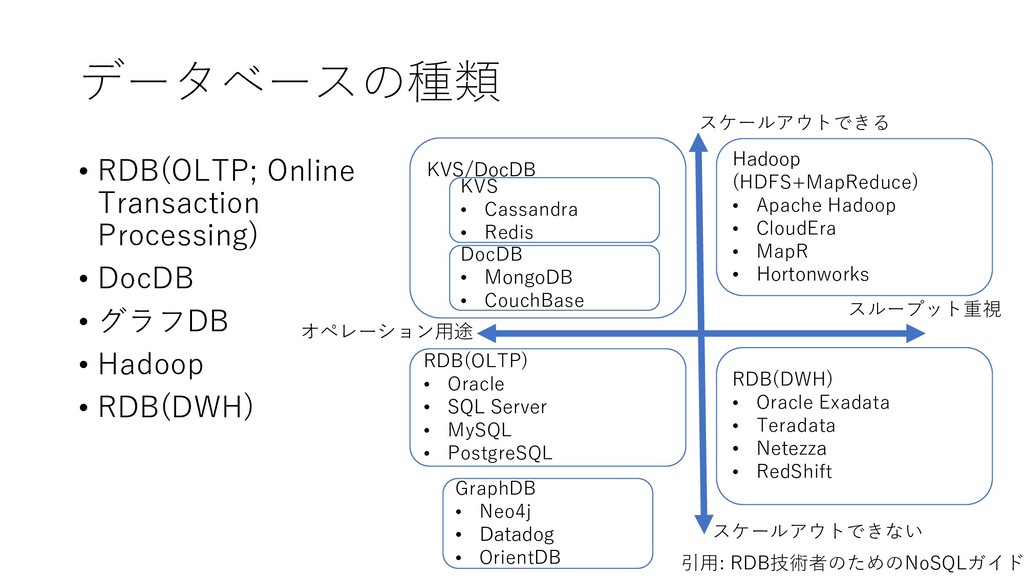
numberOfCommonApplications, p1.doc_std_name as name1, p1.person_ctry_code as cc1, p2.doc_std_name as name2, p2.person_ctry_code as cc2 FROM tls206_person p1 JOIN tls207_pers_appln pa1 ON p1.person_id = pa1.person_id JOIN tls207_pers_appln pa2 ON pa1.appln_id = pa2.appln_id JOIN tls206_person p2 ON pa2.person_id = p2.person_id join tls201_appln p3 on pa1.appln_id = p3.appln_id WHERE p1.person_ctry_code = 'JP' AND p3.appln_filing_date >= '2014-01-01' AND p3.appln_filing_date <= '2014-12-31‘ AND pa1.appln_id > 0 AND pa2.appln_id > 0 AND p1.person_ctry_code <> p2.person_ctry_code GROUP by p1.doc_std_name, p1.person_ctry_code, p2.doc_std_name, p2.person_ctry_code ORDER BY numberOfCommonApplications DESC, p1.doc_std_name ASC, p2.doc_std_name ASC 5/14/2015 28 クエリ; データを取り出す上での約束事を明記 したもの
