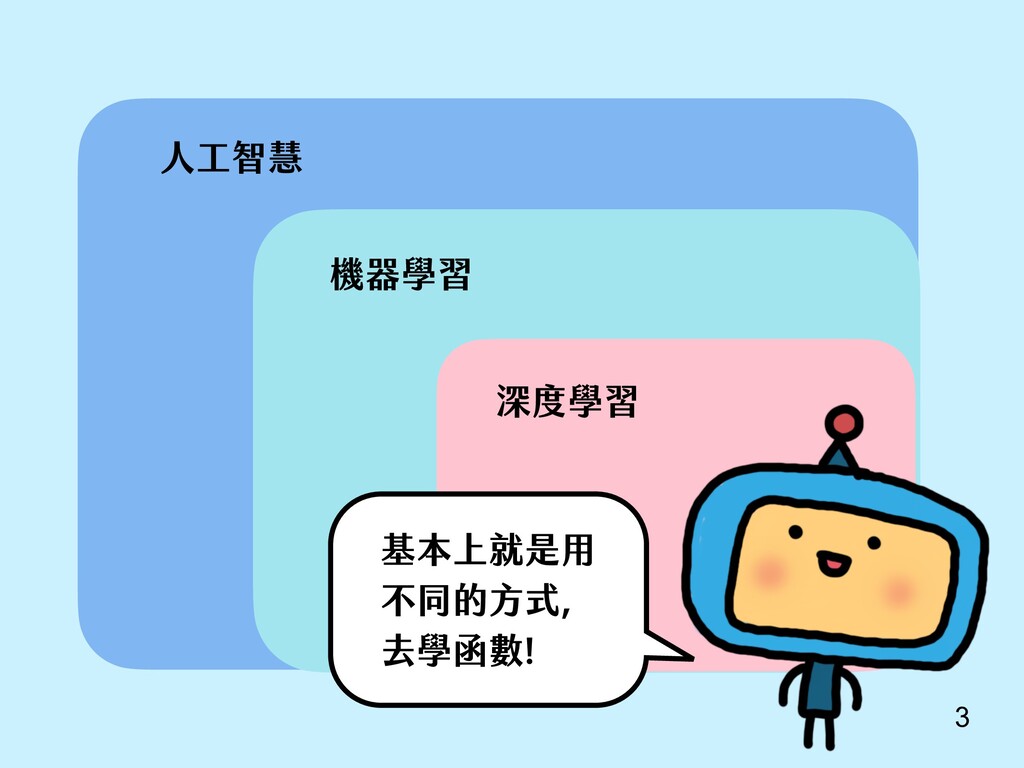
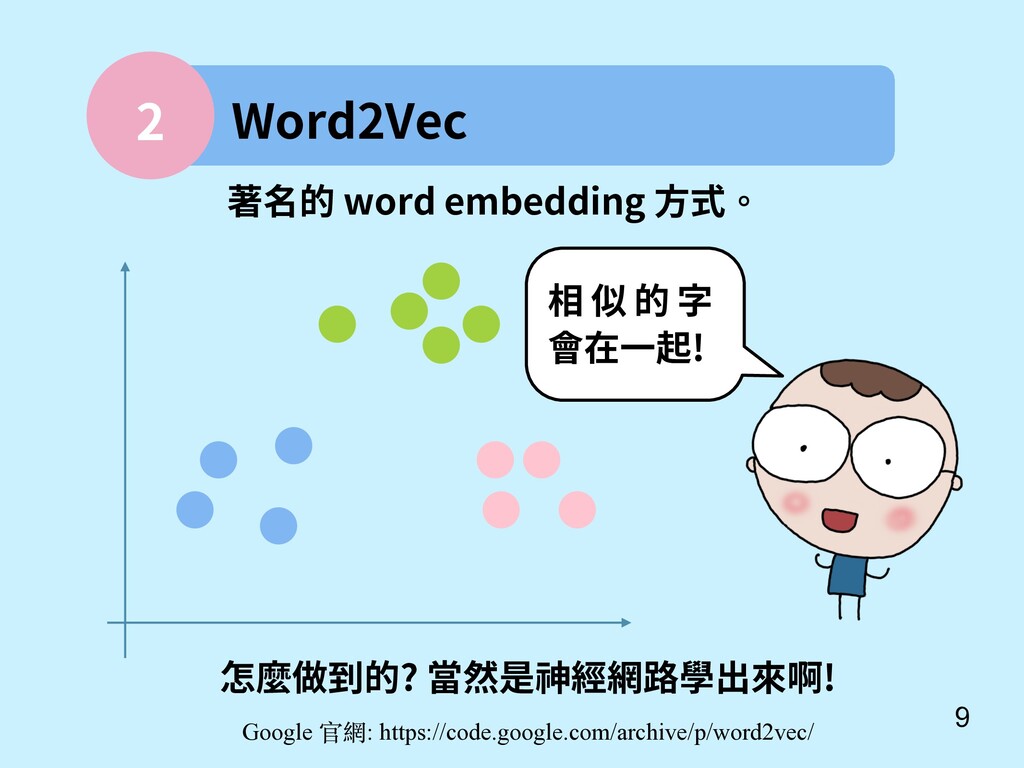
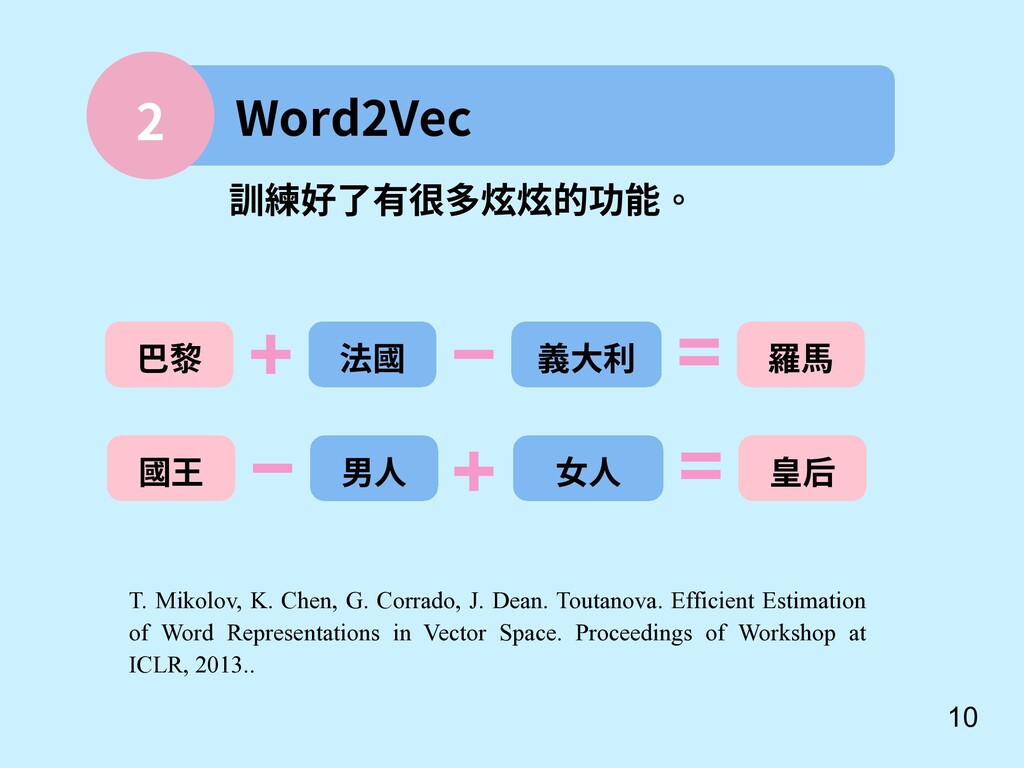
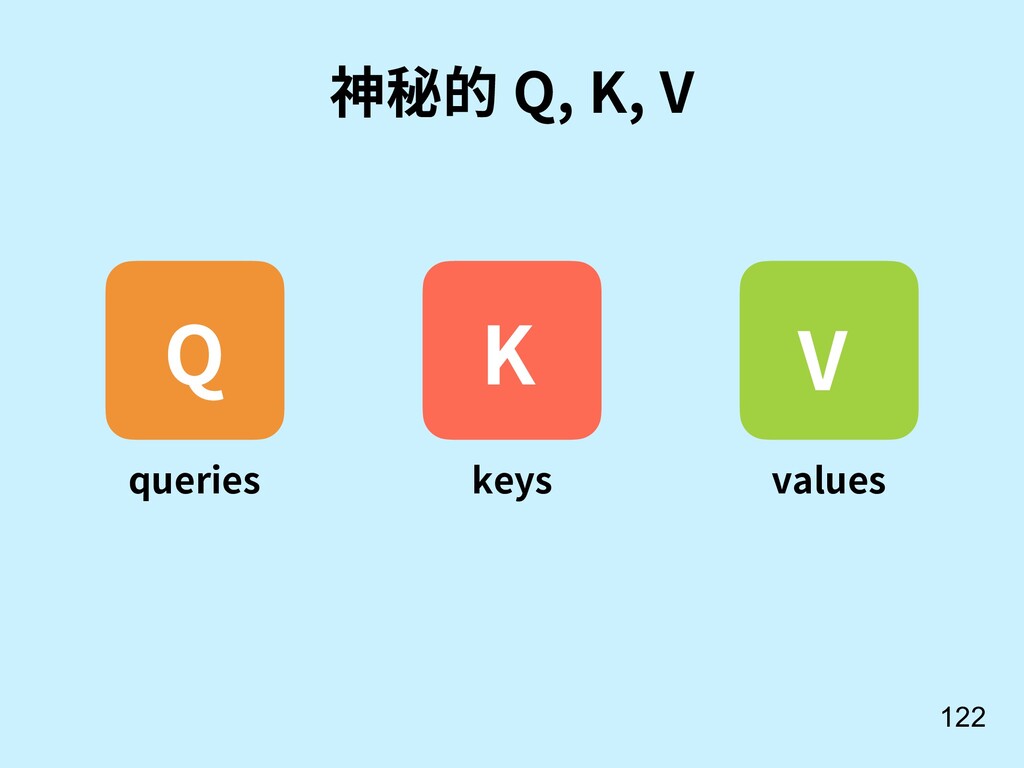
Dean. Toutanova. Efficient Estimation of Word Representations