DINOv3 is Meta AI's latest vision foundation model that pushes self-supervised learning to an unprecedented scale.
This talk introduces the key ideas behind DINOv3, including:
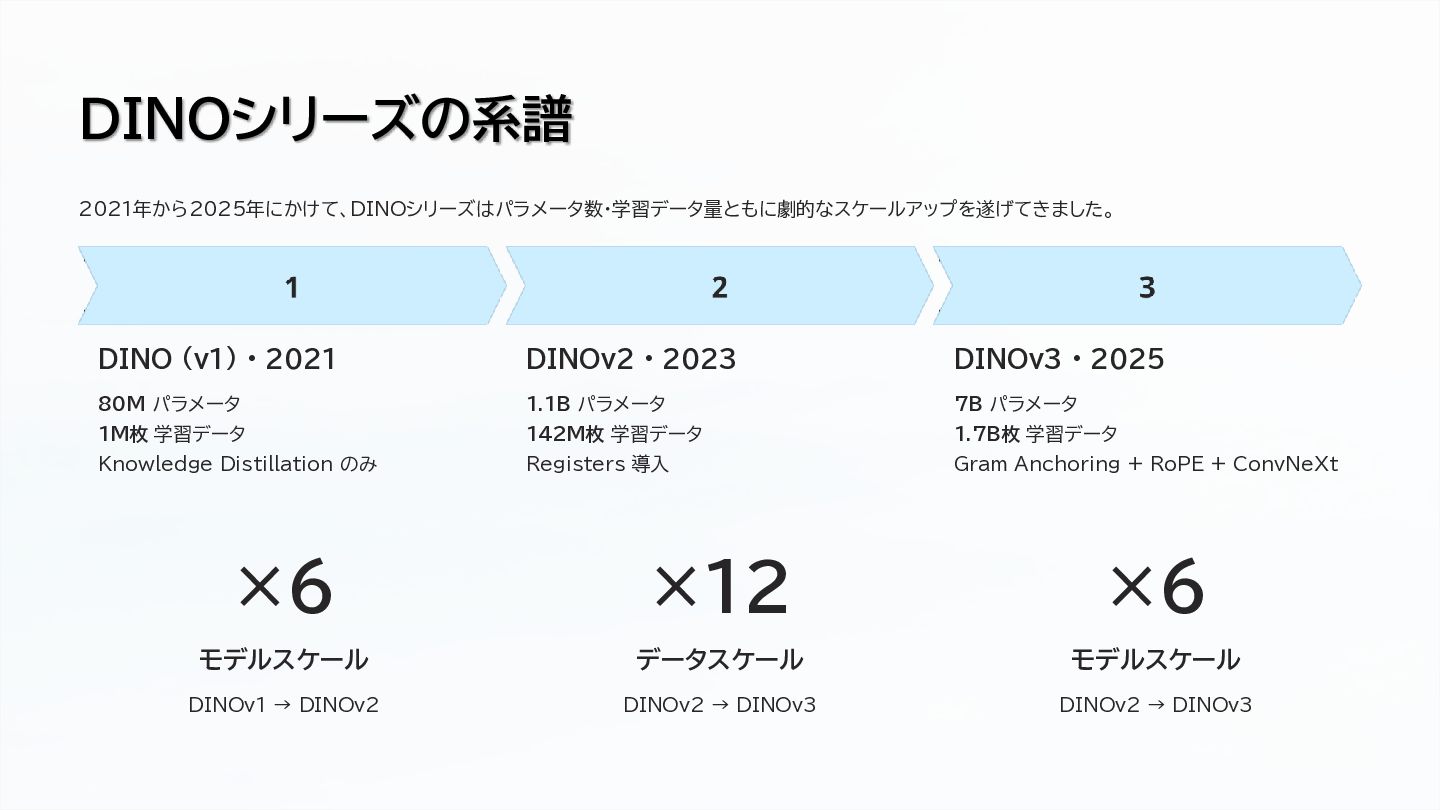
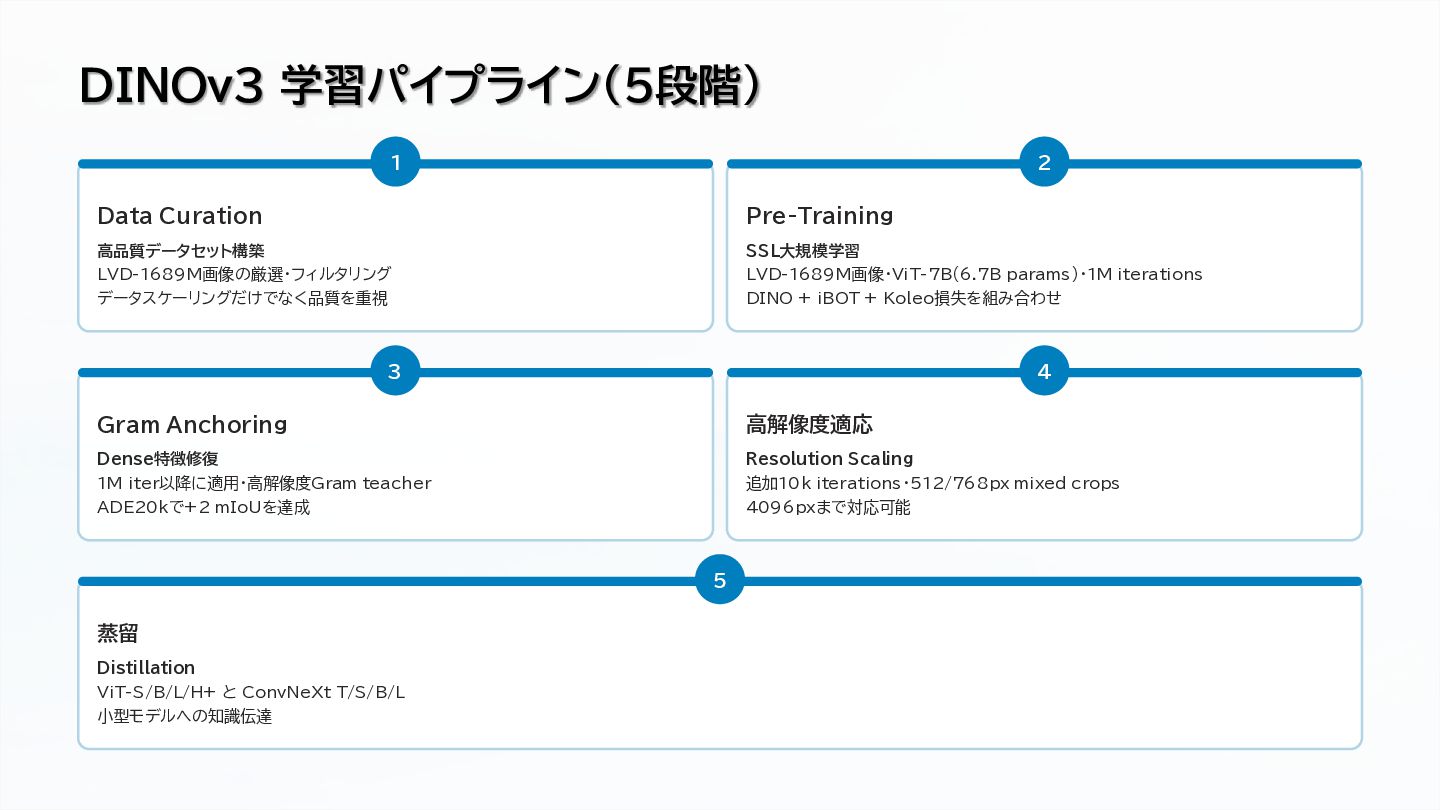
Large-scale data curation (17B images)
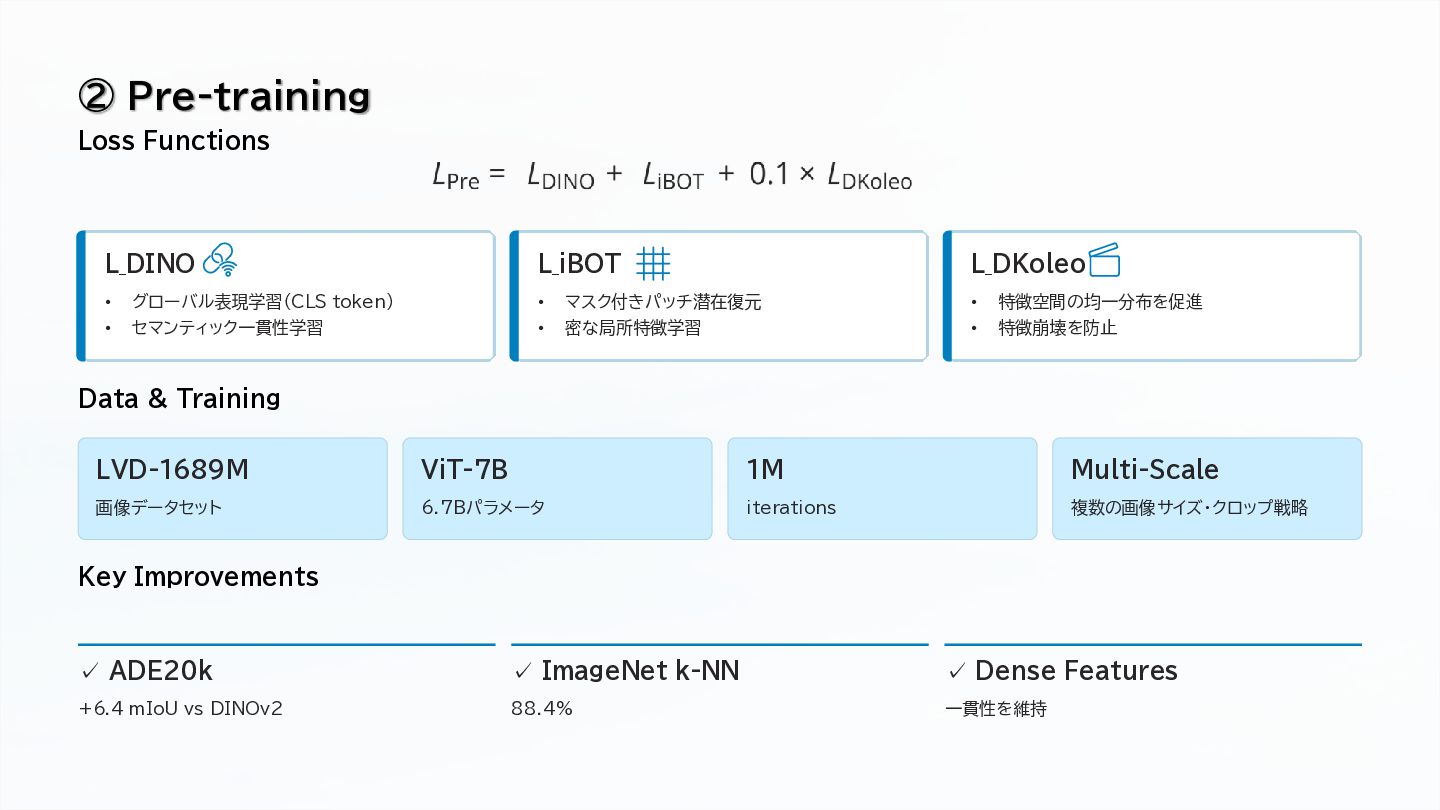
Self-supervised pre-training with DINO and iBOT objectives
