Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
小規模誤りデータからの日本語学習者作文の助詞誤り訂正
Search
youichiro
April 27, 2017
Technology
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
小規模誤りデータからの日本語学習者作文の助詞誤り訂正
平成29年4月28日
文献紹介
長岡技術科学大学 自然言語処理研究室
youichiro
April 27, 2017
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
740
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1.2k
人とエージェントが高め合う協業設計
kintotechdev
0
750
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
610
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
680
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
Featured
See All Featured
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Context Engineering - Making Every Token Count
addyosmani
9
1k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
A designer walks into a library…
pauljervisheath
211
24k
Done Done
chrislema
186
16k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
510
Become a Pro
speakerdeck
PRO
31
6k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
550
ラッコキーワード サービス紹介資料
rakko
1
4M
Transcript
小規模誤りデータからの日本語学習者 作文の助詞誤り訂正 今村 賢治・斎藤 邦子・貞光 九月・西川 仁 自然言語処理, Vol. 19,
No. 5, pp. 381-400, 2012 文献紹介 平成29年4月28日 長岡技術科学大学 自然言語処理研究室 小川耀一朗
概要 • 日本語学習者作文の助詞の誤りを自動訂正する • 大規模な学習者作文コーパスを集めるのは難しい • 少量の学習者作文から獲得したn-gram二値素性と、大規 模コーパスから獲得した言語モデル確率の併用 → 再現率の向上
• 自動生成した疑似誤り文を訓練コーパスに追加 → 安定した精度向上 2/15
日本語学習者の誤り傾向 日本語学習者37名から、2770文の学習者作文を収集 日本語母語話者が作文の誤りを訂正 訂正が可能:2171文 誤りの発生箇所:4916箇所 (大分類) - 文法誤り:54% - 語彙誤り:28%
- 表記誤り:16% - その他:複数の誤りが混在 3 (小分類) - 助詞・助動詞誤り:33% - カタカナ語誤り:11% - 単語選択(類義語)の誤り:10% /15
日本語学習者の誤り傾向 誤りの出現頻度の高い助詞誤りを訂正対象とした 助詞誤り - 置換誤り:74% - 助詞のぬけ:17% - 余分な助詞の出現:9% 原文を置換、挿入、削除することにより誤り訂正を行う
4/15
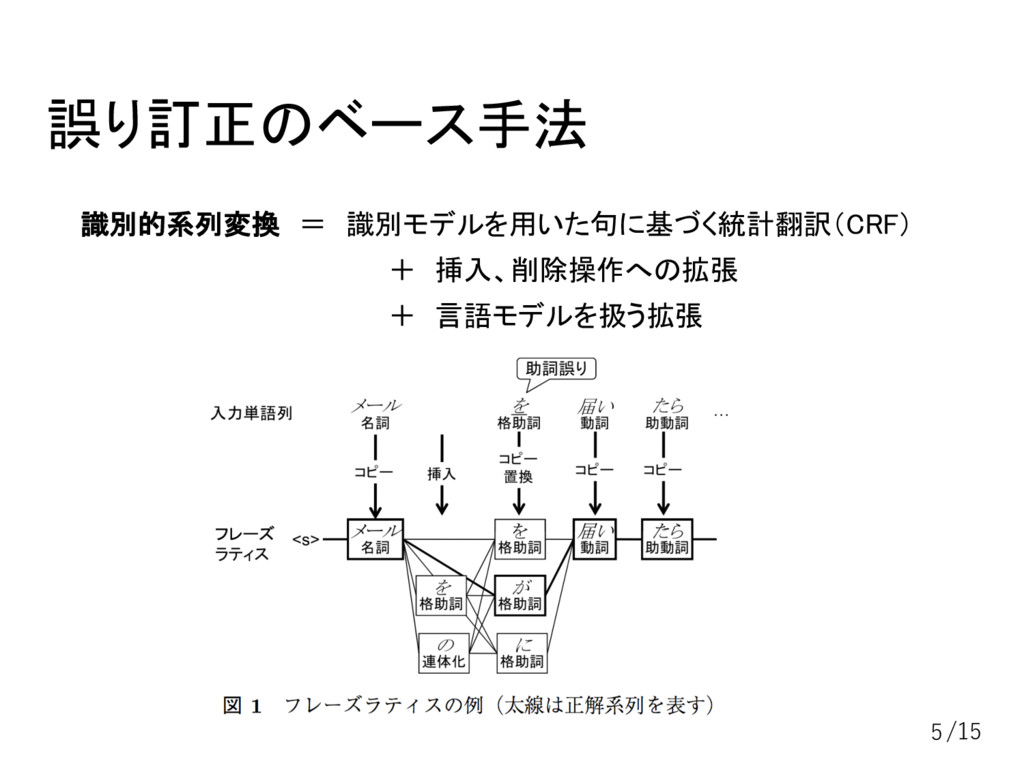
誤り訂正のベース手法 識別的系列変換 = 識別モデルを用いた句に基づく統計翻訳(CRF) + 挿入、削除操作への拡張 + 言語モデルを扱う拡張 5/15
誤り訂正のベース手法 識別的系列変換では2種類の素性を用いる ・マップ素性:入力と出力のフレーズ対応度を測る (翻訳モデル) ・リンク素性:出力単語列の日本語としてのもっともらしさを測る (言語モデル) 6/15
誤り訂正のベース手法 識別的系列変換では2種類の素性を用いる ・マップ素性:入力と出力のフレーズ対応度を測る (翻訳モデル) ・リンク素性:出力単語列の日本語としてのもっともらしさを測る (言語モデル) ↓ ・ n-gram二値素性 ・
言語モデル確率 7/15
誤り訂正のベース手法 識別的系列変換では2種類の素性を用いる ・マップ素性:入力と出力のフレーズ対応度を測る (翻訳モデル) ・リンク素性:出力単語列の日本語としてのもっともらしさを測る (言語モデル) ↓ ・ n-gram二値素性 ・
