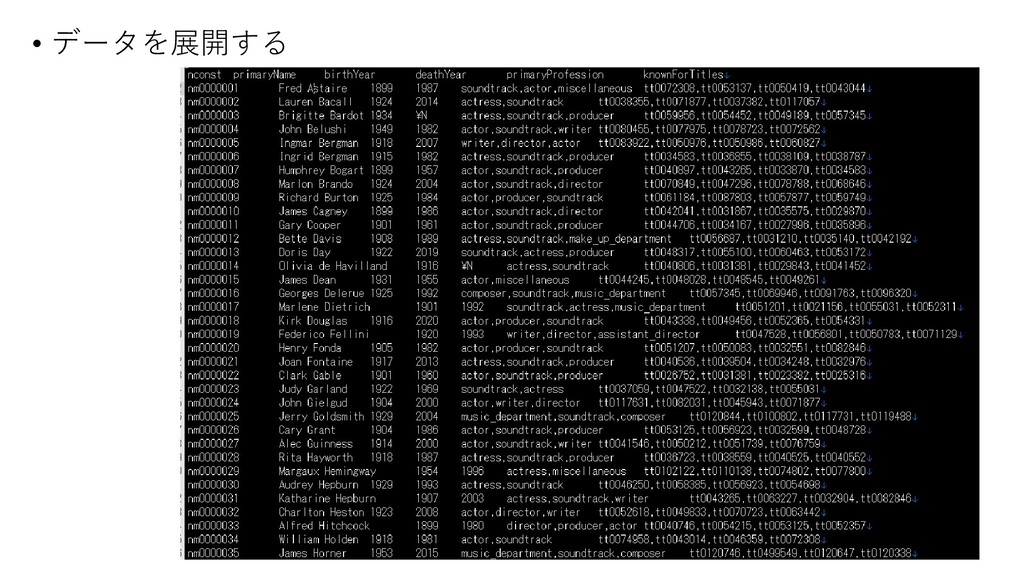
AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10 翻訳; (1.) Select Name と gender と number の合計値を取得 して, number の合計値は total という名前に してね (2.) From `bigquery-public- data.usa_names.usa_1910_2013` というテーブルからデータを取ってきてね (3.) Order by Total の数字が大きな順にしてね (4.) LIMIT 最初から10番目までにしてね
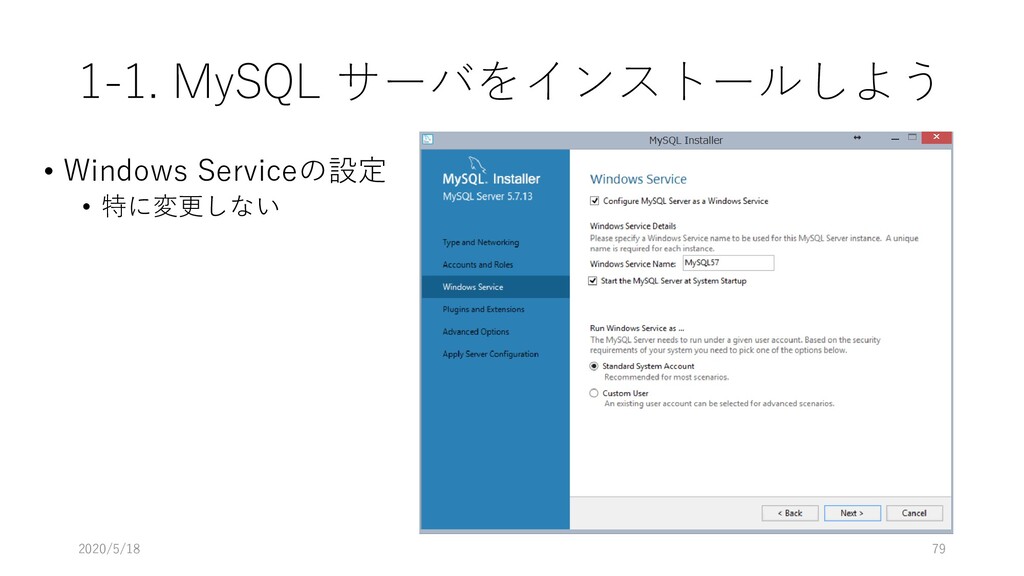
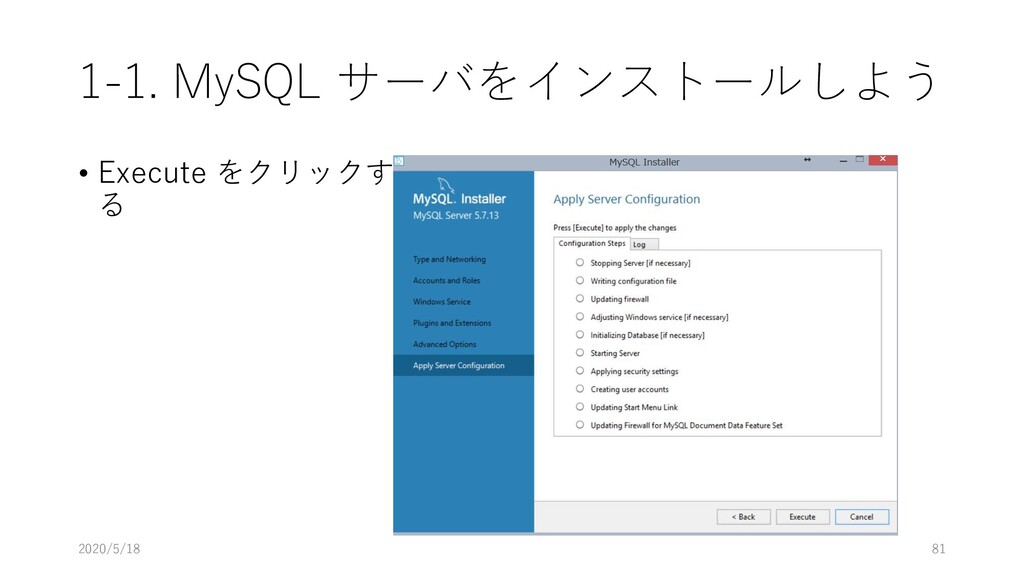
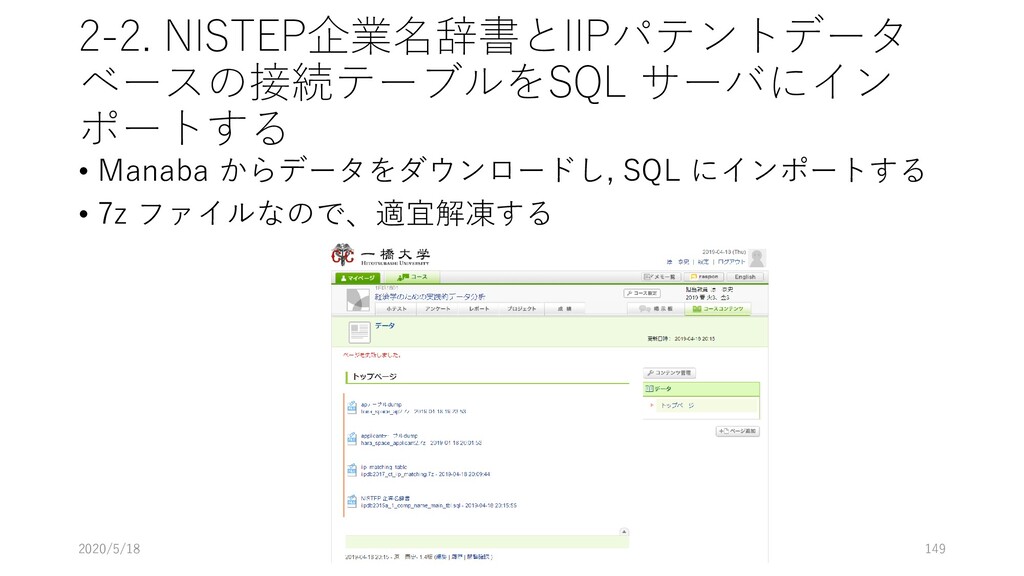
and/or Mac) に構築するため, MySQL Server と MySQL Workbench を導入する 2. Manaba からデータをダウンロードし, MySQL 上にデプロイ する 3. 展開したデータを MySQL Workbench を使って, 初期的な解 析を行う 4. JupyterNotebook からデータを読み込み初期的な解析をする
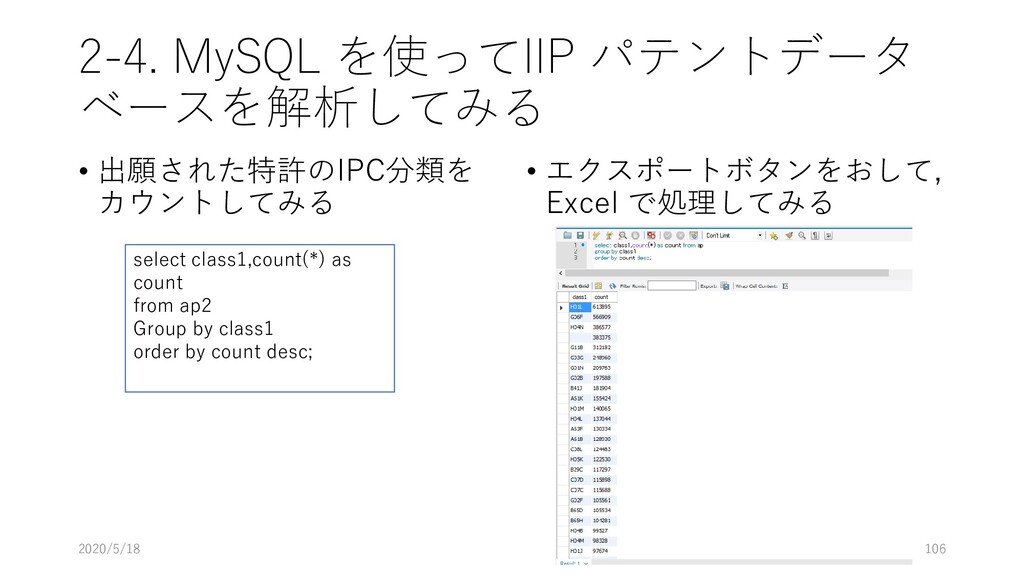
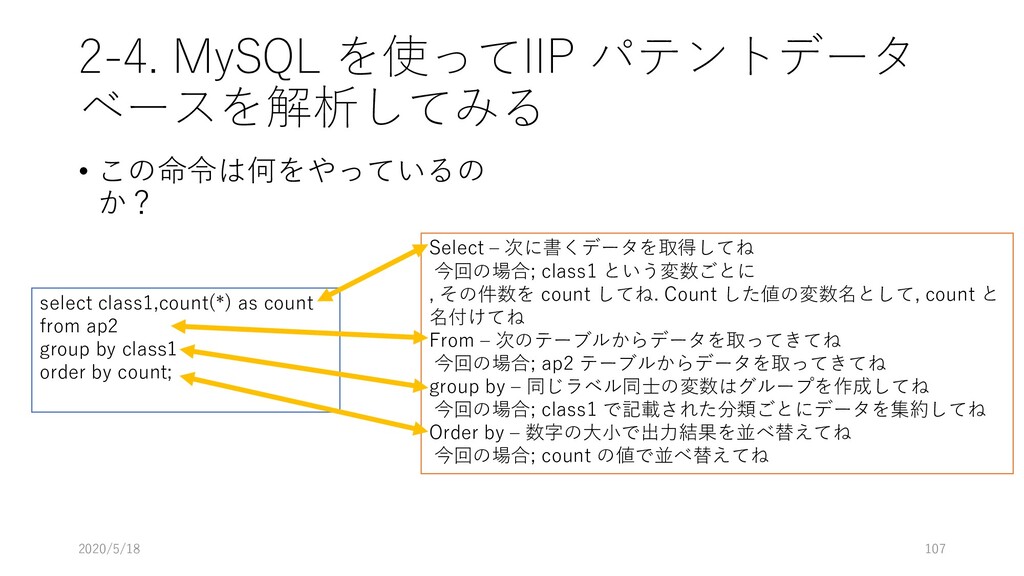
select class1,count(*) as count from ap2 group by class1 order by count; Select – 次に書くデータを取得してね 今回の場合; class1 という変数ごとに , その件数を count してね. Count した値の変数名として, count