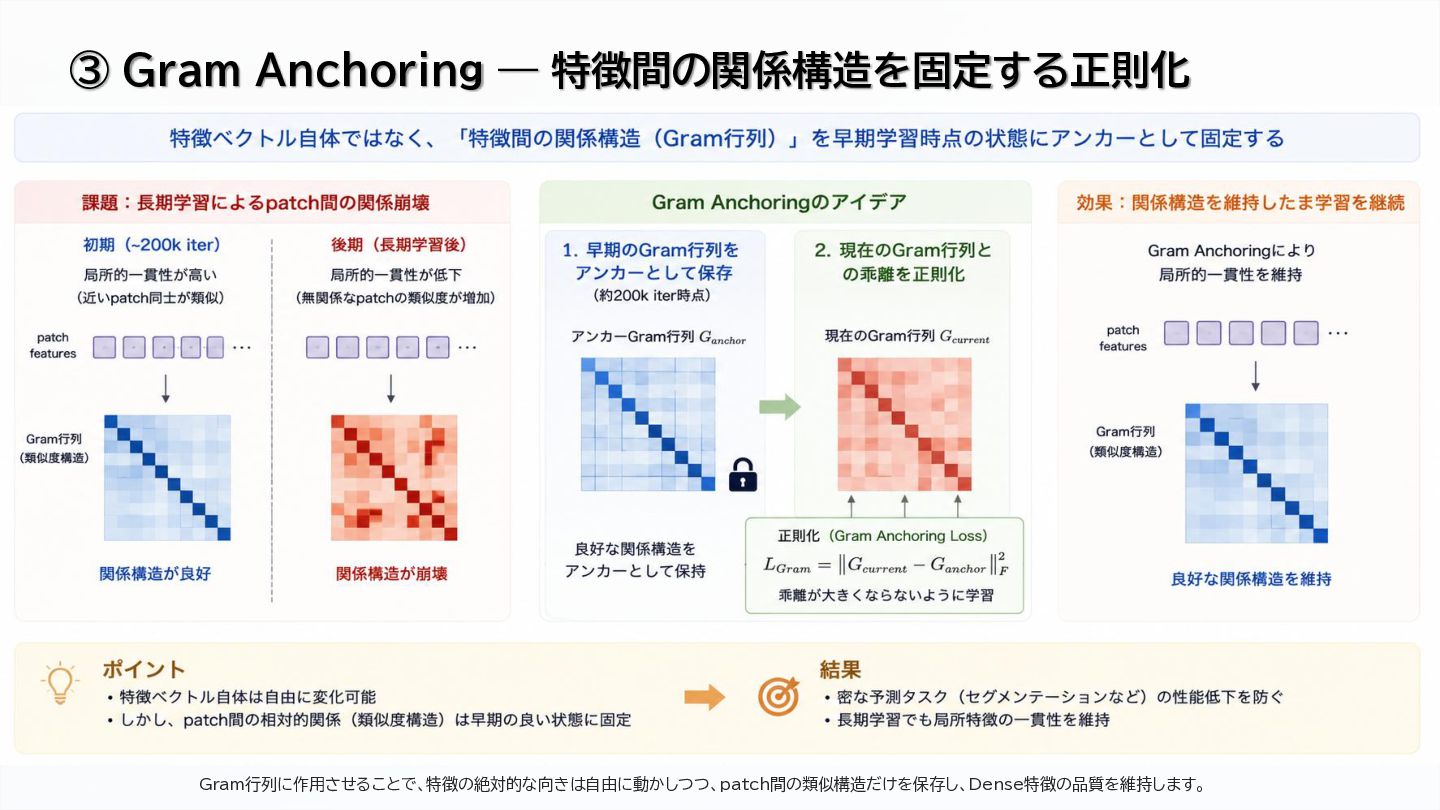
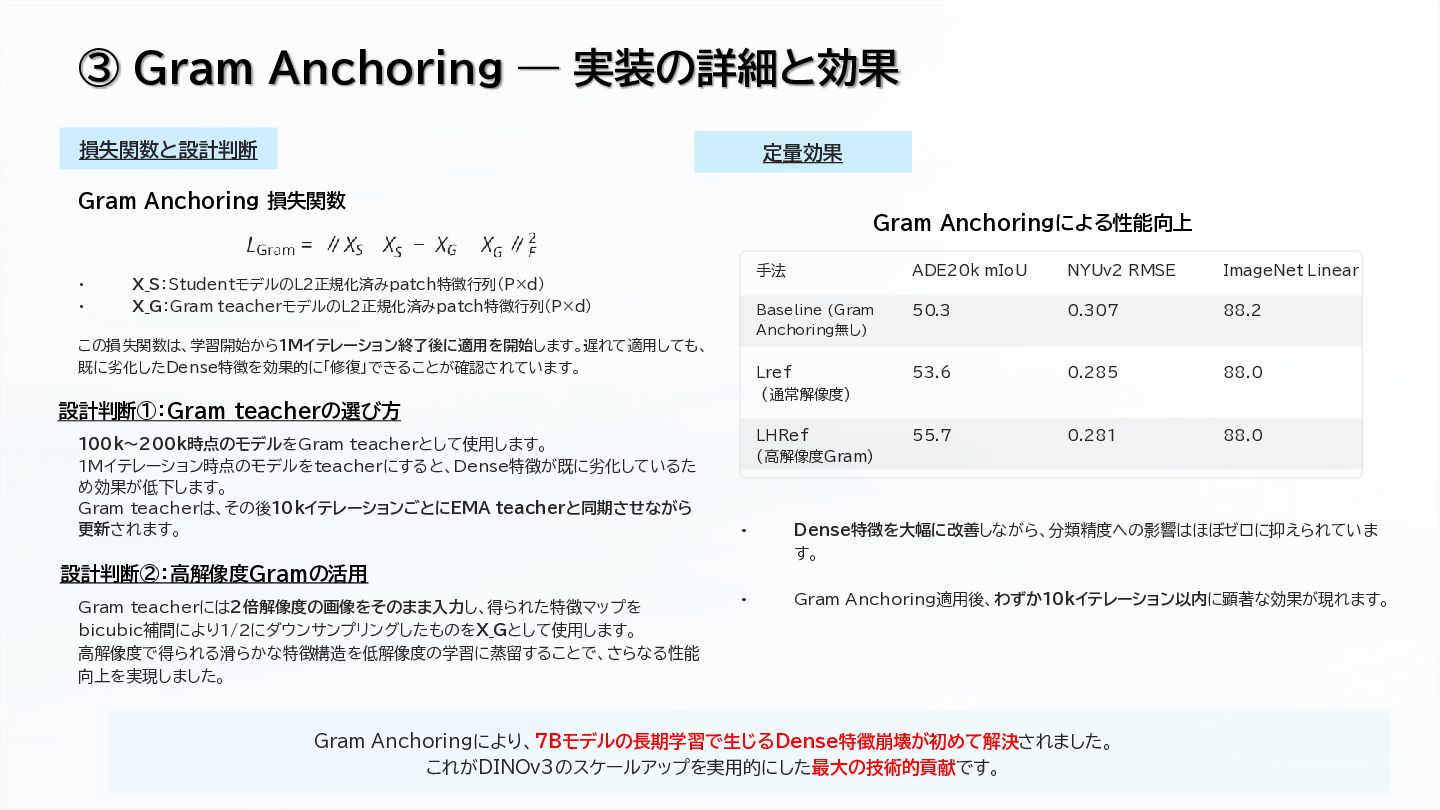
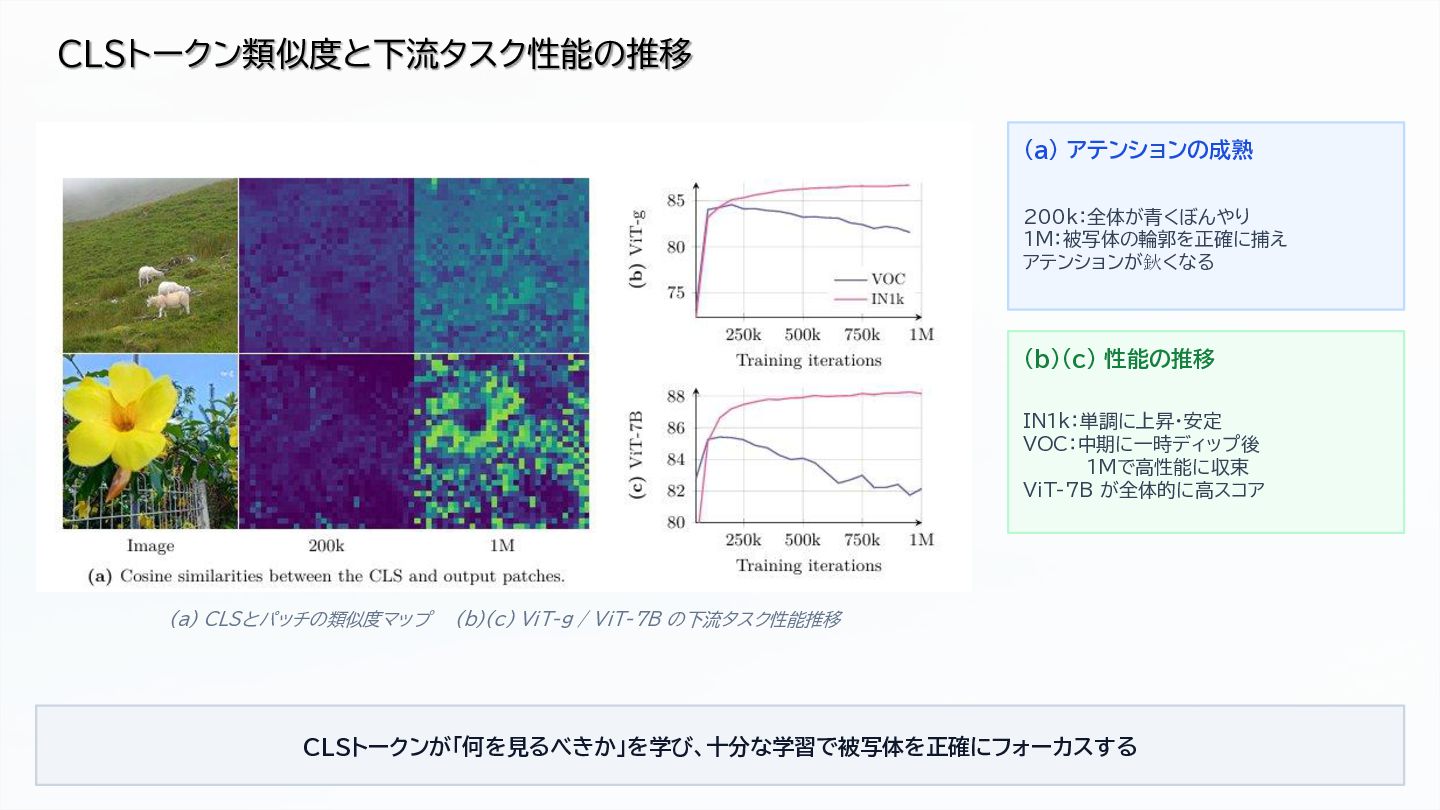
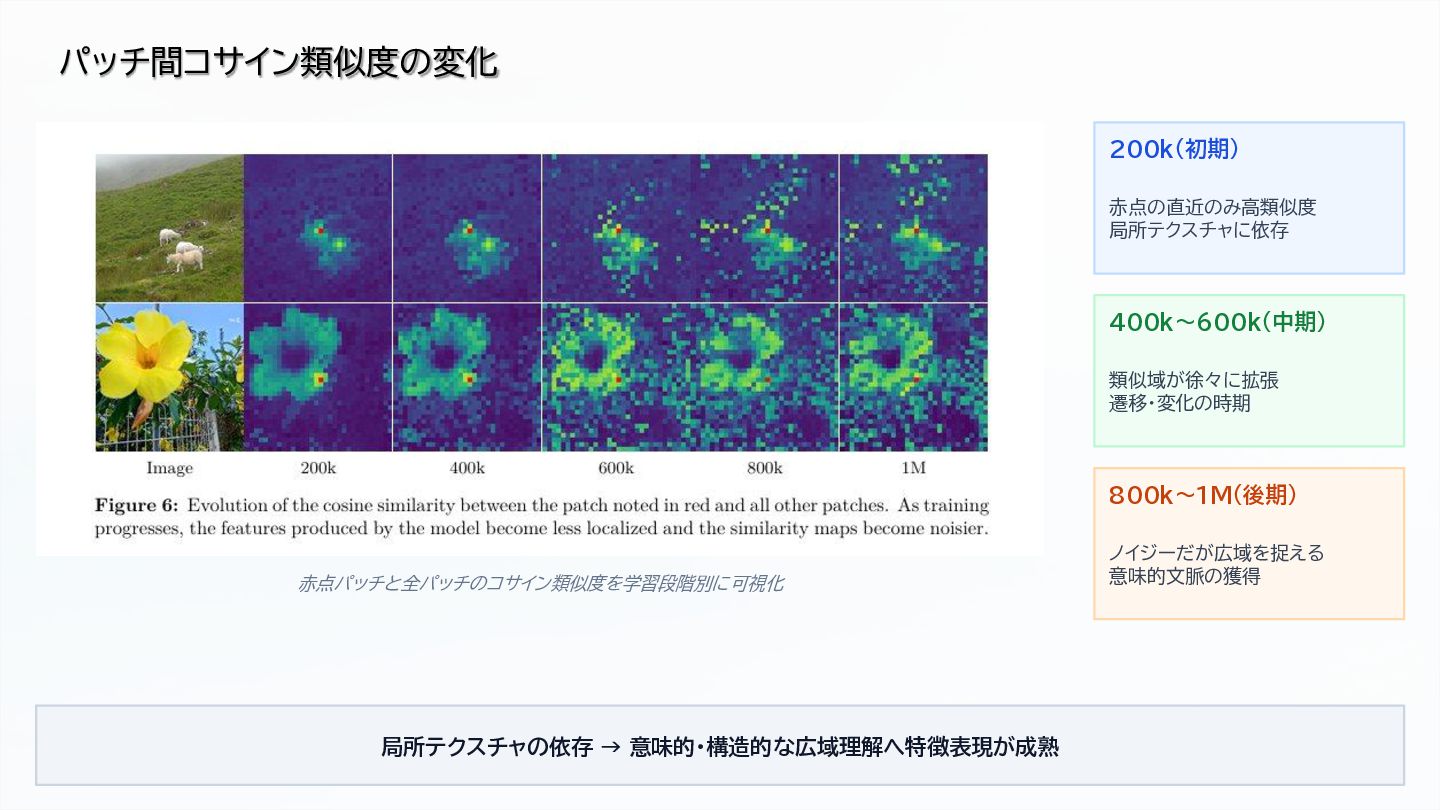