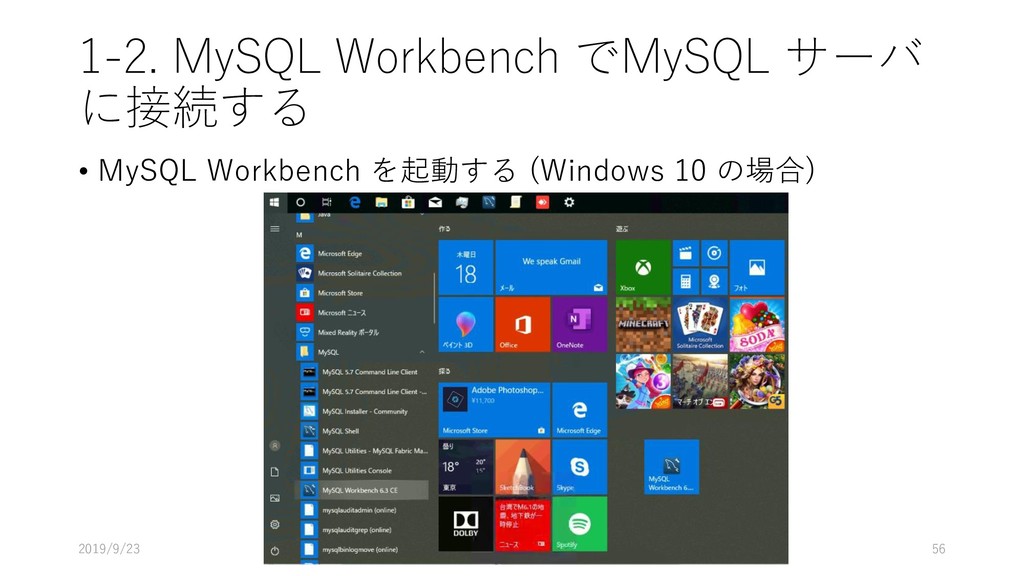
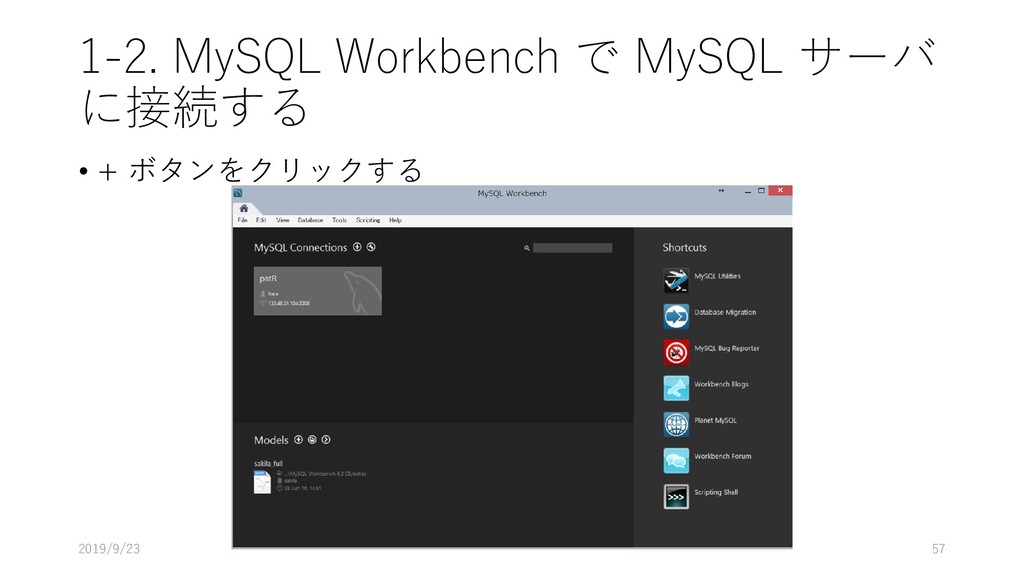
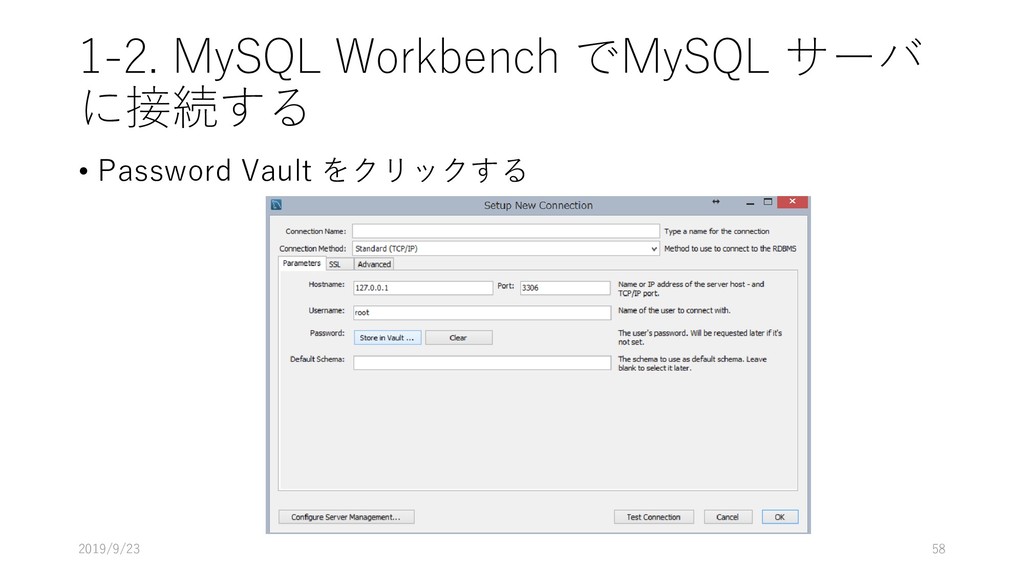
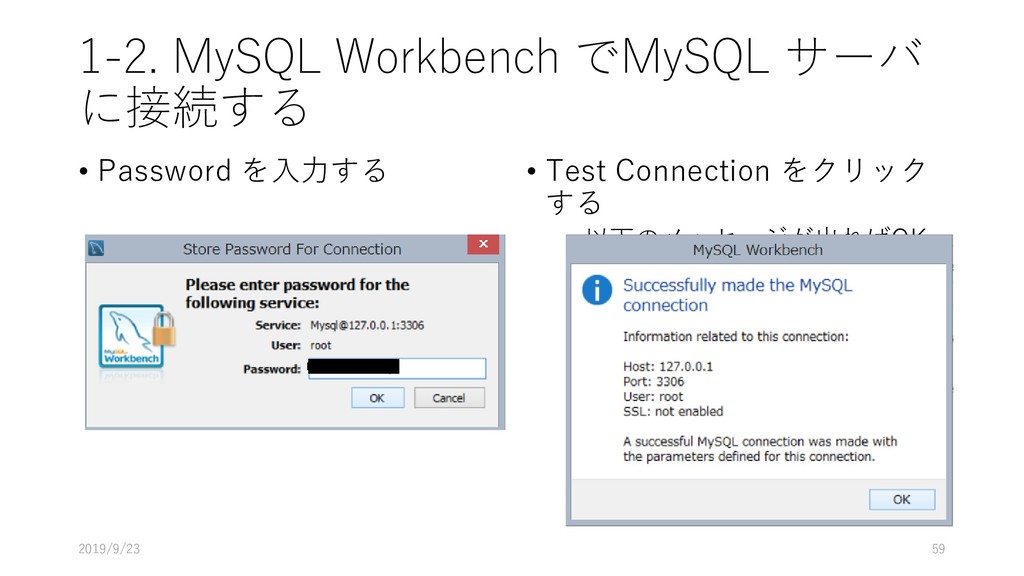
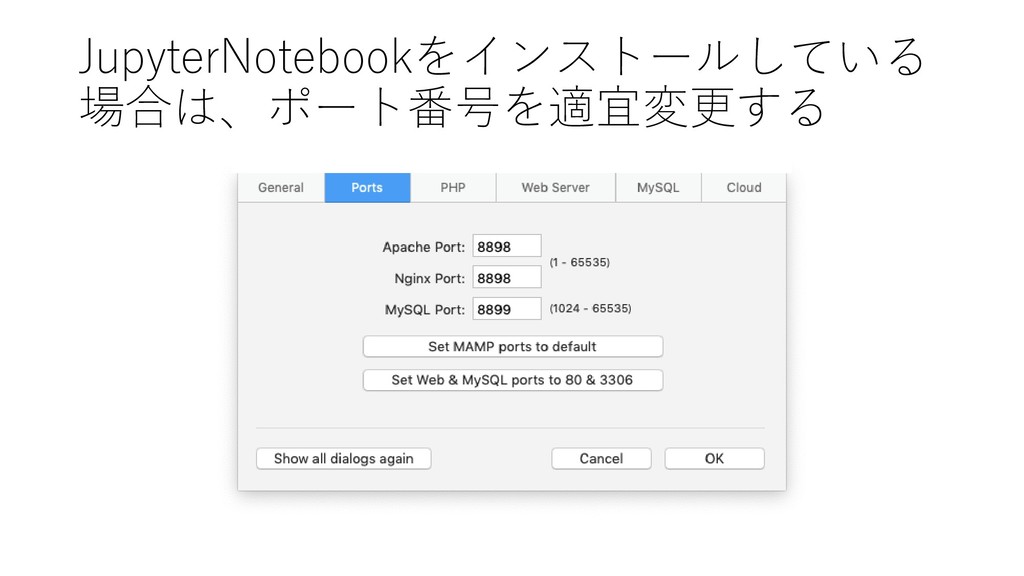
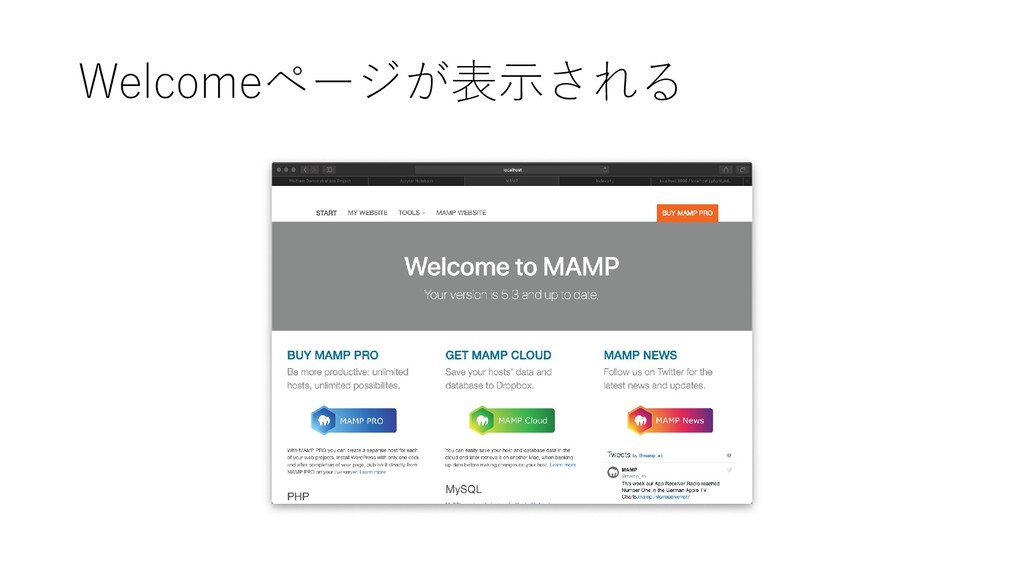
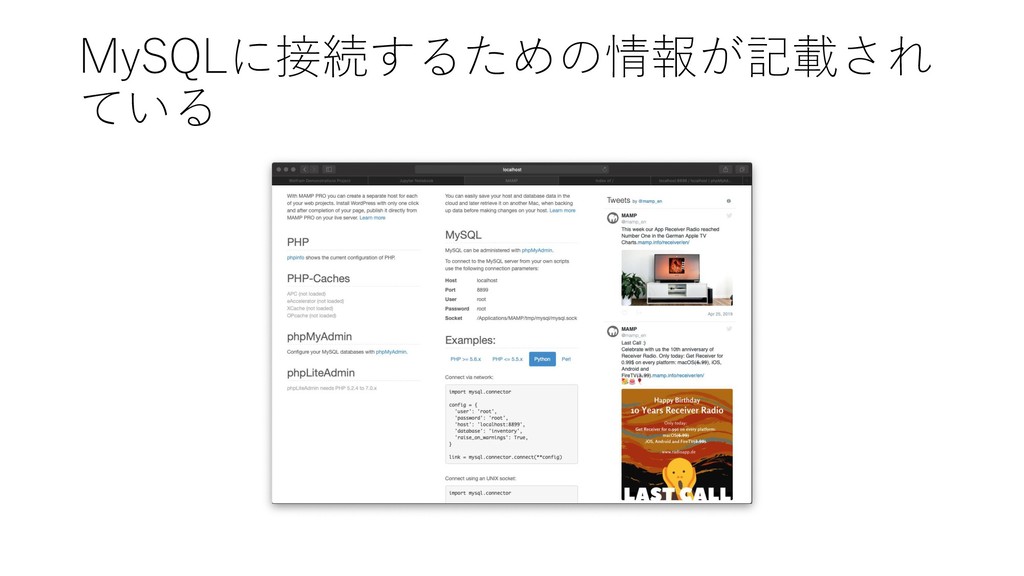
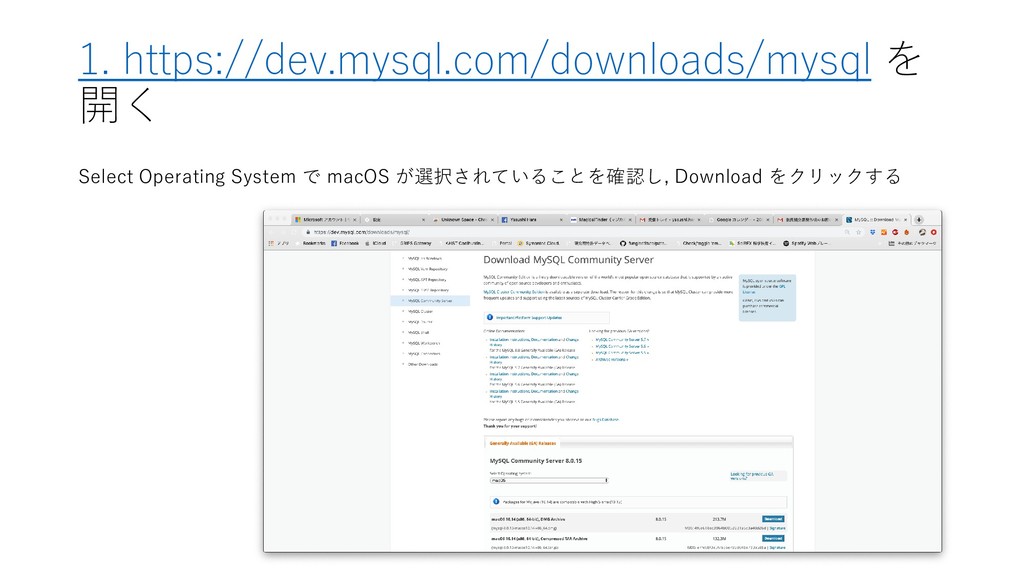
PC and/or Mac) に構築するため, MySQL Server と MySQL Workbench を導入する 2. Manaba からデータをダウンロードし, MySQL 上にデプロイ する 3. 展開したデータを MySQL Workbench を使って, 初期的な解 析を行う 4. JupyterNotebook からデータを読み込み初期的な解析をする
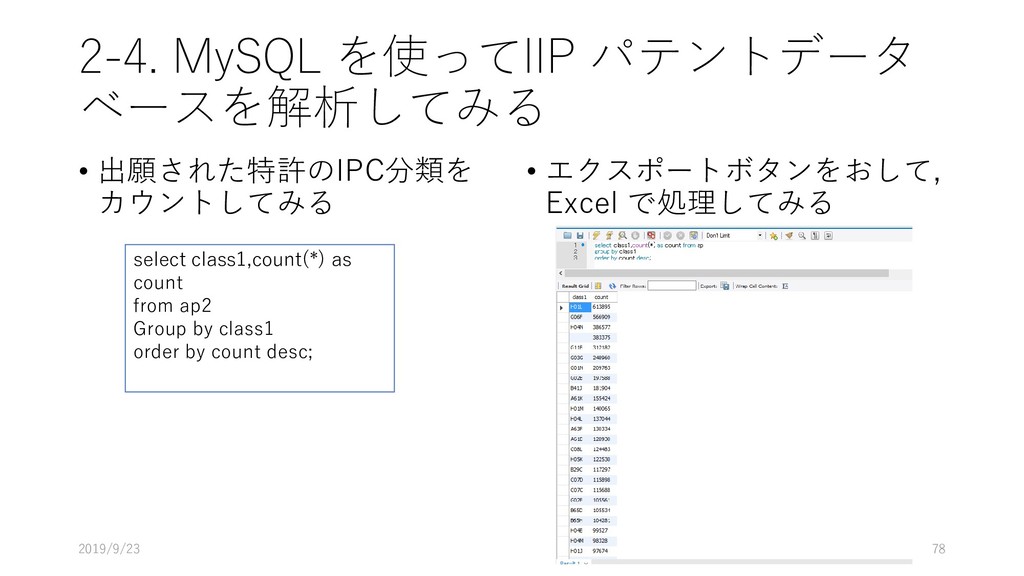
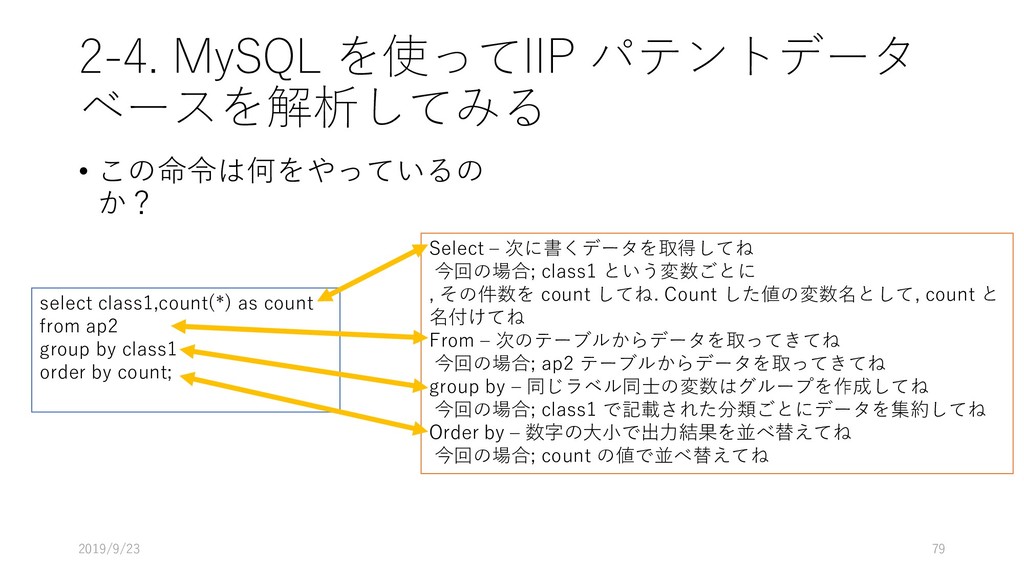
