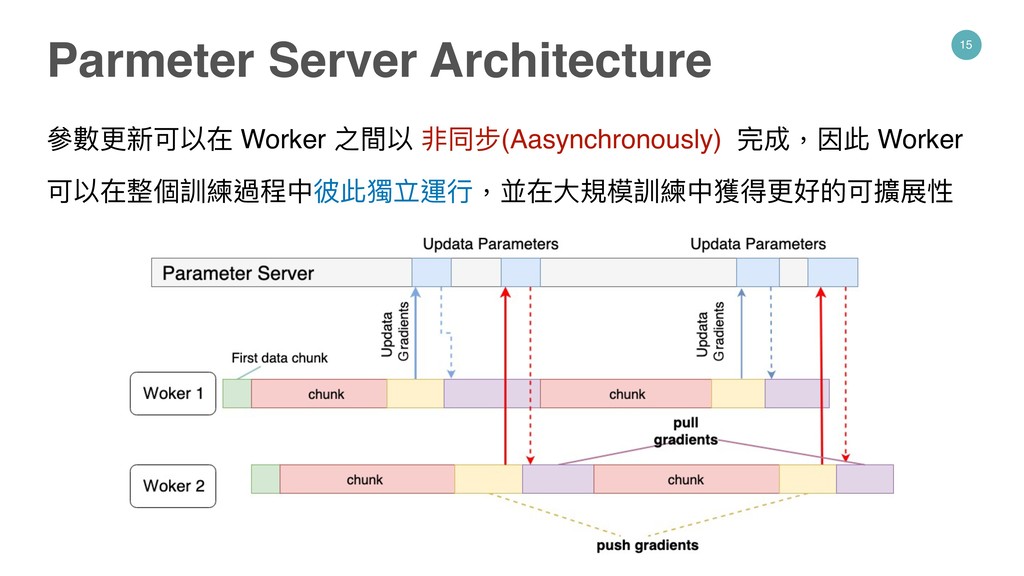
Worker 進⾏行行平⾏行行訓練 Worker : • 獲得從 PS 發送的域值(Value)來來計算每次迭 代(iteration)訓練 最 後 將 W o r k e r 訓 練 過 後 所 獲 得 新 的 梯 度 (Gradients),發送到 PS 並更更新參參數,即完成同步 更更新參參數的訓練流程 Parmeter Server Architecture Ref: Large Scale Distributed Deep Networks - NIPS Proceedings Parmeter Server Architecture
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Tensorflow 分散式訓練 17 tf.train.ClusterSpec({ "worker": [ "worker0.example.com:2222", "worker1.example.com:2222", "worker2.example.com:2222" ],](https://files.speakerdeck.com/presentations/d5cbf07799a14ff5917004197cac6f52/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![34 Thanks! You can find me at : [email protected] Any](https://files.speakerdeck.com/presentations/d5cbf07799a14ff5917004197cac6f52/slide_33.jpg){kind=link}