Gram Anchoring for dense feature preservation
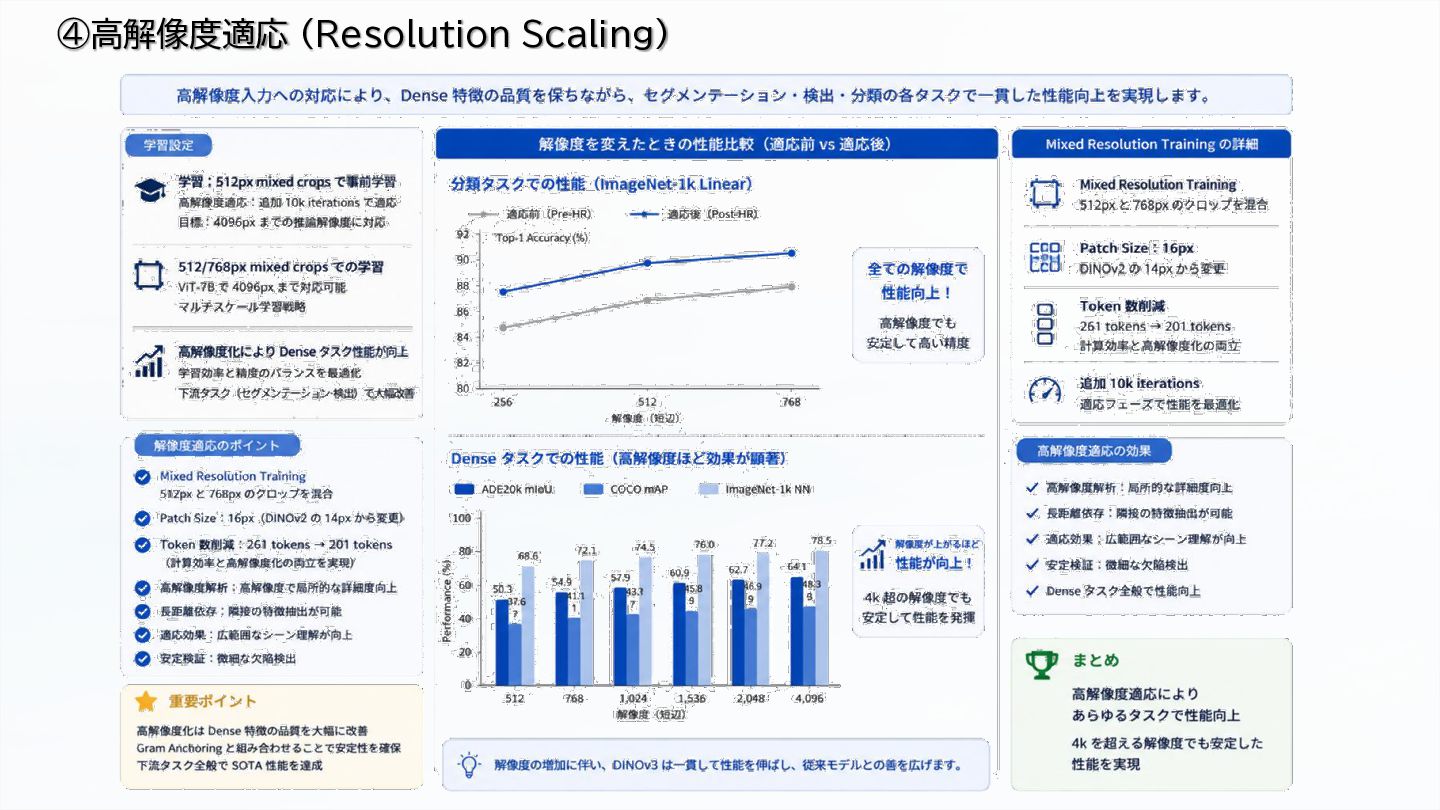
High-resolution adaptation up to 4K+ inference
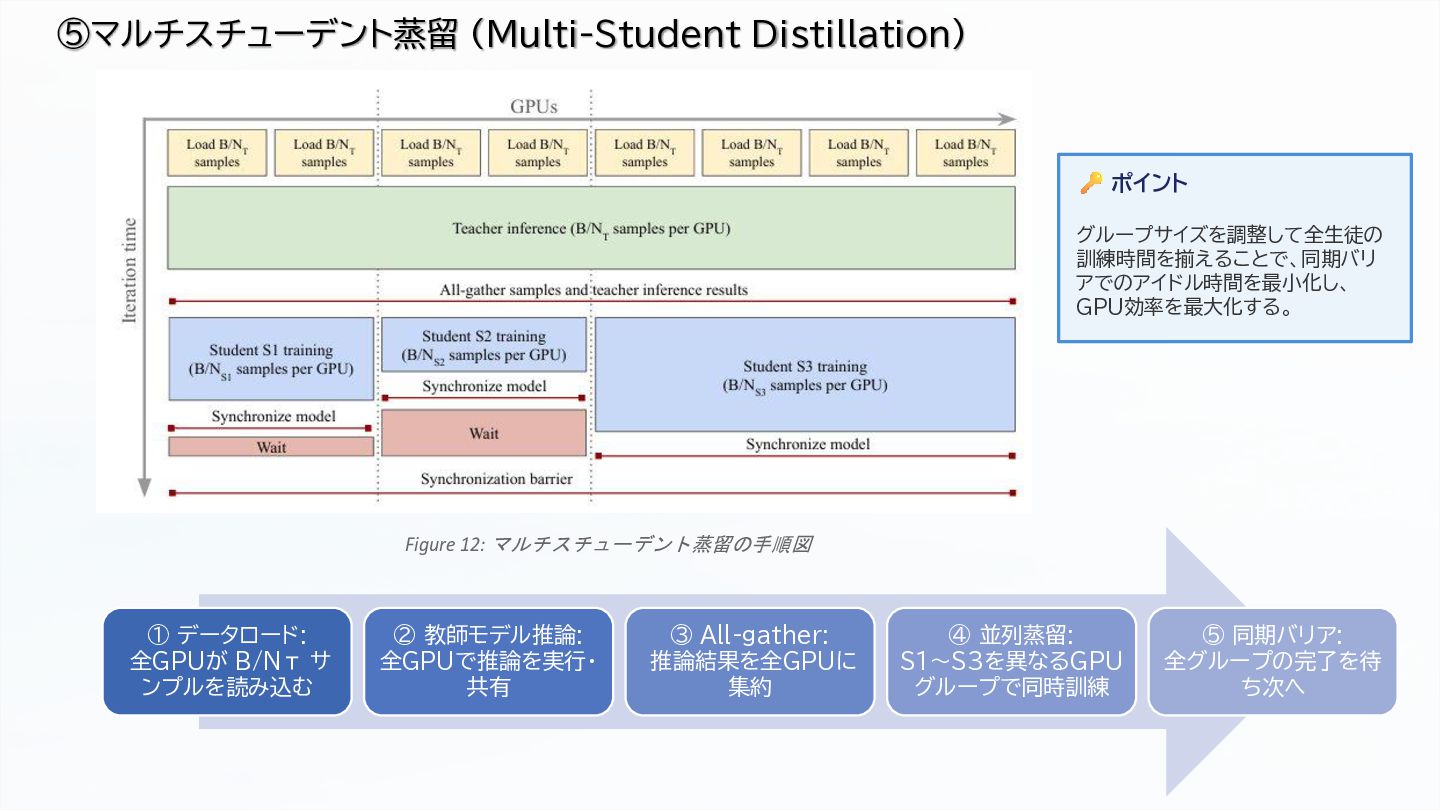
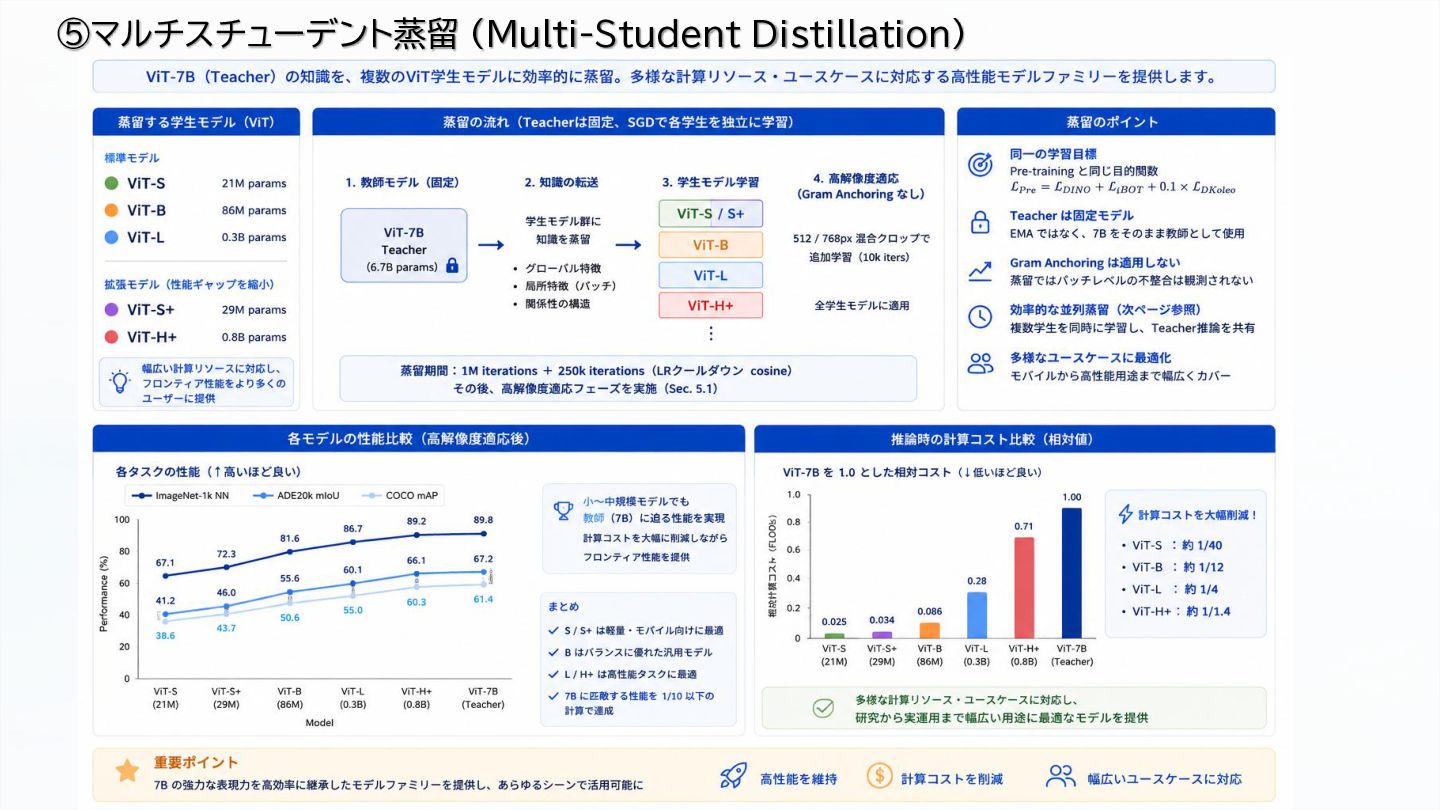