in Vector Space. Proceedings of Workshop at ICLR, 2013.. 訓練好了有很多炫炫的功能。 巴黎 法國 義大利 羅馬 國王 男人 女人 皇后
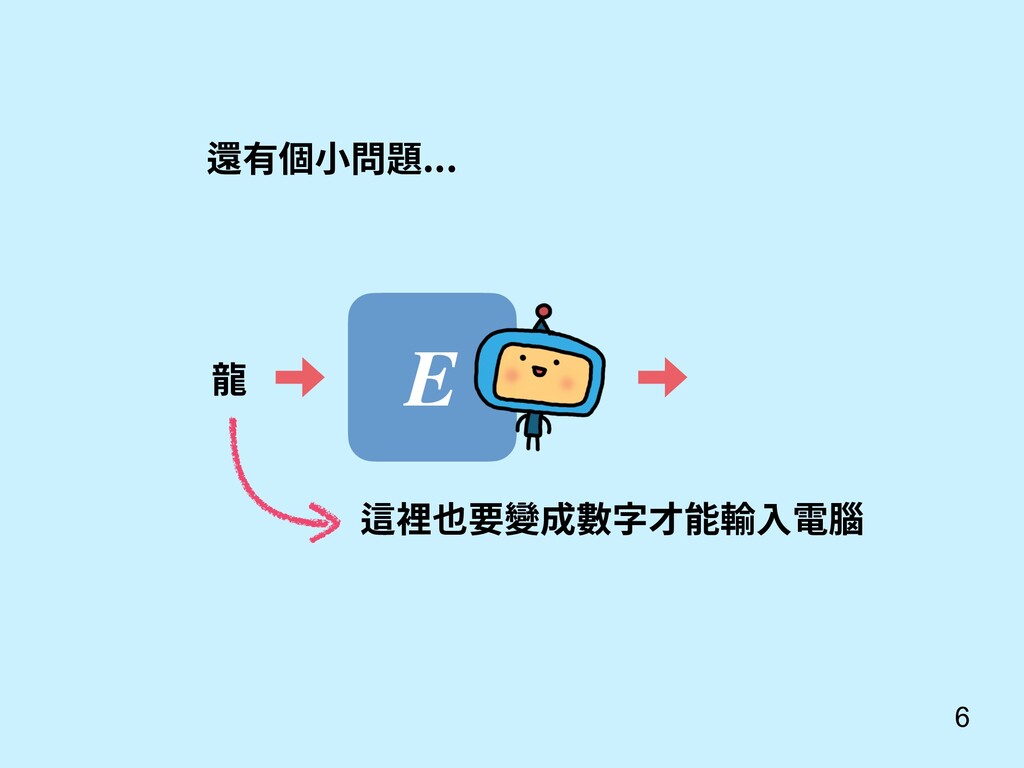
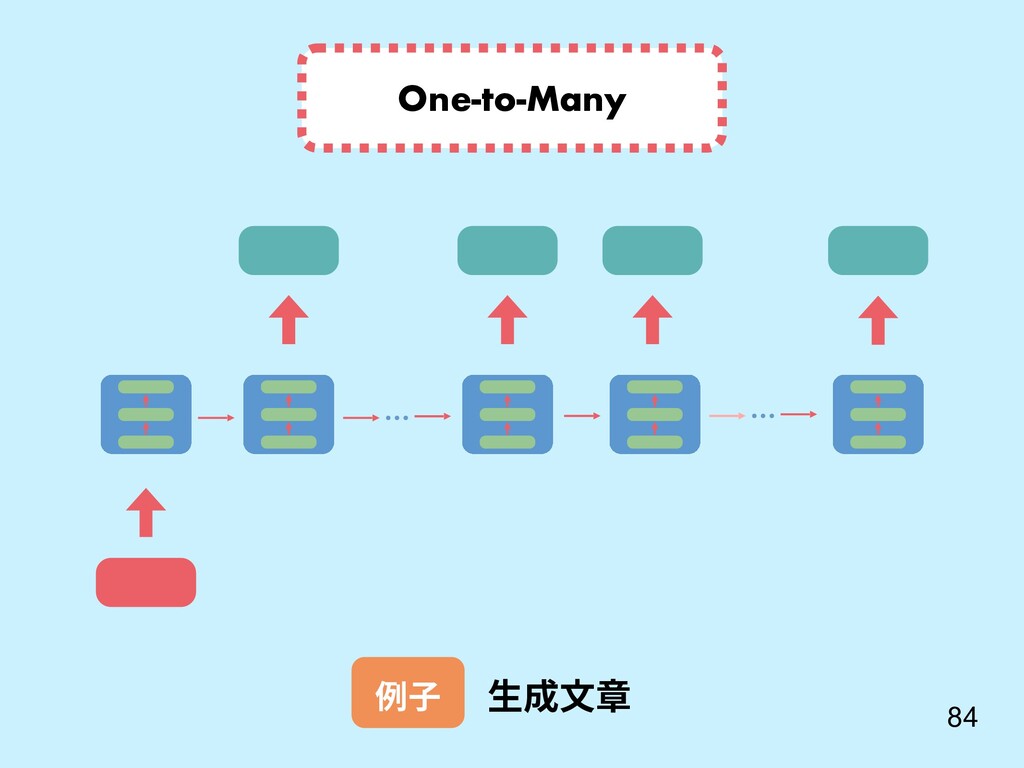
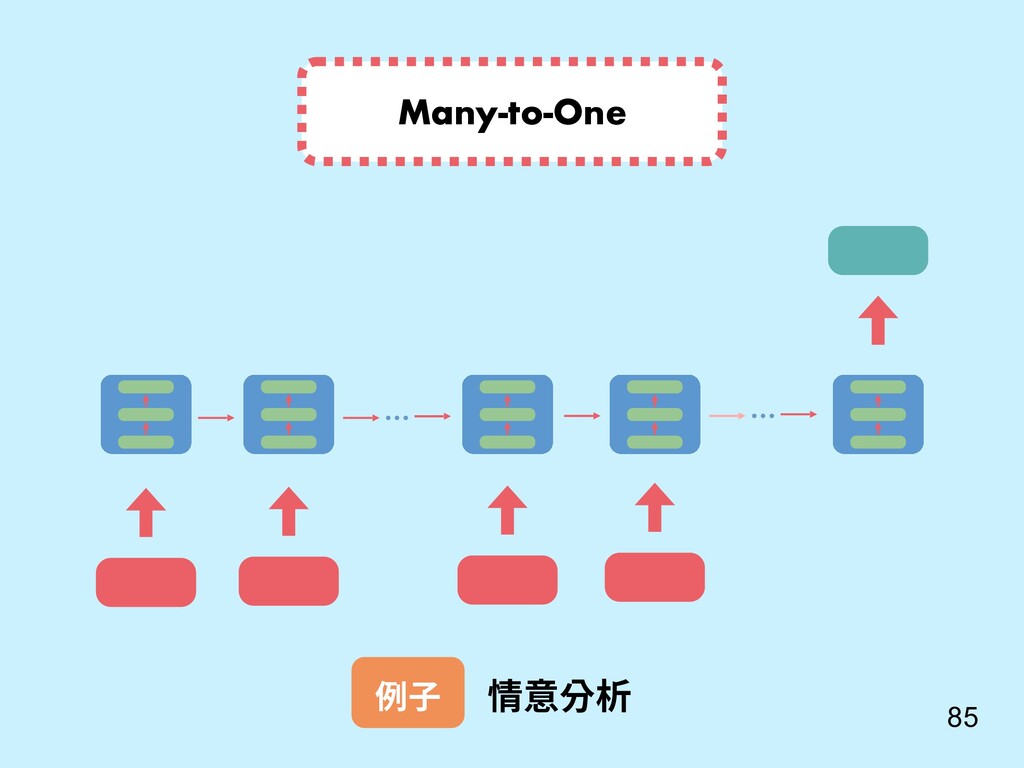
