Share
Interspeech2019 &サテライト論文読み会 ソニーシティー大崎、2019年11月24日 #interspeech2019jp
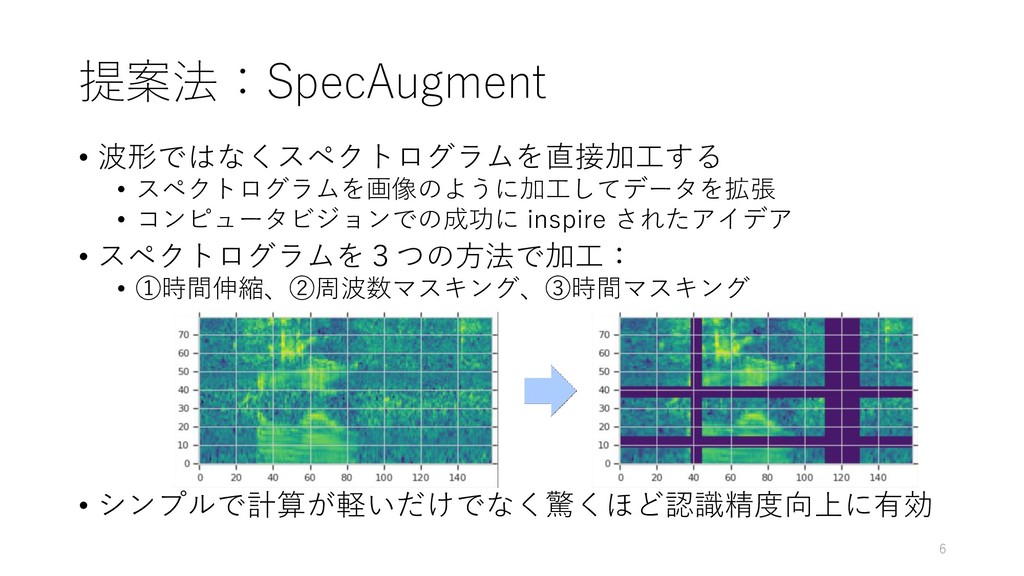
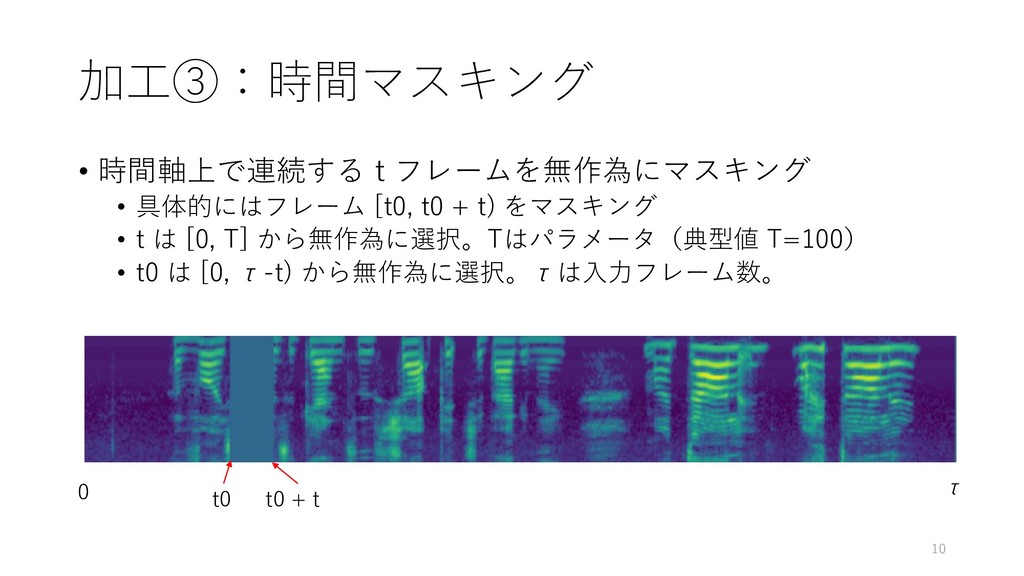
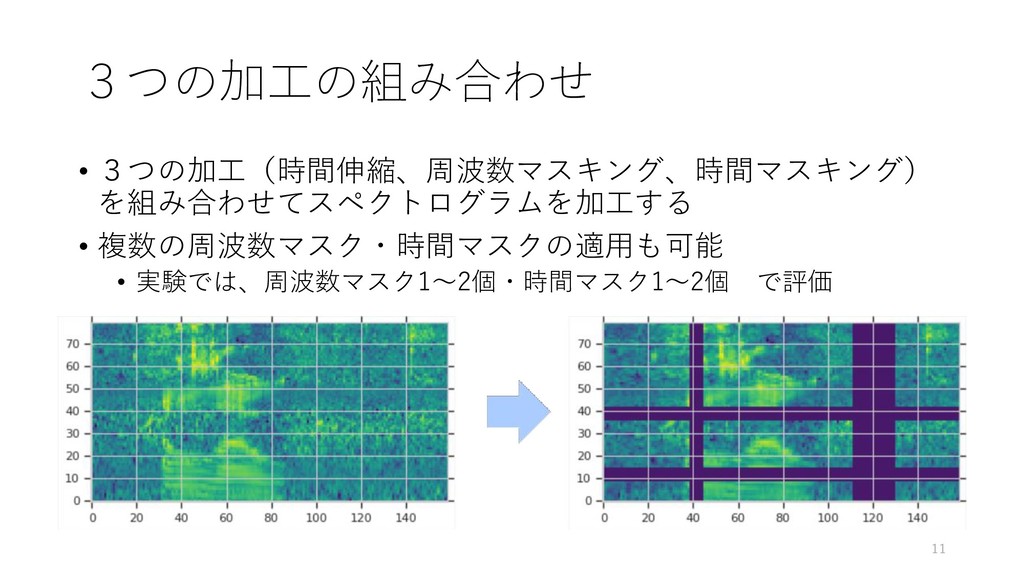