Efficient multi-student distillation
We will explore how these innovations enable DINOv3 to achieve state-of-the-art performance across a broad range of computer vision tasks while improving scalability, robustness, and deployment efficiency.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
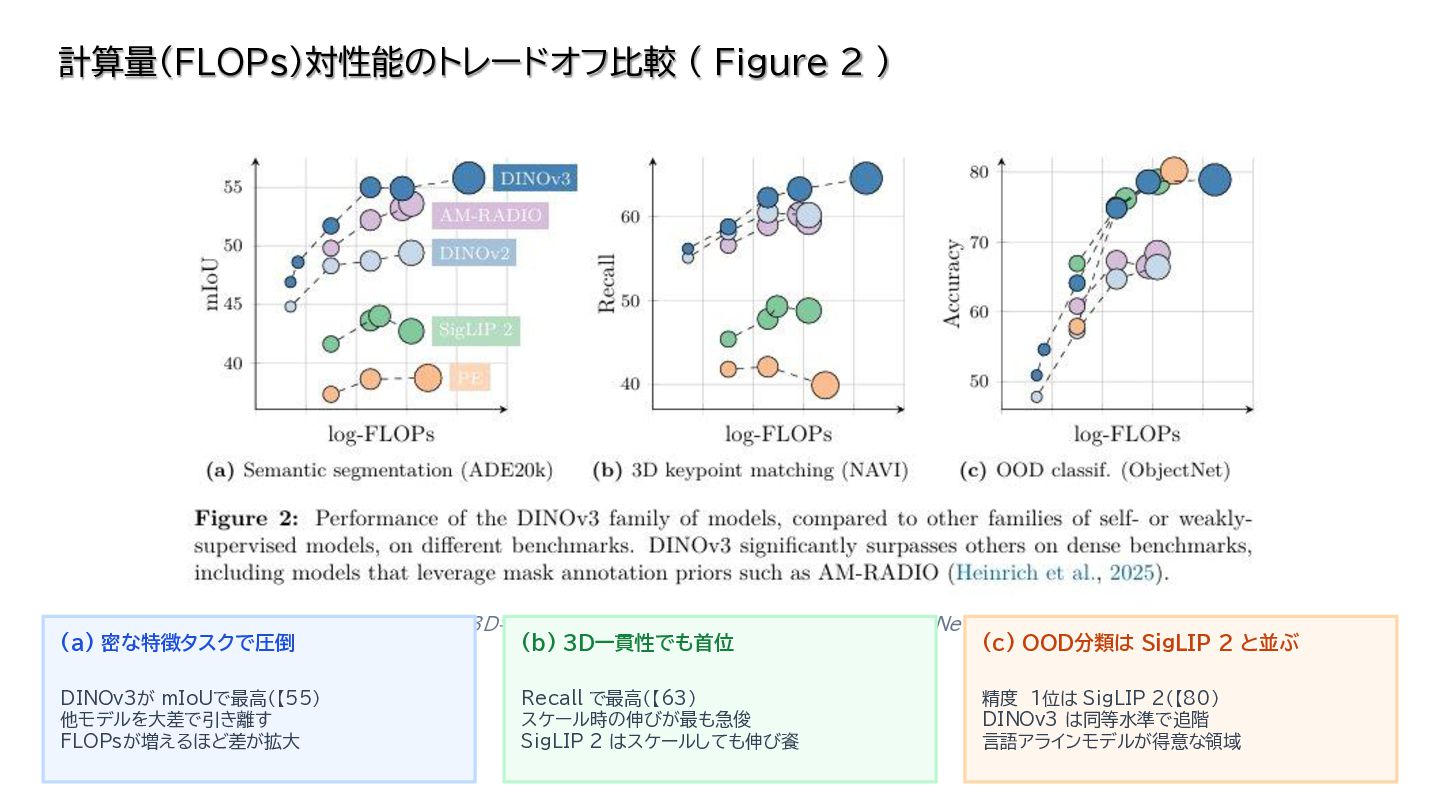{kind=link}
{kind=link}
