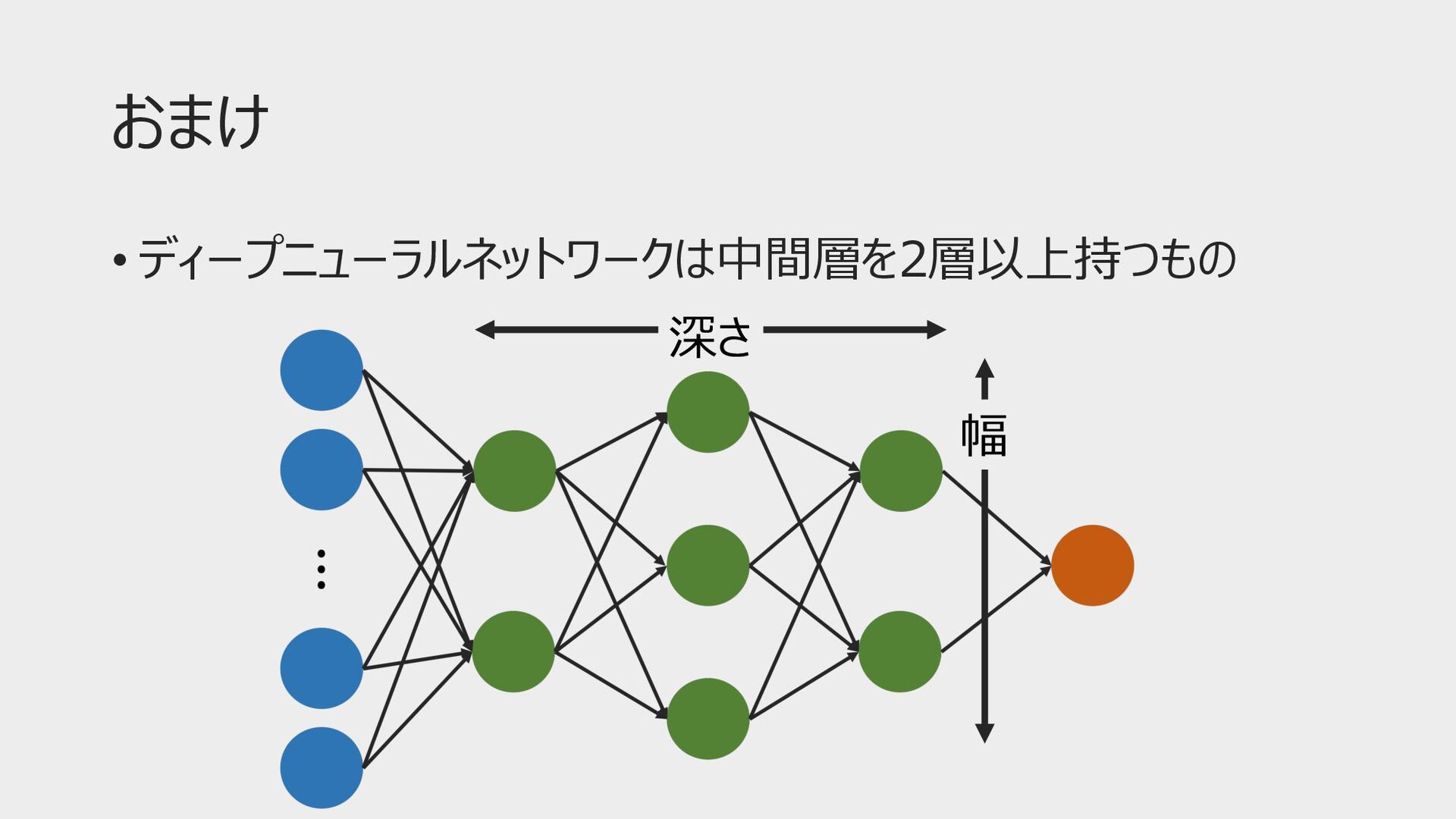
ニューラルネットワークの種類(⼀部) • ディープニューラルネットワーク • 畳み込みニューラルネットワーク(CNN): 画像認識・分類 • 再帰型ニューラルネットワーク: 系列データ •
グラフニューラルネットワーク: グラフ構造のデータ • 敵対的⽣成ネットワーク(GAN): データ⽣成
ニューラルネットワークの概要 • ニューラルネットワークって何︖ → ⼀⾔で表すと
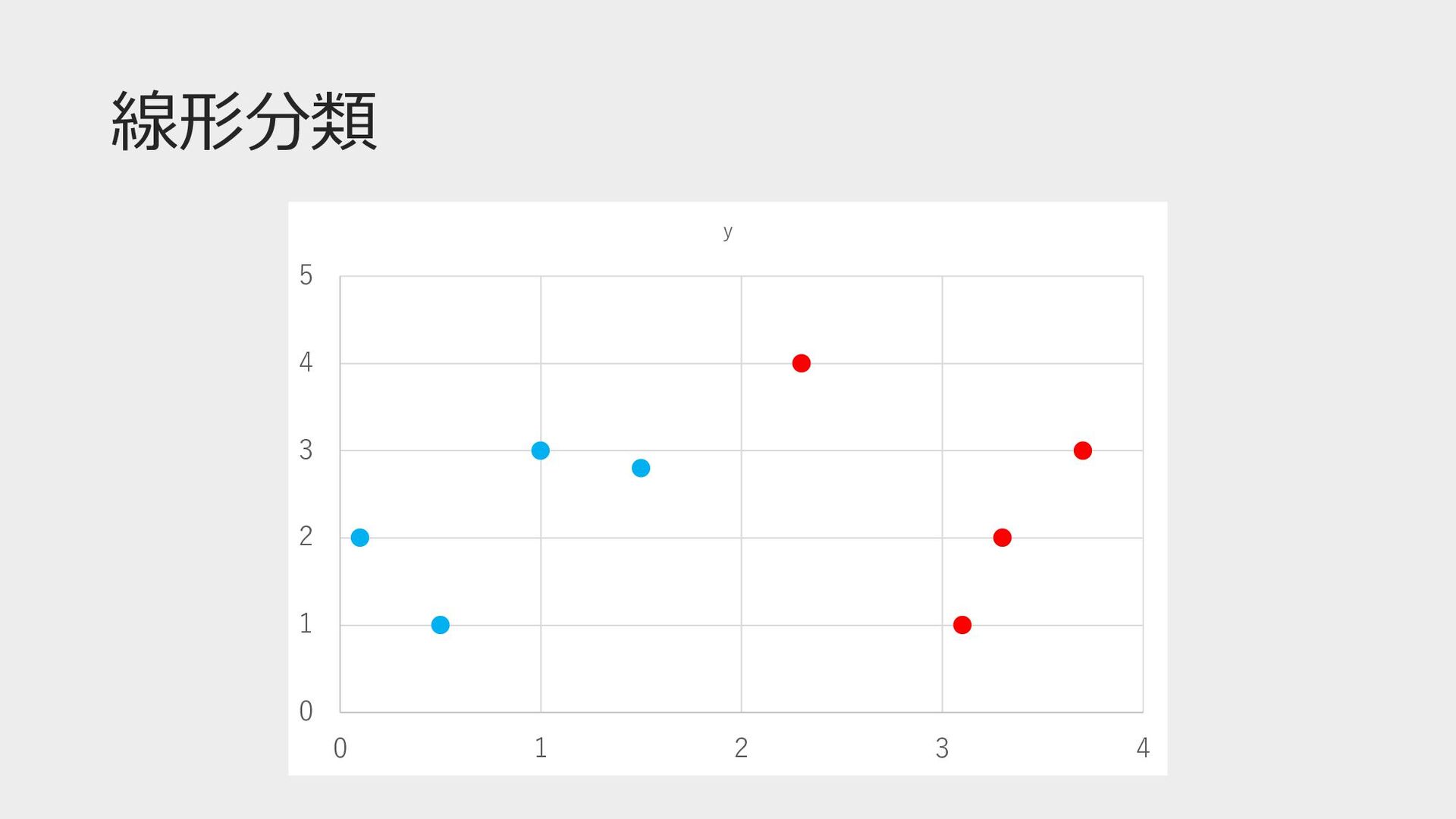
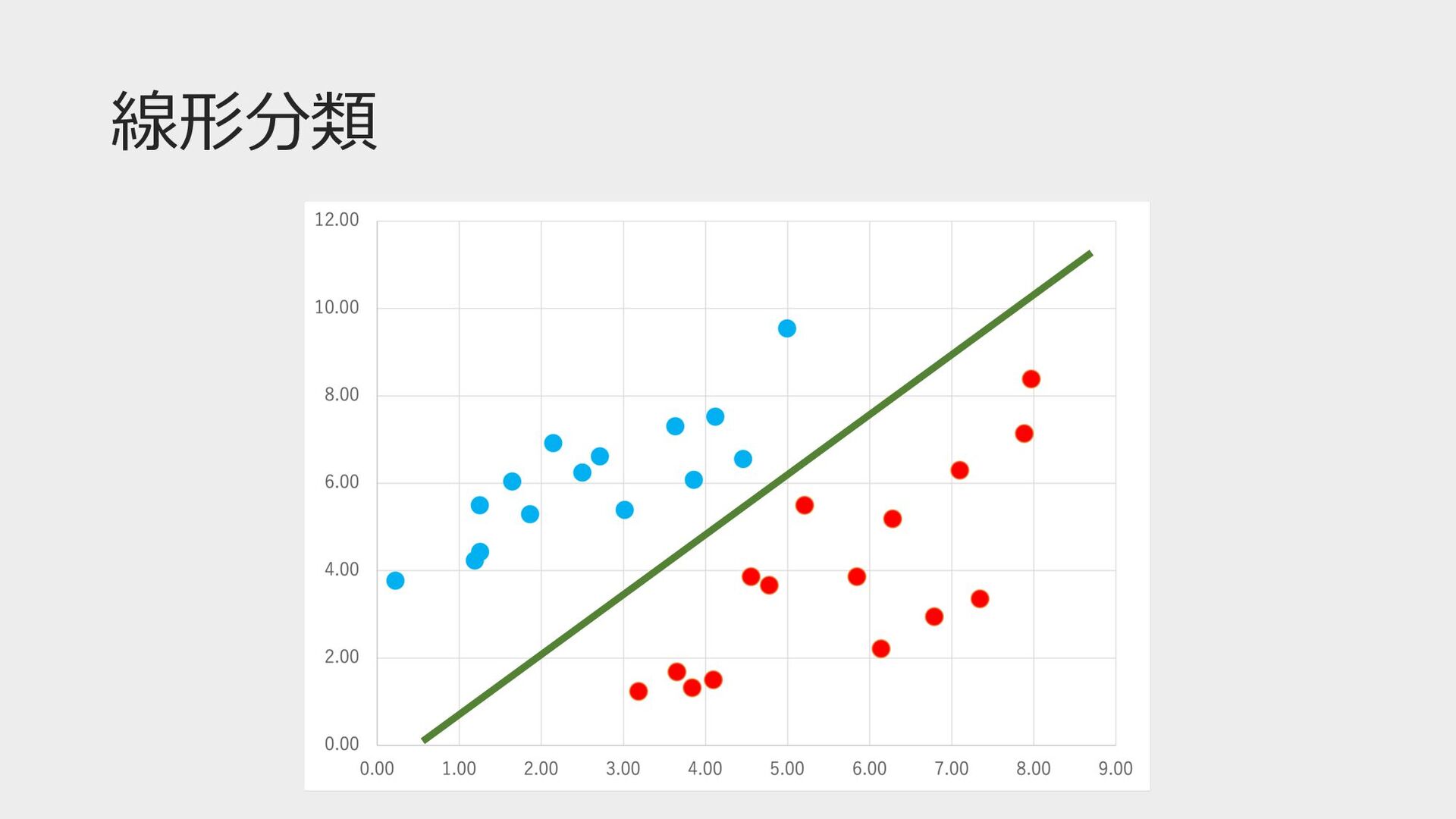
線形分類 0 1 2 3 4 5 0 1 2
3 4 y
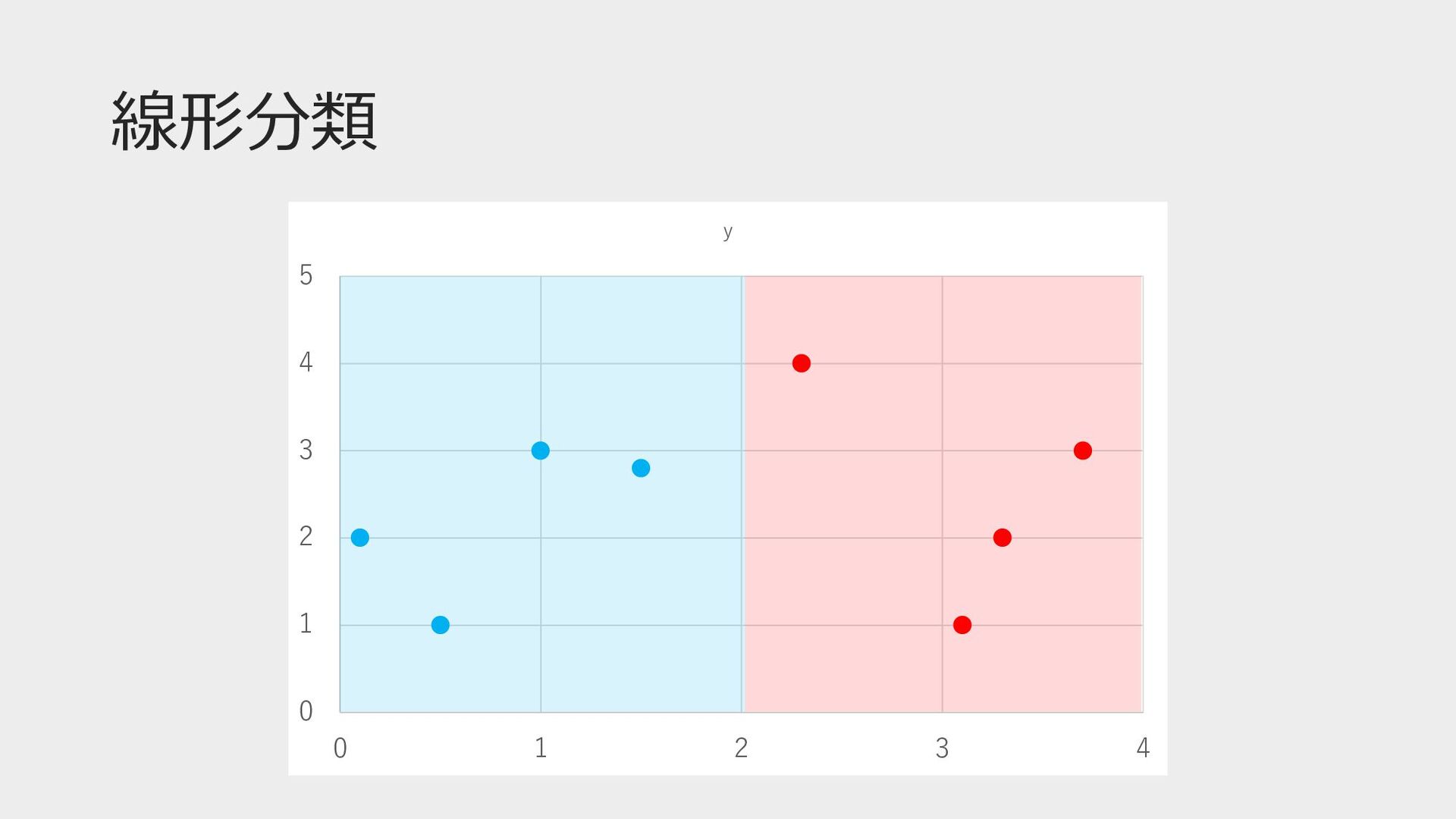
線形分類 0 1 2 3 4 5 0 1 2
3 4 y
線形分類
パーセプトロン • 1958年: ローゼンブラットが提案 • 事前に決められた出⼒(学習データ)を実現するためのパラメータ (重み)を⼊⼒に合わせて最急降下法で推定 • ニューラルネットワークの元となったアイデア(後ほど説明)