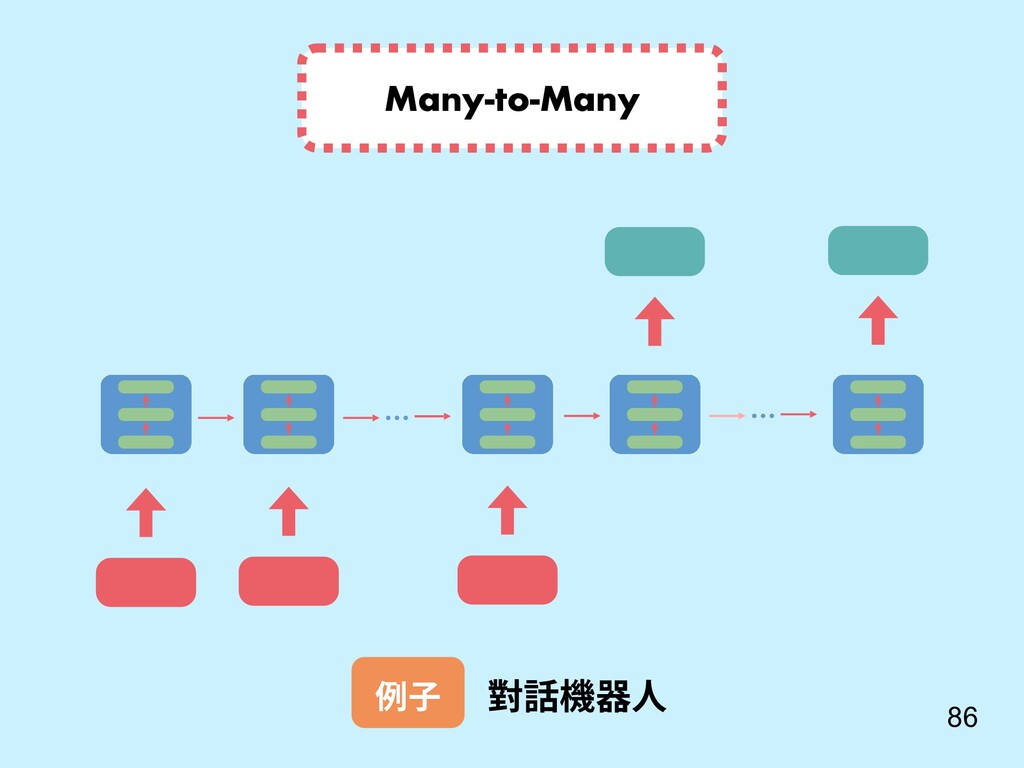
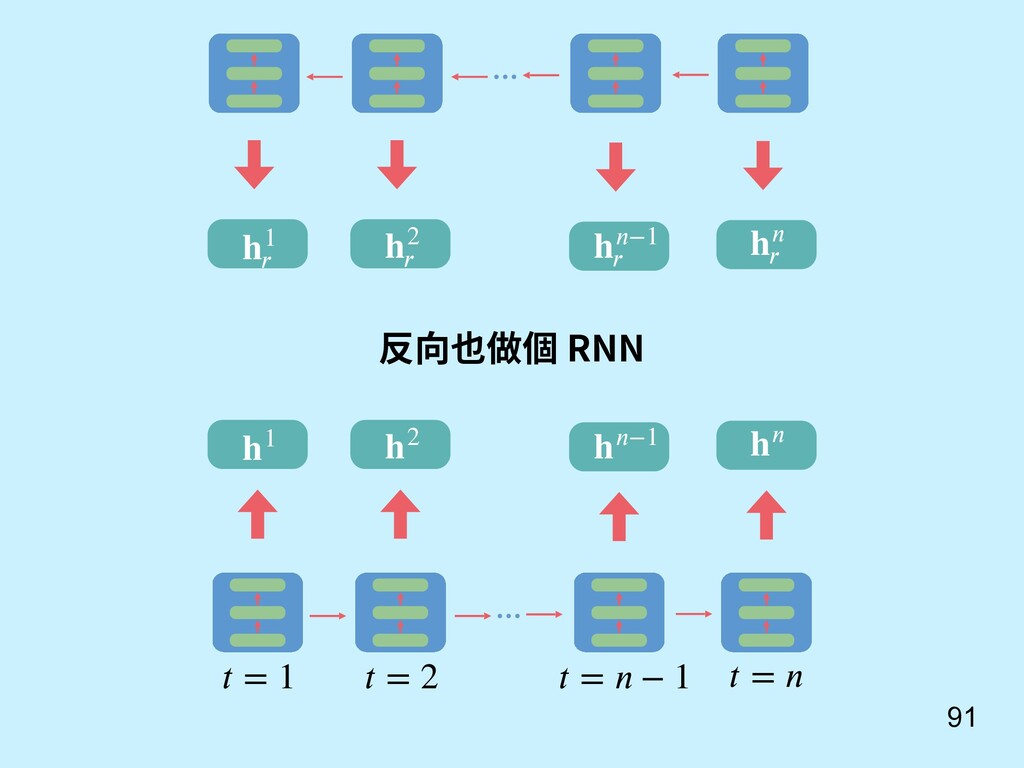
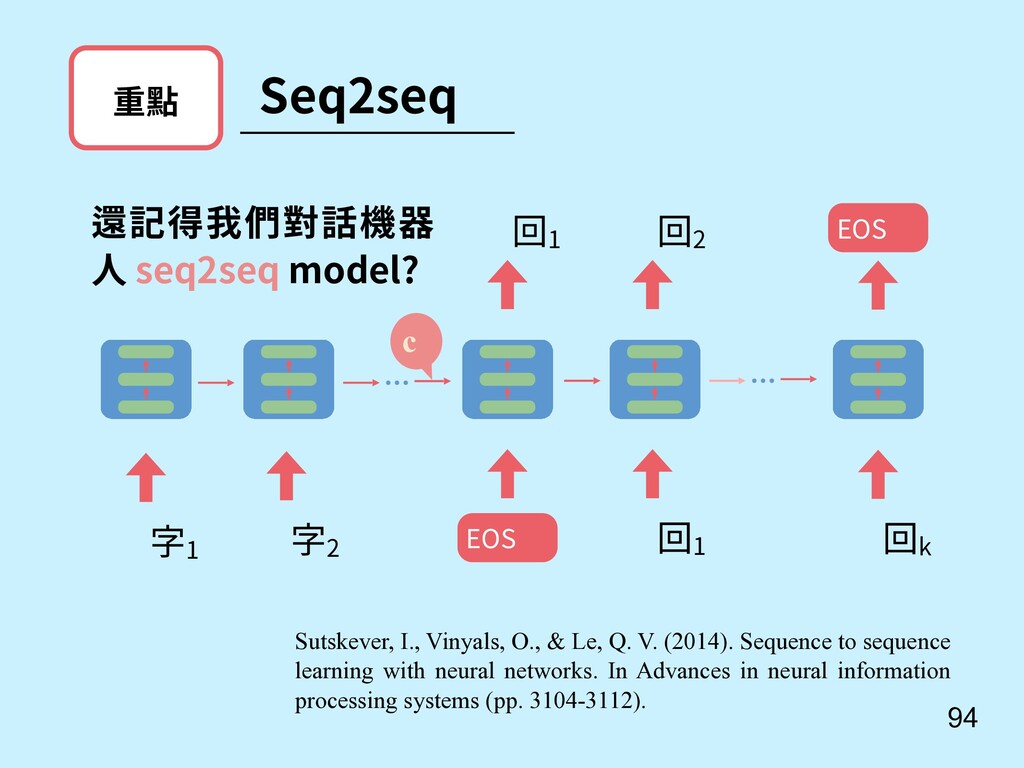
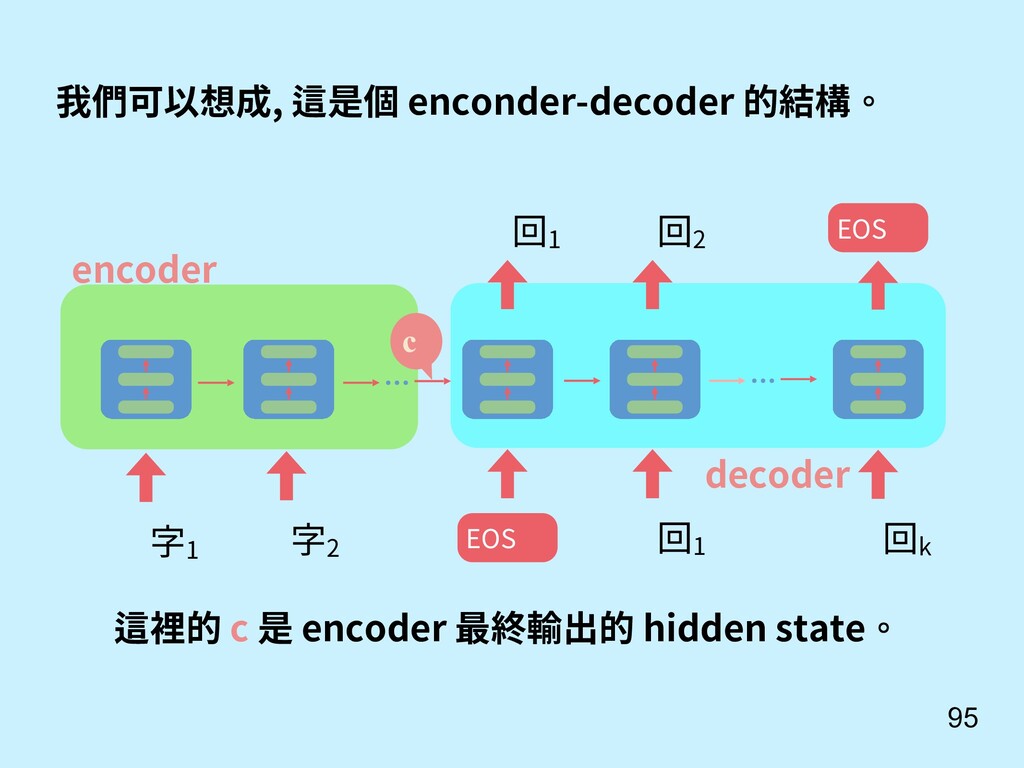
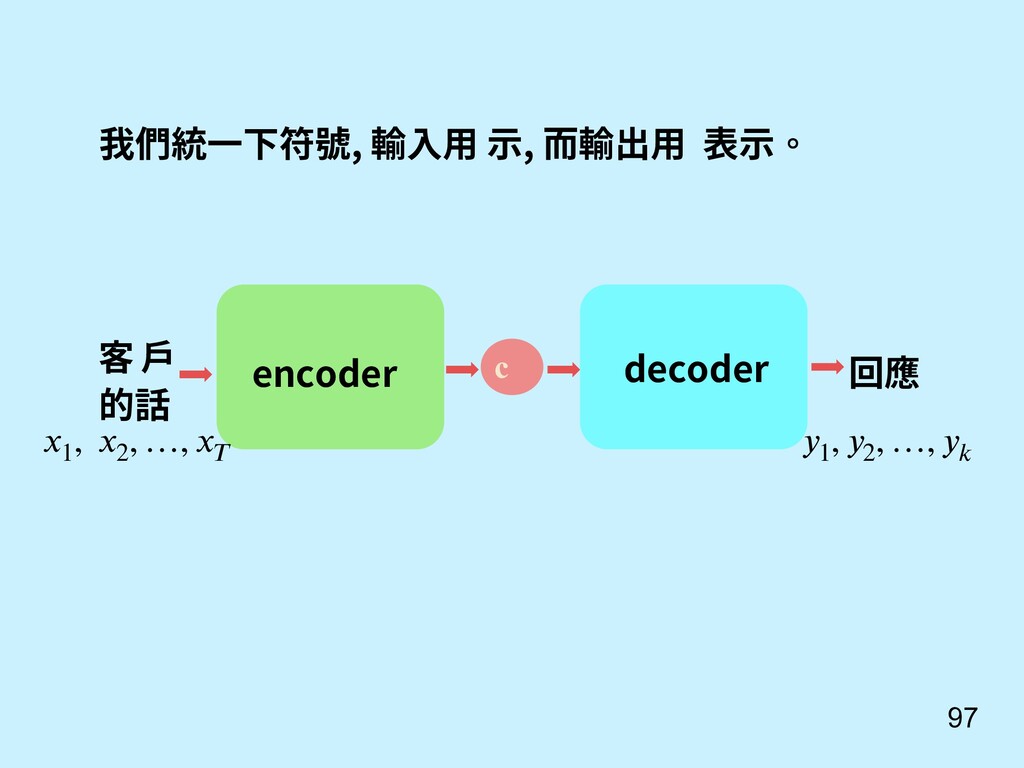