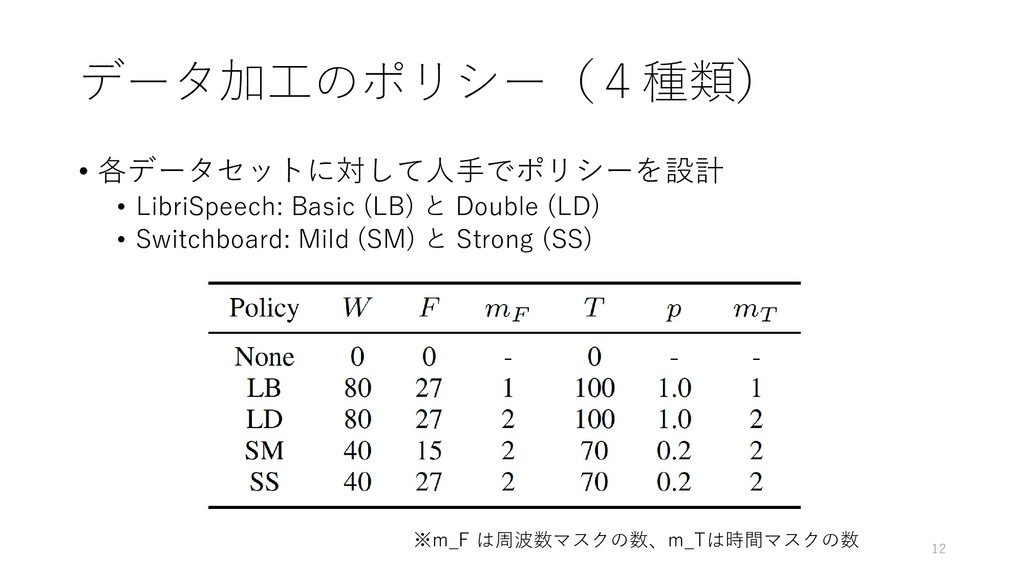
【紹介する論文】 SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition (Google Brain)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![加工①:時間伸縮 1. スペクトログラムのx軸上で1点(制御点)を選択する • ただしこの点は x 軸の [W, τ-W] から無作為に選択。