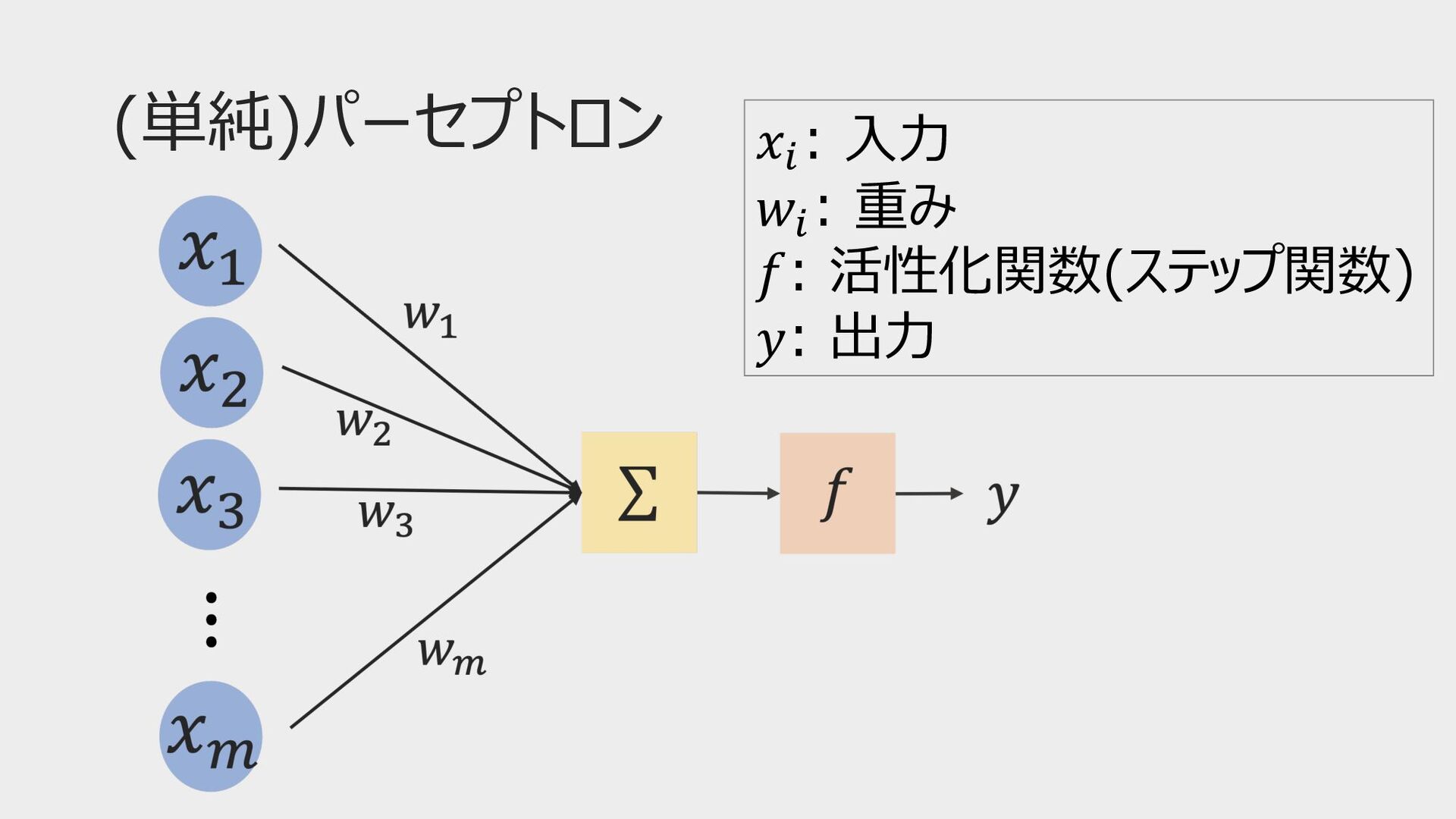
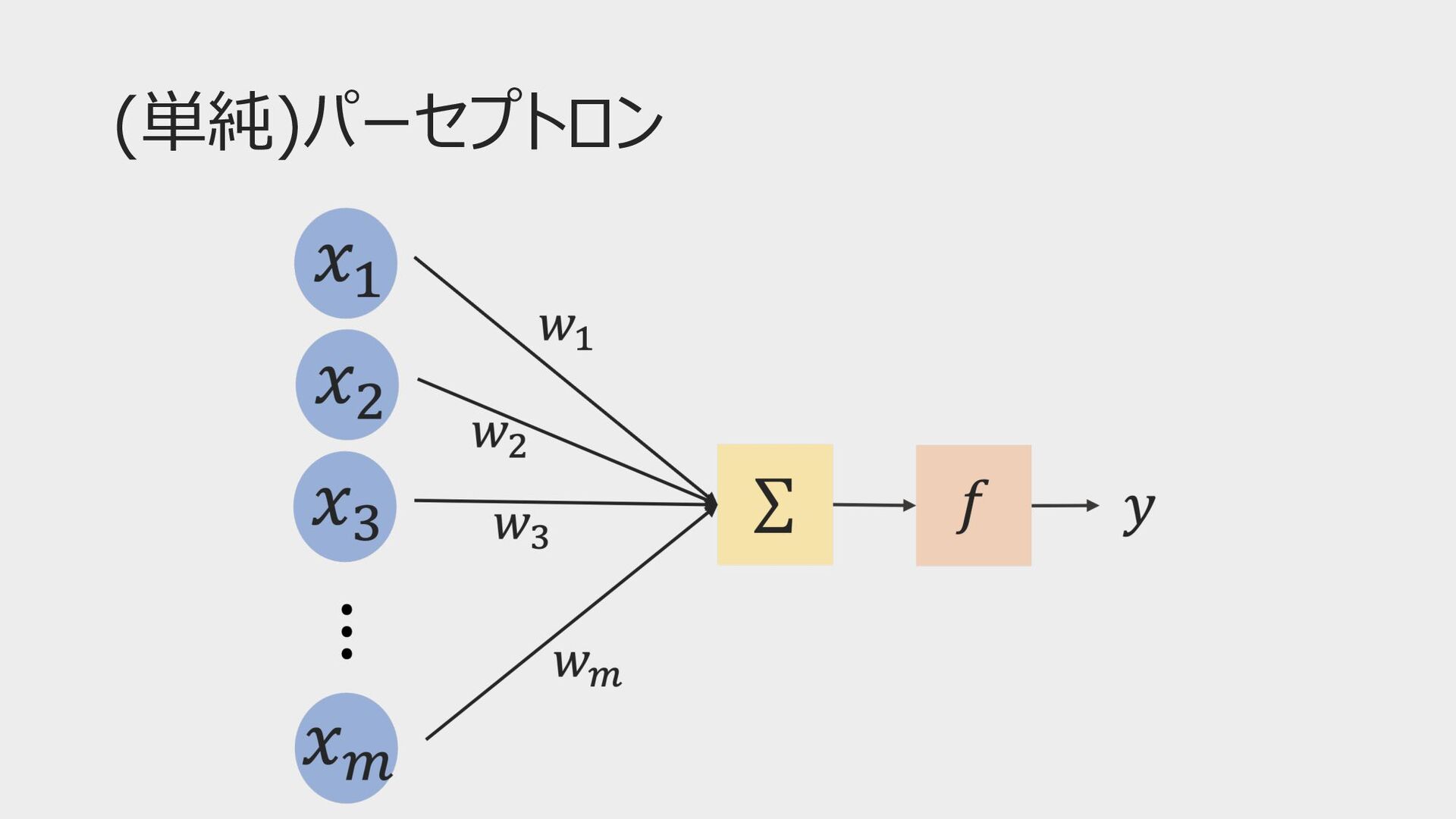
(単純)パーセプトロン 𝑥! : ⼊⼒ 𝑤! : 重み 𝑓: 活性化関数(ステップ関数) 𝑦:
出⼒
線形分類
ロジスティック回帰との違い(分からなくてもおk) • パーセプトロンはロジスティック回帰とほぼ等価と批判を受けた • 活性化関数(後ほど説明) • パーセプトロン: ステップ関数 → 0と1の⼆値の出⼒
• ロジスティック回帰: シグモイド関数 → 0~1の間の確率的な出⼒
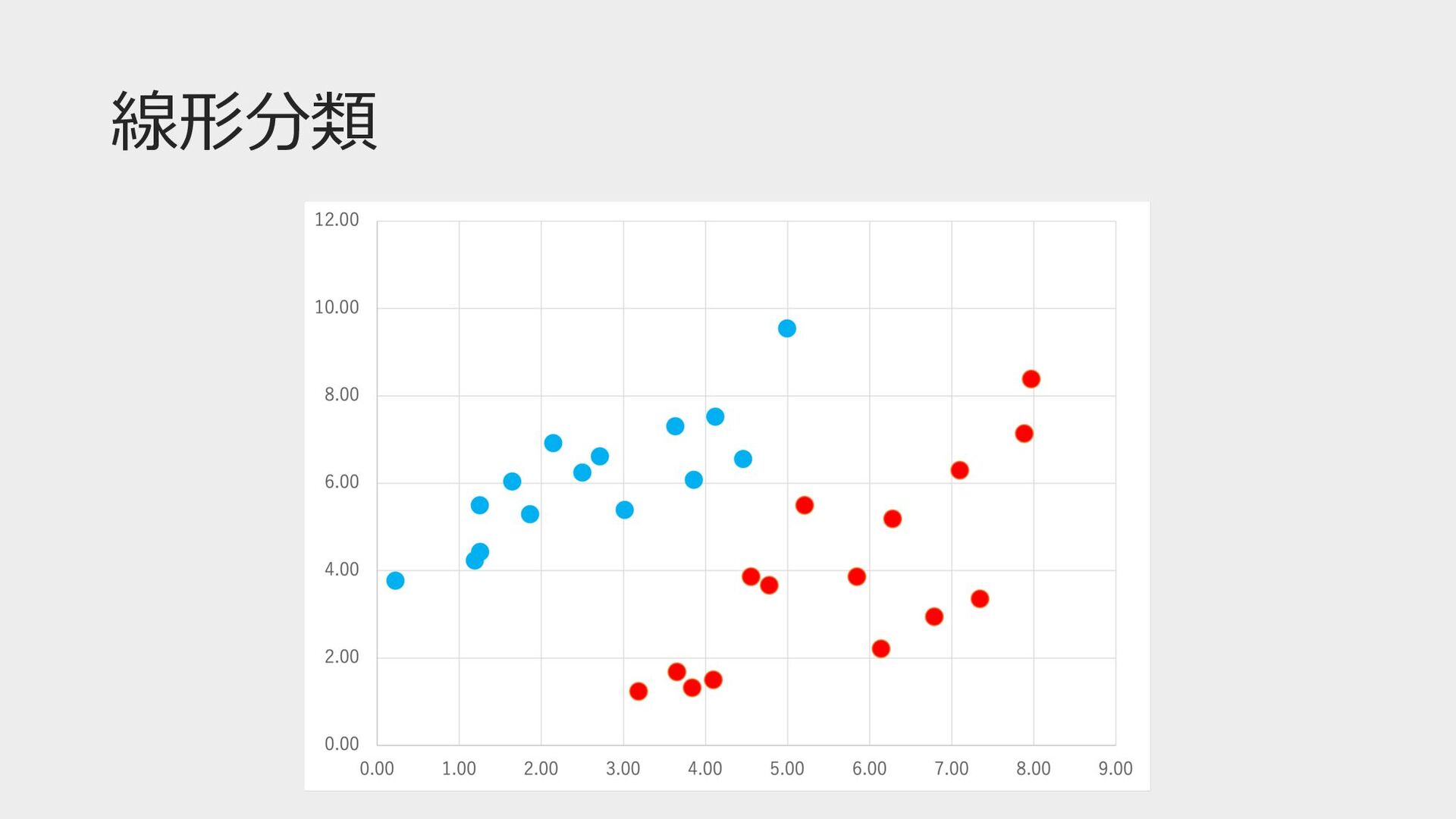
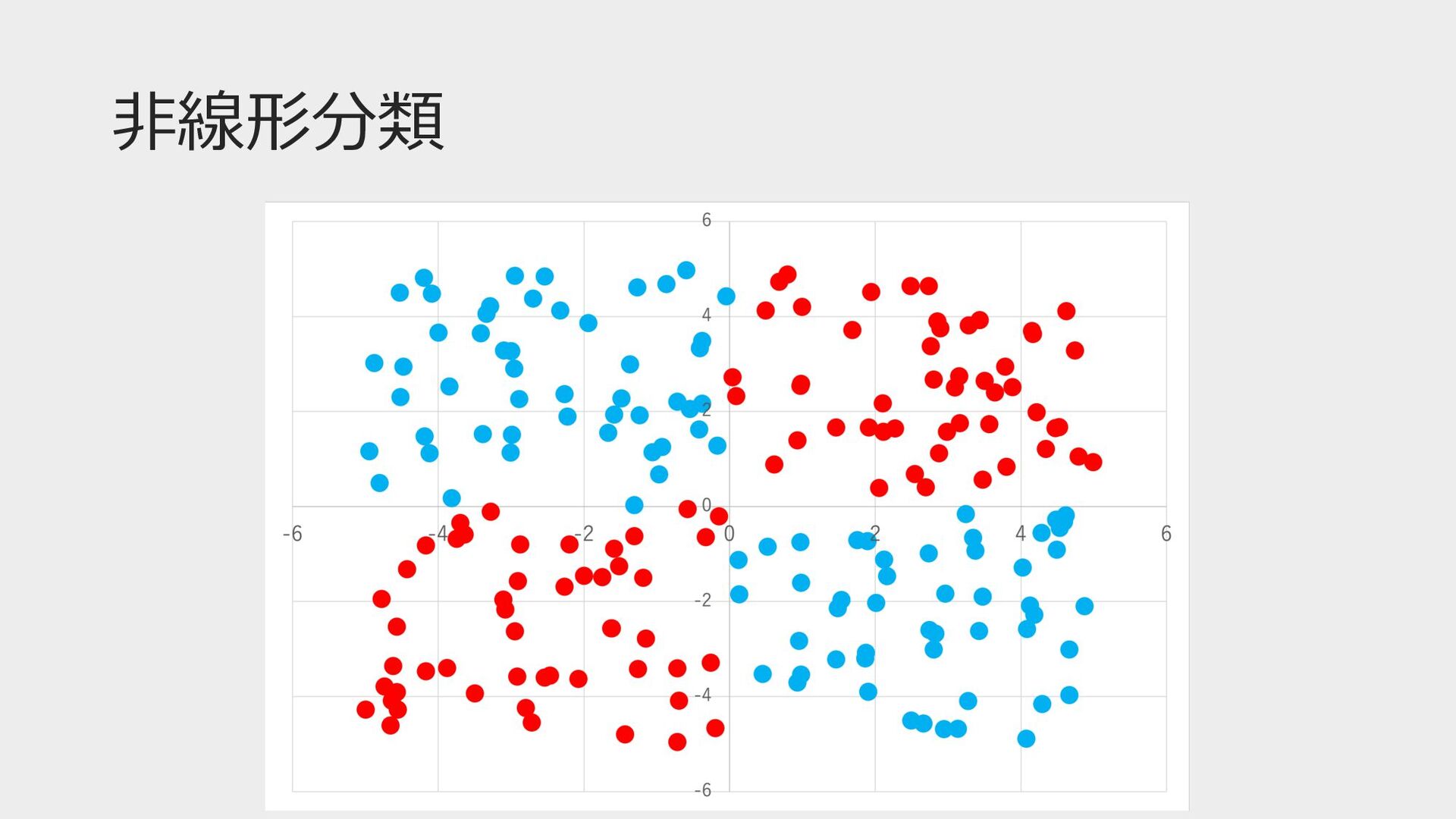
⾮線形分類
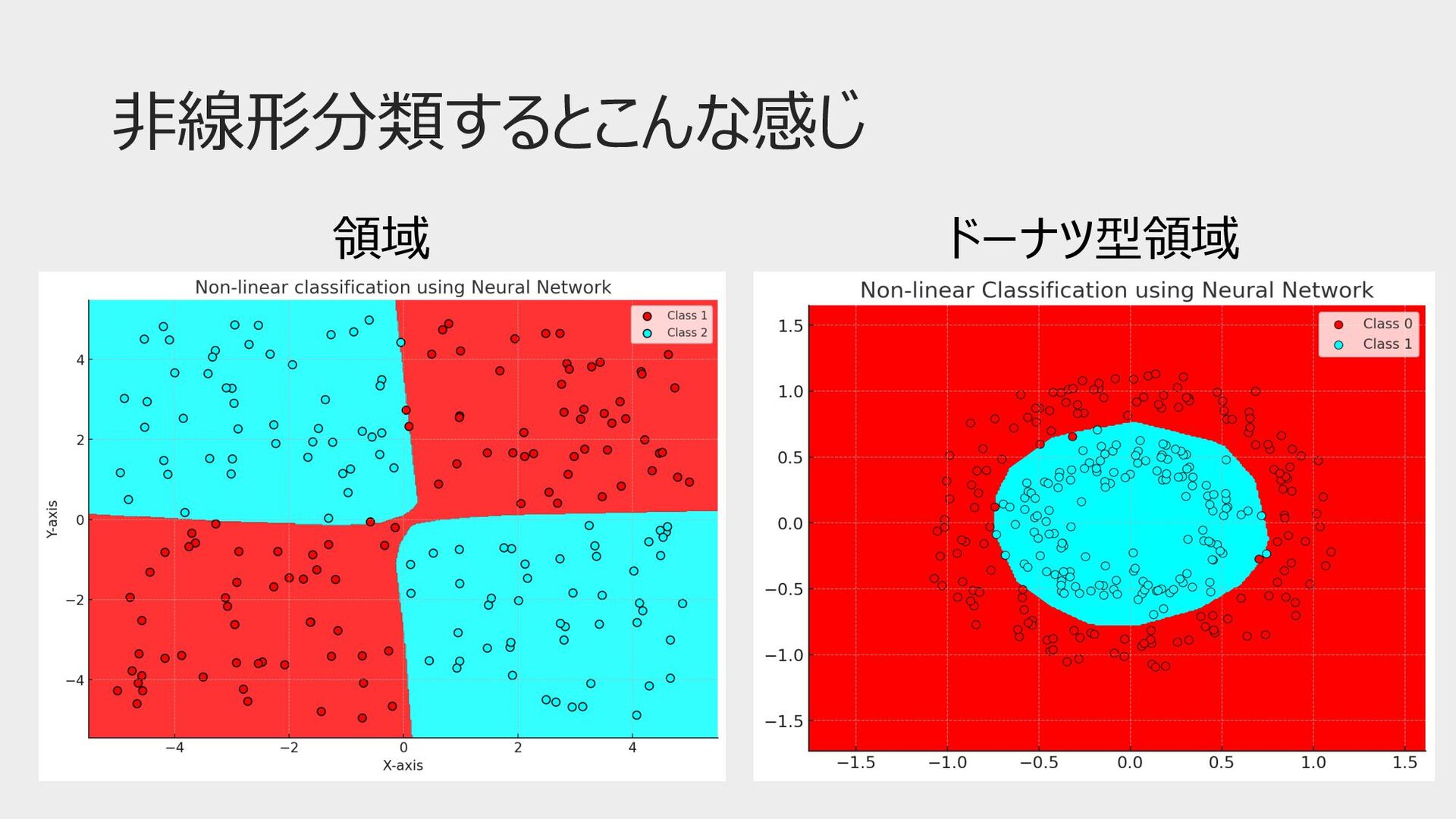