select class1,count(*) as count from ap2 group by class1 order by count; Select – 次に書くデータを取得してね 今回の場合; class1 という変数ごとに , その件数を count してね. Count した値の変数名として, count と 名付けてね From – 次のテーブルからデータを取ってきてね 今回の場合; ap2 テーブルからデータを取ってきてね group by – 同じラベル同士の変数はグループを作成してね 今回の場合; class1 で記載された分類ごとにデータを集約してね Order by – 数字の大小で出力結果を並べ替えてね 今回の場合; count の値で並べ替えてね
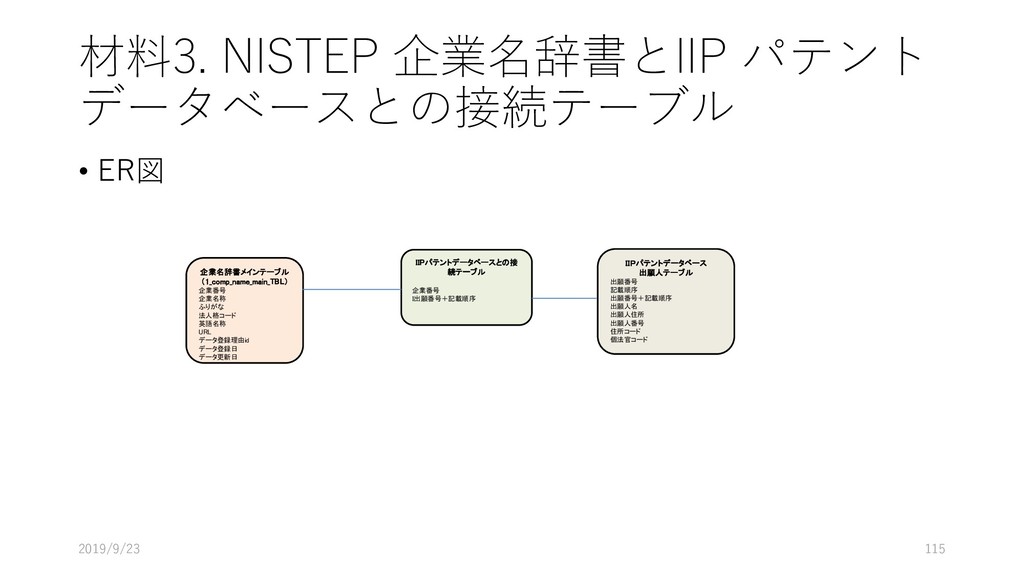
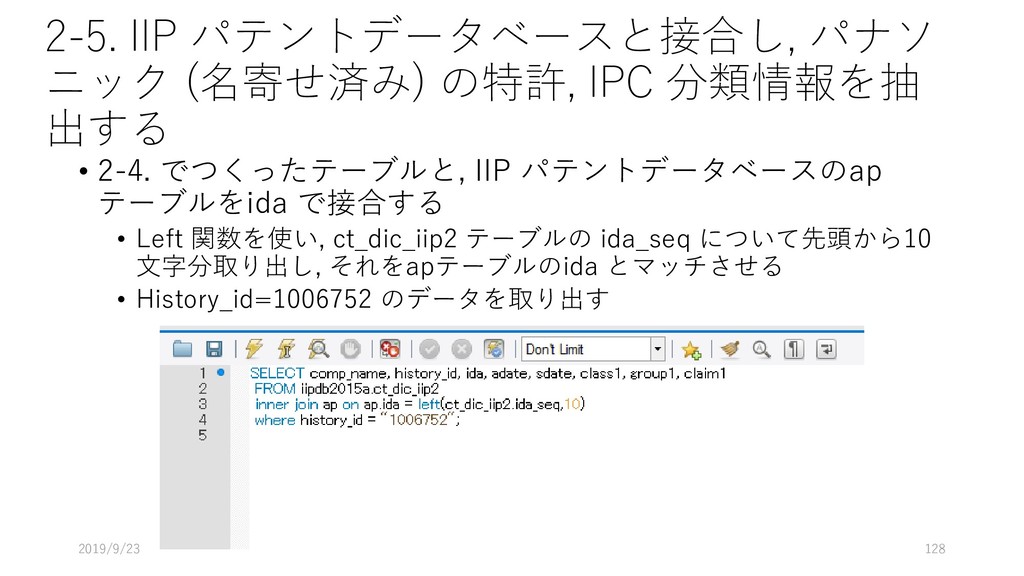
ap テーブルを参照するよ 3行目: applicant テーブルも参照するよ. このとき, applicant の ida フィールドと ap の ida フィールドを キーにして, applicant のデータを取り出してね 4行目: applicant.name が 松下電器産業株式会社 なものを持ってきてね. 2019/9/23 90 select ap.ida, ap.adate, ap.rdate, ap.class1, ap.claim1, applicant.ida_seq from ap inner join applicant on applicant.ida = ap.ida where applicant.name like "松下電器産業株式会社";