Wはパラメータ(典型値](https://files.speakerdeck.com/presentations/5023423bee4849509a59916e46516d1a/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
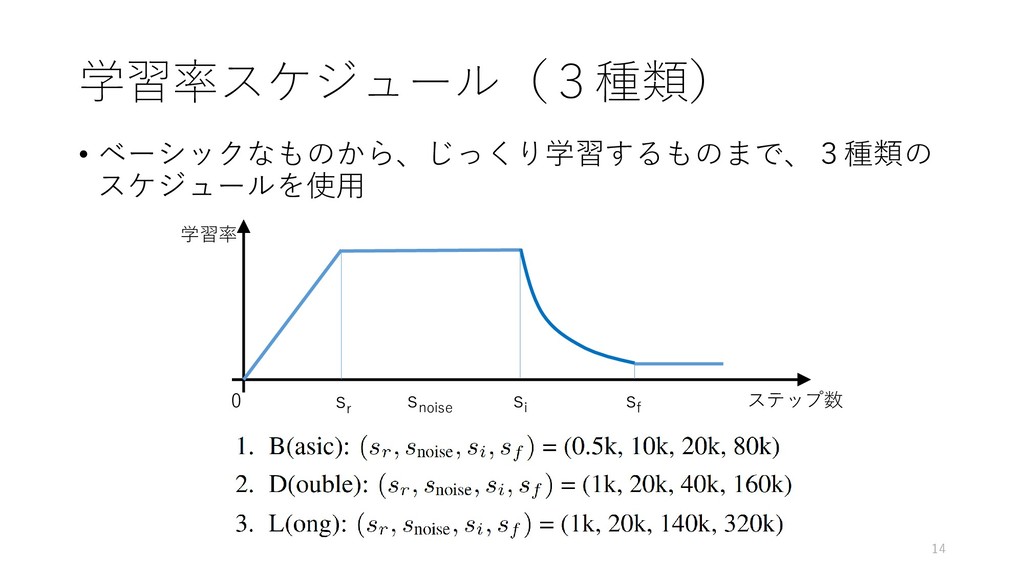{kind=link}