⾮線形分類 「線形分類不可能な問題が解けマセーン」 「パーセプトロンを複数繋げてみたらええんとちゃう︖」 パーセプトロンの「層」を増やすたびに、決定境界の形が 「直線→領域→ドーナツ型領域」と複雑さを増やしていける
(単純)パーセプトロン
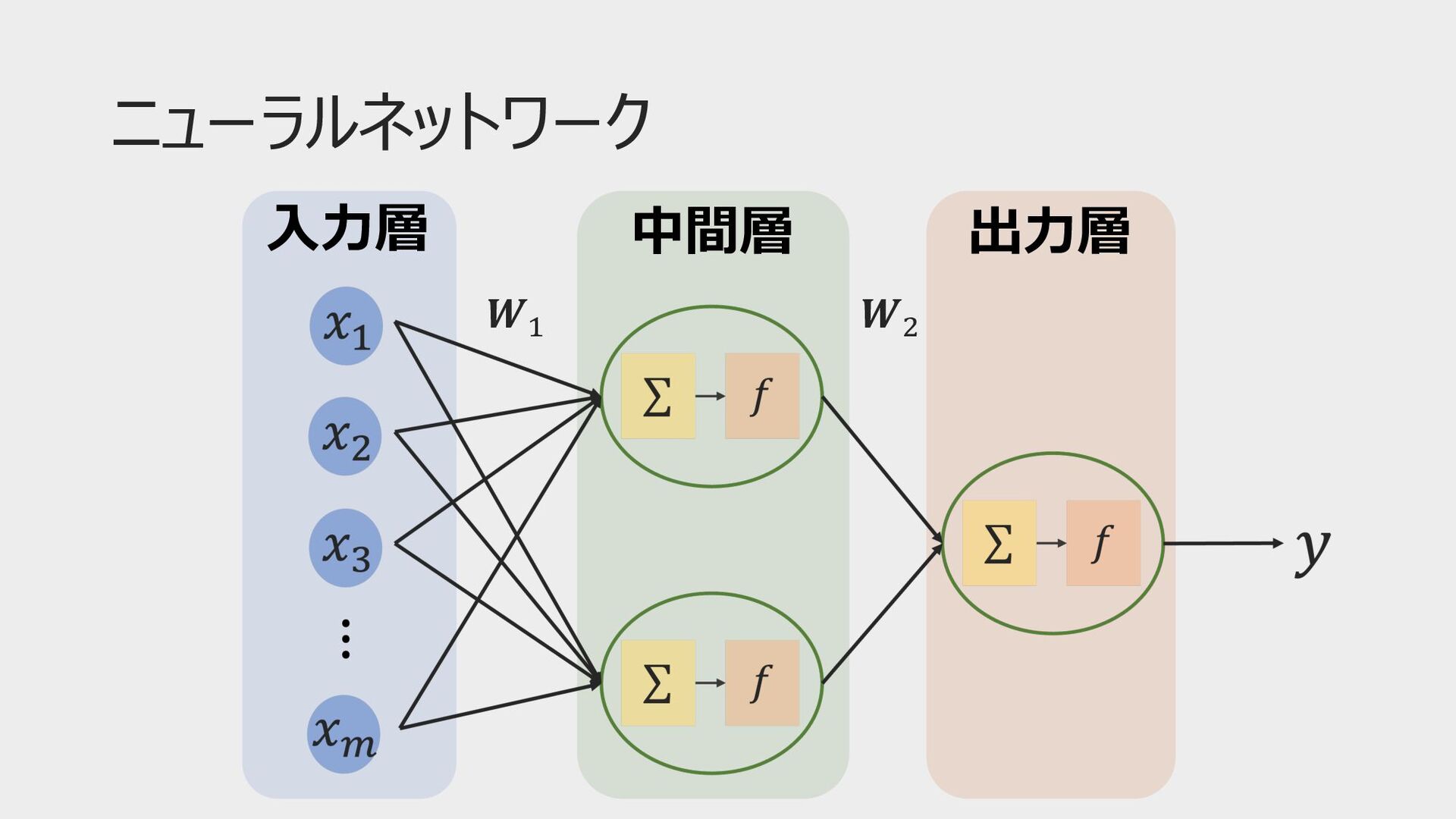
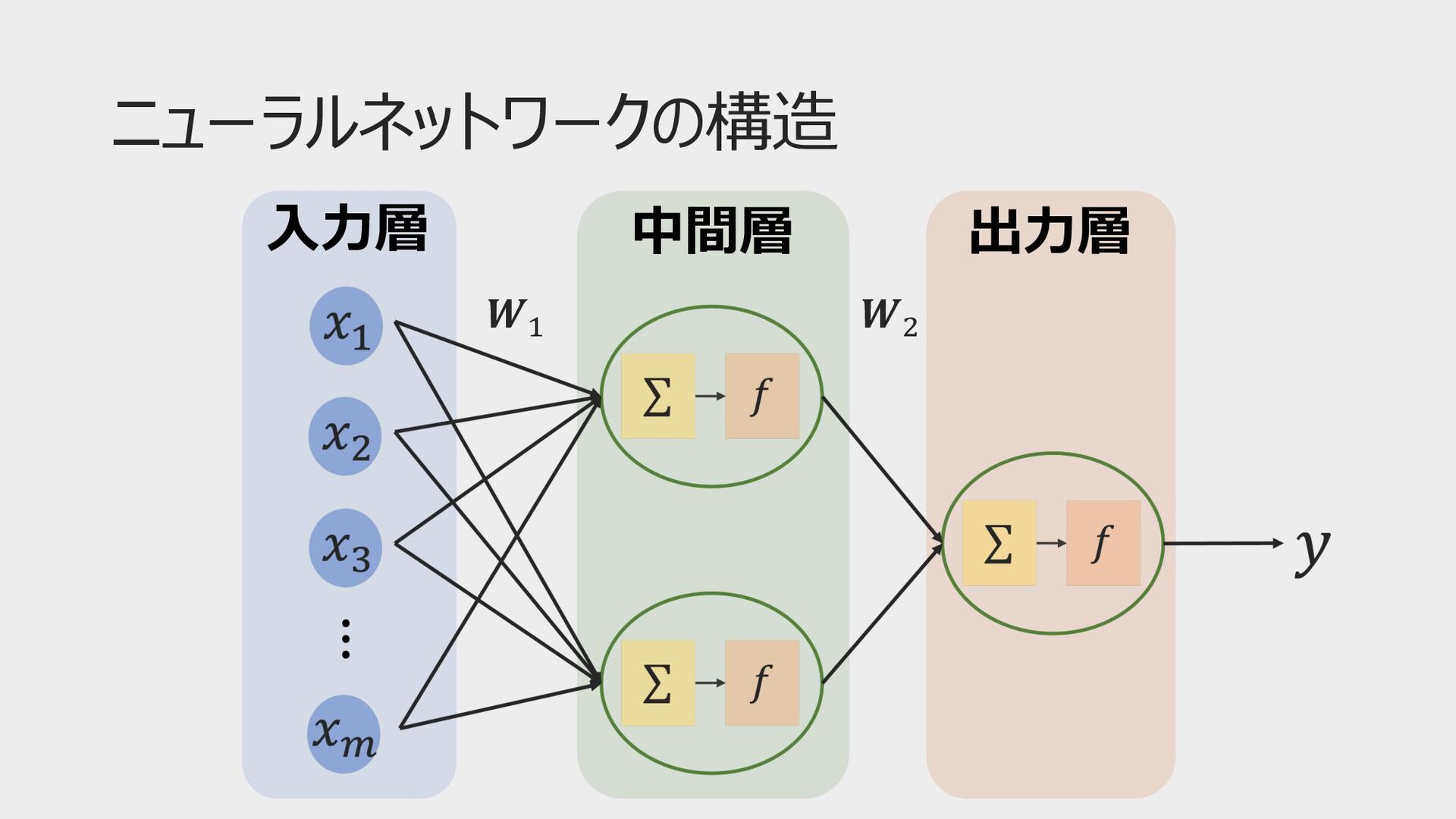
ニューラルネットワーク ⼊⼒層 中間層 出⼒層 𝑾! 𝑾"
⾮線形分類するとこんな感じ 領域 ドーナツ型領域
おまけ • ディープニューラルネットワークは中間層を2層以上持つもの 深さ 幅
ニューラルネットワークの基礎 キーワード: 活性化関数、最急降下法、確率勾配降下法、誤差逆伝播学習法、学 習、畳み込みニューラルネットワーク
数式がちょこっと出てきます。 眠気に注意してください。
ニューラルネットワークの構造 ⼊⼒層 中間層 出⼒層 𝑾! 𝑾"
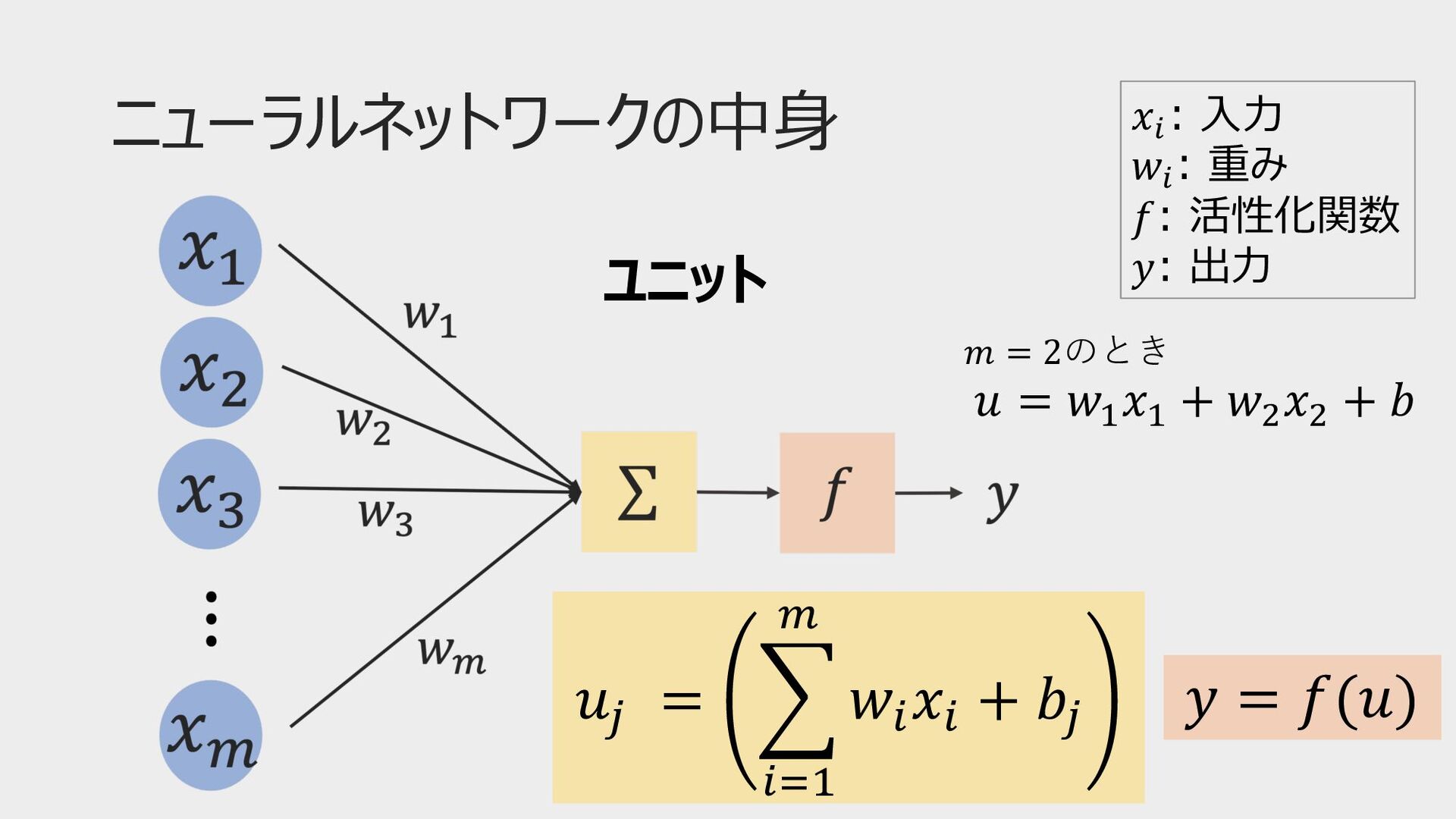
ニューラルネットワークの中⾝ 𝑢! = # "#$ % 𝑤" 𝑥" + 𝑏!