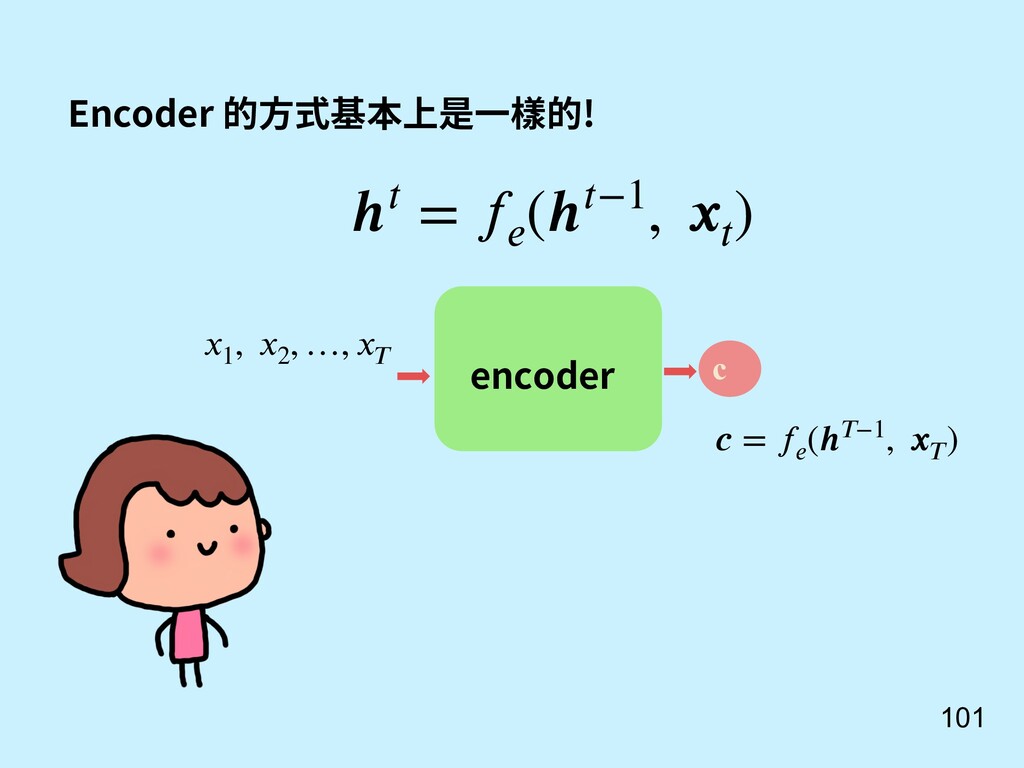
重點 Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112). 還記得我們對話機器 人 seq2seq model? c
K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
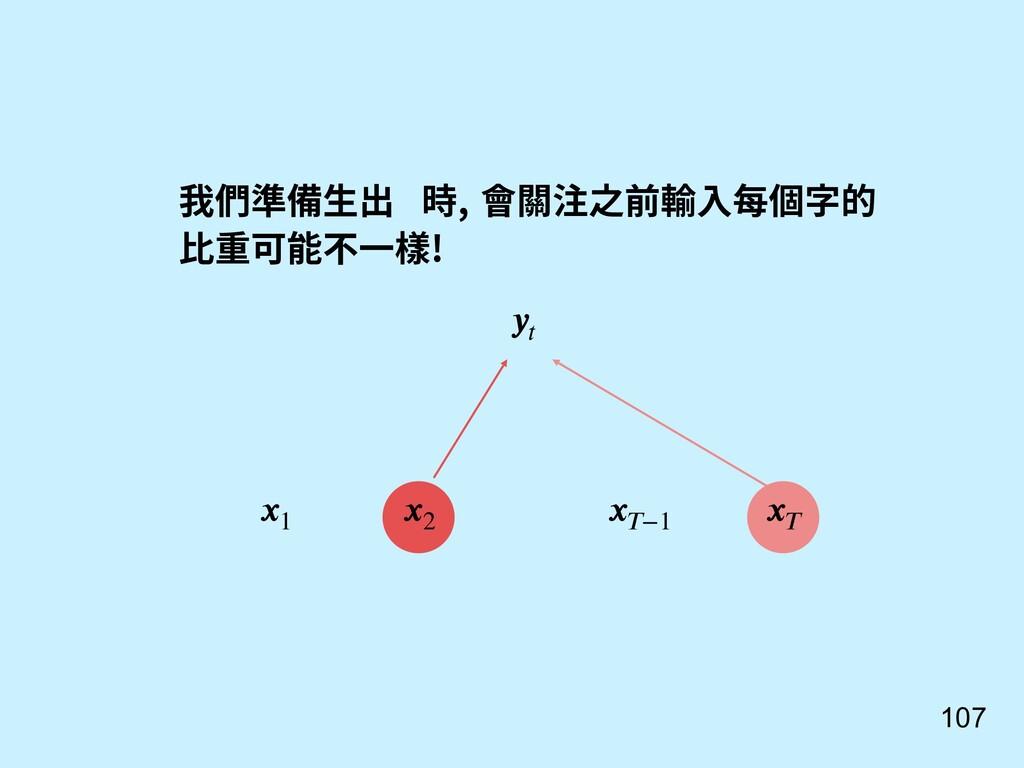