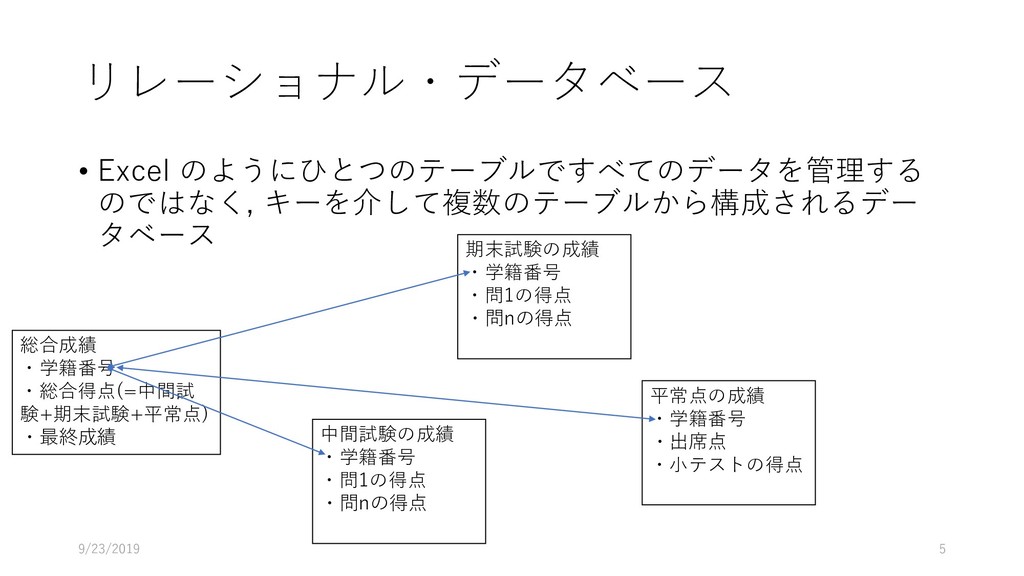
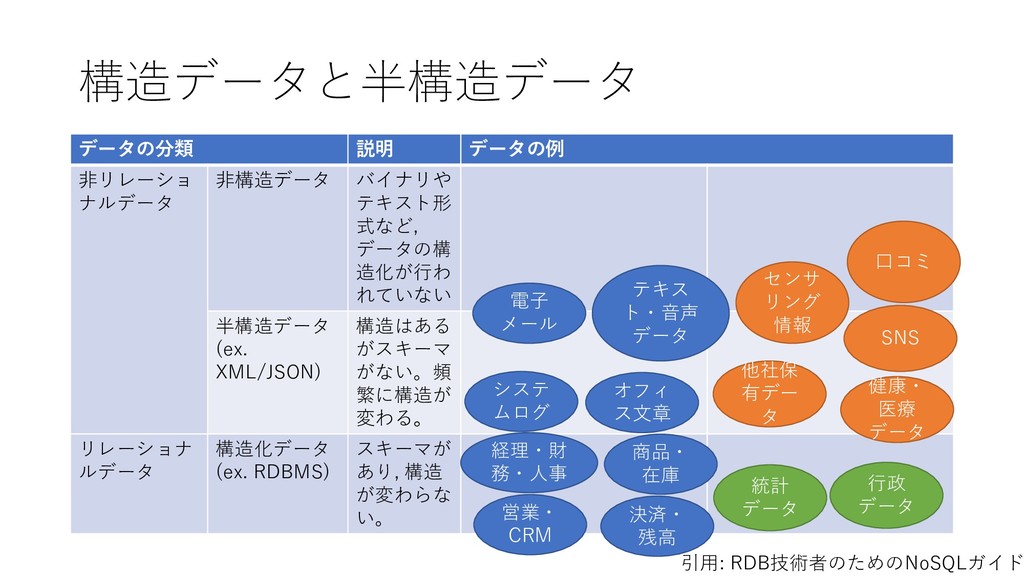
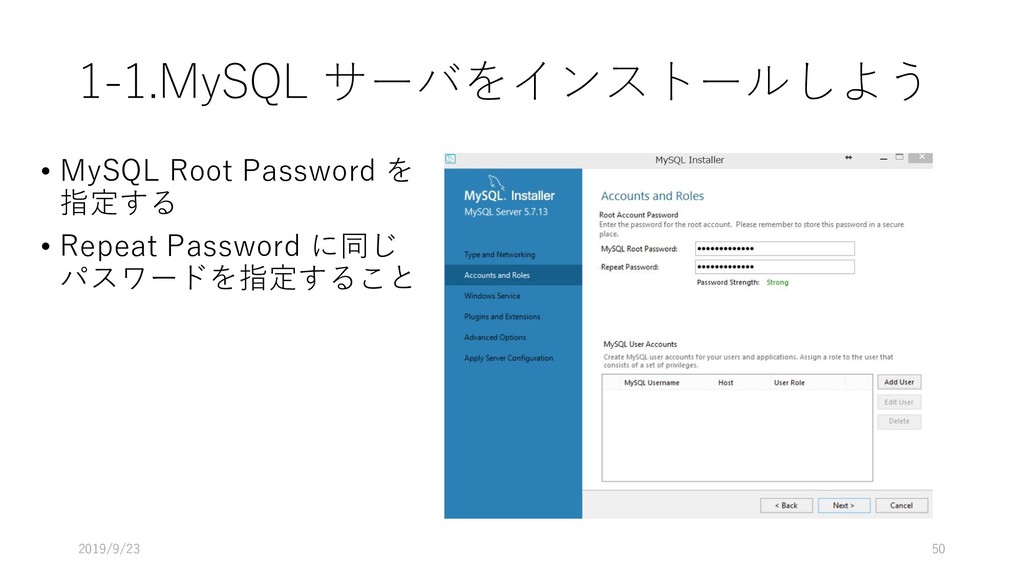
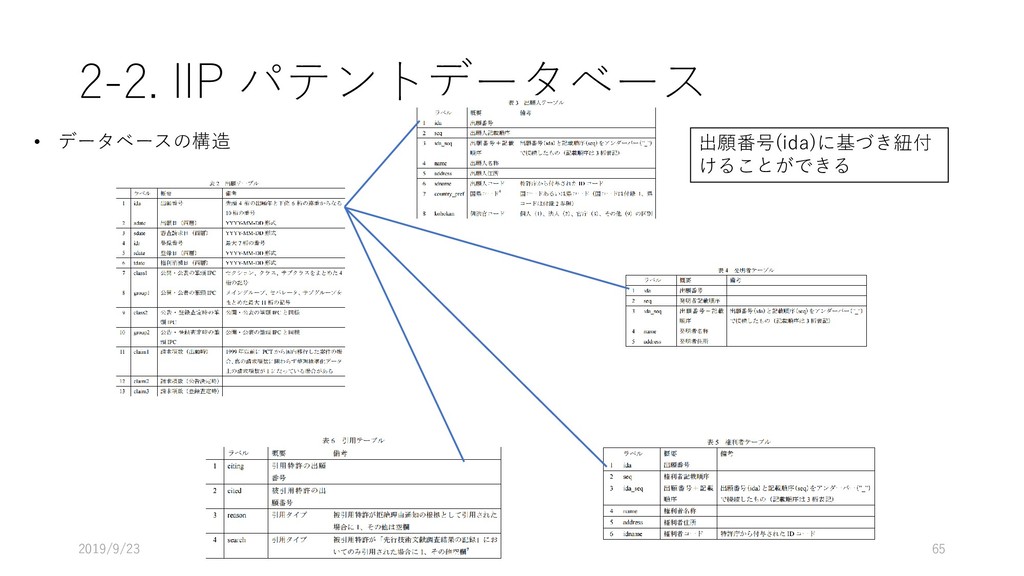
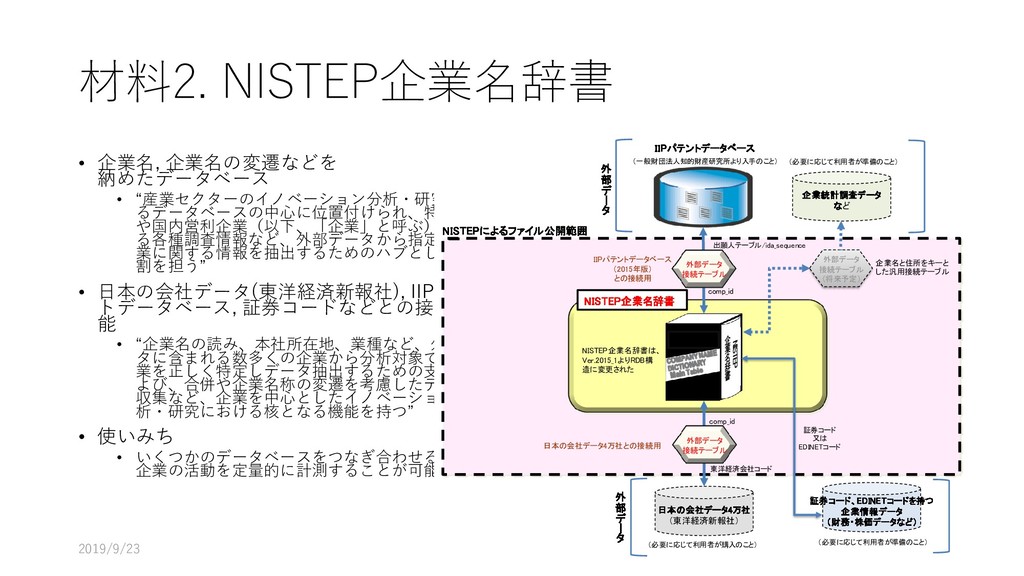
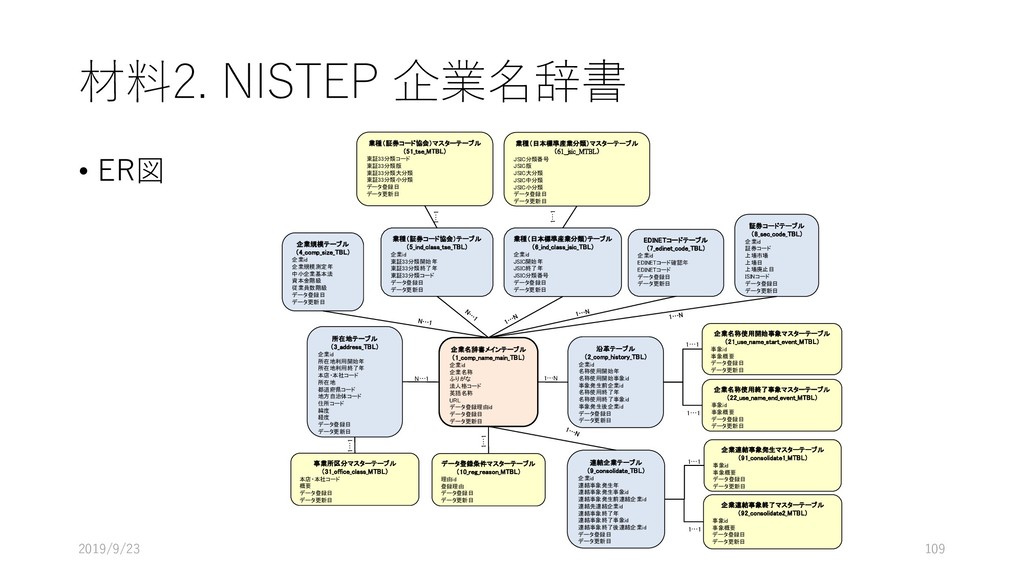
データ型 重複 NULL 主 キー 外部キー 説明 論理名 物理名 企業番号 comp_id 数値 (整数) N N Y 企業(企業名称ごと)に 固有に付与した番号 沿革番号 history_i d 数値 (整数) Y N 同一企業の変遷レコード をグループ化して扱うた めの番号 企業名称 comp_na me 文字列 Y Y 企業の名称(変遷名称も 含む) ふりがな read 文字列 Y Y 上記企業名称のふりがな 法人格 コード comp_co de 文字列 Y Y 企業の法人格を表すコー ド(下表参照) 英語名称 e_name 文字列 Y Y 企業の英語名称 URL url 文字列 Y Y 企業のウェブページの URL データ登 録理由番 号 reg_reas on_id 数値 (整数) Y Y データ登録理由マスター テーブルの理由番号 当該企業の辞書掲載条件 データ 登録日 reg_date 年月日 Y N データを本テーブルに登 録した日 データ 更新日 up_date 年月日 Y N 既登録データの情報更新 した日