𝑦 = 𝑓(𝑢) 𝑥# : ⼊⼒ 𝑤# : 重み 𝑓: 活性化関数 𝑦: 出⼒ ユニット 𝑚 = 2のとき 𝑢 = 𝑤! 𝑥! + 𝑤" 𝑥" + 𝑏
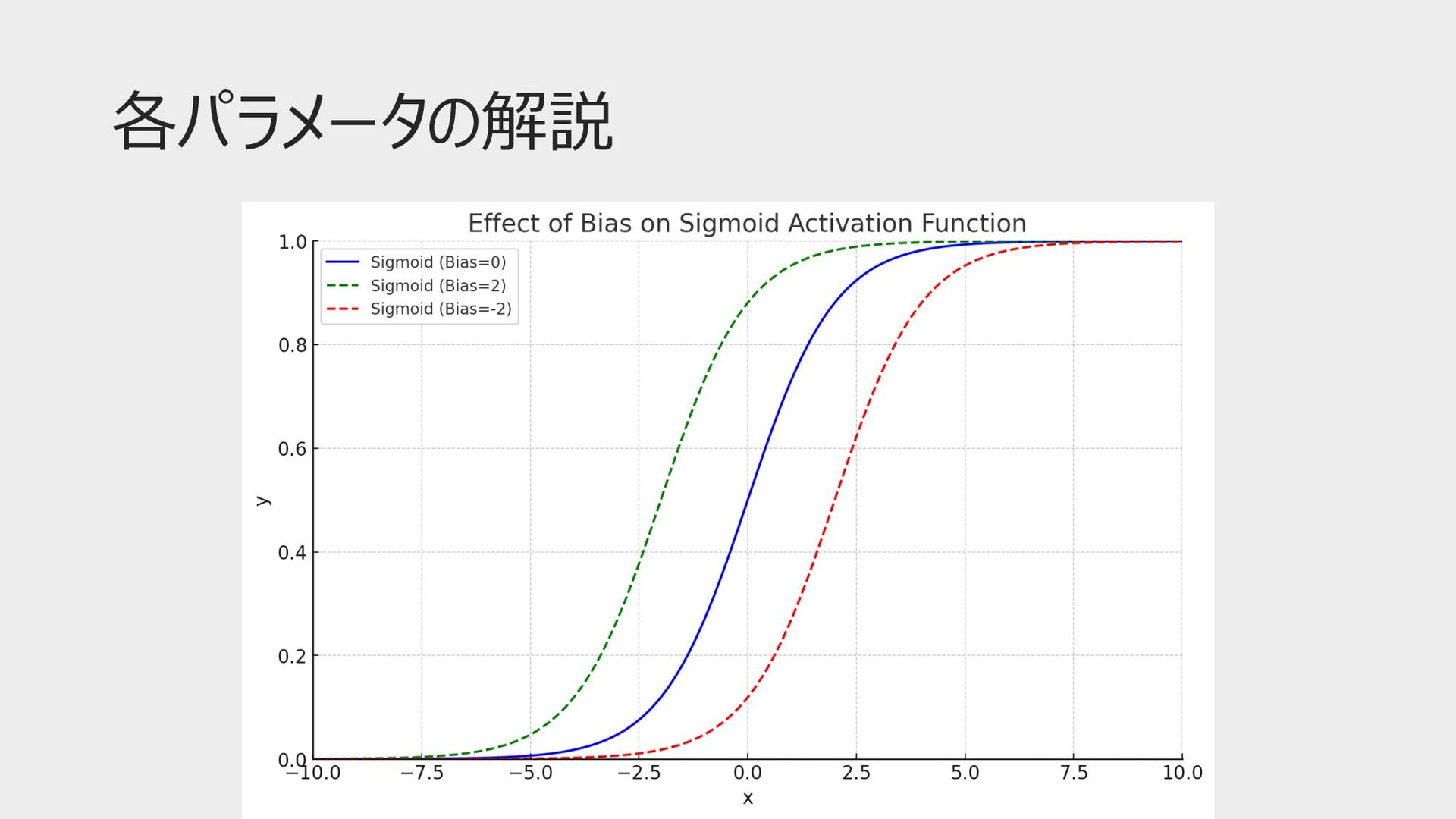
各パラメータの解説 • 重み(weight) • 各⼊⼒の重要度を⽰す • 重みは誤差を最⼩化するように調整される → 最適化アルゴリズム •
バイアス(bias) • ユニットの出⼒を調整 • 活性化関数の閾値を調整 • ユニットの「感度」を調整する役割 • バイアスも同様に調整される
各パラメータの解説
補⾜(式の表現) 𝒖 = 𝑾𝒙 + 𝒃 𝑧 = 𝑓(𝑢) 𝒛
= 𝒇(𝒖) 𝑢! = # "#$ % 𝑤" 𝑥" + 𝑏!
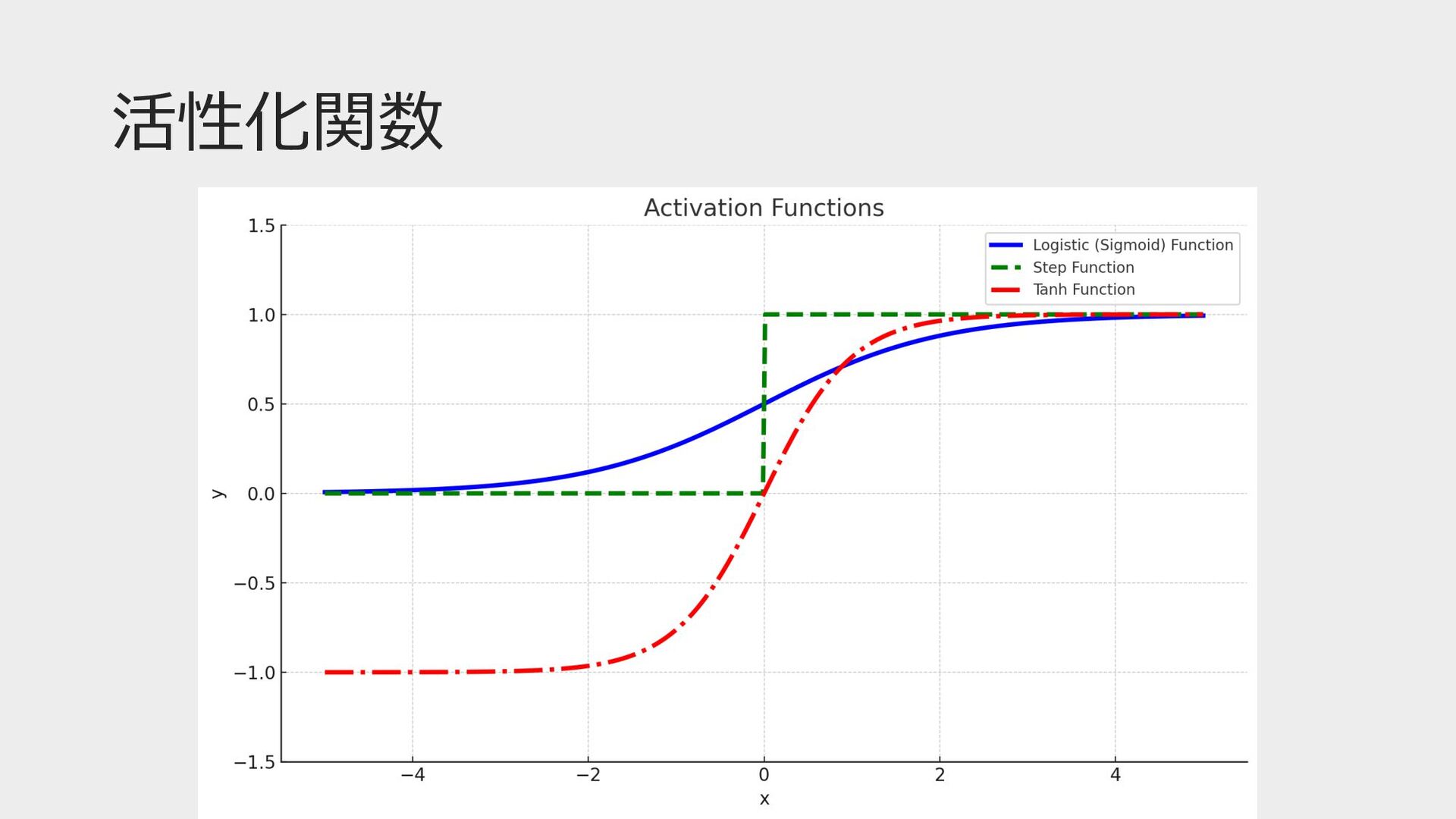
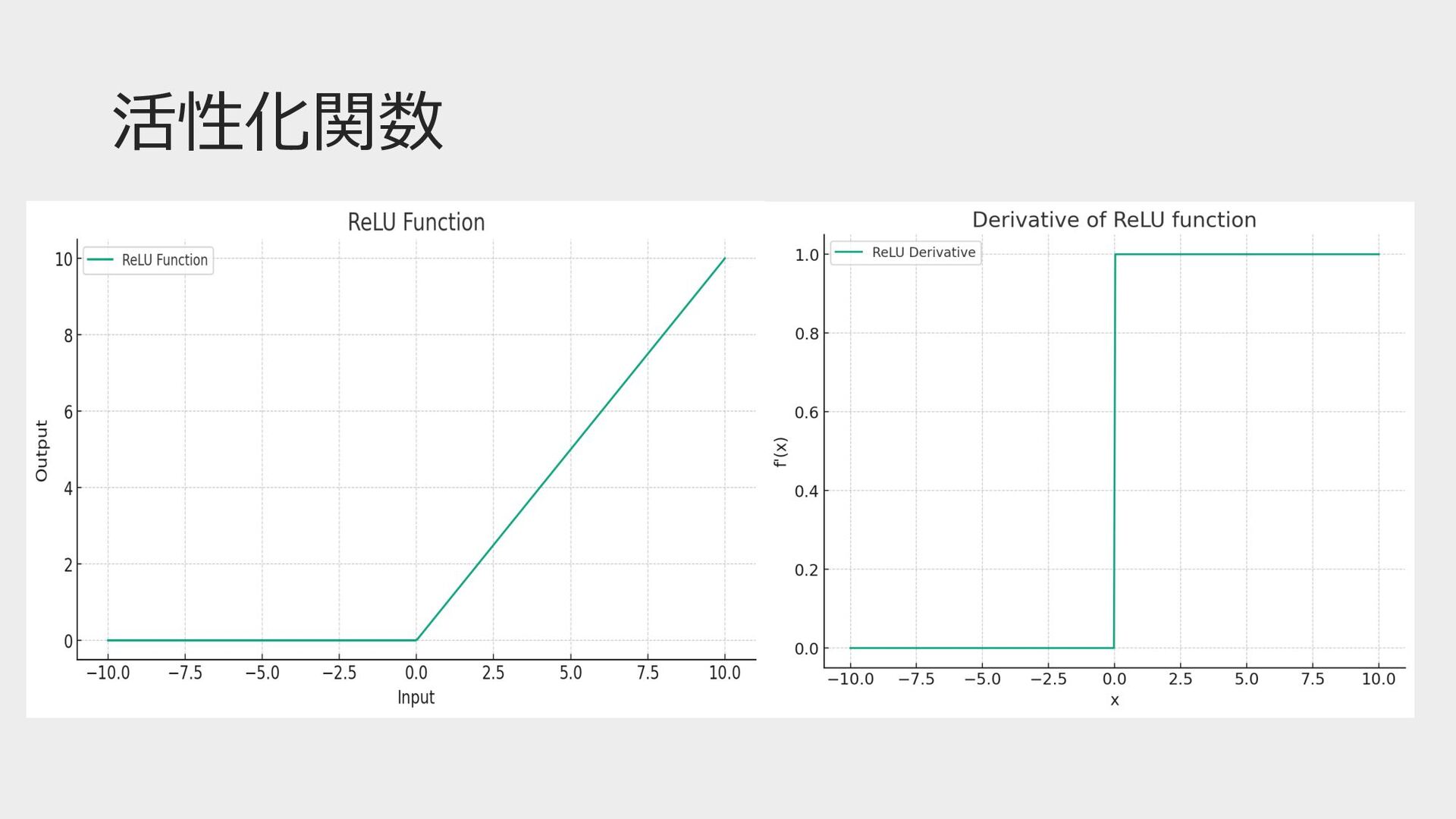
活性化関数とは • ニューラルネットワークの各ニューロンの出⼒に適⽤される関数 • ⾮線形性の導⼊(等価変換しても⼀次関数のまま) • ニューロンの出⼒の範囲を制限する役割 • 閾値を超えるとそのニューロンは発⽕(アクティブ化)する •
学習の安定化 • 過学習を防ぐ • 現代では、ReLUなどが⼀般的
活性化関数
ニューラルネットワークにおける学習とは • ⼀⾔で⾔うと → 損失関数(コスト関数)を最⼩化する → 損失関数を最⼩化するために重みやバイアスを更新するプロセス • 損失関数 •
ニューラルネットワークの出⼒と⽬的の出⼒との差を数値化したもの • 最適化アルゴリズム • 勾配法(勾配降下法)を⽤いる
損失関数の具体例 活性化関数はシグモイド関数とする 𝑓 𝑥 = 1 1 + 𝑒#$ モデルの出⼒を
̂ 𝑧 = 𝑓 𝑥! 𝑤! 、正解値が𝑧 = 1とする。 ℒ = (𝑧 − ̂ 𝑧)" = 1 − 1 1 + 𝑒#$!%! " 最⼩になるような 𝑤! を求める
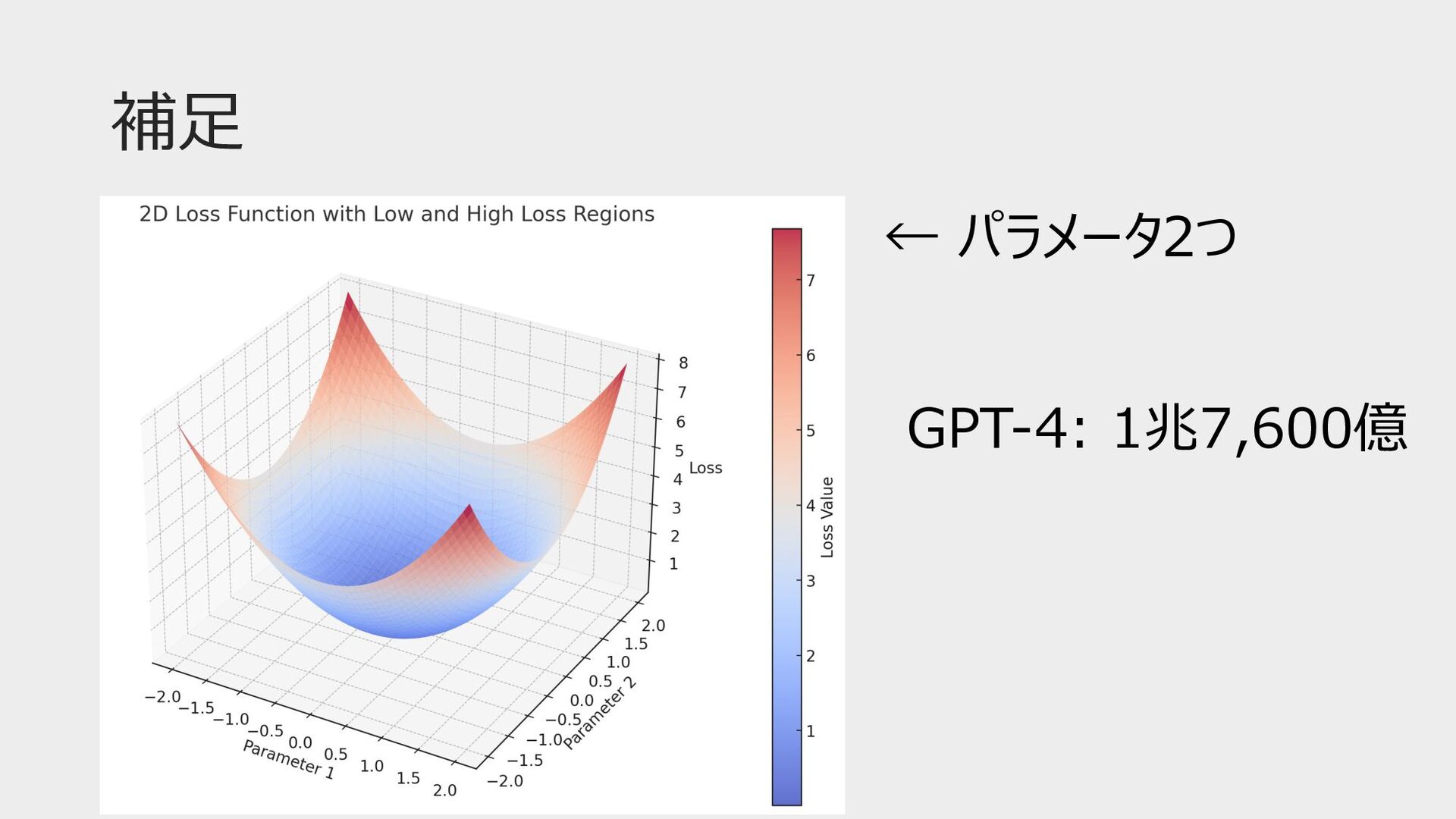
