Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ある機械学習システムをAWSからGCP/GKEに移行した話 / Machine Learnin...
Search
yukinagae
September 30, 2019
Technology
4.3k
8
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ある機械学習システムをAWSからGCP/GKEに移行した話 / Machine Learning System Migration from AWS to GKE
Data Pipeline Casual Talk Vol.4
https://dpct.connpass.com/event/139163/
yukinagae
September 30, 2019
More Decks by yukinagae
See All by yukinagae
Devin, 正しい付き合い方と使い方 / Living and Working with Devin
yukinagae
3
1.4k
BerglasとCloud Buildを使って秘密情報をセキュアに(できるかも) / Berglas with Cloud Build
yukinagae
1
1.2k
Python用のマイクロサービスフレームワークを探す旅 / A journey to find a microservices framework for Python
yukinagae
0
1.3k
AWSからGCP/GKEに移行してみた / From AWS to GKE on GCP
yukinagae
6
21k
Spotifyのレコメンドを理解する / Recommender Systems using Collaborative Filtering - Spotify
yukinagae
1
920
kintone事例紹介 JAMS.TV ケーススタディ / kintone-casestudy-jamstv
yukinagae
0
310
BigQuery MLの新機能紹介 Cloud Next '19 / BigQuery ML New Features Announced at Google Cloud Next 2019
yukinagae
2
17k
学習行動データ分析基盤 Learning Record Store(LRS)開発事例 / LRS case study
yukinagae
5
2.1k
本当に簡単なkaggleの始め方 / Easy Way to Start Kaggle - short ver.
yukinagae
2
630
Other Decks in Technology
See All in Technology
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
「休む」重要さ
smt7174
6
1.6k
reFACToring
moznion
0
130
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
170
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
520
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
190
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
310
Amazon Quick 入門!
ysuzuki
2
130
Featured
See All Featured
The Pragmatic Product Professional
lauravandoore
37
7.4k
4 Signs Your Business is Dying
shpigford
187
22k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
