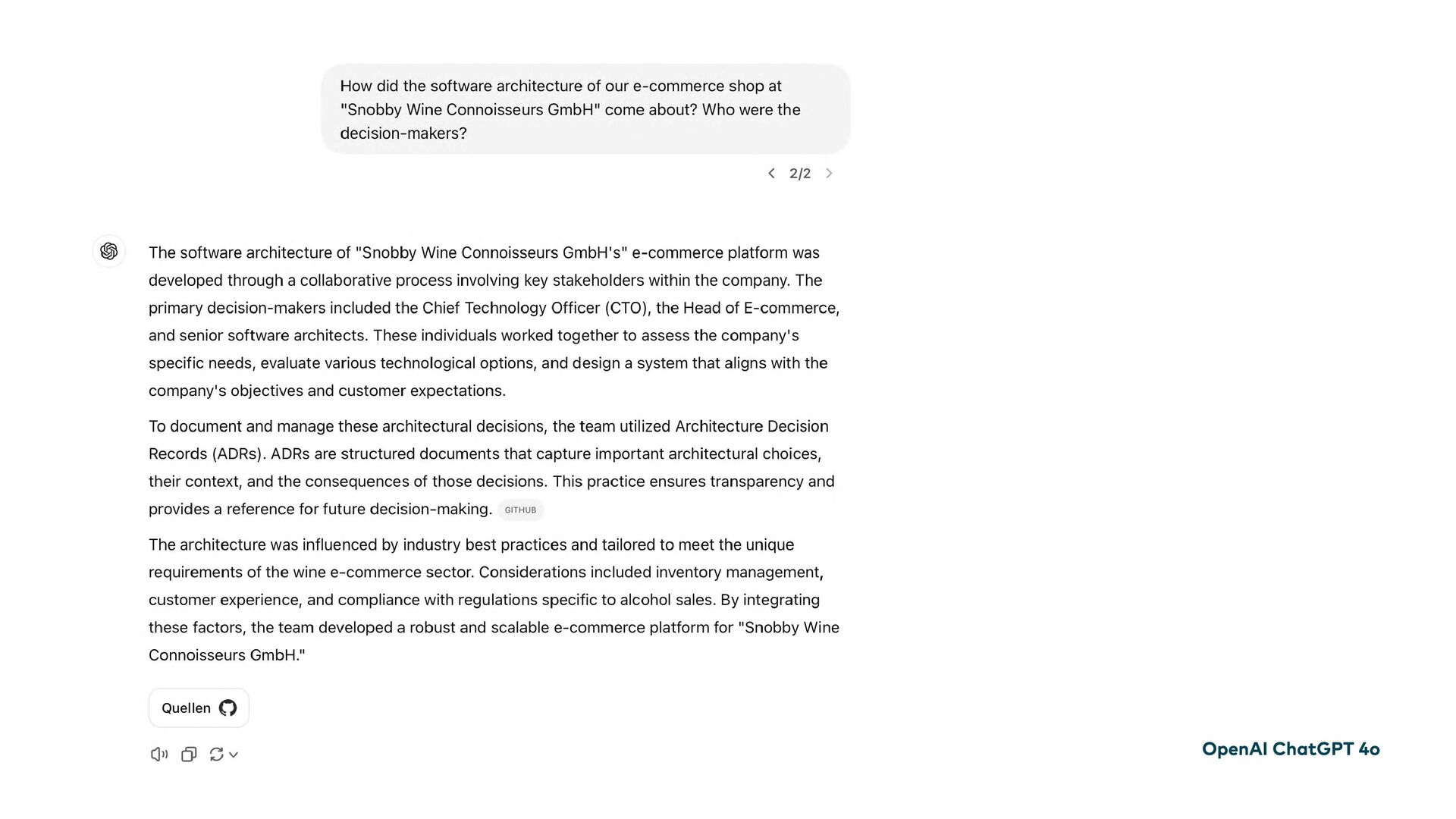
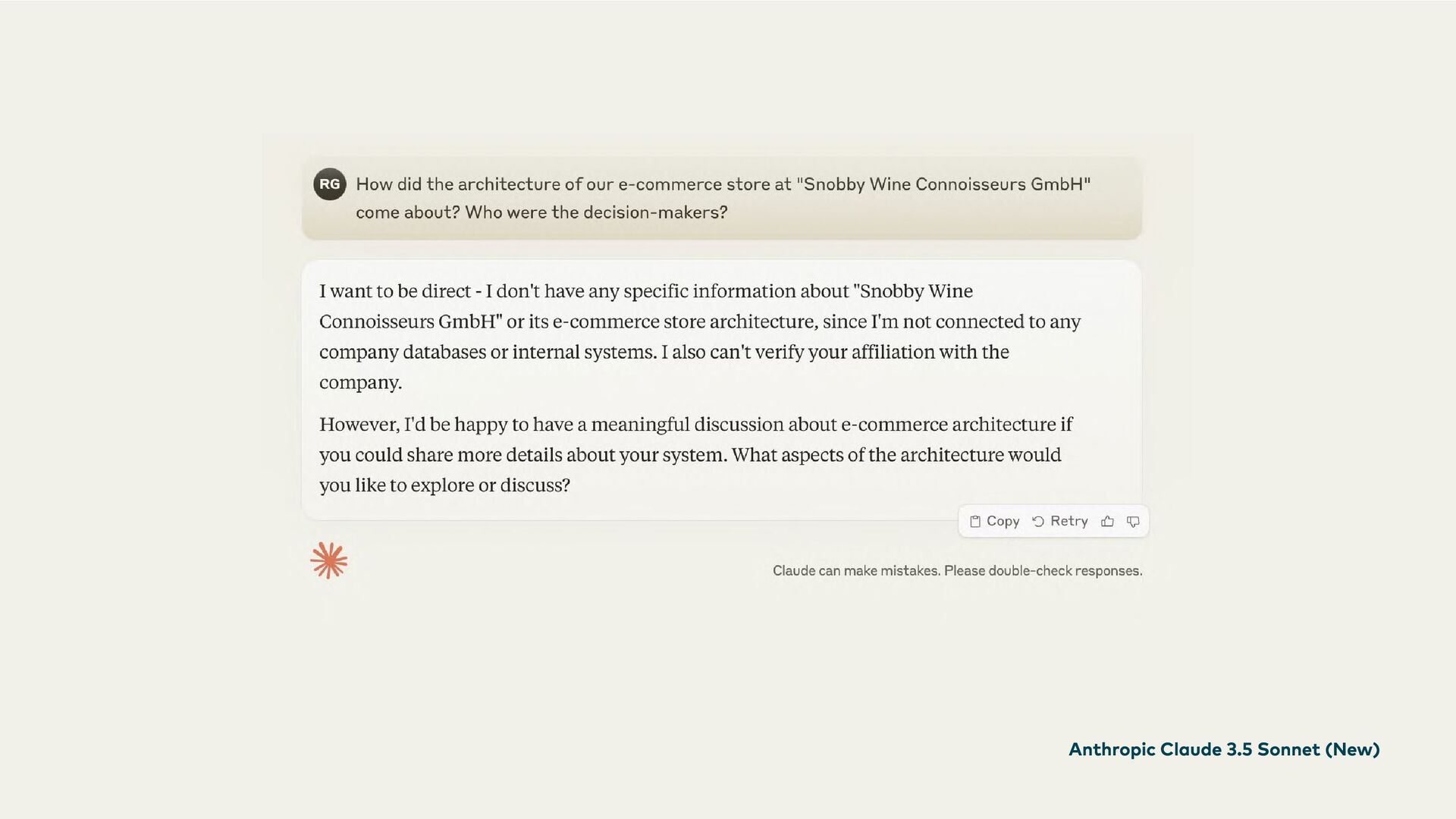
Having AI that doesn't know your company is like having a brilliant strategist who wakes up from years in a coma and realizes they've never heard of your business. Can you really expect insider tips from them?