補⾜ ← パラメータ2つ GPT-4: 1兆7,600億
最適化アルゴリズムについて • 勾配法: 関数の傾き(勾配)をもとに最⼩値を探す⼿法 • 勾配降下法の種類 • 最急降下法 • 確率的勾配降下法(SGD)
• Adagrad • RMSprop • Adadelta • Adam • AdamW
勾配降下法 勾配降下法 1.⼊⼒からニューラルネットワークの出⼒を計算する 2.出⼒から損失関数を計算 3.損失関数の勾配を計算する(→誤差逆伝播法) 4.それを⽤いて重みを更新 𝑤& = 𝑤 −
𝜂 𝜕ℒ 𝜕𝑤 𝜂: 学習率
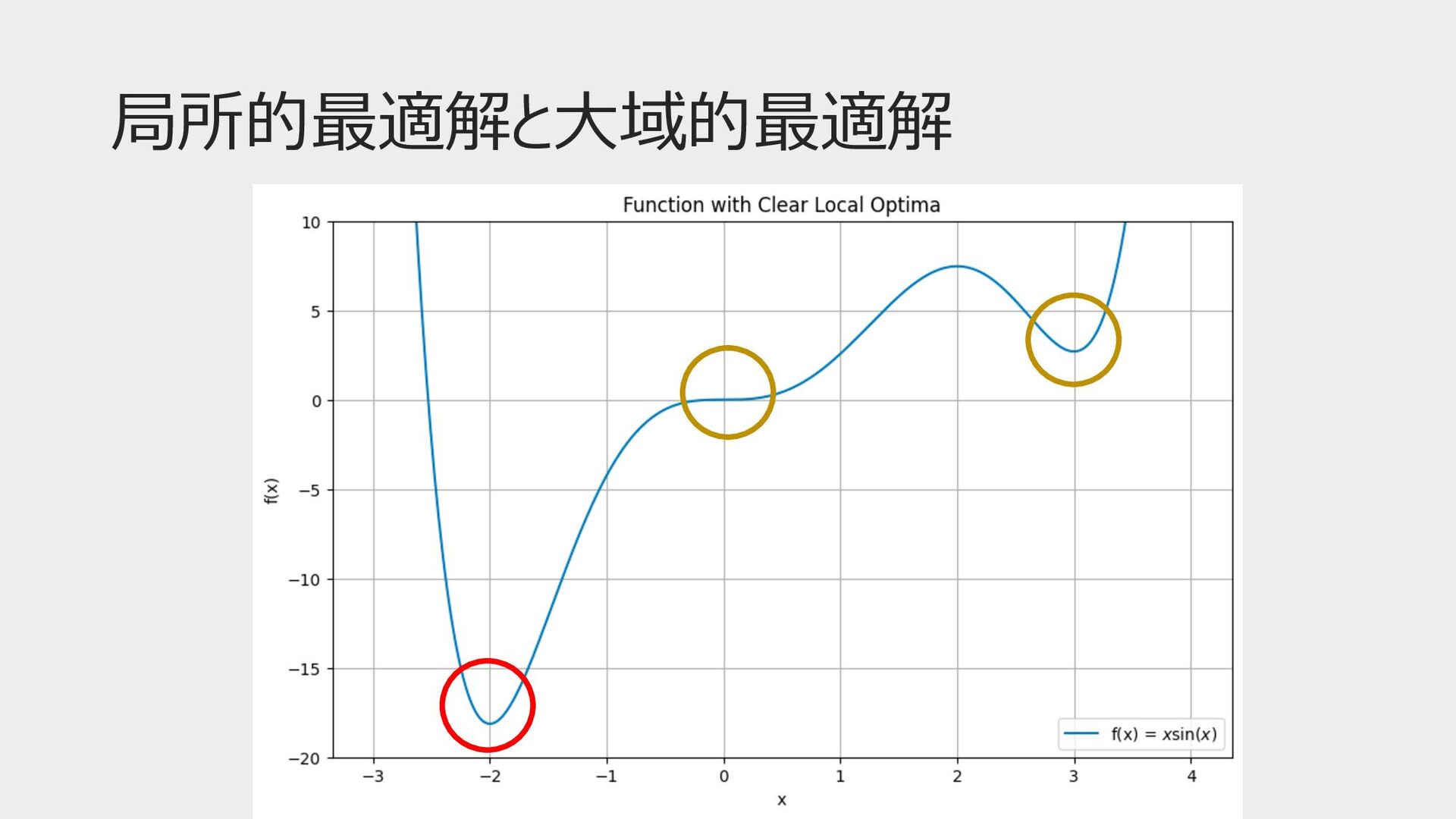
最急降下法 ⽋点 • 1回のパラメータ更新でデータ(バッチ)全部を使う • 計算量が⼤きい(並列計算で対策可能) • 局所的最適解から抜け出せない → 確率的勾配降下法(SGD)
確率的勾配降下法(SGD) 特徴 • SGDではランダムに選ばれた1つのデータを⽤いる • 毎回の更新で違うデータを使うので局所的最適解から抜け出せ る可能性がある ⽋点 • 並列化ができない
→ ミニバッチSGD
局所的最適解と⼤域的最適解
準備
準備
準備
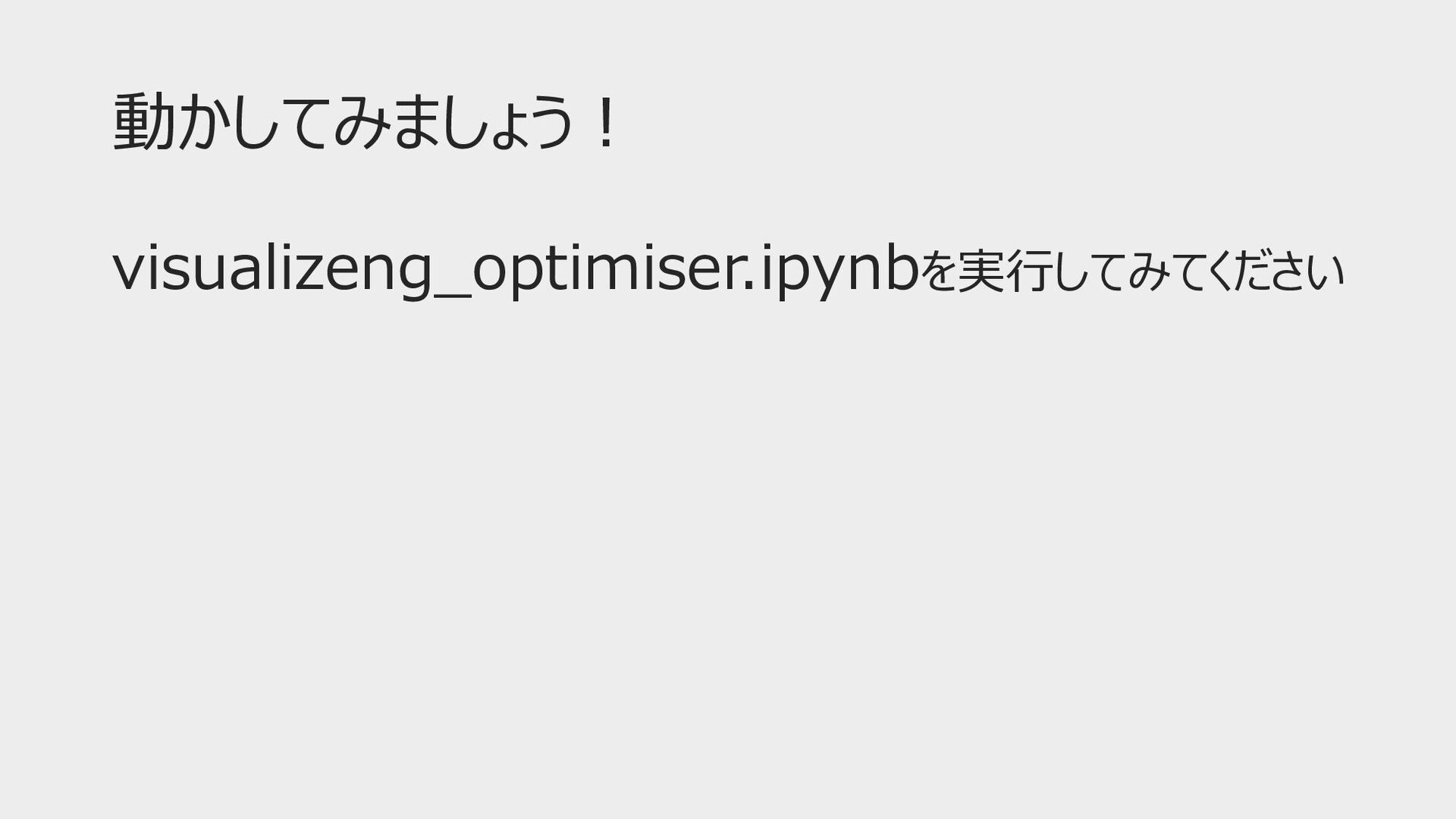
動かしてみましょう︕ visualizeng_optimiser.ipynbを実⾏してみてください
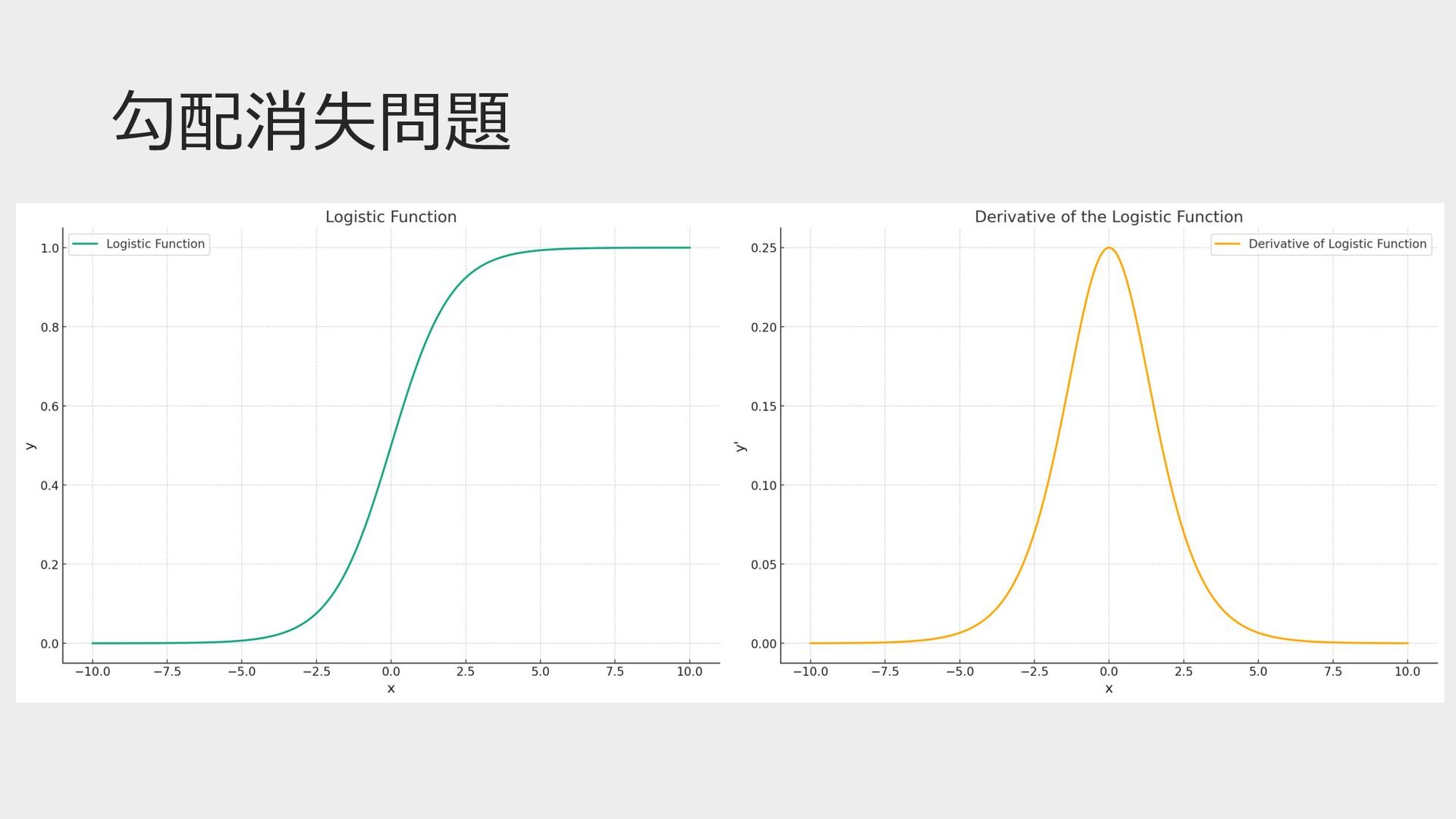
勾配消失問題
活性化関数
まとめ① • ニューラルネットワークは⾮線形分類を⾏う︕ → より複雑な関数を表現できるように • 学習とはつまり、正解との誤差をもとにパラメータを更新すること
CNNの仕組み キーワード: 畳み込み層、プーリング層、CNN、フィルター(カーネル)、特徴量
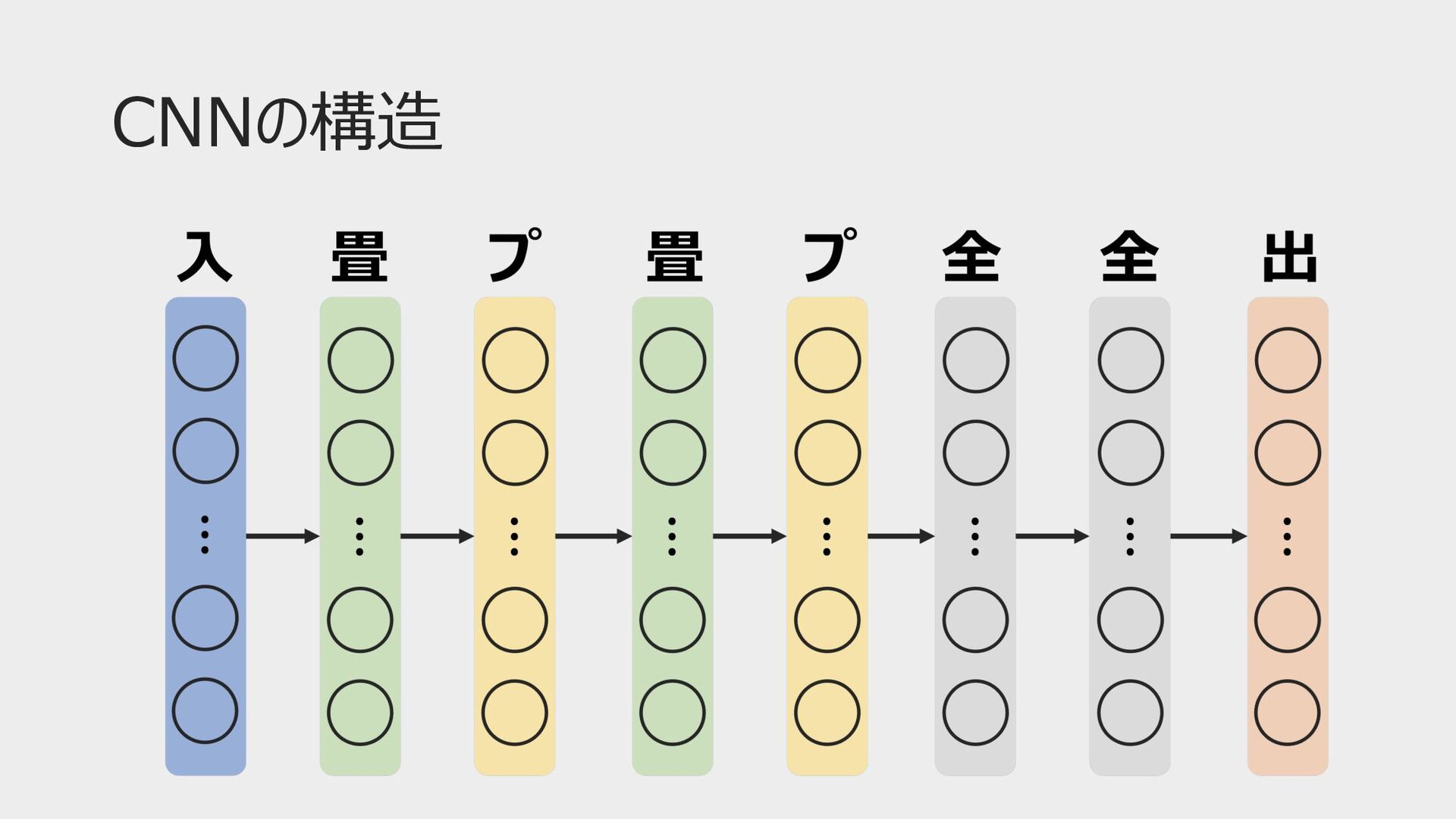
CNNとは • 畳み込み層とプーリング層を持つニューラルネットワーク • 画像分類や画像認識の分野で多く⽤いられている • 局所的な特徴抽出 • パラメータ数の削減 •
