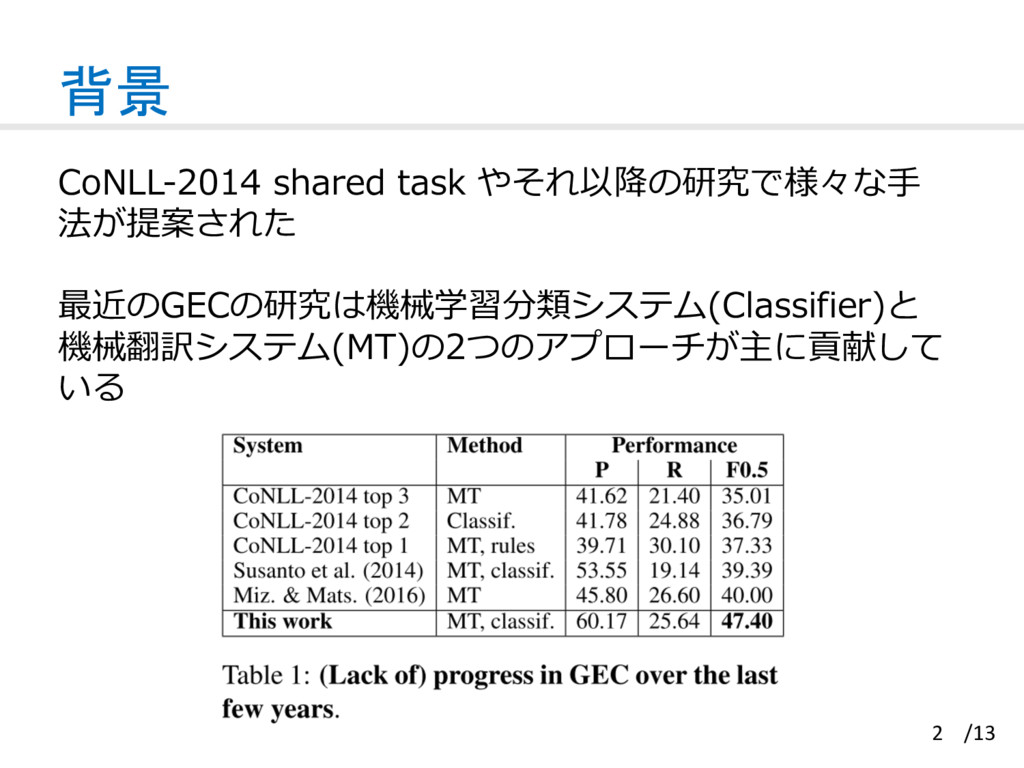
Based Java for Rapid Development of NLP Systems. In Proceedings of LREC. Classifier:ネイティブデータのトレーニング [2] A. Rozovskaya and D. Roth. 2014. Building a State-of-the-Art Grammatical Error Correction System. In Transactions of ACL. Classifierに⾔語リソースの追加 [3] Rozovskaya and D. Roth. 2011. Algorithm selection and model adaptation for ESL correction tasks. In Proceed- ings of ACL.A. CoNLL-2014 shared task [4]H. T. Ng, S. M. Wu, T. Briscoe, C. Hadiwinoto, R. H. Su- santo, and C. Bryant. 