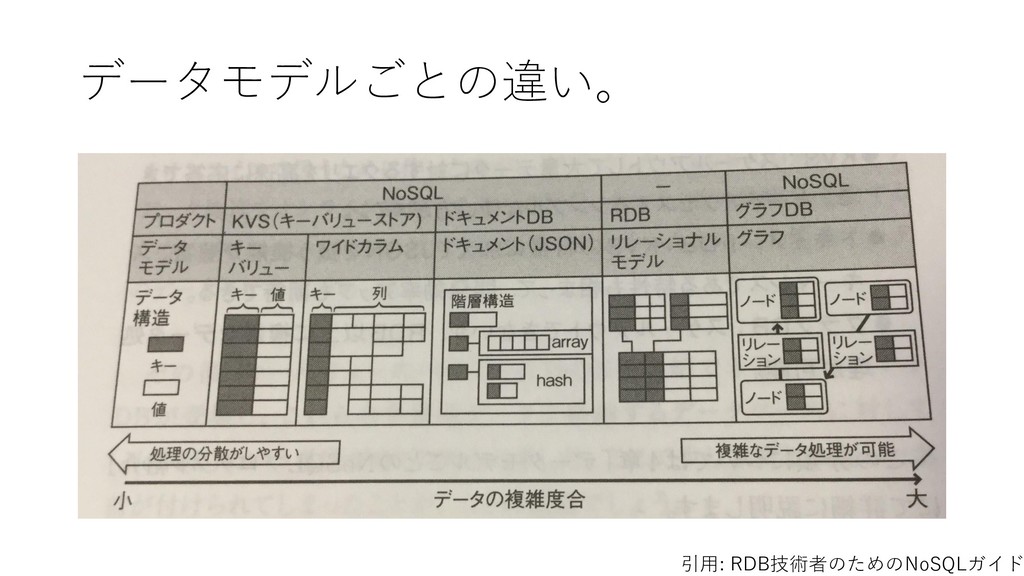
[5_ind_class_tse_TBL] フィールド名 データ型 重複 NULL 主キー 外部キー 詳細 論理名 物理名 企業番号 comp_id 数値 (整数) Y N Y 企業名辞書メインテーブ ルの企業番号 企業(企業名称ごと)に 固有に付与した番号 業種分類開 始年 inds_year YEAR Y Y 証券コード協会の業種分 類の確認初年 業種分類終 了年 inde_year YEAR Y Y 証券コード協会の業種分 類の確認最終年 業 種 分 類 コード ind_code 数値(4 桁整数) Y N Y 業種(証券コード協会) マスターテーブルの分類 コード 証券コード協会の分類該 当業種 データ 登録日 reg_date 年月日 Y N データを本テーブルに登 録した日 データ 更新日 up_date 年月日 Y N 既登録データの情報更新 した日
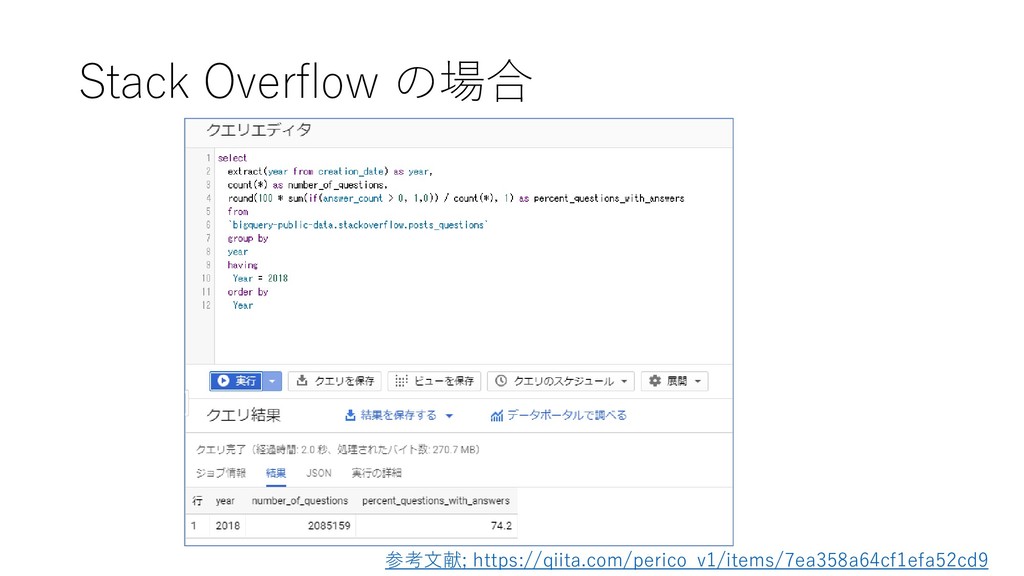
AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10 翻訳; (1.) Select Name と gender と number の合計値を取得 して, number の合計値は total という名前に してね (2.) From `bigquery-public- data.usa_names.usa_1910_2013` というテーブルからデータを取ってきてね (3.) Order by Total の数字が大きな順にしてね (4.) LIMIT 最初から10番目までにしてね