と 名付けてね From – 次のテーブルからデータを取ってきてね 今回の場合; ap2 テーブルからデータを取ってきてね group by – 同じラベル同士の変数はグループを作成してね 今回の場合; class1 で記載された分類ごとにデータを集約してね Order by – 数字の大小で出力結果を並べ替えてね 今回の場合; count の値で並べ替えてね
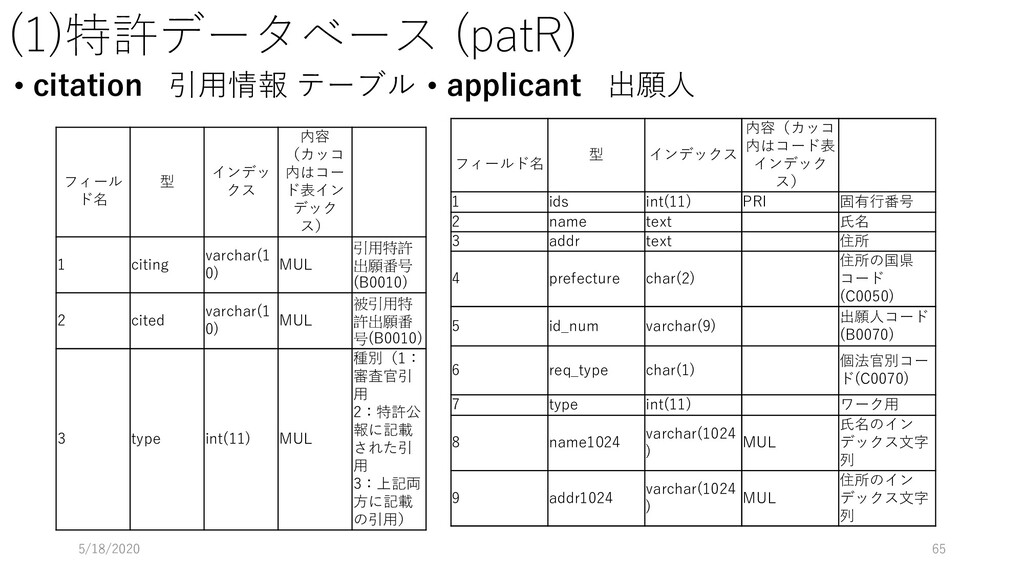
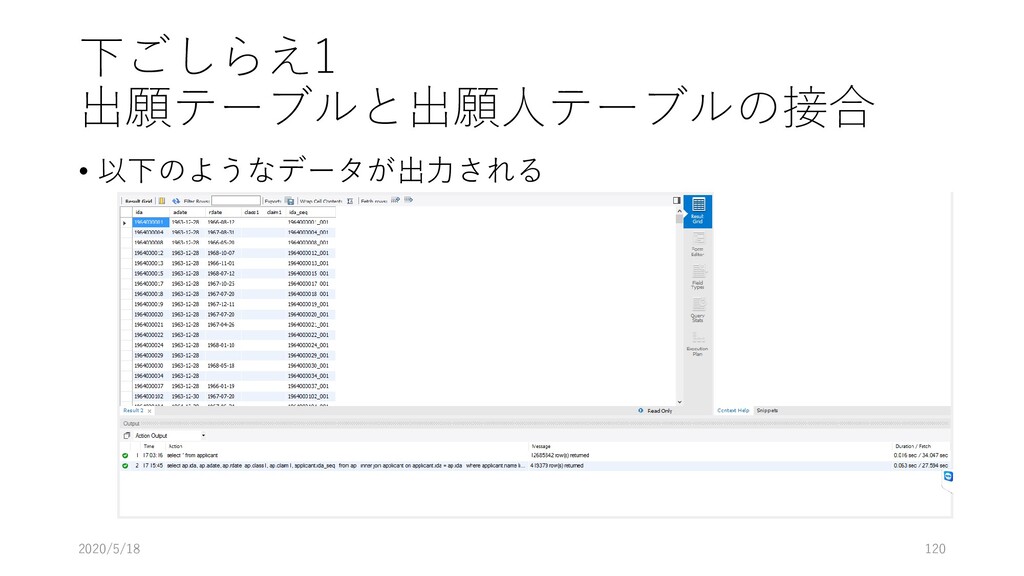
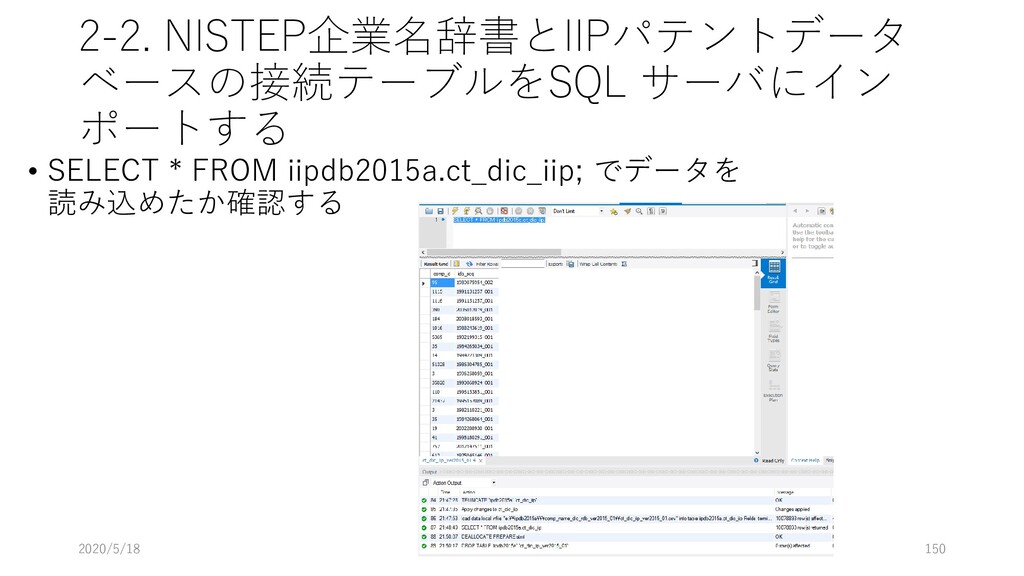
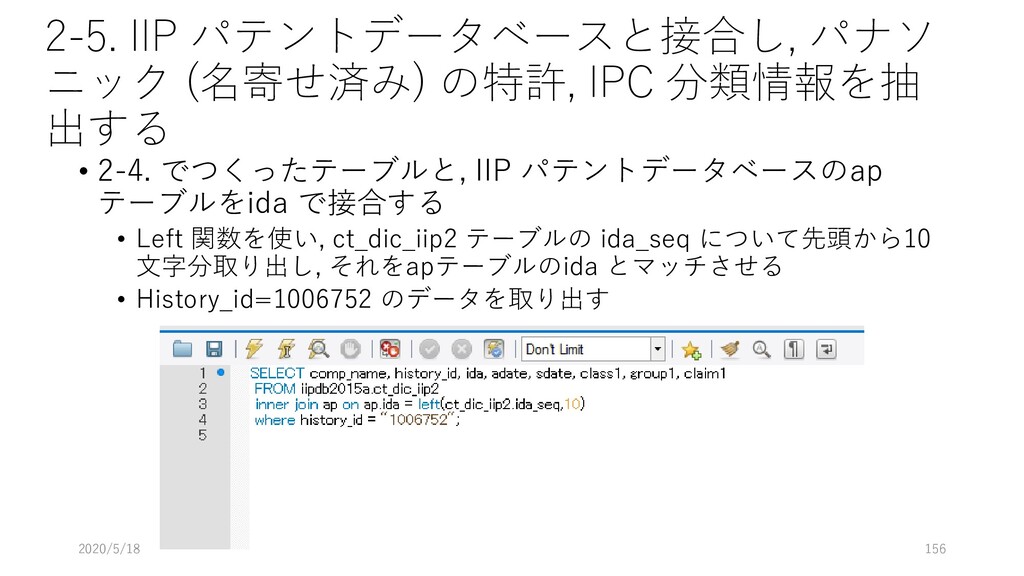
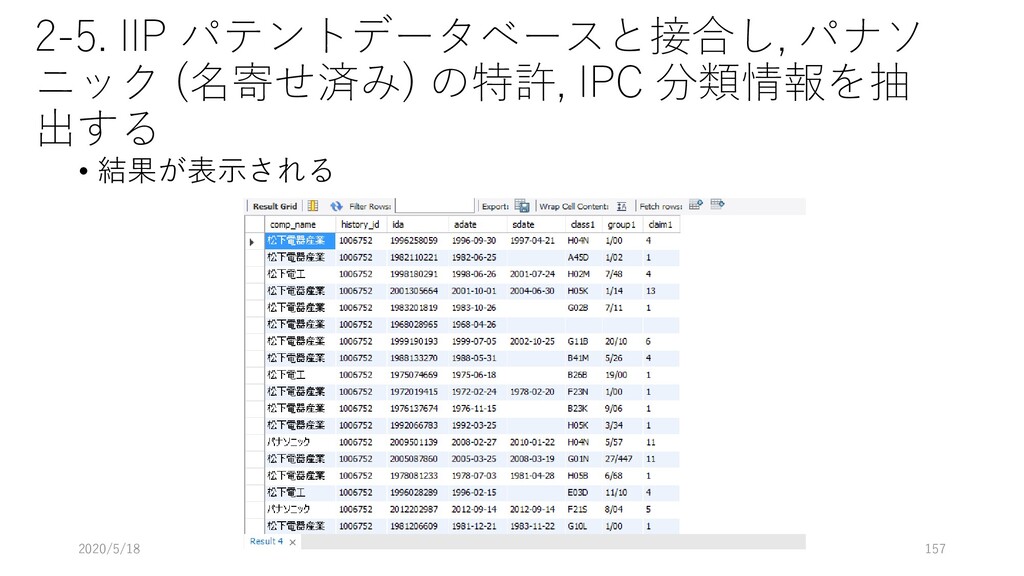
ap テーブルを参照するよ 3行目: applicant テーブルも参照するよ. このとき, applicant の ida フィールドと ap の ida フィールドを キーにして, applicant のデータを取り出してね 4行目: applicant.name が 松下電器産業株式会社 なものを持ってきてね. 2020/5/18 118 select ap.ida, ap.adate, ap.rdate, ap.class1, ap.claim1, applicant.ida_seq from ap inner join applicant on applicant.ida = ap.ida where applicant.name like "松下電器産業株式会社";
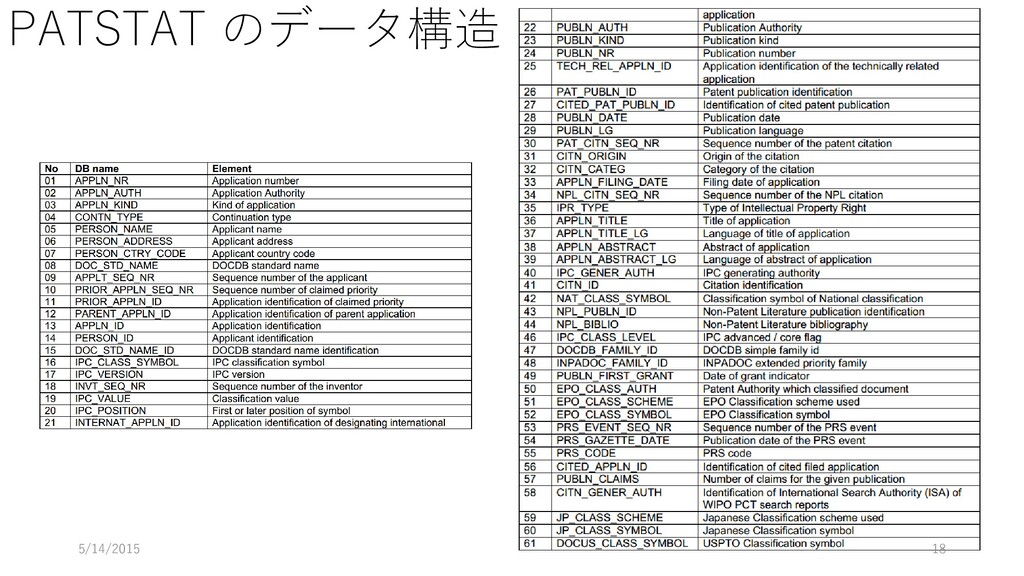
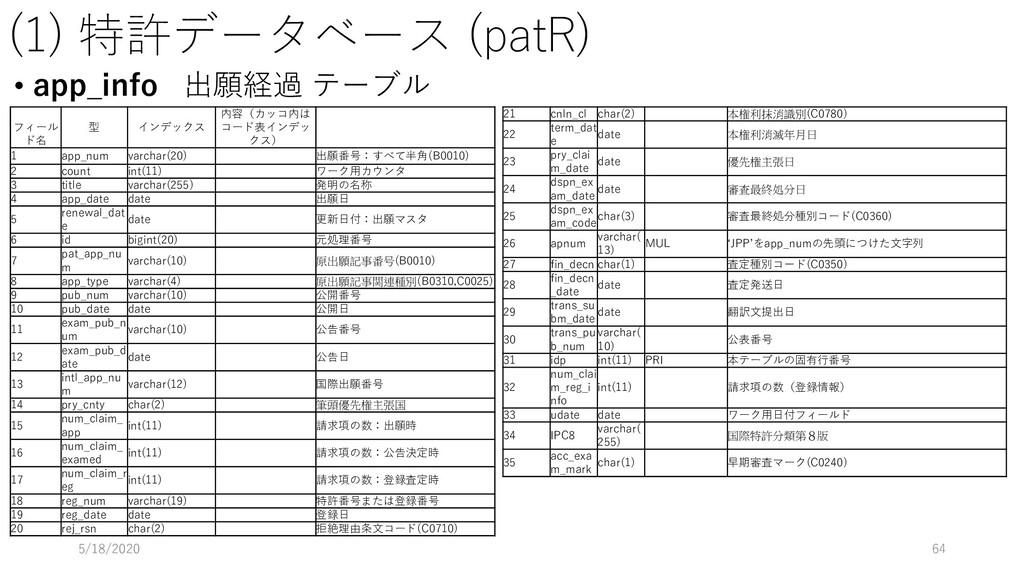
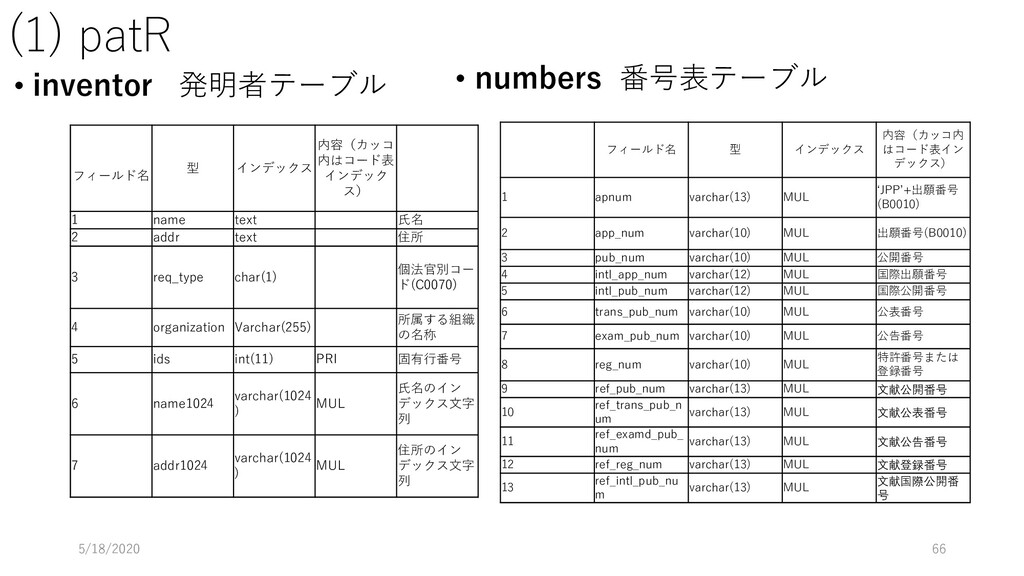
