Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Systematically Adapting Machine Translation for...
Search
youichiro
March 27, 2018
Technology
90
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Systematically Adapting Machine Translation for Grammatical Error Correction
文献紹介(2018-03-27)
長岡技術科学大学
自然言語処理研究室
youichiro
March 27, 2018
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
220
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
680
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
270
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
140
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
800
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
370
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
140
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
520
GoでCコンパイラを作った話
repunit
0
150
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
Featured
See All Featured
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Mind Mapping
helmedeiros
PRO
1
290
RailsConf 2023
tenderlove
30
1.5k
The agentic SEO stack - context over prompts
schlessera
0
850
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
510
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Bash Introduction
62gerente
615
220k
Technical Leadership for Architectural Decision Making
baasie
3
440
Optimizing for Happiness
mojombo
378
71k
For a Future-Friendly Web
brad_frost
183
10k
Transcript
Systematically Adapting Machine Translation for Grammatical Error Correction Courtney Napoles
and Chris Callison-Burch Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, pages 345–356, 2017 文献紹介(2018/03/27) 長岡技術科学大学 自然言語処理研究室 小川 耀一朗 1
概要 l 英語学習者作⽂の⽂法誤り訂正⼿法を提案 l 統計的機械翻訳(SMT)を⽂法誤り訂正に適⽤ l 少ない訓練データにおいて最⾼性能のモデルに匹敵する 性能を⽰した 2
誤り訂正のアプローチ ルールベース(rule-based system) 誤りタイプの分類器(classifiers targeting specific error types) 統計的機械翻訳(statistical machine
translation) ニューラル機械翻訳(neural machine translation) 3 ࠷ઌ (Yuan and Briscoe, 2016)
提案手法: SMEC l ⽂法誤り訂正に適した処理をSMTと組み合わせる uスペルミス訂正ルールを追加 u訂正操作のスコア素性 u⽂法誤り訂正の適した評価指標でチューニング を適⽤ 4
提案手法: SMEC uスペルミス訂正ルール *1 u名詞の単数形・複数形の変換*2(singular ⇆ plural) u動詞の基本形、3⼈称単数形、過去形、過去分詞形、進⾏ 形の変換*2(wake, wakes,
woke, woken, waking) *1: PyEnchantを使⽤ *2: RASPʼs morphological generator, morphg (Minnen et al., 2001) を使⽤ 5
提案手法: SMEC u訂正操作のスコアを素性 に⽤いる uSMTの最適化 Ø BLEUではなくGLEU 6
実験設定 l SMT: hierarchical phase-based translation model with Thrax (Weese
et al., 2011) l 訓練データ:Lang-8 corpus(1000kペア) l 開発データ:JFLEG tuning set(751ペア) l テストデータ:JFLEG test set(747ペア) l ⾔語モデル:English Gigaword 5-gram LM 7
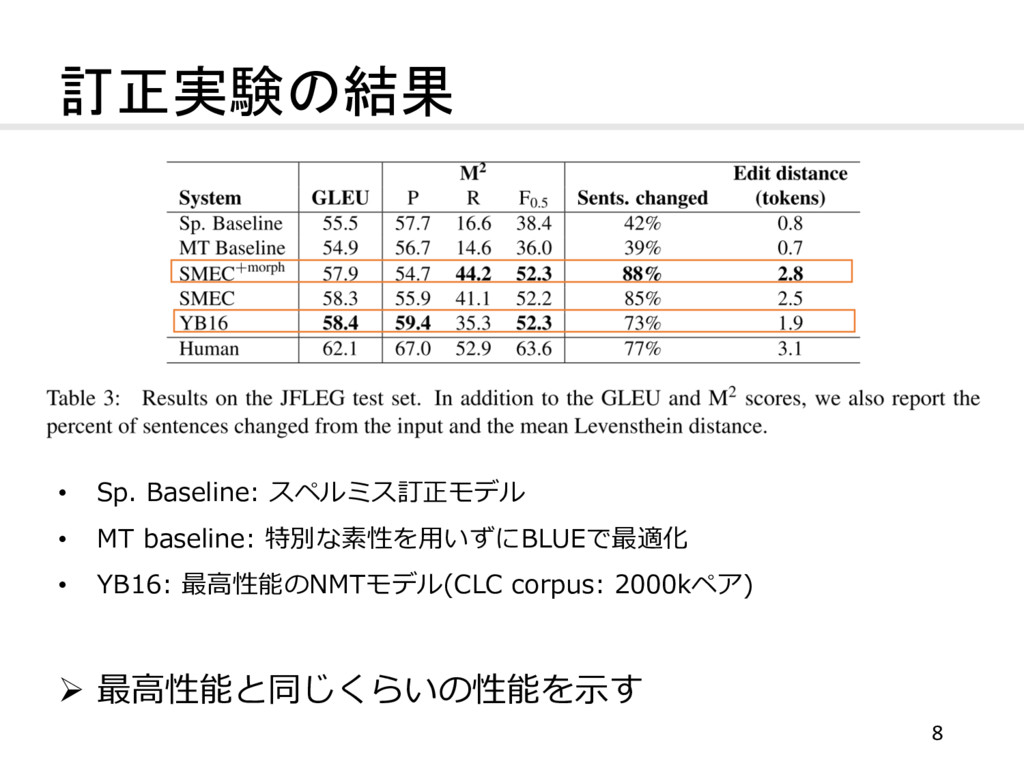
訂正実験の結果 • Sp. Baseline: スペルミス訂正モデル • MT baseline: 特別な素性を⽤いずにBLUEで最適化 •
YB16: 最⾼性能のNMTモデル(CLC corpus: 2000kペア) Ø 最⾼性能と同じくらいの性能を⽰す 8
コンポーネントの比較 • SMEC –GLEU: BLEUでSMTを最適化 • SMEC –feats:特別な素性を⽤いない • SMEC
–sp:スペルミス訂正ルールを⽤いない Ø スペル訂正による効果が⼤きい 9
まとめ n 統計的機械翻訳(SMT)を⽂法誤り訂正に適⽤ l スペル訂正ルールの追加 l 訂正操作のスコア素性 l GLEUによるSMTの最適化 を適⽤
n 半分の訓練データで、最⾼性能モデルの性能に達した 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}