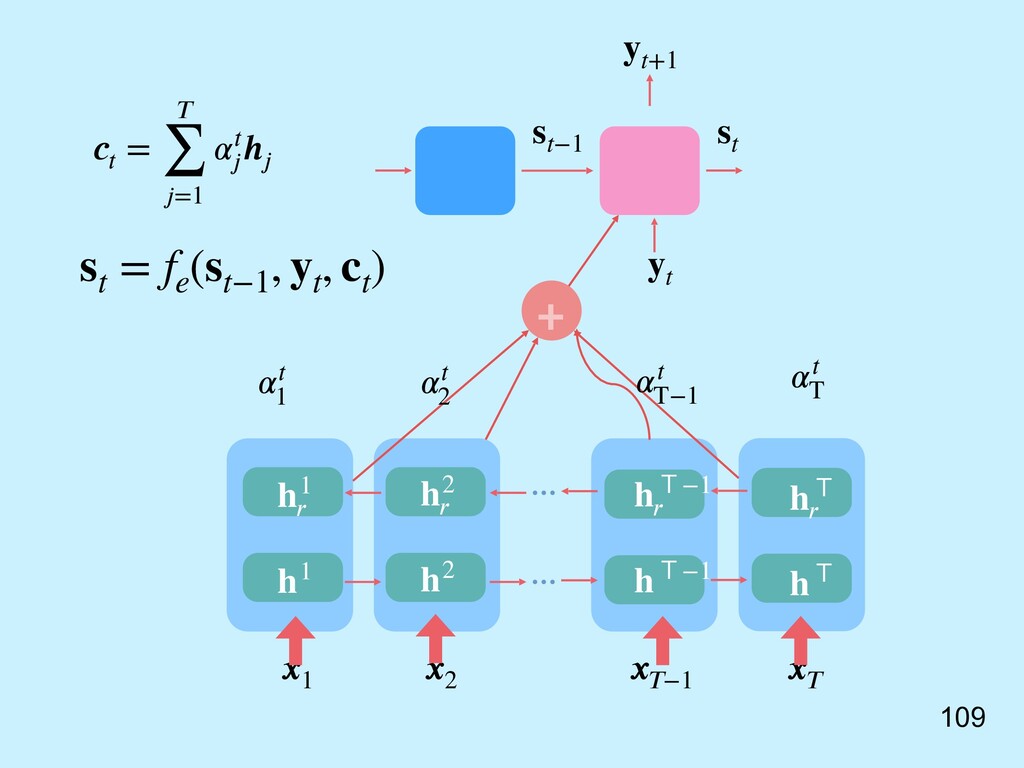
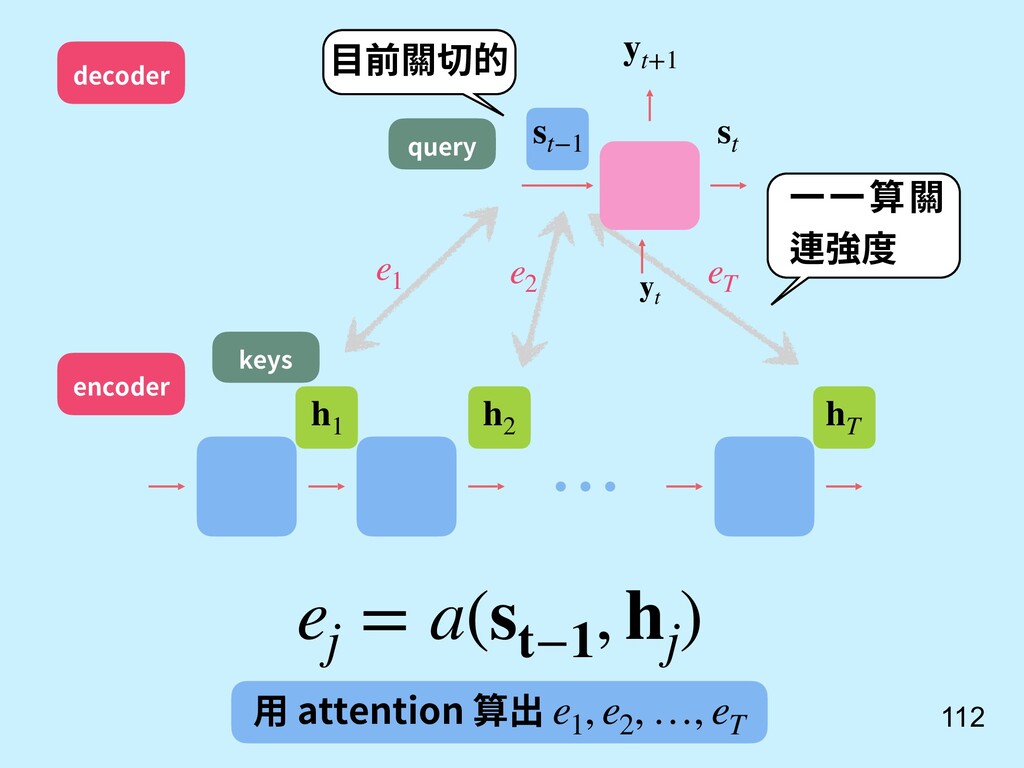
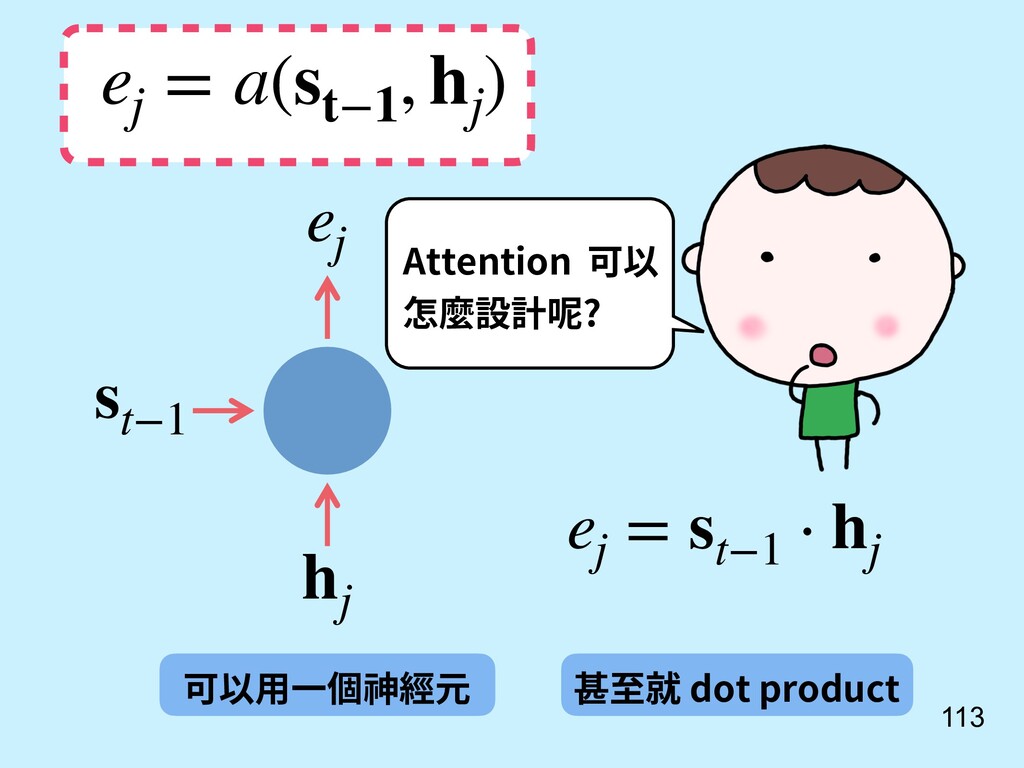
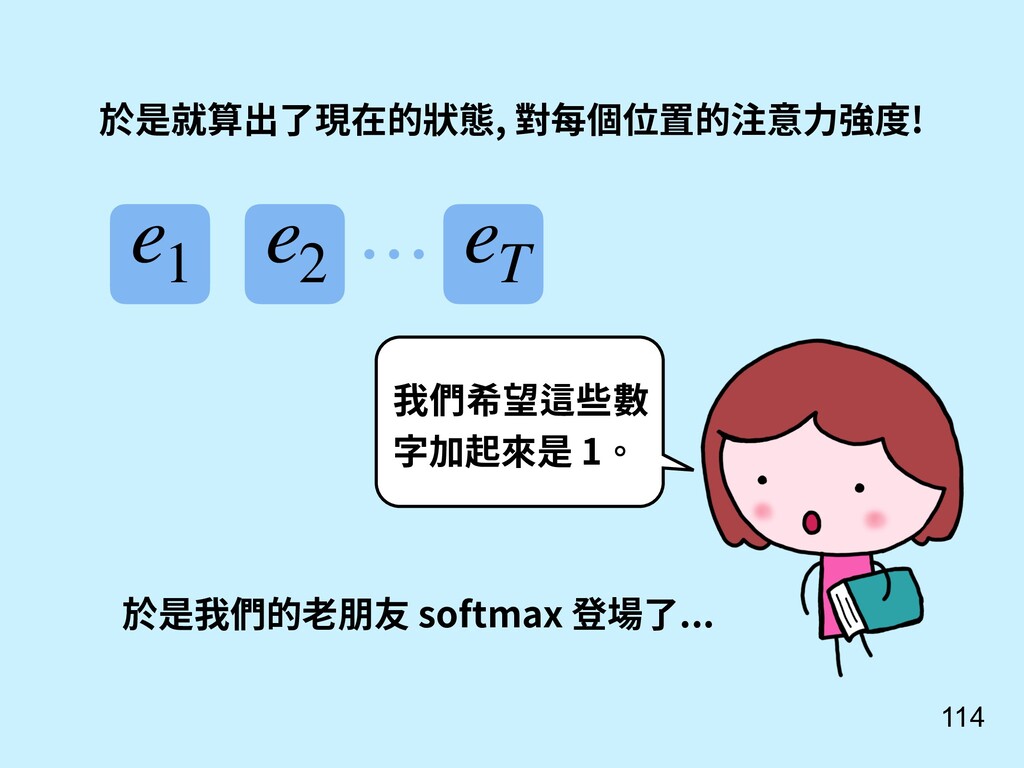
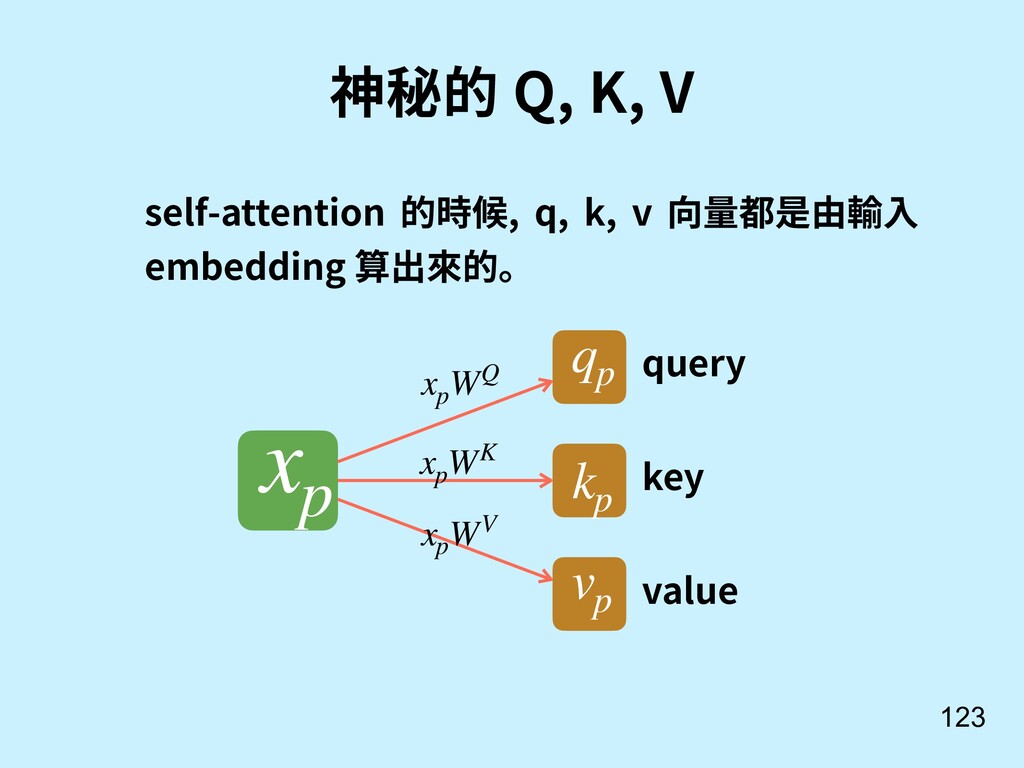