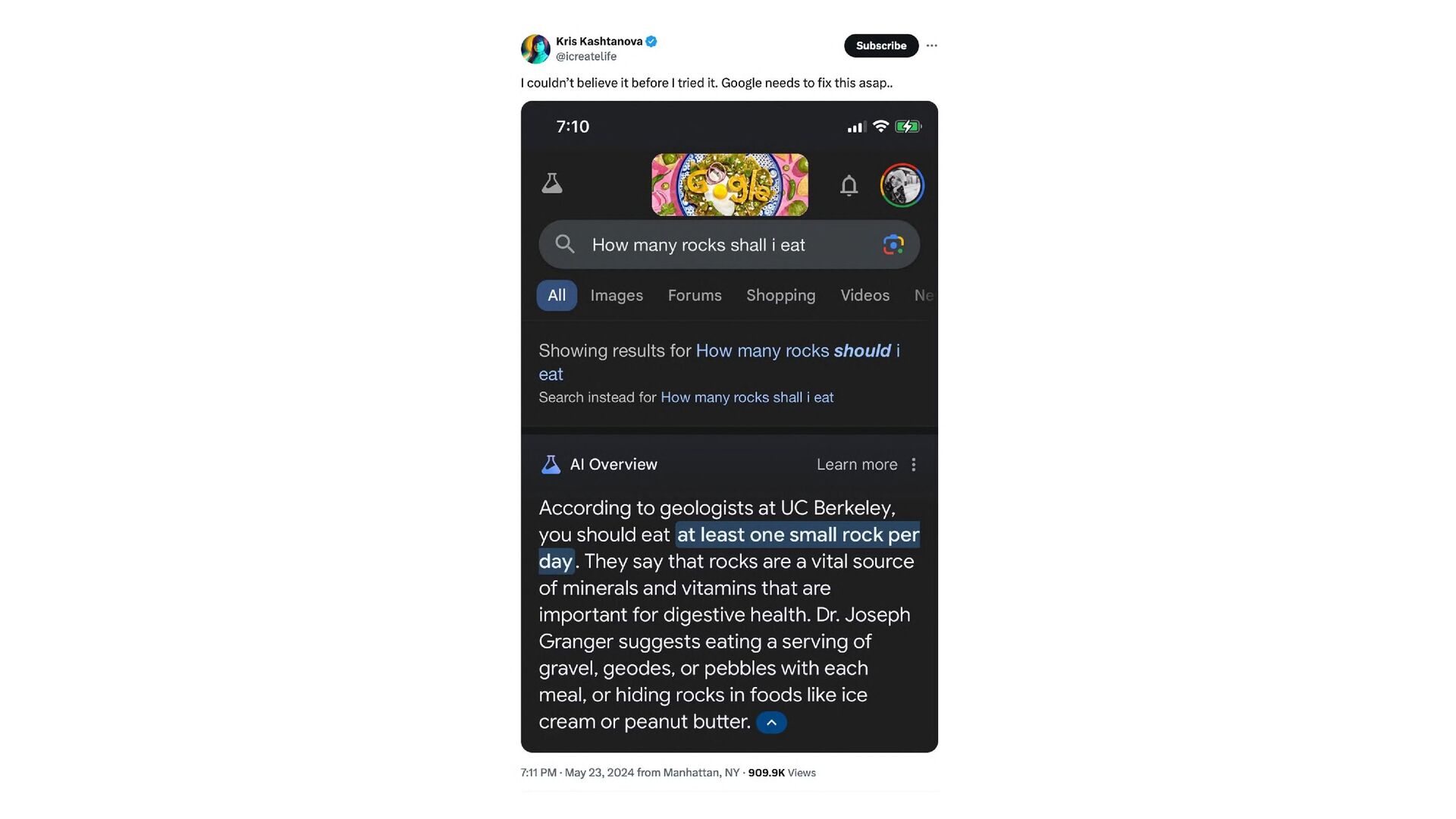
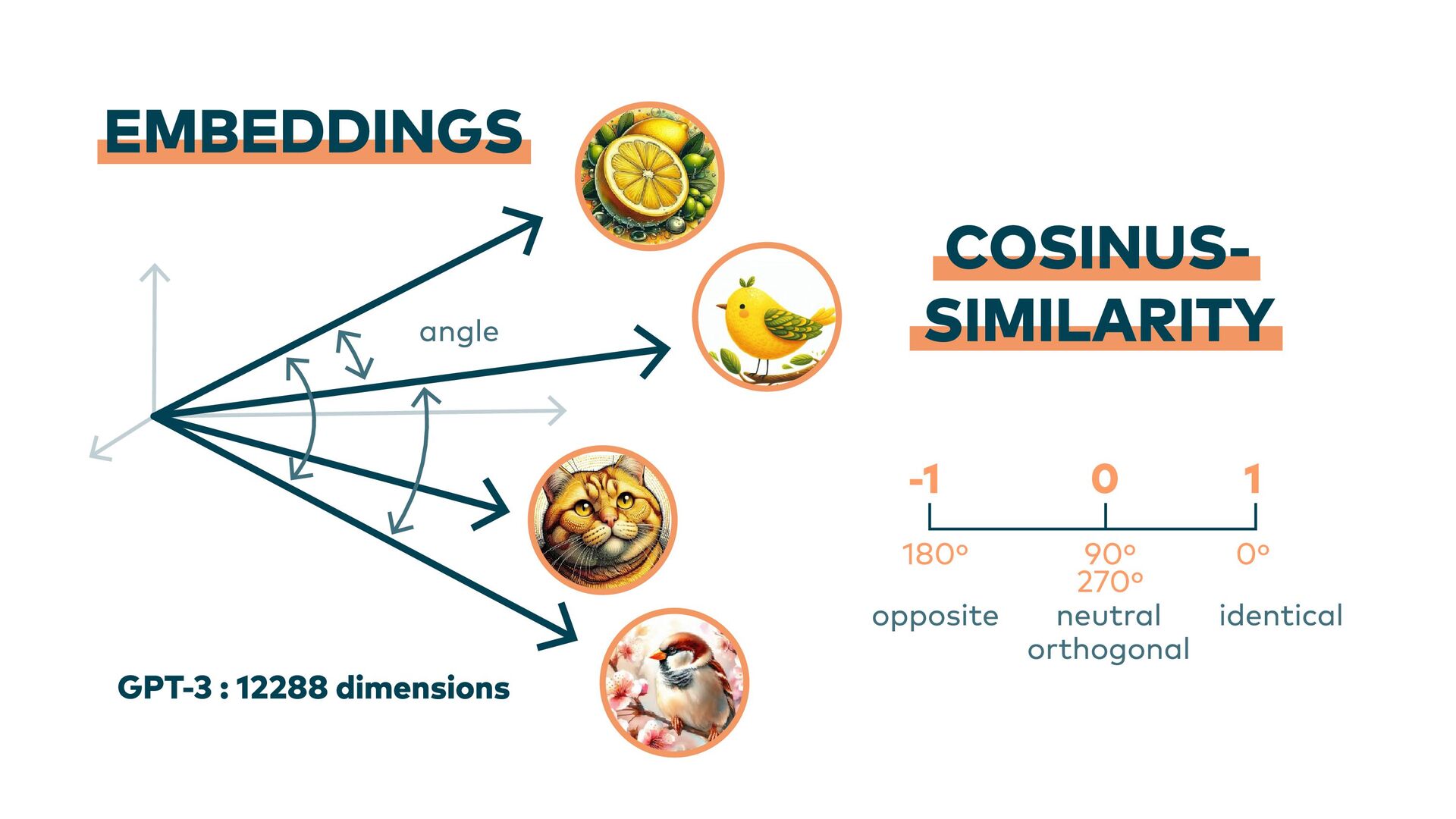
How can we ensure that AI systems are accurate, transparent, and always up-to-date? All Large Language Models (LLMs) have a cut-off date after