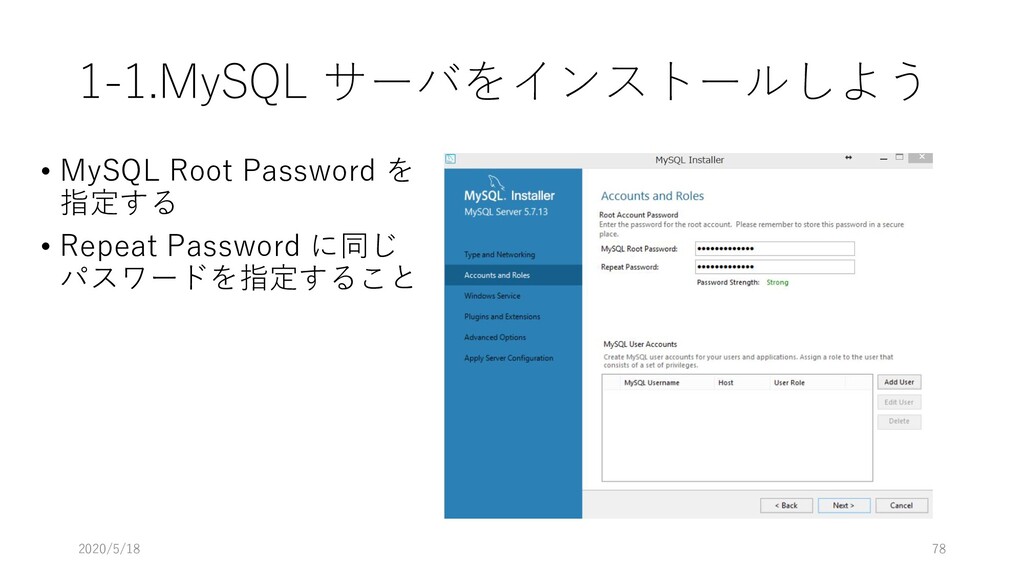
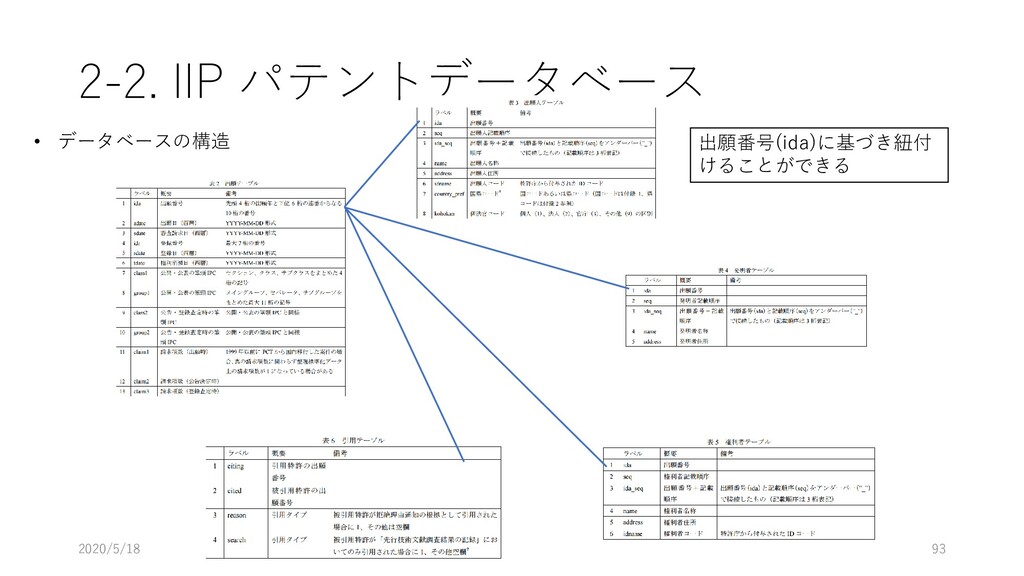
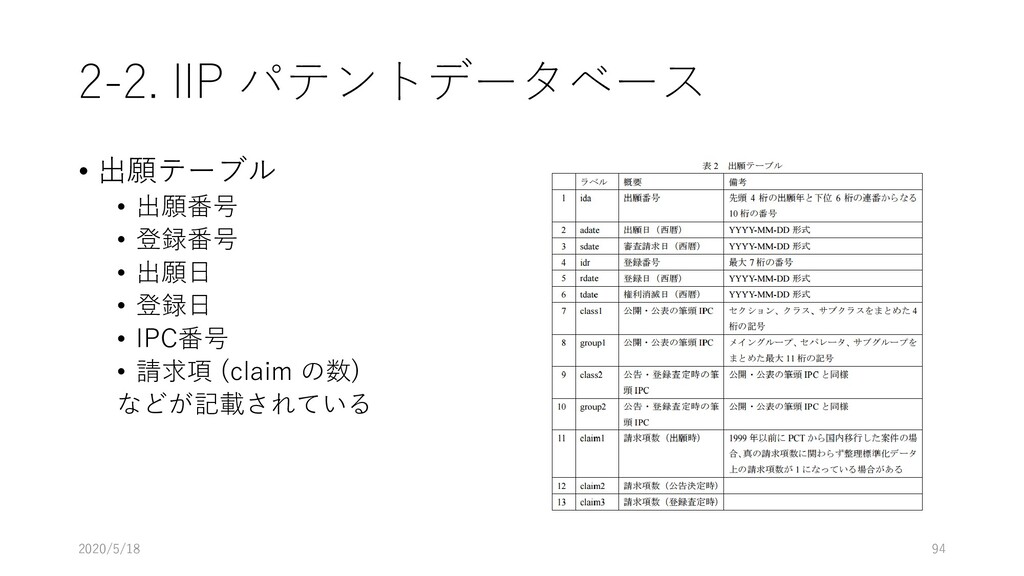
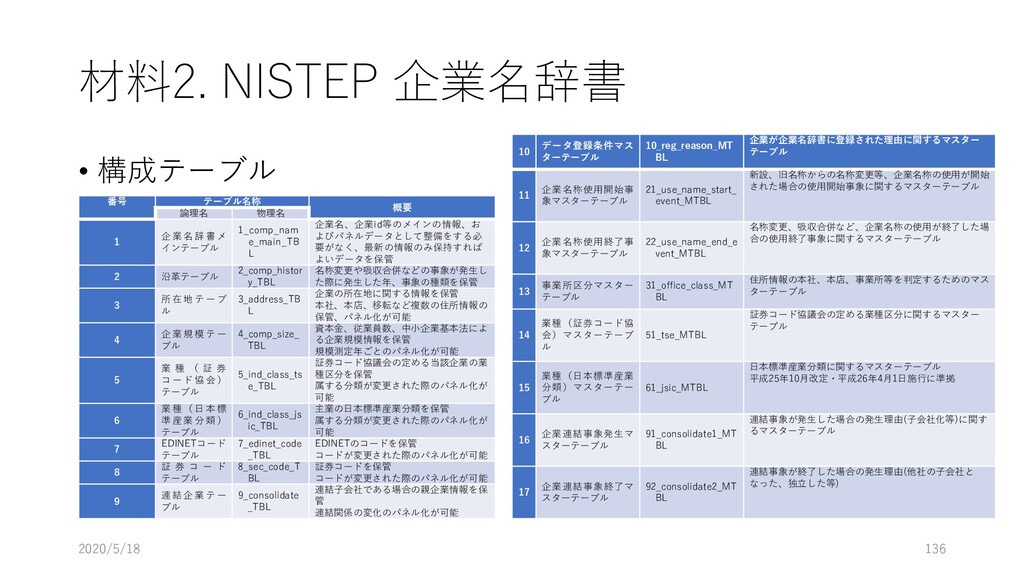
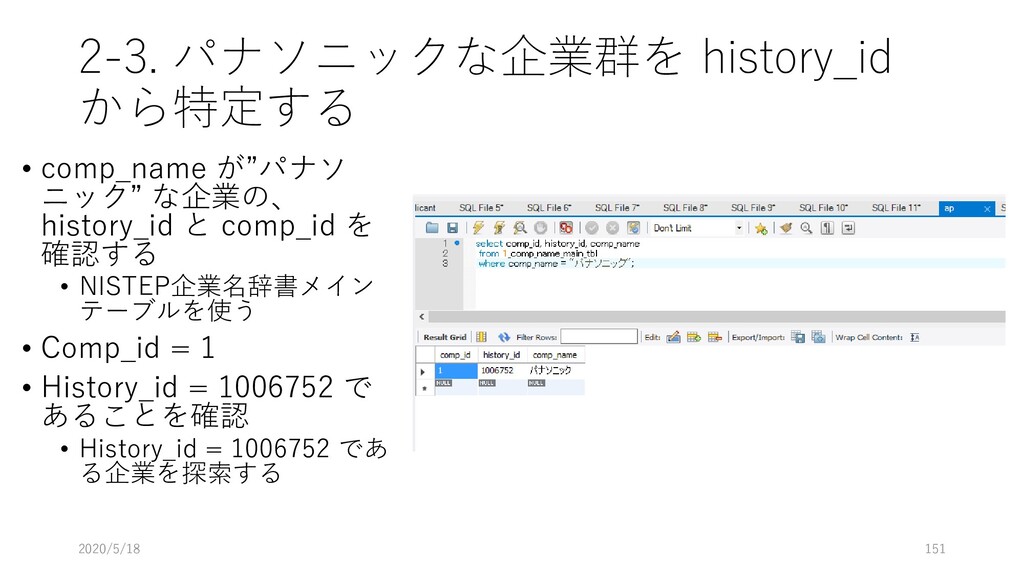
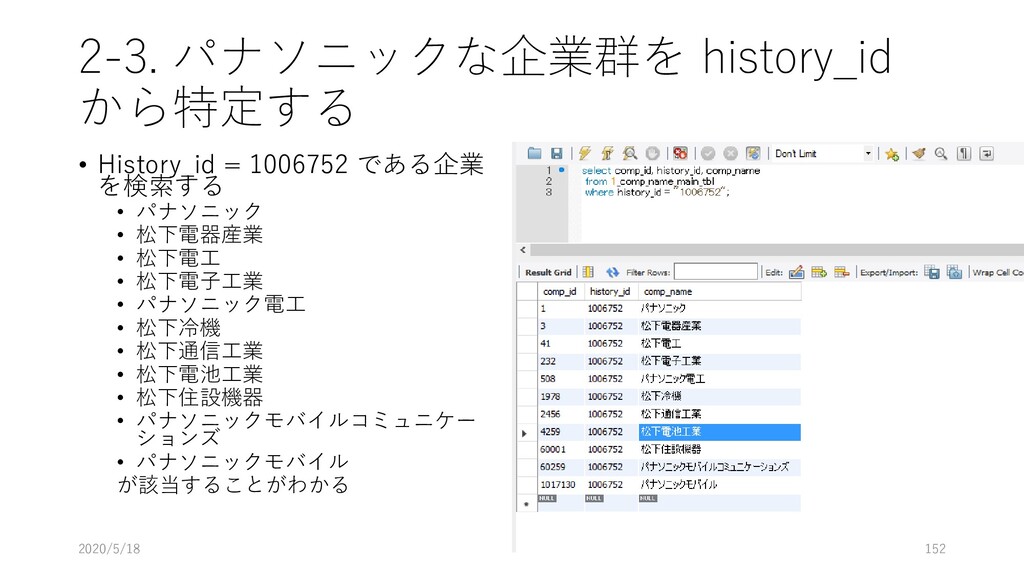
データ型 重複 NULL 主 キー 外部キー 説明 論理名 物理名 企業番号 comp_id 数値 (整数) N N Y 企業(企業名称ごと)に 固有に付与した番号 沿革番号 history_i d 数値 (整数) Y N 同一企業の変遷レコード をグループ化して扱うた めの番号 企業名称 comp_na me 文字列 Y Y 企業の名称(変遷名称も 含む) ふりがな read 文字列 Y Y 上記企業名称のふりがな 法人格 コード comp_co de 文字列 Y Y 企業の法人格を表すコー ド(下表参照) 英語名称 e_name 文字列 Y Y 企業の英語名称 URL url 文字列 Y Y 企業のウェブページの URL データ登 録理由番 号 reg_reas on_id 数値 (整数) Y Y データ登録理由マスター テーブルの理由番号 当該企業の辞書掲載条件 データ 登録日 reg_date 年月日 Y N データを本テーブルに登 録した日 データ 更新日 up_date 年月日 Y N 既登録データの情報更新 した日
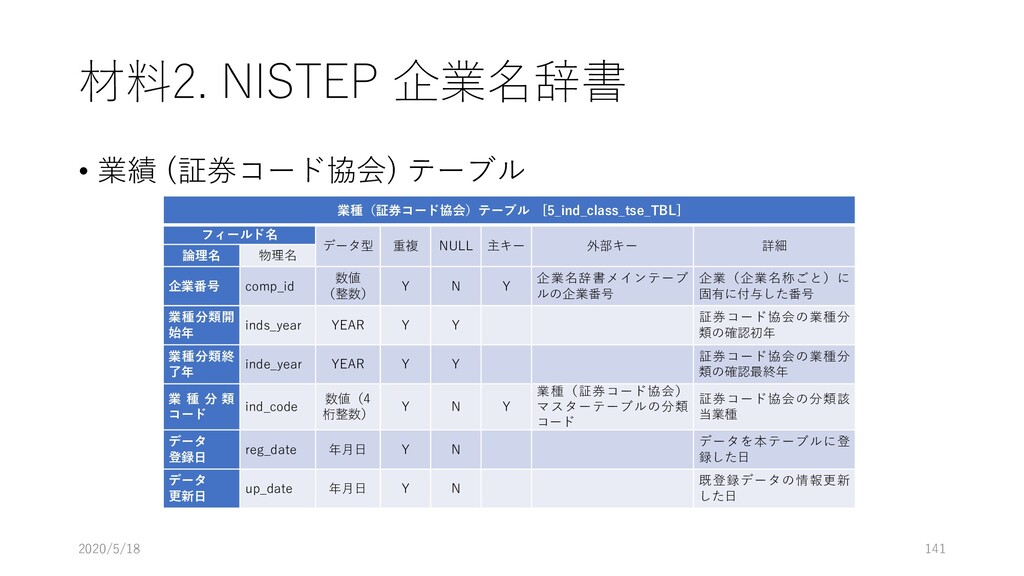