For a Future-Friendly Web
brad_frost
183
10k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
A designer walks into a library…
pauljervisheath
211
24k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Transcript
ある機械学習システムを AWS からGCP/GKE に移行した話 Data Pipeline Casual Talk Vol.4 -
2019/09/30 @yukinagae
TL;DR AWS で動いている機械学習システムをGCP/GKE 化 した(まずAPI 部分のみ) GCP/GKE 化の理由 リリースサイクルの高速化 インフラコスト削減
( リソース共有) 既存システムも徐々に移行していく予定 新システムは最初からGCP/GKE で構築 2
自己紹介 永江悠紀 @yukinagae エムスリー株式会社 ソフトウェアエンジニア データエンジニア寄り。最近はレコメンド改善 などもやる 元々Java/Scala でサーバサイドの開発をやっていた 最近はGo
+ Python を触ることが多い クラウドはGCP 担当(※AWS わからないだけ) 3
システム移行の背景 エムスリーでは多くのシステムをオンプレもしく はAWS で構築している AI チームではすでに複数の機械学習システムを開 発・リリース済み(AWS ) ※詳しくは以下のスライドが詳しいです: エムスリーにおける機械学習活用事例と開発の効率化
https://speakerdeck.com/nishiba/emusuriniokeru-ji- jie-xue-xi-huo-yong-shi-li-tokai-fa-falsexiao-lu-hua 4
多数のマイクロサービス 2 年間で20 をこえる機械学習システムをリリース 現在も増加中 すごいね!(´∀`) 5
ポイント 1. システム数が多い 6
今回の移行対象のシステム Cantor 記事などのコンテンツの関連度(類似度)を計 算するシステム ※おまけ: システム名はドイツの数学者のGeorg Cantor が由来 7
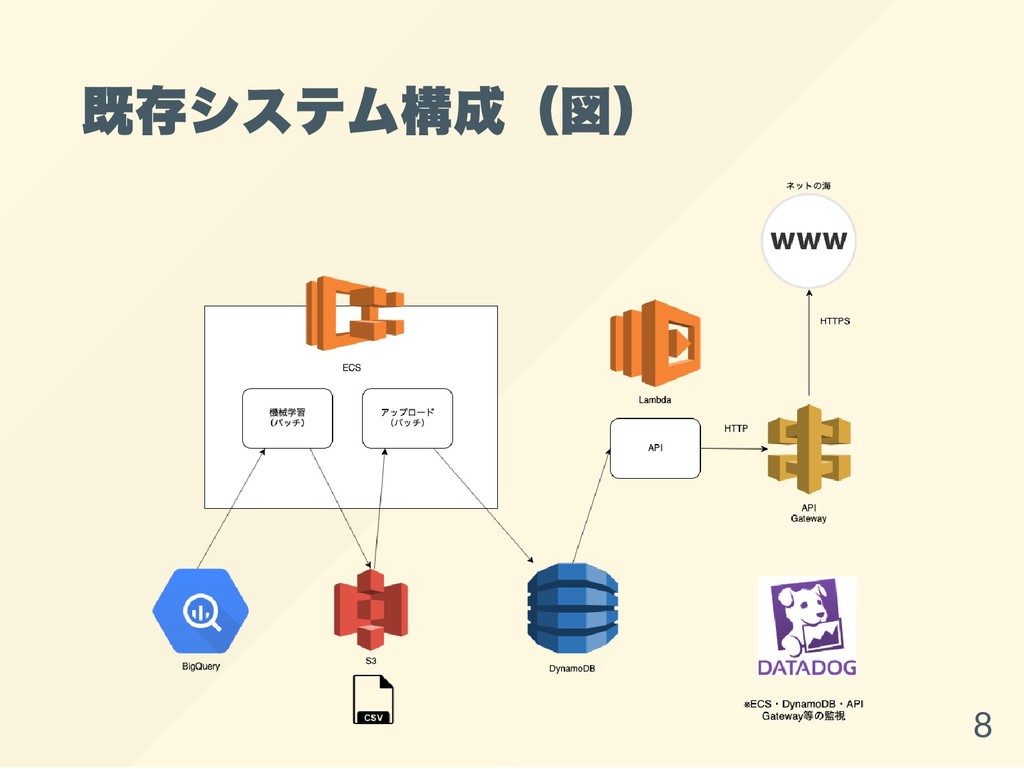
既存システム構成(図) 8
既存システムの課題① 現状のシステム構成だと、GCP/BigQuery → AWS と いうクラウドをまたいだ構成になってしまっている 9
ポイント 2. BigQuery とAWS の混在 10
既存システムの課題② Cantor というシステム構成特有の課題: Lambda でもろもろ問題があった 15 分に一度バックエンドのECS が停止されてし まう(確率的にタイムアウトが発生) 11
既存システムの課題③(※改善点) 簡単・頻繁にリリースしたい すぐリリースしたい(※カナリアリリース etc ) バグなどの際すぐ以前のバージョンに戻したい マイクロサービスの粒度のシステムが増えている ので各環境を用意するのは大変 運用や管理が面倒 インフラコストがかさむ
12
ポイント 3. どんどんリリースしたい 4. 運用・管理を楽にしたい 5. インフラコスト削減したい 13
新システム構成の選択肢 AWS なら EC2 ECS EKS GCP なら Cloud Run
GAE ( ex ) GCE GKE 14
技術選定のポイントいろいろ インフラコスト 運用の手間 クラウドベンダーのサービスの成熟度やマイルス トーン ワークロードの特性 必要なリソース要件 チーム体制(例: 人数 /
スキル / 学習コスト) 15
ポイントを振り返る 1. サービス数(API )が多い 2. BigQuery とAWS の混在 3. どんどんリリースしたい
4. 運用・管理を楽にしたい 5. インフラコスト削減したい 16