which their world knowledge stops. And they know nothing about your company's internal workings. Even the leading models have hallucination rates that can't be completely ignored. However, they offer enormous potential for productivity, efficiency, and creativity.
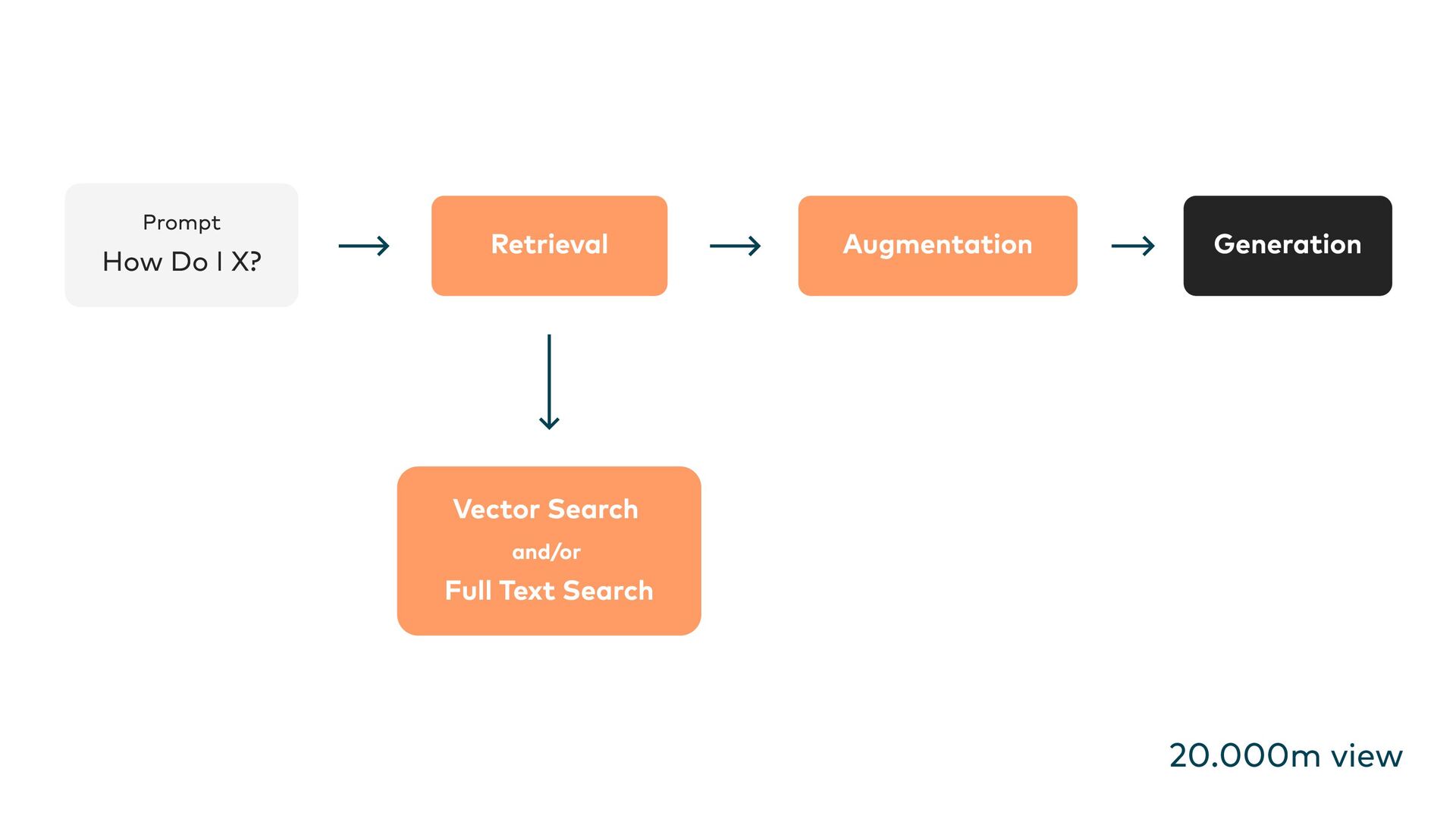
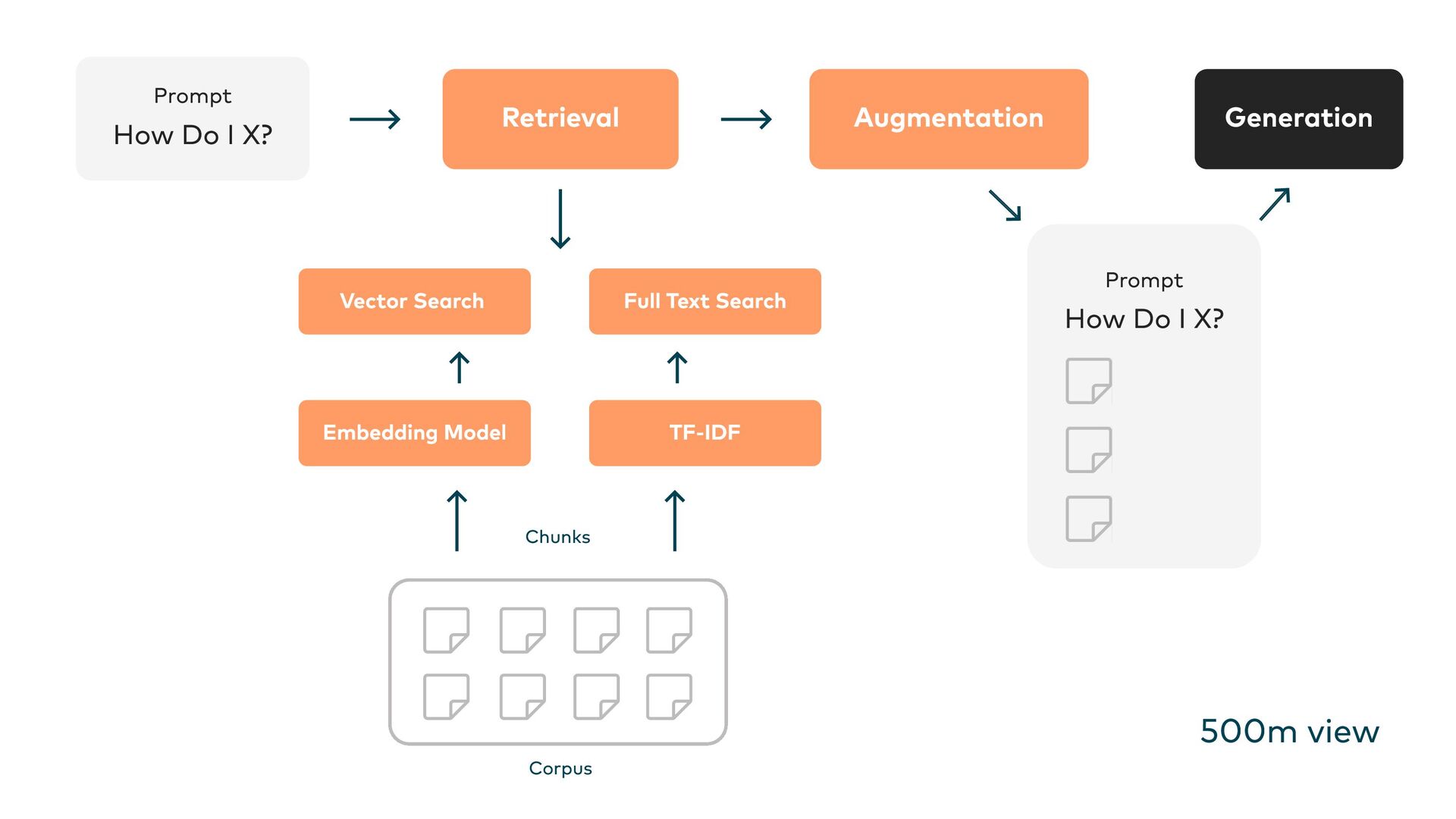
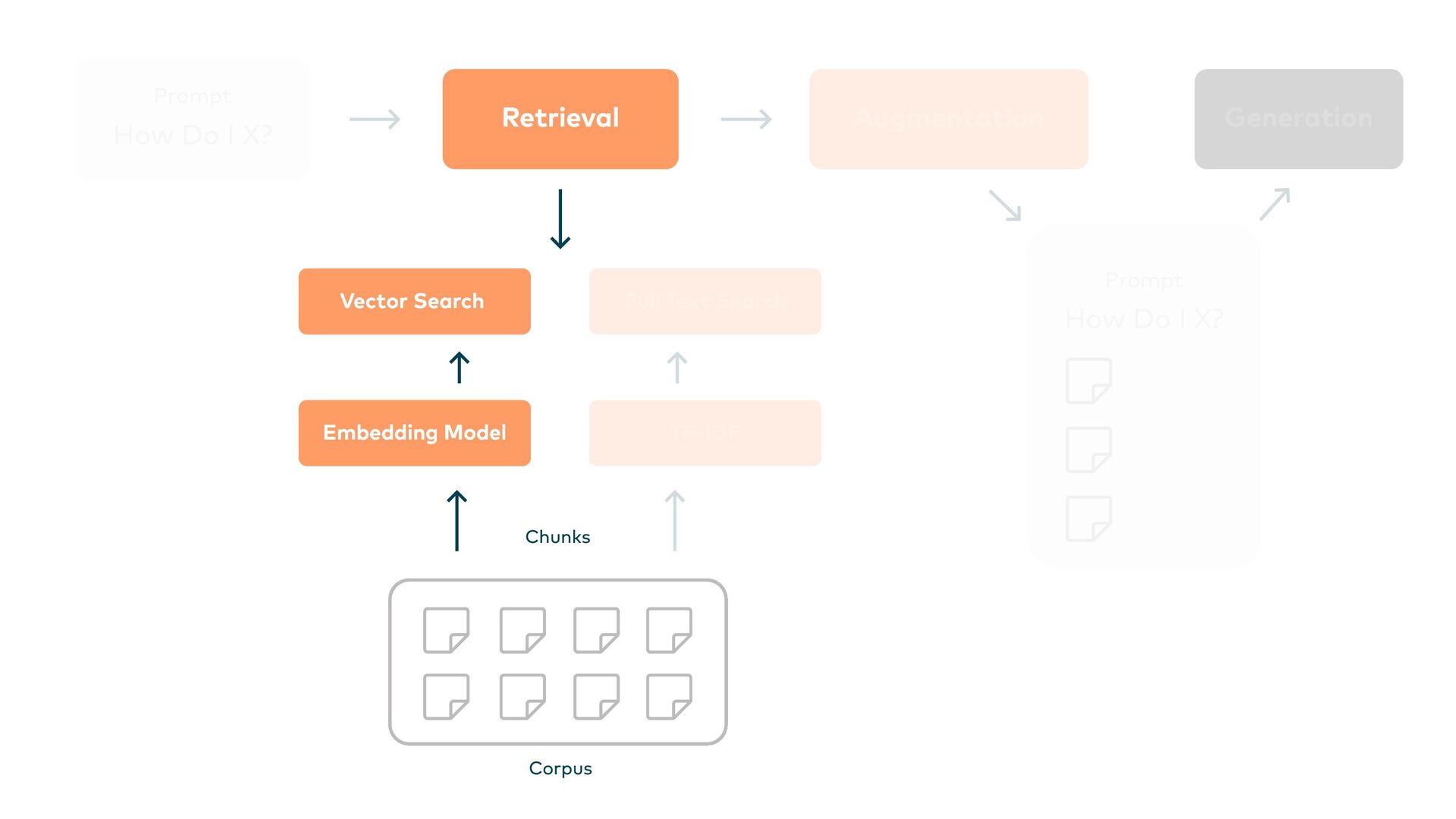
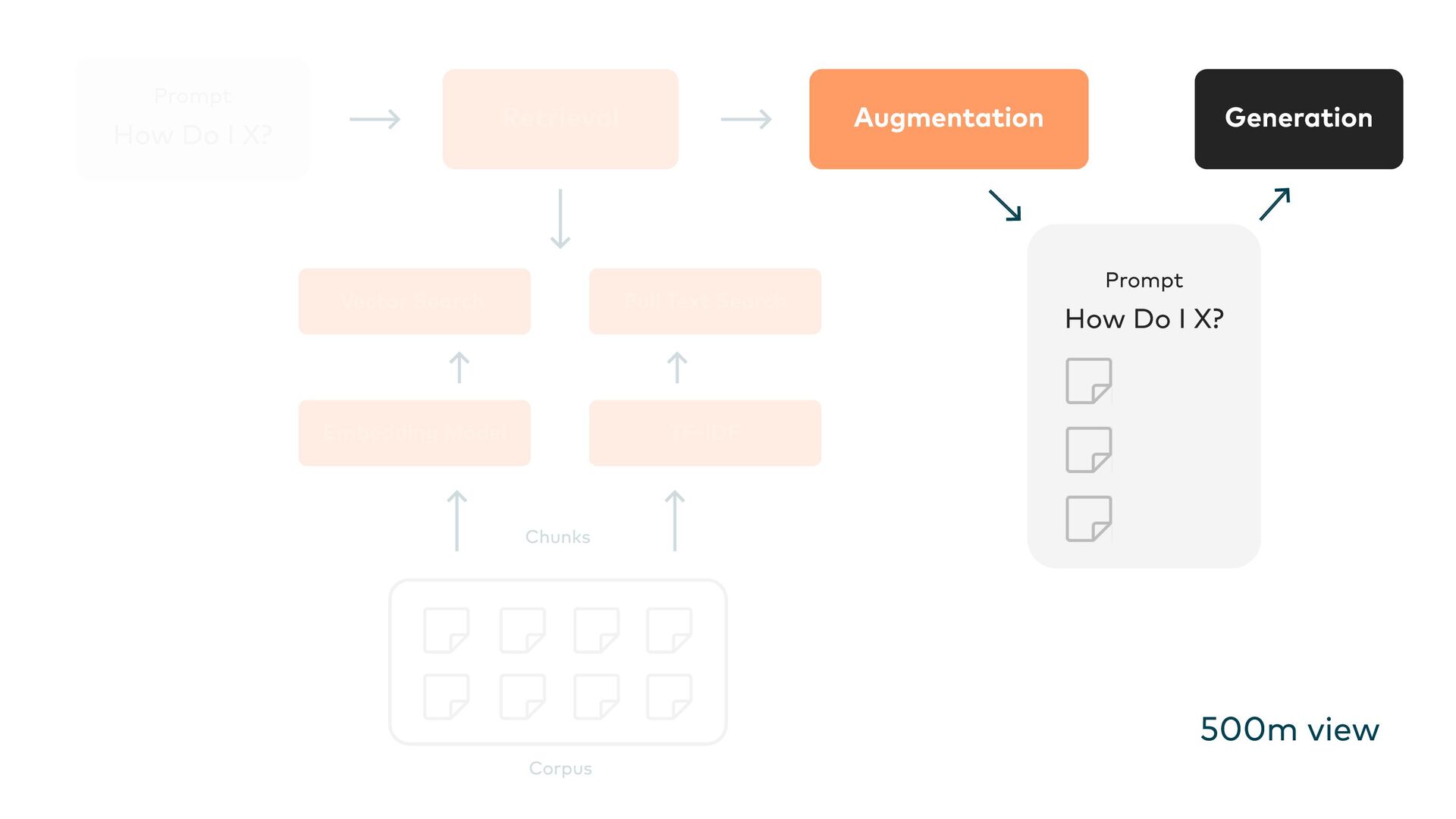