重みとしてフィルタを⽤いる
CNNの構造
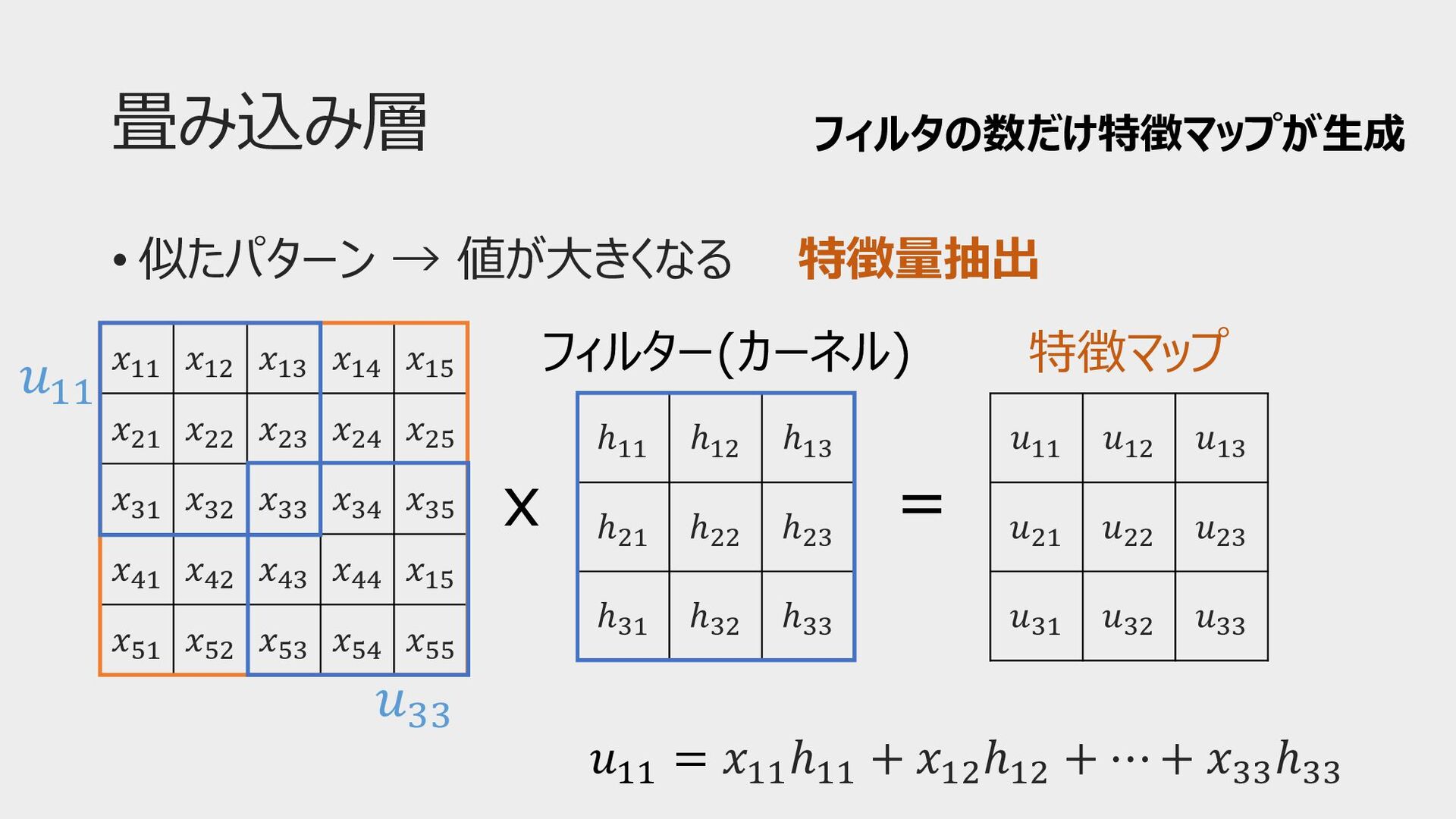
畳み込み層 • 似たパターン → 値が⼤きくなる 特徴量抽出 𝑥!! 𝑥!" 𝑥!# 𝑥!$
𝑥!% 𝑥"! 𝑥"" 𝑥"# 𝑥"$ 𝑥"% 𝑥#! 𝑥#" 𝑥## 𝑥#$ 𝑥#% 𝑥$! 𝑥$" 𝑥$# 𝑥$$ 𝑥!% 𝑥%! 𝑥%" 𝑥%# 𝑥%$ 𝑥%% ℎ!! ℎ!" ℎ!# ℎ"! ℎ"" ℎ"# ℎ#! ℎ#" ℎ## 𝑢"" 𝑢## x = 𝑢!! 𝑢!" 𝑢!# 𝑢"! 𝑢"" 𝑢"# 𝑢#! 𝑢#" 𝑢## 𝑢!! = 𝑥!! ℎ!! + 𝑥!" ℎ!" + ⋯ + 𝑥'' ℎ'' フィルター(カーネル) 特徴マップ フィルタの数だけ特徴マップが⽣成
畳み込み層
畳み込み層
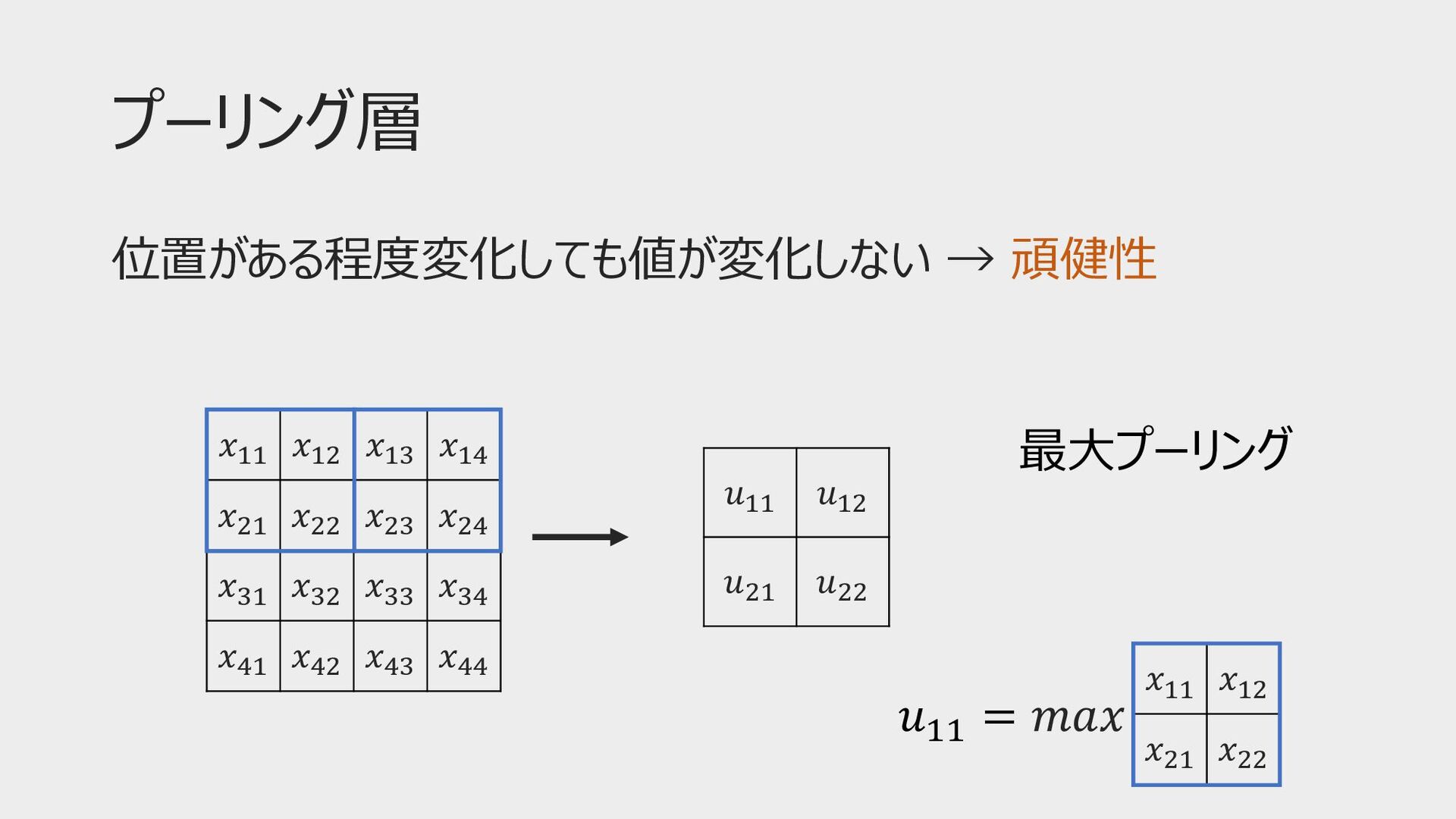
プーリング層 位置がある程度変化しても値が変化しない → 頑健性 𝑥!! 𝑥!" 𝑥!# 𝑥!$ 𝑥"! 𝑥""
𝑥"# 𝑥"$ 𝑥#! 𝑥#" 𝑥## 𝑥#$ 𝑥$! 𝑥$" 𝑥$# 𝑥$$ 𝑢!! 𝑢!" 𝑢"! 𝑢"" 𝑢!! = 𝑚𝑎𝑥 𝑥!! 𝑥!" 𝑥"! 𝑥"" 最⼤プーリング
全結合層 • 全てのニューロンが全ての⼊⼒と結合されている層 • 「どれくらい似てるか」をスカラー値で出⼒する • 特徴マップを結合して⼀次元のスカラー値を出⼒ → 元の画像データがどのラベルに属するかを⽰す確率
出⼒層 • 多くは、全結合層の出⼒に活性化関数を通したもの • ソフトマックス関数 𝑦! 𝑦" 𝑦$ ⋮ 𝑢!
𝑢" 𝑢$ 𝑦! = 𝑒"& 𝑒"' + 𝑒"( + ⋯ 𝑒") 分⼦: ⼤きい値をより強調 分⺟: 規格化のため 0~1の値を取り、総和が1 → 確率に対応
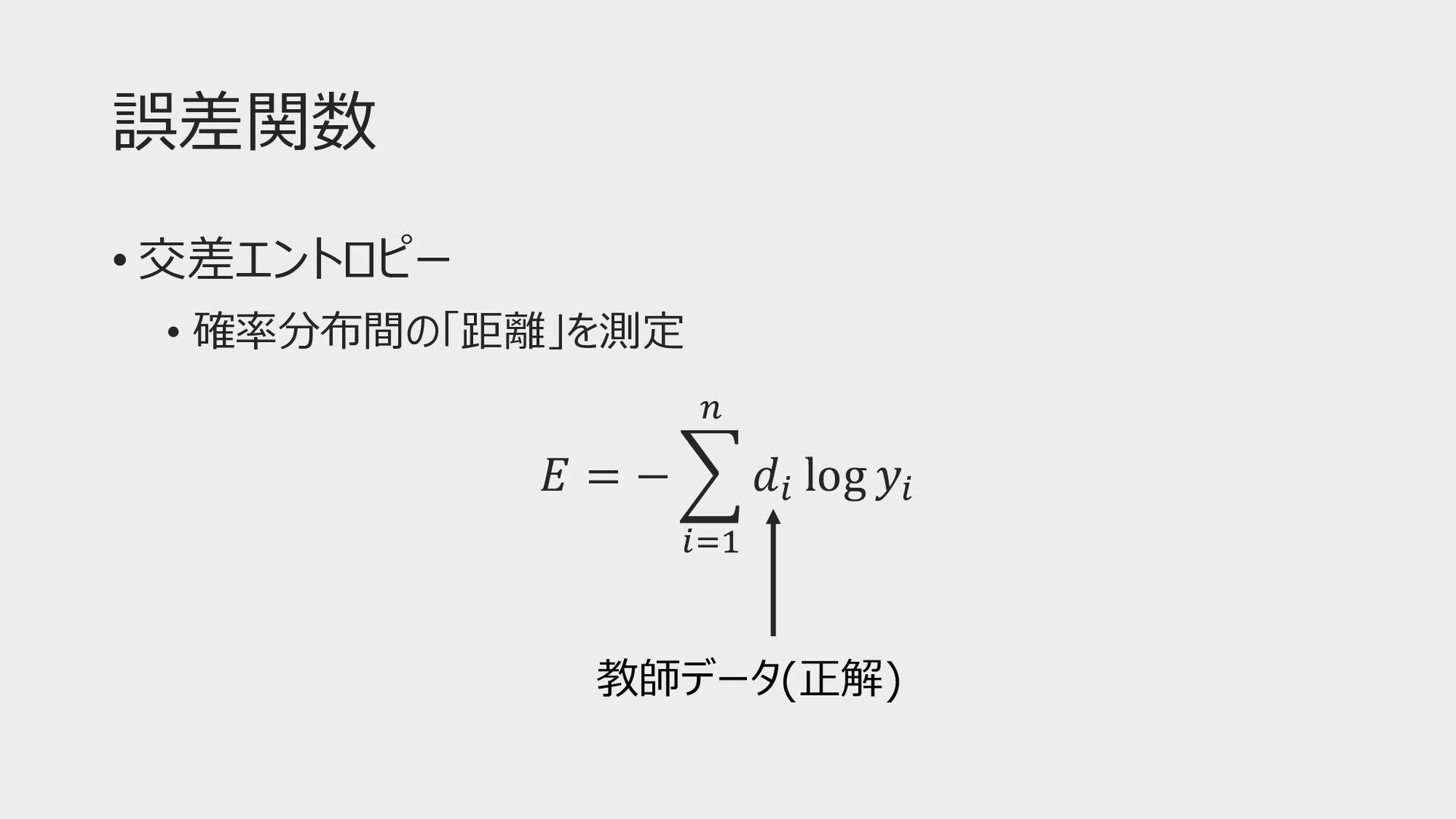
誤差関数 • 交差エントロピー • 確率分布間の「距離」を測定 𝐸 = − 7 ()!
