Share
長岡技術科学大学 自然言語処理研究室 文献紹介(2019-07-16) Contextual String Embeddings for Sequence Labeling https://www.aclweb.org/anthology/C18-1139
{kind=link}
{kind=link}
{kind=link}
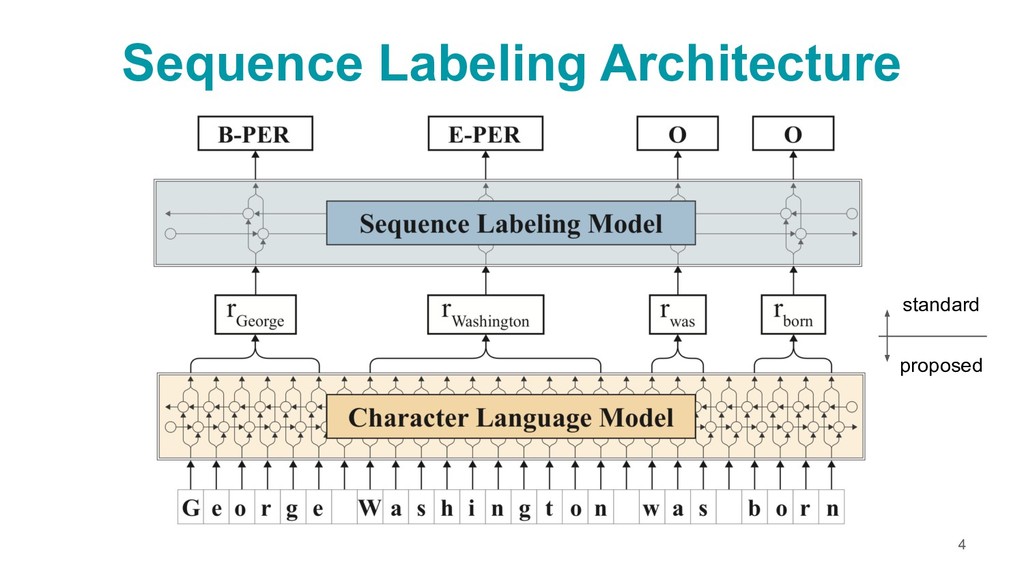{kind=link}
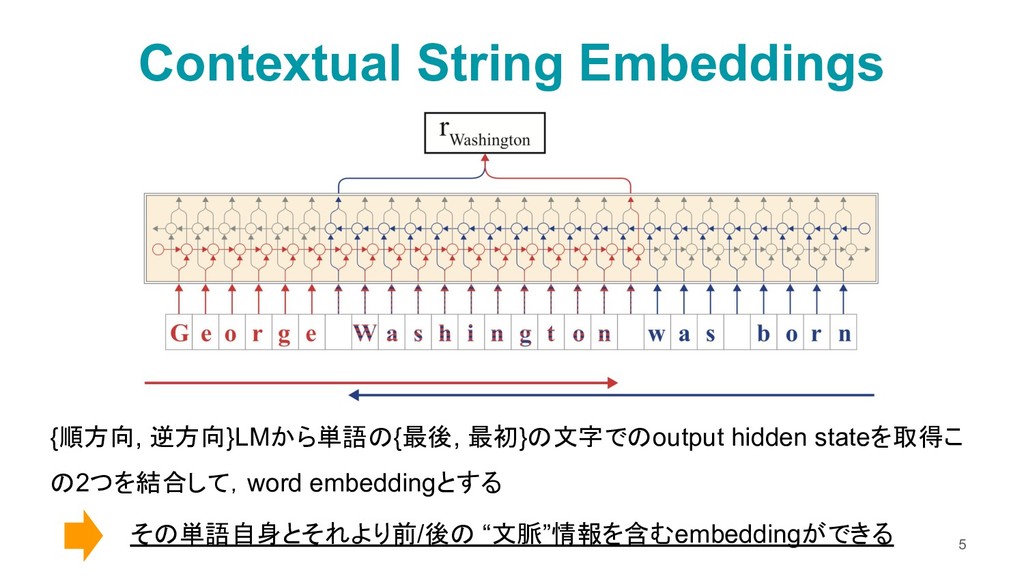{kind=link}