![経済学のための 実践的データ分析 3.4. SQL ことはじめ 38教室 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
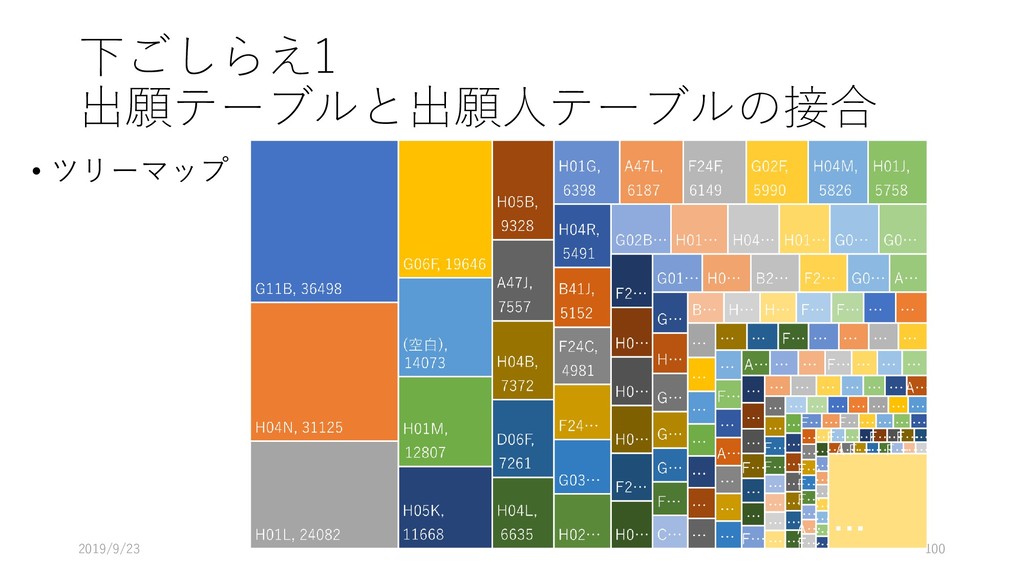
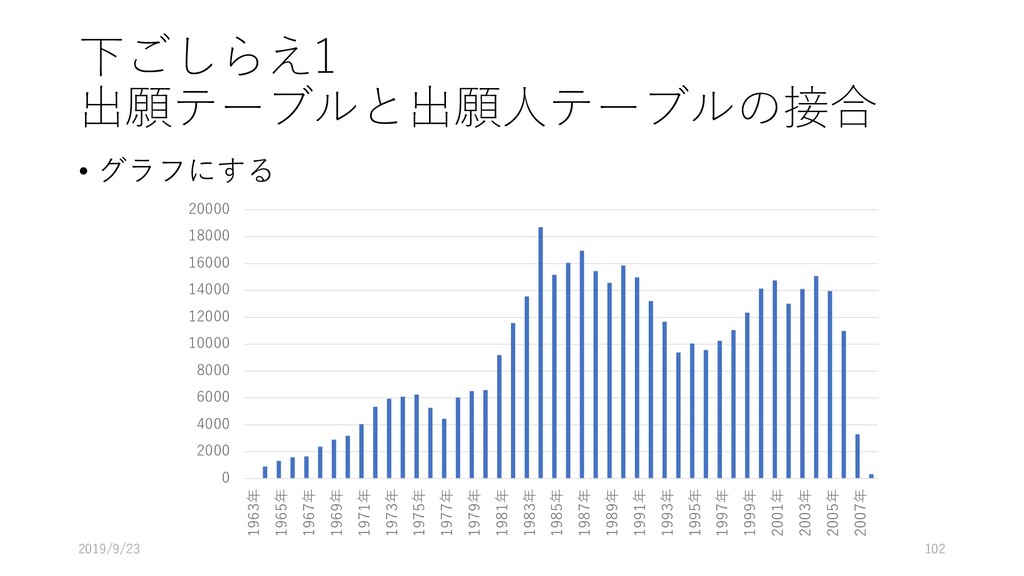
![下ごしらえ1 出願テーブルと出願人テーブルの接合 • ピボットテーブルを作る • [挿入]-[ピボットテーブル]を選 択 • ピボットテーブルの範囲が選 択されていることを確認し、](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_95.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![材料2. NISTEP 企業名辞書 • 企業名辞書メインテーブル 2019/9/23 111 企業名辞書メインテーブル [1_comp_name_main_TBL] フィールド名](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_110.jpg){kind=link}
![材料2. NISTEP 企業名辞書 • 企業規模テーブル 2019/9/23 112 企業規模テーブル [4_comp_size_TBL] フィールド名](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_111.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
