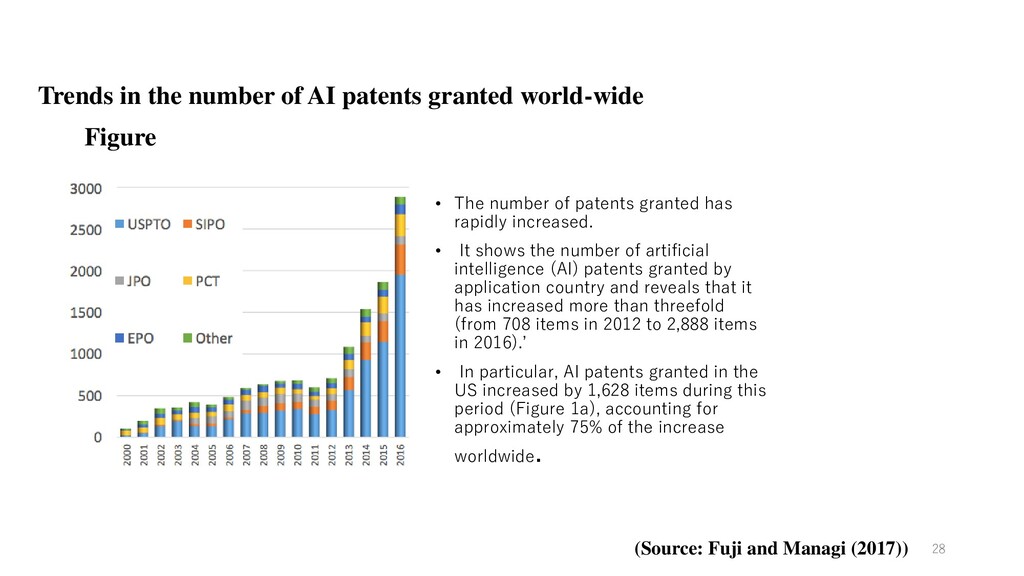
• The number of patents granted has rapidly increased. • It shows the number of artificial intelligence (AI) patents granted by application country and reveals that it has increased more than threefold (from 708 items in 2012 to 2,888 items in 2016).’ • In particular, AI patents granted in the US increased by 1,628 items during this period (Figure 1a), accounting for approximately 75% of the increase worldwide . 28 (Source: Fuji and Managi (2017))
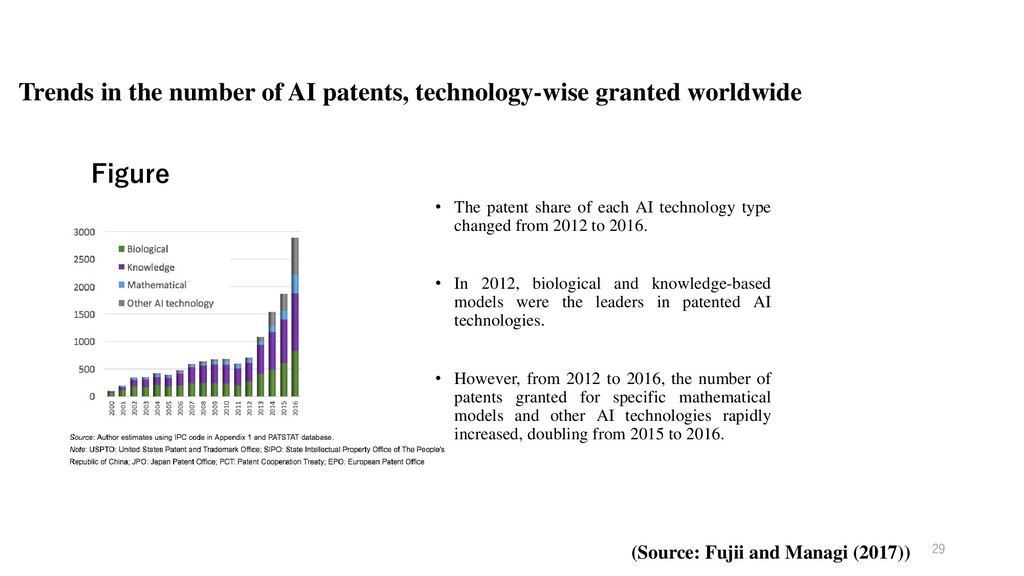
Figure • The patent share of each AI technology type changed from 2012 to 2016. • In 2012, biological and knowledge-based models were the leaders in patented AI technologies. • However, from 2012 to 2016, the number of patents granted for specific mathematical models and other AI technologies rapidly increased, doubling from 2015 to 2016. 29 (Source: Fujii and Managi (2017))