2014. The CoNLL-2014 shared task on grammatical error correction. In Proceedings of CoNLL: Shared Task. SMTの構築 [5] M. Junczys-Dowmunt and R. Grundkiewicz. 2014. The AMUsystem in the CoNLL- 2014 shared task: Grammatical error correction by data-intensive and feature-rich statistical machine translation. In Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
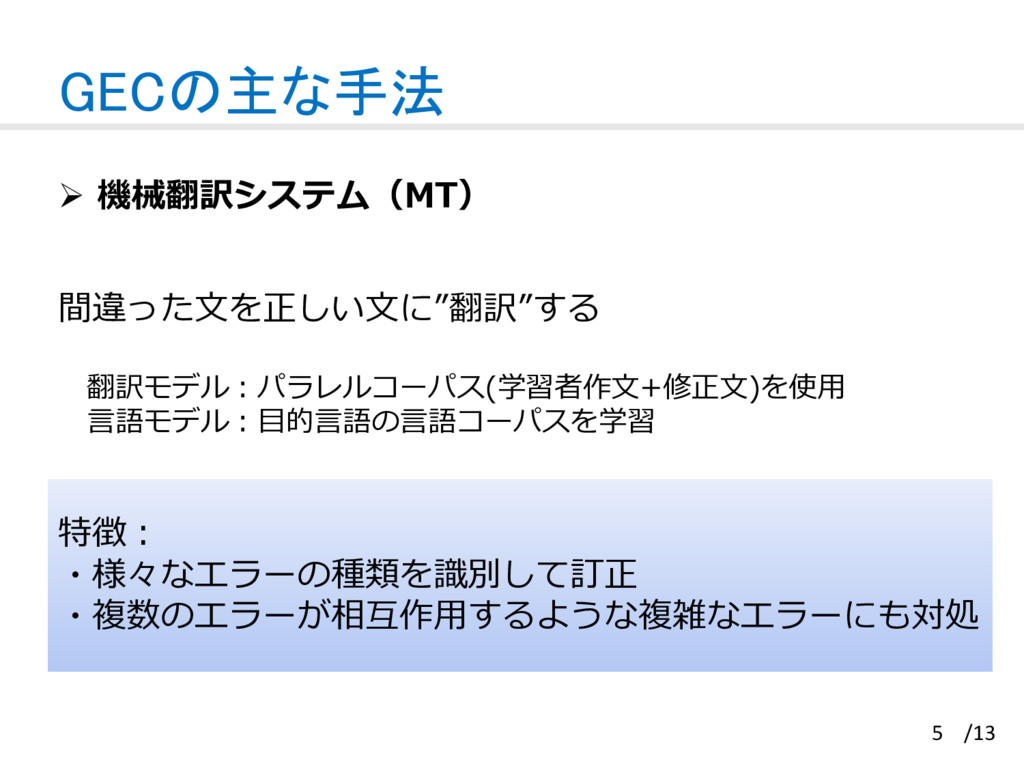
![GECの主な手法 訂正する単語を”分類予測” ⽂中のエラータイプに対して、訂正可能な単語のリストアップ (冠詞,前置詞,数名詞,動詞の調和,動詞の形式,動詞の時制,単語の形式[4]) 訂正可能な単語のうちどれに訂正すれば良いかを分類予測 特徴: ⼤量に⼊⼿可能なネイティブデータを使って訂正が可能 6 Ø 機械学習分類システム(Classifier)](https://files.speakerdeck.com/presentations/c7dca062613d437fbf7b13f41edcf2fb/slide_6.jpg){kind=link}