GKE でいい感じに作れるのでは? ( `・ω ・´) 17
想定するメリット コスト削減 複数サービスをGKE で構築しリソース最適化 メンテナンスコストも削減(されるはず) リリースの高速化 オーダーメイドから量産体制へ terraform k8s 可用性も向上
全部GCP にできてBigQuery もにっこり(´∀`) 18
移行方針: どうやって移行するか? 1. まずはAPI 部分(システムの一部)からの移行 2. 段階的にすべてを移行していく まずはAPI 部分からの移行を実施 影響範囲を小さくしたい
API だけなら最悪どうにでもなる もともとのAWS ヘの切り戻しも容易 機械学習部分をいきなり移行してデグレったら 嫌だよね(/ ・ω ・)/ 汗 19
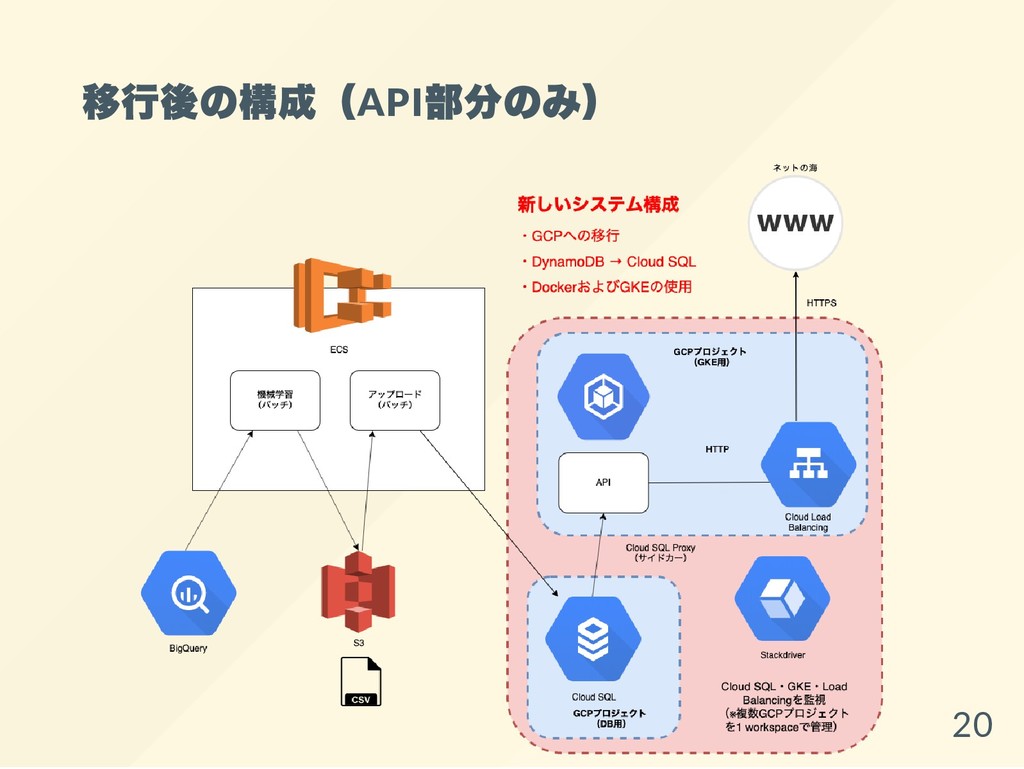
移行後の構成(API 部分のみ) 20
GKE からCloud SQL に接続 Cloud SQL Proxy で別GCP プロジェクトのDB に接
続する構成(マイクロサービス的な構成) 原理的にPrivate IP で直で接続するより当然遅い Cloud SQL Proxy にした場合にどれくらい遅くなる かは簡易的に検証(※当然実環境とは異なるが) medium 記事: https://medium.com/google-cloud- jp/eb1fbd049d56 github: https://github.com/yukinagae/latency- comparison-of-cloud-sql-connection 21
移行後の理想(全部GCP/GKE 化) 22
今後の移行方針 既存サービスのGCP/GKE 化 まずは今回のプロジェクトで導入実績を作り、 運用経験を積む 他サービスも徐々に移行していく(※移行すれ ばするほど、インフラ・運用コストを削減でき る) 新規サービスは最初からGCP/GKE で構築
次に発表する katio2 さんがそのサービスの話を してくれると思います( `・ω ・´) 23
ありがとうございました! (´∀`) 24
(おまけ)GKE 移行の辛み k8s/GKE 周りのノウハウや経験がないので手探り そもそもk8s 自体の学習コストが高い k8s の公式ドキュメントそのままだと動かない GKE はだいたいβ
版 25
(おまけ)GCP での運用・監視 datadog はちょっと辛い 既存のAWS システムではdatadog をdashboard で使 ってたが、GCP で使うのは辛い
PubSub 経由でdatadog にpush する仕組みを毎回 作らないといけない GCP プロジェクト毎に認証をしないといけない の大変 datadog APM の導入はめちゃくちゃ楽 しかし、もちろんcontainer 周りの指標しか取得 できない 26
(おまけ)現状の運用・監視方法 Stackdriver Monitoring 使う理由 datadog 用に追加のintegration 作業が不要 複数プロジェクトを一つのworkspace にまとめれ ば、GKE
やCloud SQL のプロジェクトが別でも1 つ のdashboard で監視できる alert policy やヘルスチェックもそのまま作れる (※現状はterraform 使わず、あえてGUI で手動 作成している。理由としては、監視しながらち ょこちょこ値を調整したいから) 27
(おまけ)現状の運用・監視方法 結論 GCP の場合にはStackdriver のみ使うことにした Stackdriver monitoring での監視 alert policy
の作成 + slack 通知 dashboard の作成 Stackdriver Trace でのパフォーマンスチェック opencensus 入れた Stackdriver for python はα 版。。。( `・ω ・´) 汗 28
おわり 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}