{kind=link}
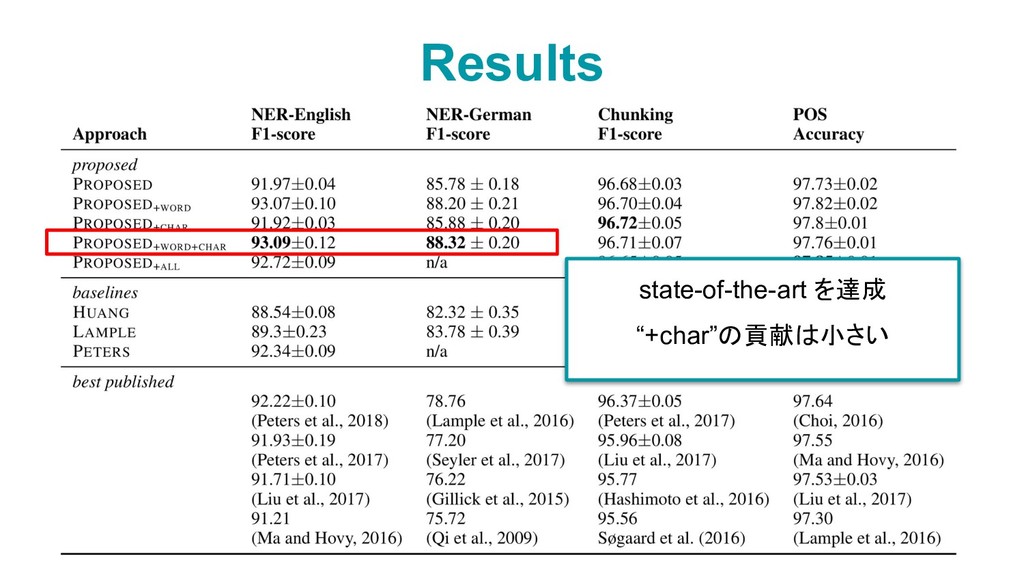
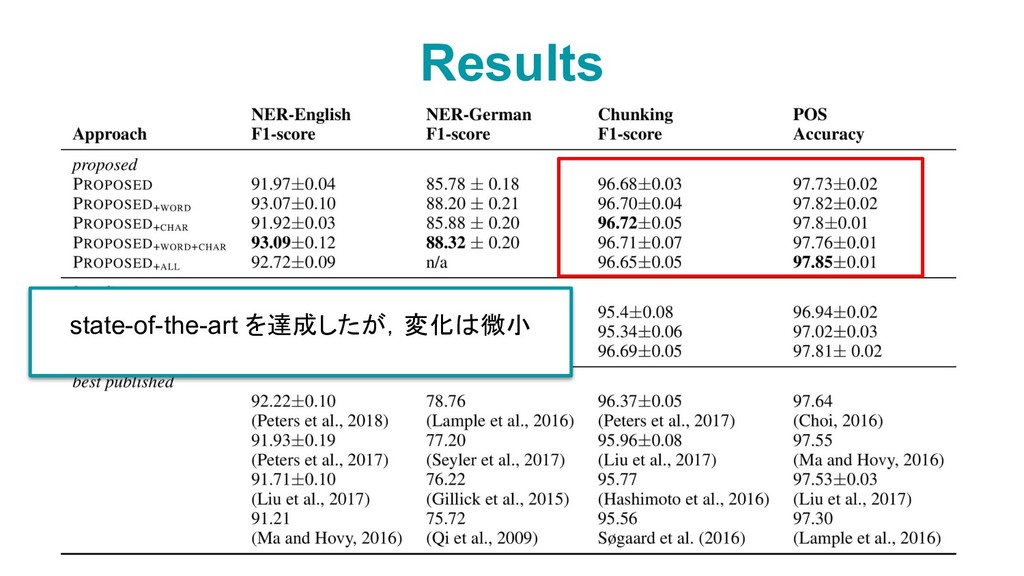
![• HUANG [1] ◦ pre-trained word embeddings ➡ BiLSTM-CRF •](https://files.speakerdeck.com/presentations/9b414f5cc0c64e09ae510ca92eae2243/slide_6.jpg){kind=link}
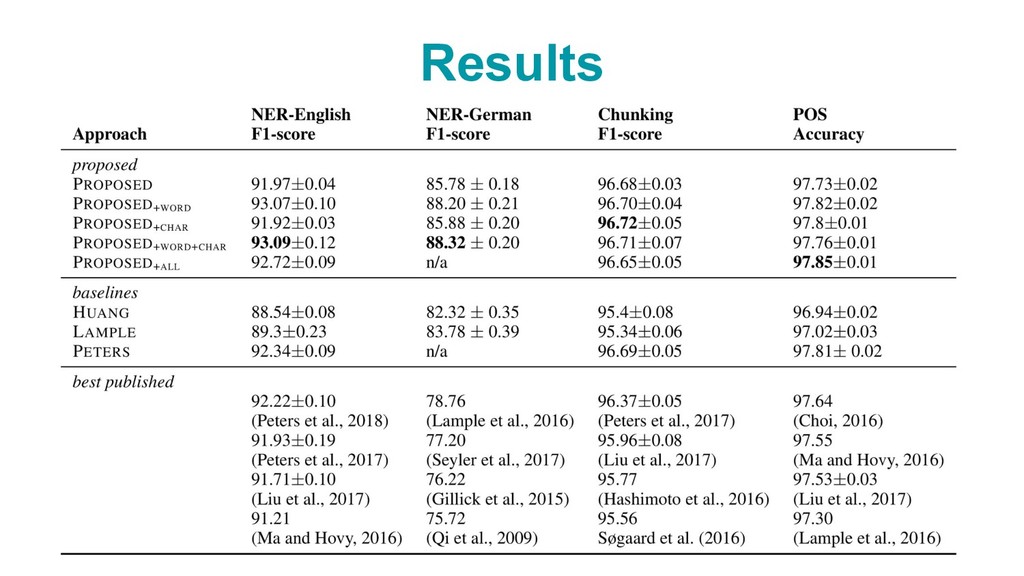{kind=link}