{kind=link}
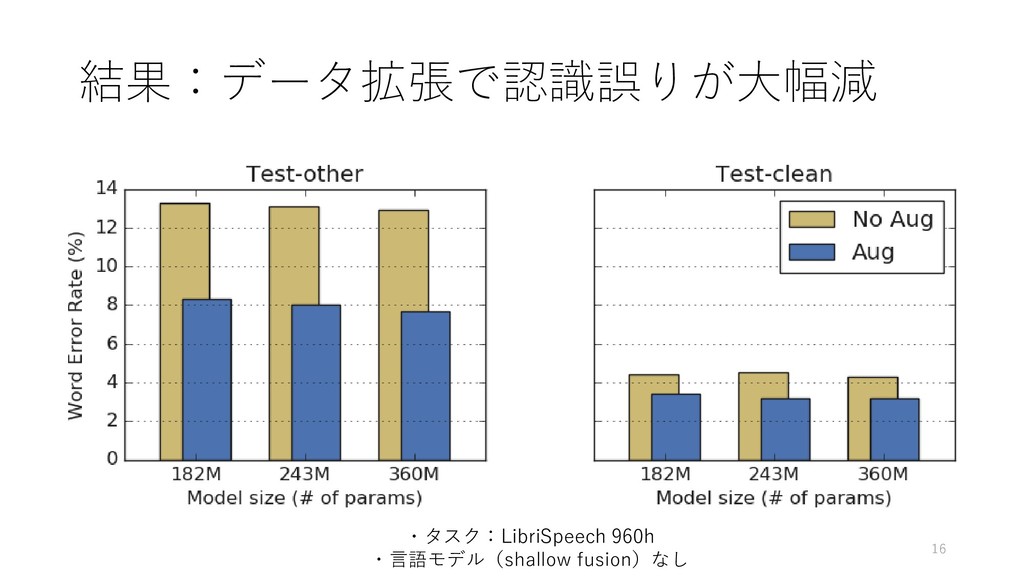{kind=link}
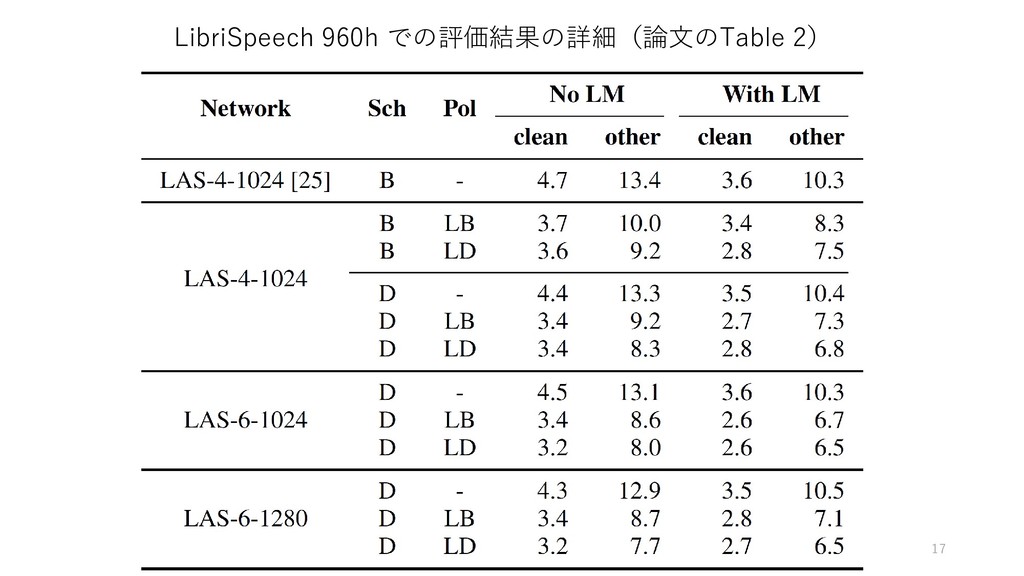{kind=link}
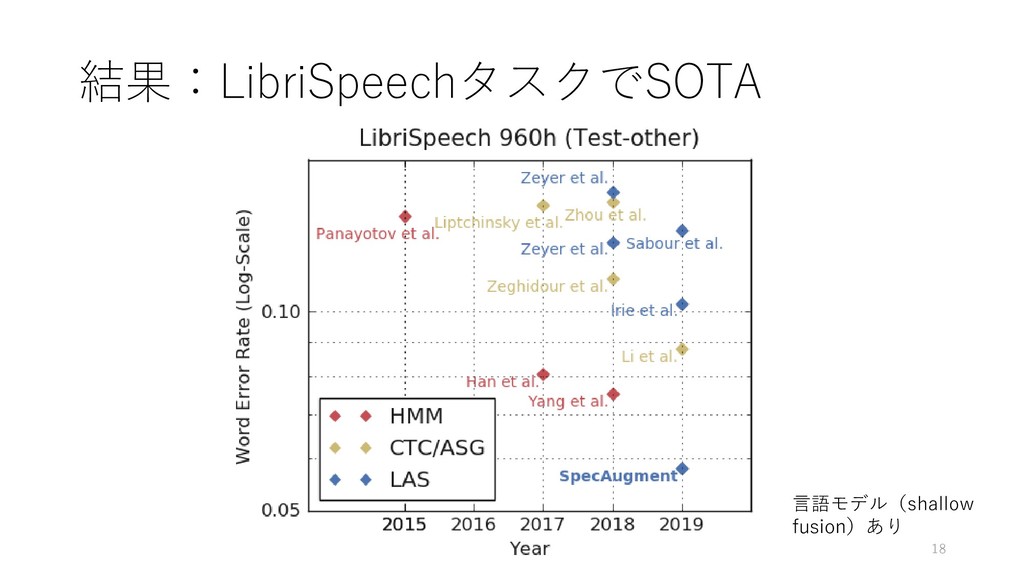{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}