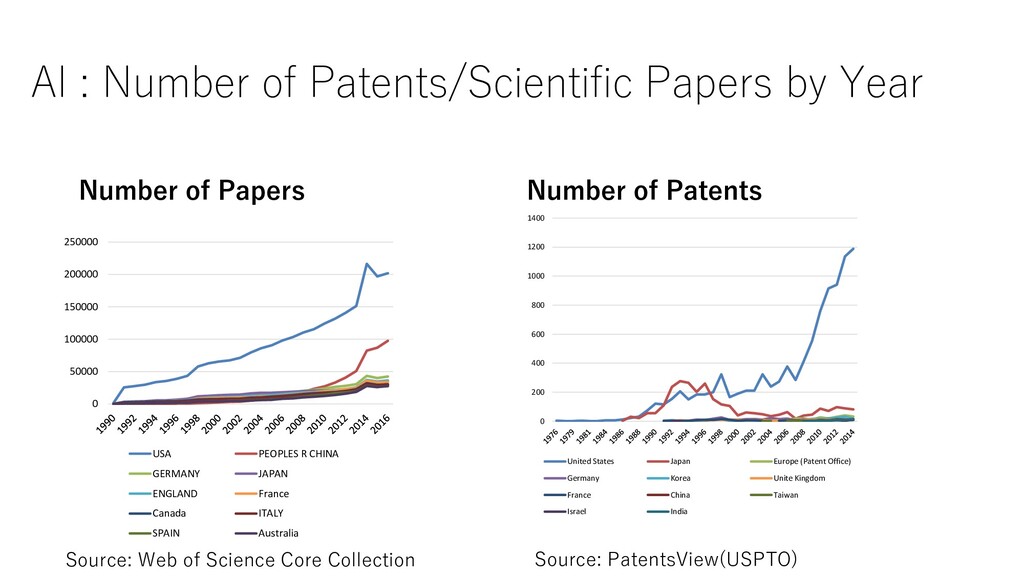
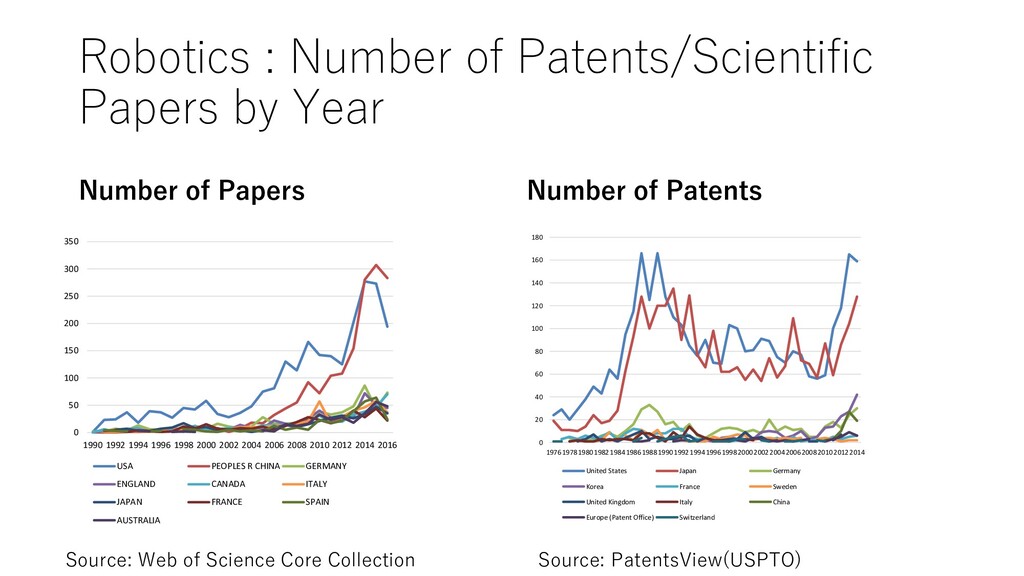
Papers Number of Patents 0 50000 100000 150000 200000 250000 USA PEOPLES R CHINA GERMANY JAPAN ENGLAND France Canada ITALY SPAIN Australia 0 200 400 600 800 1000 1200 1400 United States Japan Europe (Patent Office) Germany Korea Unite Kingdom France China Taiwan Israel India Source: Web of Science Core Collection Source: PatentsView(USPTO)
Papers Number of Patents Source: Web of Science Core Collection Source: PatentsView(USPTO) 0 50 100 150 200 250 300 350 1990 1992 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014 2016 USA PEOPLES R CHINA GERMANY ENGLAND CANADA ITALY JAPAN FRANCE SPAIN AUSTRALIA 0 20 40 60 80 100 120 140 160 180 19761978198019821984198619881990199219941996199820002002200420062008201020122014 United States Japan Germany Korea France Sweden United Kingdom Italy China Europe (Patent Office) Switzerland