其實不一定是要輸入串最後一個 hidden state。 = (1, 2, ⋯, ) 也可以參考所有輸入時的 hidden states 算出來! [9] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
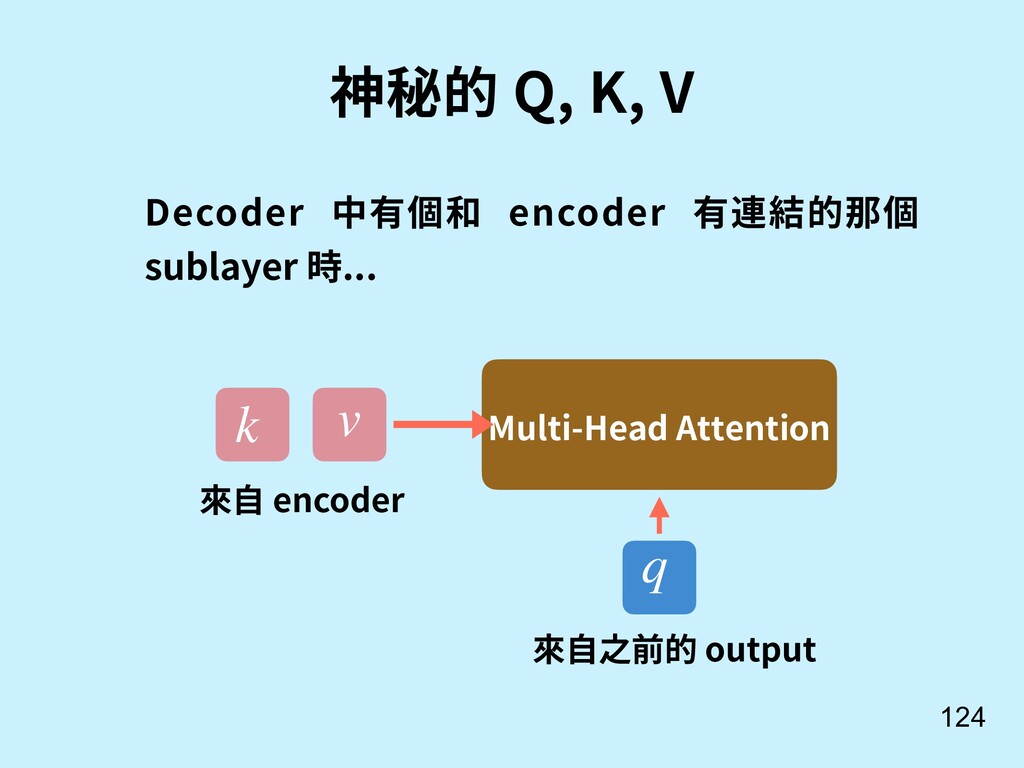
N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998-6008).