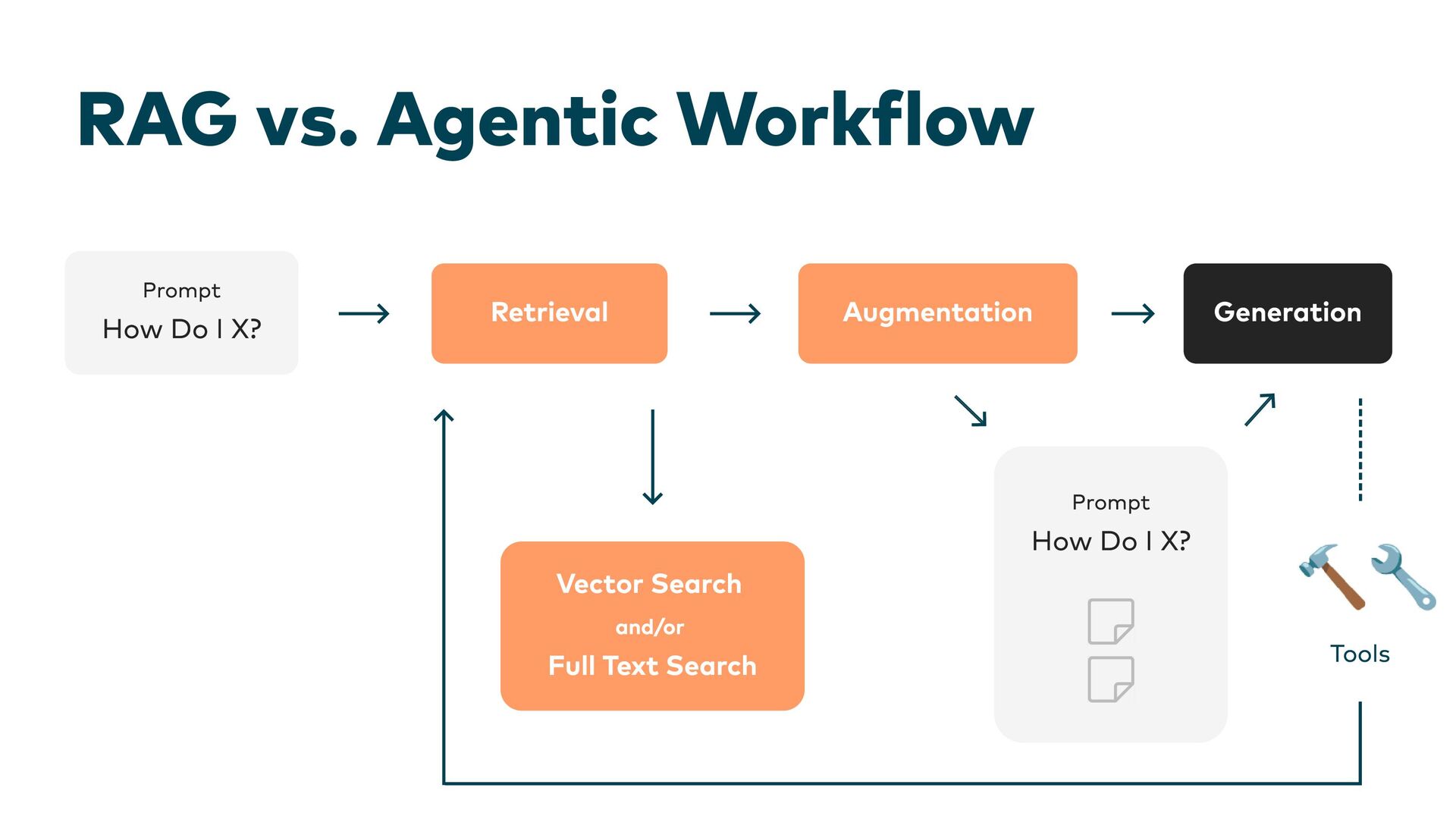
This is where Retrieval-Augmented Generation (RAG) comes in: LLMs are enhanced through targeted information retrieval. In this presentation, we’ll explore the architecture of RAG-based systems. We’ll discuss the integration into existing IT infrastructures and the optimization of data quality and context management. We’ll learn how RAG helps to fill knowledge gaps and improve the accuracy and reliability of generative AI applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Let’s talk. Robert Glaser Head of Data and AI [email protected]](https://files.speakerdeck.com/presentations/974c0ccf3b084d48ad0445a6c5d040fe/slide_57.jpg){kind=link}