MANAGI Shunsuke (2017) «Trends and Priority Shifts in Artificial Intelligence Technology Invention: A global patent analysis», RIETI Discussion Paper Series 17-E-066, https://www.rieti.go.jp/jp/publications/dp/17e066.pdf • The Economics of Artificial Intelligence: An Agenda, https://www.nber.org/books/agra-1
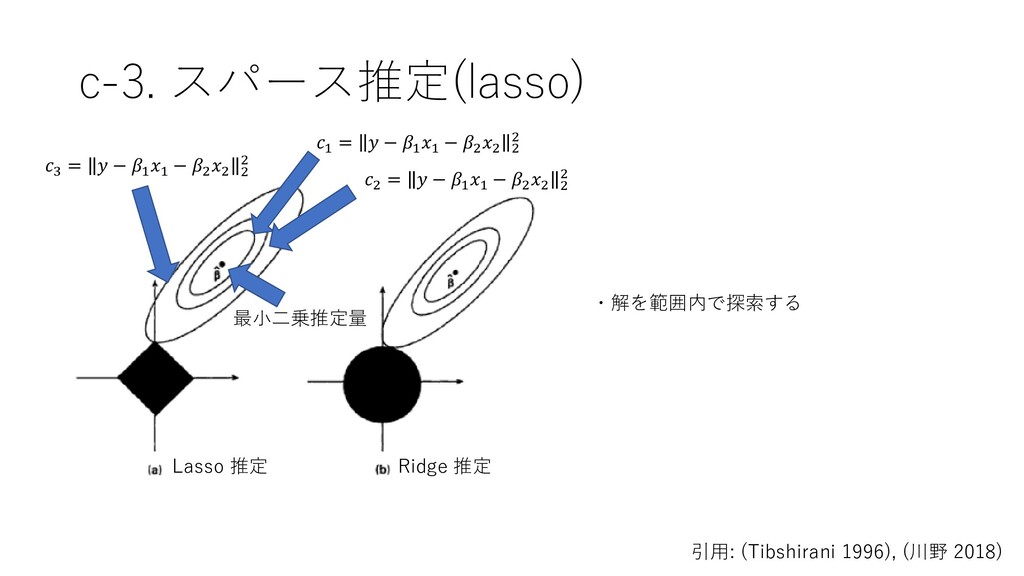
the Lasso, Journal of the Royal Statistical Society. Series B, 58, 1, pp. 267-288, https://www.jstor.org/stable/2346178 • 川野秀一(2019) スパース推定に基づく統計モデリング, HIAS Health ビッグデータ・ICT勉強会 • 川野秀一・松井秀俊・廣瀬慧 (2018) スパース推定法による統 計モデリング, 統計学 One Point
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3-12. 散布図をプロットしてみる import seaborn as sns sns.jointplot(y_test[:,0],pred_test[:,0])](https://files.speakerdeck.com/presentations/06828a08434d4332bde3a58602fd56f3/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/06828a08434d4332bde3a58602fd56f3/slide_102.jpg){kind=link}