[5_ind_class_tse_TBL] フィールド名 データ型 重複 NULL 主キー 外部キー 詳細 論理名 物理名 企業番号 comp_id 数値 (整数) Y N Y 企業名辞書メインテーブ ルの企業番号 企業(企業名称ごと)に 固有に付与した番号 業種分類開 始年 inds_year YEAR Y Y 証券コード協会の業種分 類の確認初年 業種分類終 了年 inde_year YEAR Y Y 証券コード協会の業種分 類の確認最終年 業 種 分 類 コード ind_code 数値(4 桁整数) Y N Y 業種(証券コード協会) マスターテーブルの分類 コード 証券コード協会の分類該 当業種 データ 登録日 reg_date 年月日 Y N データを本テーブルに登 録した日 データ 更新日 up_date 年月日 Y N 既登録データの情報更新 した日
• https://www.imdb.com/interfaces/ • Dataset ごとに tsv 形式で提供されているので、それをダウンロードする • title.akas.tsv.gz - Contains the following information for titles: • title.basics.tsv.gz - Contains the following information for titles: • title.crew.tsv.gz – Contains the director and writer information for all the titles in IMDb. • title.episode.tsv.gz – Contains the tv episode information. Fields include: • title.principals.tsv.gz – Contains the principal cast/crew for titles • title.ratings.tsv.gz – Contains the IMDb rating and votes information for titles • name.basics.tsv.gz – Contains the following information for names:
only the famous ‘right to be left alone’ or keeping one’s personal matters and relationships secret, but also the ability to share information selectivity but not publicly. • Confidentially • Confidentiality is preserving authorized restrictions on information access and disclosure, including means for protecting personal privacy and proprietary information.
benefit society. At the same time, its availability creates significant potential for mistaken, misguided or malevolent uses of personal information. • The conundrum for the law is to provide space for big data to fulfill its potential for social benefit, while protecting citizens adequately from related individual and social harms. Current privacy law evolved to address different concerns and must be adapted to confront big data’s challenges.”