* 𝑑( log 𝑦( 教師データ(正解)
説明できなかったものたち • 勾配消失問題 • 誤差逆伝播法 • 諸々の数学的な定理 • 万能近似定理 •
ニューラルネットワークにおけるテクニックや研究動向
やってみよう 〜説明編〜
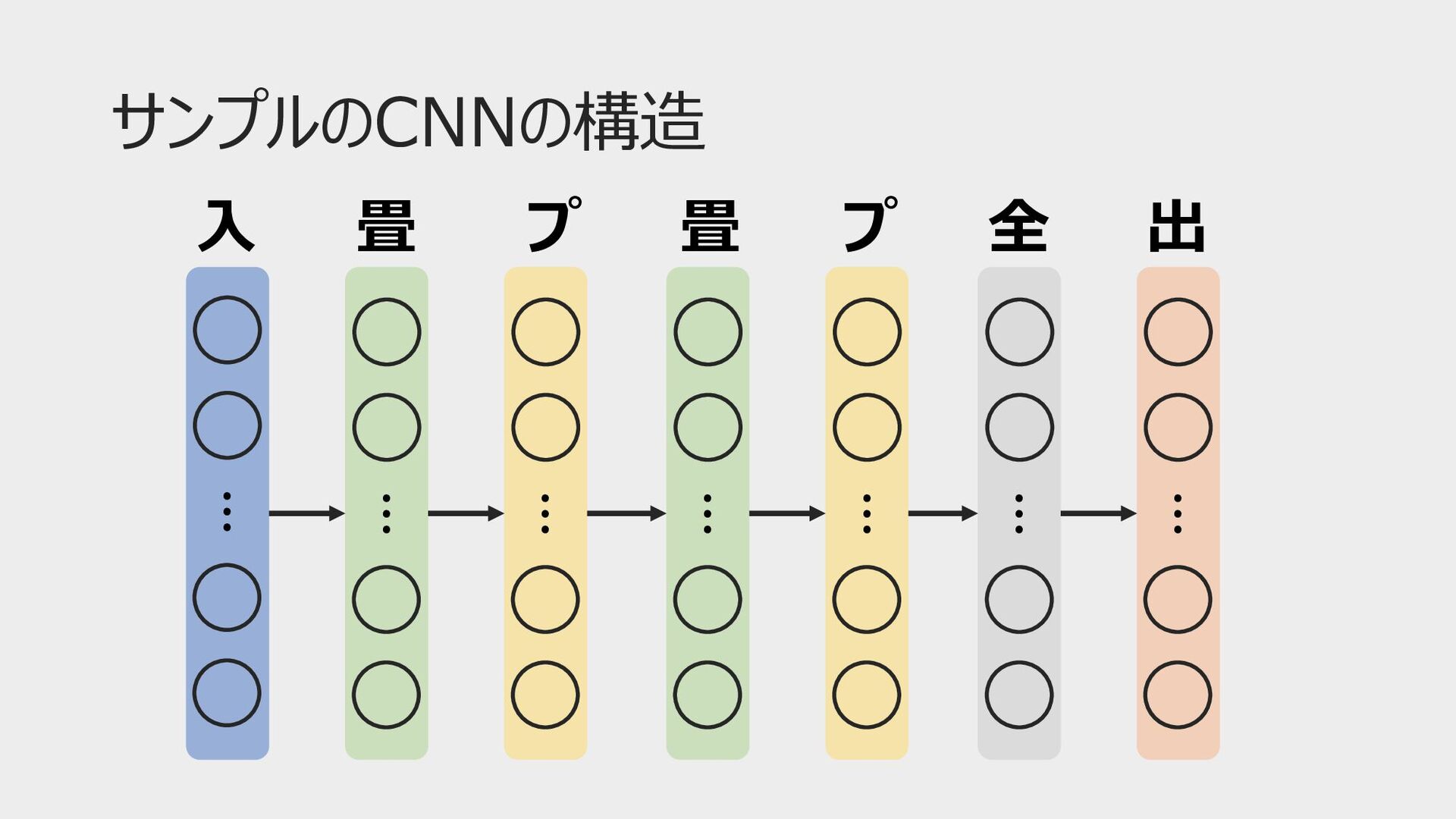
サンプルのCNNの構造 ⼊ 畳 プ 畳 プ 全 出 ⋮ ⋮
⋮ ⋮ ⋮ ⋮ ⋮
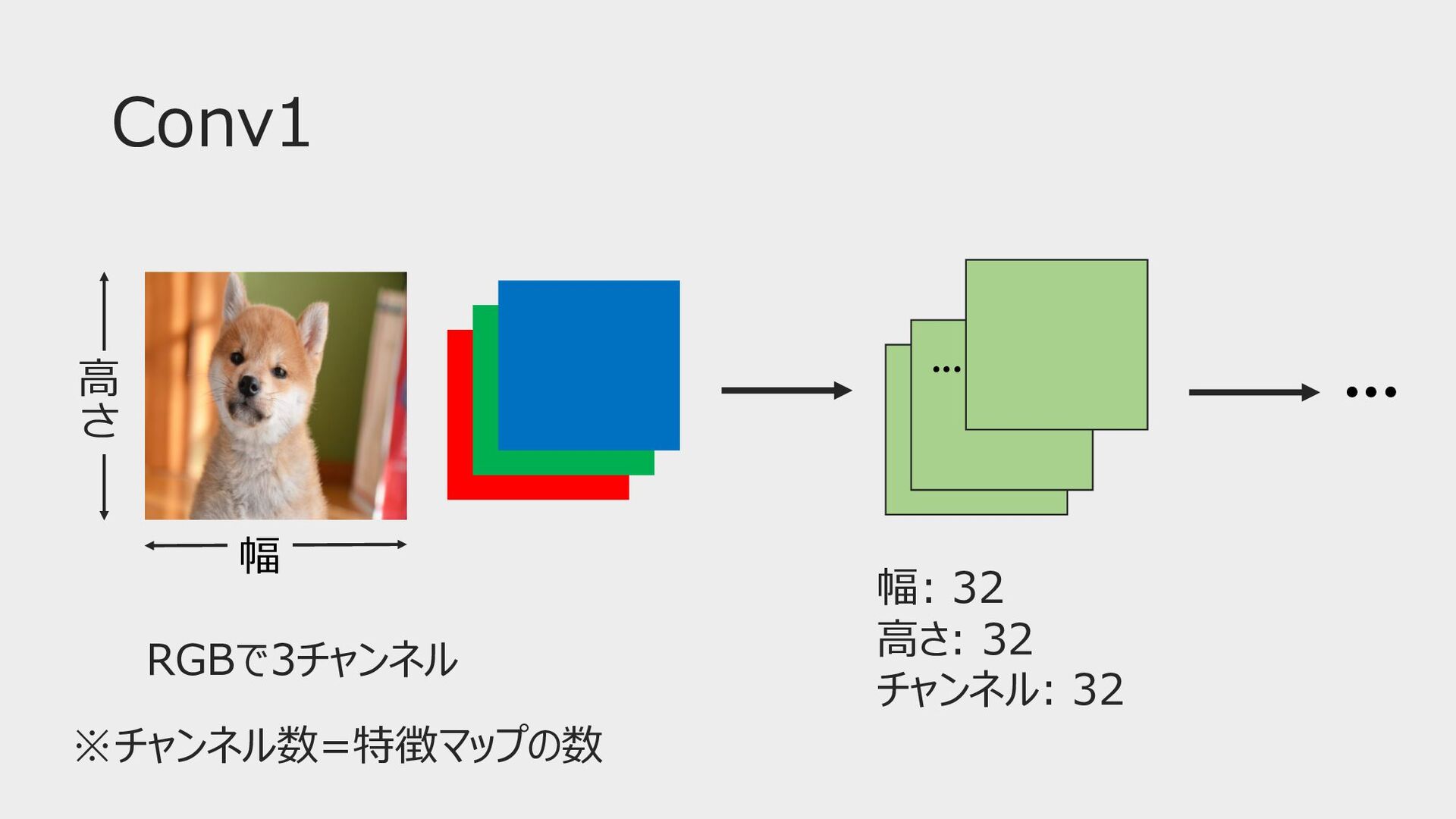
Conv1 幅 ⾼ " RGBで3チャンネル ※チャンネル数=特徴マップの数 ••• 幅: 32 ⾼さ:
32 チャンネル: 32 •••
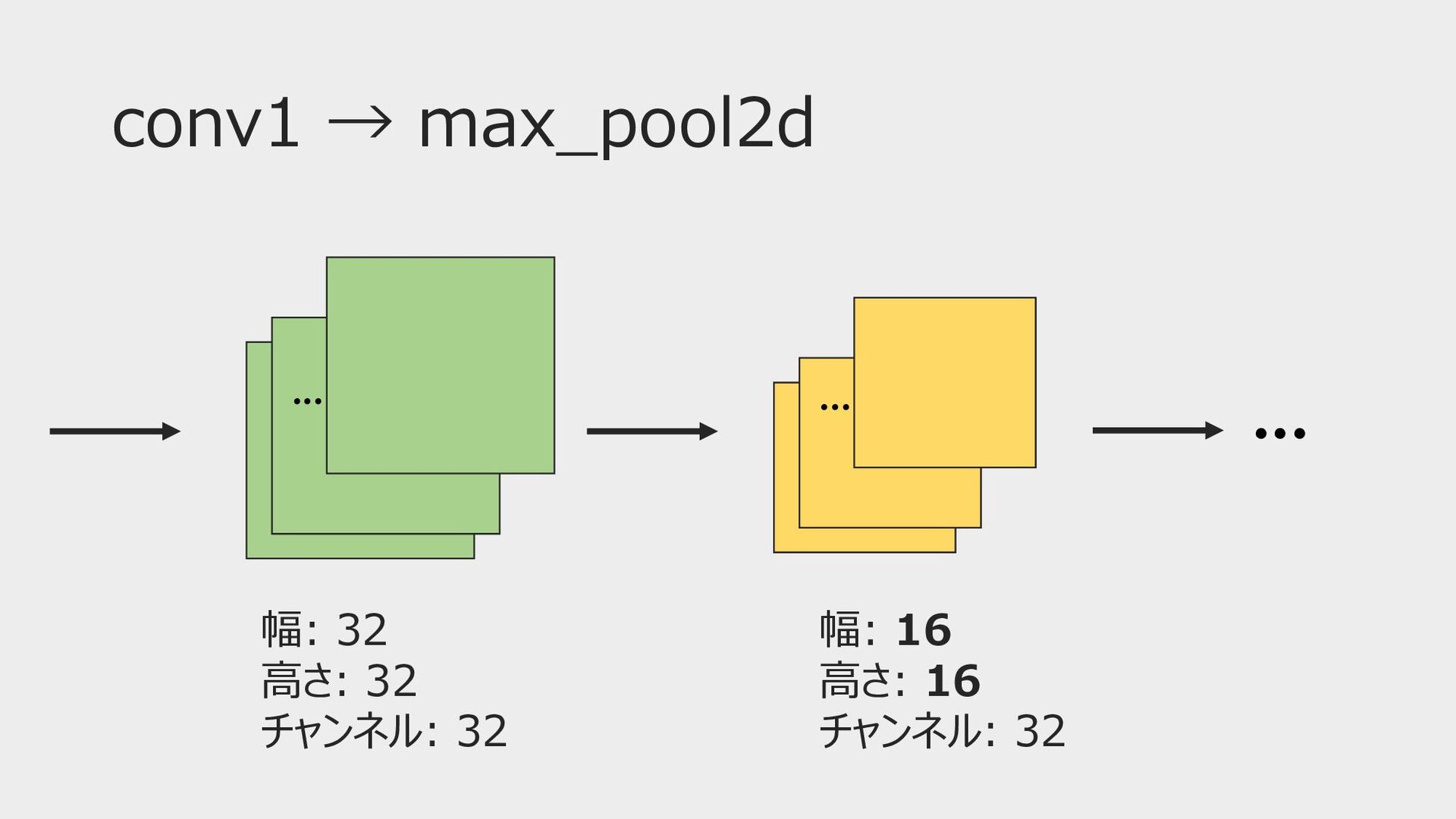
conv1 → max_pool2d ••• ••• ••• 幅: 32 ⾼さ: 32
チャンネル: 32 幅: 16 ⾼さ: 16 チャンネル: 32
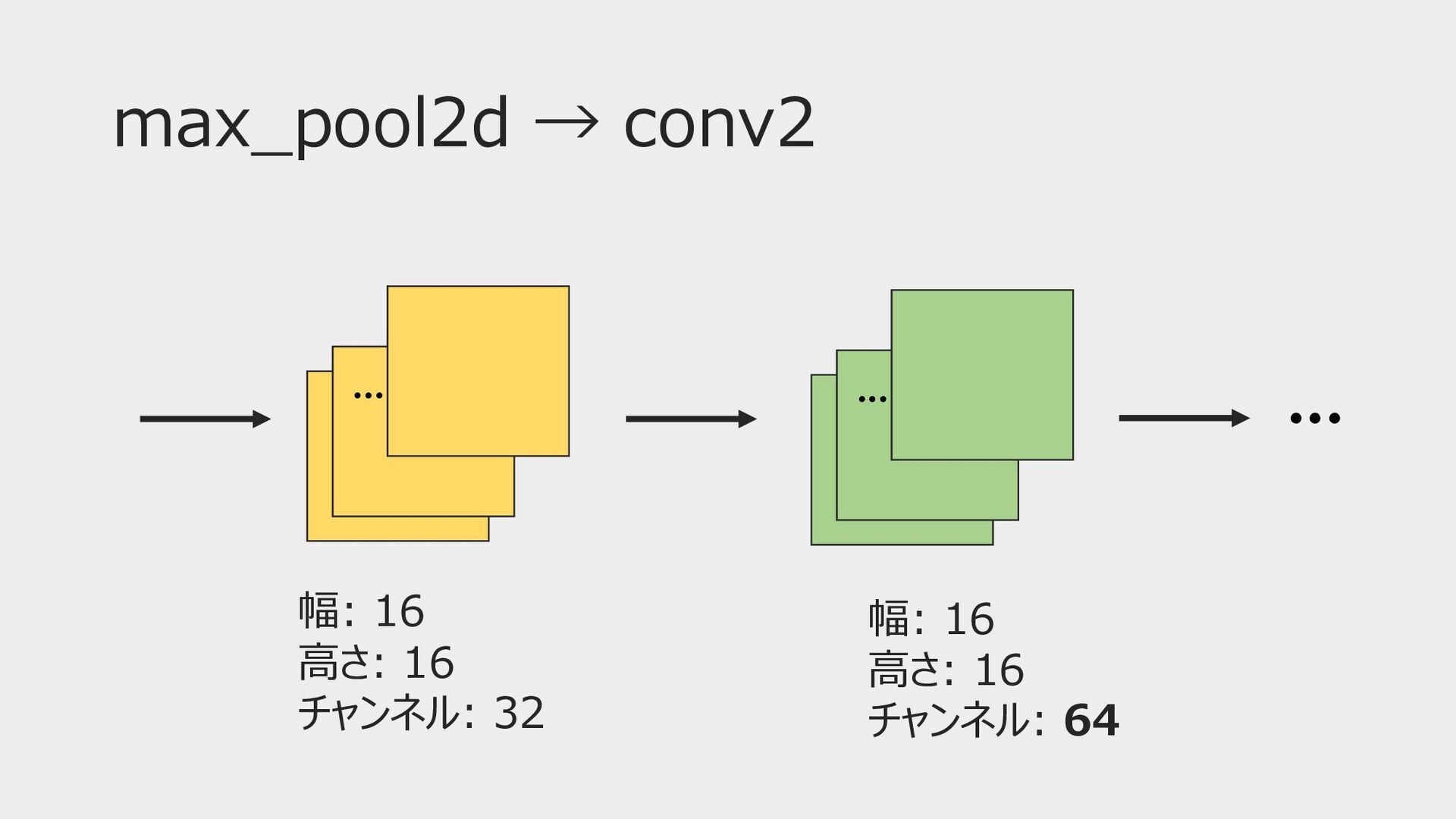
max_pool2d → conv2 ••• ••• ••• 幅: 16 ⾼さ: 16
チャンネル: 32 幅: 16 ⾼さ: 16 チャンネル: 64
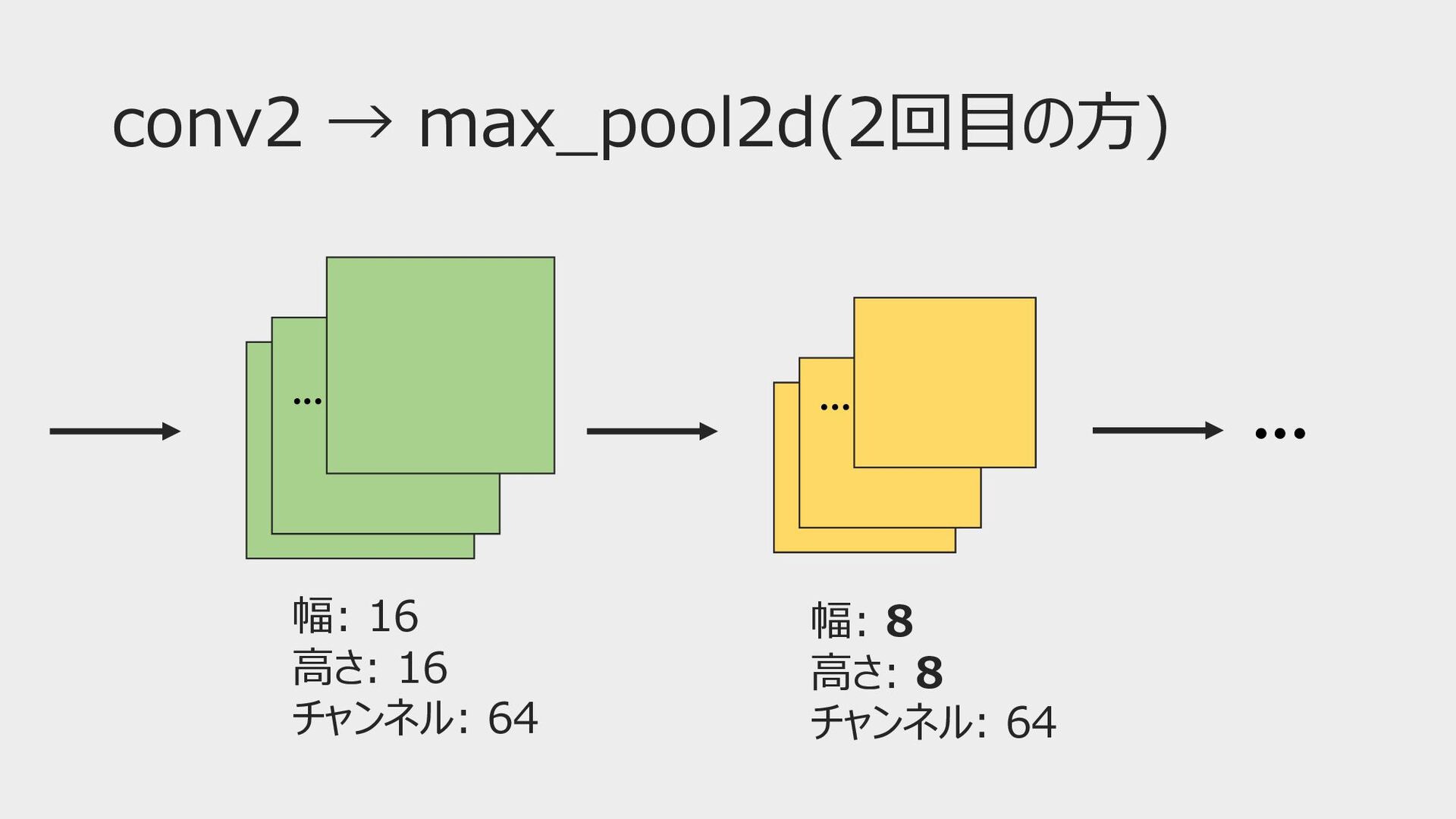
conv2 → max_pool2d(2回⽬の⽅) ••• ••• ••• 幅: 16 ⾼さ: 16
チャンネル: 64 幅: 8 ⾼さ: 8 チャンネル: 64
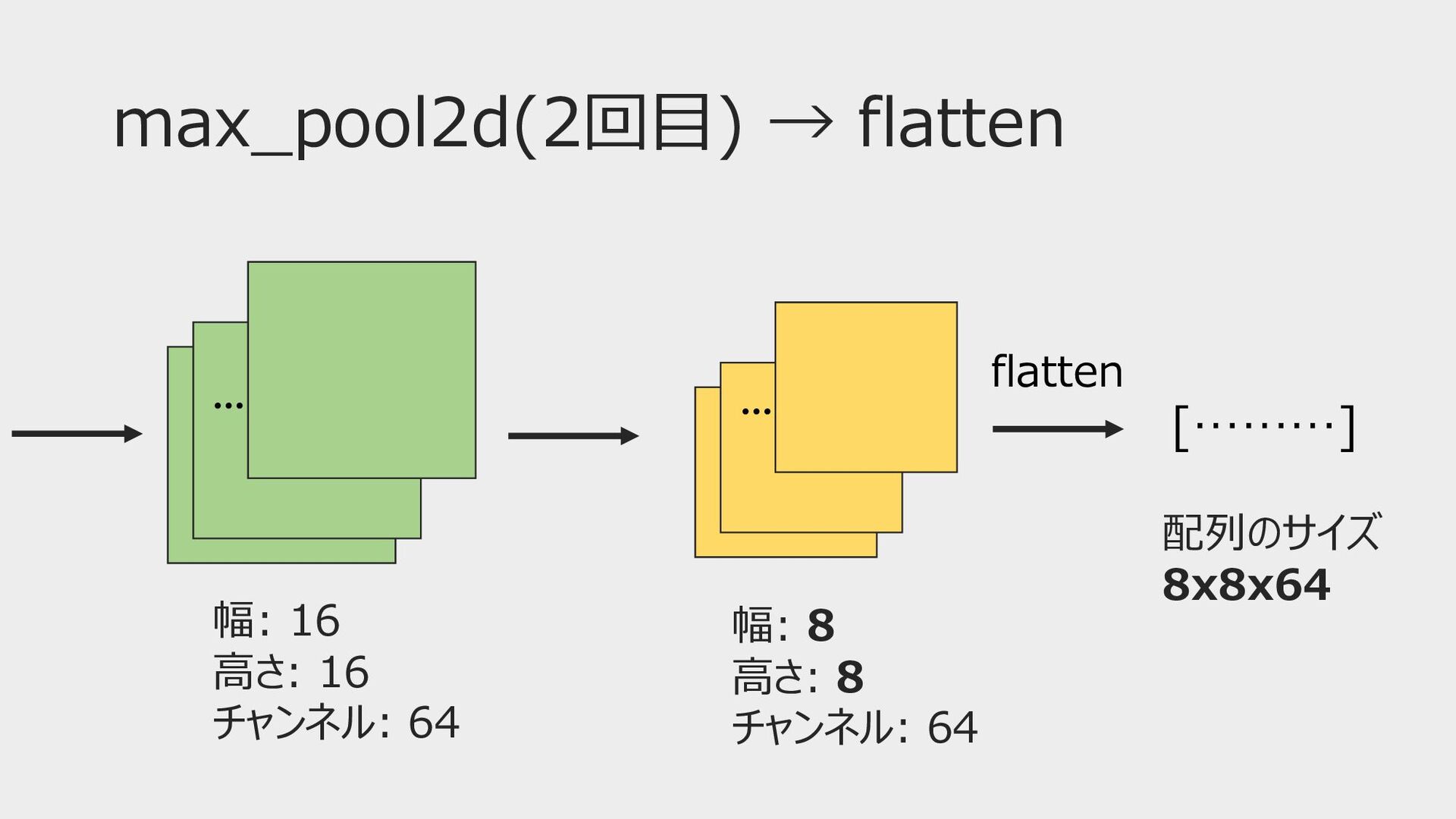
max_pool2d(2回⽬) → flatten • Flatten(平滑化) • CNNでは全結合層に渡す前に使う • Softmax関数で扱えるようにする •
多次元テンソルを任意の次元まで平滑化する → 多次元の特徴マップを⼀次元に変換
max_pool2d(2回⽬) → flatten ••• ••• 幅: 16 ⾼さ: 16 チャンネル:
64 幅: 8 ⾼さ: 8 チャンネル: 64 [………] 配列のサイズ 8x8x64 flatten