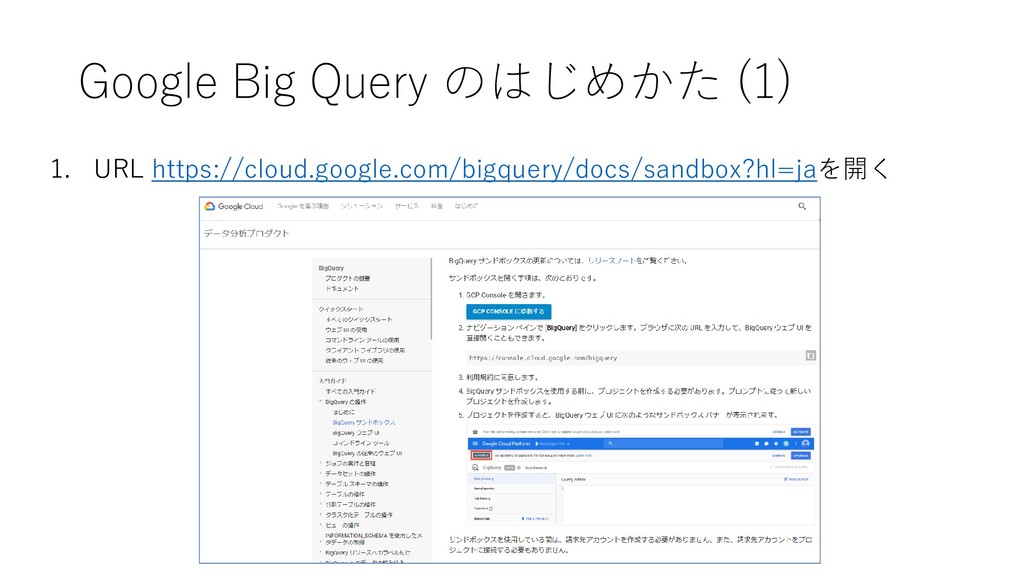
{kind=link}
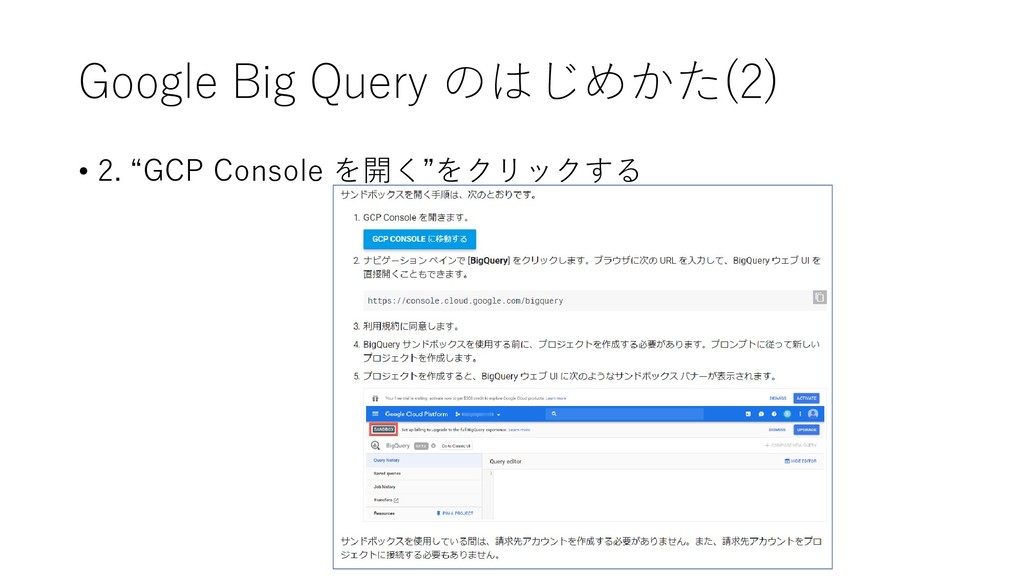
{kind=link}
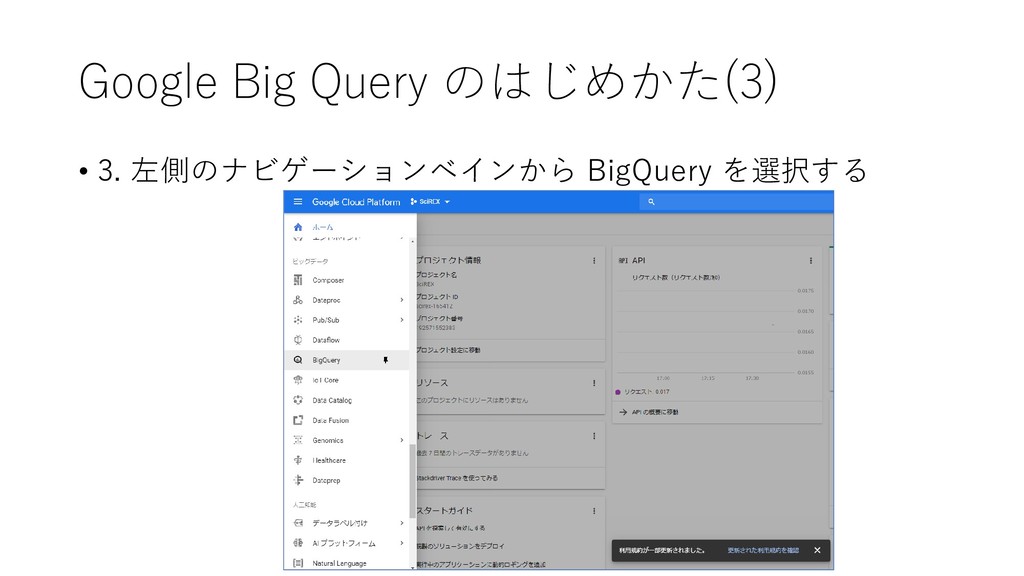
{kind=link}
{kind=link}
![Google Big Query のはじめかた(4) • 4. [完了]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_138.jpg){kind=link}
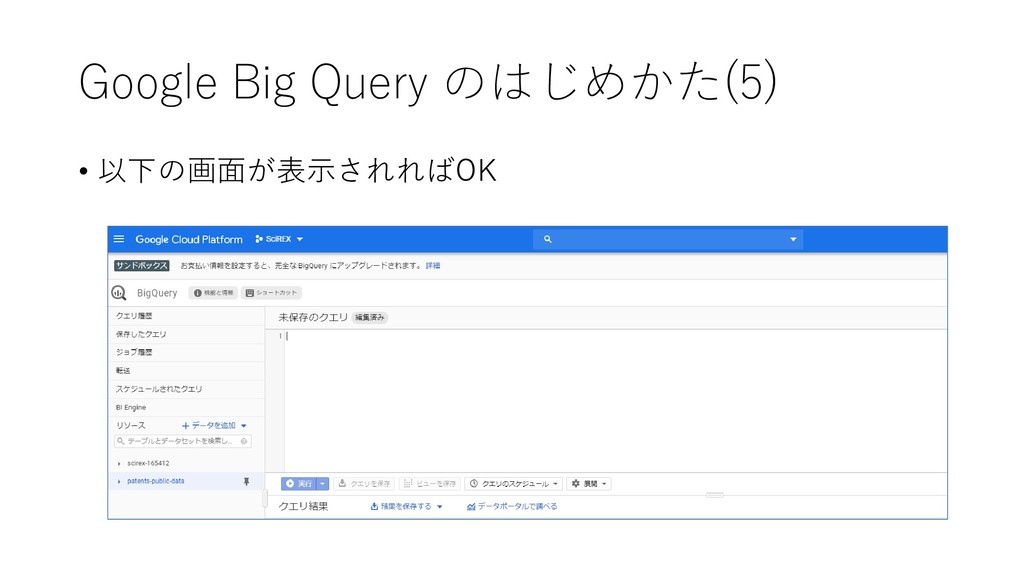{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Big Query でクエリを打ってみる(3) • [実行]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_143.jpg){kind=link}
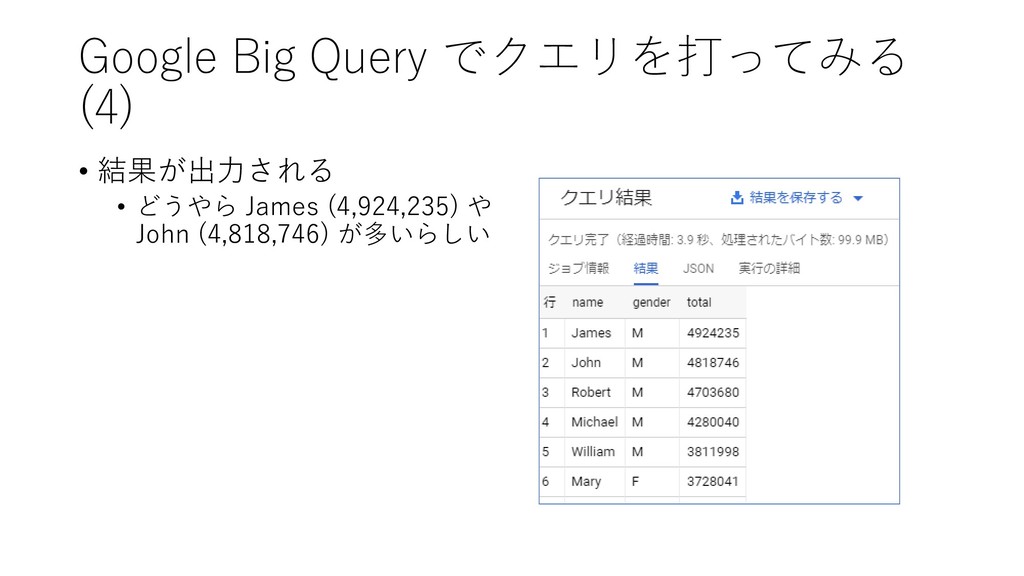{kind=link}
![Google Big Query でクエリを打ってみる (5) • [データポータルで調べる]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_145.jpg){kind=link}