(Personal Identifiable Information) • Any Information About an individual maintained by an agency, including (1) any information that can be used to distinguish or trace an individual’s identity, such as name, social security number, data and place of birth, mother’s maiden name, or biometric records; and (2) any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information. • 日本の場合 • 保険番号, パスポート番号, 名前, 住所, マイナンバー(ここ数年)
されていない危険性 • “Similarly, overreliance on, say, Twitter Data, in targeting resources after harricanes can lead to misallocation of resources towards young, Internet-savvy people with cell phones and away from elderly or impoverished neighbourhoods” https://azanaerunawano5to4.hatenablog.com/ entry/2015/09/03/101948
and Methods that ensure the confidentiality of micro and aggregated that are to be published. It is methodology used to design statistical outputs in a way that someone with access to that output cannot relate a known individual (or other responding unit) to an element in the output.
Big Data are often structured in such a way that essentially everyone in the file is unique, either because so many variables exist or because they are so frequent or geographically detailed, that they make it easy to reidentify individual pattarns.” • “There are no data stewards controlling access to individual data. Data are often so interconnected (think social media network data) that one person’s action can disclose information about another person without that person even knowing that their data are being accessed.”
instance, an attacker (or commercial actor) might instead infer a rule that relates a string of more easily observable or accessible indicators to a specific medical condition, rendering large populations vulnerable to such inferences even in the absence of PII. Ironically, this is often the very thing about big data that generate the most excitement: the capability to detect subtle correlations and draw actionable inferences. But it is this same feature that renders the traditional protections afforded by anonymity (again, more accurately, pseudosymmetry) much less effective.”