flatten → fc1 → relu → fc2 [………] 配列のサイズ 8x8x64
[………] 配列のサイズ 256 [………] 配列のサイズ 10 → 各クラスの確率 torchのCrossEntropyLossは ⾃動的にSoftmax関数使ってくれる
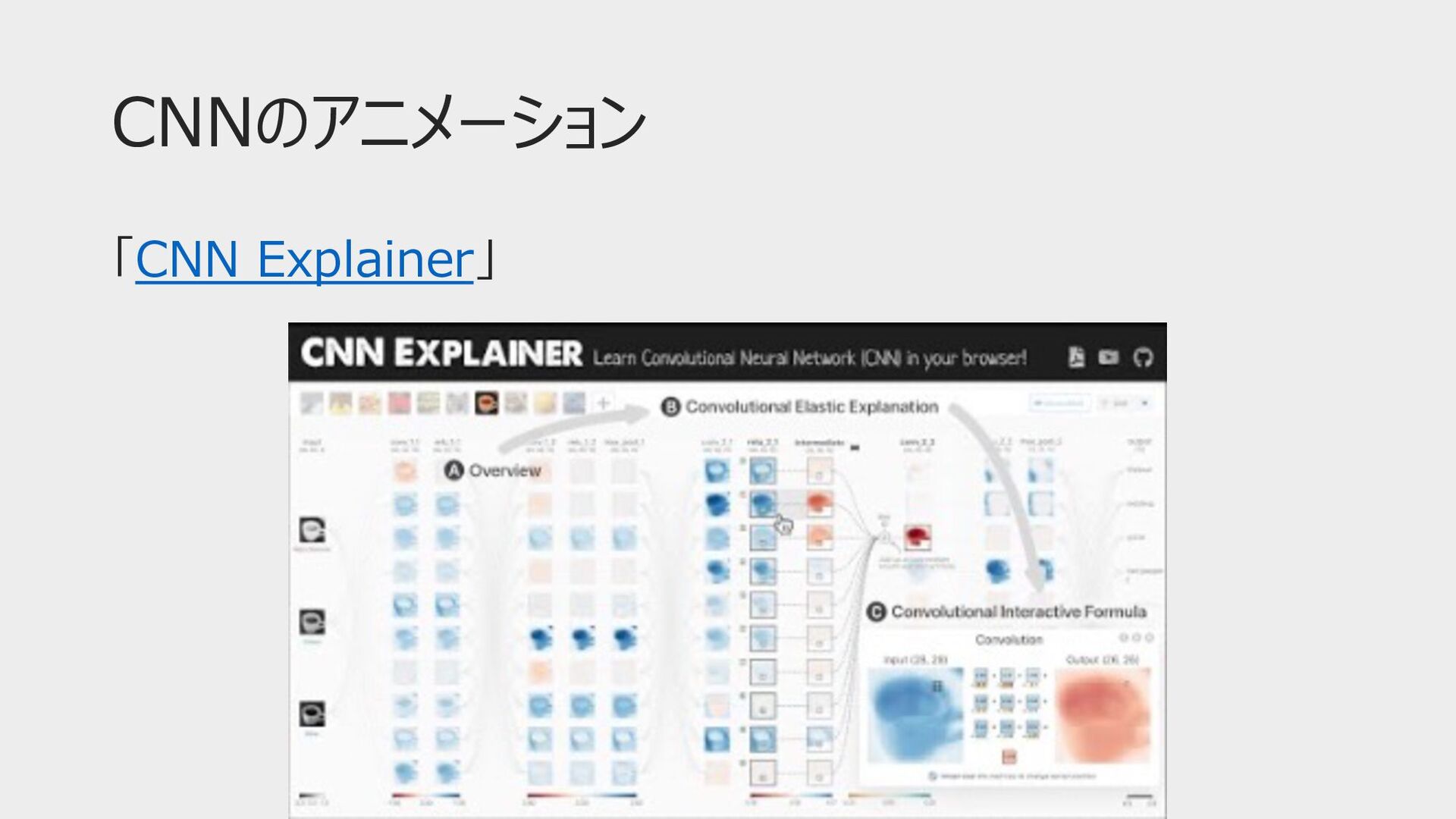
CNNのアニメーション 「CNN Explainer」
ではやってみましょう︕ • 層の数 • チャンネルの数 • 活性化関数の種類 • 最適化アルゴリズムの種類 •
バッチ正規化 • ドロップアウト 精度を上げられるよう に⼯夫してみよう︕
終わりに • ⼤規模で複雑なモデルには莫⼤な計算資源が必要 • ニューラルネットワークはブラックボックス︖ • SIGNATE、Kaggleなどのコンペにぜひ︕ • マネタイズが難しい分野 •
AIに騙されないように︕
アンケートのお願い
引⽤・参考 • https://tjo.hatenablog.com/entry/2020/08/16/153129 • https://axa.biopapyrus.jp/deep-learning/perceptron.html • 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) •
⾼校数学からはじめる深層学習⼊⾨(畳み込みニューラルネットワークの理解) • Chat-GPT(校正と図の出⼒に使⽤)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![flatten → fc1 → relu → fc2 [………] 配列のサイズ 8x8x64](https://files.speakerdeck.com/presentations/585dc2ee882e46b78a50de5462168d9b/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}