J. Carbonell, R. Salakhutdinov, Q. V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. NeruIPS 2019. 使用 Transformer XL 使用 permutation 訓練法
P. Puri, P. LeGresley, J. Casper, B. Catanzaro, Megatron-LM: Training Multi-Billion Parameter Language Models Using GPU Model Parallelism. arXiv:1909.08053 2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![37 ht = [ ht 1 ht 2 ] =](https://files.speakerdeck.com/presentations/385d6cc50ce847b994e1d871010e41d8/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
![40 ht−1 = [ ht−1 1 ht−1 2 ] hidden](https://files.speakerdeck.com/presentations/385d6cc50ce847b994e1d871010e41d8/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
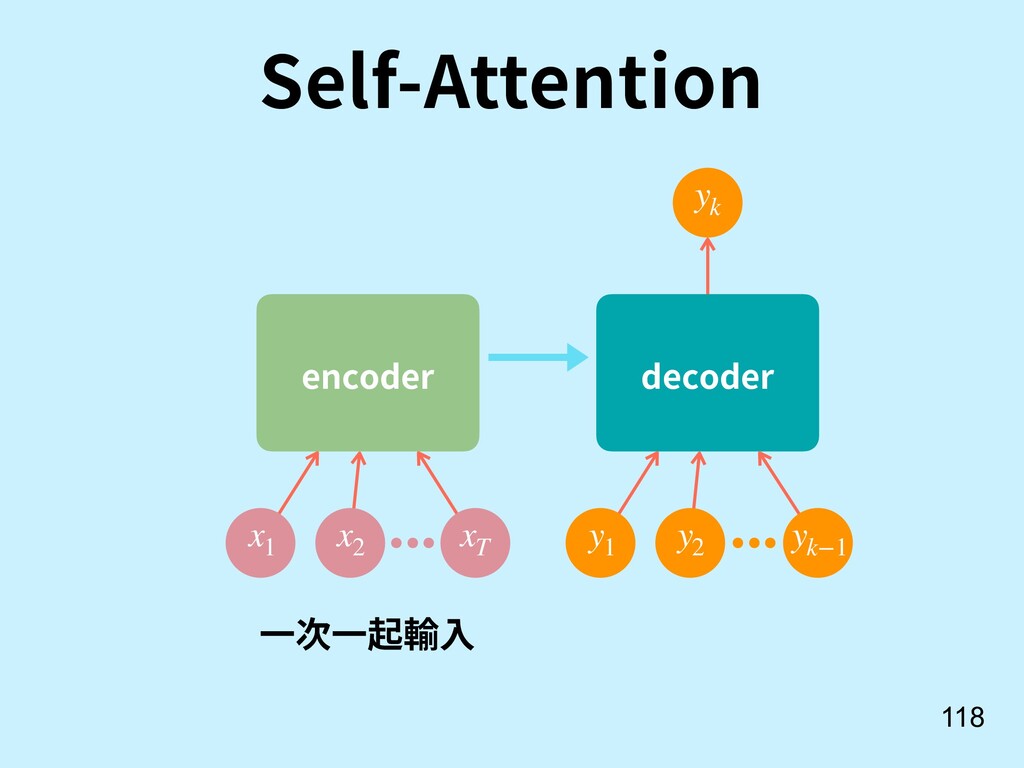
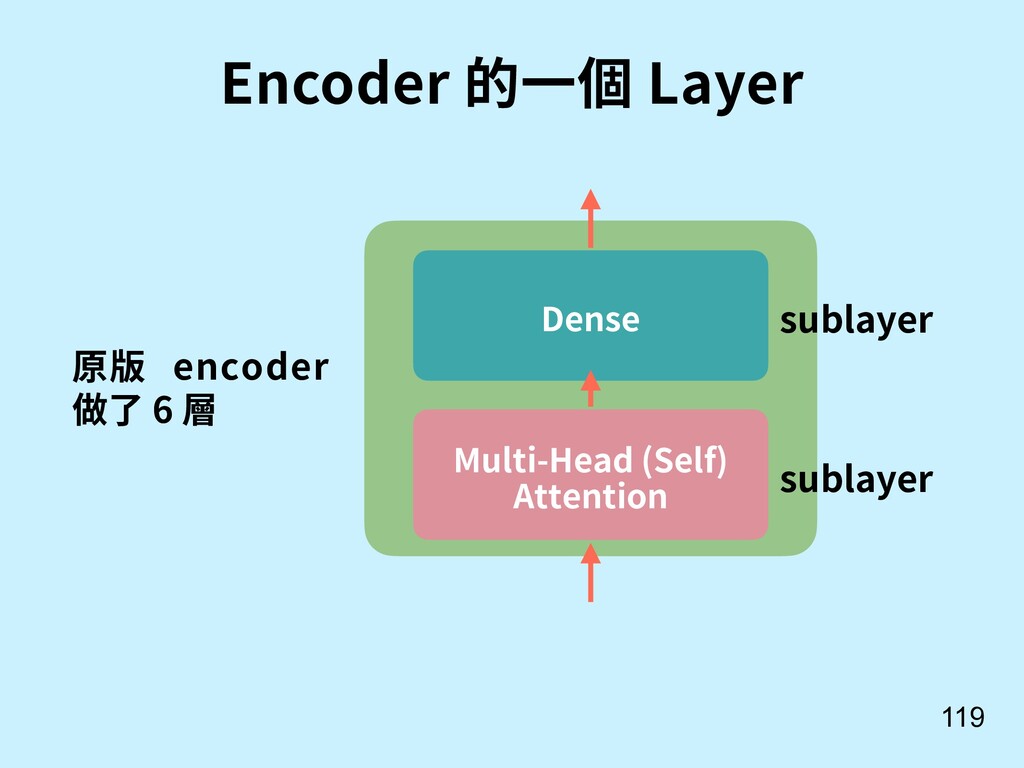