namelessness, and not even in the extension of the previous value of namelessness to all uniquely identifying information, but instead to something we called “reachability, ” the possibility of knocking on your door, hauling you out of bed, calling your phone number, threatening you with sanction, holding you accountable – with or without access to identifying information.
no longer in statistical agencies, with well-defined rules of conduct, but in businesses or administrative agencies. In addition, since digital data can be alive forever, ownership could be claimed by yet-to-be-born relatives whose personal privacy could be threatened by release of information about blood relations.” • “Traditional regulatory tools for managing privacy, notice, and consent have failed to provide a viable market mechanism allowing a form of self-regulation governing industry data collection”
account the varying levels of inherent risk to individuals across different data sets • (2) traditional definitions of PII need to be rethought • (3) regulation has a role in creating and policing walls between data sets • (4) those analyzing big data must be reminded, with a frequency in proportion to the sensitivity of the data, that they are dealing with people • (5) the ethics of big data research must be an open topic for continual reassessment.
{kind=link}
![今日の内容 • 13:00-13:15 • プレ講義 [録画なし] • 13:15-13:35 • 4.1データベース101](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Big Query のはじめかた(4) • 4. [完了]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
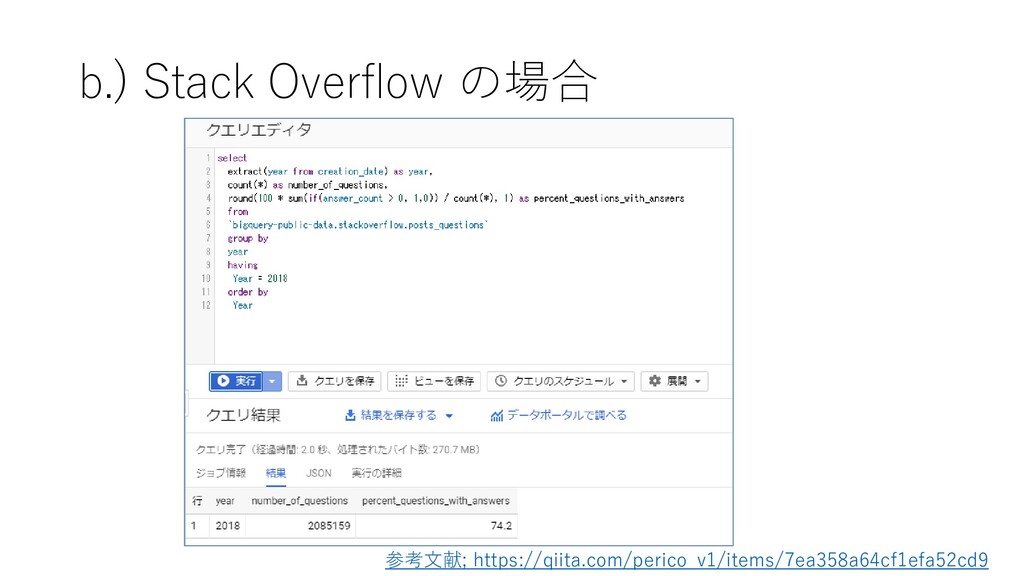