![Google Big Query でクエリを打ってみる(6) • [使ってみる]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_146.jpg){kind=link}
![Google Big Query でクエリを打ってみる(7) • [承認]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_147.jpg){kind=link}
![Google Big Query でクエリを打ってみる(8) • [許可]をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_148.jpg){kind=link}
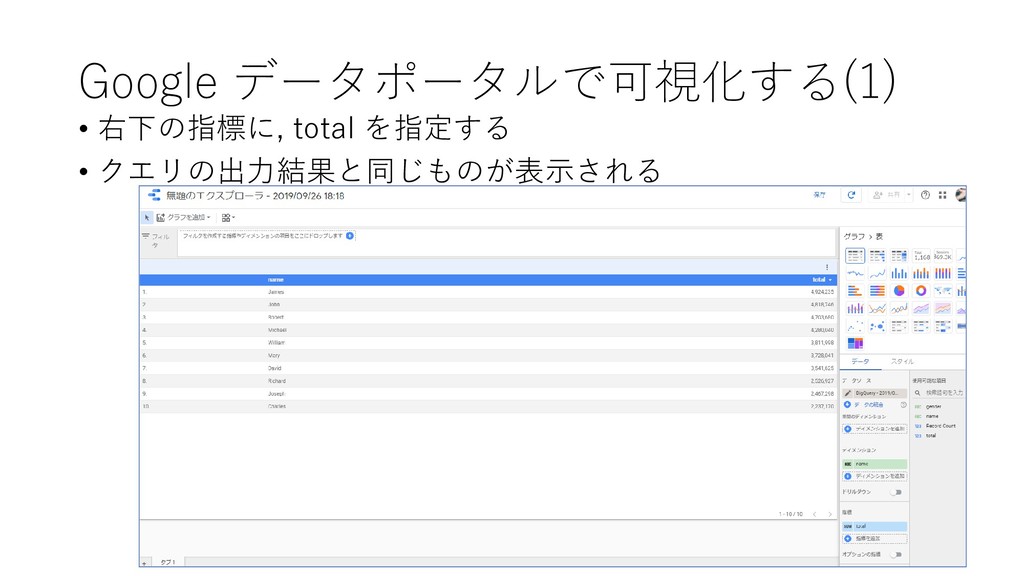{kind=link}
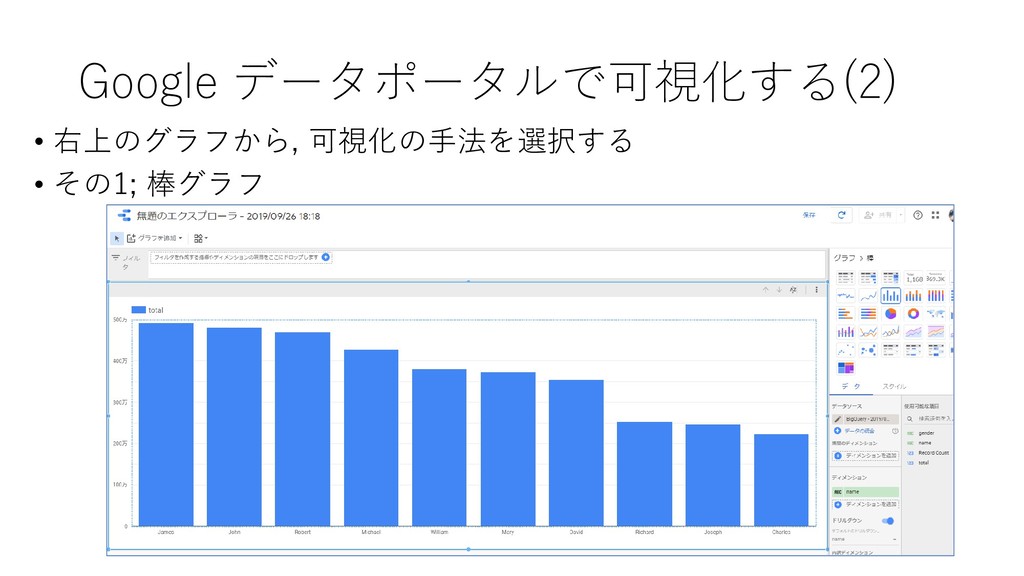{kind=link}
{kind=link}
{kind=link}
{kind=link}
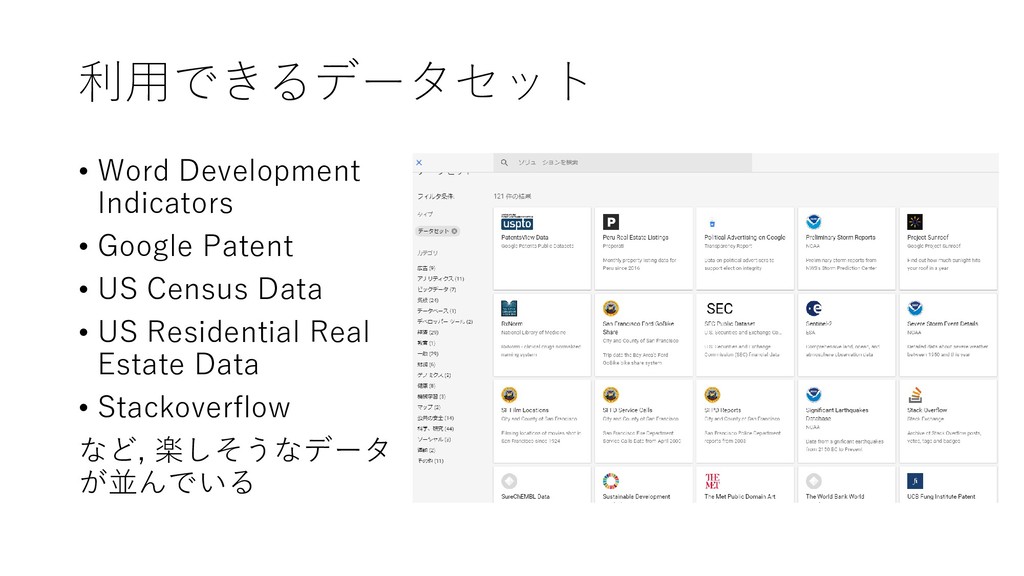
![利用できるデータセット • リソース から, [+ データを追加] をクリックする](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_154.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/a82520b80a9b46e3b58c35fbe44868d1/slide_210.jpg){kind=link}