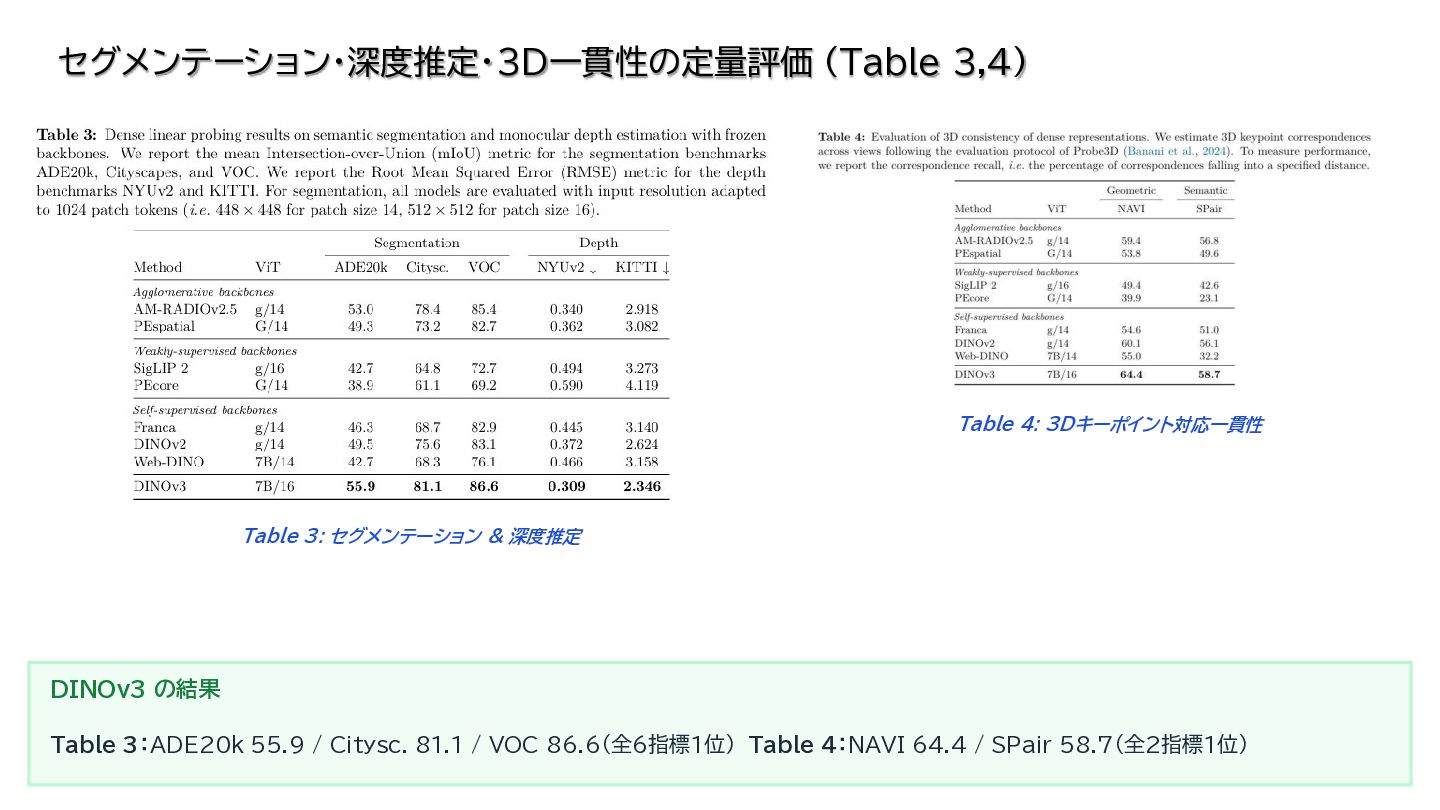{kind=link}
{kind=link}
{kind=link}
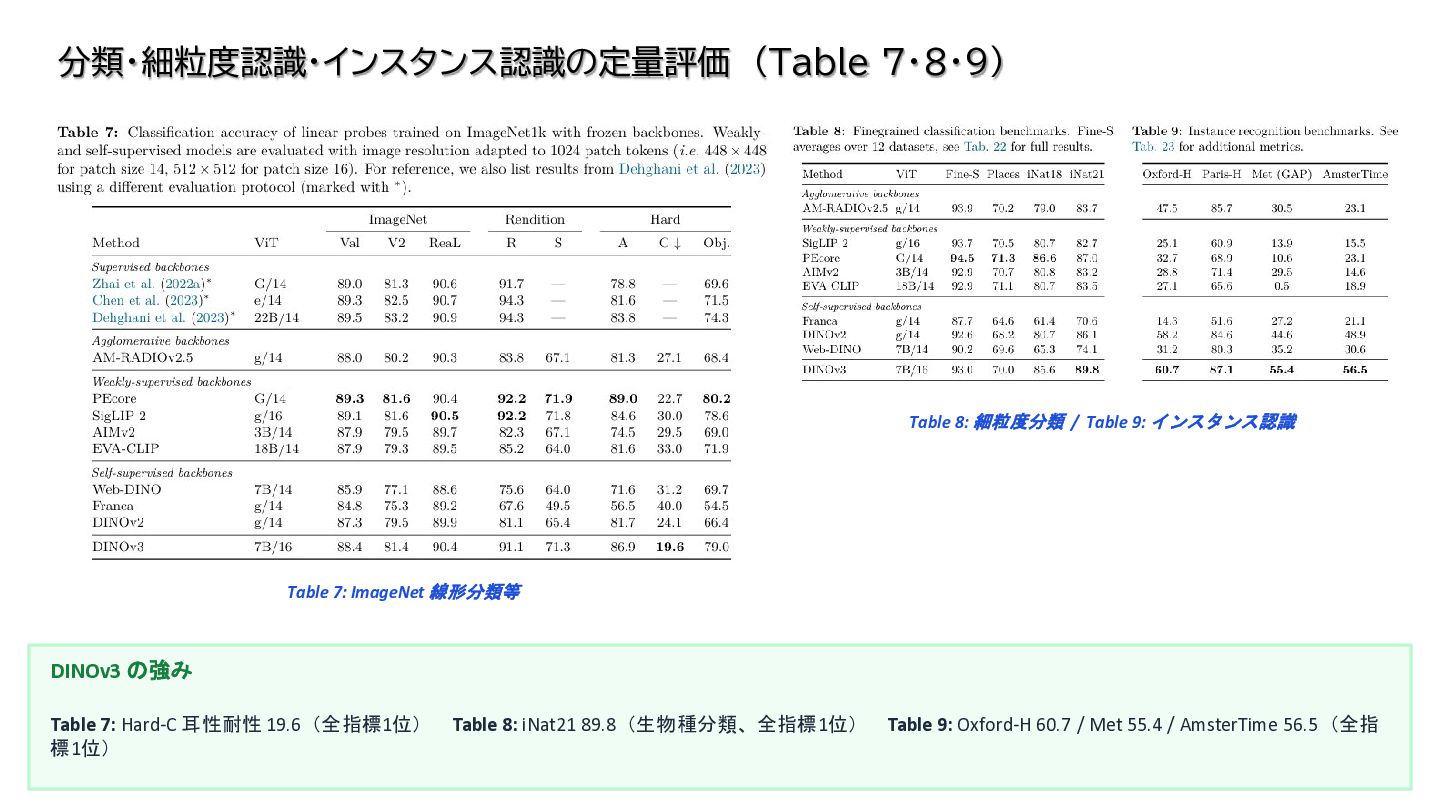{kind=link}
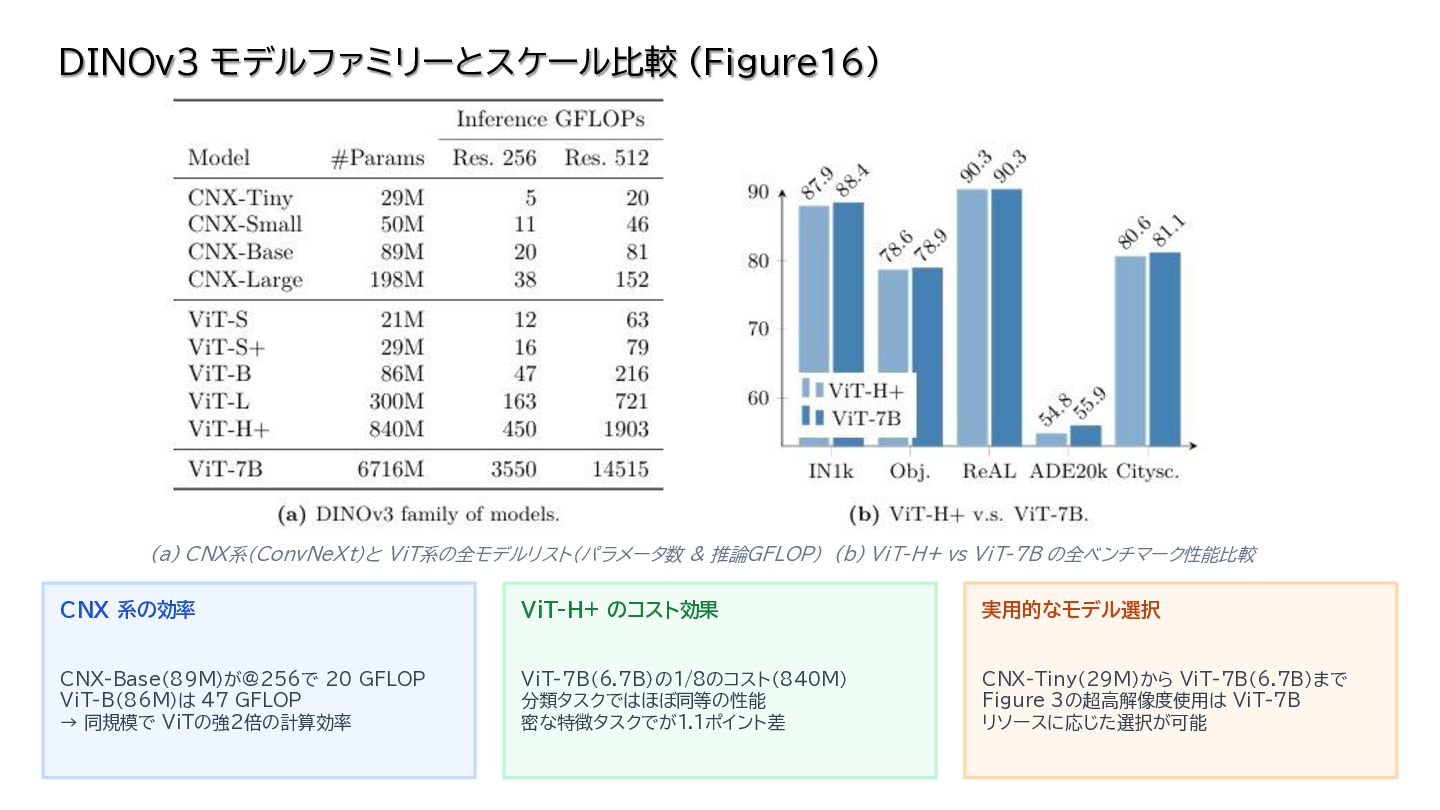{kind=link}
{kind=link}