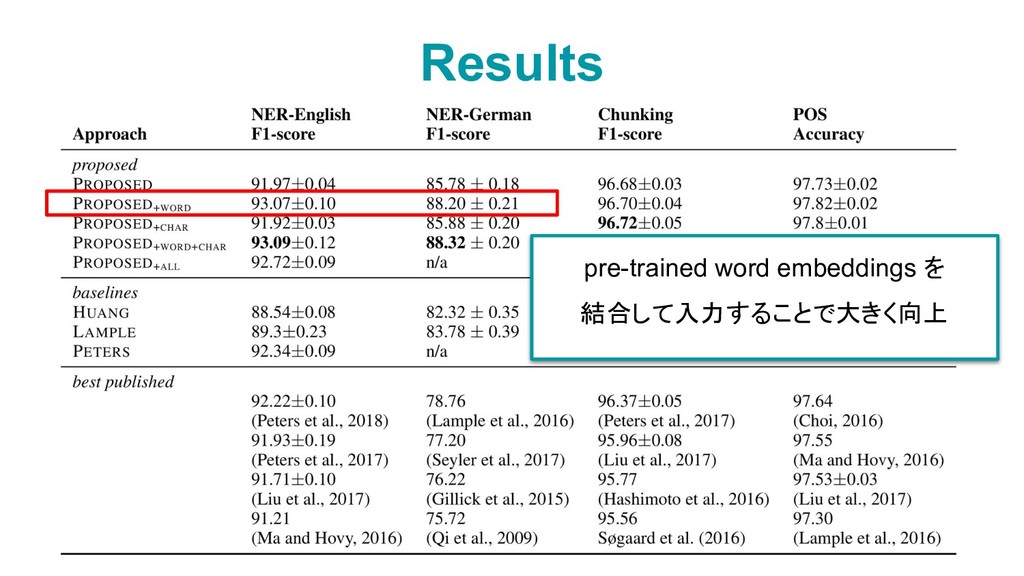{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] Bidirectional LSTM-CRF Models for Sequence Tagging • Huang et](https://files.speakerdeck.com/presentations/9b414f5cc0c64e09ae510ca92eae2243/slide_15.jpg){kind=link}