{kind=link}
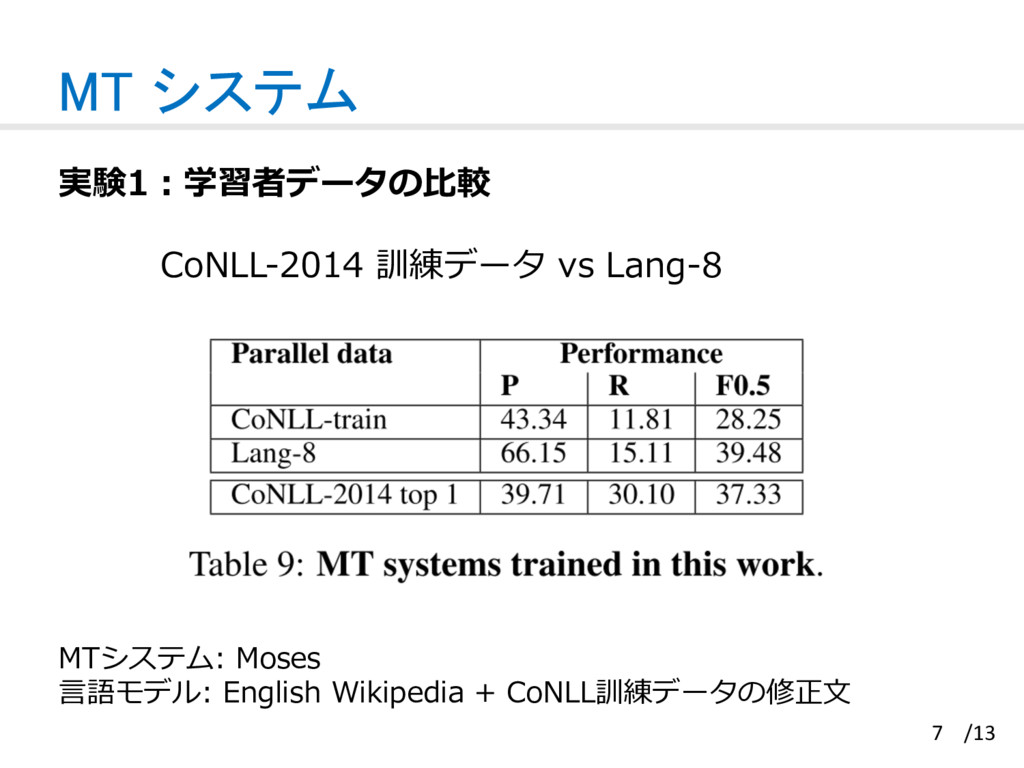
![Classifier システム 実験2:訓練データの⽐較 学習者データ(CoNLL-train)[1] vs ネイティブデータ(Web1T)[2] 学習者データ:⾮ネイティブのエラーパターン情報を保持 ネイティブデータ:安価で⼤量に⼊⼿可能 8 /13](https://files.speakerdeck.com/presentations/c7dca062613d437fbf7b13f41edcf2fb/slide_8.jpg){kind=link}
![Classifier システム 実験3:学習者情報の追加(Tailored) 学習者のエラーパターンをネイティブモデルに適合するとパフォーマン スが向上[3] ネイティブデータで訓練したモデルと学習者データで訓練したモデルを フューチャーして分類 ネイティブデータ→⽂脈情報を付与 学習者データ→⾮ネイティブ特有の書き⽅とエラーパターン情報を付与 