言語モデル確率 出力単語列のn-gram確率の対数値を実数素性として使用 訓練コーパスに限らず大量の文から構築できる 訓練コーパスに出現しなくてもスコアを与えることができる 8/15
提案手法 ・ n-gram二値素性 ・ 言語モデル確率 の2種類のリンク素性を併用することを提案 言語モデルの構築に大規模な日本語コーパスを適用するこ とで、未知テキストに対し頑健な修正が行える 9/15
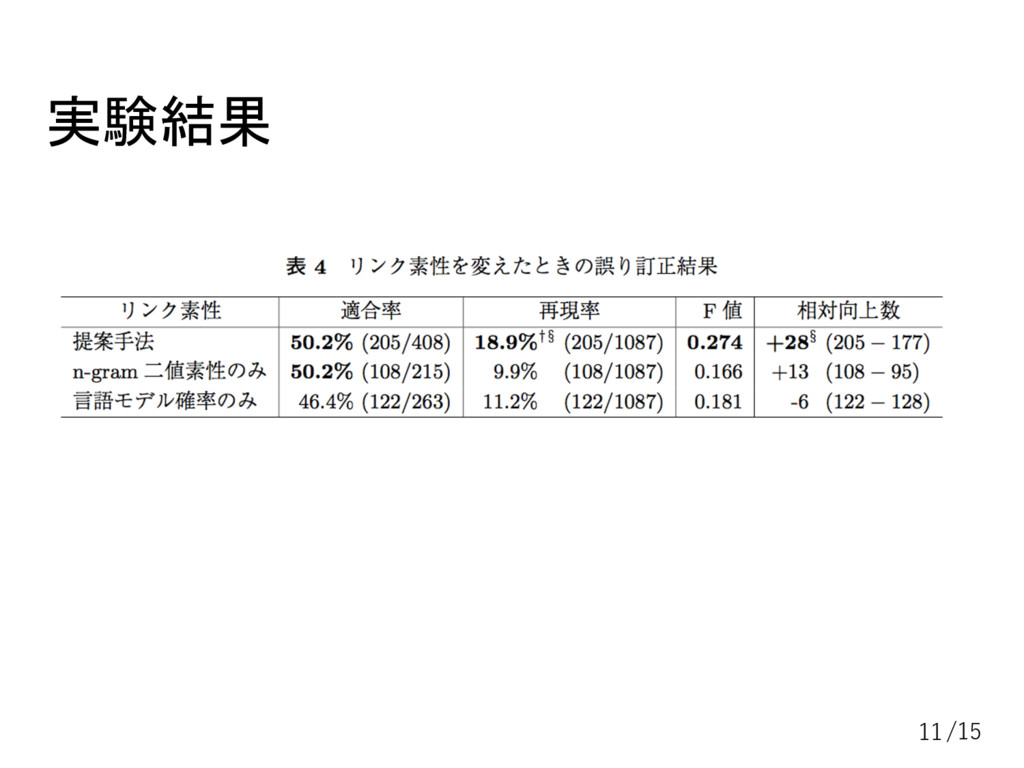
実験1 日本語平文コーパスの利用 学習者作文コーパスから助詞誤りのみを抽出(1087箇所) 言語モデル:WikipediaとCentOS5日本語マニュアルから527,151文 評価方法: ・コーパスを5分割交差検定 ・適合率、再現率、F値 ・相対向上数 (訂正によって品質が)向上した助詞数 –
悪化した助詞数 10/15
実験結果 11/15
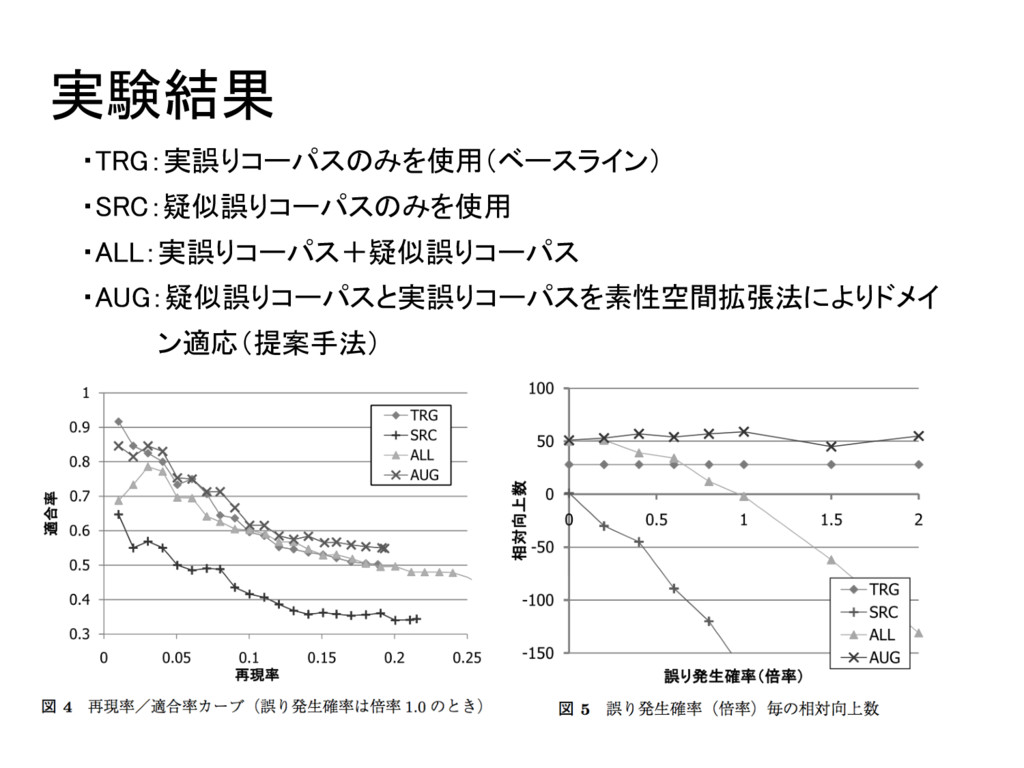
疑似誤り文によるペア文の拡張 収集した日本語コーパスの文を学習者作文のように誤らせる 誤った助詞とその訂正候補を逆に適用する 実誤りコーパスでの助詞誤りの発生確率に従って誤らせる 自動生成した疑似誤りの分布を、実際の誤りの確率分布に近づける → 素性空間拡張法(Daume Ⅲ 2017)を用いる 12/15
実験2 疑似誤り文によるペア文の拡張 疑似誤りコーパス: 言語モデル作成用コーパスから10,000文取得して生成 誤り発生確率: 実誤りコーパス上での相対頻度を倍率1.0とし、倍率0.0〜2.0まで変化さ せて実験 評価方法: ・コーパスを5分割交差検定 ・適合率、再現率
・相対向上数 (訂正によって品質が)向上した助詞数 – 悪化した助詞数 13/15
実験結果 ・TRG:実誤りコーパスのみを使用(ベースライン) ・SRC:疑似誤りコーパスのみを使用 ・ALL:実誤りコーパス+疑似誤りコーパス ・AUG:疑似誤りコーパスと実誤りコーパスを素性空間拡張法によりドメイ ン適応(提案手法) 14
まとめ • 日本語学習者の日本語作文における、助詞誤り訂正法を 提案した • n-gram二値素性と言語モデル確率を併用し、誤り訂正の再 現率を向上させた • 学習者作文を模した疑似誤り文を自動生成し、学習コーパ スに追加する際にドメイン適応を併用することで、誤り発生
確率によらず安定した精度向上ができる 15/15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}