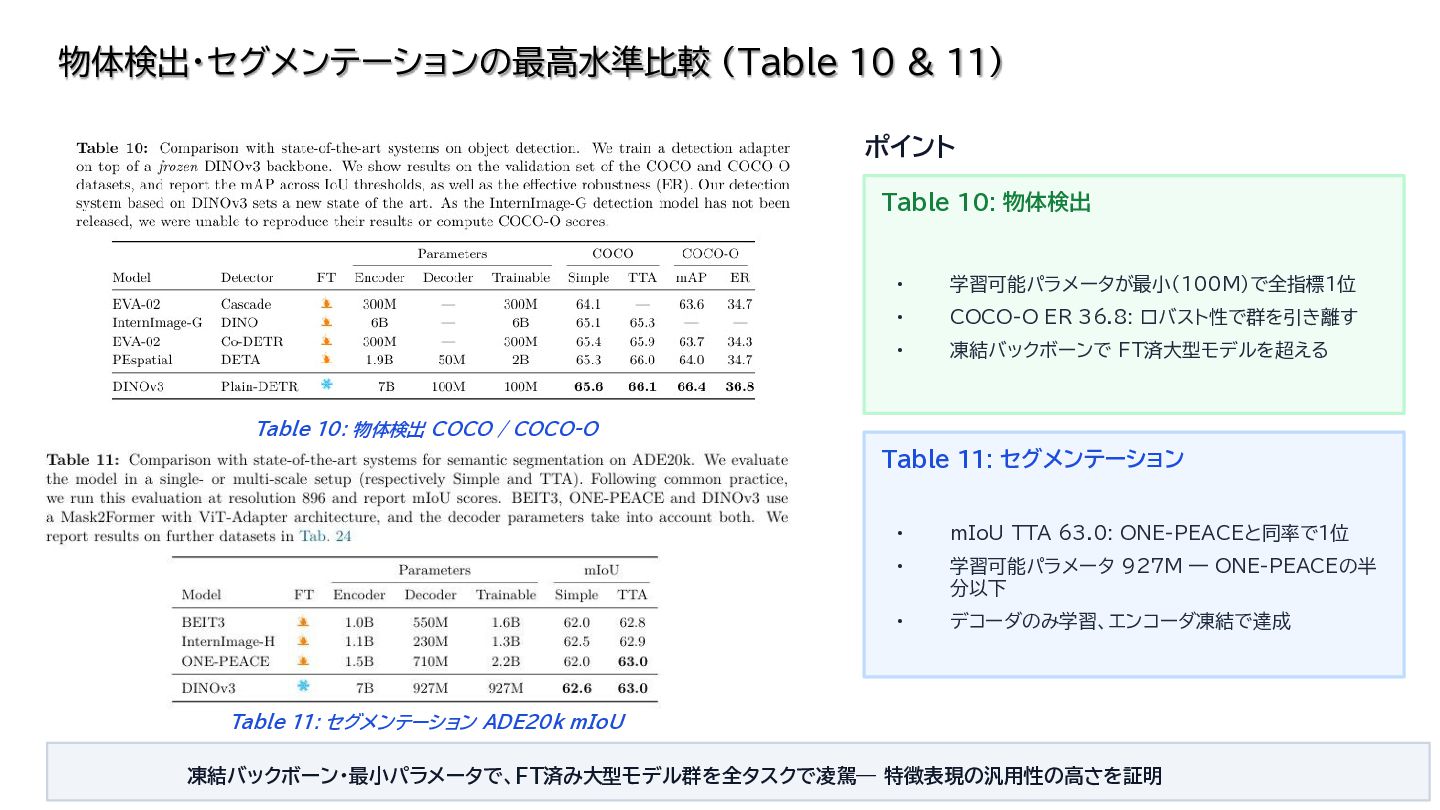{kind=link}
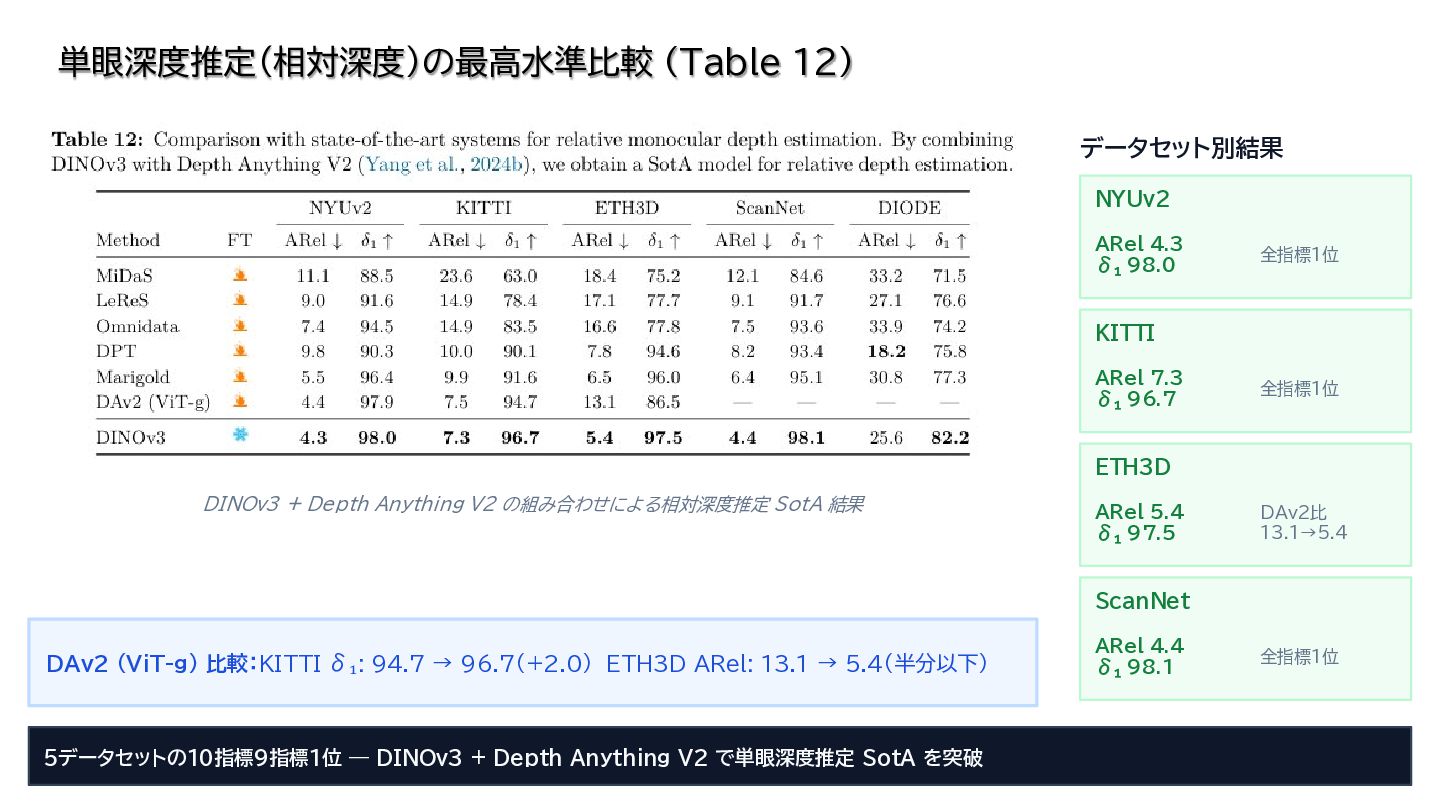{kind=link}
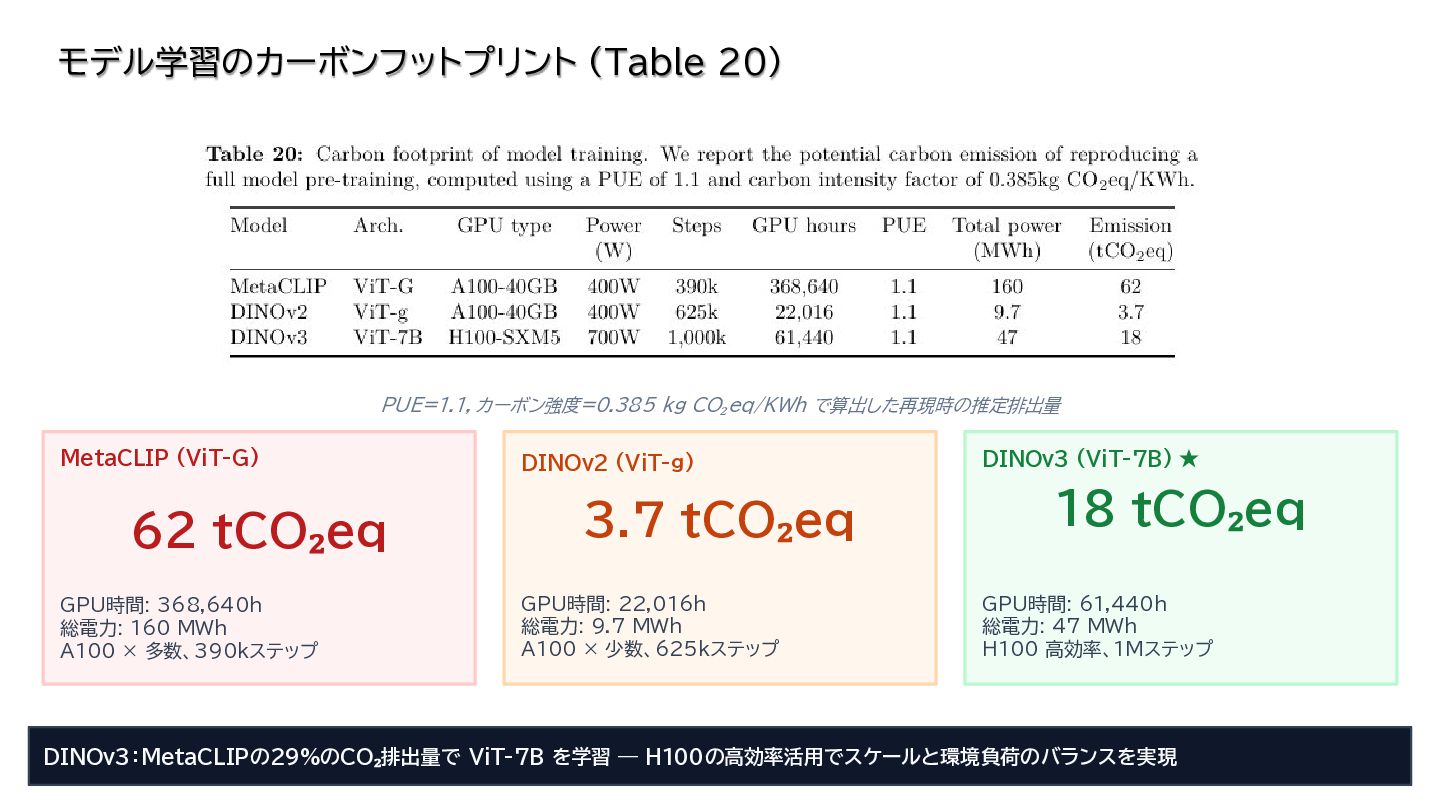{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}