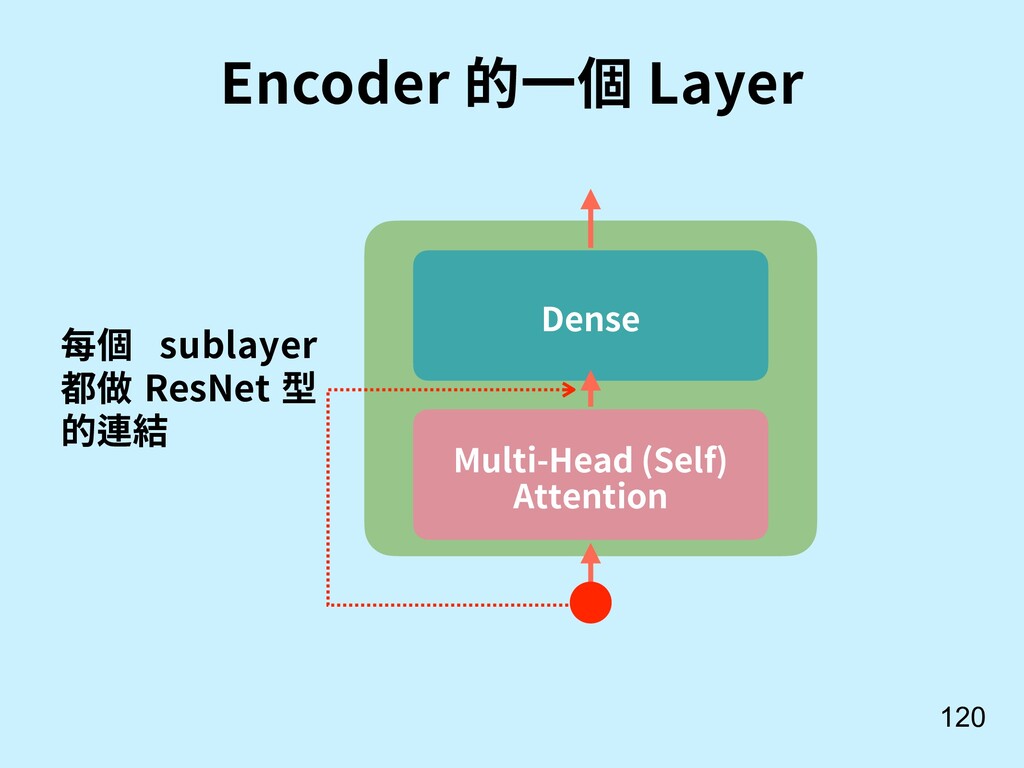
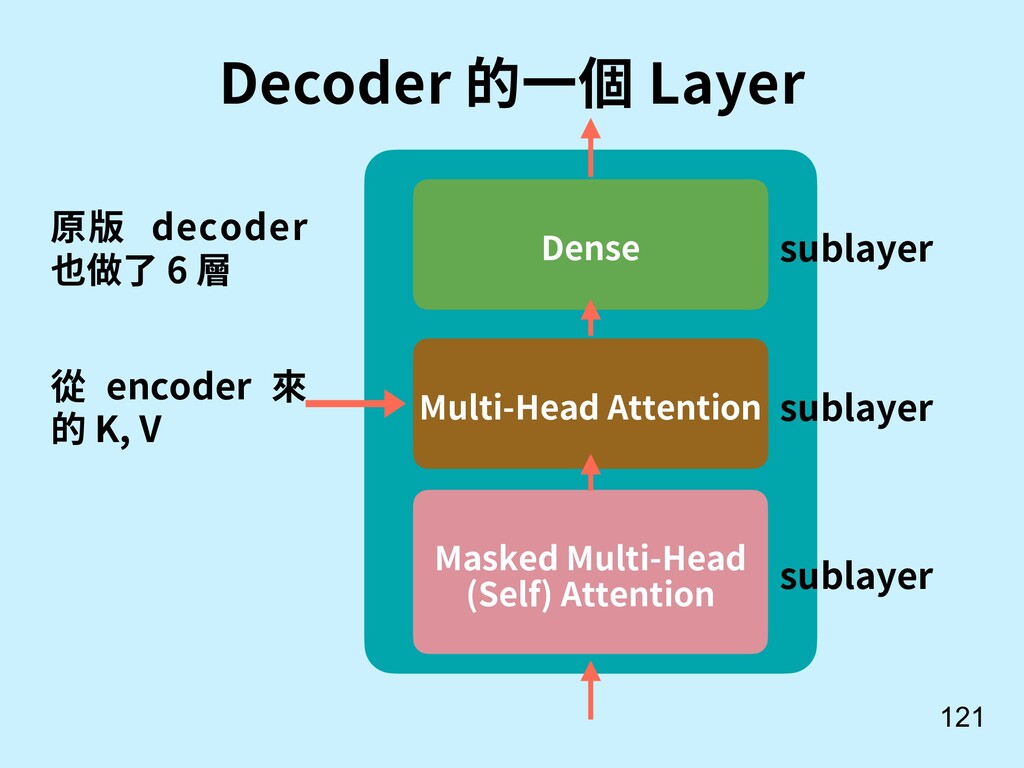
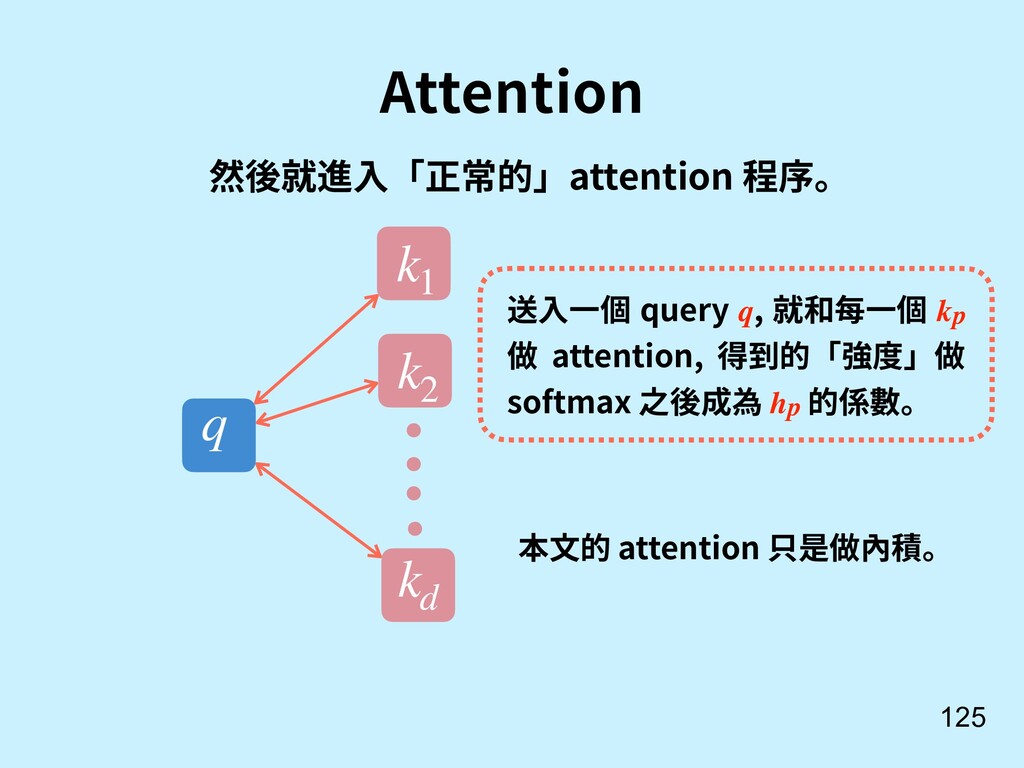
![不⽤ RNN, 可以做 Attention 嗎? 117 [13] Vaswani, A., Shazeer,](https://files.speakerdeck.com/presentations/385d6cc50ce847b994e1d871010e41d8/slide_116.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
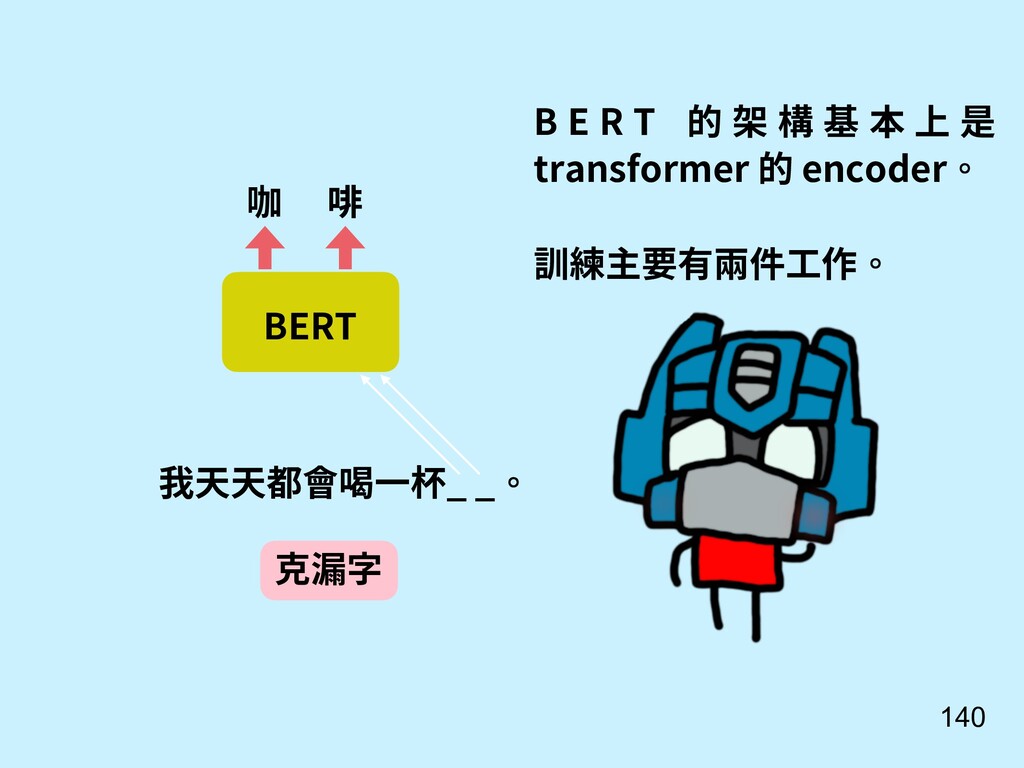
![141 我天天都會喝一杯咖啡 [sep] 微積分很重要 判斷句子是否相連](https://files.speakerdeck.com/presentations/385d6cc50ce847b994e1d871010e41d8/slide_140.jpg){kind=link}
![142 Transformer Encoder [cls] 字1 字T 記得 BERT 是用 transformer,](https://files.speakerdeck.com/presentations/385d6cc50ce847b994e1d871010e41d8/slide_141.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
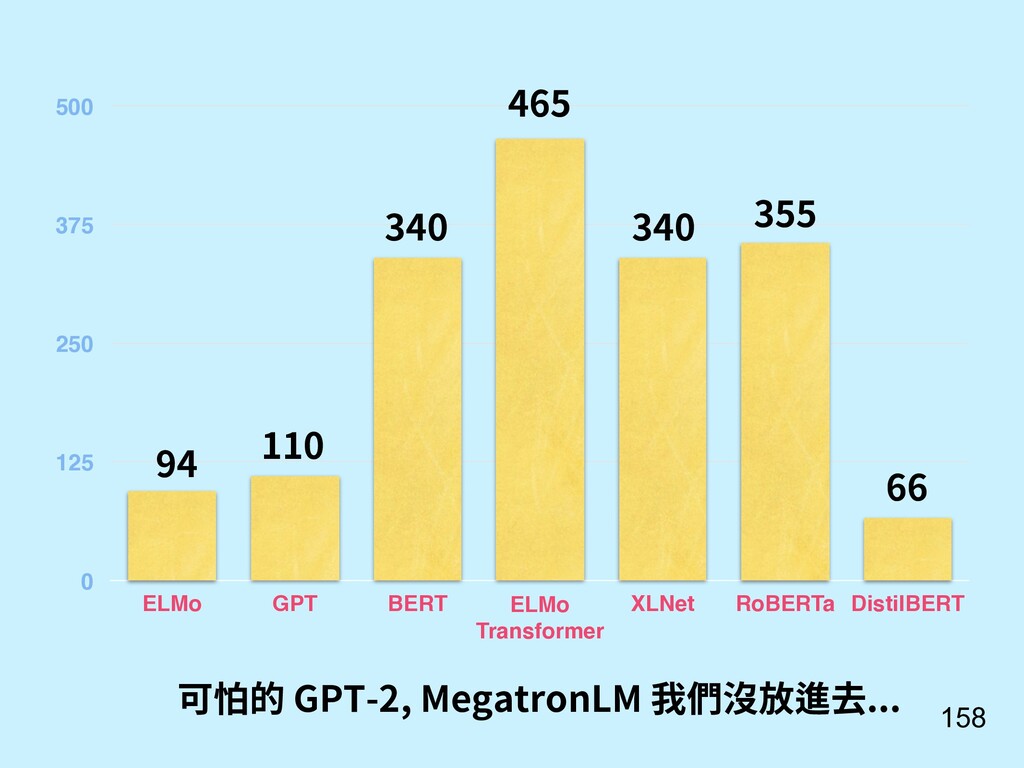{kind=link}
{kind=link}