![Google Big Query でクエリを打ってみる(3) • [実行]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_41.jpg){kind=link}
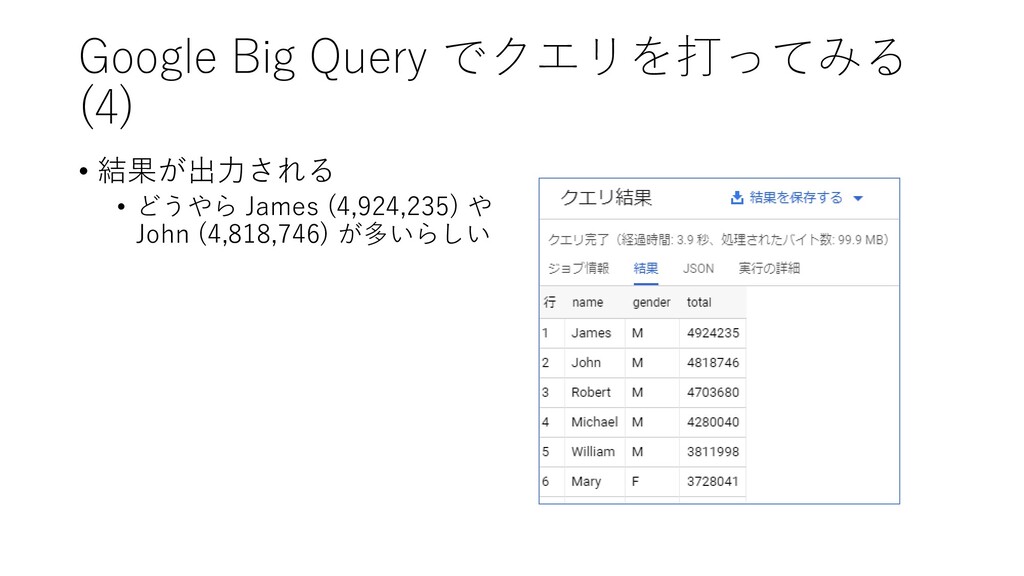{kind=link}
![Google Big Query でクエリを打ってみる (5) • [データポータルで調べる]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_43.jpg){kind=link}
![Google Big Query でクエリを打ってみる(6) • [使ってみる]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_44.jpg){kind=link}
![Google Big Query でクエリを打ってみる(7) • [承認]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_45.jpg){kind=link}
![Google Big Query でクエリを打ってみる(8) • [許可]をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_46.jpg){kind=link}
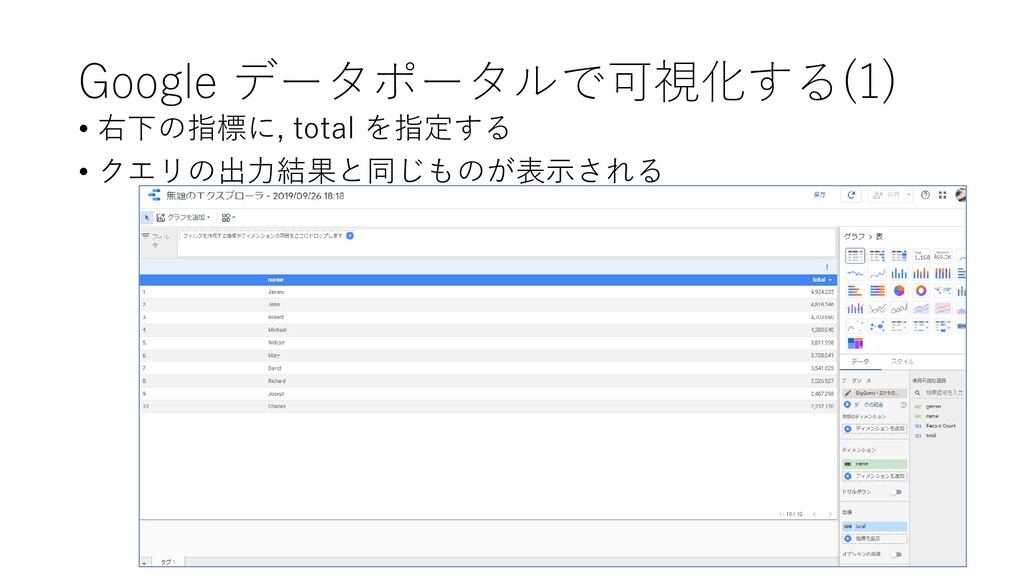{kind=link}
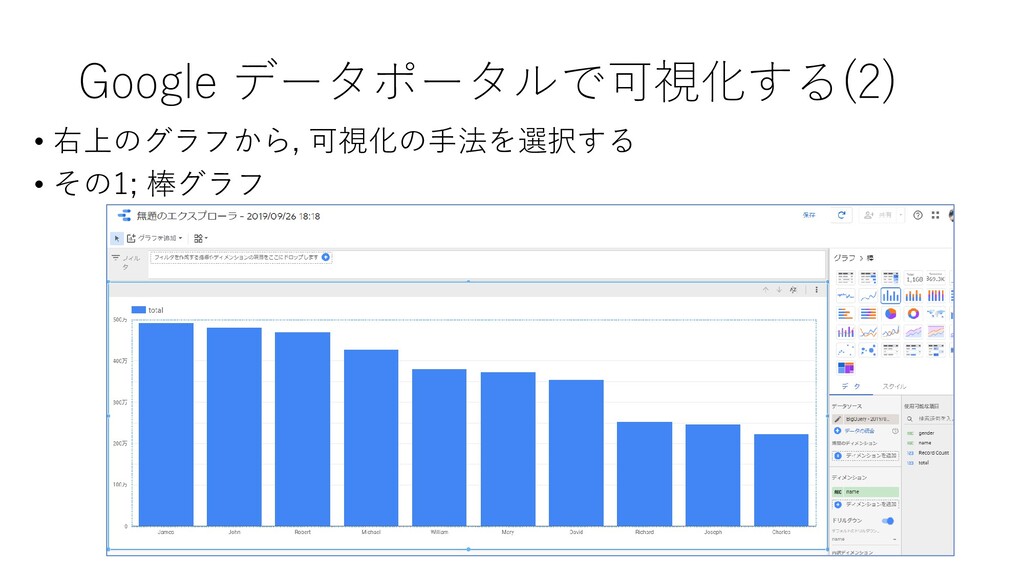{kind=link}
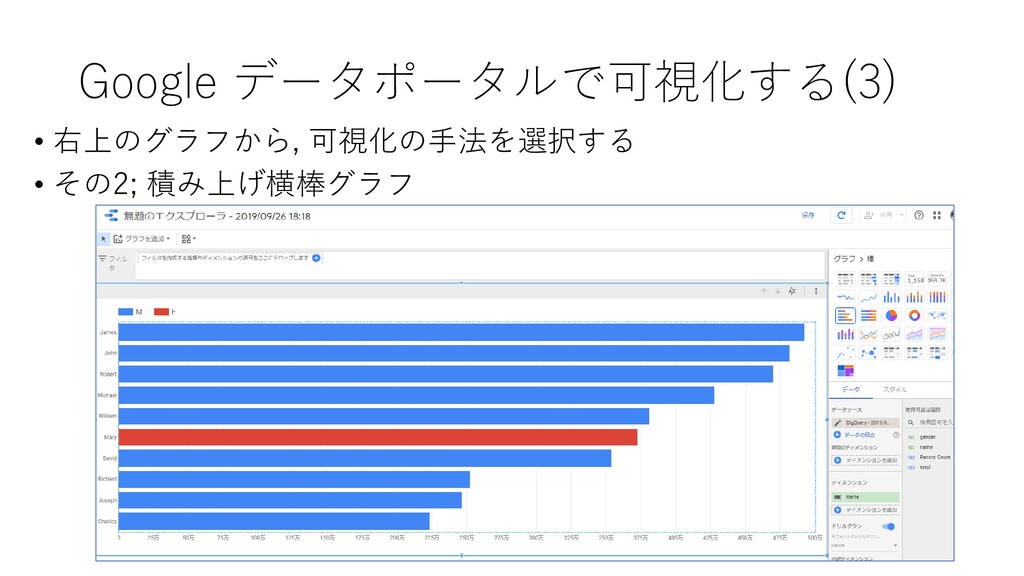{kind=link}
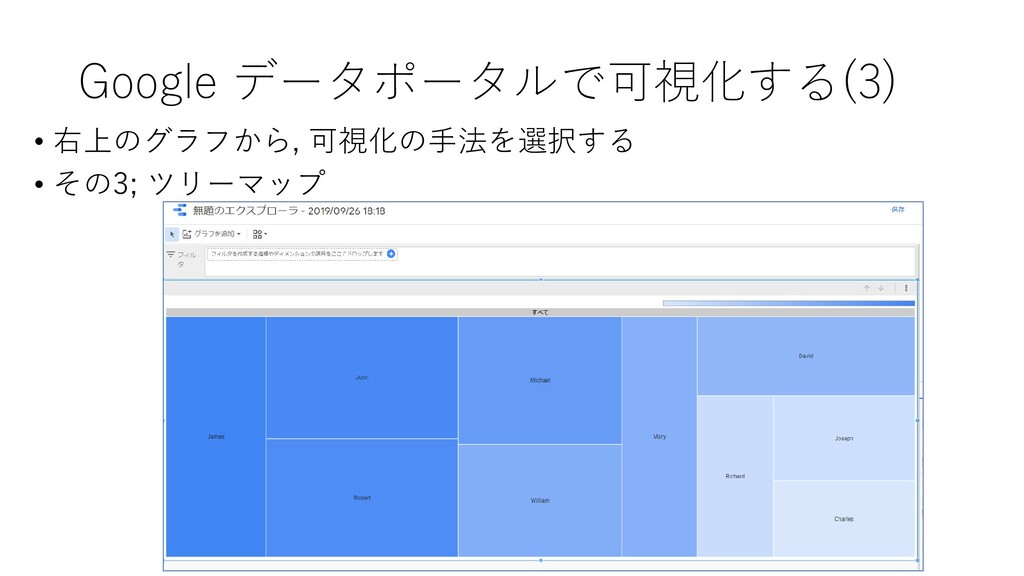{kind=link}
{kind=link}
![利用できるデータセット • リソース から, [+ データを追加] をクリックする](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_52.jpg){kind=link}
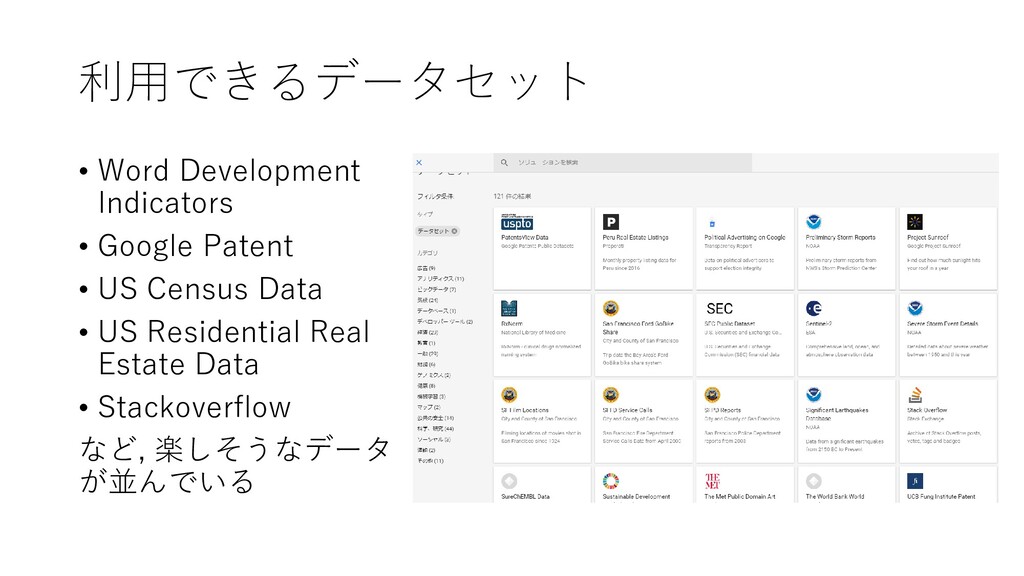{kind=link}
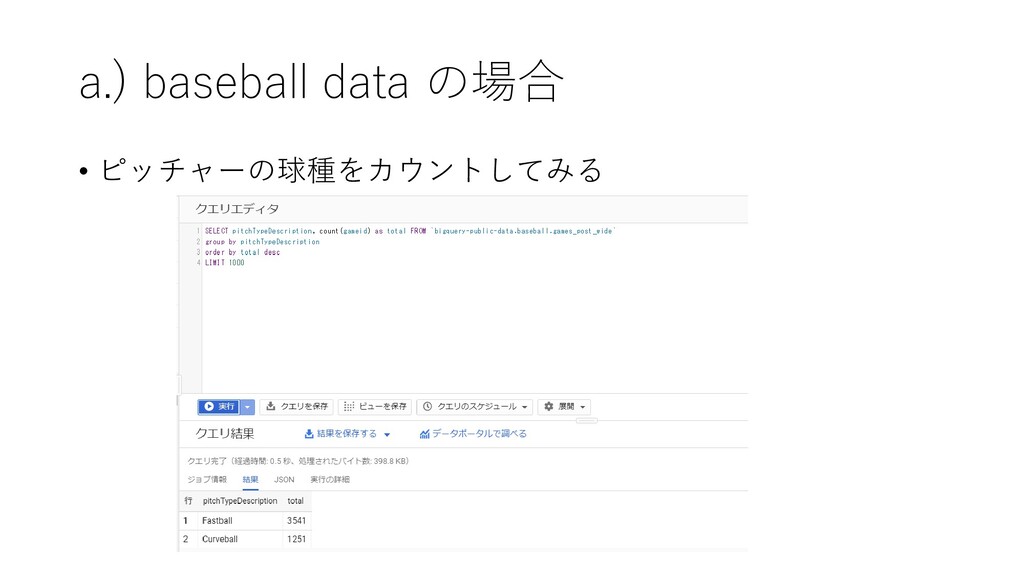{kind=link}
{kind=link}
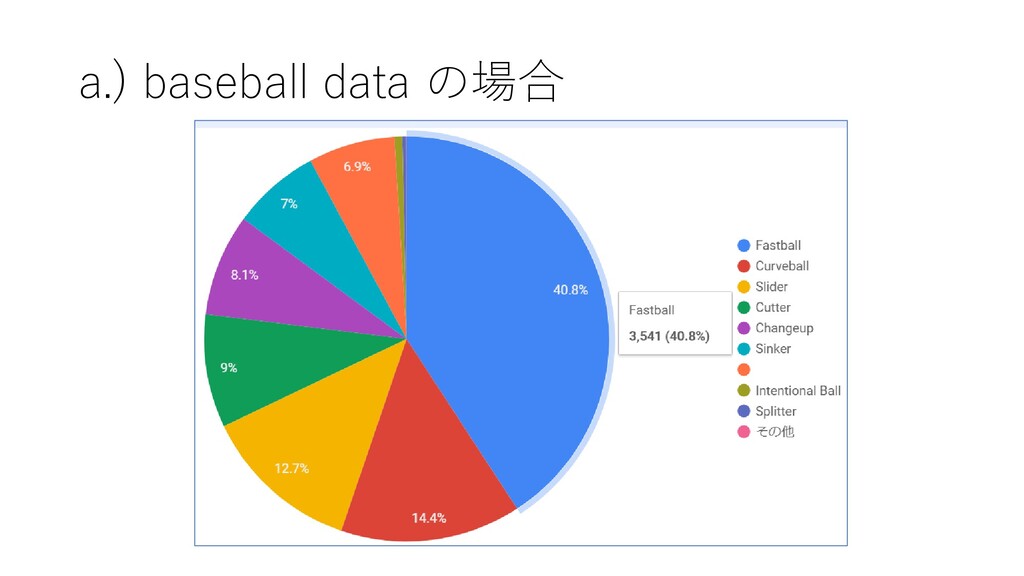{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
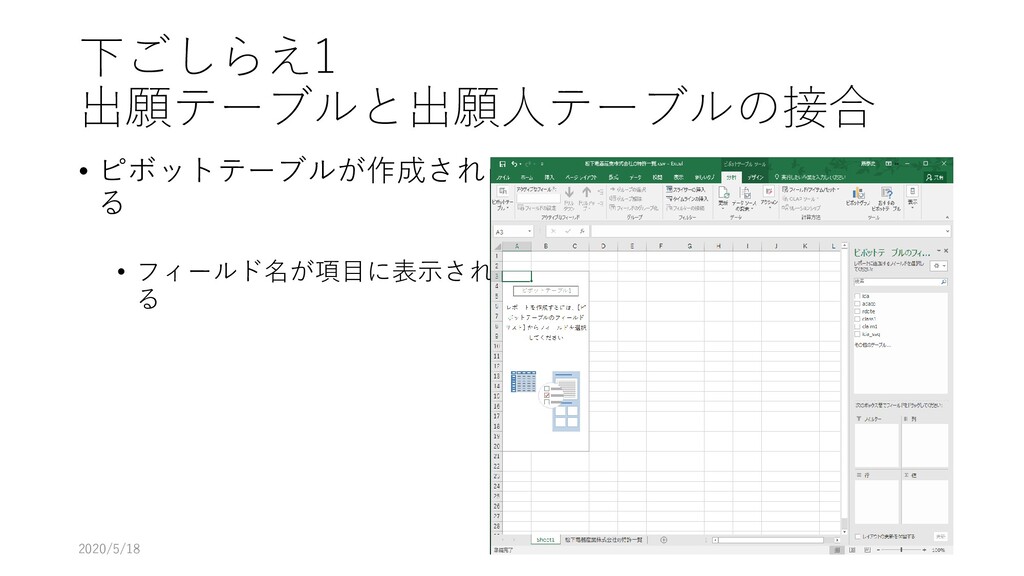
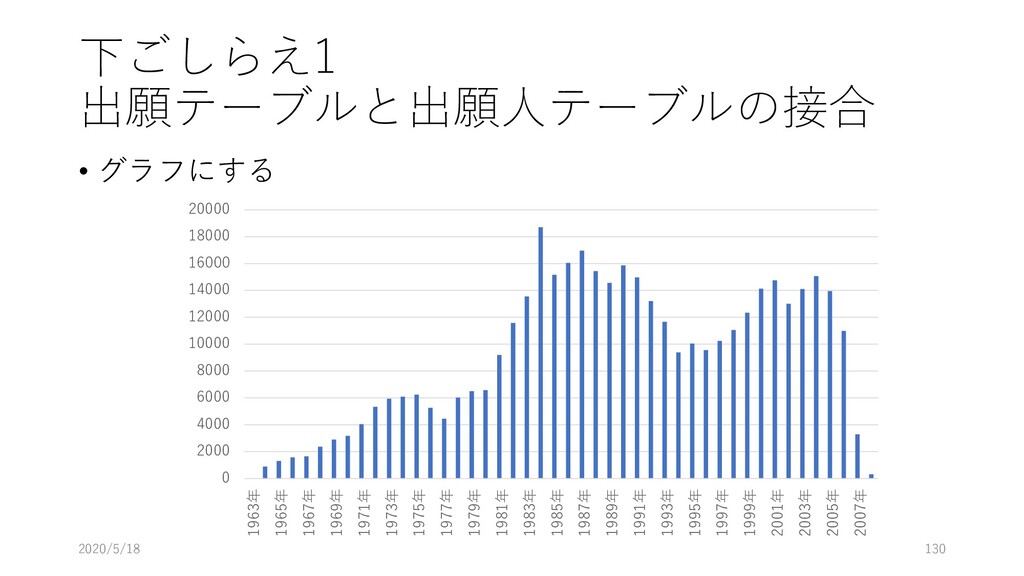
![下ごしらえ1 出願テーブルと出願人テーブルの接合 • ピボットテーブルを作る • [挿入]-[ピボットテーブル]を選 択 • ピボットテーブルの範囲が選 択されていることを確認し、](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_123.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![材料2. NISTEP 企業名辞書 • 企業名辞書メインテーブル 2020/5/18 139 企業名辞書メインテーブル [1_comp_name_main_TBL] フィールド名](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_138.jpg){kind=link}
![材料2. NISTEP 企業名辞書 • 企業規模テーブル 2020/5/18 140 企業規模テーブル [4_comp_size_TBL] フィールド名](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_139.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/6f38712b4c0c418f810480dbf4aab370/slide_202.jpg){kind=link}