9](https://files.speakerdeck.com/presentations/c7dca062613d437fbf7b13f41edcf2fb/slide_9.jpg){kind=link}
{kind=link}
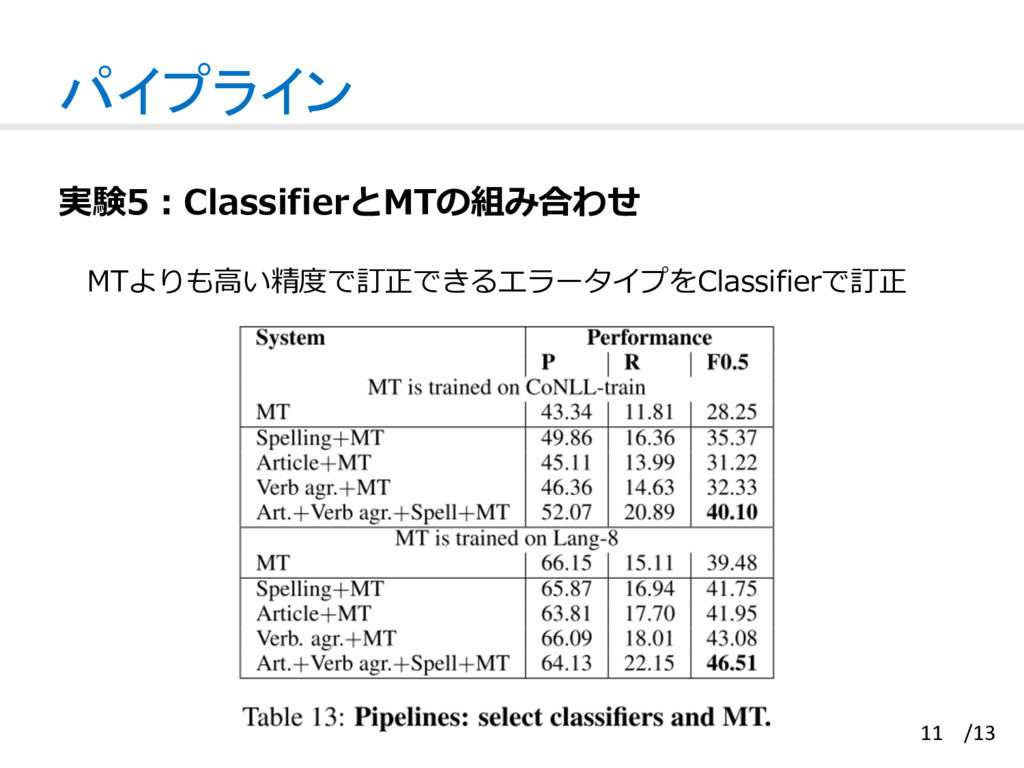{kind=link}
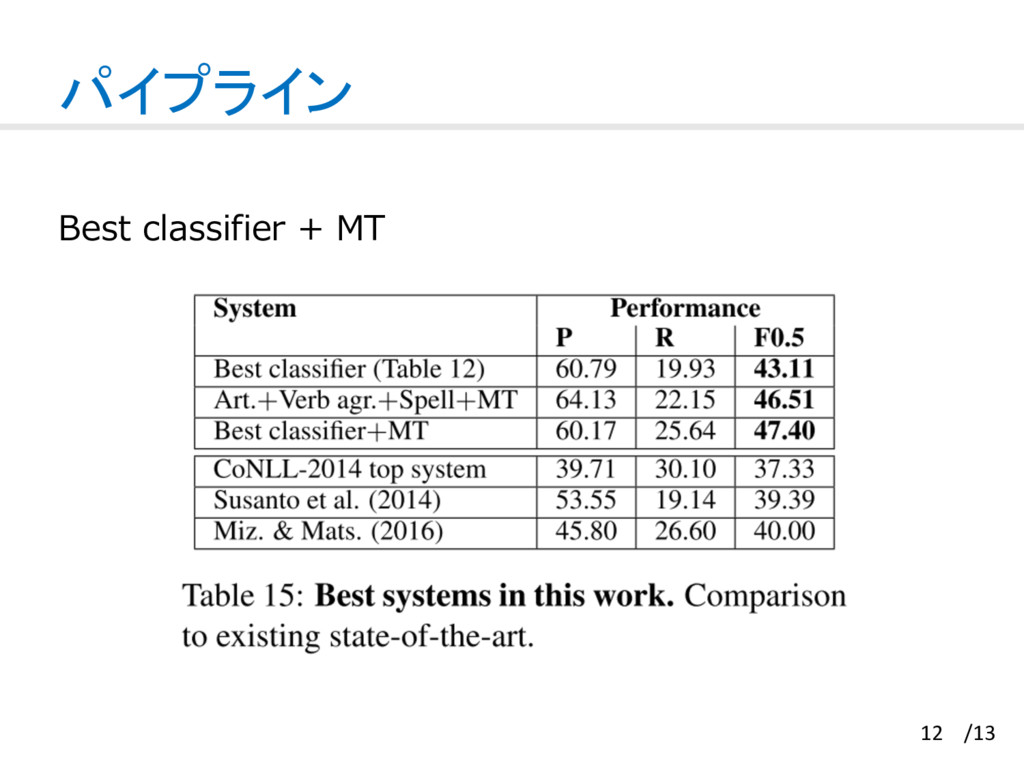{kind=link}
{kind=link}
![参考文献 Classifier:学習者データのトレーニング [1] N. Rizzolo and D. Roth. 2010. Learning](https://files.speakerdeck.com/presentations/c7dca062613d437fbf7b13f41edcf2fb/slide_14.jpg){kind=link}
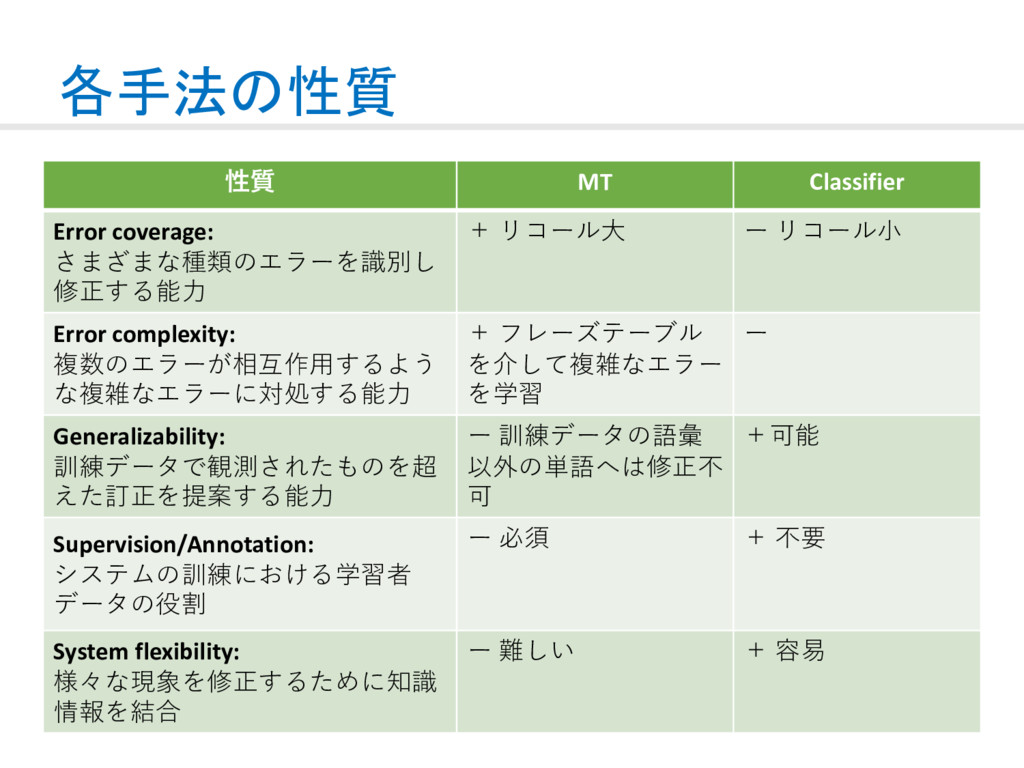{kind=link}
![エラータイプ[4]](https://files.speakerdeck.com/presentations/c7dca062613d437fbf7b13f41edcf2fb/slide_16.jpg){kind=link}